
В основе Apache Kafka находится лог — простая структура данных, которая использует последовательные операции, работающие в симбиозе с оборудованием. Эффективное использование дискового буфера и кэша процессора, prefetch, передача данных zero-copy и много других радостей — все это благодаря построенной на логе структуре, которая славится своей эффективностью и пропускной способностью. Обычно эти преимущества, а еще базовая реализация в виде лога коммитов, — первое, что люди узнают о Kafka.
Код самого лога составляет относительно малую часть всей системы. Гораздо больше занимает код, который отвечает за организацию партиций (т. е. логов) на множестве брокеров в кластере — назначает лидеров, обрабатывает сбои и т. д. Этот код и делает Kafka надежной распределенной системой.
Раньше важной частью работы распределенного кода был Apache ZooKeeper. Он хранил самые важные метаданные системы: где находятся партиции, кто из реплик лидер и т. д. Поначалу эффективный и проверенный ZooKeeper действительно был нужен, но, по сути, это что-то вроде специфической файловой системы или API триггеров поверх согласованного лога. А Kafka — это API pub/sub (издатель-подписчик) поверх согласованного лога. В результате пользователи настраивают, конфигурируют, мониторят, защищают и обдумывают взаимодействие и производительность между двумя реализациями лога, двумя сетевыми уровнями и двумя реализациями системы безопасности — каждая со своими инструментами и хуками мониторинга. Все стало неоправданно сложно, поэтому решено было заменить ZooKeeper сервисом кворума прямо в самой Kafka.
Работы предстояло немало, поэтому в прошлом апреле мы запустили проект с участием сообщества, чтобы ускорить темпы и создать рабочую систему к концу года.
Мы с Джейсоном, Колином и командой KIP-500 прогнали полный жизненный цикл сервера Kafka с созданием и потреблением сообщений — и все без Zookeeper. Какая же красота!
— Бен Стопфорд (Ben Stopford)
Рады сообщить, что ранний доступ к KIP-500 уже закоммичен в ветку trunk и будет включен в предстоящий релиз 2.8. Впервые Kafka можно использовать без ZooKeeper. Мы называем это режимом Kafka Raft Metadata, сокращенно —KRaft (читается «крафт»).
В этом релизе пока доступны не все фичи. Мы еще не поддерживаем ACL и другие транзакции или функции безопасности. Переназначение партиций и JBOD тоже не поддерживаются в режиме KRaft (надеемся, что они будут доступны в одном из релизов Apache Kafka в этом году). Так что контроллер кворума считаем экспериментальным и для прода пока не используем. В остальном преимуществ масса: деплоймент и обслуживание станут проще, всю Kafka можно запустить как один процесс, а на кластер помещается гораздо больше партиций (цифры см. ниже).
Контроллер кворума: консенсус на основе событий
Если запустить Kafka с новым контроллеров кворума, все задачи по метаданным, которые раньше выполнялись контроллером Kafka и ZooKeeper, ложатся на новый сервис, запущенный прямо в кластере Kafka. Контроллер кворума можно запустить на выделенном оборудовании, если этого требует ваш сценарий.
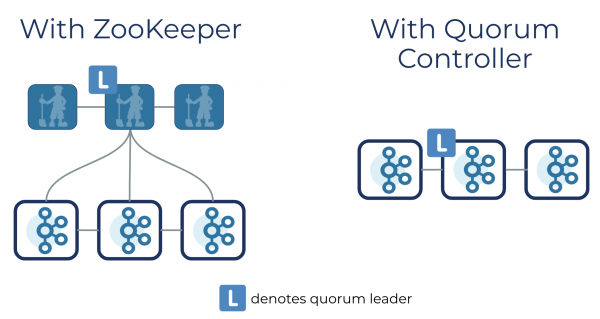
Внутри происходит много интересного. Контроллеры кворума используют новый протокол KRaft, чтобы точно реплицировать метаданные по всему кворуму. Протокол во многом напоминает ZooKeeper ZAB и Raft, но с важными отличиями — например, что логично, он использует архитектуру на основе событий.
Контроллер кворума хранит свой стейт с помощью модели на основе событий, чтобы стейт-машину всегда можно было в точности воссоздать. Чтобы лог события, который хранит стейт (также называется топиком метаданных), не разрастался до бесконечности, периодически он обрезается с созданием снапшотов. Остальные контроллеры в кворуме фолловят активный контроллер и реагируют на события, которые он создает и сохраняет в свой лог. Если одна нода приостановлена во время разделения на партиции, например, она быстро догонит пропущенные события с помощью лога. Так мы существенно сокращаем период простоя и время восстановления системы в худшем сценарии.
