Новость одной строкой: клиентам стали доступны графики потребления ресурсов виртуальными машинами в облаке.
Несколько скриншотов этой статистики даже появлялось у нас в блоге.
Мы уже почти были готовы опубликовать её для клиентов, как, вдруг, обнаружился прискорбный факт: при буквально нескольких сотнях машин 8-ядерного Xeon'а не достаточно для того, чтобы посчитать её всю.
Причина была в наивной математике. Источники статистики для каждой виртуальной машины:
На третьей сотне машин нам пришлось выключить нашу «наивную» статистику и задуматься о том, как это делать правильно…
Итогом стала, немного не мало — собственная специализированная база данных и довольно хитрый алгоритм накопления статистики. По нашим подсчётам получившаяся конструкция сможет обслуживать несколько десятков тысяч машин. Ради этой БД нам даже пришлось отказаться от python — языка, который используется для разработки большей части нашей системы — и обратиться к Erlang. Сам я его не очень люблю, но вынужден признать, что поставленную задачу он решает много успешнее питона (для которого полноценная многозадачность и десятки тысяч транзакций в секунду — это явный перебор). Второй важной особенностью была хорошая поддержка «недотредов» (аналог гринлетов, фиберов с конкурентной многозадачностью) с изоляцией ошибок, готовым супервизором и ITC (inter thread communication).
Почему же мы не выбрали RRD? Ответ прост и печален: RRD не поддерживает bulk insertion — вы не можете за одну операцию сохранить несколько значений. Это означает, что вам придётся делать тысячи раздельных транзакций, каждая из которых больно бъёт по диску.
Конвейеры двигаются с разной скоростью (читай, имеют разное разрешение), и имеют определённую длину — собственно, интервал, за который доступна статистика с заданным разрешением. При записи одного значения оно распределяется по всем конвейерам сразу же (как медленным, так и быстрым), плюс, за раз можно записывать значения для множества разных конвейеров для разных схем.
Про скорость этого решения я уже писал, но помимо скорости такой подход решил ещё одну задачу — у нас нет дрожания (на самом деле, оно есть, из-за неточности определения момента записи в ведро и ошибками округления до целых, но оно составляет от 0.1 до 0.5%, что меньше толщины линии на обычного размера графиках, в сравнении с 1-5% на наивной 'rrd-подобной' базой данных.
К сожалению, этот алгоритм обладает небольшими недостатками — у него неверно отображаются первая и последние точки — «вёдра» там ещё наполнены не до конца, так что на графике в самом начале и в самом конце конвеера наблюдается очевидный спад. И если для «начала» графика это не особо важно, то неверное отображение последней минуты — это проблема. Увы, это цена за успешное решение остальных проблем.
Клиенты, которые часто подключают-отключают диски, могут обнаружить, что при каждом переподключении диска вся статистика по операциям ввода/вывода теряется. На самом деле она не теряется, просто связь между виртуальной машиной и диском каждый раз новая — а значит, и новые конвейеры в БД.
Статистика может быть немного дырявой — в отличие от клиентских машин и данных учёта, статистику мы не считаем особо приоритетным сервисом (у нас даже нет кластера под неё) — и если сервер статистики перезагружается (или роняется добрыми программистами), то на графике могут появляется отдельные лакуны. Извините, но как есть, так есть.
По этой же причине у нас могут быть некоторые непонятности в статистике за прошлый месяц — мы отлаживали некоторые моменты «по живому».
Начав листать статистику в определённом разрешении (например, с часовыми отсчётами) вы довольно быстро наткнётесь на её окончание. Подобно RRD, мы храним данные для графиков в высоком разрешении только за некоторое время — дальше данные доступны только в более огрублённом виде (то есть, например, вместо часовых отсчётов — суточные).
Внешний вид мы ещё будем дорабатывать, в т.ч. по мотивам комментариев тут.
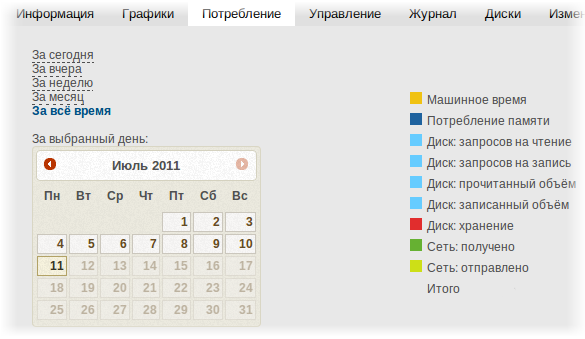
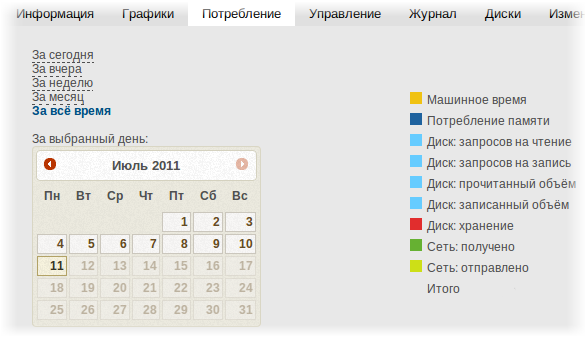
И ещё одно небольшое изменение, которое явно не стоит отдельного поста: теперь можно посмотреть потребление за каждый день, а не только фиксированные выборки (сегодня/вчера/неделя/месяц/всё время). Это явно не то, что мы хотим делать, но это прикрутить календарик было легко. Эта вкладка всё ещё в состоянии stub, то есть мы ещё будем её существенно переделывать.
