Шанс, что у взрослого человека, не знающего английский, хватит терпения выучить его, стремится к нулю. Последние 4 года я занят тем, чтобы исправить это.
У нас 12 тысяч учителей английского в Skyeng, и каждый из них имеет своё представление о том, как именно измеряется уровень ученика. Вводить единую методику и контролировать её выполнение на таком количестве человек не представляется целесообразным, но показывать ученику, где он находится и сколько ему потребуется для достижения цели, необходимо. Нужны были объективные метрики, которые можно было бы снимать в автоматическом режиме.
Поэтому я занялся большим почти научным проектом, начавшимся в 2017-м году и длящимся по сей день:
- Собрал по данным методологических исследований карту навыков английского языка, разбитую на сотни отдельных веток, связанных друг с другом, как в хорошей RPG.
- Отскринил несколько реальных учеников по этой карте и придумал, как с её помощью вычислить образовательный прогресс.
- Наложил карту навыков на контент, чтобы каждое упражнение автоматически учитывалось в оценке прогресса (о, это было долго и сложно).
- Провалидировал на тысячах внутренних тестов, не зависящих от системы оценки прогресса.
- Заложил адаптацию для учеников разных языковых групп, поскольку родной язык ученика даёт ему какие-то навыки сразу, а какие-то делает очень сложными.
- Семь раз усложнил, а после существенно упростил систему.
В итоге каждый урок моя система скорит каждому ученику баллы опыта в разные ветки навыков.
Зачем это нужно
Бизнес-задача довольно простая: чем больше ученик у нас учится, тем больше он платит денег за это обучение. В общеобразовательном обучении английскому всё просто: есть программа на N лет учёбы, и ты не уйдёшь, пока не отучишься. В онлайне же крайне важна мотивация к обучению, потому что шансы отвалиться куда выше, чем в школе/институте. Решать задачу можно либо удлиняя обучение как таковое и растягивая получение знаний, либо же увеличивая количество достигаемых с помощью английского целей и закрываемых потребностей. Как это ни странно, но именно ускоренное получение знаний вызывает у ученика понимание ценности занятий, и он учится дольше.
Вторая задача социальная. В современном мире для не англоговорящих стран ВВП на душу населения значимо связан с долей людей, владеющих английским языком. Для владельцев компании повышение уровня жизни людей за счёт достижения образовательных целей является мерилом качества нашей работы.
Чтобы довести человека из точки А в точку Б, нужно знать, где он находится. Зная, где он находился вчера, а где сегодня, можно измерять прогресс. В общем, нам нужна была какая-то методика, которая с одной стороны позволила бы достаточно детализировано определять уровень человека, а с другой — аллоцировать этот уровень на путь к заданной цели. В нашем понимании она включала набор неких атомарных единиц, на которые можно было бы декомпозировать любую цель (мы в 2017 году слабо представляли каких), и систему их оценки, чтобы понимать, как каждое маленькое действие влияет на движение к цели. С подобной системой можно корректировать направление обучения и давать самое важное для понимания и закрепления материала, а главное — собирать программы, которые меняются в зависимости от каждого действия ученика. Да, в теории это делает хороший учитель и сам, но когда количество его учеников превышает критическую отметку, становится сложно всё удержать в голове, и четыре года спустя я могу точно сказать: моя модель очень помогает справляться с этой задачей лучше. Плюс, напомню, нам надо было контролировать качество обучения, и, если на уроке не было ожидаемого прогресса, — смотреть, всё ли в порядке с программой обучения и где основные затыки. Наша задача не менять учителя, наша задача — подсказать учителю, в чём может быть проблема ученика, расшифровать ему, почему ученик топчется на месте или регрессирует, дать наводку на более годный образовательный контент, о наличии которого преподаватель может вообще не знать.
Что мы имели на старте
Есть цели обычных людей, которые они формулируют вот примерно в таких терминах:
- Уютно чувствовать себя в поездке.
- Посмотреть сериал в оригинале с субтитрами.
- Пройти собеседование.
- Переезжаю на ПМЖ в Европу.
Декомпозировать такие цели на достаточно узкий набор can-do statements, прилагающийся к шкале CEFR (Common European Framework of Reference), той самой, привычной всем, где уровень владения языком измеряется от Beginner до Proficient, достаточно сложно. В этой шкале слишком мало дискретных шагов. Да и прогресс в языке нелинейный — нельзя сказать, что вы выучили английский наполовину. Нужен был другой уровень детализации навыков: от таких базовых, как «выучить, какие бывают буквы», до гораздо более сложных и составных вроде «умение извлекать из речи аргументы, ссылающиеся на самих себя».
С чего началось
Первое, что я сделал, — полез смотреть мировые практики по декомпозиции владения языком и нашёл замечательное исследование Pearson English. В нём ребята, проделав титаническую работу, собрали перечень языковых навыков, необходимых для жизни, и проранжировали их по сложности освоения. А заодно разработали более удобную и легко интерпретируемую шкалу GSE (Global Scale of English) с большей дискретностью, чем CEFR.
Всего получилось около 1600 отдельных навыков. Их абстрактные примеры для русского могли бы выглядеть примерно вот так:
- Отличает, когда речь идёт о стоящем на столе предмете, а когда о лежащем.
- Может выделить ключевую информацию из краткого комментария о спортивном матче.
- Может выделить противоположные аргументы в художественном тексте.
- Может написать письмо с акцентом на важном.
- Может обозначать степени уверенности в точке зрения (вероятно, возможно, зуб даю и т.п.).
Чтобы комфортно чувствовать себя в загранпоездке, нужно освоить 250 из этих 1600. Серьёзно, английский язык очень простой, и 90-95% всех коммуникаций можно без труда вести за счёт словарного запаса и двух времён — Present и Past Simple. Будущее время можно уверенно делать из настоящего (Bill Gates starts his new job next week). При этом вы будете говорить технически грамотно, но бедно и неуклюже. В дороге это и не особо важно, главное, что вы сможете объясняться. А вот для ведения переговоров на высшем уровне, очевидно, не помешает английский этикет (связанный с речью), понимание довольно сложных юридических конструкций (связанных с легаси языка), расширенный словарный запас и много чего ещё. Ну вы поняли, для этого уже нужно освоить язык.
В общем, находка с навыками и шкалой была мне на руку, потому что демонстрировать прогресс по 90 делениям куда нагляднее, чем по 7. Более того, цели вполне прозрачно декомпозировались на эти навыки.

Принцип работы модели
Следующее, о чём пришлось задуматься, как по имеющимся данным вычислить текущий уровень ученика. Как я писал выше, коммерческое образование сильно отличается от государственного. В школу ученик приходит в первом классе и уходит после 9-го или 11-го. У нас же минимальный пакет продаваемых уроков 4. А это значит, ученик потенциально может бросить учёбу спустя 4 урока. С нуля же до уровня Advanced проходят сотни уроков. Есть исследование, согласно которому для этого часто нужно больше 1000 часов. Мы были морально не готовы говорить ученику, рассчитывающему на что-то за полгода, про такой объём. Поэтому вопрос о демонстрации прогресса был достаточно острым… Даже в качалке на четвёртом занятии человек может начать жать от груди больше, чем на первом, а что с языком? За 4 занятия ученик выполняет 35 упражнений, если делает домашку, и 17-18, если нет. Полностью проверять владение 1600 навыками долго и дорого. На это никто не пойдёт. Даже самое простое тестирование, по качеству не уступающее ТOEFL или IELTS, занимает те же 4 часа. Нужна была облегчённая методика вычисления уровня по очень разреженным данным.
Перебирая имеющиеся навыки, я обнаружил, что некоторые из них связаны между собой на когнитивном уровне, например, умение извлекать основную мысль из структурированной речи и умение извлекать её из структурированного текста. Также некоторые навыки были связаны на контекстном уровне, например, умение запросить медицинские рекомендации у врача и умение понять выданные медицинские рекомендации. Ещё были чисто грамматические связи: умение задавать вопросы в настоящем времени и умение задавать их в прошедшем. Из этих навыков наши методисты выделили порядка 2000 подобных связей.
Некоторые навыки оказались связаны между собой по цепочке, например: «Может понять простую анкету о здоровье» <-> «Может самостоятельно заполнить простую анкету о состоянии здоровья» <-> «Может понять простые медицинские рекомендации» <-> «Может понять сложные медицинские рекомендации».
Оставалось посчитать с каким повышающим/понижающим коэффициентом предсказывать владение связанными навыками. Здесь помогла математическая оптимизация. На выходе получилась таблица, где для каждой пары связанных навыков X <-> X’ я подсчитал коэффициенты А и В, по которым линейно предсказывалась оценка владения навыком:
- Если ученик владеет навыком Х на У баллов, то навыком Х’ он владеет на А*У баллов.
- Если ученик владеет навыком Х’ на У баллов, то навыком Х он владеет на В*У баллов.

После я взял и вручную разметил самый популярный у учеников курс — каждому упражнению присвоил метку навыка, который оно развивает. Так весной 2018 года родился первый прототип, считающий текущее состояние ученика в любой момент времени. Прототип для наглядности был выполнен в g-spreadsheet-таблице, и время его работы составляло почти 5 минут.
На тот момент он никого не заинтересовал, а меня накрыло делами, связанными с расширением департамента. Из маленькой лаборатории новых методик обучения со 150 учителями мы стали теми, кто отвечает за всех учителей, которых стало уже 10 тысяч. Поэтому целый год я был занят бизнес-аналитикой, перекраиванием процессов, настраиванием отчётности и оптимизацией расходов.
Тем не менее в августе 2019-го о моём проекте вспомнили, и дали ему зелёный свет… Получив временной ресурс (до этого я занимался проектом в свободное от других задач время), я довёл до ума прототип. С помощью Аirflow настроил сбор и предобработку данных, сам скрипт переписал на Рython, векторизировал вычисления и сократил время расчёта одного «слепка прогресса» с 5 минут до 0,75 секунды. Так я начал считать прогресс у первой 1000 студентов, пока что локально. Первое, что я выяснил, — полную несостоятельность методики расчёта уровня ученика на основе уже заполненной предсказаниями карты навыков. Об эволюции методики этого расчёта напишу как-нибудь отдельно, если будет интересно. Информации там хватит на целую статью. Пока в качестве затравки покажу несколько картинок.

Одна из первых карт навыков, точнее, агрегат, показывающий владение ими у учеников
Реальное распределение оценок по навыкам стало огромной проблемой.
Если в тепличных условиях под бдительным методическим присмотром карта навыков имела одинаковый вид (падение оценок от простых к сложным), то в реальности, да ещё и с ограниченным набором данных, типовая картина выглядела так:

Типичный ученик уровня Elementary, учится на курсе General Pre-Intermediate

Ещё один ученик, тоже уровня Elementary, учится на курсе General Elementary

Ученик уровня Pre-Intermediate, учится на курсе General Elementary
Попробуйте на глазок формализовать отличия😉

Типичный ученик уровня Elementary, учится на курсе General Pre-Intermediate

Ещё один ученик, тоже уровня Elementary, учится на курсе General Elementary

Ученик уровня Pre-Intermediate, учится на курсе General Elementary
Попробуйте на глазок формализовать отличия😉
Что получилось
Так или иначе, пришлось отказаться от наивного подхода, интуитивно используемого почти всеми учителями, и запилить более основательный. На этот раз всем заказчикам прототип понравился, и его пошли катить в прод.
Если вы думаете, что на этом история заканчивается, смею вас разочаровать: чудес не бывает. Поначалу считалочку выкатили на 100 тысяч учеников, и первый месяц я не вылезал из баг-репортов.
Во-первых, модель сильно завышала и занижала уровни, что при разборе выявило пару критических багов в методологии. Во-вторых, 100 тысяч учеников это не 1 тысяча — на большом количестве пользователей разнообразие поведений увеличилось на порядок. В-третьих, обнаружились проблемы с разметкой контента, из-за них ученики получали неоправданно высокие оценки за сложные навыки, которые на самом деле не изучались.
За месяц удалось прикрыть основные бреши, и количество обращений из десятков за день сократилось до единиц в неделю, но у модели оставались два системных недостатка. Первый — крайняя чувствительность к выбросам. То есть ученик начального уровня, ни с бухты-барахты решивший выполнить сверхсложное упражнение, получал за него оценку, пусть даже плохую, а она по связанным навыкам через понижающие/повышающие коэффициенты распространялась на более простые навыки. В результате на уровне ученика рисовалась благостная картинка, а виджет в личном кабинете показывал скачок прогресса.
Второй недостаток — зависимость от типа контента. Так уж вышло, что наши ученики в большинстве своём не пишут эссе и не выполняют самостоятельных разговорных упражнений. Хотя долгое время это были единственные упражнения, по которым можно было истинно оценить навыки письма и говорения. Из-за этого у большинства все оценки за письмо и говорение были предсказаны с понижающими коэффициентами. Прогресс таких учеников мог на месяц, а то и более, зависнуть на месте и не двигаться.
Итог
Даже несмотря на недостатки, модель позволила нам, вычистив данные, вести образовательную аналитику и оптимизировать учебный процесс. Например, мы выяснили, что в текущем general-курсе, на котором учится львиная доля учеников, подача навыков очень скачет по сложности. Плюс есть и вовсе проклятые упражнения, в которых все ученики допускают по 3 и более ошибок.
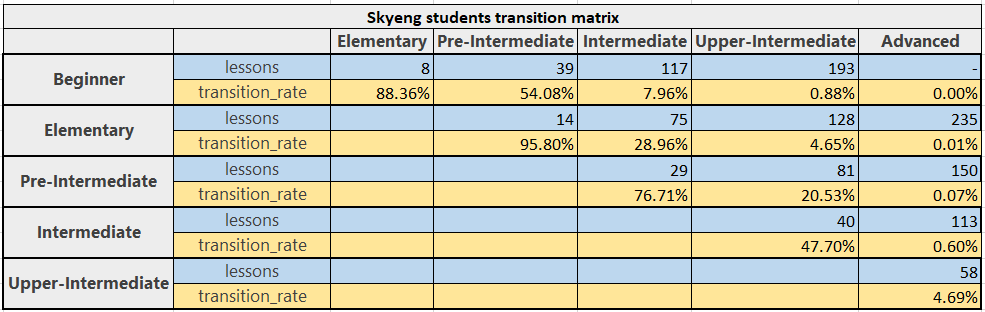
Более сбалансированный новый курс позволил ученикам прогрессировать на 17% быстрее: навыки, что ученик раньше осваивал за 10 уроков, теперь осваиваются за 8 и одну домашку. А это уже неплохая экономия для самих учеников, и мы не собираемся останавливаться на достигнутом. Кстати, если вы думаете, что для нас экономически нецелесообразно сокращать путь ученика, то взгляните на матрицу переходов в самом начале поста и обратите внимание, какая доля учеников доходит, скажем, от Еlementary до Аdvanced. Ученик, достигающий поставленных целей быстрее и веселее, более склонен ставить новые и продолжать учиться, нежели ученик, месяцами стоящий на месте. Но я отвлёкся, вернёмся к модели.
В таком состоянии модель прожила весь 2020-й год и половину 2021-го. Да, были значительные изменения, связанные с методикой, из-за которых задним числом приходилось пересчитывать прогресс сотен тысяч учеников, но системные недостатки от этого никуда не девались. Тем не менее за эти полтора года собирались ценнейшие данные об учениках и их уровнях на каждый урок. Эти данные, будучи очищенными от выбросов, помогли сделать следующие шаги. И конечно, низкий поклон тем, кто придумал и довёл до ума трансформеры. Их использование в обработке аудио и текста внесло огромную лепту в мою работу. Об этом могу рассказать подробнее в другой раз, а пока вернусь к тому, что удалось сделать, переиспользуя обработанные моделью прогресса данные.
Во-первых, была разработана методика оценки уровня активного словарного запаса. Не объёма, а именно уровня. В отличие от простых текстовых классификаторов она не просто смотрит распределение слов, а вычисляет их смыслы в речи и лишь после этого распределяет по уровням.
Во-вторых, был написан гибридный грамматический парсер. За 1,1 секунды эта машина проверяет сказанное учеником в течение урока, выделяя использование 400+ грамматических конструкций.
В-третьих, на основе 5 млн записей об уровнях учеников была построена модель предсказания уровня по трём аспектам вместо пяти. Зная на входе только данные по грамматике, аудированию и чтению, мы с 99,7% точностью можем сказать уровень CEFR ученика.
В-четвёртых, была обучена модель, которая на основе 500 секунд произвольной речи ученика может с 97,6% точностью определить его уровень по CEFR.
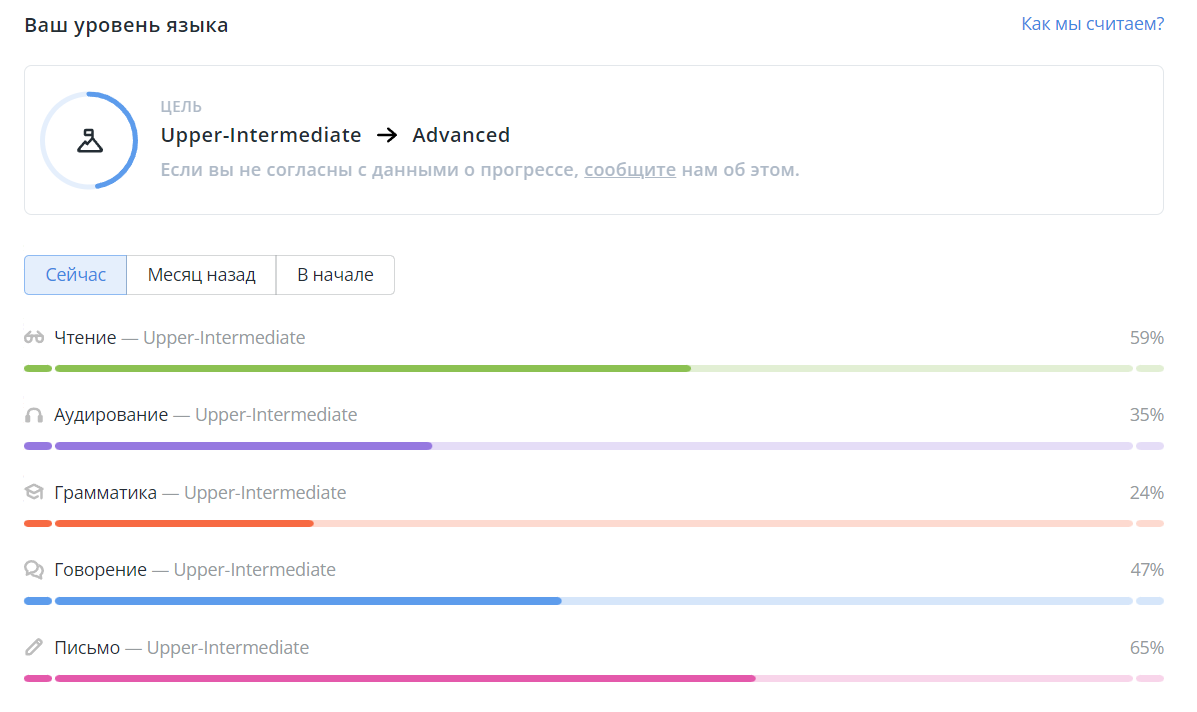
И наконец, я посчитал насколько каждое упражнение, в зависимости от того как хорошо оно выполнено, меняет уровень ученика. Эти данные позволили расшить сложную модель предсказания уровня и впредь оперировать только изменениями, агрегируя их как душе угодно. Хотите знать, как домашка приблизила вас к новому уровню, но сделали из неё только половину, — пожалуйста. Хотите знать, сколько уроков вам осталось до level-up’а — пожалуйста. Для каждого деления шкалы GSE мы знаем сколько потребуется ученику упражнений и какого уровня сложности, чтобы перейти на следующее деление. Так родилась шкала опыта, той самой экспы, что мы сейчас начисляем ученику. Наконец-то демонстрация прогресса приблизилась к тому, как я её себе представлял 4 года назад: за каждый шаг ученик получает положительное подкрепление, и более того, видит, где он сейчас, и что чем более внимательно и усерднее он занимается, тем быстрее растёт.
Ещё пара аспектов работы модели.
Если ученик подтянул английский где-то самостоятельно — это обнаружится на следующих занятиях. Перескоринга не будет, но если ученик обычно получал, скажем, по 50 опыта за домашку, то будет получать по 75 за счёт уменьшения количества ошибок, пока его оценка в системе не придёт в соответствие с его реальным навыком.
В зависимости от локали нужно достаточно сильно менять уровни некоторых навыков. Например, китайский ученик сначала проходит склонения, потом времена. У нас наоборот. Некоторые навыки, помеченные в исходной модели как «средний», попали в самое начало, потому что то, что взрослый человек освоил на уровне русского, часто может смоделировать на английском. И наоборот. То, что очевидно для романской группы языков и находится на начальном уровне, у нас или в Китае вполне будет в конце или середине по сложности (речь про диапазон от Beginner до Pre-Intermediate). При выходе на китайский рынок мы будем долго собирать данные, догоним модель ещё раз, но не будем продумывать методику и размечать упражнения ещё раз. Поправки будут по уровням и коэффициентам, по шкале опыта, но не по ядру.
В заключение хочу рассказать, зачем я всё это пишу. Сейчас EdTech развивается невероятными темпами, но многие компании игнорируют подобные задачи из-за их сложности и длительности, даже ко мне поначалу относились со скепсисом. Так вот я хочу, чтобы никто не боялся браться за нетривиальные вызовы, чтобы онлайн-образование и вообще образование в целом было более интересным и более наглядным. Лично мне этого в детстве очень не хватало.