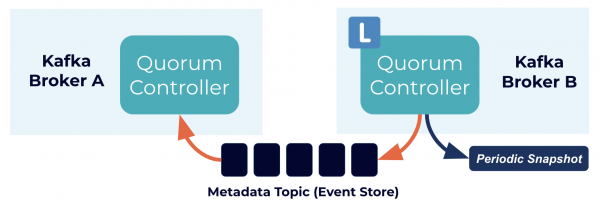
Консенсус на основе событий
Раз протокол KRaft управляется событиями, в отличие от контроллера ZooKeeper контроллер кворума не загружает стейт из ZooKeeper, когда становится активным. При смене лидера у нового активного контроллера уже есть в памяти все закоммиченные записи метаданных. Более того, для отслеживания метаданных в кластере используется тот же механизм на основе событий, что и в протоколе KRaft. Задача, которую раньше обрабатывали RPC, теперь полагается на события и использует лог для коммуникации. Приятное последствие этих изменений (и изменений, которые были предусмотрены изначальным замыслом) — Kafka теперь поддерживает гораздо больше партиций, чем раньше. Обсудим подробнее.
Увеличение масштаба Kafka до миллионов партиций
Максимальное число партиций в кластере Kafka определяется двумя свойствами: лимит партиций для ноды и лимит партиций для кластера. Сейчас на ограничение в кластере во многом влияет управление метаданными. Предыдущие KIP улучшили лимит для ноды, хотя и здесь нет предела совершенству. Масштабируемость в Kafka зависит от добавления нод. Здесь нам важен лимит для кластера, который определяет верхнюю границу масштабирования всей системы.
Новый контроллер кворума может обрабатывать гораздо больше партиций на кластере. Чтобы это проверить, можно провести такие же тесты, как в 2018 году, с помощью которых мы демонстрировали лимиты партиций в Kafka. Эти тесты измеряют время, которое требуется для завершения работы и восстановления. В старом контроллере это операция O (число партиций). Она устанавливает верхнюю границу числа партиций, которые сейчас поддерживает один кластер Kafka.
Предыдущая реализация, как рассказывалось в посте по ссылке, могла достигать 200K партиций. Ограничивающим фактором служило время, которое требовалось для переноса важных метаданных между внешним консенсусом (ZooKeeper) и внутренним управлением лидером (контроллер Kafka). С новым контроллером кворума обе роли выполняет один компонент. Подход на основе событий означает, что контроллер отрабатывает отказ почти моментально. Ниже приводятся цифры нашего тестирования для кластера с 2 млн партиций (в 10 раз больше предыдущего лимита):
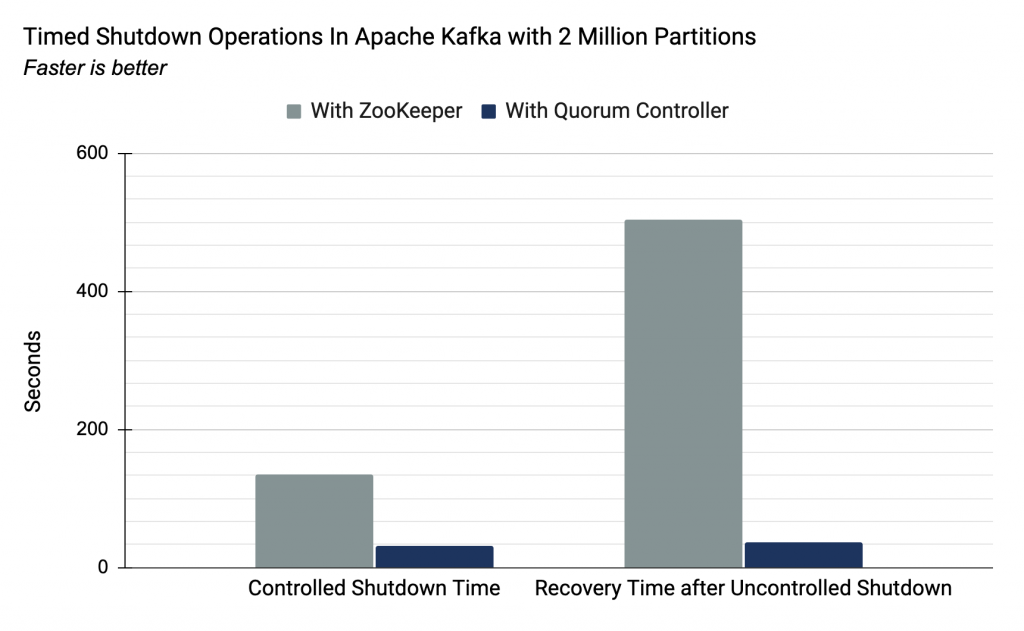
| Контроллер | С контроллером ZooKeeper | С контроллером кворума |
|---|---|---|
| Время контролируемой остановки (2 млн партиций) | 135 сек | 32 сек |
| Восстановление после неконтролируемой остановки (2 млн партиций) | 503 сек | 37 сек |
Важно учитывать контролируемую и неконтролируемую остановку. Контролируемые остановки включают типичные рабочие сценарии, вроде rolling restart — стандартная процедура развертывания изменений без потери доступности. Восстановление после неконтролируемой остановки важнее, потому что оно задает целевое время восстановления (RTO) системы в случае, скажем, неожиданного сбоя, например, на виртуальной машине или поде, или потери связи с дата-центром. Хотя эти цифры указывают на производительность всей системы, они напрямую определяют хорошо известное узкое место, которое возникает при использовании ZooKeeper.
Измерения для контролируемой и неконтролируемой остановки не сравниваются напрямую, потому что неконтролируемая остановка включает выбор новых лидеров, а контролируемая — нет. Это расхождение введено специально, чтобы контролируемая остановка соответствовала изначальным тестам 2018 года.
Упрощение Kafka — единый процесс
Kafka часто воспринимается как тяжеловес, и такой репутацией она во многом обязана сложностями с управлением ZooKeeper. Из-за этого для запуска проектов часто выбирают более легкую очередь сообщений, вроде ActiveMQ или RabbitMQ, а Kafka появляется на сцене только при разрастании масштаба.
Это печально, ведь Kafka дает удобную абстракцию на основе лога коммитов, которая одинаково хорошо подходит для маленьких рабочих нагрузок у стартапов и для бешеного трафика у Netflix или Instagram. А если вам нужна стриминговая обработка, без Kafka с абстракцией лога коммитов не обойтись, будь то Kafka Streams, ksqlDB или другой аналогичный фреймворк. Управлять двумя отдельными системами (Kafka и Zookeeper) сложно, поэтому пользователи выбирали между масштабированием и простотой.
Теперь можно получить все и сразу. Благодаря KIP-500 и режиму KRaft мы можем легко начать проект с Kafka или использовать его как альтернативу монолитным брокерам, вроде ActiveMQ или RabbitMQ. Благодаря легкости и единому процессу это подходящий вариант для ограниченных в ресурсах устройств. В облаке все еще проще. Управляемые сервисы, например, Confluent Cloud, все берут на себя. Не важно, собственный это будет кластер или управляемый, мы можем начать с малого, а потом расширять его вместе со своими рабочими нагрузками — все в рамках одной инфраструктуры. Давайте посмотрим, как выглядит развертывание с одним процессом.
Испытываем Kafka без ZooKeeper
Новый контроллер кворума пока доступен в экспериментальном режиме, но, скорее всего, будет включен в релиз Apache Kafka 2.8. На что он способен? Самое крутое — это, конечно, возможность создавать кластер Kafka с одним процессом, как в демо.
Конечно, если вам нужна очень высокая пропускная способность, и вы хотите добавить репликацию для отказоустойчивости, понадобятся еще процессы. Пока контроллер кворума на базе KRaft доступен только как Early Access, для критических рабочих нагрузок он не годится. В ближайшие месяцы мы будем добавлять недостающие фрагменты, моделировать протокол с помощью TLA+ и внедрять контроллер кворума в Confluent Cloud.
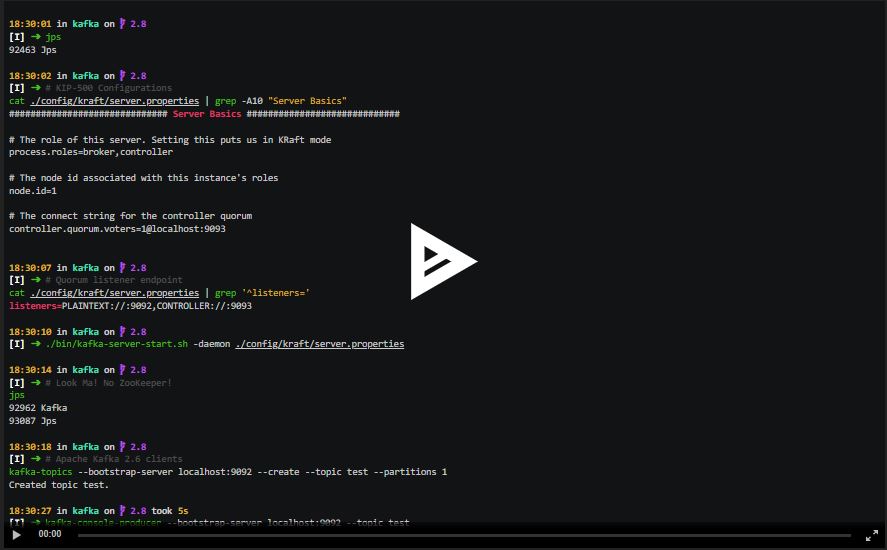
Но поэкспериментировать вы можете уже сейчас. См. полный README на GitHub.
