Управляемые данными алгоритмы, такие как нейронные сети, взяли мир штурмом. Их развитие вызвано несколькими причинами, в том числе дешевым и мощным оборудованием и огромным объемом данных. Нейронные сети в настоящее время находятся в авангарде во всем, что касается «когнитивных» задач, таких как распознавание изображений, понимание естественного языка и т.д. Но они не должны ограничиваться такими задачами. В этом материале рассказывается о способе сжатия изображений с помощью нейронных сетей, при помощи остаточного обучения. Представленный в статье подход работает быстрее и лучше стандартных кодеков. Схемы, уравнения и, конечно, таблица с тестами под катом.
Эта статья основана на этой работе. Предполагается, что вы знакомы с нейронными сетями и их понятиями свертка и функция потерь.
Что такое сжатие изображений и какое оно бывает?
Сжатие изображений — это процесс преобразования изображения таким образом, чтобы оно занимало меньше места. Простое хранение изображений заняло бы много места, поэтому существуют кодеки, такие как JPEG и PNG, которые нацелены на уменьшение размера исходного изображения.
Как известно, существует два типа сжатия изображений: без потерь и с потерями. Как следует из названий, при сжатии без потерь можно получить данные исходного изображения, а при сжатии с потерями некоторые данные теряются во время сжатия. например, JPG — это алгоритмы с потерями [прим. перев. — в основном, не будем также забывать о JPEG без потерь], а PNG — алгоритм без потерь.

Сравнение сжатия без потерь и с потерями
Обратите внимание, что на изображении справа много блочных артефактов. Это потерянная информация. Соседние пиксели похожих цветов сжимаются как одна область для экономии места, но при этом теряется информация о фактических пикселях. Конечно, алгоритмы, применяемые в кодеках JPEG, PNG и т.д., намного сложнее, но это хороший интуитивный пример сжатия с потерями. Сжатие без потерь — это хорошо, но сжатые без потерь файлы занимают много места на диске. Есть более эффективные способы сжатия изображений без потери большого количества информации, но они довольно медленные, и многие применяют итеративные подходы. Это означает, что их нельзя запускать параллельно на нескольких ядрах центрального или графического процессора. Такое ограничение делает их совершенно непрактичными в повседневном использовании.
Ввод сверточной нейронной сети
Если что-то нужно вычислить и вычисления могут быть приближёнными, добавьте нейронную сеть. Авторы использовали довольно стандартную сверточную нейронную сеть для улучшения сжатия изображений. Представленный метод не только работает наравне с лучшими решениями (если не лучше), он также может использовать параллельные вычисления, что приводит к резкому увеличению скорости. Причина в том, что сверточные нейронные сети (CNN) очень хороши в извлечении пространственной информации из изображений, которые затем представляются в форме компактнее (например, сохраняются только «важные» биты изображения). Авторы хотели использовать эту возможность CNN, чтобы лучше представлять изображения.
Архитектура
Авторы предложили двойную сеть. Первая сеть принимает на вход изображение и генерирует компактное представление (ComCNN). Выходные данные этой сети затем обрабатываются стандартным кодеком (например, JPEG). После обработки кодеком изображение передается во вторую сеть, которая «исправляет» изображение из кодека в попытке вернуть исходное изображение. Авторы назвали эту сеть реконструирующей CNN (RecCNN). Подобно GAN обе сети обучаются итеративно.

ComCNN Компактное представление передается стандартному кодеку
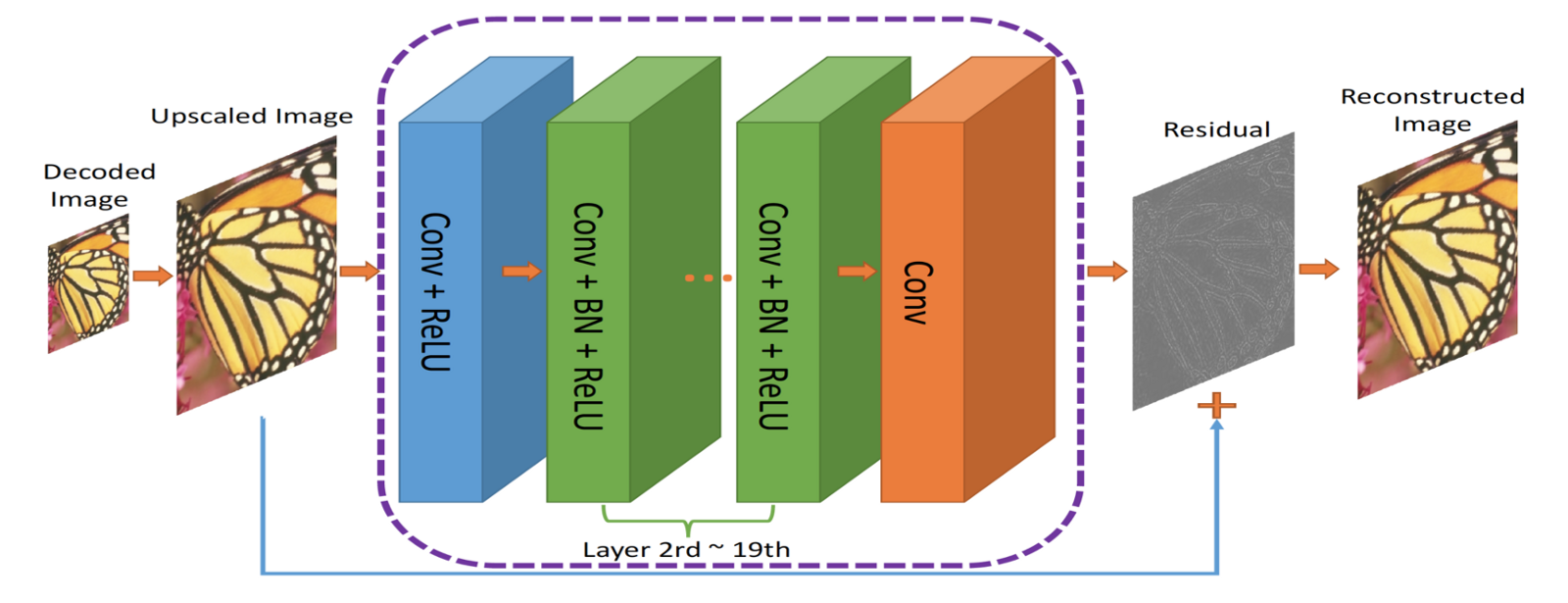
RecCNN. Выходные данные ComCNN масштабируются с увеличением и передаются в RecCNN, которая попытается изучить остаток
Выходные данные кодека масштабируются с увеличением, а затем передаются в RecCNN. RecCNN будет пытаться вывести изображение, похожее на оригинал настолько, насколько это возможно.
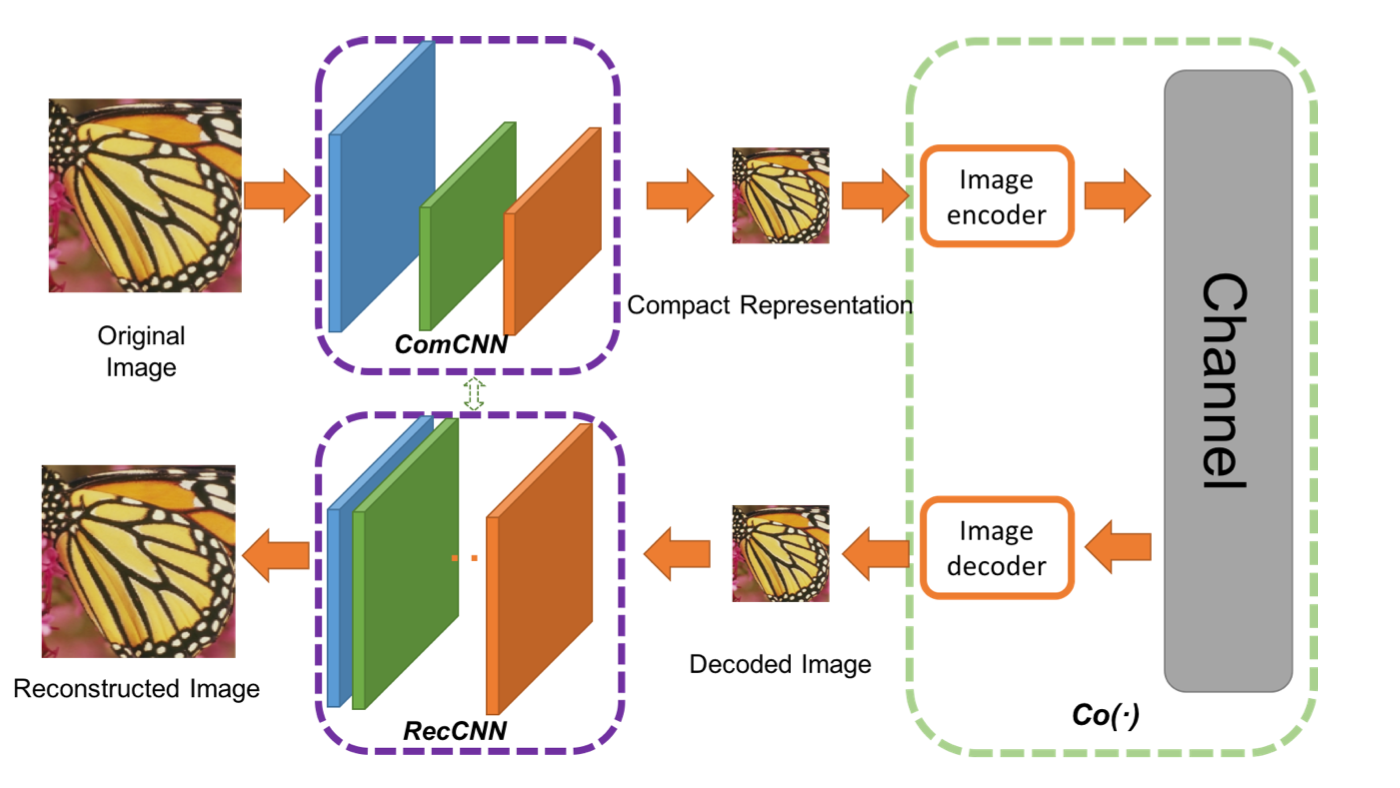
Сквозной фреймворк сжатия изображений. Co(.) представляет собой алгоритм сжатия изображений. Авторы применяли JPEG, JPEG2000 и BPG
Что такое остаток?
Остаток можно рассматривать как шаг постобработки для «улучшения» декодируемого кодеком изображения. Обладающая большим количеством «информации» о мире нейронная сеть может принимать когнитивные решения о том, что исправлять. Эта идея основана на остаточном обучении, прочитать подробности о котором вы можете здесь.
Функции потерь
Две функции потерь используются потому, что у нас две нейронные сети. Первая из них, ComCNN, помечена как L1 и определяется так:
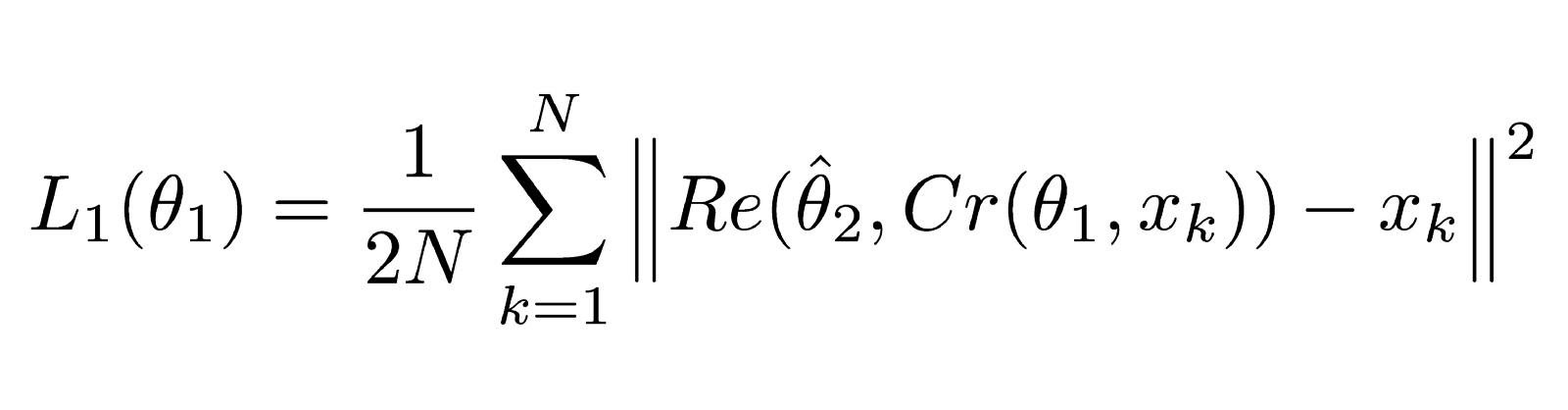
Функция потерь для ComCNN
Объяснение
Это уравнение может показаться сложным, но на самом деле это стандартная (среднеквадратичная ошибка) MSE. ||² означает норму вектора, который они заключают.
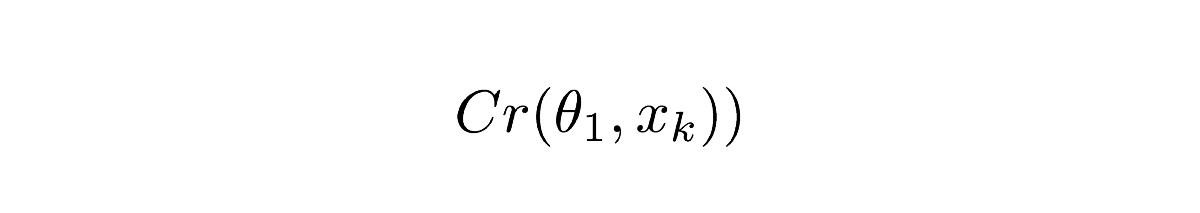
Уравнение 1.1
Cr обозначает выходные данные ComCNN. θ обозначает обучаемость параметров ComCNN, XK — это входное изображение

Уравнение 1.2
Re() означает RecCNN. Это уравнение просто передает значение уравнения 1.1 В RecCNN. θ обозначает обучаемые параметры RecCNN (шляпка сверху означает, что параметры фиксированы).Интуитивное определение
Уравнение 1.0 заставит ComCNN изменить свои веса таким образом, чтобы после воссоздания с помощью RecCNN окончательное изображение выглядело как можно более похожим на входное изображение. Вторая функция потерь RecCNN определяется так:
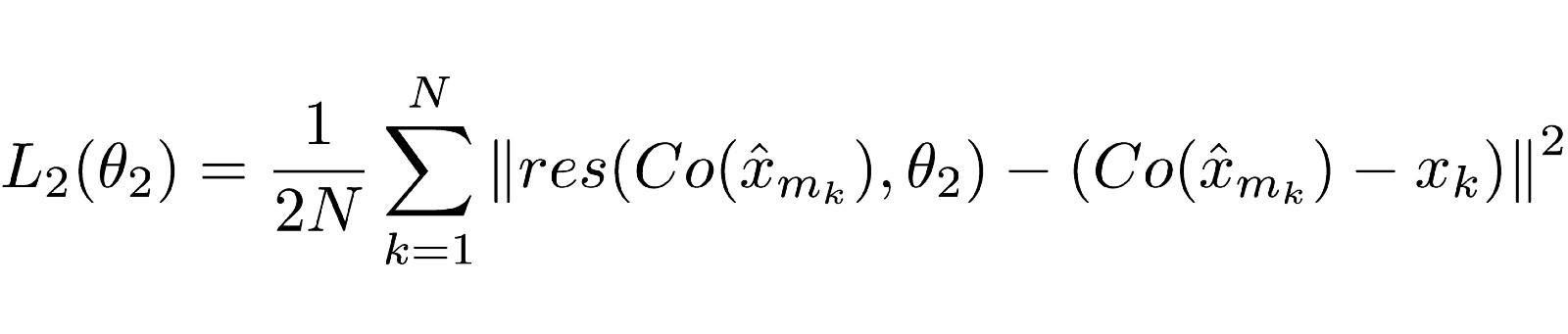
Уравнение 2.0
Объяснение
Снова функция может выглядеть сложной, но это по большей части стандартная функция потерь нейронной сети (MSE).
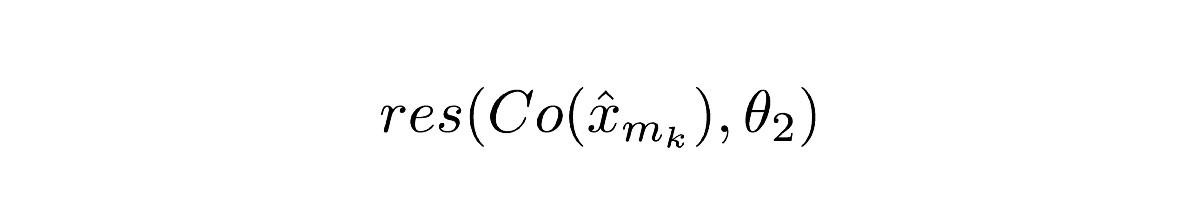
Уравнение 2.1
Co() означает вывод кодека, x со шляпкой сверху означает вывод ComCNN. θ2 — это обучаемые параметры RecCNN, res() представляет собой просто остаточный вывод RecCNN. Стоит отметить, что RecCNN обучается на разнице между Co() и входным изображением, но не на входном изображении.Интуитивное определение
Уравнение 2.0 заставит RecCNN изменить свои веса так, чтобы выходные данные выглядели как можно более похожими на входное изображение.
Схема обучения
Модели обучаются итеративно, подобно GAN. Веса первой модели фиксируются, пока веса второй модели обновляются, затем веса второй модели фиксируются, пока первая модель обучается.
Тесты
Авторы сравнили свой метод с существующими методами, включая простые кодеки. Их метод работает лучше других, сохраняя при этом высокую скорость на соответствующем оборудовании. Кроме того, авторы попытались использовать только одну из двух сетей и отметили падение производительности.

Сравнение индекса структурного сходства (SSIM). Высокие значения указывают на лучшее сходство с оригиналом. Жирным шрифтом выделен результат работы авторов
Заключение
Мы рассмотрели новый способ применения глубокого обучения для сжатия изображений, поговорили о возможности использования нейронных сетей в задачах помимо «общих», таких как классификация изображений и языковая обработка. Этот метод не только не уступает современным требованиям, но и позволяет обрабатывать изображения гораздо быстрее.
Изучать нейронные сети стало проще, ведь специально для хабравчан мы сделали промокод HABR, дающий дополнительную скидку 10% к скидке указанной на баннере.

- Обучение профессии Data Science с нуля
- Онлайн-буткемп по Data Science
- Обучение профессии Data Analyst с нуля
- Онлайн-буткемп по Data Analytics
- Курс «Python для веб-разработки»
Eще курсы
- Курс по аналитике данных
- Курс по DevOps
- Профессия Веб-разработчик
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
- Профессия Java-разработчик с нуля
- Курс по JavaScript
- Курс по Machine Learning
- Курс «Математика и Machine Learning для Data Science»
- Продвинутый курс «Machine Learning Pro + Deep Learning»