История создания
Статистика, точнее, её первая версия, была сделана ещё в районе ноября месяца (до момента публичного анонса запуска облака). Это была очень наивная версия, которая честно считала статистику для каждой машины, писала её в БД.Несколько скриншотов этой статистики даже появлялось у нас в блоге.
Мы уже почти были готовы опубликовать её для клиентов, как, вдруг, обнаружился прискорбный факт: при буквально нескольких сотнях машин 8-ядерного Xeon'а не достаточно для того, чтобы посчитать её всю.
Причина была в наивной математике. Источники статистики для каждой виртуальной машины:
- процессор
- память
- дисковые операции: 2 шт. (чтение/запись)
- объём прочитанных/записанных данных: 2шт.
- место на диске
- сеть: 2 шт.
На третьей сотне машин нам пришлось выключить нашу «наивную» статистику и задуматься о том, как это делать правильно…
Итогом стала, немного не мало — собственная специализированная база данных и довольно хитрый алгоритм накопления статистики. По нашим подсчётам получившаяся конструкция сможет обслуживать несколько десятков тысяч машин. Ради этой БД нам даже пришлось отказаться от python — языка, который используется для разработки большей части нашей системы — и обратиться к Erlang. Сам я его не очень люблю, но вынужден признать, что поставленную задачу он решает много успешнее питона (для которого полноценная многозадачность и десятки тысяч транзакций в секунду — это явный перебор). Второй важной особенностью была хорошая поддержка «недотредов» (аналог гринлетов, фиберов с конкурентной многозадачностью) с изоляцией ошибок, готовым супервизором и ITC (inter thread communication).
Немного о RRD
Разумеется, при словах «статистика» и «графики», на языке крутится слово «round robin database», одна из самых популярных систем для хранения статистических данных на барабанах. Эта статья не про RRD, так что скажу основной принцип: данные хранятся в файлах фиксированного размера, новые данные вытесняют старые. Вытесняемые данные из одного барабана переносятся в другой барабан в режиме суммирования. Барабаны имеют разную размерность, например, «час с секундными отсчётами», «сутки с минутными отсчётами», «месяц с часовыми отсчётами», «год с суточными отсчётами» и т.д.Почему же мы не выбрали RRD? Ответ прост и печален: RRD не поддерживает bulk insertion — вы не можете за одну операцию сохранить несколько значений. Это означает, что вам придётся делать тысячи раздельных транзакций, каждая из которых больно бъёт по диску.
Дрожание
Ещё одной проблемой, с которой мы столкнулись, стала проблема дрожания графиков. Стоит задержаться хоть чуть-чуть при записи значения — как на графике появляется лёгкий провал — а в следующую итерацию — лёгкий вплеск. Почти незаметное на непостоянных нагрузках, это дрожание довольно глупо смотрелось на графике потребления памяти и размере диска.Решение проблем
Наше решение — особый метод сбора статистики, запись в «вёдра», двигающиеся по конвейеру. Вёдра двигаются независимо от того, есть в них запись или нет. Когда происходит запись, его содержимое разделяется между двумя вёдрами пропорционально моменту записи. Если у нас есть ведро 1:01 и 1:02, а запись произошла в 1:01.33, то две трети значения будет записано в первое ведро, а треть — во второе.Конвейеры двигаются с разной скоростью (читай, имеют разное разрешение), и имеют определённую длину — собственно, интервал, за который доступна статистика с заданным разрешением. При записи одного значения оно распределяется по всем конвейерам сразу же (как медленным, так и быстрым), плюс, за раз можно записывать значения для множества разных конвейеров для разных схем.
