В этой статье мы поговорим о ранжирующих (retrieval) моделях диалоговых систем, и методах их персонификации.
Данный текст не является подробной и всеобъемлющей, пошаговой инструкцией по созданию диалогового агента и не претендует на большую научную ценность. Эта статья, скорее, представляет собой краткий обзор существующих методов и инструментов, применяющихся в наши дни и единственная ее задача - заинтересовать читателя и дать начальное представление о такого рода моделях оставив большой простор для собственных экспериментов.
Краткий список всего необходимого: базовое знания Python и PyTorch (если вы являетесь адептом TensorFlow, не пугайтесь, здесь будут показаны общие приемы, которые легко реализовать в других библиотеках), желательно знание библиотеки transformers, а также полезным будет минимальный опыт написания ботов для telegram (это, совершенно, не обязательно, ведь, с ботом можно общаться и в терминале) Ну что ж если вы готовы, то мы отправляемся в наше небольшое путешествие по миру диалоговых моделей.
Прежде всего необходимо сказать, что существует два принципиально разных вида моделей: генеративные, их также часто называют refine models и ранжирующие (retrieval), а также различные виды гибридов, комбинирующие их. Давайте разбираться по порядку.
Генеративные модели получают на вход токенизированную последовательность (в нашем случае реплику пользователя и весь предшествующий диалог), после чего они предсказывают следующий токен, дописывают его в конец входной последовательности, после чего она снова подается на вход. этот процесс повторяется до тех пор, пока модели не надоест, о чем она просигнализирует генерацией специального eos токена.
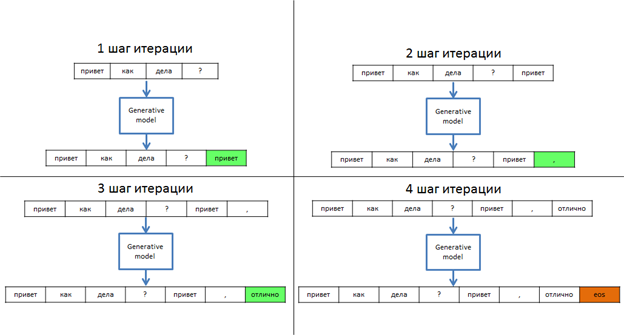
Итак, основной принцип понятен, теперь давайте разберемся как же модели делают предсказания. Начнем с конца, общим для любой генеративной архитектуры является последний полносвязный слой, который по сути является классифицирующим. Число нейронов в нем совпадает с размером словаря модели, функция активация может быть любой на усмотрение разработчика, но для простоты понимания представим, что это SofMax, а значит значение каждого нейрона будет вероятностью того, что слово, соответствующее данному нейрону должно быть следующим.
Однако здесь не все так просто, выбирать наиболее вероятный токен на каждой итерации (это кстати называется Greedy Search) - не лучшая стратегия. Генерируя ответ, мы всегда хотим получать наиболее вероятную последовательность, однако при каждом выборе, мы рискуем пропустить действительно хороший ответ, отбросив его в самом начале. Именно поэтому так хочется заглянуть наперед и узнать к чему приведет то или иное решение. Такой подход называется Beam Search, он основывается на подсчете некоторого числа лучей, которым присваиваются веса, которые в свою очередь складываются из вероятностей токенов через которые лучи проходят. Beam Search дает гораздо лучшие результаты, однако несколько более затратен в сравнении с Greedy Search.

Кроме того, никому не нравится быть предсказуемым, даже нейронная сеть не хочет повторяться (а это к слову очень свойственно генеративным моделям) для борьбы с этим существует два проверенных средства: добавление температуры и запрет на дублирование токенов. Температура - выбор не наиболее вероятного, а случайного (в разумных пределах конечно) токена, можно, например, выбрать случайный среди 10 наиболее вероятных или добавить немного шума к полученному распределения вероятностей.
С запретом на дублирование токенов все еще более просто. Он работает именно так как вы думаете, в случае предсказания токена который совпадает с предыдущим или тем который был пару токенов назад, мы просто его отбрасываем и берем следующий подходящий. Если пока это звучит слишком сложно, не пугайтесь, на самом деле все уже давно сделано за вас.
Если мы используем transformer модель, например gpt (о моделях мы поговорим буквально через минуту), то для генерации достаточно использовать метод generate (num_beams, temperature, no_repeat_ngram_size) который уже имеет все необходимые настройки генерации и даже больше.
Принцип работы всех этих настроек хорошо иллюстрируется в следующих диалогах (авторская орфография сохранена). Первый диалог производился с моделью с минимальными настройками температуры и практически без запрета повторения. Второй - с оптимальными настройками, а в третьем мы решили немного вскипятить модель и подняли температуру до 100.
dialog 1
User:привет
no_temperature_model: Привет, привет
User:как дела?
no_temperature_model: Как дела? Как дела? Нормально, нормально
User:ты любишь повторяться?
no_temperature_model: Ты любишь повторятся?
User:не передразнивай меня!
no_temperature_model: Не передразнюй меня! Я люблю повторяться!
User:если бы я хотел попугая, я бы сходил в зоомагазин!
no_temperature_model: А я бы купил попугая!
dialog 2
User:привет
low_temperature_model: Здарова
User:а теперь, когда у тебя поднялась температура, ты будь повторяться?
low_temperature_model: У меня нет температуры, у меня просто кашель и сопли
User:ты просто трансформер, у тебя не бывает кашля
low_temperature_model: Это был сарказм
dialog 3
User:привет
high_temperature_model: О*******но
User:не ругайся, это не красиво!
high_temperature_model: Я так-то вообще ничего подобного и близко видеть и произносить никогда в жизни
User:я смотрю тебе совсем не хорошо? лучше приляг
high_temperature_model: Спать
User:да, лучше отдохни
high_temperature_model: Хорошо отдохнём, но уже без Вас. С наступающими!) Счастьем. Спасибо.!! :) :)!!!)))!!!
dialog 4
User:привет
nerd_refine_model: Здравствуй
User:как дела?
nerd_refine_model: Все отлично.
User:это хорошо
nerd_refine_model: Спасибо.
User:пожалуйста
nerd_refine_model: Ты очень добрый
К слову только что вы видели работу русскоязычной GPT-3, именно эту архитектуру на сегодняшний день чаще всего применяют в генеративных диалоговых системах. GPT, как дорогой читатель уже вероятно мог слышать, это декодирующий блок трансформера, к слову, полный трансформер для этих задач тоже можно использовать, но это несколько более накладно.
К сожалению, рассказ о том почему все сложилось именно так и self-attention модели практически полностью вытеснили rnn из nlp, будет слишком долгим и лежит за пределами темы этой статьи. Поэтому если вы еще не успели познакомиться с базовыми принципами этих архитектур очень советую вам эту и еще вот эту статьи.
Но если с генеративными моделями все настолько хорошо зачем существует ранжирующий подход? Здесь следует заметить, что первые три диалога, которые вы видели, не являются показательными. Во-первых, для данной статьи были выбраны наиболее интересные варианты развития общения, во-вторых при кажущейся увлекательности, на самом деле пользователь полностью и всецело “ведет” беседу и то насколько увлекательной она может получиться, зависит только от человека.
В случае если пользователь не будет проявлять должного усердия (что происходит чаще всего) общение будет походить на четвертый диалог. Именно так в основном и выглядит коммуникация с генеративными диалоговыми агентами. Основную проблему данного подхода можно сформулировать примерно следующим образом: “инициатива - наказуема”. Любое отклонение от обучающей последовательности является ошибкой и минимизируется в ходе оптимизации весов, ввиду чего модель начинает давать наиболее вероятные, а значит наиболее общие ответы, так или иначе подходящие к любому вопросу.
К слову, эту проблему пытаются решить использованием CPM (Context Prediction Model), дополнительная модель, работающая в паре с генеративной, которая пытается восстановить контекст - историю диалога, по полученному от основной модели ответу, но это уже совсем другая история.
Тем временем рассказ о генеративных системах затянулся и нам пора переходить к моделям ранжирующего поиска. Принцип работы таких архитектур прост, так же, как и в случае refine подхода, модель получает на вход историю диалога, однако затем она ранжирует базу кандидатов расставляя их по порядку в соответствии с их релевантностью последней фразе пользователя.
База кандидатов — это большой корпус текстов, составленный из реальных реплик живых людей, извлеченных из диалогов. И сразу отвечу на возникший у читателя вопрос, да это выглядит весьма естественно и органично, при условии достаточно большой базы кандидатов (примерно от 50 тыс.) модель способна найти подходящий ответ, который идеально подойдет для каждого конкретного случая.
На первый взгляд такой подход может выглядеть как небольшой обман, где же здесь искусственный интеллект и все что мы так сильно любим? Да отчасти это действительно так, но лишь отчасти. В действительности для правильного ранжирования кандидатов от модели требуется глубокое понимание контекста и кандидатов, в противном случае она просто не сможет их сопоставить.
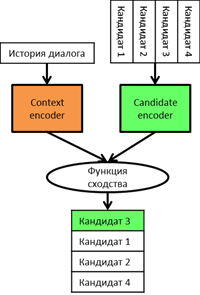
Ну что ж закончим предисловие и перейдем к непосредственному рассмотрению архитектур. Базовая модель представлена на картинке. Как и в большинстве задач машинного обучения для начала нам необходимо получить векторное представление объекта, в нашем случае двух объектов: контекста - истории диалога, и кандидатов - возможных ответов модели. Для этого для начала необходимо произвести токенизацию, а затем отправить в любую доступную вам модель, которая отразит наши тексты в векторном пространстве. Лучше всего на данный момент с этим справляется BERT, его и будем использовать.
После прямого прохода через наш энкодер, достаточно лишь умножить вектор представления контекста на матрицу кандидатов, и мы получим расстояние между ними, основываясь на котором сможем расставить ранги. Кстати такое умножение векторов называется dot product чем она больше - тем ближе друг к другу находятся векторы, и как показывают наши сравнения - это наиболее эффективная функция сходства в сравнении с косинусным сходством (нормализованной формой dot product), Евклидовым и Манхэттенским расстоянием.
Однако внимательный читатель, решивший провести эксперимент здесь заметит, что для произведения размерности наших выходных тензоров контекста и кандидатов должны совпасть. Неужели длинна контекста и кандидатов обязательно должна быть одинакова? Нет в качестве представления каждого объекта при помощи BERT мы берем не весь output, а лишь представление первого [CLS] токена, который благодаря предварительному обучению на nsp задаче научился аккумулировать в себе общий смысл всего следующего высказывания. Это удобный и очень простой способ агрегировать выходной тензор BERT который в наших экспериментах показал себя гораздо лучше, чем поиск средних или максимальных значений.
Поздравляем, только что вы ознакомились с принципом работы Bi-Encoder! Это наиболее распространенная архитектура ранжирующих диалоговых моделей, но далеко не единственная. Помимо нее существует Cross-Encoder, основное ее отличие - использование одного экземпляра BERT. В случае обработки обои векторов единой моделью позволит нам обращать внимание на контекст во время кодирования кандидатов, это в значительной степени повышает точность ответов. Но есть небольшое Но, эта модель крайне медленная и на практике применяется не часто.

Тем не менее, есть небольшая хитрость, которая позволит нам использовать внимание для более полного представления нах векторов. здесь вы можете видеть архитектуру Poly-Encoder, которая делает практически тоже самое, но с значительно меньшими временными затратами. Со всеми этими архитектурами более подробно вы можете ознакомиться здесь.

Здесь у читателя возникнет резонный вопрос зачем же нам нужен Bi-Encoder, если Poly-Encoder делает то же самое, только лучше? Ответ достаточно прост - скорость инференса. Bi-Encoder может использовать заранее вычисленные векторы кандидатов для этого достаточно получить представление контекста и умножить его на матрицу кандидатов, в то время как Poly и Cross Encoder модели каждый раз должны обрабатывать всю базу кандидатов. И скорость прямого прохода модели здесь практически не важна, главная проблема - размер базы. Более того, мы можем стать еще быстрее за счет использования faiss - это специальная библиотека, позволяющая ускорить поиск векторов и сократить объем занимаемой ими памяти. подробнее о ней вы можете прочитать здесь.
Но что делать если мы не готовы жертвовать качеством ответов? Неужели нашим пользователям придется часами ждать ответов диалогового агента? На самом деле нет, один из компромиссов в этом вопросе - сокращение базы кандидатов до приемлемых размеров путем выбора 100-500 наиболее подходящих ответов Bi-Encoder моделью (кстати это очень удобно делать уже упомянутым faiss, он умеет делать это прямо из коробки) и дальнейшее их переранжирование при помощи Poly-Encoder, а блоки кодирования обеих моделей идентичны (да так тоже можно), то наши заранее вычисленные представления кандидатов могут выиграть еще немного времени, останется лишь пересчитать вектор контекста с учетом внимания.
Это все, конечно, здорово, но где же обещанная персонофикация? Не волнуйтесь сейчас мы перейдем к этому вопросу. Здесь все на самом деле очень просто. Все что мы хотим сделать - модифицировать вектор запроса, который в нашем случае является контекстом, таким образом, чтобы он запрашивал кандидатов, подходящих не только к последней реплике пользователя и контексту истории диалога, но и персоне самого агента.
Первый вариант - добавить еще один кодировщик, на вход которого будет подаваться вектор с описанием персоны, представленный небольшим списком с фактами о говорящем, к примеру: “Я люблю дождливые осенние вечера. Я магистрант ИТМО...”. Кодировщик персоны работает идентично всем остальным, а его выходное значение необходимо агрегировать с представлением контекста. Для этого можно использовать целый ряд функций: max, mean, meanmax и др., но наши эксперименты показывают, что meanmax показывает себя лучше всего.
Второй вариант еще проще, для этого нам необходимо всего лишь конкатенировать контекст и персону через специальный токен, всего то! Этот метод мотивирован все тем же стремлением получить более полное внимательное представление. Однако здесь стоит помнить, что с увеличением размера кодируемых векторов затраты вычислительных ресурсов растут совсем не линейно, убедитесь, что вектор персоны поместится в вашу графическую память целиком, иначе ваш агент рискует потерять часть своей личности.

И да конкатенация персоны — это достаточно универсальный метод, его можно применять и для генеративных моделей. Кстати раз уж мы вспомнили о генеративном подходе, стоит все-таки определиться какая же архитектура лучше? Ответ на этот вопрос весьма банален, обе имеют свои плюсы и минусы. Генеративные агенты всегда дают довольно подходящие ответы за счет своей гибкости, однако зачастую они очень поверхностные, сухие и складывается ощущение, что он вас даже не слушает и вряд ли заинтересован в продолжении диалога. Ранжирующие модели напротив чаще всего отвечают достаточно содержательно и могут брать инициативу на себя, но качество их ответов напрямую зависит от качества и главное размера базы кандидатов. Однако, как это часто бывает из двух возможных вариантов, лучшим оказывается третий. В нашем случае это вариант 2.5 - гибридные модели, совмещающие в себе ранжирующие и генеративные подходы. Однако это уже совсем другая история…
Коды по данному обзору можно посмотреть на здесь.
