Одна из задач при интеграции сторонней поисковой машины в систему — это настройка процесса обработки исходных документов (грубо говоря, индексирования). Сложность настройки такого процесса зависит от функциональных требований к системе поиска и возможностей поисковой машины. Настройка может как ограничиться парой кликов в админке поисковой машины, так и вылиться в написание собственных процедур, скриптов и т.д. Если стандартным возможностям системы (тем более если ее код не может быть модифицирован) мы привыкли доверять, то для собственных скриптов хотелось бы иметь тесты, реализация которых не всегда предусмотрена движком.
Мы столкнулись с необходимостью реализации поиска на платформе MS FAST ESP 5.3. Этот серьезный движок имеет внушительные возможности кастомизации обработки документов, некоторые из которых мы затронули в своем проекте. В-общем-то, мы хотим поделиться нашим способом тестирования кастомных стейджей на этом движке.
Документация достаточно хорошо описывает процесс создания стейджей. Мы не будем ее пересказывать, ограничимся лишь сведениями, необходимыми для понимания изложенного.
В терминологии FAST ESP вся последовательность действий, которая должна быть выполнена при индексировании одного документа, называется Pipeline, а отдельные действия — Stage. Stage запускается в определенном контексте, с которым может взаимодействовать, одним из элементов которого является документ. К примеру, stage может считывать и записывать атрибуты обрабатываемого документа. Схематично весь процесс обработки документов выглядит так:

Стейдж представлен в виде двух файлов — xml-спецификации и реализации (в FAST ESP 5.3 реализация предусматривает использование языка python v.2.3).
Ниже пример стейджа, который записывает в поле quality значение 500, если атрибут документа hotornew имеет значение true.
(спецификация непосредственно в тестах не участвует, приведена для целостности картинки)
Для того, чтобы проверить работу созданного стейджа в родном контексте обработки документа, необходимо проделать последовательность действий, указанную в документации:
1. Выложить в определенные каталоги файлы спецификации и реализации;
2. Перезапустить службу обработки документов — Document Processor (procserver. при запуске он компилирует код стейджей);
3. Включить новый стейдж в pipeline;
4. Проиндексировать тестовый документ;
5. Посмотреть на результат обработки документа (можно вывести в лог-файл, а можно “найти” новый документ через стандартный фронтенд и посмотреть все атрибуты документа).
В случае, если мы не получили ожидаемого результата (к примеру в документе выставили поле hotornew = true, a значение поля Quality так и не изменилось), нам придется заняться отладкой, что означает:
— Поискать ошибку в логе procserver’a;
— Проконтролировать, сделал ли конкретно наш стейдж то, что от него просили, поставив стейджи Spy до и после выполнения тестируемого стейджа. (Spy выгружает дамп документа вместе с его атрибутами в файл на диске);
— Поискать ошибку в коде стейджа.
После того как ошибка поправлена, нужно опять проверить — т.е. опять выполнить шаги 1, 2, 4, 5.
Это муторно. Удобнее отлаживать код стейджа “как есть” привычными методами, например в unit-тесте:
Поэтому для “воссоздания” контекста мы сделали примитивные моки классов, с объектами которых работает стейдж:
В реальности сущность document предоставляет и другие методы. Мы ограничились теми, что используем.
Теперь можно писать/отлаживать/тестировать стейдж без поискового движка:
Код целиком есть в архиве.
Что нам дал такой подход:
— Упрощение жизни себе (здорово экономит время и позволяет не отходить от практики модульного тестирования);
— Упрощение жизни тестировщику.
Автор:
Лия Шабакаева
Ведущий разработчик
Департамент разработки Softline
Мы столкнулись с необходимостью реализации поиска на платформе MS FAST ESP 5.3. Этот серьезный движок имеет внушительные возможности кастомизации обработки документов, некоторые из которых мы затронули в своем проекте. В-общем-то, мы хотим поделиться нашим способом тестирования кастомных стейджей на этом движке.
Документация достаточно хорошо описывает процесс создания стейджей. Мы не будем ее пересказывать, ограничимся лишь сведениями, необходимыми для понимания изложенного.
В терминологии FAST ESP вся последовательность действий, которая должна быть выполнена при индексировании одного документа, называется Pipeline, а отдельные действия — Stage. Stage запускается в определенном контексте, с которым может взаимодействовать, одним из элементов которого является документ. К примеру, stage может считывать и записывать атрибуты обрабатываемого документа. Схематично весь процесс обработки документов выглядит так:
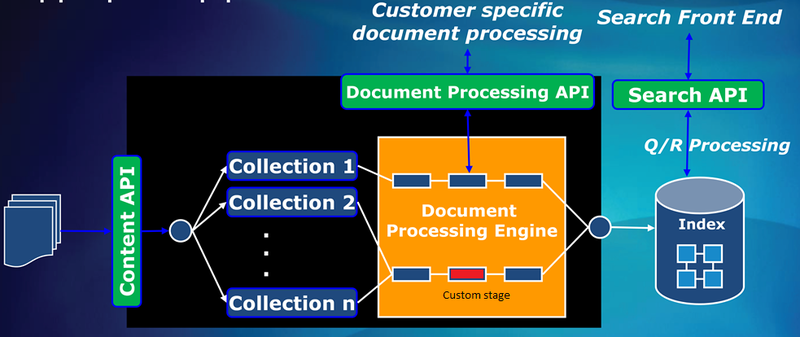
Стейдж представлен в виде двух файлов — xml-спецификации и реализации (в FAST ESP 5.3 реализация предусматривает использование языка python v.2.3).
Ниже пример стейджа, который записывает в поле quality значение 500, если атрибут документа hotornew имеет значение true.
<processors>
<processor>
<load module="processors.SetOnEqual" class="SetOnEqual"/>
<desc>Set high rank to documents, which have HotOrNew = yes
</desc>
<config>
<param name="Input" value="hotornew" type="str" />
<param name="Output" value="quality" type="str" />
<param name="InputFieldValue" value="true" type="str" />
<param name="OutputFieldValue" value="500" type="int" />
</config>
<ops>
<add/>
</ops>
</processor>
</processors>
(спецификация непосредственно в тестах не участвует, приведена для целостности картинки)
from docproc import Processor, DocumentException, ProcessorStatus
class SetOnEqual(Processor.Processor):
def ConfigurationChanged(self, attributes):
self.input = self.GetParameter('Input')
self.output = self.GetParameter('Output')
self.inputfieldvalue = self.GetParameter('InputFieldValue')
self.outputfieldvalue = self.GetParameter('OutputFieldValue')
def Process(self, docid, document):
testField = str(document.GetValue(self.input, None))
if testField == str(self.inputfieldvalue):
output = int(self.outputfieldvalue)
document.Set(self.output,output)
else:
document.Set(self.output, 0)
return ProcessorStatus.OK
Для того, чтобы проверить работу созданного стейджа в родном контексте обработки документа, необходимо проделать последовательность действий, указанную в документации:
1. Выложить в определенные каталоги файлы спецификации и реализации;
2. Перезапустить службу обработки документов — Document Processor (procserver. при запуске он компилирует код стейджей);
3. Включить новый стейдж в pipeline;
4. Проиндексировать тестовый документ;
5. Посмотреть на результат обработки документа (можно вывести в лог-файл, а можно “найти” новый документ через стандартный фронтенд и посмотреть все атрибуты документа).
В случае, если мы не получили ожидаемого результата (к примеру в документе выставили поле hotornew = true, a значение поля Quality так и не изменилось), нам придется заняться отладкой, что означает:
— Поискать ошибку в логе procserver’a;
— Проконтролировать, сделал ли конкретно наш стейдж то, что от него просили, поставив стейджи Spy до и после выполнения тестируемого стейджа. (Spy выгружает дамп документа вместе с его атрибутами в файл на диске);
— Поискать ошибку в коде стейджа.
После того как ошибка поправлена, нужно опять проверить — т.е. опять выполнить шаги 1, 2, 4, 5.
Это муторно. Удобнее отлаживать код стейджа “как есть” привычными методами, например в unit-тесте:
Поэтому для “воссоздания” контекста мы сделали примитивные моки классов, с объектами которых работает стейдж:
class Document(object):
"""
Mock сущности Document
"""
def GetValue(self, name, default):
return getattr(self, name, default)
def Set(self, field, value):
setattr(self, field, str(value))
class Processor (object):
"""
Mock сущности Processor
"""
def GetParameter(self, name):
return getattr(self, name)
def Set(self, field, value):
setattr(self, field, str(value))
В реальности сущность document предоставляет и другие методы. Мы ограничились теми, что используем.
Теперь можно писать/отлаживать/тестировать стейдж без поискового движка:
import unittest
import docproc.Processor as proclib
from docproc import ProcessorStatus
import SetOnEqual
class testSetOnEqual(unittest.TestCase):
def setUp(self):
self.stage = SetOnEqual.SetOnEqual()
self.stage.Set('Input', 'hot')
self.stage.Set('Output', 'quality')
self.assertEquals(self.stage.GetParameter('Input'), 'hot')
self.assertEquals(self.stage.GetParameter('Output'), 'quality')
def test_true(self):
self.stage.Set('InputFieldValue', 'true')
self.stage.Set('OutputFieldValue', '600')
doc = proclib.Document()
doc.Set('hot', 'true')
self.stage.ConfigurationChanged('')
status = self.stage.Process("docid", doc)
self.assertEquals(status, ProcessorStatus.OK)
self.assertEquals(doc.GetValue('quality', ""), '600')
def test_false(self):
self.stage.Set('InputFieldValue', 'true')
self.stage.Set('OutputFieldValue', '600')
doc = proclib.Document()
doc.Set('hot', 'no')
self.stage.ConfigurationChanged('')
status = self.stage.Process("docid", doc)
self.assertEquals(status, ProcessorStatus.OK)
self.assertEquals(doc.GetValue('quality', ""), '0')
def suite():
suite = unittest.TestSuite()
suite.addTest(unittest.makeSuite(testSetOnEqual))
return suite
if __name__ == "__main__":
unittest.main()
Код целиком есть в архиве.
Что нам дал такой подход:
— Упрощение жизни себе (здорово экономит время и позволяет не отходить от практики модульного тестирования);
— Упрощение жизни тестировщику.
Автор:
Лия Шабакаева
Ведущий разработчик
Департамент разработки Softline