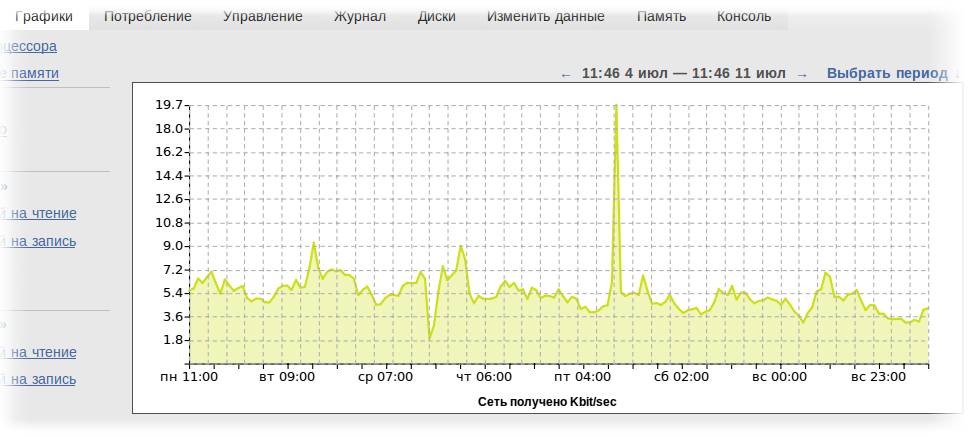
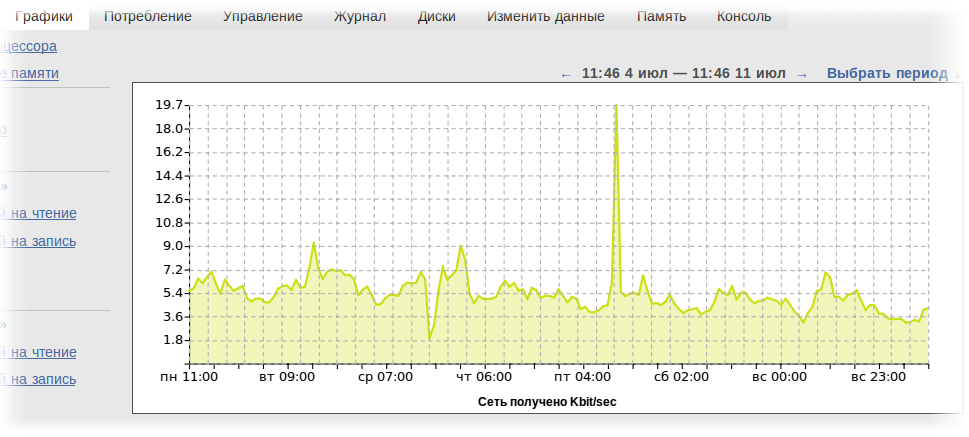
Про скорость этого решения я уже писал, но помимо скорости такой подход решил ещё одну задачу — у нас нет дрожания (на самом деле, оно есть, из-за неточности определения момента записи в ведро и ошибками округления до целых, но оно составляет от 0.1 до 0.5%, что меньше толщины линии на обычного размера графиках, в сравнении с 1-5% на наивной 'rrd-подобной' базой данных.
К сожалению, этот алгоритм обладает небольшими недостатками — у него неверно отображаются первая и последние точки — «вёдра» там ещё наполнены не до конца, так что на графике в самом начале и в самом конце конвеера наблюдается очевидный спад. И если для «начала» графика это не особо важно, то неверное отображение последней минуты — это проблема. Увы, это цена за успешное решение остальных проблем.
Хранение
Фактическим бэкэндом у нас сейчас (временно) выступает Redis благодаря поддержке нужных нам типов данных и скорости. Впрочем, этой скорости нам всё-таки не хватает, так что по мере развития облака мы заменим его на собственное хранилище, целиком и полностью заточенное под наши потребности. В настоящий момент на обработку одного тика по конвейерам уходит больше одной транзакции и нам это не нравится.Отображение
Следуя нашей традиции, мы постарались всё сделать средствами HTML/JS — графики рисуются прямо JS'ом в SVG, без предварительного рендеринга в PNG со стороны сервера. Для этого мы используем библиотеку gRaphaël (http://g.raphaeljs.com/).Известные проблемы
Клиенты, которые часто подключают-отключают диски, могут обнаружить, что при каждом переподключении диска вся статистика по операциям ввода/вывода теряется. На самом деле она не теряется, просто связь между виртуальной машиной и диском каждый раз новая — а значит, и новые конвейеры в БД.
Статистика может быть немного дырявой — в отличие от клиентских машин и данных учёта, статистику мы не считаем особо приоритетным сервисом (у нас даже нет кластера под неё) — и если сервер статистики перезагружается (или роняется добрыми программистами), то на графике могут появляется отдельные лакуны. Извините, но как есть, так есть.
По этой же причине у нас могут быть некоторые непонятности в статистике за прошлый месяц — мы отлаживали некоторые моменты «по живому».
Начав листать статистику в определённом разрешении (например, с часовыми отсчётами) вы довольно быстро наткнётесь на её окончание. Подобно RRD, мы храним данные для графиков в высоком разрешении только за некоторое время — дальше данные доступны только в более огрублённом виде (то есть, например, вместо часовых отсчётов — суточные).
Внешний вид мы ещё будем дорабатывать, в т.ч. по мотивам комментариев тут.
Показ потребления
И ещё одно небольшое изменение, которое явно не стоит отдельного поста: теперь можно посмотреть потребление за каждый день, а не только фиксированные выборки (сегодня/вчера/неделя/месяц/всё время). Это явно не то, что мы хотим делать, но это прикрутить календарик было легко. Эта вкладка всё ещё в состоянии stub, то есть мы ещё будем её существенно переделывать.