В лаборатории моделирования природных систем НЦКР ИТМО мы занимаемся разработкой и продвижением решений в области AutoML. Наши научные сотрудники Николай Никитин, Анна Калюжная, Павел Вычужанин и Илья Ревин рассказывают о трендах и задачах AutoML, плюс — о собственных open-source разработках в этой области.
Минутка теории и пара слов об AutoML фреймворках
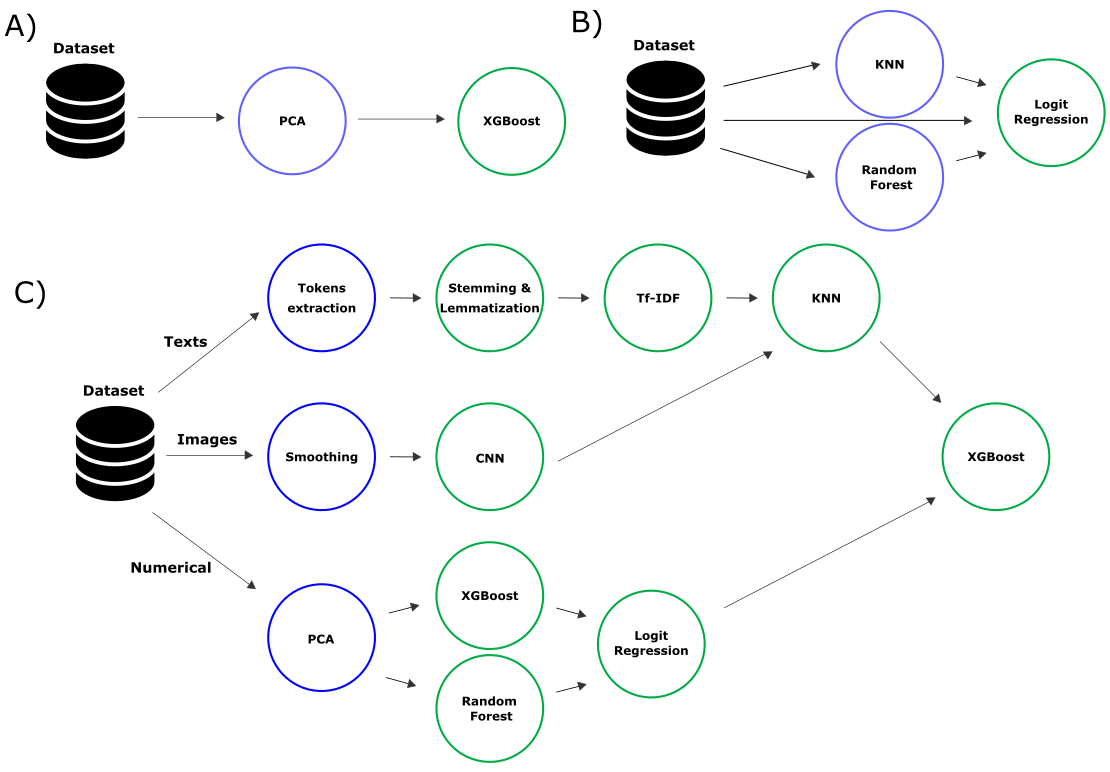
Для того, чтобы решить какую-либо задачу с помощью методов машинного обучения (МО), требуется пройти множество шагов: от очистки данных и подготовки датасета, выбора наиболее информативных признаков и преобразования признакового пространства до подбора модели МО и настройки ее гиперпараметров. Такую последовательность часто представляют в виде пайплайна. Однако даже на работу с линейными пайплайнами (А, на схеме выше), подбор их структуры и параметров могут требоваться дни, а иногда и недели. В процессе решения сложных задач пайплайны приобретают иную структуру. Для повышения качества моделирования часто используют ансамблевые методы (стекинг), объединяющие несколько моделей (на схеме — B), либо делают пайплайн разветвленным. В последнем случае задействуют различные методы предобработки для вариативных моделей МО, обучаемых на разных частях датасета (С).
Автоматизированная подготовка пайплайна — это преимущественно задача комбинаторной оптимизации или поиска наилучшего сочетания возможных факторов — множества вычислительных блоков. В этом случае пайплайн описывают в виде направленного ациклического графа (directed acyclic graph, DAG), который может быть транслирован в граф вычислений, а эффективность определяют с помощью целевых функций, численно оценивающих качество, сложность, устойчивость и другие свойства получившейся модели.
Модели со структурой типа В и С фактически становятся композитными, т.е. включают в себя различные алгоритмы МО. Например, можно объединить байесовскую сеть и свёрточную для предсказания на мультимодальных данных. А с композитными моделями и пайплайнами МО можно работать с помощью методов и технологий AutoML.
Самый примитивный метод решения этой задачи — случайный поиск (random search) с оценкой сочетаний блоков. Более совершенный подход — мета-эвристические алгоритмы оптимизации: роевые и эволюционные (последние можно реализовать с помощью фреймворков TPOT и FEDOT). Такие алгоритмы должны иметь специализированные операторы кроссовера, мутации и селекции для применения к особям, описываемым графом (обычно деревом), работать с многокритериальной целевой функцией, включать дополнительные процедуры для создания устойчивых и не склонных к переобучению пайплайнов (например, регуляризацию).
Операторы кроссовера и мутации могут быть реализованы классическим способом — в виде кроссовера поддеревьев (subtree crossover), когда выбираются две родительские особи, которые обмениваются случайными частями своих графов. Но это — не единственная возможная реализация, есть и более семантически сложные варианты (например, one-point crossover). Мутация на деревьях также предполагает реализации, включающие случайное изменение модели (или вычислительного блока) в случайном узле графа на подходящий вариант из пула моделей, удаление случайного узла, а также случайное добавление поддерева.

(эта и другие иллюстрации доступны в нашей статье в Procedia Computer Science)
В идеальном случае, AutoML позволяет исключить эксперта-аналитика из процесса разработки, эксплуатации и внедрения модели. Однако пока добиться этого в полной мере сложно — большая часть AutoML фреймворков поддерживает решение отдельных задач автоматического МО (настройка гиперпараметров, выбор признаков и тому подобных) в рамках фиксированных пайплайнов и только для некоторых типов данных (в таблице далее). Приведенное сравнение, разумеется, не претендует на полноту — оно выполнялось на основе анализа открытой документации и примеров, а положение дел в области AutoML может быстро меняться.
| Название | Тип пайплайна |
Метод оптимизации |
Входные данные |
Масшта- бирование |
Дополнительные особенности |
Источник |
|---|---|---|---|---|---|---|
| TPOT | Variable | GP | Tabular | Multiprocessing, Rapids | Code generation | github |
| H2O | Fixed | Grid Search | Tabular, Texts | Hybrid | - | githib |
| AutoSklearn | Fixed | SMAC | Tabular | - | - | github |
| ATM | Fixed | BTB | Tabular | Hybrid | - | github |
| FEDOT | Variable | GP + hyperopt | Tabular, Timeseries, Images, Texts |
- | Composite pipelines |
github |
| AutoGluon | Fixed | Fixed Defaults | Tabular, Images, Texts | - | NAS, AWS integration | github |
| LAMA | Fixed | Optuna | Tabular, Texts | MLSpace | Profiling | github |
| NNI | Fixed | Bayes | Tabular, Images | Hybrid, Kubernetes |
NAS, WebUI | github |
Фреймворк TPOT, например, позволяет автоматизировать создание моделей для задач классификации (в том числе многоклассовой) и регрессии только на табличных данных. При этом — в отличие от большинства других фреймворков — он строит «гибкие» пайплайны.
Чего не хватает, и что предложили мы
Типовой сценарий применения AutoML выглядит следующим образом. На основе доступных данных (обучающей выборки) осуществляют оптимизация структуры пайплайна моделирования и гиперпараметров блоков, входящих в его состав. Однако на практике реализации, неплохо работающие на тестовых задачах, оказываются не так хороши на «боевых» сводах данных. Поэтому появляются всё новые и новые AutoML-решения: H2O, AutoGluon, LAMA, NNI и другие. Они отличаются по возможностям (например, индустриальные решения обладают развитыми инфраструктурными возможностями), но часто не подходят для широкого круга задач. Хотя большинство фреймворков позволяют решать задачи классификации и регрессии, прогнозирование временных рядов они часто не поддерживают.

ML-пайплайн может включать модели для разных задач. Например, генерировать на основе регрессии новый полезный признак, а потом использовать его в классификации. На данный момент AutoML фреймворки не позволяют решать такую задачу удобным способом. Нередко ML-инженеры сталкиваются с мультимодальными и разнородными данными, которые приходится интегрировать для дальнейшего моделирования вручную.
До недавнего времени готовых к использованию инструментов такого рода не было, но мы решили попробовать разработать свой и обойти описанные проблемы. Мы назвали его FEDOT. Это — open-source фреймворк автоматического машинного обучения, автоматизирующий создание и оптимизацию цепочек задач (пайплайнов) МО и их элементов. FEDOT позволяет компактно и эффективно решать различные задачи моделирования.

Вот пример его использования для решения задачи классификации:
# new instance to be used as AutoML tool with time limit equal to 10 minutes
auto_model = Fedot(problem='classification', learning_time=10)
#run of the AutoML-based model generation
pipeline = auto_model.fit(features=train_data_path, target='target')
prediction = auto_model.predict(features=test_data_path)
auto_metrics = auto_model.get_metrics() Основной акцент в работе фреймворка — управление взаимодействием между вычислительными блоками пайплайнов. В первую очередь, это касается этапа формирования модели машинного обучения. FEDOT не просто помогает подобрать лучший вариант модели и обучить ее, но и создать композитную модель — совместно использовать несколько моделей различной сложности и за счет этого добиваться лучших результатов. В рамках фреймворка мы описываем композитные модели в виде графа, определяющего связи между блоками предобработки данных и блоками моделей.
Однако фреймворк не ограничивается отдельными AutoML-задачами, а позволяет заниматься структурным обучением, когда для заданного набора данных строится решение в виде ациклического графа (DAG), узлы которого представлены моделями МО, процедурами предобработки и трансформации данных. Структуру этого графа, а также параметры каждого узла и подвергают обучению.
Формируют подходящую для конкретной задачи структуру автоматически. Для этого мы задействовали эволюционный алгоритм оптимизации GPComp, который создает популяцию из множества ML-пайплайнов и последовательно ищет лучшее решение, применяя методы эволюции — мутацию и кроссовер. Плюс — избегает нежелательного усложнения структуры модели за счет применения процедур регуляризации и многокритериальных подходов.
Для наглядности приведем тизер фреймворка, доступный в нашем YouTube-канале:
Как и ряд ранее отмеченных фреймворков, FEDOT реализован на Python и доступен под открытой лицензией BSD-3. Но есть и отличия с точки зрения преимуществ:
- Архитектура FEDOT обладает высокой гибкостью, фреймворк можно использовать для автоматизации создания МО для различных задач, типов данных и моделей;
- FEDOT поддерживает популярные ML-библиотеки (scikit-learn, keras, statsmodels и др.), но при необходимости допускает интеграцию и других инструментов;
- Алгоритмы оптимизации пайплайнов не привязаны к типам данных или задачам, но можно использовать специальные шаблоны под определенный класс задач или тип данных (прогнозирование временных рядов, NLP, табличные данные и др.);
- Фреймворк не ограничен машинным обучением, в пайплайны можно встроить модели, специфичные для конкретных областей (например, модели в ОДУ или ДУЧП);
- Дополнительные методы настройки гиперпараметров различных моделей также могут быть бесшовно добавлены в FEDOT в дополнение к уже поддерживаемым;
- FEDOT поддерживает any-time режим работы (в любой момент времени можно остановить алгоритм и получить результат);
- Итоговые пайплайны могут быть экспортированы в json-формате без привязки к фреймворку, что позволяет добиться воспроизводимости эксперимента.
Таким образом, по сравнению с другими фреймворками, FEDOT не ограничен одним классом задач, а претендует на универсальность и расширяемость. Он позволяет строить модели, использующие входные данные различной природы.
Применение AutoML для реальных задач на примере FEDOT
Для проверки корректности и эффективности алгоритмов, лежащих в основе FEDOT, мы протестировали его на известных бенчмарках (например, наборе задач Penn ML). Помимо этого мы подготовили пример из области нефтехимии — разберем его далее.
На объектах для хранения нефтепродуктов зачастую их смешивают. Однако, если совместимость у нефтепродуктов слабая, происходят качественные потери, а именно — образование общего осадка. Он ведет к ухудшению работы производственной цепочки. Определение состава топлива и наличия в нем осадка — весьма дорогой процесс. Наиболее часто используется метод хроматографии, стоимостью порядка одного миллиона рублей за пробу. Однако с помощью исторических данных, содержащих информацию о параметрах топлива и различных смесей, плюс — функциональность FEDOT, можно моделировать варианты с наименьшим содержанием осадка.
Прогнозирование величины осадка, а также классификацию смесей топлив с точки зрения его выпадения, можно одновременно трактовать как задачу регрессии, так и задачу классификации.

Входные данные для моделирования имеют табличную структуру: набор признаков представляет собой численные оценки физико-химических свойств смеси топлив (перечисленных в стандарте), полученных в результате лабораторных измерений. Целевые переменные преставляют собой а) процент серы в полученной смеси — для постановки задачи регресии; б) класс экологической безопасности топлива — для задачи многоклассовой классификации.
Для наглядности покажем фрагмент самих данных:
| Значение целевой переменной (задача регрессии) | Значение целевой переменной (задача классификации) | № образца | Кин.вязкость при 50°С | Плотность при 15 °С | Содержание серы | Содержание воды | TSA | Т потери текучести | Т вспышки в закрытом тигле | Вид топлива |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.17 | 1 Класс | 13 | 583.6 | 973.0 | 2.74 | 0.3 | 0.03 | 20.0 | 110.0 | ТПБ |
| 0.1 | 2 Класс | 37 | 472.3 | 965.0 | 2.48 | 0.2 | 0.03 | 19.0 | 110.0 | М-100 |
| 0.03 | 2 Класс | 22 | 18.80 | 851.0 | 0.0015 | 0.1 | 0.02 | 20.0 | 110.0 | ТМУ ЭКО |
| 0.21 | 1 Класс | 98 | 574.3 | 970.0 | 2.74 | 0.2 | 0.03 | 20.0 | 110.0 | ТМУ-180 |
Результаты применения фреймворка «Федот» и созданной вручную модели (на основе градиентного бустинга) к сформированном набору данных таковы: для задачи регрессии созданная вручную модель обеспечивает MSE — 0.215, R2 — 0.723, FEDOT — 0.168 и 0.761 соответственно; для задачи регрессии базовое решение обеспечивает ROC AUC — 0.737, F1 — 0.714, FEDOT — 0.861 и 0.764 соответственно.
Перспективы развития AutoML
Среди AutoML-решений — помимо перечисленных выше инструментов — есть EvalML, TransmogrifAI, Lale и множество других. Все они — собственные разработки компаний. В некоторых случаях им не хватает технических аспектов вроде поддержки масштабируемости и распределенных вычислений, Kubernetes и интеграции с MLOps инструментами. В других — появляются концептуальные вопросы вроде реализации новых алгоритмов оптимизации или их интерпретируемости. Однако есть несколько направлений и перспектив развития AutoML, которым уделяют еще меньше внимания.
Гибкое управление сложностью поиска. В зависимости от требований и допустимого бюджета, ML-инженеру может подойти как модель градиентного бустинга с оптимизированными гиперпараметрами, так и глубокая нейронная сеть или нелинейный пайплайн. Так или иначе, он будет вынужден вникать в возможности доступных AutoML-фреймворков и проводить экспериментальные исследования, выясняя, что работает лучше или хуже. Было бы весьма удобно иметь непрерывный переключатель сложности поиска, при помощи которого можно регулировать размерность пространства поиска — от простых решений до сложных, но эффективных пайплайнов (вплоть до созданных с нуля).
Фабрика решений. Помимо допустимых значений метрик качества, в ML-задачах могут возникать и другие критерии для решений. Например, интерпретируемость, необходимый объем вычислительных ресурсов и памяти для поддержания в production-среде, заблаговременность прогнозов и так далее. Здесь был бы полезным удобный интерфейс, где такие критерии можно указать и учитывать, что в ряде случаев невозможно минимизировать все критерии одновременно, так как существует Парето-фронт решений. Например, при повышении сложности архитектуры нейронной сети точность растет, но и требуются более существенные вычислительные ресурсы.
Наша команда проводила экспериментальные исследования, где мы попробовали применить эволюционные многокритериальные алгоритмы оптимизации в рамках FEDOT для оптимизации пайплайнов машинного обучения. В качестве критериев для оптимизации мы выбрали не только точность, но и сложность пайплайнов (число узлов и глубину графа вычислений). В ходе экспериментов мы обнаружили, что такое введение Парето-фронта решений в процесс поиска повышает разнообразие в популяции, а также позволяет находить решения с большей точностью.
Идею о фабрике AutoML-решений, в том числе высказывал и исследователь Yuriy Guts из компании DataRobot в своем докладе Automated Machine Learning. В частности он проводил аналогию с ООП-паттерном Factory, где AutoML мог бы предоставлять разные решения пользователю в зависимости от заданных условий: типы наборов данных, интервалы прогнозов, время жизненного цикла модели и так далее.
Модели могут быть получены для разных наборов данных: случайных выборок, данных в рамках временных диапазонов. Возможно и получение «короткоживущих» моделей на актуальном срезе данных.
В целом автоматическое машинное обучение — многообещающее направление. Если вы работаете в области data science, следить за новостями из мира AutoML весьма ценно. Мы подобрали материалы для погружения в эту тему:
- Репозиторий FEDOT
- Репозиторий разрабатываемого web-интерфейса к фреймворку — FEDOT.Web
- Канал NSS Lab — анонсы новых статей и докладов по AutoML и не только
- Наш YouTube канал с руководствами по AutoML
- Подборка open-source AutoML инструментов
- Набор бенчмарков для AutoML
