
MPIRE комбинирует функции, подобные map из multiprocessing.Pool, с преимуществами копирования при записи общих объектов multiprocessing.Process. В пакете также есть простые в работе функции состояния рабочего процесса, информирования о нём и индикатора выполнения. Сокращённым переводом документации делимся к старту курса по Fullstack-разработке на Python.
Особенности
Пакет быстрее других многопроцессорных библиотек. См. бенчмарки.
Интуитивный синтаксис.
Функции map/map_unordered/imap/imap_unordered.
Простое применение общих объектов с возможностью копирования при записи вместе с пулом рабочих процессов (копирование при записи доступно только методу запуска fork).
Каждый рабочий процесс может иметь собственное состояние, и с помощью удобных функций инициализации и выхода рабочего процесса этим состоянием можно легко манипулировать (например, загрузить занимающую много памяти модель, только один раз для каждого рабочего процесса, не отправляя её в очередь).
Прогресс-бары на tqdm.
Дашборд.
Анализ рабочих процессов, чтобы узнать эффективность многопроцессорной обработки.
Изящная и удобная обработка исключений.
Автоматическая разбивка задач для всех доступных функций map, чтобы ускорить обработку небольших очередей задач, включая массивы numpy.
Регулировка максимума активных задач, чтобы избегать проблем с памятью.
Автоматический перезапуск рабочих процессов после выполнения определённого количества заданий, чтобы потреблять меньше памяти.
Вложенный пул рабочих процессов возможен при установке опции daemon.
Дочерние процессы возможно привязать к определённому CPU или к нескольким.
Опционально dill работает бэкендом сериализации через multiprocess, позволяя распараллелить экзотические объекты, лямбды и функции в iPython или Jupyter Notebook.
MPIRE тестировался на Linux и Windows. В Windows есть небольшие предостережения.
Установка
Сборки MPIRE распространяются через PyPi. Установить MPIRE можно через pip:
pip install mpireMPIRE работает с Python >= 3.6.
Зависимости
Python 3.7
Пакеты Python (устанавливаются автоматически):
tqdm;
pywin32 (только Windows).
Dill
Для некоторых функций или задач может быть полезно не полагаться на pickle, а использовать более мощный бэкенд сериализации, например dill. dill не устанавливается по умолчанию, так как имеет лицензию BSD, в то время как MPIRE имеет лицензию MIT. Если вы хотите использовать его, лицензия MPIRE также изменится на лицензию BSD, как того требует BSD. Дополнительную информацию см. здесь. Вы можете включить dill, выполнив команду:
pip install mpire[dill]Это позволит установить multiprocess, в котором задействован dill. Вы можете включить использование dill, установив use_dill в True в конструкторе mpire.WorkerPool.
Дашборд
По желанию вы можете установить зависимости дашборда MPIRE, который зависят от Flask. Как и dill, Flask имеет BSD-лицензию. Дополнительную информацию см. в BSD лицензии Flask. Дашборд позволяет просматривать информацию о ходе работ через браузер. Это удобно, когда вы выполняете сценарии в блокноте или на экране или хотите поделиться информацией о ходе выполнения. Установка:
pip install mpire[dashboard]Начинаем
Предположим, трудоёмкая функция получает некоторые входные данные и возвращает результаты:
import time
def time_consuming_function(x):
time.sleep(1) # Simulate that this function takes long to complete
return ...
results = [time_consuming_function(x) for x in range(10)]Выполнение займёт около 10 секунд.
Функции, подобные этим, известны как ужасно параллельные задачи, то есть такие, для превращения которых в параллельную задачу не требуется практически никаких усилий. Не сложнее может оказаться импорт multiprocessing и работа с классом multiprocessing.Pool:
from multiprocessing import Pool
with Pool(processes=5) as pool:
results = pool.map(time_consuming_function, range(10))Мы настроили 5 рабочих процессов, чтобы параллельно выполнять 5 задач. В результате эта функция завершится примерно через 2 секунды. MPIRE может использоваться почти как замена для multiprocessing. Мы используем mpire.WorkerPool класс и вызовем одну из доступных функций map:
from mpire import WorkerPool
with WorkerPool(n_jobs=5) as pool:
results = pool.map(time_consuming_function, range(10))Аналогичным образом процесс завершится примерно через 2 секунды. Различия в коде незначительны: нет необходимости изучать совершенно новый синтаксис мультипроцессинга, если вы привыкли к ванильному мультипроцессингу. Однако MPIRE отличают дополнительные функции.
Шкала прогресса
Предположим, нужно узнать статус текущей задачи: сколько заданий выполнено, сколько времени осталось до готовности работы? Установите progress_bar в True:
with WorkerPool(n_jobs=5) as pool:
results = pool.map(time_consuming_function, range(10), progress_bar=True)И он выведет красиво отформатированный tqdm индикатор выполнения. Если выполнять код в блокноте, он автоматически переключится на виджет.
Общие объекты
Если у вас есть один или несколько объектов, которые вы хотите разделить между всеми рабочими, вы можете воспользоваться опцией copy-on-write shared_objects в MPIRE. MPIRE будет передавать эти объекты только один раз для каждого рабочего процесса без копирования/сериализации. Только когда вы измените объект в рабочей функции, она начнёт копировать его для этого рабочего.
def time_consuming_function(some_object, x):
time.sleep(1) # Simulate that this function takes long to complete
return ...
def main():
some_object = ...
with WorkerPool(n_jobs=5, shared_objects=some_object) as pool:
results = pool.map(time_consuming_function, range(10), progress_bar=True)Более подробную информацию см. в разделе Общие объекты.
Инициализация рабочих процесса
Необходимо инициализировать каждого рабочего процесса перед началом работы? Взгляните на worker_state и worker_init:
def init(worker_state):
# Load a big dataset or model and store it in a worker specific worker_state
worker_state['dataset'] = ...
worker_state['model'] = ...
def task(worker_state, idx):
# Let the model predict a specific instance of the dataset
return worker_state['model'].predict(worker_state['dataset'][idx])
with WorkerPool(n_jobs=5, use_worker_state=True) as pool:
results = pool.map(task, range(10), worker_init=init)Аналогично вы можете использовать параметр worker_exit, чтобы позволить MPIRE вызывать функцию всякий раз, когда рабочий процесс завершает работу. Возможно даже позволить этой функции выхода возвращать результаты, которые можно получить позже. Более подробную информацию см. в разделе Инициализация и выход рабочего процесса.
Информация о рабочих процессах
Если мультипроцессинг работает не так, как вы хотите, и вы не знаете причину, есть функциональность worker insights. Она даёт представление об обстоятельствах, но не профилирует выполняемую функцию. Зато профилирует время запуска, ожидания и работы процесса. Если предоставлены функции init и exit, он будет выполнять их также по времени.
Возможно, вы отправляете много данных через очередь задач. Так или иначе вы получите информацию с помощью флага enable_insights и функции mpire.WorkerPool.get_insights() соответственно:
with WorkerPool(n_jobs=5) as pool:
results = pool.map(time_consuming_function, range(10), enable_insights=True)
insights = pool.get_insights()Более подробный пример и ожидаемый результат см. здесь.
Ссылка на сокращённую часть о функциях отображения (map).
WorkerPool
Класс mpire.WorkerPool управляет пулом подобно multiprocessing.Pool. Он содержит все функции типа map (с добавлением mpire.WorkerPool.map_unordered()), но сейчас в нём нет функции apply и apply_async. Пул mpire.WorkerPool может быть запущен двумя различными способами. Первый и рекомендуемый способ сделать это — использовать контекстный менеджер:
from mpire import WorkerPool
# Start a pool of 4 workers
with WorkerPool(n_jobs=4) as pool:
# Do some processing here
passОператор with позаботится о правильном объединении/прерывании порождённых рабочих процессов, когда блок завершится. Другой способ сделать то же самое — вручную:
# Start a pool of 4 workers
pool = WorkerPool(n_jobs=4)
# Do some processing here
pass
# Only needed when keep_alive=True:
# Clean up pool (this will block until all processing has completed)
pool.stop_and_join()
# In the case you want to kill the processes, even though they are still busy
pool.terminate()При использовании n_jobs=None MPIRE породит столько процессов, сколько процессоров имеется в вашей системе. Конечно, можно указать больше заданий, чем у вас имеется процессоров. Предупреждаем:
При ручном подходе очередь результатов должна быть осушена первой перед присоединением рабочих, иначе возможна блокировка. Если вы хотите присоединиться любым способом, используйте mpire.WorkerPool.terminate(). Предупреждения в документации Python — здесь.
Вложенные WorkerPool
По умолчанию класс mpire.WorkerPool порождает дочерние процессы-демоны, которые не могут сами создавать дочерние процессы, поэтому вложенные пулы не допускаются. Есть возможность создавать дочерние процессы, не являющиеся демонами, чтобы предоставить вложенные структуры:
def job(...)
with WorkerPool(n_jobs=4) as p:
# Do some work
results = p.map(...)
with WorkerPool(n_jobs=4, daemon=True) as pool:
# This will raise an AssertionError telling you daemon processes
# can't start child processes
pool.map(job, ...)
with WorkerPool(n_jobs=4, daemon=False) as pool:
# This will work just fine
pool.map(job, ...)Вложенные пулы не поддерживаются при использовании потоков.
Из-за странной ошибки в Python использование forkserver в качестве метода запуска во вложенном пуле не допускается, если внешний пул использует fork, так как forkserver там не будет запущен. Чтобы это работало, методом запуска внешнего пула должен иметь либо spawn, либо forkserver. Предупреждаем:
Вложенные пулы не готовы к производственному коду. Обработка ошибок и прерывания клавиатуры при использовании вложенных пулов могут, в редких случаях всё ещё могут вызывать блокировки (~1 % времени). Используйте на свой страх и риск. Когда функция гарантированно завершается успешно, использование вложенных пулов абсолютно нормально.
Привязка к CPU
Вы можете закрепить дочерние процессы mpire.WorkerPool к конкретному CPU через cpu_ids в конструкторе:
# Pin the two child processes to CPUs 2 and 3
with WorkerPool(n_jobs=2, cpu_ids=[2, 3]) as pool:
...
# Pin the child processes to CPUs 40-59
with WorkerPool(n_jobs=20, cpu_ids=list(range(40, 60))) as pool:
...
# All child processes have to share a single core:
with WorkerPool(n_jobs=4, cpu_ids=[0]) as pool:
...
# All child processes have to share multiple cores, namely 4-7:
with WorkerPool(n_jobs=4, cpu_ids=[[4, 5, 6, 7]]) as pool:
...
# Each child process can use two distinctive cores:
with WorkerPool(n_jobs=4, cpu_ids=[[0, 1], [2, 3], [4, 5], [6, 7]]) as pool:
...Идентификаторы CPU должны быть целыми положительными числами, не превышающими количество доступных CPU (которое можно получить методом mpire.cpu_count()). Используйте None, чтобы отключить привязку процессора по умолчанию.
Привязка процессов к идентификаторам CPU не работает при использовании потоков.
Получение идентификатора рабочего процесса
Каждому рабочему процессу в MPIRE присваивается целочисленный идентификатор, чтобы различать их. Рабочий процесс #1 будет иметь ID 0, #2 будет иметь ID 1 и т. д. Иногда может быть полезно иметь доступ к этому идентификатору. Например, когда у вас есть общий массив, размер которого равен количеству рабочих, и вы хотите, чтобы процесс #1 имел доступ только к первому элементу, а процесс #2 — только ко второму и т. д.
По умолчанию идентификатор рабочего процесса не передаётся. Вы можете включить и выключить эту функцию, установив флаг pass_worker_id:
def square_sum(worker_id, shared_objects, x):
# Even though the shared objects is a single container, we 'unpack' it anyway
results_container = shared_objects
# Square and sum
results_container[worker_id] += x * x
# Use a shared array of size equal to the number of jobs to store the results
results_container = Array('f', 4, lock=False)
with WorkerPool(n_jobs=4, shared_objects=results_container, pass_worker_id=True) as pool:
# Square the results and store them in the results container
pool.map_unordered(square_sum, range(100))Важно: идентификатор рабочего процесса всегда будет первым аргументом, передаваемым указателю функции.
Вместо передачи флага в конструктор mpire.WorkerPool вы также можете использовать mpire.WorkerPool.pass_on_worker_id():
with WorkerPool(n_jobs=4, shared_objects=results_container) as pool:
pool.pass_on_worker_id()
pool.map_unordered(square_sum, range(100))Общие объекты
MPIRE позволяет вам предоставлять общие объекты рабочим процессам аналогично тому, как это возможно с классом multiprocessing.Process. Методом запуска fork эти общие объекты рассматриваются как копируемые при записи, это означает, что они копируются только после внесения в них изменений. В противном случае они используют один и тот же адрес памяти. Это удобно, если вы хотите предоставить рабочим процессам доступ к большому набору данных, который не поместится в памяти при многократном копировании.
Для потока эти общие объекты доступны для чтения и записи без создания копий. Для методов запуска spawn и forkserver общие объекты копируются только один раз для каждого рабочего процесса, в отличие от копирования для каждой задачи, которое происходит при использовании обычного multiprocessing.Pool.
def task(dataset, x):
# Do something with this copy-on-write dataset
...
def main():
dataset = ... # Load big dataset
with WorkerPool(n_jobs=4, shared_objects=dataset, start_method='fork') as pool:
... = pool.map(task, range(100))Помимо обмена обычными объектами Python между рабочими вы также можете обмениваться примитивами синхронизации, такими как multiprocessing.Lock, используя этот метод. Подобные объекты требуют совместного использования через наследование, именно так в MPIRE передаются общие объекты.
Если копирование при записи вам недоступно, вы также можете использовать общие объекты для совместного использования multiprocessing.Array, multiprocessing.Value или другого объекта с multiprocessing.Manager. Затем вы можете хранить в одном объекте результаты нескольких процессов. Однако вам следует свести количество синхронизации к минимуму, когда ресурсы защищены блокировкой, или отключить блокировку, если ваша ситуация позволяет это сделать, как показано здесь:
from multiprocessing import Array
def square_add_and_modulo_with_index(shared_objects, idx, x):
# Unpack results containers
square_results_container, add_results_container = shared_objects
# Square, add and modulo
square_results_container[idx] = x * x
add_results_container[idx] = x + x
return x % 2
def main():
# Use a shared array of size 100 and type float to store the results
square_results_container = Array('f', 100, lock=False)
add_results_container = Array('f', 100, lock=False)
shared_objects = square_results_container, add_results_container
with WorkerPool(n_jobs=4, shared_objects=shared_objects) as pool:
# Square, add and modulo the results and store them in the results containers
modulo_results = pool.map(square_add_and_modulo_with_index,
enumerate(range(100)), iterable_len=100)Можно предоставить несколько объектов, поместив их, например, в контейнер кортежа, как показано выше.
Важно: общие объекты передаются в качестве второго аргумента после идентификатора рабочего процесса (если он включён) в указатель предоставленной функции.
В приведённом выше примере мы создаём два контейнера результатов по одному для возведения в квадрат и для добавления заданного значенияи отключаем блокировку для обоих. Кроме того, мы также возвращаем значение, несмотря на то, что для хранения результатов мы используем общие объекты. Здесь мы можем безопасно отключить блокировку, так как каждая задача записывает в свой индекс массива, поэтому никаких условий гонки возникнуть не может. Отключить блокировку, конечно, намного быстрее, чем включить её. Вместо того чтобы передавать общие объекты в конструктор mpire.workerpool, можно воспользоваться mpire.workerpool.set_shared_objects():
def square_with_index(shared_objects, idx, x):
results_container = shared_objects
results_container[idx] = x * x
results_container = Array('f', 100, lock=False)
with WorkerPool(n_jobs=4) as pool:
pool.set_shared_objects(results_container)
pool.map_unordered(square_with_index, enumerate(range(100)),
iterable_len=100)Общие объекты должны быть указаны до запуска рабочих процессов. Они запускаются после выполнения первого вызова map. То есть, когда keep_alive=True и рабочие процессы используются повторно, изменение общих объектов между двумя последовательными вызовами map не сработает.
Состояние рабочего процесса
Если вы хотите, чтобы каждый рабочий процесс имел своё собственное состояние, воспользуйтесь флагом use_worker_state. Состояние рабочего процесса может быть объединено с параметрами worker_init и worker_exit каждой функции map, что приводит к некоторым действительно полезным возможностям:
import numpy as np
import pickle
def load_big_model(worker_state):
# Load a model which takes up a lot of memory
with open('./a_really_big_model.p3', 'rb') as f:
worker_state['model'] = pickle.load(f)
def model_predict(worker_state, x):
# Predict
return worker_state['model'].predict(x)
with WorkerPool(n_jobs=4, use_worker_state=True) as pool:
# Let the model predict
data = np.array([[...]])
results = pool.map(model_predict, data, worker_init=load_big_model)Важно: состояние рабочего процесса передаётся в качестве третьего аргумента после идентификатора рабочего процесса и общих объектов (если они включены) в указатель функции.
Более подробную информацию о параметрах worker_init и worker_exit можно найти здесь. Вместо того чтобы передавать флаг в конструктора mpire.WorkerPool, можно воспользоваться mpire.WorkerPool.set_use_worker_state():
with WorkerPool(n_jobs=4) as pool:
pool.set_use_worker_state()
results = pool.map(model_predict, data, worker_init=load_big_model)Метод запуска процесса
Пакет multiprocessing позволяет запускать процессы несколькими методами: 'fork', 'spawn' или 'forkserver'. Генерация потоков также доступна с помощью 'threading'. Подробности смотрите здесь и здесь:
‘fork’ (по умолчанию в Unix-системах) копирует родительский процесс таким образом, что дочерний процесс фактически идентичен. Это включает копирование всего, что в данный момент в памяти. Иногда это полезно, но иногда бесполезно или даже является серьёзным узким местом.
‘spawn’ (по умолчанию в Windows) запускает новый интерпретатор Python, где наследуются только необходимые ресурсы.
‘forkserver’ сначала запускает серверный процесс при помощи spawn. Всякий раз, когда требуется новый процесс, родительский процесс запрашивает у сервера форк нового процесса.
‘threading’ запускает дочерние потоки.
Имейте в виду, что глобальные переменные (например, константы) могут иметь значение, отличное от ожидаемого. Вы также должны импортировать пакеты внутри вызываемой функции:
import os
def failing_job(folder, filename):
return os.path.join(folder, filename)
# This will fail because 'os' is not copied to the child processes
with WorkerPool(n_jobs=2, start_method='spawn') as pool:
pool.map(failing_job, [('folder', '0.p3'), ('folder', '1.p3')])def working_job(folder, filename):
import os
return os.path.join(folder, filename)
# This will work
with WorkerPool(n_jobs=2, start_method='spawn') as pool:
pool.map(working_job, [('folder', '0.p3'), ('folder', '1.p3')])Много усилий было потрачено на то, чтобы индикатор выполнения, дашборд и вложенные пулы (с несколькими индикаторами выполнения) хорошо работали со spawn и forkserver. Так что всё должно работать нормально.
Поддержание жизни рабочих процессов
Рабочие процессы могут поддерживаться между последовательными вызовами map с помощью флага keep_alive. Это полезно, когда они длительно запускаются и вам нужно вызвать одну из функций map несколько раз. Когда выполняется функция или изменяется параметр worker_lifespan, MPIRE игнорирует флаг, так как ему всё равно нужно перезапустить процессы.
Опираясь далее на пример:
import numpy as np
import pickle
def load_big_model():
# Load a model which takes up a lot of memory
with open('./a_really_big_model.p3', 'rb') as f:
return pickle.load(f)
def model_predict(worker_state, x):
# Load model
if 'model' not in worker_state:
worker_state['model'] = load_big_model()
# Predict
return worker_state['model'].predict(x)
with WorkerPool(n_jobs=4, use_worker_state=True, keep_alive=True) as pool:
# Let the model predict
data = np.array([[...]])
results = pool.map(model_predict, data)
# Do something with the results
...
# Let the model predict some more. In this call the workers are reused,
# which means the big model doesn't need to be loaded again
data = np.array([[...]])
results = pool.map(model_predict, data)
# Workers are restarted in this case because the function changed
pool.map(square_sum, range(100))Вместо того чтобы передавать флаг в mpire.WorkerPool, можно использовать mpire.WorkerPool.set_keep_alive():
with WorkerPool(n_jobs=4) as pool:
pool.set_keep_alive()
pool.map_unordered(square_sum, range(100))Dill
Для некоторых функций или задач может быть полезно полагаться не на pickle, а на некоторые более мощные серверные части сериализации, такие как dill. Dill не устанавливается по умолчанию. Дополнительные сведения об установке зависимостей см. в разделе Dill. Чтобы зунать обо всех преимуществах dill, пожалуйста, обратитесь к документации. После установки зависимостей их можно включить с помощью флага use_dill:
with WorkerPool(n_jobs=4, use_dill=True) as pool:
...При использовании dill это может потенциально замедлить обработку. Это — цена надёжной и мощной сериализации бэкенда.
Дашборд
Панель мониторинга позволяет просматривать информацию о ходе выполнения из браузера. Это удобно при запуске сценариев в блокноте или на экране, если вы хотите поделиться информацией о ходе выполнения с другими или если вы хотите получить информацию о рабочем процессе в режиме реального времени. Зависимости дашборда не устанавливаются по умолчанию. Дополнительные сведения см. здесь.
Запуск дашборда
Вот так он запускается программно:
from mpire.dashboard import start_dashboard
# Will return a dictionary with dashboard details
dashboard_details = start_dashboard()
print(dashboard_details)выведет:
{'dashboard_port_nr': 8080,
'manager_host': 'localhost',
'manager_port_nr': 8081}Код запустит панель мониторинга на локальном компьютере на порте 8080. Если порт занят, MPIRE попробует следующий, пока не найдёт свободный. В редких случаях, когда порты недоступны до номера 8099, функция вызовет OSError. По умолчанию MPIRE пытается занять порты 8080–8100. Этот диапазон можно переопределить:
dashboard_details = start_dashboard(range(9000, 9100))Возвращённый словарь содержит номер порта, который выбран в конечном счёте. Он также содержит информацию о том, как удалённо подключиться к этой панели мониторинга. Другой способ запуска панели мониторинга — сценарий bash:
mpire-dashboardЭто запустит панель мониторинга с деталями подключения:
Starting MPIRE dashboard...
MPIRE dashboard started on http://localhost:8080
Server is listening on localhost:8098
--------------------------------------------------Серверная часть соответствует manager_host и manager_port_nr из словаря, возвращаемого mpire.dashboard.start_dashboard(). Возможен пользовательский диапазон портов:
mpire-dashboard --port-range 9000-9100Преимущество запуска дашборда таким образом заключается в том, что он продолжает работать в случае ошибок в скрипте. Вы сможете увидеть, что была за ошибка, когда и где она произошла в вашем коде.
Подключение к существующей панели мониторинга
Если вы запустили дашборд в другом месте, подключиться к ней можно так:
from mpire.dashboard import connect_to_dashboard
connect_to_dashboard(manager_port_nr=8081, manager_host='localhost')Убедитесь, что вы используете manager_port_nr, а не dashboard_port_nr.
Вы можете подключиться к существующей приборной панели на той же, но удалённой машине (если порты открыты). Если manager_host опущен, он вернётся к использованию 'localhost'.
Работа с дашбордом
После подключения к приборной панели вам не нужно ничего менять в своём коде. Когда вы включили использование индикатора выполнения в вызове map, индикатор выполнения автоматически регистрируется на сервере панели инструментов и отображается, как здесь:
from mpire import WorkerPool
from mpire.dashboard import connect_to_dashboard
connect_to_dashboard(8099)
def square(x):
import time
time.sleep(0.01) # To be able to show progress
return x * x
with WorkerPool(4) as pool:
pool.map(square, range(10000), progress_bar=True)Вы увидите что-то вроде этого:
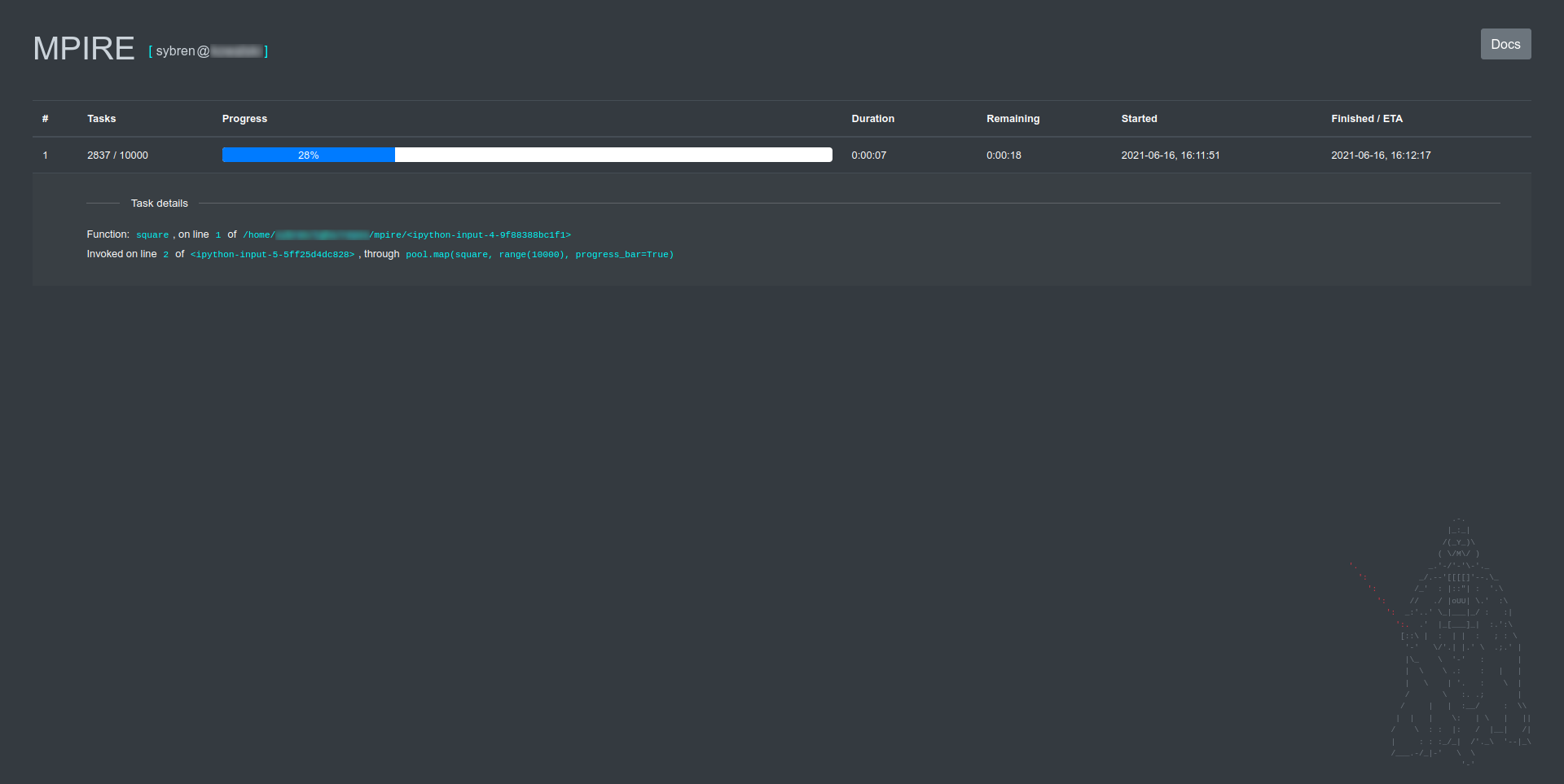
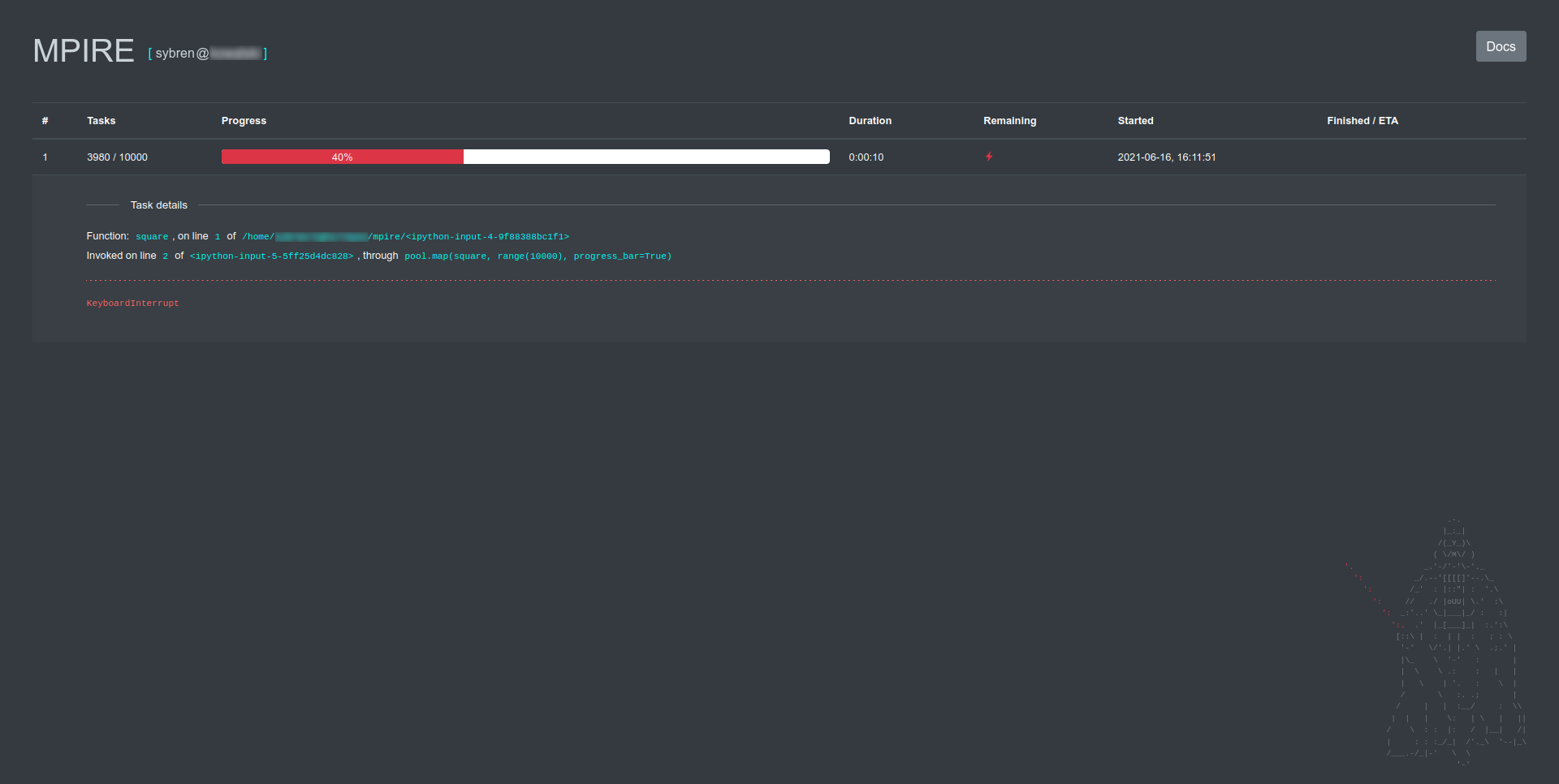
Можно нажать на строку индикатора выполнения, чтобы просмотреть подробную информацию о вызываемой функции (что уже было сделано на скриншоте выше). Индикатор сообщит, когда запущенному процессу был отправлен сигнал KeyboardInterrupt:
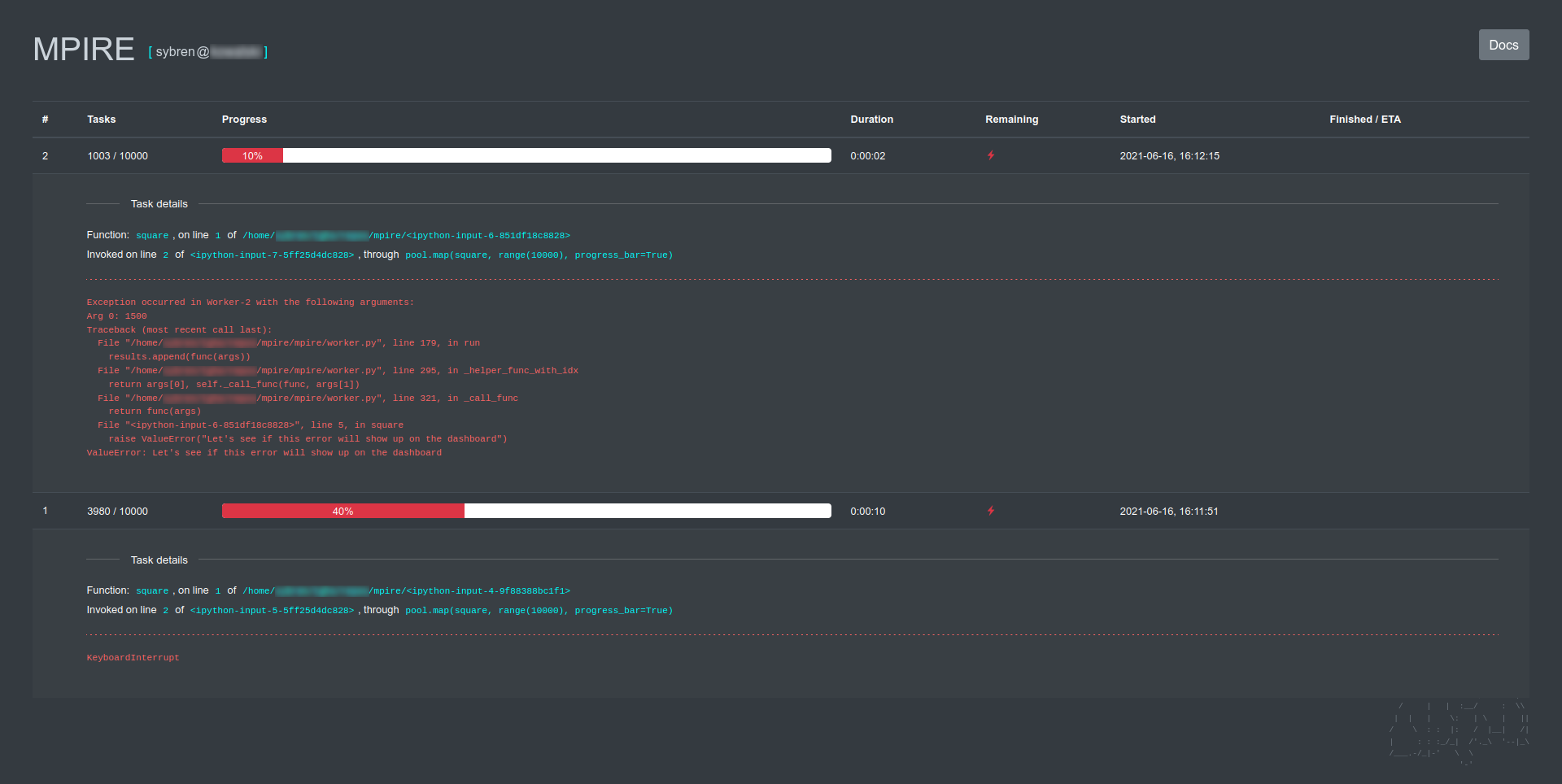
или покажет информацию об обратном пути в случае исключения:
Если вы включили информацию о рабочих процессах, она будет отображаться в реальном времени:

Нажмите на Insights (click or expand/collapse), чтобы развернуть или свернуть детали. Дашборд автоматически обновляется каждые полсекунды.
Код на Github.
На сегодня всё. Попробовать MPIRE вы сможете на нашем курсе по Fullstack-разработке на Python. Также вы можете перейти на страницы других курсов, чтобы узнать, как мы готовим специалистов в других направлениях IT.

Другие профессии и курсы
Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также:
