
Определение TTL для некоторых кэшированных данных («time to live» — время существования или длительность хранения) может стать своего рода шарлатанской нумерологией для программистов. При кэшировании по значениям TTL корректность жертвуется ради достижения скорости. Но до какой степени можно отказаться от корректности? Как долго можно показывать где-то неправильное значение, прежде чем пользователь будет сбит с толку? Как скоро такие пользователи заподозрят наличие у себя проблемы и лягут бременем на службы поддержки клиентов? Давайте разбираться.
Кэширование имеет значение, потому что оно обеспечивает большую скорость. Программа с наивным кодом, но которая хорошо использует кэш, обычно работает быстрее программы с умным кодом, которая этого не делает. Использование кеша часто меняет неявный класс сложности системы — вниз и в сторону постоянного времени.
Но будет справедливо сказать, что кэширование — это не круто. Существует снобизм в отношении кэша уровня приложений. Респектабельнее переписать программу на «языке системного программирования» (читайте: быстрая, скомпилированная программа для серьёзных целей), чем широко применять Memcache к PHP-приложению (читай: временное решение, apache2, используется только шутниками).
Это досадно, особенно потому, что часто переписывание не начинается (или никогда не заканчивается), а приложение PHP остается в рабочем состоянии, устойчиво и неподвижно, с упущенной простотой оптимизации.
Далее я подробно расскажу о стратегиях кэширования без отказа от корректности в целях достижения скорости. Во всех таких стратегиях вместо значений TTL используется активное аннулирование.
Стратегия 1: Просто никогда не аннулируйте
Самая простая стратегия - никогда не аннулировать. Некоторые данные не теряют актуальности. Содержимое CSV-файла upload #42345 не изменится. Как и HTML-преобразование некоторых данных продукта в формате markdown. Одна из причин, по которой люди не рассматривают эту стратегию, заключается в том, что они ошибочно опасаются, что кэш "заполнится". Краткосрочный кэш так не работает.
Вам не нужно управлять содержимым краткосрочного кэша с помощью TTL. Краткосрочный кэш будет управлять собственным содержимым с помощью вытеснения.
Кэши приложений, будь то Memcache или соответствующим образом настроенный Redis (см. ниже), работают по алгоритму LRU (least recently used). Редко используемые («холодные») данные вытесняются по мере необходимости, чтобы освободить место для более часто используемых («горячих») данных. Благодаря этому кэш в целом остаётся максимально «горячим» с учётом доступного пространства. Цель состоит в том, чтобы всегда иметь «полный» кеш.
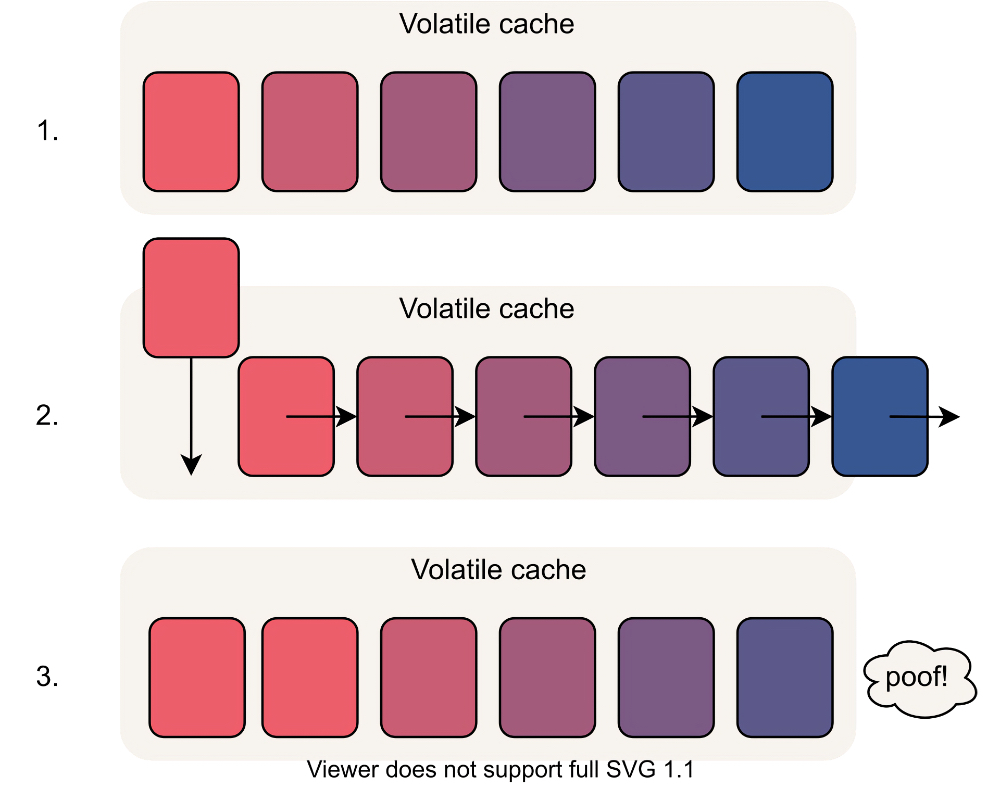
При поступлении новых данных старые (более «холодные») данные перемещаются вниз по иерархии. Если кэш заполнен (как это и должно быть), самые «холодные» данные грубо вытесняются. Я добавил клубы дыма для акцента.
В результате получается кэш, битком набитый данными, которые, скорее всего, понадобятся вашему приложению.
