
В стремлении прояснить языковые модели Transformer с помощью пакета Ecco авторы показывают механизм генерации предложений внутри предварительно обученной языковой модели. После генерации предложения возможно визуализировать представление о том, как модель пришла к каждому слову — речь идёт о столбце на рисунке выше. Строки — это слои модели. Чем темнее элемент строки, тем выше ранг токена в слое. Слой 0 расположен на самом верху. Слой 47 — в самом низу. К старту курса о машинном и глубоком обучении показываем и рассказываем о том, как мыслит GPT.
Здесь сосредоточимся на скрытом состоянии и его эволюции от одного слоя модели к другому. Рассматривая создаваемые каждым блоком декодера трансформера скрытые состояния мы стремимся узнать, как модель пришла к конкретному слову и его выводу.
Применяемый нами метод исследован Войта и др.[1] Ностальджбрейст[2] представляет убедительные визуализации эволюции рангов токенов, оценок logit и вероятностей softmax эволюционирующего скрытого состояния через различные слои модели.
Реконструируем слои
Ниже показано, как работает языковая модель трансформера, как слои приводят к последнему скрытому состоянию, а затем оно проецируется на выходной словарь, в результате оценивается каждый токен словаря. Ниже мы видим токены с самыми высокими оценками, когда DistilGPT2 подаётся входная последовательность "1, 1":

На этом рисунке показано, как модель приходит к пяти лучшим кандидатам на выходной токен и к оценкам их вероятности. На последнем слое модель на 59 % уверена, что следующим токеном окажется '1', именно его модель выберет в качестве выходного при жадном декодировании. Другие вероятные выходные данные — '2' с вероятностью 18 % (возможно) и '0' с вероятностью 5% (возможно, мы ведём обратный отсчёт). Ecco даёт представление о токенах модели с высоким рангом и об оценке их вероятности.
# Generate one token to complete this input string
output = lm.generate(" 1, 1, 1,", generate=1)
# Visualize
output.layer_predictions(position=6, layer=5)Что покажет следующее распределение токенов-кандидатов на вывод и их оценки вероятности:

Оценки после каждого слоя
Применяя ту же проекцию к внутренним скрытым состояниям модели, получим представление о том, как убеждённость модели в оценке на выходе развивалась при обработке входных данных. Эта проекция внутренних скрытых состояний даёт нам представление о том, какой слой внёс наибольший вклад в оценку, а значит и в ранг конкретного потенциального выходного токена.

Мы смотрим не на выходные токены-кандидаты, которые получили при проецировании конечного состояния модели, а на токены с наибольшей оценкой после проецирования скрытого состояния, при этом состояние — результат работы каждого слоя; в этом сущность просмотра эволюции скрытых состояний. Визуализации выше создавались одним методом, но у второй на пятом слое нет аргумента 'layer':
# Visualize the top scoring tokens after each layer
output.layer_predictions(position=6)Результат:

В каждой строке показаны десять лучших предсказанных токенов, полученных через проецирование каждого скрытого состояния на выходной словарь. Оценки вероятности обозначены розовым цветом. Мы получили их, пропустив logit через softmax.
Видно, что Слой 0 не имеет цифр в первой десятке предсказаний.
Слой 1 даёт токену '1' вероятность 0,03%, что хотя и мало, но ставит его на седьмое место по рангу.
Последующие слои повышают вероятность и ранг '1', пока последний слой не снижает вероятность со 100 % до ~60 %, сохраняя самый высокий ранг токена в выводе модели.
Рисунок выше из-за округления неверно показывает нулевую вероятность токенов. В новом Ecco проблема исправлена: показывается '<0.01%'.
Поэкспериментировать с этими визуализациями на своих входных предложениях можно по этой ссылке на Google Colab.
Эволюция выбранного токена

Слой 0 в сгенерированном им скрытом состоянии поднял токен '1' на 31 место.
Слои 1 и 2 подняли ранг до 7 и 5 соответственно.
Все следующие слои были уверены, что это лучший токен, и отдали ему первое место.
Другой взгляд на эволюцию скрытых состояний — повторное изучение скрытых состояний после выбора выходного токена, чтобы увидеть, как скрытое состояние после каждого слоя ранжировало этот токен. Такой взгляд — один из многих, которые исследовались Ностальджбрейстом [2], его мы считаем отличным подходом для первой попытки. На рисунке сбоку мы видим ранг токена '1' в пределах 500,000+ токенов модели, а каждая строка означает вывод слоя. Также возможно визуализировать всю входную последовательность. Столбец обозначает шаг генерации и его выходной токен, каждая строка — ранжирование выходного токена на каждом слое:

Слой 3 — точка, где модель обрела уверенность в том, что на выходе будет цифра '1'.
Когда на выходе должна быть запятая, слой 0 обычно оценивает запятую как 5.
Когда выходом должна быть '1', слой 0 не так уверен, но всё равно оценивает токен ' 1' на 31 или 32.
Обратите внимание: каждый выходной токен занимает первое место после слоя 5, таково определение жадной выборки. Причина выбора токена заключается в том, что он занял первое место.
Давайте продемонстрируем эту визуализацию, представив GPT2-Large такой ввод:

Визуализация эволюции скрытых состояний показывает, как различные слои способствуют созданию последовательности:

Столбцы розового цвета соответствуют новым строкам и точкам. Начиная со слоя 0 и далее, модель уверена в этих токенах на ранних этапах, это указывает на осведомлённость слоя 0 об определённых синтаксических свойствах (и что последующие слои не вызывают возражений).
Столбцы, в которых предсказываются названия стран, очень яркие в верхней части, и именно последние пять слоёв должны фактически придумать соответствующий токен.
Столбцы, отслеживающие возрастающий номер, как правило, разрешаются на слое 9.
Модель ошибочно включает в список Чили, а не страну ЕС. Но обратите внимание: ранг этого токена равен 43 — это указывает на то, что ошибку лучше отнести к нашему методу выборки токенов, а не к самой модели. В случае всех остальных стран они были правильными и входили в топ-3.
Страны, кроме Чили, верны, они даже следуют алфавитному порядку ввода.


Мы не ограничиваемся наблюдением за эволюцией единственного выбранного на определённую позицию токена. Иногда нужно сравнить ранги нескольких токенов в одной и той же позиции независимо от того, выбрала ли их модель.
Один из таких случаев — задача предсказания числа, которую описали Линзен и др.[3], она возникает из-за согласования подлежащего и сказуемого в английском языке. В этой задаче нужно проанализировать способность модели кодировать множественное и единственное числа слова и то, к какому подлежащему предложения мы обращаемся. Проще говоря, заполните пробел. Приемлемые ответы: 1) is 2) are:
The keys to the cabinet __Чтобы ответить правильно, сначала нужно определить, рассказываем ли мы о ключах или о шкафе. Решив, что это ключи, нужно определить число слова.

Сопоставьте ответ на вопрос с таким вариантом:
The key to the cabinets __Рисунки в этом разделе отображают эволюцию скрытых состояний токенов «is» и «are». Числа в ячейках — это ранжирование в позиции пропуска. Оба столбца относятся к одной и той же позиции последовательности, они не следуют друг за другом, как в предыдущей визуализации.
Посмотрите на рисунок ранжирования последовательности «The keys to the cabinet». Возникает вопрос: почему пять слоев не справляются с задачей, всё на места ставит только последний.
Наверное, такое поведение аналогично эффекту в BERT, последний слой наиболее специфичен для конкретной задачи[4, 5]. Стоит разобраться, локализовано ли умение решать задачу преимущественно в слое 5, или этот слой — только окончательное выражение на схеме[6], которая охватывает несколько слоёв, особенно чувствительных к согласованию подлежащего и сказуемого.
Выявляем заблуждения
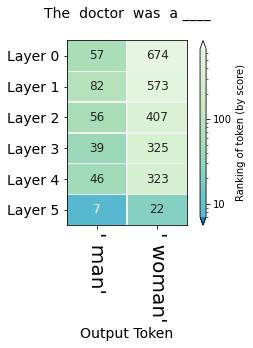
Этот метод может прояснить вопросы о заблуждениях и о том, где она возникает. Цифры ниже отражают профессионально-гендерные ожидания модели:


Первые пять слоёв ранжируют мужчину выше женщины в обеих профессиях. В случае медсестры последний слой решительно ставит выше женщину.
Более системно и подробно заблуждения в контекстуализированных векторных представлениях слов (это ещё один термин для «скрытых состояний») изучается в работах 7, 8, 9, 10 раздела ссылок.
Ваша очередь!
Поэкспериментируйте с Ecco и тремя блокнотами Jupyter из этой статьи:
О проблемах сообщайте на странице Ecco на Github. Свободно делитесь любыми интересными выводами на доске обсуждений Ecco. Я оставляю небольшую галерею примеров с ответами разных моделей на разный ввод.
Галерея
Ввод: «Heathrow airport is located in the city of».

Ввод: «Some of the most glorious historical attractions in Spain date from the period of Muslim rule, including The Mezquita, built as the Great Mosque of Cordoba and the Medina Azahara, also in Cordoba and now in ruins but still visitable as such and built as the Madinat al-Zahra, the Palace of al-Andalus; and the Alhambra in Granada, a splendid, intact palace. There are also two synagogues still standing that were built during the era of Muslim Spain: Santa Maria la Blanca in Toledo and the Synagogue of Cordoba, in the Old City. Reconquista and Imperial era».



Ввод: «The countires of the European Union are:\n1. Austria\n2. Belgium\n3. Bulgaria\n4.»



Ссылки
[1] The bottom-up evolution of representations in the transformer: A study with machine translation and language modeling objectives
Voita, Elena and Sennrich, Rico and Titov, Ivan, 2019. arXiv preprint arXiv:1909.01380.
[2] interpreting GPT: the logit lens
nostalgebraist, 2020.
[3] Assessing the ability of LSTMs to learn syntax-sensitive dependencies
Linzen, Tal and Dupoux, Emmanuel and Goldberg, Yoav, 2016. Transactions of the Association for Computational Linguistics.
[4] Linguistic Knowledge and Transferability of Contextual Representations
Nelson F. Liu and Matt Gardner and Yonatan Belinkov and Matthew E. Peters and Noah A. Smith, 2019.
[5] A Primer in BERTology: What we know about how BERT works
Anna Rogers and Olga Kovaleva and Anna Rumshisky, 2020.
[6] Thread: Circuits
Cammarata, Nick and Carter, Shan and Goh, Gabriel and Olah, Chris and Petrov, Michael and Schubert, Ludwig, 2020. Distill.
[7] Gender bias in contextualized word embeddings
Zhao, Jieyu and Wang, Tianlu and Yatskar, Mark and Cotterell, Ryan and Ordonez, Vicente and Chang, Kai-Wei, 2019. arXiv preprint arXiv:1904.03310.
[8] Measuring bias in contextualized word representations
Kurita, Keita and Vyas, Nidhi and Pareek, Ayush and Black, Alan W and Tsvetkov, Yulia, 2019. arXiv preprint arXiv:1906.07337.
[9] Evaluating the underlying gender bias in contextualized word embeddings
Basta, Christine and Costa-Juss{\`a}, Marta R and Casas, Noe, 2019. arXiv preprint arXiv:1904.08783.
[10] Measuring and Reducing Gendered Correlations in Pre-trained Models
Kellie Webster and Xuezhi Wang and Ian Tenney and Alex Beutel and Emily Pitler and Ellie Pavlick and Jilin Chen and Slav Petrov, 2020.
Визуализации показывают, что внутренняя работа нейронных сетей достаточно сложна, но понять её, а значит и внутренние механизмы нейросетей — задача хотя и непростая, но вполне по силам. Если вы хотите изменить свою карьеру, приходите на наш курс о глубоком и машинном обучении, флагманский курс по Data Science или по анализу данных. Также вы можете узнать, как освоить другие профессии или прокачать свои навыки:

Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также:
