Благодаря анализу в реальном времени мы, сотрудники компании Uber, получаем представление о состоянии дел и эффективности работы и на основе данных решаем, как повысить качество работы на платформе Uber. Например, проектная команда мониторит состояние рынка и выявляет потенциальные проблемы на нашей платформе; программное обеспечение на базе моделей машинного обучения прогнозирует предложения пассажиров и спрос на водителей; специалисты по обработке данных улучшают модели машинного обучения — чтобы, в свою очередь, повысить качество прогнозирования.

В прошлом для анализа в реальном времени мы использовали решения по базам данных от других компаний, но ни одно не отвечало всем нашим критериям функциональности, масштабируемости, эффективности, стоимости и эксплуатационным требованиям.
Выпущенный в ноябре 2018 года AresDB представляет собой инструмент анализа в реальном времени с открытым исходным кодом. Он использует нетрадиционный источник питания, графические процессоры (GPU), что позволяет увеличивать масштаб анализа. Технология GPU, перспективный инструмент анализа в реальном времени, за последние годы значительно продвинулась, что делает ее идеальной для параллельных вычисления в реальном времени и обработки данных.
В следующих разделах мы опишем структуру AresDB и то, как это интересное решение для анализа в реальном времени позволило нам эффективнее и более рационально унифицировать, упростить и усовершенствовать решения по базам данных Uber для анализа в реальном времени. Надеемся, после прочтения данной статьи вы опробуете AresDB в рамках собственных проектов и также убедитесь в его полезности!
Приложения Uber для анализа в реальном времени
Анализ данных принципиально важен для успешной деятельности Uber. Помимо других функций, аналитические инструменты используются для решения следующих задач:
- Построение информационных панелей для мониторинга бизнес-метрик.
- Принятие автоматических решений (например, определение стоимости поездки и выявление случаев мошенничества) на базе собранных сводных метрик.
- Создание случайных запросов для диагностики, поиска и устранения проблем в рамках бизнес-операций.
Мы распределяем эти функции по категориям с различными требованиями следующим образом:

Информационные панели и системы принятия решений используют системы анализа в реальном времени, чтобы создавать аналогичные запросы по относительно небольшим, но обладающим высокой важностью подмножествам данных (с максимальным уровнем актуальности данных) при высоком QPS и низком запаздывании.
Потребность в другом аналитическом модуле
Наиболее распространенная проблема, для решения которой в Uber используются инструменты анализа в реальном времени, — это вычисления совокупностей временных рядов. Эти вычисления дают представление о взаимодействии с пользователями, чтобы мы могли соответствующим образом повышать качество услуг. На их основе мы запрашиваем показатели по определенным параметрам (например, день, час, идентификатор города и статус поездки) за определенный период времени для произвольно отфильтрованных (или иногда объединенных) данных. За прошедшие годы компания Uber развернула несколько систем, направленных на решение этой задачи различными способами.
Вот некоторые сторонние решения, которые мы использовали для решения проблем этого типа:
- Apache Pinot, распределенная аналитическая база данных с открытым исходным кодом, написанная на Java, подходит для крупномасштабного анализа данных. Pinot использует внутреннюю лямбда-архитектуру для запроса пакетных данных и данных в реальном времени в столбчатом хранилище, инвертированный битовый индекс для фильтрации и звездчатое дерево — для кеширования совокупных результатов. Однако он не поддерживает функции дедупликации на основе ключей, обновления или вставки, объединения, а также расширенные функции запросов, например функцию геопространственной фильтрации. Кроме того, поскольку Pinot представляет собой базу данных на основе JVM, выполнение запросов является очень дорогим с точки зрения использования памяти.
- Elasticsearch используется в Uber для решения различных задач по потоковому анализу. Он построен на базе библиотеки Apache Lucene, в которой хранятся документы, для полнотекстового поиска по ключевым словам и инвертированного индекса. Система широко распространена и расширена для поддержки совокупных данных. Инвертированный индекс обеспечивает фильтрацию, но не оптимизирован для хранения и фильтрации данных на основе временных диапазонов. Записи хранятся в виде документов JSON, что накладывает дополнительные расходы на обеспечение доступа к хранилищу и запросам. Как и Pinot, Elasticsearch представляет собой базу данных на основе JVM и, соответственно, не поддерживает функцию объединения, а выполнение запросов занимает большой объем памяти.
Хотя эти технологии имеют свои сильные стороны, им не хватало некоторых функций, необходимых для нашего варианта использования. Нам нужно было унифицированное, упрощенное и оптимизированное решение, и в его поисках мы работали в нестандартном направлении (точнее, внутри GPU).
Использование GPU для анализа в реальном времени
Для реалистичного рендеринга изображений с высокой частотой кадров графические процессоры параллельно обрабатывают огромное количество форм и пикселей на высокой скорости. Хотя тенденция к увеличению тактовой частоты блоков обработки данных за последние несколько лет пошла на убыль, число транзисторов в микросхеме увеличилось только по закону Мура. В результате скорость вычислений GPU, измеряемая в гигафлопсах в секунду (Гфлопс/с), быстро увеличивается. На рисунке 1 ниже представлено сравнение тенденции теоретической скорости (Гфлопс/с) GPU от NVIDIA и CPU от Intel на протяжении ряда лет:
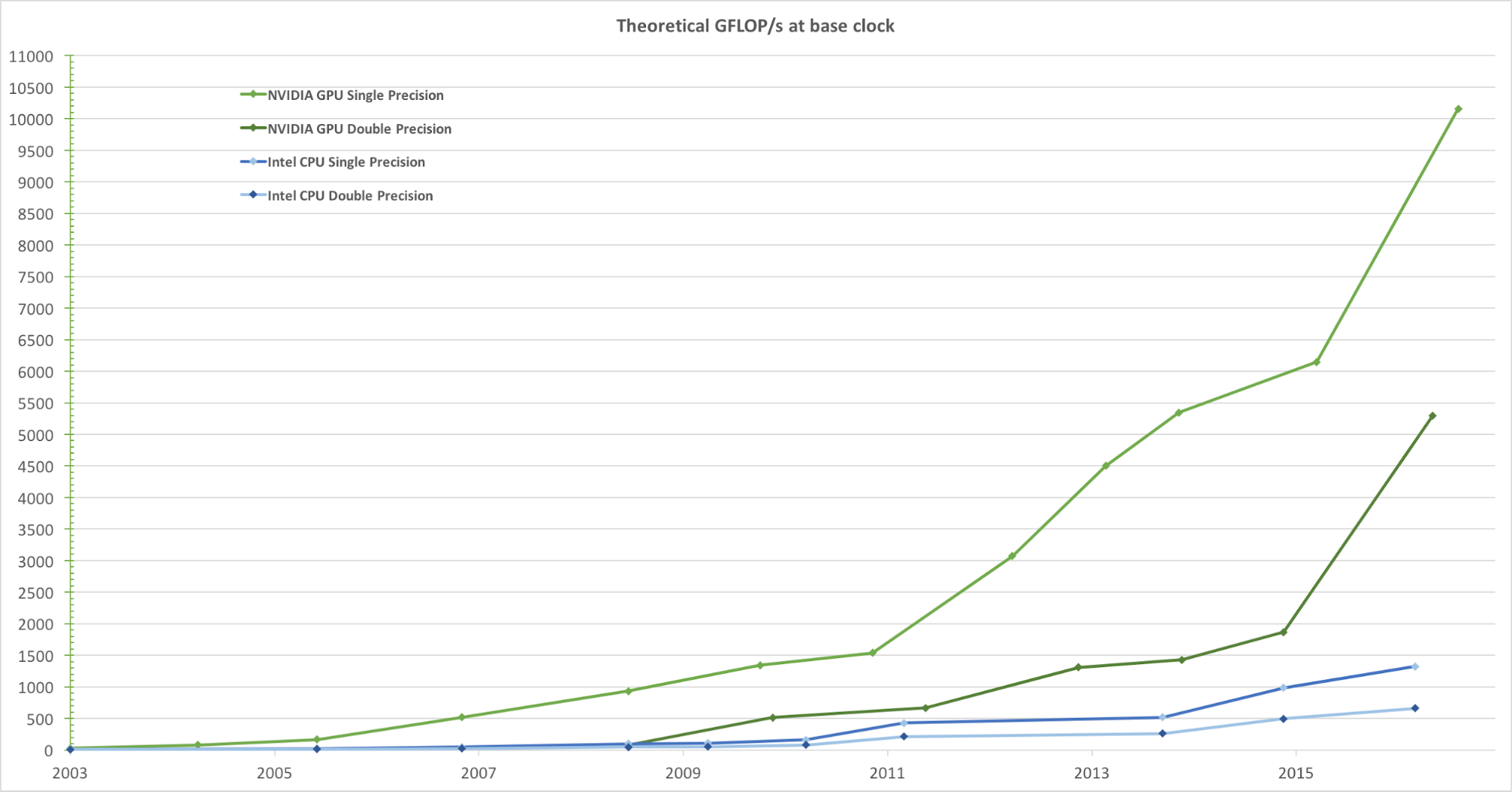
Рисунок 1. Сравнение эффективности CPU и GPU по одинарной точности с плавающей запятой на протяжении нескольких лет. Изображение взято из руководства по программированию CUDA C от Nvidia.
При разработке механизма запроса анализа в реальном времени решение об интеграции графического процессора было естественным. В Uber типичный запрос анализа в реальном времени требует обработки данных за несколько дней с миллионами, а то и миллиардами записей, затем их фильтрации и обобщения за короткий период времени. Эта вычислительная задача идеально вписывается в модель параллельной обработки GPU общего назначения, поскольку они:
- Обрабатывают данные параллельно с очень высокой скоростью.
- Обеспечивают более высокую скорость вычислений (Гфлопс/с), благодаря чему прекрасно подходят для выполнения сложных вычислительных задач (по блокам данных), которые можно распараллелить.
- Обеспечивают более высокую производительность (без запаздывания) по обмену данными между вычислительным блоком и хранилищем (ALU и глобальная память GPU) по сравнению с центральными процессорами (CPU), благодаря чему они идеально подходят для обработки параллельных задач ввода-вывода, связанных с памятью, что требует значительного объема данных.
Остановившись на использовании аналитической базы данных на основе GPU, мы — с позиции своих потребностей — оценили несколько существующих аналитических решений, в которых используются GPU:
- Kinetica, аналитический инструмент на базе GPU, появился на рынке в 2009 году, первоначально для использования в структурах армии и разведслужб США. Хотя он демонстрирует высокий потенциал технологии GPU в аналитике, мы обнаружили, что для наших условий использования отсутствуют многие ключевые функции, в том числе изменение схемы, частичная вставка или обновление, сжатие данных, конфигурация памяти диска и памяти на уровне столбцов, а также соединение по геопространственным связям.
- OmniSci, модуль запросов на базе SQL с открытым исходным кодом, казался многообещающим вариантом, но при оценке продукта мы поняли, что в нем отсутствуют некоторые важные функции для использования в Uber, например дедупликация. Хотя OminiSci представила открытый код своего проекта в 2017 году, после анализа их решения на основе C++ мы пришли к выводу, что ни изменение, ни разветвление их кодовой базы практически не осуществимы.
- Инструменты анализа в реальном времени на основе GPU, в том числе GPUQP, CoGaDB, GPUDB, Ocelot, OmniDB и Virginian, часто используются в научно-образовательных учреждениях. Однако, учитывая их академические цели, эти решения сосредоточены на разработке алгоритмов и проверке концепций, а не на решении реальных задач. По этой причине мы не принимали их в расчет — в условиях нашего объема и масштаба.
В целом, эти системы демонстрируют огромное преимущество и потенциал обработки данных с использованием технологии GPU, и они вдохновили нас на создание нашего собственного решения по анализу в реальном времени на базе GPU, адаптированного к потребностям Uber. Опираясь на эти концепции, мы разработали и открыли исходный код AresDB.
Обзор архитектуры AresDB
На высоком уровне AresDB хранит большую часть данных в памяти хоста (RAM, которая связана с CPU), использует CPU для обработки принятых данных и диски для восстановления данных. В период запроса AresDB передает данные из памяти хоста в память GPU для параллельной обработки в GPU. Как показано на рисунке 2 ниже, AresDB включает хранилище памяти, хранилище метаданных и диск:

Рисунок 2. Уникальная архитектура AresDB включает хранилище памяти, диск и хранилище метаданных.
Таблицы
В отличие от большинства систем управления реляционными базами данных (RDBMS), в AresDB отсутствует область действия базы данных или схемы. Все таблицы относятся к одной и той же области действия в одном кластере/экземпляре AresDB, что позволяет пользователям обращаться к ним напрямую. Пользователи хранят свои данные в виде таблиц фактов и таблиц измерений.
Таблица фактов
В таблице фактов хранится бесконечный поток событий временных рядов. Пользователи используют таблицу фактов для хранения событий/фактов, которые происходят в реальном времени, и каждое событие связано со временем события, при этом запрос таблицы часто производится по времени события. В качестве примера того типа информации, который хранится в таблице фактов, можно назвать поездки, где каждая поездка представляет собой событие, а время запроса на поездку часто обозначается как время события. Если с событием связано несколько временных меток, только одна временная метка указывается в качестве времени события и отображается в таблице фактов.
Таблица измерения
В таблице измерения хранятся текущие характеристики объектов (включая города, клиентов и водителей). Например, пользователи могут хранить информацию о городе, в частности название города, временную зону и страну, в таблице измерения. В отличие от таблиц фактов, которые постоянно увеличиваются, таблицы измерений всегда ограничены по размеру (например, для Uber таблица городов ограничена фактическим количеством городов в мире). Таблицы измерений не требуют наличия специального столбца времени.
Типы данных
В таблице ниже представлены текущие типы данных, которые поддерживаются в AresDB:
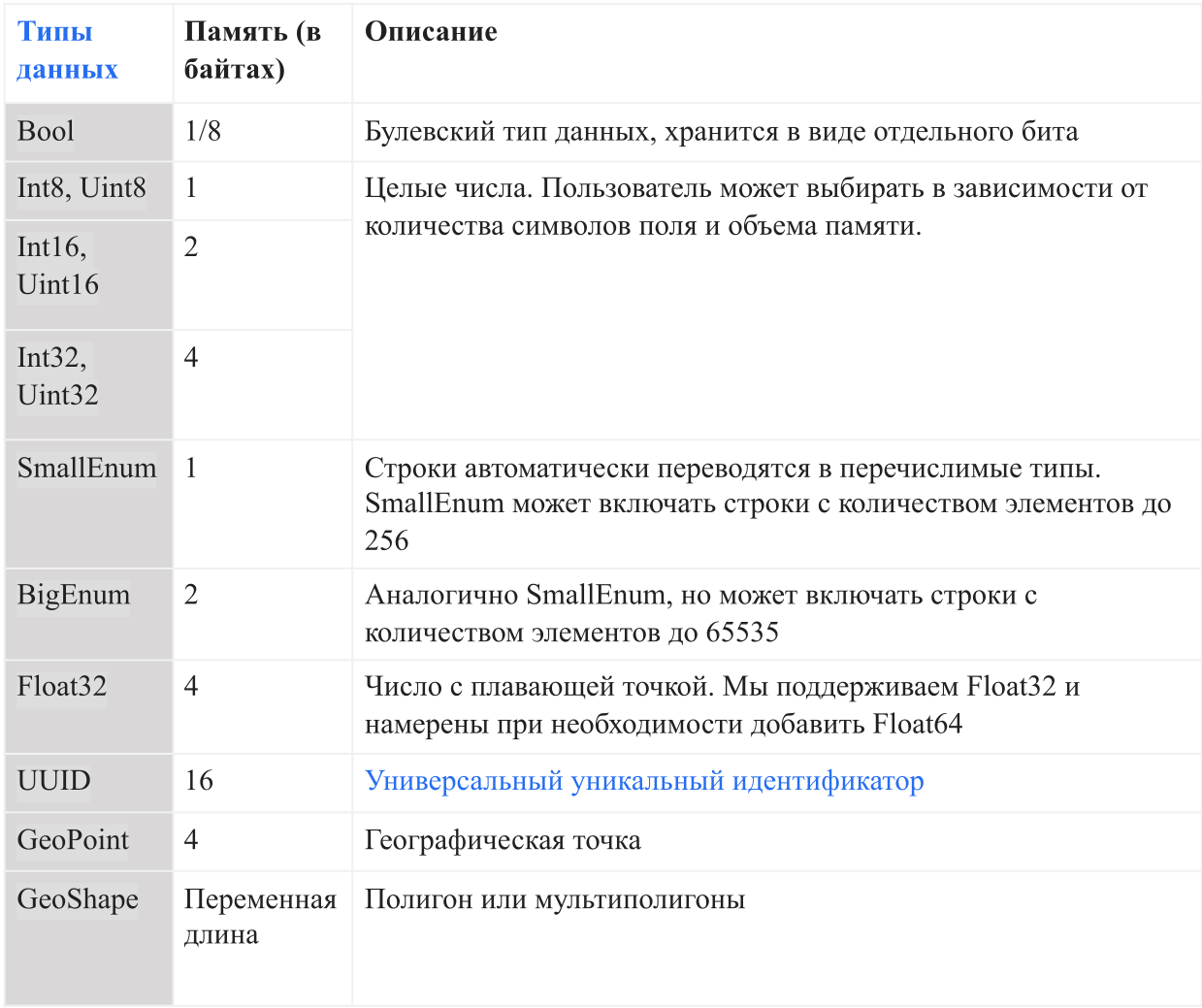
В AresDB строки конвертируются в перечислимые типы (enums) автоматически перед попаданием в базу данных, чтобы повысить удобство хранения и эффективность запросов. Это позволяет выполнять проверку равенства с учетом регистра, но не поддерживает такие продвинутые операции, как конкатенация, подстроки, маски и сопоставление регулярных выражений. В будущем мы намерены добавить опцию поддержки полной строки.
Основные функции
Архитектура AresDB поддерживает следующие функции:
- Хранение на основе столбцов со сжатием для повышения эффективности хранения (меньший объем использования памяти в байтах для хранения данных) и эффективности запроса (меньший объем обмена данными между памятью CPU и памятью GPU при обработке запроса)
- Обновление или вставка в реальном времени с дедупликацией первичного ключа для повышения точности данных и обновления данных в реальном времени в течение нескольких секунд
- Обработка запросов с использованием GPU для высокопараллельной обработки данных на GPU с низкой задержкой запроса (от доли секунды до нескольких секунд)
Столбчатое хранилище
Вектор
AresDB хранит все данные в столбчатом формате. Значения каждого столбца хранятся в виде вектора значения столбца. Маркер достоверности/неопределенности значений в каждом столбце хранится в отдельном нулевом векторе, при этом маркер достоверности каждого значения представлен в виде одного бита.
Активное хранилище
AresDB хранит несжатые и неотсортированные данные столбцов (активные векторы) в активном хранилище. Записи данных в активном хранилище делятся на (активные) пакеты заданного объема. Новые пакеты создаются при приеме данных, в то время как старые пакеты удаляются после архивации записей. Индекс первичного ключа используется для определения местоположения записей для дедупликации и обновления. На рисунке 3 ниже показано, как мы организуем активные записи и используем значение первичного ключа для определения их местоположения:
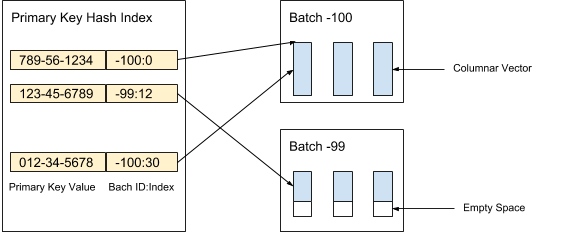
Рисунок 3. Мы используем значение первичного ключа для определения местоположения пакета и позиции каждой записи внутри пакета.
Значения каждого столбца в пакете хранятся в виде вектора столбца. Маркер достоверности/неопределенности значений в каждом векторе значения хранится в виде отдельного нулевого вектора, при этом маркер достоверности каждого значения представлен в виде одного бита. На рисунке 4 ниже мы предлагаем пример с пятью значениями для столбца city_id:
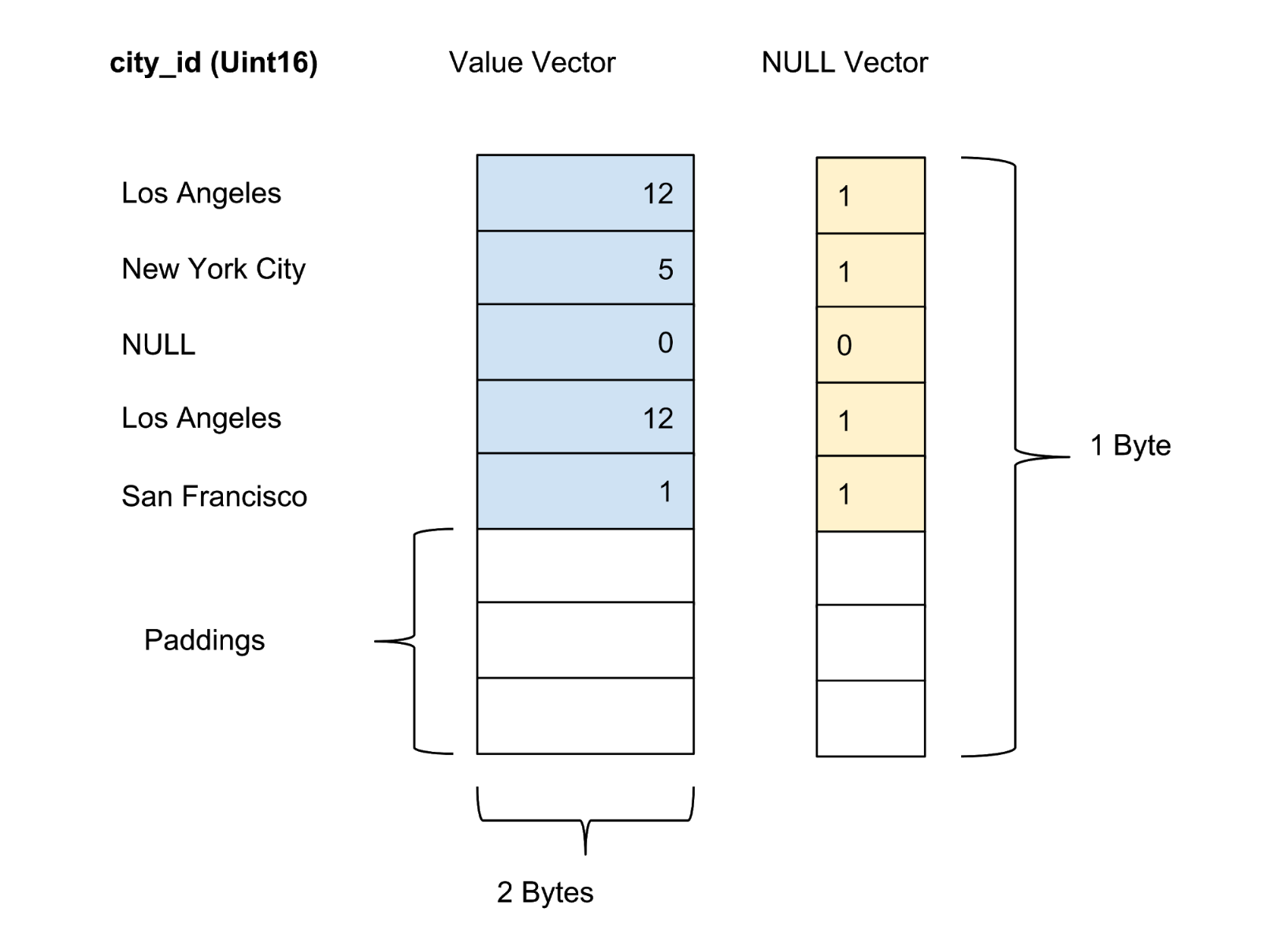
Рисунок 4. Мы храним значения (фактическое значение) и нулевые вектора (маркер достоверности) несжатых столбцов в таблице данных.
Архивное хранилище
AresDB также хранит законченные, отсортированные и сжатые столбчатые данные (векторы архивов) в архивном хранилище через таблицы фактов. Записи в архивном хранилище также распределяются по пакетам. В отличие от активных пакетов, архивный пакет хранит записи за день по всемирному координированному времени (UTC). Архивный пакет использует количество дней в качестве идентификатора пакета еще со времен Unix Epoch.
Записи хранятся в рассортированном виде в соответствии с заданным пользователем порядком сортировки столбцов. Как показано на рисунке 5 ниже, мы производим сортировку сначала по столбцу city_id, а затем по столбцу состояния:
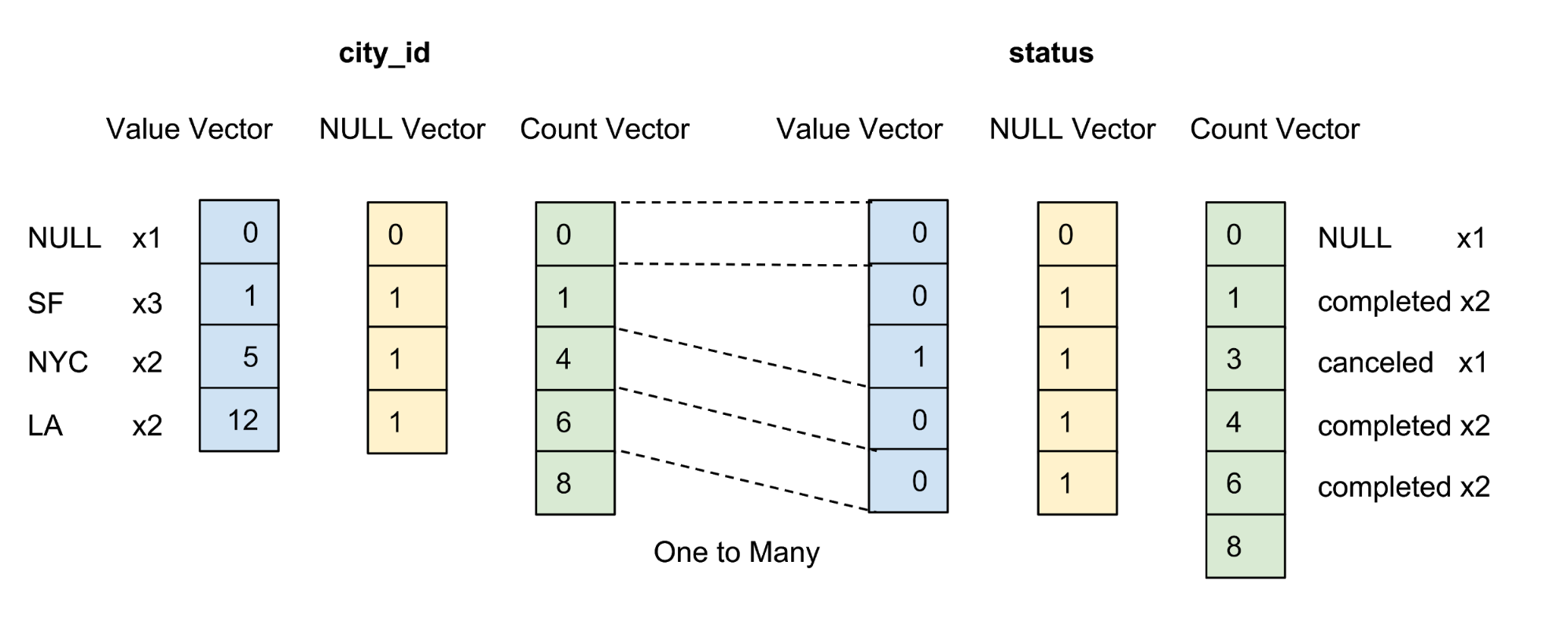
Рисунок 5. Мы сортируем все строки по city_id, затем по состоянию, после чего сжимаем каждый столбец путем группового кодирования. После сортировки и сжатия каждый столбец получит учетный вектор.
Цель настройки порядка сортировки столбцов пользователем заключается в следующем:
- Максимизация эффекта сжатия путем сортировки столбцов с небольшим количеством элементов в первую очередь. Максимальное сжатие повышает эффективность хранения (меньше байтов требуется для хранения данных) и эффективность запроса (меньше байтов передается между памятью CPU и памятью GPU).
- Обеспечение удобной предварительной фильтрации на основе диапазонов для общих эквивалентных фильтров, например city_id=12. Предварительная фильтрация позволяет минимизировать количество байтов, необходимое для передачи данных между памятью CPU и памятью GPU, что максимизирует эффективность запроса.
Столбец сжимается только в том случае, если он присутствует в заданном пользователем порядке сортировки. Мы не пытаемся сжимать столбцы с большим количеством элементов, поскольку экономию памяти это дает незначительную.
После сортировки данные для каждого квалифицированного столбца сжимаются с помощью определенного варианта группового кодирования. Помимо вектора значения и нулевого вектора мы вводим учетный вектор для повторного представления того же значения.
Прием данных в реальном времени с поддержкой функций обновления и вставки
Клиенты получают данные через HTTP API путем публикации пакета обновления. Пакет обновления является специальным упорядоченным двоичным форматом, который минимизирует использование пространства, сохраняя при этом произвольный доступ к данным.
Когда AresDB получает пакет обновления, он сначала записывает пакет обновления в журнал регистрации операций для восстановления. Когда в конец журнала регистрации событий добавляется пакет обновлений, AresDB идентифицирует и пропускает поздние записи в таблицах фактов для использования в активном хранилище. Запись считается «поздней», если время события расположено раньше архивного времени события отключения. В отношении записей, которые не считаются «поздними», AresDB использует индекс первичного ключа для определения местоположения пакета внутри активного хранилища, куда их нужно вставить. Как показано на рисунке 6 ниже, новые записи (не встречавшиеся ранее на базе значения первичного ключа) вставляются в пустое пространство, а существующие записи обновляются напрямую:
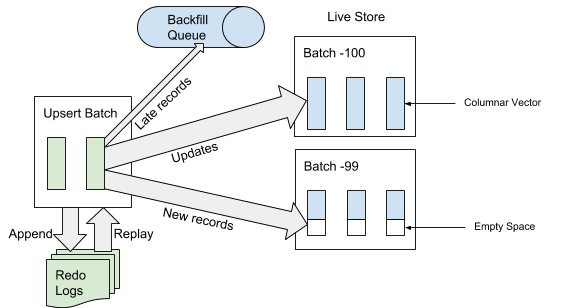
Рисунок 6. При получении данных, после добавления пакета обновления в журнал регистрации событий, «поздние» записи добавляются в обратную очередь, а прочие записи — в активное хранилище.
Архивирование
При получении данных записи либо добавляются/обновляются в активном хранилище, либо добавляются в обратную очередь, ожидающую помещения в архивное хранилище.
Мы периодически запускаем плановый процесс, обозначаемый как архивирование, в отношении записей активного хранилища для присоединения новых записей (записей, которые ранее никогда не архивировались) к архивному хранилищу. Процесс архивирования только обрабатывает записи в активном хранилище со временем события в диапазоне между старым временем отключения (время отключения с последнего процесса архивирования) и новым временем отключения (новое время отключения на основе параметра задержки архивирования в схеме таблицы).
Время события записей используется для определения того, в какой архивный пакет должны быть объединены записи при пакетировании архивных данных в ежедневные пакеты. Архивирование не требует дедупликации индекса значения первичного ключа при объединении, поскольку архивируются только записи в диапазоне между старым и новым временем отключения.
На рисунке 7 ниже представлен график согласно времени события определенной записи.
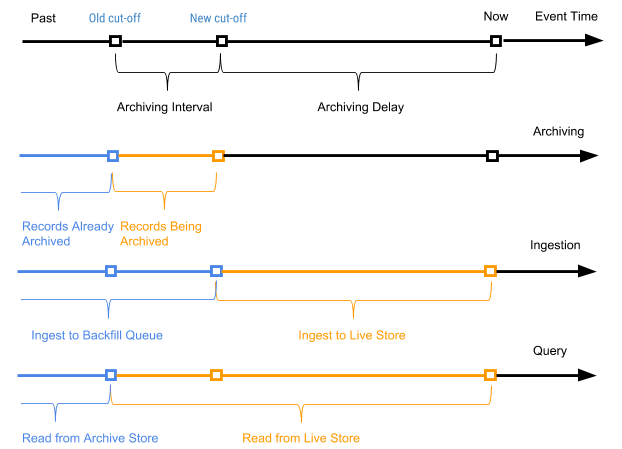
Рисунок 7. Мы используем время события и время отключения для определения записей как новых (активных) и старых (время события расположено раньше архивного времени события отключения).
В этом случае интервал архивирования представляет собой временной промежуток между двумя процессами архивирования, а задержка архивирования представляет собой период после времени события, но до момента возможного архивирования события. Оба параметра определяются в настройках схемы таблицы AresDB.
Обратное заполнение
Как показано на рисунке 7 выше, старые записи (время события которых расположено раньше архивного времени события отключения) для таблиц фактов добавляются в обратную очередь и в конечном итоге обрабатываются в рамках процесса обратного заполнения. Триггерами этого процесса также являются время или размер обратной очереди, если она достигает порогового уровня. По сравнению с процессом добавления данных в активное хранилище обратное заполнение является асинхронным и относительно более дорогостоящим с точки зрения ресурсов CPU и памяти. Обратное заполнение используется в следующих сценариях:
- Обработка случайных, очень поздно полученных данных
- Ручная фиксация исторических данных из восходящего потока данных
- Внесение исторических данных в недавно добавленные столбцы
В отличие от архивирования, процесс обратного заполнения является идемпотентным и требует дедупликации на основе значения первичного ключа. Заполняемые данные в конечном итоге будут видны для запросов.
Обратная очередь поддерживается в памяти с предварительно заданным размером, и при большой нагрузке обратного заполнения процесс будет заблокирован для клиента до очистки очереди путем запуска процесса обратного заполнения.
Обработка запроса
В текущем варианте реализации пользователю нужно использовать язык Ares Query Language (AQL), созданный Uber для выполнения запросов в AresDB. AQL — это эффективный язык для аналитических запросов по временным рядам и не следует стандартному синтаксису SQL типа «SELECT FROM WHERE GROUP BY», как другие схожие с SQL языки. Вместо этого AQL используется в структурированных полях и может входить в объекты JSON, YAML и Go. Например, вместо ВЫБРАТЬ/SELECT пункт(*) ИЗ/FROM ГРУППЫ поездок ПО/GROUP BY city_id, ГДЕ/WHERE статус = «завершено» И/AND request_at >= 1512000000, эквивалентный вариант AQL в JSON записывается следующим образом:
{
“table”: “trips”,
“dimensions”: [
{“sqlExpression”: “city_id”}
],
“measures”: [
{“sqlExpression”: “count(*)”}
],
;”> “rowFilters”: [
“status = ‘completed'”
],
“timeFilter”: {
“column”: “request_at”,
“from”: “2 days ago”
}
}В формате JSON AQL предлагает разработчикам информационной панели и системы принятия решений более удобный алгоритм программного запроса, чем SQL, позволяя им легко составлять запросы и манипулировать ими с помощью кода, не беспокоясь о таких вещах, как внедрение SQL. Он выступает в качестве универсального формата запросов для типичных архитектур веб-браузеров, внешних и внутренних серверов вплоть до базы данных (AresDB). Кроме того, AQL предоставляет удобный синтаксический прием для фильтрации по времени и пакетирования с поддержкой собственной временной зоны. Кроме того, язык поддерживает ряд функций, например неявные подзапросы, для предотвращения распространенных ошибок в запросах и облегчает процессы анализа и перезаписи запросов для разработчиков внутреннего интерфейса.
Несмотря на множество преимуществ, которые предлагает AQL, мы прекрасно понимаем, что большинство инженеров лучше знакомо с SQL. Предоставление интерфейса SQL для выполнения запросов является одним из следующих шагов, которые мы рассмотрим в рамках работы по улучшению взаимодействия с пользователями AresDB.
Схема выполнения запроса AQL представлена на рисунке 8 ниже:
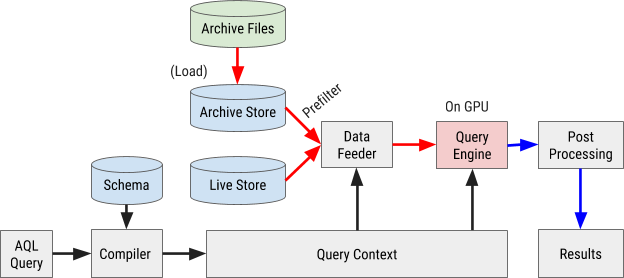
Рисунок 8. В схеме выполнения запросов AresDB используется наш собственный язык запросов AQL для быстрой и эффективной обработки и извлечения данных.
Компиляция запросов
Запрос AQL компилируется во внутренний контекст запроса. Выражения в фильтрах, измерениях и параметрах анализируются в абстрактных синтаксических деревьях (AST) для последующей обработки через графический процессор (GPU).
Загрузка данных
В AresDB используются предварительные фильтры для дешевой фильтрации архивных данных перед их отправкой в GPU для параллельной обработки. Поскольку архивные данные сортируются в соответствии с настроенным порядком столбцов, некоторые фильтры могут использовать этот порядок сортировки и метод двоичного поиска для установления соответствующего диапазона соответствия. В частности, эквивалентные фильтры для всех изначально отсортированных Х столбцов и дополнительный фильтр диапазона для отсортированных столбцов X+1 могут использоваться в качестве предварительных фильтров, как показано на рисунке 9 ниже.

Рисунок 9. AresDB производит предварительную фильтрацию данных столбцов перед их отправкой в GPU для обработки.
После предварительной фильтрации только зеленые значения (отвечающие условию фильтра) должны направляться в GPU для параллельной обработки. Входные данные загружаются в GPU и обрабатываются по одному пакету за раз. Сюда относятся как активные пакеты, так и архивные пакеты.
В AresDB используются потоки CUDA для конвейерной загрузки и обработки данных. По каждому запросу поочередно применяются два потока для обработки в два перекрывающихся этапа. На рисунке 10 ниже мы предлагаем график, иллюстрирующий этот процесс.
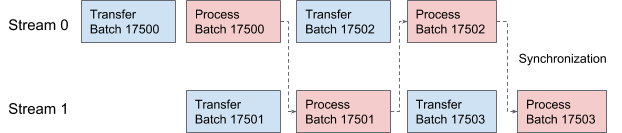
Рисунок 10. В AresDB два потока CUDA поочередно занимаются передачей и обработкой данных.
Выполнение запроса
Для простоты в AresDB используется библиотека Thrust для реализации процедур выполнения запроса, которая предлагает блоки точно настроенного параллельного алгоритма для быстрой реализации в текущем инструменте запросов.
В Thrust входные и выходные векторные данные оцениваются с помощью случайных итераторов доступа. Каждый поток GPU ищет входные итераторы в своей рабочей позиции, считывает значения и выполняет вычисления, а затем записывает результат в соответствующую позицию в выходном итераторе.
Для вычисления выражений AresDB следует модели «один оператор на одно ядро» (OOPK).
На рисунке 11 ниже эта процедура демонстрируется на примере AST, сгенерированного из выражения размерности request_at – request_at % 86400 на этапе компиляции запроса:
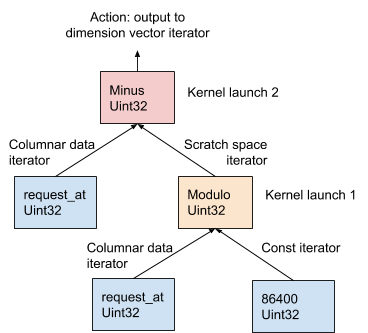
Рисунок 11. AresDB использует модель OOPK для вычисления выражений.
В модели OOPK механизм запросов AresDB обходит каждую конечную ноду дерева AST и возвращает итератор для исходной ноды. Если корневая нода также является конечной, действие корня выполняется непосредственно на входном итераторе.
Для каждой некорневой неконцевой ноды (операция по модулю в этом примере) временный вектор рабочего пространства выделяется для хранения промежуточного результата, полученного из выражения request_at% 86400. С помощью Thrust запускается функция ядра для вычисления результата по этому оператору в GPU. Результаты хранятся в итераторе рабочего пространства.
Для корневой ноды функция ядра запускается таким же образом, как и для некорневой, неконечной ноды. Различные выходные действия выполняются на основе типа выражения, что подробно описано ниже:
- Фильтрация для сокращения количества элементов входных векторов
- Запись выходных данных измерений в векторе измерений для последующего объединения данных
- Запись выходных данных параметров в векторе параметров для последующего объединения данных
После вычисления выражения выполняются сортировка и преобразование для окончательного объединения данных. В операциях сортировки и преобразования мы используем значения вектора измерений в качестве ключевых значений сортировки и преобразования, а значения вектора параметров — в качестве значений для объединения данных. Таким образом, строки с аналогичными значениями измерений группируются и объединяются. На рисунке 12 ниже показан этот процесс сортировки и преобразования.
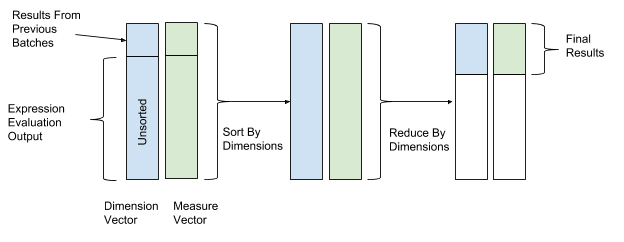
Рисунок 12. После вычисления выражения AresDB сортирует и преобразует данные по ключевым значениям векторов измерений (ключевое значение) и параметров (значение).
AresDB также поддерживает следующие продвинутые функции запроса:
- Join: в настоящее время AresDB поддерживает опцию соединения хешированием между таблицей фактов и таблицей измерений
- Оценка количества элементов Hyperloglog: В AresDB используется алгоритм Hyperloglog
- Geo Intersect: в настоящее время AresDB поддерживает только взаимосвязанные операции между GeoPoint и GeoShape
Управление ресурсами
Будучи базой данных на основе внутренней памяти, AresDB должен управлять следующими типами использования памяти:
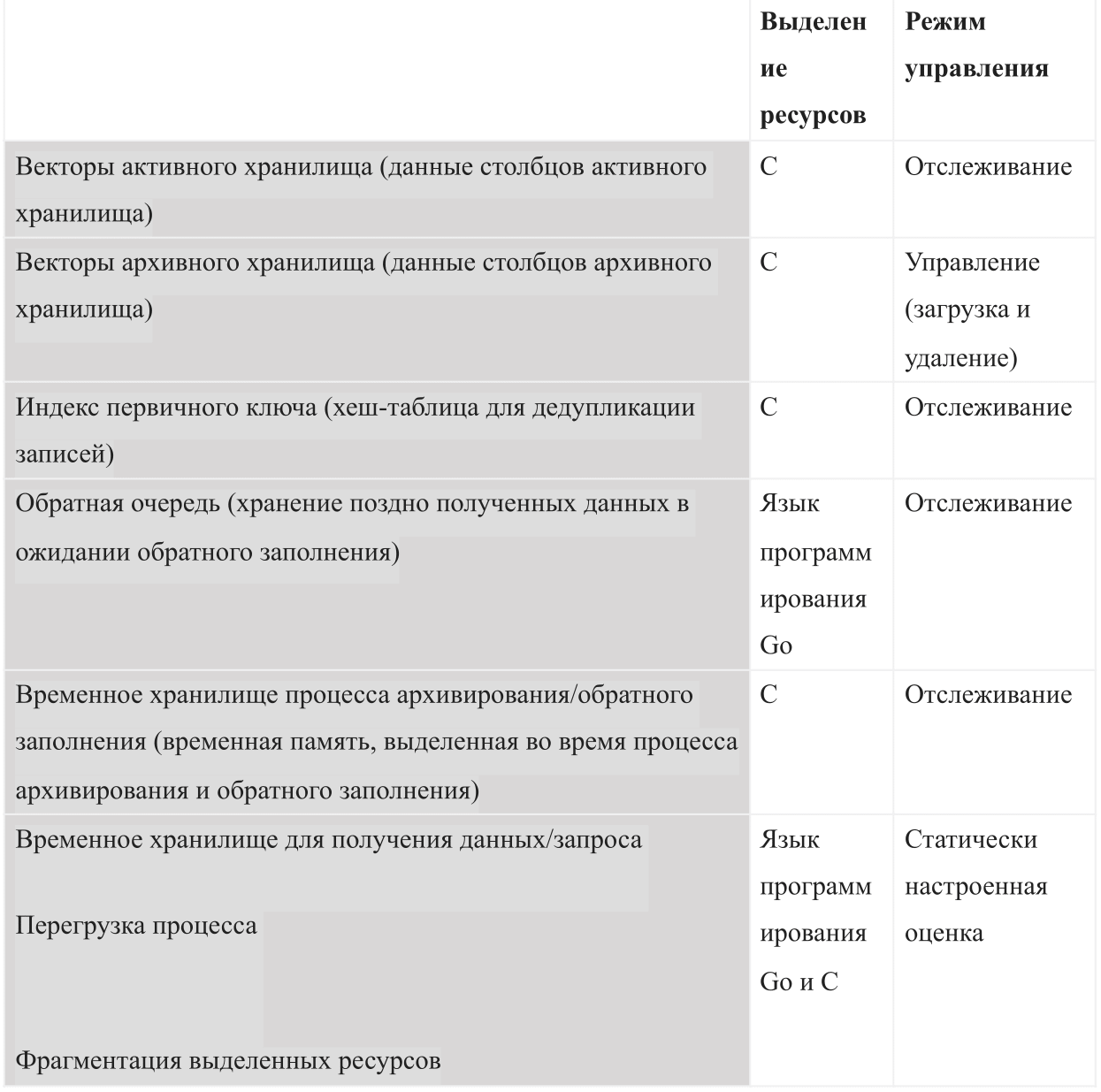
При запуске AresDB в работу он использует настроенный общий бюджет памяти. Бюджет делится на все шесть типов памяти и также должен оставлять достаточно пространства для операционной системы и других процессов. Этот бюджет также включает статически настроенную оценку перегрузки, активное хранилище данных, отслеживаемое сервером, и архивные данные, которые сервер может решить загрузить и удалить в зависимости от оставшегося бюджета памяти.
На рисунке 13 ниже представлена модель памяти хоста AresDB.
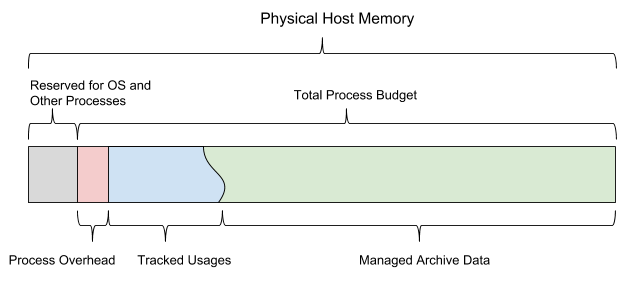
Рисунок 13. AresDB управляет собственным использованием памяти, чтобы оно не превышало настроенный общий бюджет процесса.
AresDB позволяет пользователям настроить дни предварительной загрузки и приоритеты на уровне столбцов для таблиц фактов и производит предварительную загрузку архивных данных только в дни предварительной загрузки. Данные, не загруженные предварительно, загружаются в память из диска по требованию. При заполнении AresDB также удаляет архивные данные из памяти хоста. Принципы удаления AresDB опираются на следующие параметры: количество дней предварительной загрузки, приоритеты столбцов, день составления пакета и размер столбца.
AresDB также управляет несколькими устройствами GPU и моделирует ресурсы устройства как потоки GPU и память устройства, отслеживая использование памяти GPU для обработки запросов. AresDB управляет устройствами GPU через менеджер устройств, который моделирует ресурсы устройства GPU в двух измерениях (потоки GPU и память устройства) и отслеживает использование памяти при обработке запросов. После компиляции запроса AresDB позволяет пользователям оценить объем ресурсов, необходимых для выполнения запроса. Требования по памяти устройства должны быть выполнены до того, как будет разрешен запрос; если в данный момент на любом устройстве недостаточно памяти, запрос должен ожидать выполнения. В настоящее время AresDB может выполнять один или несколько запросов на одном устройстве GPU одновременно, если устройство отвечает всем требованиям по ресурсам.
В текущем варианте реализации AresDB не кеширует входные данные в памяти устройства для повторного использования в нескольких запросах. AresDB нацелен на поддержку запросов к наборам данных, которые постоянно обновляются в режиме реального времени и слабо поддаются корректному кешированию. В будущих версиях AresDB мы намерены реализовать функции кеширования данных в памяти GPU, что поможет оптимизировать производительность запросов.
Пример использования: обзорная информационная панель Uber
В Uber мы используем AresDB для создания информационных панелей для получения бизнес-информации в режиме реального времени. AresDB отвечает за хранение первичных событий с постоянными обновлениями и вычисление критических метрик для них за доли секунды благодаря ресурсам GPU при низких затратах, таким образом, пользователи могут использовать информационные панели в интерактивном режиме. Например, анонимизированные данные о поездках, которые имеют длительный срок действия в хранилище данных, обновляются несколькими службами, включая нашу диспетчерскую систему, системы оплаты и оценки. Для эффективного использования данных о поездках пользователи разделяют и разбивают данные по разным измерениям, чтобы получить представление о решениях в реальном времени.
При использовании AresDB сводная информационная панель Uber — это широко распространенная информационная панель анализа, которая применяется командами внутри компании для получения соответствующих произведений метрик и реагирования в реальном времени для улучшения взаимодействия с пользователями.
Рисунок 14. В почасовом режиме обзорная информационная панель Uber использует AresDB для просмотра аналитики данных в реальном времени в течение определенных периодов.
Чтобы создать макет информационной панели, приведенной выше, мы смоделировали следующие таблицы:
Поездки (таблица фактов)

Города (таблица измерений)

Схемы таблиц в AresDB
Для создания двух моделируемых таблиц, описанных выше, сначала нам нужно создать таблицы в AresDB по следующим схемам:

Как описано в схеме, таблицы поездок создаются в качестве таблиц фактов, которые отражают события поездок, происходящие в реальном времени, а таблицы городов создаются в качестве таблиц измерений, в которых хранится информация о фактических городах.
После создания таблиц пользователи могут использовать клиентскую библиотеку AresDB для загрузки данных из шины событий, например Apache Kafka, или с платформ потоковой или пакетной обработки, например Apache Flink или Apache Spark.
Примеры запросов для AresDB
В пробных информационных панелях мы выбираем в качестве примера две метрики, «общий тариф на поездку» и «активные водители». В информационной панели пользователи могут отфильтровать город по метрикам, например Сан-Франциско. Для отображения временных рядов по этим двум метрикам за последние 24 часа в информационных панелях можно запустить следующие запросы AQL:

Пример результатов по запросу:
Результатом приведенных выше пробных запросов будут следующие временные ряды, которые можно легко представить на графиках временных рядов, как показано ниже.

В приведенном выше примере мы продемонстрировали, как можно использовать AresDB для приема первичных событий, происходящих в режиме реального времени, в течение нескольких секунд и немедленного выполнения произвольных пользовательских запросов данных для вычисления метрик за доли секунды. AresDB помогает инженерам в создании средств обработки данных, которые определяют критически важные для бизнеса метрики, что требует понимания человеческих или автоматических решений в реальном времени.
Следующие шаги
AresDB широко используется в Uber для поддержки информационных панелей анализа данных в реальном времени, что позволяет принимать соответствующие решения на основе данных по множеству аспектов бизнеса. Открывая исходный код этого инструмента, мы надеемся, что другие представители сообщества смогут использовать AresDB в своих аналитических целях.
В будущем мы намерены добавить в проект следующие функции:
- Распределенное проектирование: мы работаем над созданием функционала распределенного проектирования в AresDB, включая репликацию, управление разделением и управление схемами, для повышения уровня масштабируемости и снижения эксплуатационных расходов.
- Поддержка и инструментарий разработчика: с момента открытия исходного кода AresDB в ноябре 2018 года мы работали над созданием более интуитивного инструментария, реорганизацией структур кода и расширением документации для улучшения взаимодействия с пользователем, что позволит разработчикам быстро интегрировать AresDB в свою аналитическую систему.
- Расширенный набор функций: мы также планируем расширить набор функций запроса, включив в него такие функции, как оконные функции и функции объединения с помощью вложенных циклов, что позволит инструменту поддерживать больше вариантов использования.
- Оптимизация механизма запроса: мы также собираемся заниматься разработкой более эффективных способов оптимизации производительности запросов, например на основе низкоуровневой виртуальной машины (LLVM) и кеширования памяти GPU.
AresDB имеет открытый исходный код по лицензии Apache. Мы приглашаем вас попробовать AresDB и присоединиться к нашему сообществу.
Если вас интересует разработка технологий крупномасштабного анализа данных в реальном времени, подумайте о подаче заявки на работу в нашей команде.
Благодарности
Особая благодарность Кейт Чанг (Kate Zhang), Дженнифер Андерсон (Jennifer Anderson), Нихилу Джоши (Nikhil Joshi), Аби Куну (Abhi Khune), Шене Цзи (Shengyue Ji), Чинмэю Сомэну (Chinmay Soman), Сяну Фу (Xiang Fu), Дэвиду Чену (David Chen) и Ли Нингу (Li Ning) за то, что обеспечили невероятный успех этого проекта!