Не путайте вытеснение (часть алгоритма удаления наиболее давно использованных элементов) с истечением срока действия (часть TTL). Данные могут быть вытеснены до истечения срока их действия. И так будет часто: в большинстве случаев в кэше не учитываются значения TTL при поиске данных, которые следует вытеснить.
Стратегия 2: Обновление при записи
Иногда требуется кэшировать данные, которые будут изменяться. Например, возьмём объект пользователя вашего приложения: имя пользователя, адрес электронной почты, почтовый адрес и т. д. Эти данные неизбежно изменяются с течением времени, но к ним также обращаются часто, в каждом запросе или в каждой операции.
Лучший подход здесь — обновлять кеш всякий раз, когда вы обновляете данные в своём постоянном хранилище. Таким образом, кеш остается в актуальном состоянии, не требуя каких-либо нечетких значений TTL и всех связанных предположений о том, как долго что-то будет оставаться в силе.
В соответствии с этой стратегией чтение преимущественно осуществляется из кэша, и только запись должна идти в постоянное хранилище или базу данных. Вытеснение данных из кэша – не проблема: когда в кэше нет нужных данных, вы возвращаетесь к чтению из базы данных (требование для каждой стратегии из этой статьи).
Небольшой бонус в том, что многие базы данных могут записывать данные быстрее, когда модули записи не борются с модулями чтения за блокировки.
Стратегия 3: Аннулирование при записи
Иногда изменение данных может повлиять на несколько объектов в кэше. Например: объект User может содержаться в кэше как в переменной user_id, так и в переменной email_address. При каждом изменении пользователя все данные уже будет в памяти, так что вы можете легко обновить оба кэшированных значения. Вы можете красиво инкапсулировать это в одном месте своей базы кода, где редактируются пользователи. Счастливые дни.
Проблема возникает, когда нет всех данных, необходимых для этих обновлений. Например, если пользователь лайкает какую-то статью, то кэш его списка наиболее понравившихся авторов статей необходимо обновить, но при обработке одного лишь лайка в памяти нет всех необходимых данных. Можно каждый раз извлекать все эти данные, чтобы пересчитать этот список в кэше, или просто аннулировать список в кэше и восстановить его, когда он понадобится в следующий раз.
Это может варьироваться от сценария к сценарию, но обычно аннулирование ведет к превышению скорости извлечения дополнительных данных в программу только для того, чтобы наполнить кэш. В следующий раз значение восстановится без замедления и, как знать, может быть, вам повезёт: возможно, пользователь не увидит его, прежде чем оно снова изменится.
Эта стратегия обычно применяется к связанным данным, но очень часто — к агрегированным данным. Аннулирование при записи может применяться довольно широко, но имеет большое ограничение: необходимо знать ключи кэша, чтобы их можно было аннулировать. Это не всегда возможно.
Стратегия 4: Использование пространства имен
Когда нет конечного, узнаваемого списка ключей, которые исходя из изменения требуется аннулировать с эффектом домино, лучшим решением является кэширование «пространства имен».
Пространства имён работают следующим образом: у вас есть специальное значение из пространства имён, которое следует включить как часть ключа в другие кэшированные данные. Часто, но не всегда значение из пространства имён представляет собой монотонно возрастающую метку времени последнего изменения.
Рабочий пример:
В /namespaces/user657 сохраняется монотонно возрастающая метка времени момента, когда пользователь № 657 в последний раз изменил свой профиль, например, 1514937600.
Затем эта метка времени вносится в ключи, относящиеся к этому пользователю, например:
/user657/1514937600/likes/article-12312/user657/1514937600/comments/article-12315/user657/1514937600/something-else-completely
Теперь для каждого логического поиска в кэше требуются два реальных поиска: сначала ключа пространства имён, а затем фактического ключа. Когда пользователи что-то меняют, вы обновляете содержимое соответствующих ключей пространства имён, и все ключи, подчинённые старому ключу пространства имён, теперь недоступны и поэтому фактически недействительны. Достаточно остывшие данные вытесняются.
Очевидный недостаток: для каждого доступа к кэшу с пространством имён теперь требуются две двусторонние передачи сигналов вместо одной. Часто это того стоит. Во-первых, потому что с пространствами имён можно гораздо шире использовать кэширование, чем без них. Вы кэшируете данные, которые иначе не могли бы использовать. Вторая причина заключается в том, что две двусторонние передачи данных из кэша обычно всё ещё намного быстрее регенерируют или извлекают всё, что есть. Попадание в кэш, как мы надеемся, происходит намного более чем в два раза чаще промаха кэша.
Будьте осторожны: есть много способов наивно «улучшить» эту стратегию способами, которые не работают. Я не буду вдаваться в подробности сомнительно «улучшенных» версий, лишь укажу два варианта, которые необходимы для правильной работы такой схемы:
1. Ключ пространства имён должен быть не менее горячим, чем самый горячий вложенный в него ключ, в противном случае он может постоянно вытесняться перед этими ключами. Остерегайтесь «оптимизаций», которые избегают необходимости извлекать ключ. Это приведёт к тому, что кэш LRU будет считать его холодным.
2. Фактически при аннулированиях такого рода предполагается, что нет других способов доступа к устаревшим подключам. Остерегайтесь попыток заменить иерархическое пространство имён подходами на основе тегов, которые позволяют продолжать извлекать такие устаревшие подключи после намеренного аннулирования.
Стратегия 5: HTTP — PUSH и PURGE
HTTP имеет встроенную систему кэширования, но эта система основана только на значениях TTL. Однако в самом широком смысле стратегия 1 продолжает работать: просто установите абсурдно большое значение TTL, и браузеры и CDN будут следовать ей в той мере, в какой им это нужно.
Стратегия 4 также хорошо работает в HTTP, за исключением того, что в этом контексте она обычно называется «перебором кэша». Общее использование заключается в том, чтобы поместить строки версий или метки времени выпусков в URL-пути или строки-запросы, чтобы браузер загружал только последний пакет JavaScript.
Иногда CDN предоставляют явные API очистки, хотя это в основном удобно тем, кто развёртывает изменения в статических файлах. Традиционные операции очистки CDN обычно занимают несколько минут, поэтому, вероятно, не стоит полагаться на них на уровне приложений, хотя что-то вроде сервиса fly.io, где вы выполняете часть своего кода в CDN, может работать лучше.
При кэшировании инвертированных прокси-серверов, которые вы размещаете самостоятельно, например Varnish и Apache Traffic Server, могут использоваться нестандартные команды PUSH и PURGE, которые позволяют явно контролировать содержимое кэша. Если возможно явное аннулирование, можно использовать стратегии 2 и 3. Если под рукой есть нужный файл, почему бы также не заполнить кэш инвертированного прокси-сервера?
В целом хорошее свойство кэширования на уровне HTTP заключается в том, что оно снимает нагрузку с сервера приложений.
Советы и подводные камни
Кэширование — не такое уж солнечное и приветливое. Вот некоторые проблемы, которых следует избегать, и некоторые советы, которые следует учитывать.
Не помещайте в кэш некэшируемые данные
Одна из проблем, которая встречается на практике, заключается в том, что иногда программисты становятся жертвой архитектур Baser Software и начинают использовать кэш в качестве базы данных и помещать туда реальные данные.
Некоторые люди совершают этот грех, так как получить новое хранилище данных, одобренное Центральным галактическим техническим консультативным советом организации, — это бюрократический кошмар. Тем временем кэш-сервер сидит там и выглядит как потрясающая хэш-таблица, в которую можно просто втиснуть что-то. Следовательно, это отличное место, чтобы хранить некоторые статические данные, не спрашивая ни у кого разрешения. «Наверняка такие данные всегда будут достаточно "горячими", чтобы не вытесняться», — подумает кто-то. Но, в конце концов, специальные данные остынут, и будет великий плач и скрежет зубов, когда Memcache выбросит чьи-то данные в космос. «Глупый кэш! Как ты смеешь!»
В других случаях причиной становятся заманчивые дополнительные функции кэша. Redis обладает огромным количеством встроенных функций, выходящих далеко за рамки кэширования: он может служить шиной сообщений, средством поиска сервисов, рабочей очередью и даже своего рода нереляционной базой данных. Тем не менее ограничения памяти и политики вытеснения Redis устанавливаются глобально для всего экземпляра, а значения по умолчанию не подходят для кэширования — они предназначены для долговременного использования Redis.
Настройка максимально доступной памяти Redis по умолчанию (maxmemory) не ограничена. Это означает, что экземпляр всегда расширяется — даже за пределами физической памяти — без какого-либо вытеснения. Для кэширования задайте максимальный предел памяти, который строго меньше объёма физической памяти. Политика выселения по умолчанию (maxmemory-policy) заключается не в вытеснении, а в вызове ошибок в случае заполнения памяти. Опять же, если требуется вытеснение, это не хорошо для кэширования. В этом случае задайте значение allkeys-lru.
Большинство управляемых сервисов, таких как ElastiCache компании AWS, имеет другое значение по умолчанию для политики вытеснения: volatile-lru. При этой настройке для вытеснения рассматриваются только ключи, для которых задано значение TTL. Это «умный» подход, который позволяет дополнительно использовать экземпляр кэша для некэшируемых данных путём перегрузки флага TTL. По сути, volatile-lru — это мина-ловушка, у которой есть множество неожиданных видов отказов. Во-первых, она побуждает программистов размещать некэшируемые данные на сервере, который сисадмины считают изменчивым и временным. Во-вторых, программисты, которые не знают об этой специальной настройке, склонны заполнять экземпляр по ошибке, многократно вставляя данные в кэше без TTL.
Redis можно настроить как сервер «структур данных» или непосредственно как кэш. Но нельзя сделать и то, и другое. Решив использовать Redis в качестве кэша, убедитесь, что экземпляр кэша служит только в качестве кэша. Ваша межсистемная шина сообщений должна быть в другом экземпляре Redis с другой конфигурацией.
Никогда не требовать попадания в кэш
Важно никогда не требовать попадания в кэш, даже в качестве мягкого требования. Вытеснение может происходить в неудобное время, например, когда какая-то другая часть системы находится под нагрузкой, и не должно быть никаких негативных последствий промаха кэша.
Одна из особенно сомнительных вещей — хранить веб-сессии только в кэше. Тогда промах кэша невольно инициирует выход из системы незадачливого пользователя, который не сделал ничего плохого и ничего не нарушил. Вместо этого используйте стратегию 2, описанную выше, и храните веб-сессии в своей базе данных, используя кэш лишь для ускорения.
Чтобы избавиться от подобных проблем, стоит попробовать запустить автоматизированные тесты со специальными кэшами: тесты с частотой попадания 0 % или со случайной частотой попадания. Промах кэша ничего не должен нарушать, поэтому любые провальные тесты заслуживают изучения.
API в стиле декоратора
В стране Python люди любят декораторы. Например:
from functools import lru_cache
@lru_cache(maxsize=1000)
def get_slow_thing_v1(thing_id):
thing = get_slow_thing_from_a_database_layer(thing_id)
return thingВ приведённом выше коде нет ничего плохого, но он допускает только стратегию 1: никогда не аннулировать. Если есть необходимость в аннулировании/обновлении, код следует усложнить:
from pyappcache import RedisCache
my_cache = RedisCache()
def get_slow_thing_v2(thing_id):
thing = my_cache.get_by_str(thing_id)
if thing is None:
thing = get_slow_thing_from_a_database_layer()
my_cache.set_by_str(thing_id, thing)
return thing
def update_something_slow(thing_id, new_thing):
set_thing_in_a_database_layer(new_thing)
my_cache.set_by_str(thing_id, new_thing)Вторая версия более многословна, но зато позволяет обновлять кэш при настройке чего-либо.
Другое преимущество заключается в том, что значение из кэша можно получать в других местах по ключу — оно больше не привязано к get_something_slow_v1. Это не важно в тривиальных случаях, но приобретает значение в более крупных системах. Если вы можете кэшировать по аргументам, почему бы и нет, но лучше не зацикливаться на кешировании исключительно на основе аргументов функций, поскольку это может быть немного ограничивающим.
Упоминание о собственной библиотеке
Если вы работаете с Python и хотите кэшировать данные, подумайте об использовании моей библиотеки: pyappcache (код здесь, документация здесь).
В ней много потрясающих функций, в том числе:
поддержка кэширования произвольных объектов Python;
использование подсказок типа PEP484, чтобы помочь typecheck cache возвращать значения;
поддержка Memcache, Redis и Sqlite-as-a-cache;
поддержка уже упомянутых трюков, включая пространства имён;
поддержка кэширования ответов внутри библиотеки популярных запросов.
Есть и другие хорошие библиотеки для Python, в том числе dogpile.cache, cachew и, конечно, вы можете использовать Redis-py или pylibmc напрямую.
Иногда оно того стоит
Ничто из этого не означает, что кэш всегда стоит использовать. Это дополнительная работа по программированию, дополнительный сервис резервного копирования, который вам нужно запустить, и, конечно, больше драгоценного пространства для скрытия ошибок. «Эффект Расёмона» в смысле ошибок кэша делает их особенно неприятными как с точки зрения опыта, так и для отладки.
Тем не менее существует огромное количество систем, которые могли бы уменьшиться на пару размеров экземпляров AWS при обнаружении следов применения Memcache. Думайте об окружении, если это вас мотивирует.
Один совет: лучше всего начать с поиска вариантов аннулирования. Перефразируя кого-то: «спрашивайте не о том, что можно кэшировать, а о том, что можно аннулировать». Если невозможно что-то надёжно аннулировать, то маловероятно, что удастся кэшировать это в первую очередь. Прежде чем пытаться что-то кэшировать, убедитесь, что это можно аннулировать везде, где необходимо.
Смотрите также
Мне нравится вот это объяснение, почему идея хранить сеансы в своем кэше — не очень хорошая.
Apache (née Inktomi) Traffic Server поддерживает PUSH и PURGE.
Я думаю, что Varnish поддерживает оба варианта, но вы должны их настроить.
На двух страницах, которые мне нравятся, описывается (слегка устаревшая, общая картина) конструкция Memcache: Memcache для чайников, автор Тиноу (Tinou), и Внутренние компоненты Memcache, автор Джошуа Тийссен (Joshua Thijssen). Документация memcache хороша и, хоть она и явно не закончена, включает некоторые трюки, о которых я не упоминал.
Документы системы Redis по её использованию в качестве кэша LRU необходимо прочитать, прежде чем пытаться использовать её таким образом. Как у большинства вещей у Redis, есть острые края. Важно знать, что при использовании кэширования значения по умолчанию вызывают проблемы.

Узнайте, как прокачаться в других специальностях или освоить их с нуля:
Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ
