
Часть 1/3 тут.
Часть 2/3 тут.
Всем привет! А вот и третья часть руководства «Kubernetes на «голом железе»! Я уделю внимание мониторингу кластера и сбору логов, также мы запустим тестовое приложение для использования предварительно настроенных компонентов кластера. Затем проведем несколько стресс-тестов и проверим стабильность этой кластерной схемы.
Наиболее популярным инструментом, который сообщество Kubernetes предлагает для обеспечения веб-интерфейса и получения статистических данных о кластере, является Kubernetes Dashboard. Фактически он все еще на стадии разработки, но даже сейчас может предоставить некоторые дополнительные данные для устранения неполадок приложений и управления ресурсами кластера.
Тема — отчасти спорная. Правда ли для управления кластером нужен какой-либо веб-интерфейс, или достаточно использовать консольный инструмент kubectl? Что ж, иногда упомянутые варианты дополняют друг друга.
Давайте развернем наш Kubernetes Dashboard и посмотрим. При стандартном деплое эта панель мониторинга запустится только по адресу локального хоста. Таким образом, для раскрытия надо использовать команду kubectl proxy, но она все еще доступна только на вашем локальном управляющем устройстве kubectl. Неплохо с точки зрения безопасности, но я хочу иметь доступ в браузере, за пределами кластера, и готов пойти на определенный риск (все равно ведь используется ssl с эффективным токеном).
Чтобы применить мой способ, нужно немного изменить стандартный файл деплоя в разделе сервиса. Для раскрытия этой панели мониторинга на открытом адресе используем наш балансировщик нагрузки.
Входим в систему машины с настроенной утилитой kubectl и создаем:
control# vi kube-dashboard.yaml
# Copyright 2017 The Kubernetes Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ------------------- Dashboard Secret ------------------- #
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-certs
namespace: kube-system
type: Opaque
---
# ------------------- Dashboard Service Account ------------------- #
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
---
# ------------------- Dashboard Role & Role Binding ------------------- #
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: kubernetes-dashboard-minimal
namespace: kube-system
rules:
# Allow Dashboard to create 'kubernetes-dashboard-key-holder' secret.
- apiGroups: [""]
resources: ["secrets"]
verbs: ["create"]
# Allow Dashboard to create 'kubernetes-dashboard-settings' config map.
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["create"]
# Allow Dashboard to get, update and delete Dashboard exclusive secrets.
- apiGroups: [""]
resources: ["secrets"]
resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs"]
verbs: ["get", "update", "delete"]
# Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map.
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["kubernetes-dashboard-settings"]
verbs: ["get", "update"]
# Allow Dashboard to get metrics from heapster.
- apiGroups: [""]
resources: ["services"]
resourceNames: ["heapster"]
verbs: ["proxy"]
- apiGroups: [""]
resources: ["services/proxy"]
resourceNames: ["heapster", "http:heapster:", "https:heapster:"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: kubernetes-dashboard-minimal
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kubernetes-dashboard-minimal
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kube-system
---
# ------------------- Dashboard Deployment ------------------- #
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: kubernetes-dashboard
template:
metadata:
labels:
k8s-app: kubernetes-dashboard
spec:
containers:
- name: kubernetes-dashboard
image: k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.1
ports:
- containerPort: 8443
protocol: TCP
args:
- --auto-generate-certificates
# Uncomment the following line to manually specify Kubernetes API server Host
# If not specified, Dashboard will attempt to auto discover the API server and connect
# to it. Uncomment only if the default does not work.
# - --apiserver-host=http://my-address:port
volumeMounts:
- name: kubernetes-dashboard-certs
mountPath: /certs
# Create on-disk volume to store exec logs
- mountPath: /tmp
name: tmp-volume
livenessProbe:
httpGet:
scheme: HTTPS
path: /
port: 8443
initialDelaySeconds: 30
timeoutSeconds: 30
volumes:
- name: kubernetes-dashboard-certs
secret:
secretName: kubernetes-dashboard-certs
- name: tmp-volume
emptyDir: {}
serviceAccountName: kubernetes-dashboard
# Comment the following tolerations if Dashboard must not be deployed on master
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
---
# ------------------- Dashboard Service ------------------- #
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: LoadBalancer
ports:
- port: 443
targetPort: 8443
selector:
k8s-app: kubernetes-dashboardЗатем запускаем:
control# kubectl create -f kube-dashboard.yaml
control# kubectl get svc --namespace=kube-system
kubernetes-dashboard LoadBalancer 10.96.164.141 192.168.0.240 443:31262/TCP 8hОтлично, как видите, наш БН добавил IP 192.168.0.240 для этого сервиса. Теперь попробуйте открыть https://192.168.0.240 для просмотра Kubernetes Dashboard.
Чтобы получить доступ, есть 2 способа: использовать файл admin.conf с нашей мастер-ноды, которую мы использовали ранее, когда настраивали kubectl, или создать специальную служебную учетную запись с токеном безопасности.
Давайте создадим пользователя-администратора:
control# vi kube-dashboard-admin.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kube-system
control# kubectl create -f kube-dashboard-admin.yaml
serviceaccount/admin-user created
clusterrolebinding.rbac.authorization.k8s.io/admin-user createdТеперь нужен токен для входа в систему:
control# kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')
Name: admin-user-token-vfh66
Namespace: kube-system
Labels: <none>
Annotations: kubernetes.io/service-account.name: admin-user
kubernetes.io/service-account.uid: 3775471a-3620-11e9-9800-763fc8adcb06
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1025 bytes
namespace: 11 bytes
token: erJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwna3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJr
dWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VmLXRva2VuLXZmaDY2Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZ
XJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIzNzc1NDcxYS0zNjIwLTExZTktOTgwMC03Nj
NmYzhhZGNiMDYiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.JICASwxAJHFX8mLoSikJU1tbij4Kq2pneqAt6QCcGUizFLeSqr2R5x339ZR8W4
9cIsbZ7hbhFXCATQcVuWnWXe2dgXP5KE8ZdW9uvq96rm_JvsZz0RZO03UFRf8Exsss6GLeRJ5uNJNCAr8No5pmRMJo-_4BKW4OFDFxvSDSS_ZJaLMqJ0LNpwH1Z09SfD8TNW7VZqax4zuTSMX_yVS
ts40nzh4-_IxDZ1i7imnNSYPQa_Oq9ieJ56Q-xuOiGu9C3Hs3NmhwV8MNAcniVEzoDyFmx4z9YYcFPCDIoerPfSJIMFIWXcNlUTPSMRA-KfjSb_KYAErVfNctwOVglgCISAСкопируйте токен и вставьте его в поле токена на экране входа.
После входа в систему вы сможете чуть глубже изучить кластер — мне нравится этот инструмент.
Следующий шаг на пути углубления системы мониторинга нашего кластера — установка heapster.
Heapster позволяет мониторить контейнерный кластер и анализировать производительность для Kubernetes (версия v1.0.6 и выше). Он предлагает соответствующие платформы.
Этот инструмент предлагает статистику использования кластера через консоль, а также добавит больше информации о ресурсах нод и подов на панель Kubernetes Dashboard.
С его установкой на «голое железо» есть небольшая сложность, и мне потребовалось провести некоторое расследование: почему инструмент не работает в исходном варианте, — но решение я нашел.
Итак, давайте продолжим и задеплоим это дополнение:
control# vi heapster.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: heapster
namespace: kube-system
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: heapster
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
task: monitoring
k8s-app: heapster
spec:
serviceAccountName: heapster
containers:
- name: heapster
image: gcr.io/google_containers/heapster-amd64:v1.4.2
imagePullPolicy: IfNotPresent
command:
- /heapster
- --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true
---
apiVersion: v1
kind: Service
metadata:
labels:
task: monitoring
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: Heapster
name: heapster
namespace: kube-system
spec:
ports:
- port: 80
targetPort: 8082
selector:
k8s-app: heapster
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: heapster
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:heapster
subjects:
- kind: ServiceAccount
name: heapster
namespace: kube-systemЭто наиболее распространенный стандартный файл деплоя от сообщества Heapster, только с небольшим отличием: чтобы он работал на нашем кластере, строка «source =» в деплое heapster изменена следующим образом:
--source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=trueВ этом описании вы найдете все эти опции. Я изменил порт kubelet на 10250 и отключил проверку сертификата ssl (с ним была небольшая проблема).
Также нам нужно добавить разрешения для получения статистики нод в роль Heapster RBAC; добавьте эти несколько строк в конце роли:
control# kubectl edit clusterrole system:heapster
......
...
- apiGroups:
- ""
resources:
- nodes/stats
verbs:
- getВ итоге ваша роль RBAC должна иметь следующий вид:
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
creationTimestamp: "2019-02-22T18:58:32Z"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:heapster
resourceVersion: "6799431"
selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/system%3Aheapster
uid: d99065b5-36d3-11e9-a7e6-763fc8adcb06
rules:
- apiGroups:
- ""
resources:
- events
- namespaces
- nodes
- pods
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- deployments
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- nodes/stats
verbs:
- getХорошо, теперь выполним команду, чтобы удостовериться в успешном запуске деплоя heapster.
control# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
kube-master1 183m 9% 1161Mi 60%
kube-master2 235m 11% 1130Mi 59%
kube-worker1 189m 4% 1216Mi 41%
kube-worker2 218m 5% 1290Mi 44%
kube-worker3 181m 4% 1305Mi 44%Отлично, если вы получили какие-то данные на выходе, значит, все сделано правильно. Снова зайдем на нашу страницу панели мониторинга и проверим новые графики, которые теперь доступны.
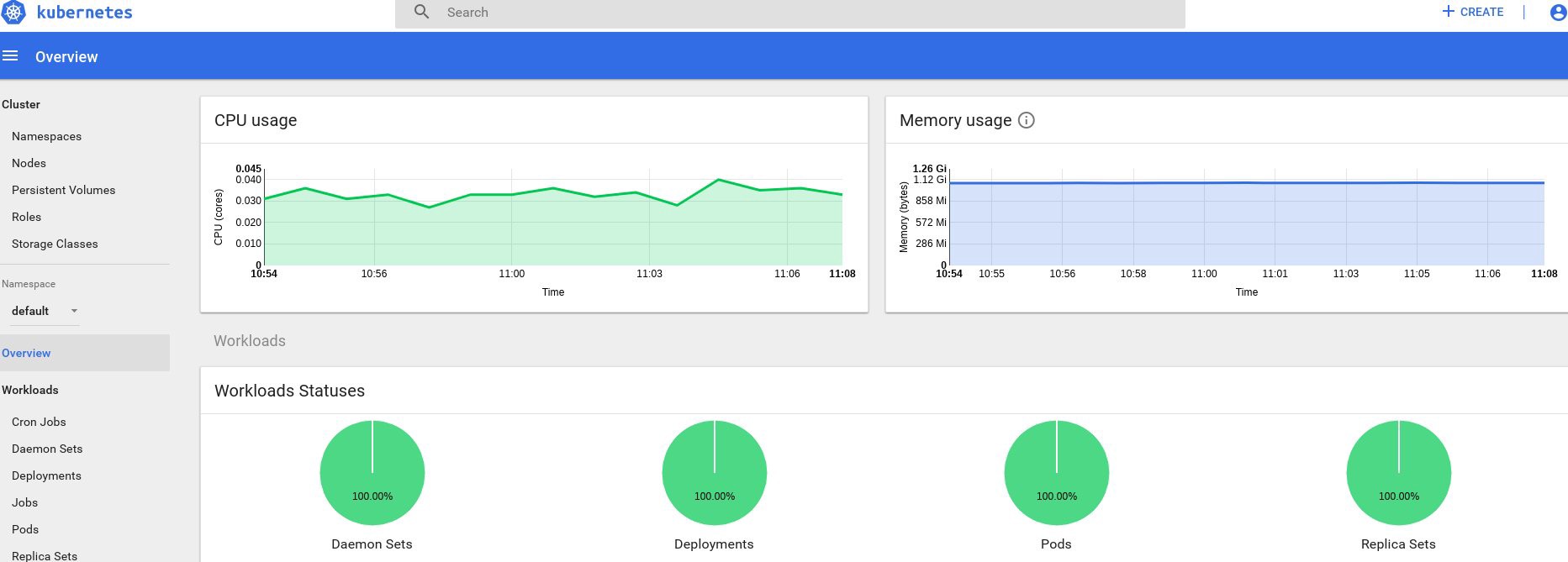

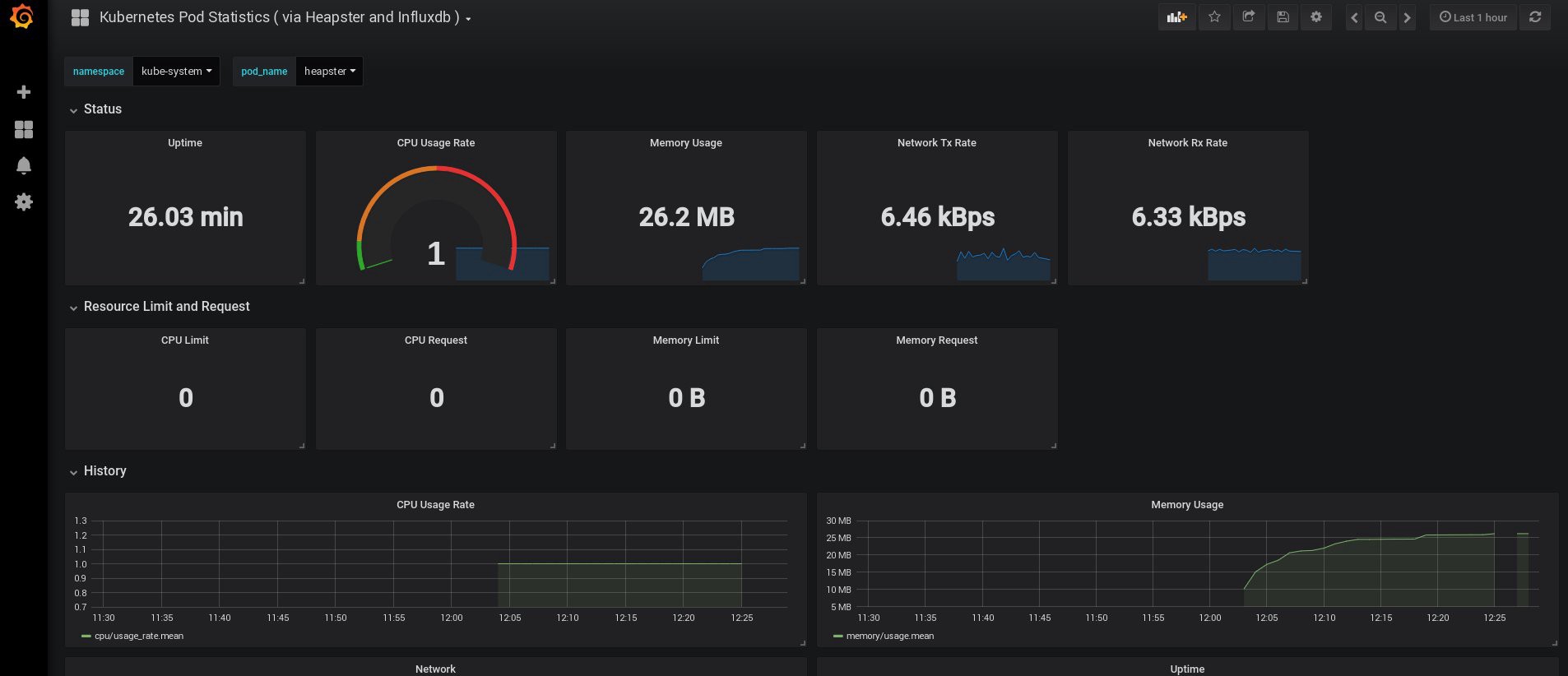
С этого момента мы можем также отслеживать реальное использование ресурсов для нод кластера, подов и т. д.
Если этого недостаточно, можно еще немного усовершенствовать статистику, добавив InfluxDB+Grafana. Это добавит возможность рисовать собственные панели Grafana.
Мы будем использовать эту версию установки InfluxDB+Grafana со страницы Heapster Git, но, как обычно, внесем поправочки. Поскольку ранее мы уже настроили деплой heapster, нам нужно только добавить Grafana и InfluxDB, а затем изменить существующий деплой heapster, чтобы он также заносил метрики в Influx.
Хорошо, давайте создадим деплои InfluxDB и Grafana:
control# vi influxdb.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: monitoring-influxdb
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
task: monitoring
k8s-app: influxdb
spec:
containers:
- name: influxdb
image: k8s.gcr.io/heapster-influxdb-amd64:v1.5.2
volumeMounts:
- mountPath: /data
name: influxdb-storage
volumes:
- name: influxdb-storage
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
labels:
task: monitoring
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-influxdb
name: monitoring-influxdb
namespace: kube-system
spec:
ports:
- port: 8086
targetPort: 8086
selector:
k8s-app: influxdbДальше — Grafana, и не забудьте изменить настройку сервиса, чтобы включить балансировщик нагрузки MetaLB и получить внешний IP-адрес для сервиса Grafana.
control# vi grafana.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
containers:
- name: grafana
image: k8s.gcr.io/heapster-grafana-amd64:v5.0.4
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certificates
readOnly: true
- mountPath: /var
name: grafana-storage
env:
- name: INFLUXDB_HOST
value: monitoring-influxdb
- name: GF_SERVER_HTTP_PORT
value: "3000"
# The following env variables are required to make Grafana accessible via
# the kubernetes api-server proxy. On production clusters, we recommend
# removing these env variables, setup auth for grafana, and expose the grafana
# service using a LoadBalancer or a public IP.
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
# If you're only using the API Server proxy, set this value instead:
# value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
value: /
volumes:
- name: ca-certificates
hostPath:
path: /etc/ssl/certs
- name: grafana-storage
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
labels:
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-grafana
name: monitoring-grafana
namespace: kube-system
spec:
# In a production setup, we recommend accessing Grafana through an external Loadbalancer
# or through a public IP.
# type: LoadBalancer
# You could also use NodePort to expose the service at a randomly-generated port
# type: NodePort
type: LoadBalancer
ports:
- port: 80
targetPort: 3000
selector:
k8s-app: grafanaИ создайте их:
control# kubectl create -f influxdb.yaml
deployment.extensions/monitoring-influxdb created
service/monitoring-influxdb created
control# kubectl create -f grafana.yaml
deployment.extensions/monitoring-grafana created
service/monitoring-grafana createdПришло время изменить деплой heapster и добавить в него подключение InfluxDB; нужно добавить всего одну строку:
- --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086Отредактируйте деплой heapster:
control# kubectl get deployments --namespace=kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
coredns 2/2 2 2 49d
heapster 1/1 1 1 2d12h
kubernetes-dashboard 1/1 1 1 3d21h
monitoring-grafana 1/1 1 1 115s
monitoring-influxdb 1/1 1 1 2m18s
control# kubectl edit deployment heapster --namespace=kube-system
... beginning bla bla bla
spec:
containers:
- command:
- /heapster
- --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true
- --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086
image: gcr.io/google_containers/heapster-amd64:v1.4.2
imagePullPolicy: IfNotPresent
.... end Теперь найдем внешний IP-адрес сервиса Grafana и войдем в систему внутри него:
control# kubectl get svc --namespace=kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
..... some other services here
monitoring-grafana LoadBalancer 10.98.111.200 192.168.0.241 80:32148/TCP 18mОткройте http://192.168.0.241 в браузере, в первый раз используйте учетные данные admin/admin:

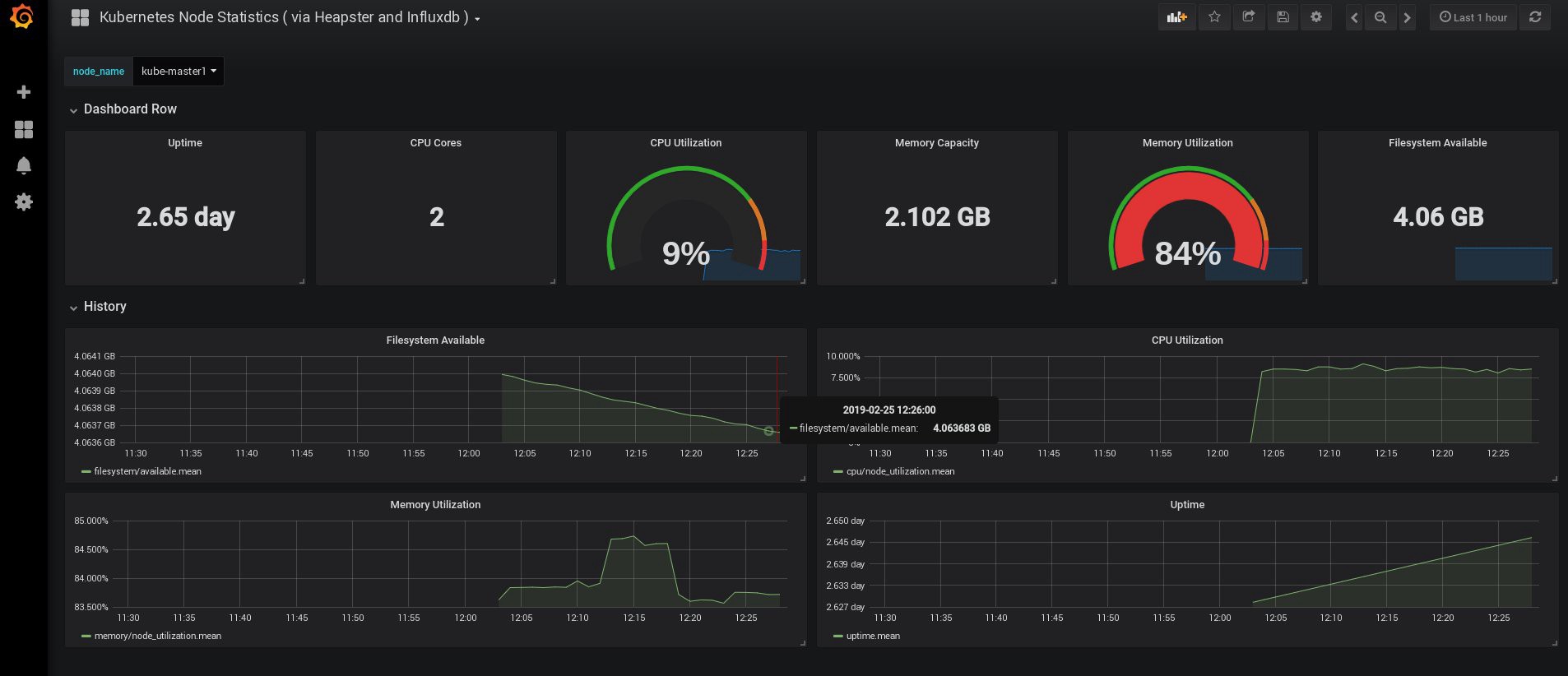
Когда я вошел в систему, моя Grafana была пуста, но, к счастью, мы можем получить все необходимые панели мониторинга с grafana.com. Нужно импортировать панели № 3649 и 3646. При импорте выберите правильный источник данных.
После этого отслеживайте использование ресурсов нод и подов и, конечно, создавайте собственные уникальные панели мониторинга.
Хорошо, на этом пока что закончим с мониторингом; следующие элементы, которые могут нам потребоваться, — это логи хранения наших приложений и кластера. Существует несколько способов для реализации этого, и все они описаны в документации Kubernetes. Исходя из собственного опыта, я предпочитаю использовать внешние установки сервисов Elasticsearch и Kibana, а также только агенты регистрации, которые запускаются на каждой рабочей ноде Kubernetes. Это защитит кластер от перегрузок, связанных с большим количеством логов и другими проблемами, и позволит получать логи, даже если кластер станет совсем полностью нефункциональным.
Наиболее популярный стек сбора логов для поклонников Kubernetes — это Elasticsearch, Fluentd и Kibana (стек EFK). В данном примере мы запустим Elasticsearch и Kibana на внешней ноде (можете использовать и существующий стек ELK), а также Fluentd внутри нашего кластера в качестве daemonset для каждой ноды как агент сбора логов.
Я пропущу часть о создании VM с установками Elasticsearch и Kibana; это достаточно популярная тема, так что вы сможете найти много материалов о том, как лучше всего это сделать. Например, в моей же статье. Просто удалите фрагмент конфигурации logstash из файла docker-compose.yml, а также удалите 127.0.0.1 из раздела портов elasticsearch.
После этого у вас должен быть рабочий elasticsearch, подключенный к порту VM-IP:9200. Для дополнительной защиты настройте login:pass или ключи безопасности между fluentd и elasticsearch. Однако я часто защищаю их просто с помощью правил iptables.
Все, что осталось сделать, — это создать fluentd daemonset в Kubernetes и указать внешний адрес elasticsearch node:port в конфигурации.
Используем официальное дополнение Kubernetes с конфигурацией yaml отсюда, с небольшими модификациями:
control# vi fluentd-es-ds.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: kube-system
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: kube-system
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-es-v2.4.0
namespace: kube-system
labels:
k8s-app: fluentd-es
version: v2.4.0
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: fluentd-es
version: v2.4.0
template:
metadata:
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
version: v2.4.0
# This annotation ensures that fluentd does not get evicted if the node
# supports critical pod annotation based priority scheme.
# Note that this does not guarantee admission on the nodes (#40573).
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
seccomp.security.alpha.kubernetes.io/pod: 'docker/default'
spec:
priorityClassName: system-node-critical
serviceAccountName: fluentd-es
containers:
- name: fluentd-es
image: k8s.gcr.io/fluentd-elasticsearch:v2.4.0
env:
- name: FLUENTD_ARGS
value: --no-supervisor -q
resources:
limits:
memory: 500Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: config-volume
mountPath: /etc/fluent/config.d
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: config-volume
configMap:
name: fluentd-es-config-v0.2.0Затем произведем определенную конфигурацию fluentd:
control# vi fluentd-es-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-es-config-v0.2.0
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
containers.input.conf: |- @id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
tag raw.kubernetes.*
read_from_head true
<parse>
@type multi_format
<pattern>
format json
time_key time
time_format %Y-%m-%dT%H:%M:%S.%NZ
</pattern>
<pattern>
format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/
time_format %Y-%m-%dT%H:%M:%S.%N%:z
</pattern>
</parse># Detect exceptions in the log output and forward them as one log entry.
<match raw.kubernetes.**>
@id raw.kubernetes
@type detect_exceptions
remove_tag_prefix raw
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
# Concatenate multi-line logs
<filter **>
@id filter_concat
@type concat
key message
multiline_end_regexp /\n$/
separator ""
</filter>
# Enriches records with Kubernetes metadata
<filter kubernetes.**>
@id filter_kubernetes_metadata
@type kubernetes_metadata
</filter>
# Fixes json fields in Elasticsearch
<filter kubernetes.**>
@id filter_parser
@type parser
key_name log
reserve_data true
remove_key_name_field true
<parse>
@type multi_format
<pattern>
format json
</pattern>
<pattern>
format none
</pattern>
</parse>
</filter>
output.conf: |-
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
type_name _doc
include_tag_key true
host 192.168.1.253
port 9200
logstash_format true
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
</match>Конфигурация элементарная, но ее вполне достаточно для быстрого запуска; она соберет логи системы и приложений. Если нужно что-то более сложное, можете ознакомиться с официальной документацией о плагинах fluentd и конфигурациях Kubernetes.
Теперь давайте создадим fluentd daemonset в нашем кластере:
control# kubectl create -f fluentd-es-ds.yaml
serviceaccount/fluentd-es created
clusterrole.rbac.authorization.k8s.io/fluentd-es created
clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created
daemonset.apps/fluentd-es-v2.4.0 created
control# kubectl create -f fluentd-es-configmap.yaml
configmap/fluentd-es-config-v0.2.0 createdУбедитесь, что все поды fluentd и другие ресурсы успешно запущены, затем откройте Kibana. В Kibana найдите и добавьте новый индекс из fluentd. Если вы что-то найдете, значит, все сделано правильно, если нет — проверьте предыдущие шаги и повторно создайте daemonset или отредактируйте configmap:

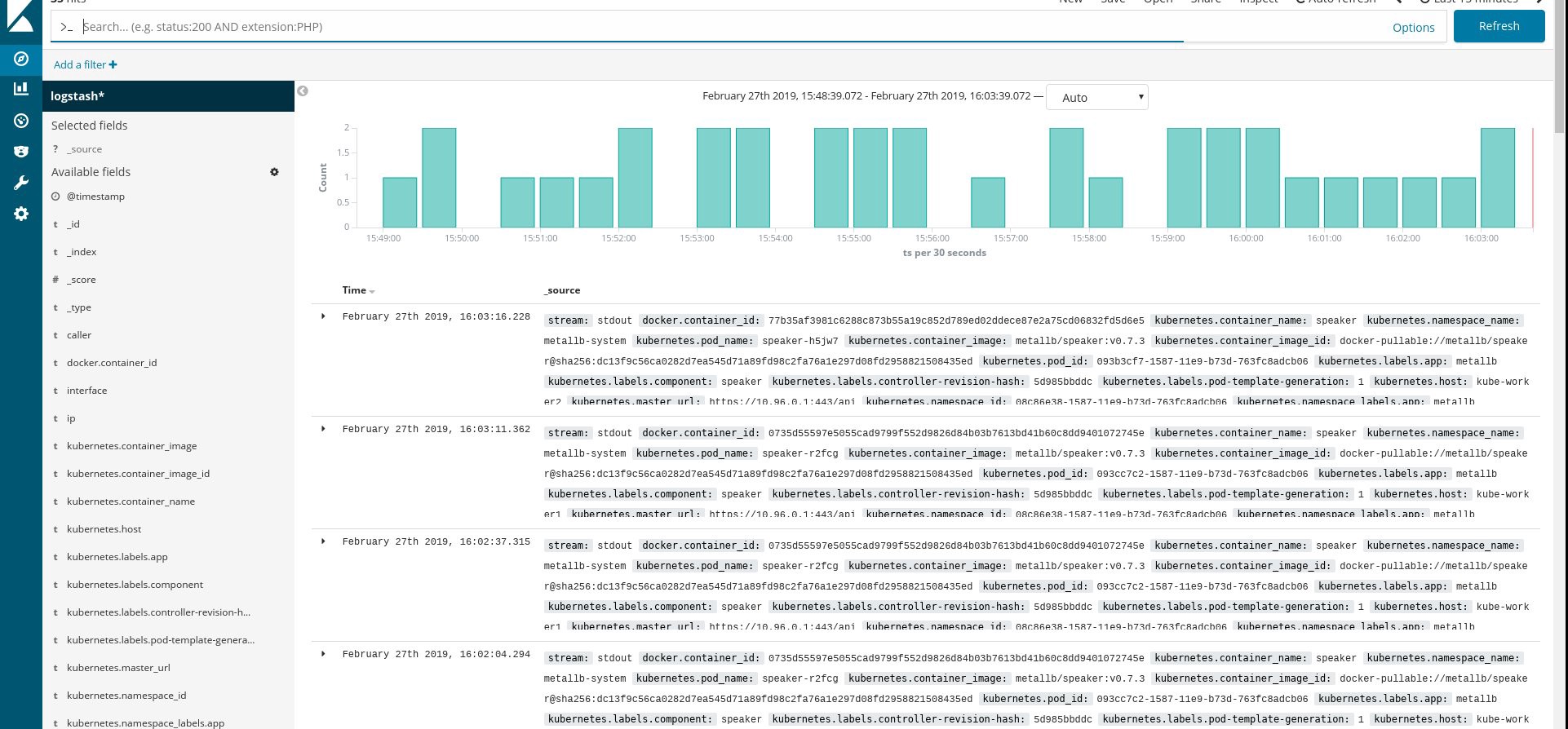
Отлично, теперь, когда мы получаем логи из кластера, можно создавать любые панели мониторинга. Разумеется, конфигурация — простейшая, так что надо, наверное, будет ее поменять под себя. Главной целью было показать, как это делается.
Выполнив все предыдущие шаги, мы получили действительно хороший, готовый к работе кластер Kubernetes. Пришло время задеплоить в него какое-нибудь тестовое приложение и посмотреть, что будет.
Для этого примера возьмем взять мое небольшое приложение Python/Flask Kubyk, которое уже имеет контейнер Docker, так что берем его из открытого реестра docker. Теперь добавим в это приложение файл внешней базы данных — для этого воспользуемся настроенным хранилищем GlusterFS.
Сначала создадим для этого приложения новый том pvc (запрос постоянного тома), где будем хранить базу данных SQLite с учетными данными пользователей. Можно использовать предварительно созданный класс памяти из части 2 этого руководства.
control# mkdir kubyk && cd kubyk
control# vi kubyk-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: kubyk
annotations:
volume.beta.kubernetes.io/storage-class: "slow"
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
control# kubectl create -f kubyk-pvc.yamlСоздав новый PVC для приложения, мы готовы к деплою.
control# vi kubyk-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubyk-deployment
spec:
selector:
matchLabels:
app: kubyk
replicas: 1
template:
metadata:
labels:
app: kubyk
spec:
containers:
- name: kubyk
image: ratibor78/kubyk
ports:
- containerPort: 80
volumeMounts:
- name: kubyk-db
mountPath: /kubyk/sqlite
volumes:
- name: kubyk-db
persistentVolumeClaim:
claimName: kubyk
control# vi kubyk-service.yaml
apiVersion: v1
kind: Service
metadata:
name: kubyk
spec:
type: LoadBalancer
selector:
app: kubyk
ports:
- port: 80
name: httpТеперь давайте создадим деплой и сервис:
control# kubectl create -f kubyk-deploy.yaml
deployment.apps/kubyk-deployment created
control# kubectl create -f kubyk-service.yaml
service/kubyk createdПроверьте новый IP-адрес, назначенный для сервиса, а также статус пода:
control# kubectl get po
NAME READY STATUS RESTARTS AGE
glusterfs-2wxk7 1/1 Running 1 2d1h
glusterfs-5dtdj 1/1 Running 1 41d
glusterfs-zqxwt 1/1 Running 0 2d1h
heketi-b8c5f6554-f92rn 1/1 Running 0 8d
kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 11s
control# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
... some text..
kubyk LoadBalancer 10.109.105.224 192.168.0.242 80:32384/TCP 10sИтак, похоже, что мы успешно запустили новое приложение; если откроем в браузере IP-адрес http://192.168.0.242, мы должны увидеть страницу входа этого приложения. Можно использовать учетные данные admin/admin для входа в систему, но если мы попытаемся войти на данном этапе, то получим ошибку, поскольку доступной базы данных еще нет.
Вот пример сообщения об ошибке лога из пода на панели мониторинга Kubernetes:
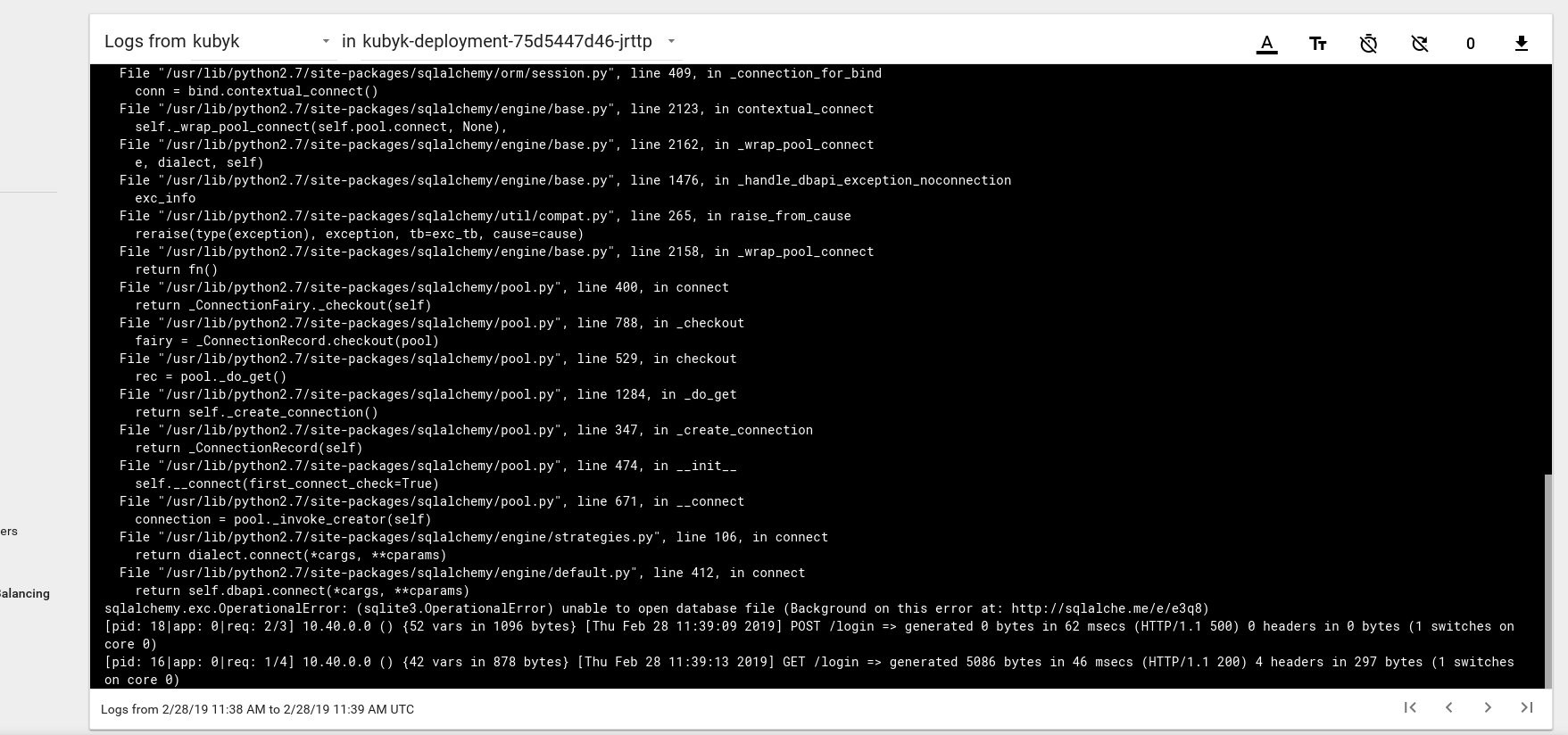
Чтобы исправить ситуацию, нужно скопировать файл SQlite DB из моего репозитория git в предварительно созданный том pvc. Приложение начнет использовать эту базу данных.
control# git pull https://github.com/ratibor78/kubyk.git
control# kubectl cp ./kubyk/sqlite/database.db kubyk-deployment-75d5447d46-jrttp:/kubyk/sqliteМы используем под из приложения и команду kubectl cp, чтобы скопировать этот файл в том.
Также надо предоставить пользователю nginx доступ к этому каталогу с правом записи; мое приложение запускается через пользователя nginx с помощью supervisord.
control# kubectl exec -ti kubyk-deployment-75d5447d46-jrttp -- chown -R nginx:nginx /kubyk/sqlite/Попробуем войти в систему еще раз:
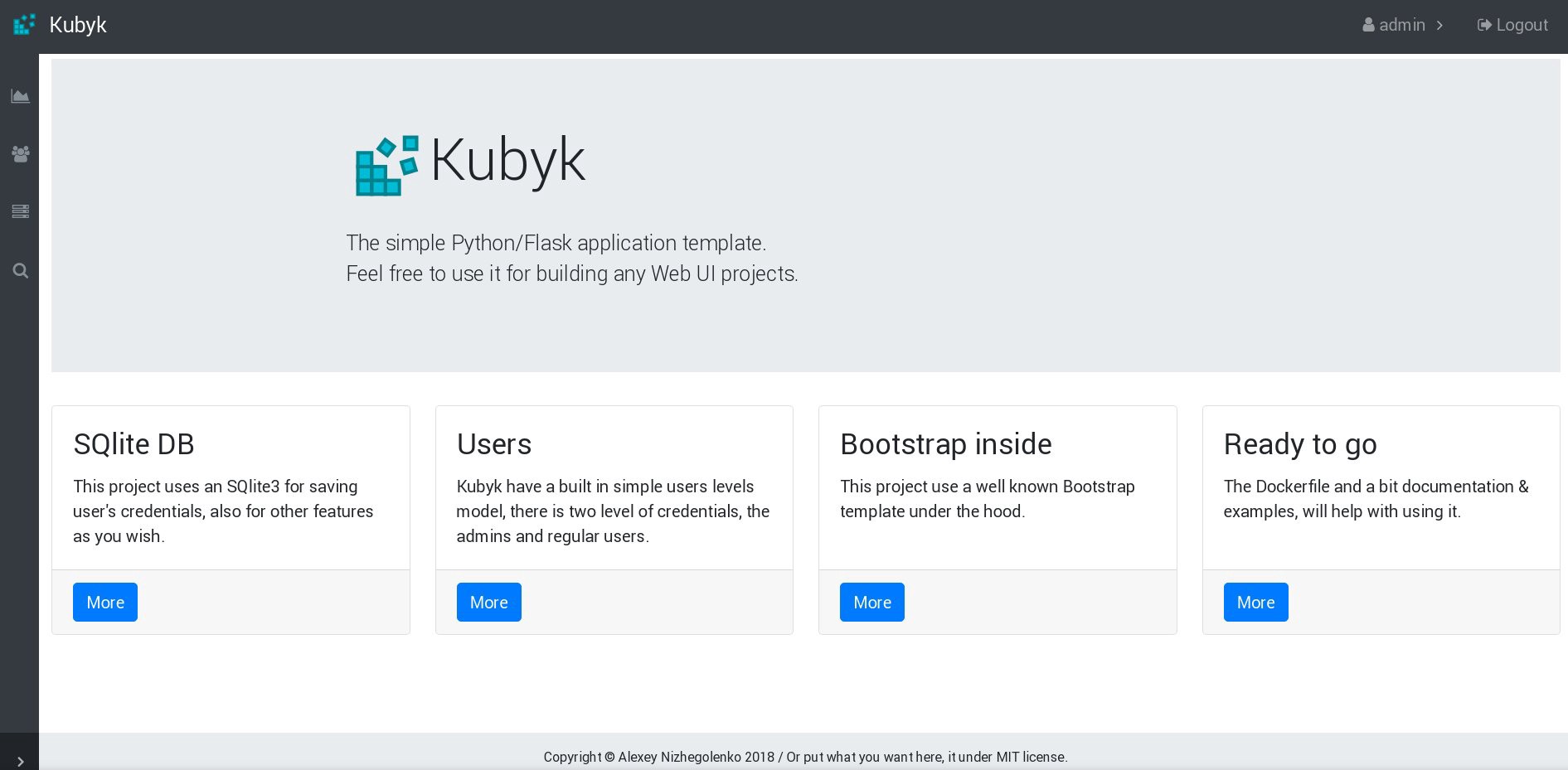
Отлично, теперь наше приложение работает правильно, и мы можем масштабировать деплой kubyk до 3 реплик, например, чтобы поместить одну копию приложения в одну рабочую ноду. Поскольку ранее мы создали том pvc, все наши поды с репликами приложения будут использовать одну базу данных, и сервис, таким образом, будет распределять трафик между репликами по циклической схеме.
control# kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
heketi 1/1 1 1 39d
kubyk-deployment 1/1 1 1 4h5m
control# kubectl scale deployments kubyk-deployment --replicas=3
deployment.extensions/kubyk-deployment scaled
control# kubectl get po
NAME READY STATUS RESTARTS AGE
glusterfs-2wxk7 1/1 Running 1 2d5h
glusterfs-5dtdj 1/1 Running 21 41d
glusterfs-zqxwt 1/1 Running 0 2d5h
heketi-b8c5f6554-f92rn 1/1 Running 0 8d
kubyk-deployment-75d5447d46-bdnqx 1/1 Running 0 26s
kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 4h7m
kubyk-deployment-75d5447d46-wz9xz 1/1 Running 0 26s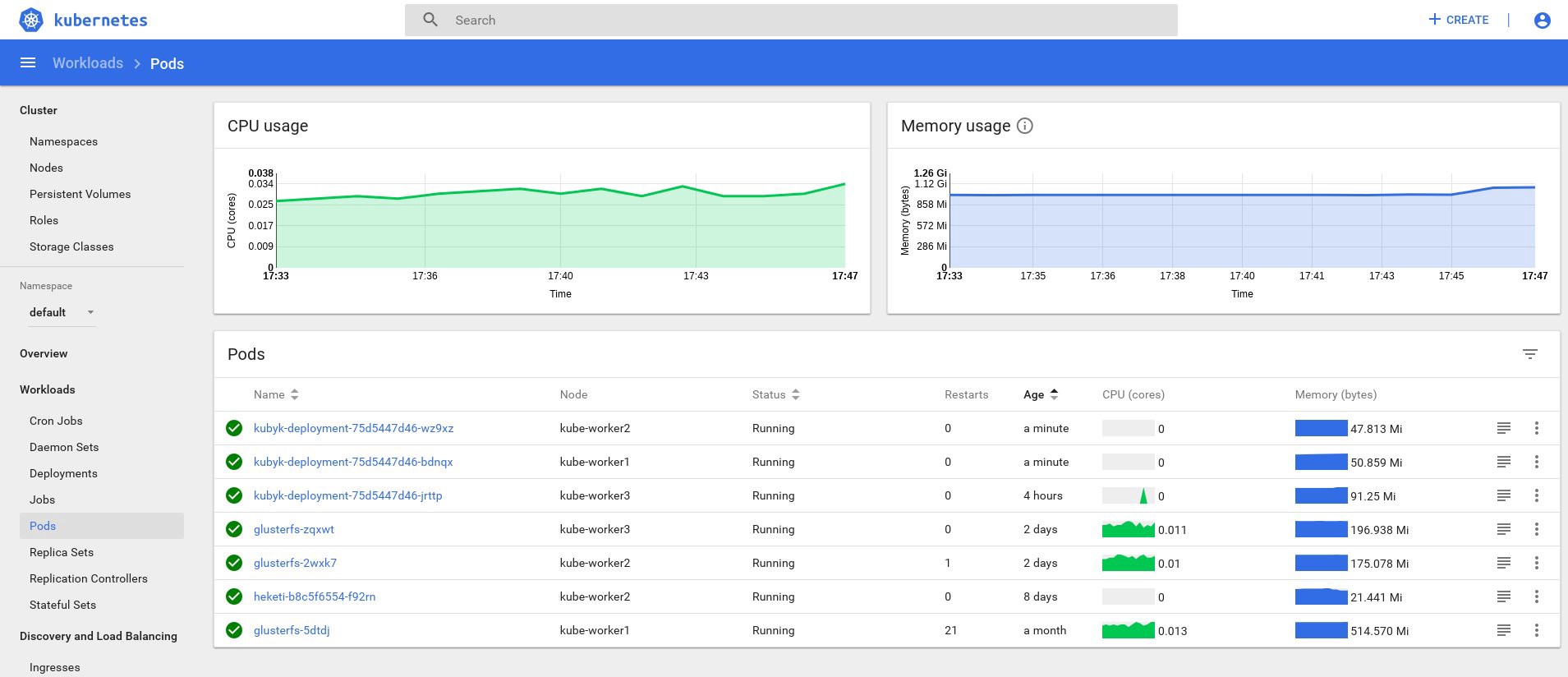
Теперь у нас есть реплики приложения для каждой рабочей ноды, поэтому приложение, если потеряет какие-то ноды, работать не прекратит. Кроме того, мы получаем простой способ балансировки нагрузки, как я говорил ранее. Неплохо для начала.
Давайте создадим в нашем приложении нового пользователя:
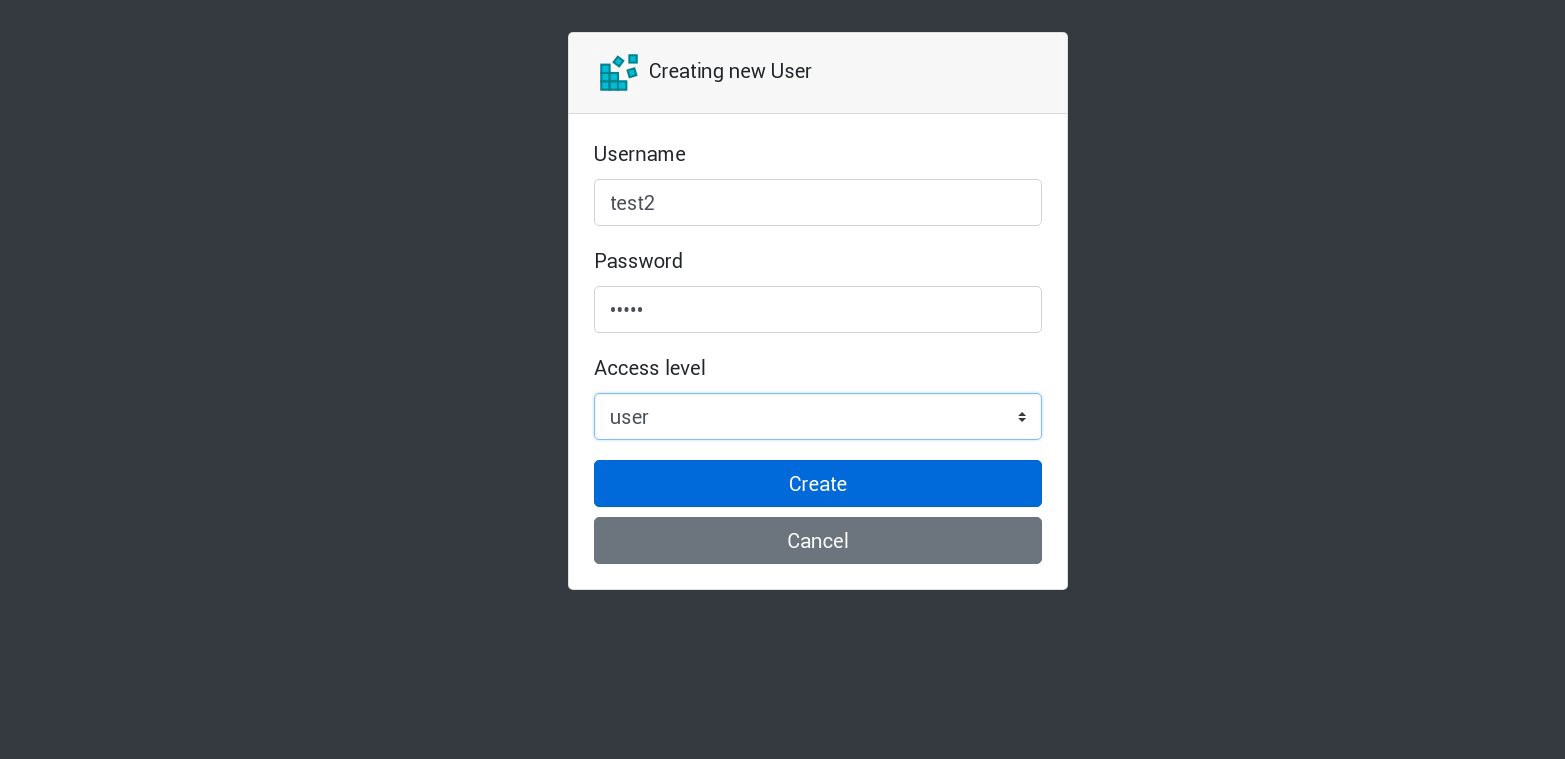
Все новые запросы будут обрабатываться следующим подом в списке. Это можно проверить по логам подов. Например, новый пользователь создается приложением в одном поде, тогда следующий под отвечает на следующий запрос, и так далее. Поскольку это приложение использует один постоянный том для хранения базы данных, все данные будут в безопасности даже в случае потери всех реплик.
В больших и сложных приложениях понадобится не просто назначенный том для базы данных, а различные тома для размещения постоянной информации и многих других элементов.
Ну что ж, мы почти закончили. Добавить можно еще много аспектов, поскольку Kubernetes — тема объемная и динамично развивается, но мы на этом остановимся. Главная целью данного цикла статей было показать способ создания собственного кластера Kubernetes, и я надеюсь, эта информация была вам полезна.
P. S.
Проверка стабильности и стресс-тесты, разумеется.
Схема кластера из нашего примера работает без 2 рабочих нод, 1 мастер-ноды и 1 ноды etcd. Хотите — отключите их и проверьте, будет ли тестовое приложение функционировать.
Составляя эти руководства, я готовил для продакшена кластер почти аналогичной схемы. Однажды, создав кластер и задеплоив в него приложение, я нарвался на крупный сбой электропитания; рубануло абсолютно все серверы кластера — прямо оживший кошмар системного администратора. Некоторые серверы отключились надолго, и после на них возникли ошибки файловой системы. Но повторный запуск меня весьма удивил: кластер Kubernetes полностью восстановился. Запустились все тома GlusterFS и деплои. Как по мне, это — демонстрация большого потенциала данной технологии.
Всего доброго и, надеюсь, до новой встречи!
