Один из самых гибких и привычных способов сгенерировать pdf — написать код на LaTeX и воспользоваться соответствующей программой. Но есть и другие способы, которые могут оказаться проще и понятнее, чем LaTeX. Специально к старту курса Fullstack-разработчик на Python представляем перевод статьи о том, как для генерации PDF можно воспользоваться библиотекой pText; эта статья написана Йорисом Схеллекенсом — разработчиком pText.
В этом руководстве мы будем использовать pText — библиотеку Python, предназначенную для чтения, обработки и создания PDF-документов. Он предлагает как низкоуровневую (позволяющую получить доступ к точным координатам и макету, если вы решите их использовать), так и высокоуровневую модель (где вы можете делегировать точные расчёты полей, позиций и т. д.). Мы рассмотрим, как создавать и проверять PDF-документ в Python, используя pText, а также как использовать некоторые LayoutElement [элементы макета] для добавления штрих-кодов и таблиц.
Portable Document Format (PDF) не является форматом WYSIWYG («что видишь, то и получаешь»). Он был разработан как платформенно-независимый, не зависящий от базовой операционной системы и механизмов рендеринга.
Чтобы добиться этого, PDF был создан взаимодействовать с помощью чего-то, больше похожего на язык программирования, и полагается на серию инструкций и операций для достижения результата. Фактически PDF основан на языке сценариев — PostScript, который был первым независимым от устройства языком описания страниц. В нём есть операторы, которые изменяют графические состояния, на высоком уровне они выглядят примерно так:
Установить шрифт Helvetica.
Установить чёрный цвет обводки.
Перейти к (60,700).
Нарисовать глиф "H".
Это объясняет несколько вещей:
Почему так сложно точно извлечь текст из PDF.
Почему сложно редактировать PDF-документ.
Почему большинство библиотек PDF применяют очень низкоуровневый подход к созданию контента (вы должны указать координаты, в которых следует отображать текст, поля и т. д.).
Установка pText
pText можно загрузить c GitHub или установить через pip:
$ pip install ptext-joris-schellekensПримечание. На момент написания статьи в версии 1.8.6 по умолчанию не устанавливаются внешние зависимости, такие как python-barcode и qrcode. Если появится сообщение об ошибке, установите их вручную:
$ pip install qrcode python-barcode requestsСоздание PDF-документа на Python с помощью pText
pText имеет два интуитивно понятных ключевых класса — Document и Page, которые представляют документ и страницы в нём. Это основная структура для создания PDF-документов. Кроме того, класс PDF представляет собой API для загрузки и сохранения создаваемых нами документов. Имея это в виду, давайте создадим пустой файл PDF:
from ptext.pdf.document import Document
from ptext.pdf.page.page import Page
from ptext.pdf.pdf import PDF
# Create an empty Document
document = Document()
# Create an empty page
page = Page()
# Add the Page to the Document
document.append_page(page)
# Write the Document to a file
with open("output.pdf", "wb") as pdf_file_handle:
PDF.dumps(pdf_file_handle, document)Большая часть кода здесь говорит сама за себя. Мы начинаем с создания пустого документа, затем добавляем пустую страницу в документ с помощью функции append() и, наконец, сохраняем файл с помощью PDF.dumps().
Стоит отметить, что мы использовали флаг "wb" для записи в двоичном режиме, поскольку мы не хотим, чтобы Python кодировал этот текст. Это даёт нам пустой PDF-файл с названием output.pdf в вашей файловой системе:
Создание документа «Hello World» с помощью pText
Конечно, пустые PDF-документы не содержат много информации. Давайте добавим контент на страницу, прежде чем добавлять его в экземпляр документа.
Подобно двум классам, описанным ранее, чтобы добавить контент на страницу, мы добавим PageLayout, указывающий на тип макета, который мы хотели бы видеть, и добавим один или несколько абзацев в этот макет.
С этой целью Document является экземпляром самого низкого уровня в иерархии объектов, а Paragraph — экземпляром самого высокого уровня, размещённым поверх PageLayout и, следовательно, страницы. Давайте добавим абзац на нашу страницу:
from ptext.pdf.document import Document
from ptext.pdf.page.page import Page
from ptext.pdf.pdf import PDF
from ptext.pdf.canvas.layout.paragraph import Paragraph
from ptext.pdf.canvas.layout.page_layout import SingleColumnLayout
from ptext.io.read.types import Decimal
document = Document()
page = Page()
# Setting a layout manager on the Page
layout = SingleColumnLayout(page)
# Adding a Paragraph to the Page
layout.add(Paragraph("Hello World", font_size=Decimal(20), font="Helvetica"))
document.append_page(page)
with open("output.pdf", "wb") as pdf_file_handle:
PDF.dumps(pdf_file_handle, document)Вы заметите, что мы добавили 2 дополнительных объекта:
Экземпляр PageLayout, более конкретный через его подкласс SingleColumnLayout: этот класс отслеживает, где контент добавляется на страницу, какие области доступны для будущего контента, каковы поля страницы и какие ведущие (пространство между объектами Paragraph) должно быть.
Поскольку здесь мы работаем только с одним столбцом, мы используем SingleColumnLayout. В качестве альтернативы мы можем использовать MultiColumnLayout.
Экземпляр Paragraph: этот класс представляет блок текста. Вы можете установить такие свойства, как шрифт, font_size, font_color, и многие другие. Дополнительные примеры вы можете найти в документации.
Код генерирует файл output.pdf, содержащий наш абзац:
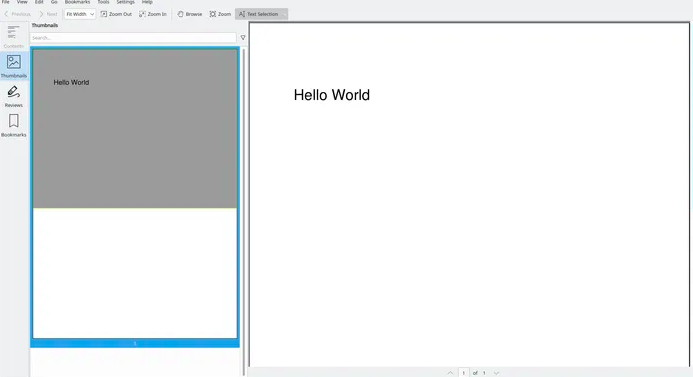
Проверка созданного PDF с помощью pText.
Примечание: этот раздел является необязательным, если вас не интересует внутренняя работа PDF-документа.
Но может быть очень полезно немного узнать о формате (например, при отладке классической проблемы «почему мой контент теперь отображается на этой странице»). Обычно программа для чтения PDF читает документ, начиная с последних байтов:
xref
0 11
0000000000 00000 f
0000000015 00000 n
0000002169 00000 n
0000000048 00000 n
0000000105 00000 n
0000000258 00000 n
0000000413 00000 n
0000000445 00000 n
0000000475 00000 n
0000000653 00000 n
0000001938 00000 n
trailer
<</Root 1 0 R /Info 2 0 R /Size 11 /ID [<61e6d144af4b84e0e0aa52deab87cfe9><61e6d144af4b84e0e0aa52deab87cfe9>]>>
startxref
2274
%%EOFЗдесь мы видим маркер конца файла (%% EOF) и таблицу перекрестных ссылок (обычно сокращённо xref).
Внешняя ссылка ограничена токенами «startxref» и «xref».
Внешняя ссылка (в документе может быть несколько) действует как справочная таблица для программы чтения PDF-файлов.
Он содержит байтовое смещение (начиная с верхней части файла) каждого объекта в PDF. Первая строка внешней ссылки (0 11) говорит, что в этой внешней ссылке 11 объектов и что первый объект начинается с номера 0.
Каждая последующая строка состоит из байтового смещения, за которым следует так называемый номер поколения и буква f или n:
Объекты, отмеченные буквой f, являются свободными, их рендеринг не ожидается.
Объекты, отмеченные буквой n, «используются».
Внизу xref мы находим словарь трейлеров. Словари в синтаксисе PDF разделяются символами << и >>. В этом словаре есть следующие пары:
/Root 1 0 R
/Info 2 0 R
/Size 11
/ID [<61e6d144af4b84e0e0aa52deab87cfe9> <61e6d144af4b84e0e0aa52deab87cfe9>]
Словарь трейлеров является отправной точкой для программы чтения PDF-файлов и содержит ссылки на все другие данные. В этом случае:
/Root: это ещё один словарь, который ссылается на фактическое содержание документа.
/Info: это словарь, содержащий метаинформацию документа (автор, название и так далее).
Строки типа 1 0 R в синтаксисе PDF называются «ссылками». И здесь нам пригодится таблица xref. Чтобы найти объект, связанный с 1 0 R, мы смотрим на объект 1 (номер поколения 0). Таблица поиска xref сообщает нам, что мы можем ожидать найти этот объект в 15-м байте документа. Если проверить это, то обнаружим:
1 0 obj
<</Pages 3 0 R>>
endobjОбратите внимание, что тот объект начинается с 1 0 obj и заканчивается endobj. Это ещё одно подтверждение того, что мы на самом деле имеем дело с объектом 1. Этот словарь говорит нам, что мы можем найти страницы документа в объекте 3:
3 0 obj
<</Count 1 /Kids [4 0 R]
/Type /Pages>>
endobjЭто словарь /Pages, и он сообщает нам, что в этом документе одна страница (запись /Count). Запись для /Kids обычно представляет собой массив с одной ссылкой-объектом на страницу. Мы можем ожидать найти первую страницу в объекте 4:
4 0 obj
<</Type /Page /MediaBox [0 0 595 842]
/Contents 5 0 R /Resources 6 0 R /Parent 3 0 R>>
endobjЭтот словарь содержит несколько интересных записей:
/MediaBox: физические размеры страницы (в данном случае страница формата A4).
/Contents: ссылка на (обычно сжатый) поток операторов содержимого PDF.
/Resources: ссылка на словарь, содержащий все ресурсы (шрифты, изображения и так далее), используемые для рендеринга этой страницы.
Давайте проверим объект 5, чтобы узнать, что на самом деле отображается на этой странице:
5 0 obj
<</Filter /FlateDecode /Length 85>>
stream
xÚãR@
\È<§`a¥£šÔw3T0É
€!K¡š3Benl7'§999ù
åùE9)
!Y(!8õÂyšT*î
endstream
endobjКак упоминалось ранее, этот поток содержимого сжимается. Вы можете определить, какой метод сжатия использовался, с помощью записи /Filter. Если мы применим распаковку (unzip) к объекту 5, то мы должны получить фактические операторы содержимого:
5 0 obj
<</Filter /FlateDecode /Length 85>>
stream
q
BT
0.000000 0.000000 0.000000 rg
/F1 1.000000 Tf
20.000000 0 0 20.000000 60.000000 738.000000 Tm
(Hello world) Tj
ET
Q
endstream
endobjНаконец, мы находимся на уровне, где можем декодировать контент. Каждая строка состоит из аргументов, за которыми следует их оператор. Быстро пройдёмся по операторам:
q: сохранить текущее графическое состояние (помещая его в стек);
BT: начать текст;
0 0 0 rg: установить текущий цвет обводки на (0,0,0) rgb. Это чёрный;
/F1 1 Tf: установить текущий шрифт на /F1 (это запись в словаре ресурсов, упомянутом ранее) и размер шрифта на 1.
20.000000 0 0 20.000000 60.000000 738.000000 Tm: установить текстовую матрицу, что требует отдельного руководства. Достаточно сказать, что эта матрица регулирует размер шрифта и положение текста. Здесь мы масштабируем шрифт до размера 20 и устанавливаем курсор для рисования текста на 60 738. Система координат PDF начинается в нижнем левом углу страницы. Итак, 60 738 находится где-то рядом с левым верхом страницы (с учётом того, что высота страницы составляет 842 единицы).
(Hello world) Tj: строки в синтаксисе PDF разделяются ( и ). Эта команда указывает программе чтения PDF-файлов отобразить строку «Hello world» в позиции, которую мы указали ранее с помощью текстовой матрицы, в шрифте, размере и цвете, которые мы указали в командах перед этим.
ET: конец текста.
Q: извлечь состояние графики из стека (таким образом восстанавливая состояние графики).
Добавление других элементов макета pText на страницы
pText поставляется с широким спектром объектов LayoutElement. В предыдущем примере мы кратко исследовали Paragraph. Но есть и другие элементы, такие как UnorderedList, OrderedList, Image, Shape, Barcode и Table. Давайте создадим чуть более сложный пример с таблицей и штрих-кодом. Таблицы состоят из TableCells, которые мы добавляем в экземпляр Table. Штрих-код может быть одним из многих типов штрих-кода — мы будем использовать QR-код:
from ptext.pdf.document import Document
from ptext.pdf.page.page import Page
from ptext.pdf.pdf import PDF
from ptext.pdf.canvas.layout.paragraph import Paragraph
from ptext.pdf.canvas.layout.page_layout import SingleColumnLayout
from ptext.io.read.types import Decimal
from ptext.pdf.canvas.layout.table import Table, TableCell
from ptext.pdf.canvas.layout.barcode import Barcode, BarcodeType
from ptext.pdf.canvas.color.color import X11Color
document = Document()
page = Page()
# Layout
layout = SingleColumnLayout(page)
# Create and add heading
layout.add(Paragraph("DefaultCorp Invoice", font="Helvetica", font_size=Decimal(20)))
# Create and add barcode
layout.add(Barcode(data="0123456789", type=BarcodeType.QR, width=Decimal(64), height=Decimal(64)))
# Create and add table
table = Table(number_of_rows=5, number_of_columns=4)
# Header row
table.add(TableCell(Paragraph("Item", font_color=X11Color("White")), background_color=X11Color("SlateGray")))
table.add(TableCell(Paragraph("Unit Price", font_color=X11Color("White")), background_color=X11Color("SlateGray")))
table.add(TableCell(Paragraph("Amount", font_color=X11Color("White")), background_color=X11Color("SlateGray")))
table.add(TableCell(Paragraph("Price", font_color=X11Color("White")), background_color=X11Color("SlateGray")))
# Data rows
for n in [("Lorem", 4.99, 1), ("Ipsum", 9.99, 2), ("Dolor", 1.99, 3), ("Sit", 1.99, 1)]:
table.add(Paragraph(n[0]))
table.add(Paragraph(str(n[1])))
table.add(Paragraph(str(n[2])))
table.add(Paragraph(str(n[1] * n[2])))
# Set padding
table.set_padding_on_all_cells(Decimal(5), Decimal(5), Decimal(5), Decimal(5))
layout.add(table)
# Append page
document.append_page(page)
# Persist PDF to file
with open("output4.pdf", "wb") as pdf_file_handle:
PDF.dumps(pdf_file_handle, document)Некоторые детали реализации:
pText поддерживает различные цветовые модели, в том числе RGBColor, HexColor, X11Color и HSVColor.
Вы можете добавлять объекты LayoutElement непосредственно в объект Table, но вы также можете обернуть их объектом TableCell, это даёт вам некоторые дополнительные параметры, такие как col_span и row_span или, в данном случае, background_color.
Если font, font_size или font_color не указаны, Paragraph примет значение по умолчанию Helvetica, размер 12, чёрный.
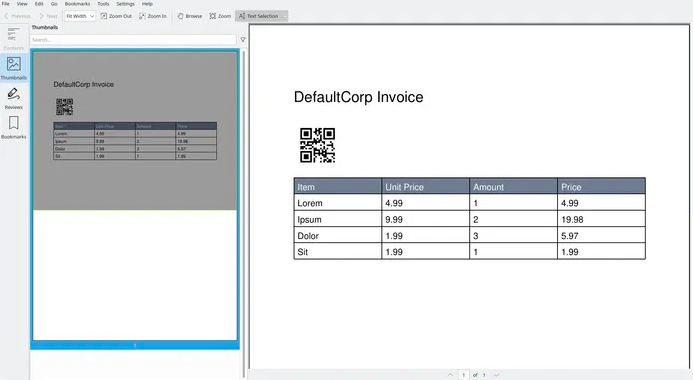
Код сгенерирует такой документ:
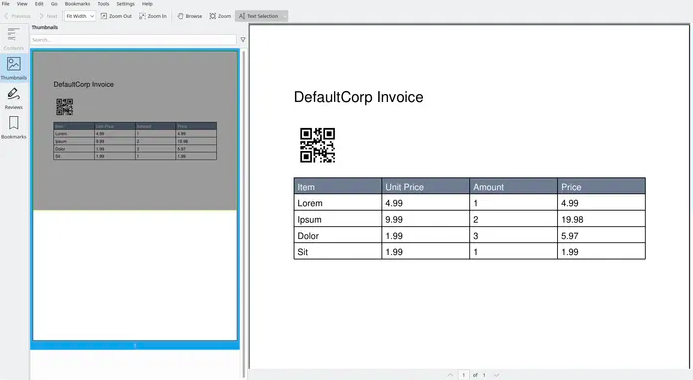
Заключение
В этом руководстве мы рассмотрели pText — библиотеку для чтения, записи и управления файлами PDF. Мы рассмотрели ключевые классы, такие как Document и Page, а также некоторые элементы, такие как Paragraph, Barcode и PageLayout. Наконец, мы создали несколько PDF-файлов с различным содержимым, а также проверили, как PDF-файлы хранят данные под капотом.
Документ PDF приятен глазу и достаточно удобен для того, чтобы использовать его в электронном документообороте, для генерации разнообразных счетов и отчётов, особенно актуальных в крупных организациях и в их внутренней сети, поэтому разработка крупных и сложных веб-проектов часто сопряжена с генерацией PDF. Если вам интересна работа со сложными веб-проектами и не хочется выбирать между бэком или фронтом, то вы можете присмотреться к курсу Fullstack-разработчик на Python.

Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ
