В последнем посте я рассказывал о Kubernetes, о том, как ThoughtSpot использует его для собственных нужд по поддержке разработки. Сегодня хотелось бы продолжить разговор о короткой, но от того не менее интересной истории отладки, которая произошла совсем недавно. Статья базируется на том, что containerization != virtualization. К тому же наглядно показывается, как контейнеризированные процессы конкурируют за ресурсы даже при оптимальных ограничениях по cgroup и высокой производительности машины.
Ранее мы запускали серии операций, связанных с разработкой b CI/CD, во внутренем кластере Kubernetes. Все бы ничего, да при запуске «докеризированного» приложения неожиданно сильно падала производительность. Мы не скупились: в каждом из контейнеров стояли ограничения по вычислительной мощности и памяти (5 CPU / 30 ГБ RAM), заданные через конфигурацию Pod. На виртуальной машине с такими параметрами все наши запросы из крошечного набора данных (10 Кб) для тестов летали бы. Однако в Docker & Kubernetes на 72 CPU / 512 ГБ RAM мы успевали запустить 3–4 копии продукта, а потом начинались тормоза. Запросы, которые раньше завершались за пару миллисекунд, теперь висели по 1–2 секунде, и это вызывало всевозможные сбои в CI-конвейере задач. Пришлось вплотную заняться отладкой.
Как правило, под подозрением — всевозможные ошибки конфигурации при упаковке приложения в Docker. Однако мы не нашли ничего, что могло бы вызвать хоть какое-либо замедление (если сравнивать с установками на голом железе или виртуальных машинах). С виду все правильно. Далее мы опробовали всевозможные тесты из пакета Sysbench. Проверили производительность ЦП, диска, памяти — все было таким же, как и на голом железе. Некоторые сервисы нашего продукта хранят подробную информацию обо всех действиях: ее потом можно использовать в профилировании производительности. Как правило, при нехватке какого-либо ресурса (ЦП, оперативной памяти, диска, сети) в некоторых вызовах отмечается значительный провал во времени — так мы обнаруживаем, что именно тормозит и где. Однако в данном случае ничего такого не произошло. Временные пропорции не отличались от исправной конфигурации — с той лишь разницей, что каждый вызов был значительно медленнее, чем на голом железе. Ничто не указывало на настоящий источник проблемы. Мы уже были готовы сдаться, как вдруг нашли вот это.
В этой статье автор анализирует похожий загадочный случай, когда два, по идее, легких процесса убивали друг друга при запуске внутри Docker на одной и той же машине, причем ограничения ресурсов выставлялись на весьма скромные значения. Мы сделали два важных вывода:
- Основная причина крылась в самом ядре Linux. Из-за структуры кэша-объектов dentry в ядре, поведение одного процесса сильно тормозило вызов ядра
__d_lookup_loop, что прямым образом сказывалось на производительности другого. - Автор использовал
perfдля обнаружения ошибки в ядре. Прекрасное средство отладки, которым мы никогда раньше не пользовались (а жаль!).
perf (иногда его называют perf_events или perf-инструменты; ранее был известен как Performance Counters for Linux, PCL) — это инструмент анализа производительности в Linux, доступный с версии ядра 2.6.31. Утилита управления пользовательским пространством, perf, доступна с командной строки и представляет собой набор подкоманд.
Она осуществляет статистическое профилирование целой системы (ядра и пространства пользователя). Данное средство поддерживает счетчики производительности аппаратной и программной (например, hrtimer) платформы, точки трассировки и динамические пробы (скажем, kprobes или uprobes). В 2012 году два инженера IBM признали perf (наряду с OProfile) одним из двух наиболее используемых инструментов профилирования счетчиков производительности в Linux.
Вот мы и подумали: может, и у нас то же самое? Мы же запускали сотни различных процессов в контейнерах, и во всех было одно и то же ядро. Мы чуяли, что напали на след! Вооружившись perf, повторили отладку, и в итоге нас ждало преинтереснейшее открытие.
Ниже приведены записи perf первых 10 секунд ThoughtSpot, работающего на здоровой (быстрой) машине (слева) и внутри контейнера (справа).
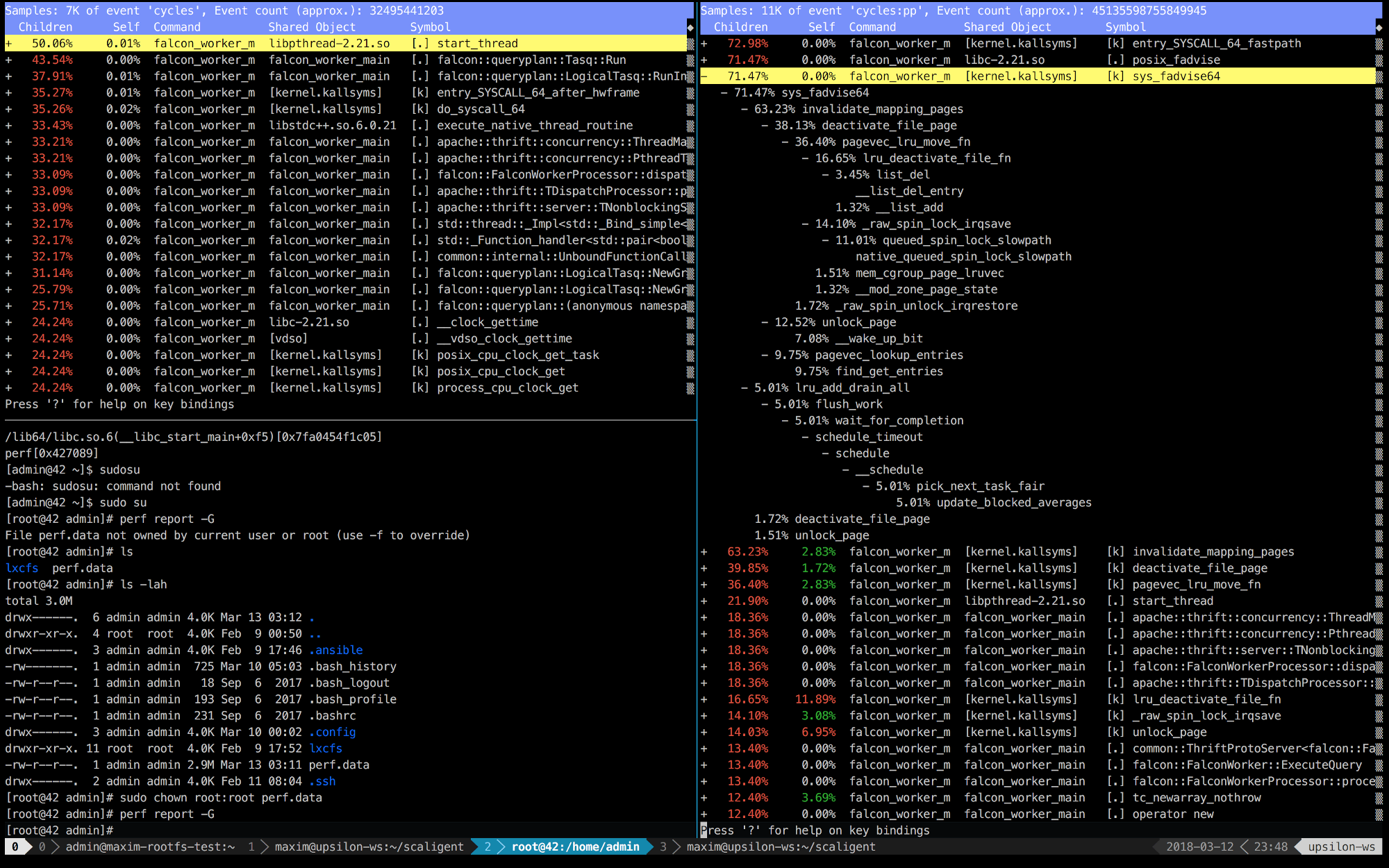
Сразу видно, что справа первые 5 вызовов связаны с ядром. Время, в основном, расходуется на пространство ядра, тогда как слева — большая часть времени идет на собственные процессы, выполняемые в пространстве пользователя. Но самое интересное, что все время занимает вызов posix_fadvise.
Программы используют posix_fadvise(), заявляя о намерении доступа к данным файла по определенному шаблону в будущем. Это дает ядру возможность провести необходимую оптимизацию.
Вызов используется для любых ситуаций, поэтому явно на источник проблемы не указывает. Однако, покопавшись в коде, я нашел лишь одно место, которое, теоретически, затрагивал каждый процесс в системе:
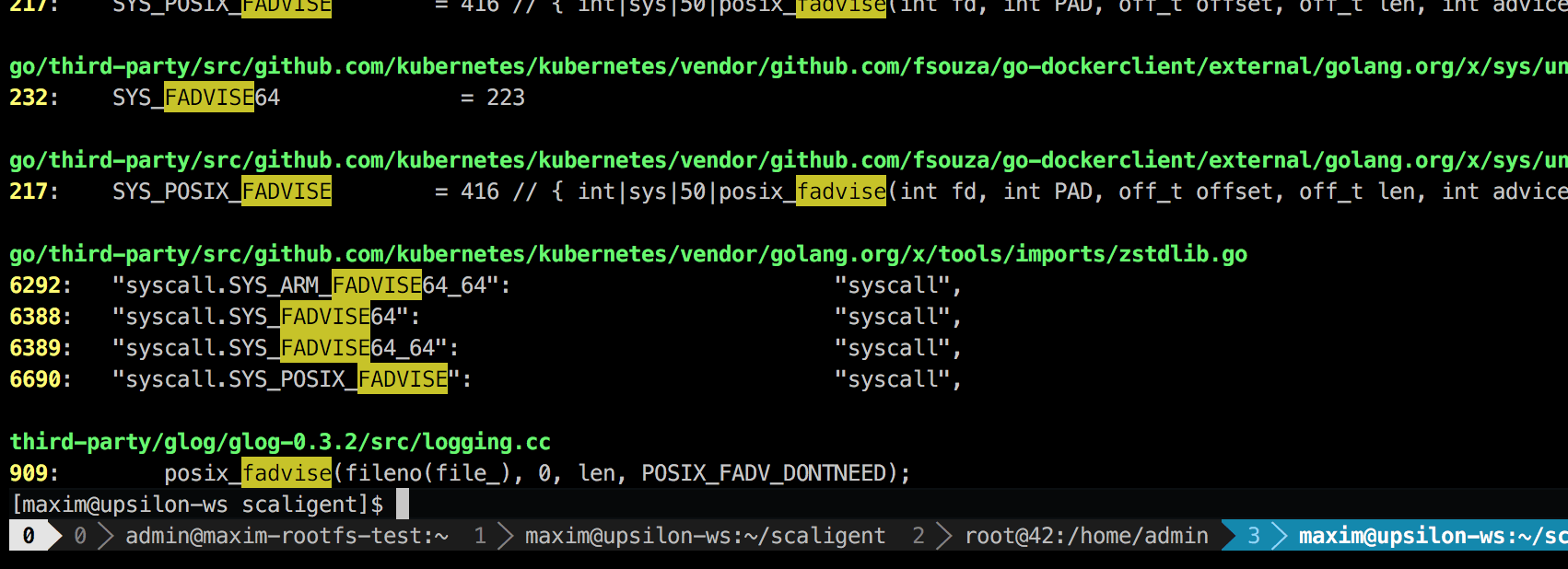
Это сторонняя библиотека логирования под названием glog. Мы пользовались ей для проекта. Конкретно эта строка (в LogFileObject::Write), наверное, самый критический путь всей библиотеки. Она вызывается для всех событий «запись лога в файл» (log to file), а многие экземпляры нашего продукта пишут лог довольно часто. Беглый взгляд на исходный код подсказывает, что часть fadvise можно отключить, установив параметр --drop_log_memory=false:
if (file_length_ >= logging::kPageSize) {
// don’t evict the most recent page
uint32 len = file_length_ & ~(logging::kPageSize — 1);
posix_fadvise(fileno(file_), 0, len, POSIX_FADV_DONTNEED);
}
}что мы, конечно же, сделали и… в яблочко!
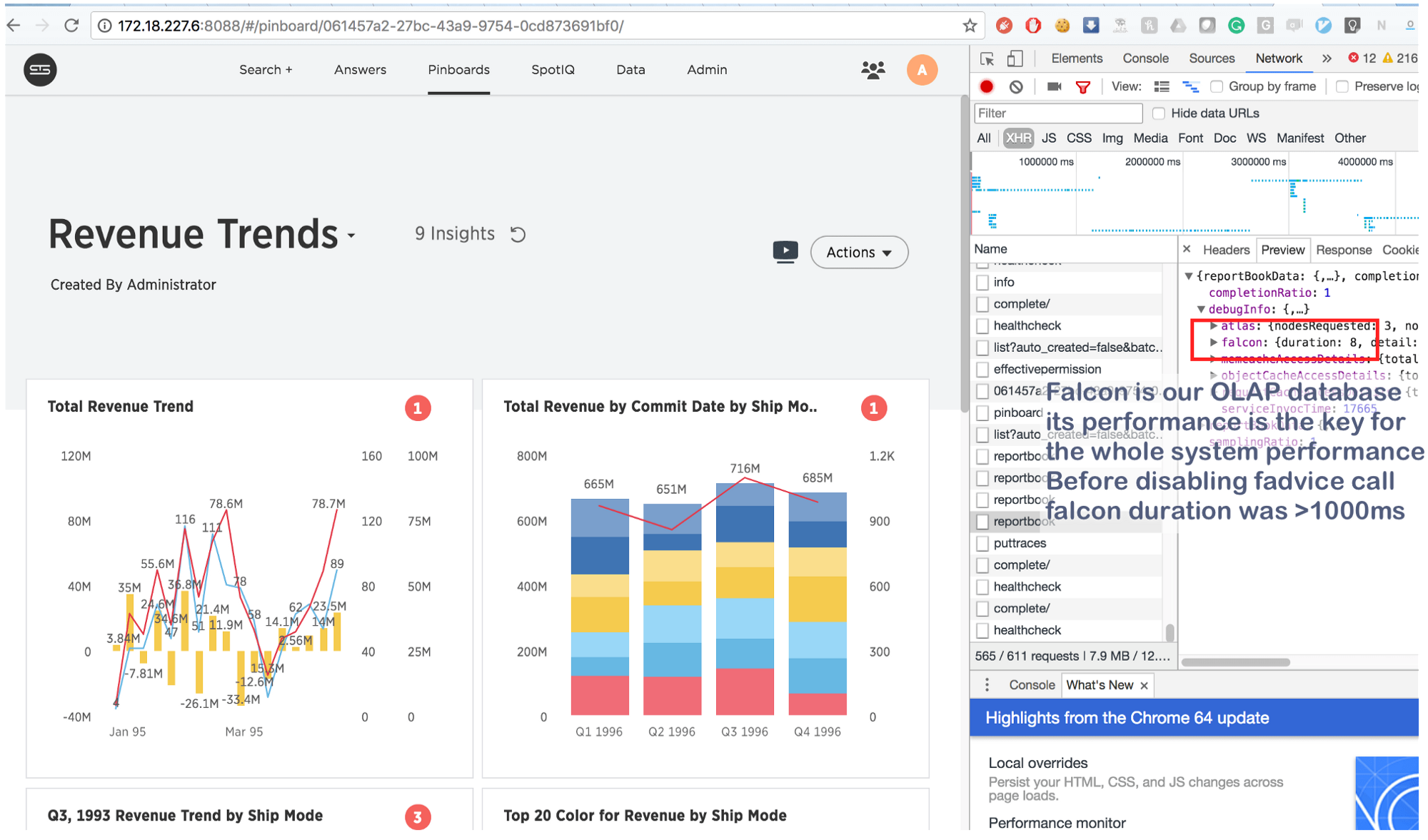
То, что раньше отнималло пару секунд, теперь выполняется за 8 (восемь!) миллисекунд. Немножко погуглив, мы нашли вот что: https://issues.apache.org/jira/browse/MESOS-920 и еще это: https://github.com/google/glog/pull/145, что в очередной раз подтвердило нашу догадку об истинной причине торможения. Скорее всего, то же самое происходило и на виртуальной машине/голом железе, но так как у нас было по 1 копии процесса на каждую машину/ядро, то интенсивность вызова fadvise была значительно ниже, чем и объяснялось отсутствие дополнительного потребления ресурсов. Увеличив процессы логирования в 3–4 раза и выделив им одно общее ядро, мы увидели, что это действительно застопорило fadvise.
И в заключение:
Информация эта не нова, но многие почему-то забывают главное: в случаях с контейнерами «изолированные» процессы конкурируют за все ресурсы ядра, а не только за ЦП, оперативную память, дисковое пространство и сеть. А поскольку ядро — это архисложная структура, то сбои могут происходить где угодно (как, например, в __d_lookup_loop из статьи Sysdig). Это, правда, не говорит о том, что контейнеры хуже или лучше традиционной виртуализации. Они — отличный инструмент, решающий свои задачи. Просто помните: ядро — это общий ресурс, и готовьтесь к отладке неожиданных конфликтов в пространстве ядра. Кроме того, такие конфликты — отличная возможность для злоумышленников прорваться через «истонченную» изоляцию и создать скрытые каналы между контейнерами. И, наконец, есть perf — отличное средство, которое покажет, что происходит в системе, и поможет отладить любые проблемы с производительностью. Если планируете запускать высоконагруженные приложения в Docker, то обязательно выделите время на изучение perf.
