Хочу рассказать о нашем опыте разработки приложений на основе платформы полнотекстового поиска Apache Solr.
Перед нами стояла задача разработать систему речевой аналитики для контактных центров. В основе системы две базовых технологии: распознавание речи и индексированный поиск. Для распознавания мы использовали свои движки, а для индексации и поиска выбрали Solr.
Почему именно Solr? Собственных сравнительных исследований движков индексированного поиска мы не проводили, но внимательно ознакомились с мнением коллег. Конечно, выбор мог состояться и в пользу Elasticsearch или Sphinx, но, видимо, звезды в нашем проекте сложились в пользу Solr, его мы и “пилили”. Уже по ходу проекта мы определили, что имеющихся в Solr настроек достаточно для конфигурирования под наши задачи.
Система разрабатывалась для аналитики звонков клиентов, которые записываются в контактном центре для контроля за качеством обслуживания. Анализируется не звук, а текстовки, получаемые в результате автоматического распознавания диалога. Тексты распознанной речи принципиально отличаются от текстов, с которыми мы регулярно сталкиваемся на сайтах или e-mail. Даже при 100% точности распознавания тексты распознанной спонтанной речи могут показаться лишенными какого-либо смысла.
Связано это с двумя основными факторами. Во-первых, в устной речи сплошь и рядом используются невербальные и мимические средства, которые не распознаются в текст, но имеют важное значение для понимания сказанного. Во-вторых, в речи постоянно используются сокращения и пропуски языковых конструкций, которые могут быть восстановлены из контекста коммуникативной ситуации. Это явление в лингвистике называется эллипсис.
Чтобы увидеть своими глазами текст распознанной речи со всеми его особенностями, посмотрите автоматические субтитры к ролику на youtube с отключенным звуком. Вот примерно такого содержания материал поступает на вход системы речевой аналитики.
Хотя Solr поддерживает стандартные условные операторы и группировки, зачастую этих возможностей недостаточно для реализации всех сценариев работы аналитиков.
Часто аналитику необходимо построить запрос с параметрами, не входящими в индекс Solr. Например, найти все слова “спасибо”, которые произнесены в последние 30 секунд беседы. Слова проиндексированы Solr, а временные позиции слов нет. Такие запросы мы и называем “сложными” — запросы, которые включают в себя и параметры индекса Solr, и любые другие параметры отбора данных, которые в индекс Solr не входят.
Аналитик не имеет представления о составе индекса Solr, для него важно проводить поиск и срезы по всем атрибутам фонограмм звонков и их текстовых расшифровок. Поэтому понятие “сложные запрос” для аналитика носит чисто прагматический характер: запросы, в которых параметров отбора много, или запросы расположены в иерархии.
Описывая действия аналитика на языке теории множеств, можно сказать, что с помощью запросов аналитик исследует отношения между различными подмножествами: пересечения, разности, дополнения. С помощью иерархических запросов аналитик разбирает массив данных до необходимого уровня детализации его структуры.

Рисунок 1. Иерархические запросы
На рисунке 2 представлен классический пример сложного запроса, содержащего и текстовые и числовые критерии отбора.
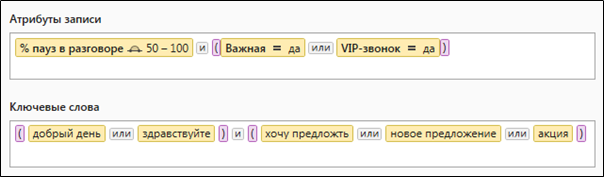
Рисунок 2. Сложный запрос, содержащий количественные и лексические параметры отбора данных
Рассмотрим общий механизм выполнения запроса в Solr на примере запроса B на рисунке 1. Как мы видим, у запроса B есть родительский запрос A, другими словами B⊆A. В речевой аналитике запрос не может быть выполнен, пока хотя бы один из его “родителей” является невыполненным. Таким образом, сначала выполняется запрос A и только потом B. Очевидно, что В должен содержать условия запроса A.
Первое, что приходит на ум, объединить условия обоих запросов через
Однако, если мы будем просто объединять все последовательные запросы в один
Попробуем добавлять родительские запросы как
Если рассматривать формат запроса к Solr схематично, то можно выделить две основные сущности:
Разделение запроса на
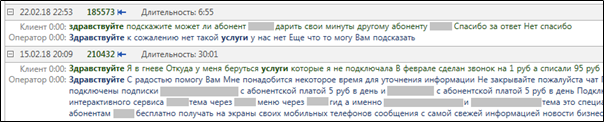
Рисунок 3.
Вернемся к примеру про вежливого оператора. В этом примере мы определили подходящие звонки по наличию в речи оператора словосочетания “добрый день”, но не указывали временной промежуток, в котором необходимо выполнить поиск ключевых слов относительно начала или конца разговора.
Вроде бы, для этого есть все необходимое — текстовая расшифровка телефонного разговора содержит временную метку timestamp для каждого слова, а также информацию о том, кому из участников диалога оно принадлежит. Эти данные также можно использовать при поиске.

Рисунок 4. Фрагмент текстовой расшифровки с разметкой, не входящий в индекс Solr: принадлежность диктору, временные метки.
Но как обработать поисковый запрос к Solr, если в запросе участвует неиндексируемые параметры — время произнесения слова?
Напрашиваются два очевидных способа решения этой задачи:
Нами был выбран второй вариант. Для этого мы разработали сервис, выполняющий вычисление коллекций по запросам, содержащим любые логические и числовые параметры, не входящими в индекс Solr. В результате работы этого сервиса, часть коллекции, не удовлетворяющая запросу, маркировалась специальным тэгом (“экранировалась”) и далее уже не участвовала в вычислении результатов запроса.
Представим, что мы хотим наложить на уже знакомый нам запрос B ограничение на поиск только в первых 30 секундах диалога. На первом этапе мы выполняем B как простой запрос, далее “экранируем” слова выходящие за пределы выбранного диапазона таким образом, чтобы они не попали в индекс Solr, но, при этом, мы могли восстановить из них исходный документ. Получившиеся документы помещаются в отдельную коллекцию Solr и на ней повторно запускается поиск по запросу B.
Тут надо сказать, что ограничения относительно начала или конца разговора это цветочки, ягодки это ограничения относительно результатов родительского запроса. Рассмотрим выполнение подобного запроса.
На практике за шариками 5 и 6 обычно скрываются запросы, занимающие несколько экранов в своём текстовом представлении. Радует, что реализовали мы такой поиск не зря — аналитики очень часто используют запросы с ограничениями от родительских.
Что мы узнали, чему научились и чего достигли в результате проекта?
Мы знаем, как эффективно использовать Solr для работы с данными разного типа, можем “научить” Solr обрабатывать запросы с параметрами, не входящими в его поисковый индекс.
Мы разработали промышленную систему речевой аналитики, работающую под высокой нагрузкой: сложные поисковые запросы аналитиков рассчитываются для выборок до пяти миллионов текстовых документов. Можно и больше, но не возникало практической необходимости. Обычная рабочая выборка аналитика, примерно, до 500 тысяч текстов распознанных телефонных звонков, а общие количество звонков может достигать 15 миллионов.
Для наших клиентов в контактных центрах система предоставляет невиданные ранее возможности для аналитики самого разного характера: анализ тем и причин обращений, анализ удовлетворенности клиентов и многие другие.
Сейчас мы подключаем к нашей аналитике новые источники — текстовые чаты клиентов с операторами. Реализуем единое приложение для аналитики клиентских обращений по всем каналам контактного центра: телефон, чат, формы на сайтах и др.
С удовольствием ответим на ваши вопросы.
Спасибо.
P.S. Solr очень непростая штука и для получение хороших результатов требует хорошей настройки. О нашем опыте на этом поле мы расскажем в следующих статьях.
Перед нами стояла задача разработать систему речевой аналитики для контактных центров. В основе системы две базовых технологии: распознавание речи и индексированный поиск. Для распознавания мы использовали свои движки, а для индексации и поиска выбрали Solr.
Почему именно Solr? Собственных сравнительных исследований движков индексированного поиска мы не проводили, но внимательно ознакомились с мнением коллег. Конечно, выбор мог состояться и в пользу Elasticsearch или Sphinx, но, видимо, звезды в нашем проекте сложились в пользу Solr, его мы и “пилили”. Уже по ходу проекта мы определили, что имеющихся в Solr настроек достаточно для конфигурирования под наши задачи.
Особенности нашего проекта
Система разрабатывалась для аналитики звонков клиентов, которые записываются в контактном центре для контроля за качеством обслуживания. Анализируется не звук, а текстовки, получаемые в результате автоматического распознавания диалога. Тексты распознанной речи принципиально отличаются от текстов, с которыми мы регулярно сталкиваемся на сайтах или e-mail. Даже при 100% точности распознавания тексты распознанной спонтанной речи могут показаться лишенными какого-либо смысла.
Связано это с двумя основными факторами. Во-первых, в устной речи сплошь и рядом используются невербальные и мимические средства, которые не распознаются в текст, но имеют важное значение для понимания сказанного. Во-вторых, в речи постоянно используются сокращения и пропуски языковых конструкций, которые могут быть восстановлены из контекста коммуникативной ситуации. Это явление в лингвистике называется эллипсис.
Чтобы увидеть своими глазами текст распознанной речи со всеми его особенностями, посмотрите автоматические субтитры к ролику на youtube с отключенным звуком. Вот примерно такого содержания материал поступает на вход системы речевой аналитики.
Сложные запросы
Хотя Solr поддерживает стандартные условные операторы и группировки, зачастую этих возможностей недостаточно для реализации всех сценариев работы аналитиков.
Часто аналитику необходимо построить запрос с параметрами, не входящими в индекс Solr. Например, найти все слова “спасибо”, которые произнесены в последние 30 секунд беседы. Слова проиндексированы Solr, а временные позиции слов нет. Такие запросы мы и называем “сложными” — запросы, которые включают в себя и параметры индекса Solr, и любые другие параметры отбора данных, которые в индекс Solr не входят.
Как формирует запросы аналитик?
Аналитик не имеет представления о составе индекса Solr, для него важно проводить поиск и срезы по всем атрибутам фонограмм звонков и их текстовых расшифровок. Поэтому понятие “сложные запрос” для аналитика носит чисто прагматический характер: запросы, в которых параметров отбора много, или запросы расположены в иерархии.
Описывая действия аналитика на языке теории множеств, можно сказать, что с помощью запросов аналитик исследует отношения между различными подмножествами: пересечения, разности, дополнения. С помощью иерархических запросов аналитик разбирает массив данных до необходимого уровня детализации его структуры.
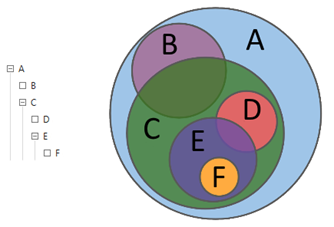
Рисунок 1. Иерархические запросы
На рисунке 2 представлен классический пример сложного запроса, содержащего и текстовые и числовые критерии отбора.
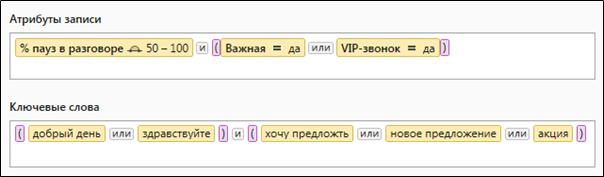
Рисунок 2. Сложный запрос, содержащий количественные и лексические параметры отбора данных
Как выглядят запросы для Solr?
Рассмотрим общий механизм выполнения запроса в Solr на примере запроса B на рисунке 1. Как мы видим, у запроса B есть родительский запрос A, другими словами B⊆A. В речевой аналитике запрос не может быть выполнен, пока хотя бы один из его “родителей” является невыполненным. Таким образом, сначала выполняется запрос A и только потом B. Очевидно, что В должен содержать условия запроса A.
Первое, что приходит на ум, объединить условия обоих запросов через
AND и вставить в query:q=key:A AND key:BОднако, если мы будем просто объединять все последовательные запросы в один
query, он будет большой, для каждого запроса разный и вычисляться будет целиком. Также, условия A будут влиять на релевантность результатов запроса В, чего бы очень не хотелось. Попробуем добавлять родительские запросы как
FilterQuery. В этом случае запрос A не будет влиять не релевантность и мы можем рассчитывать, что он уже выполнен и его результаты находятся в кеше. Таким образом, Solr придется вычислить только запрос B, при этом Solr отсортирует результирующую выборку нужным нам образом: q=keyword:B &fq=keyword:AЕсли рассматривать формат запроса к Solr схематично, то можно выделить две основные сущности:
-
MainQuery— основной запрос с набором параметров, которым должен удовлетворять искомый документ. Например, запрос на поиск вежливых операторов будет выглядеть так:text_operator: ”добрый день”.
Это означает, что поле text_operator искомого документа должно содержать словосочетание“добрый день”
FilterQuery— набор дополнительных фильтров, ограничивающих результирующую выборку. По своему форматуFilterQueryсовпадает сMainQuery
Разделение запроса на
Main и Filter позволяет:- явно указывать, какие параметры запроса должны влиять на ранг документа в выборке, а какие служат только для отбора в результирующую выборку. Релевантность для построения ранга документов рассчитывается при выполнении части запроса MainQuery, а при выполнении части запроса
FilterQueryотсеиваются документы, которые не удовлетворяют условиям запроса - существенно снизить нагрузку на поисковый движок, так как результирующая выборка, полученная после вычислений
FilterQuery, кэшируется полностью, тогда как результаты вычисленияMainQueryхранятся в кэше только для первых в ранге 50-ти значений
MainQuery и FiletrQuery по разному влияют на функции Solr. Например, для highlighting — функции, отвечающей за выделение релевантных фрагментов документа, — имеет значение только MainQuery, а параметры FilterQuery не влияют на highlighting. Это логично, ведь релевантность рассчитывается именно в части запроса MainQuery. Вот так выглядит результаты работы highlighting в реальном запросе на поиск текстов со словами “здравствуйте” и “услуги”.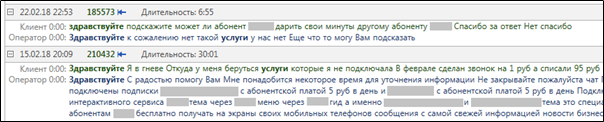
Рисунок 3.
highlighting для релевантных слов после выполнения запроса MainQuery.Сложные запросы в Solr
Вернемся к примеру про вежливого оператора. В этом примере мы определили подходящие звонки по наличию в речи оператора словосочетания “добрый день”, но не указывали временной промежуток, в котором необходимо выполнить поиск ключевых слов относительно начала или конца разговора.
Вроде бы, для этого есть все необходимое — текстовая расшифровка телефонного разговора содержит временную метку timestamp для каждого слова, а также информацию о том, кому из участников диалога оно принадлежит. Эти данные также можно использовать при поиске.
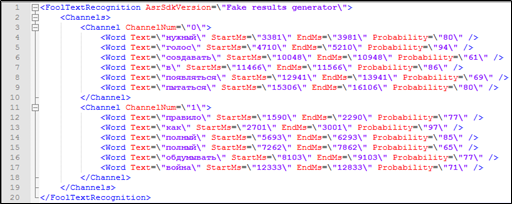
Рисунок 4. Фрагмент текстовой расшифровки с разметкой, не входящий в индекс Solr: принадлежность диктору, временные метки.
Но как обработать поисковый запрос к Solr, если в запросе участвует неиндексируемые параметры — время произнесения слова?
Напрашиваются два очевидных способа решения этой задачи:
- добавить неиндексированные параметры в индекс Solr. При этом, расход памяти увеличится незначительно, но существенно утяжелим индекс
- отбор данных по неиндексируемым параметрам проводить с помощью своего сервиса, а в коллекции документов, полученной после такого отбора, проводить поиск с помощью индекса Solr. При этом, расход памяти будет значительно больше чем в первом случае, но производительность будет прогнозируема
Нами был выбран второй вариант. Для этого мы разработали сервис, выполняющий вычисление коллекций по запросам, содержащим любые логические и числовые параметры, не входящими в индекс Solr. В результате работы этого сервиса, часть коллекции, не удовлетворяющая запросу, маркировалась специальным тэгом (“экранировалась”) и далее уже не участвовала в вычислении результатов запроса.
Представим, что мы хотим наложить на уже знакомый нам запрос B ограничение на поиск только в первых 30 секундах диалога. На первом этапе мы выполняем B как простой запрос, далее “экранируем” слова выходящие за пределы выбранного диапазона таким образом, чтобы они не попали в индекс Solr, но, при этом, мы могли восстановить из них исходный документ. Получившиеся документы помещаются в отдельную коллекцию Solr и на ней повторно запускается поиск по запросу B.
Тут надо сказать, что ограничения относительно начала или конца разговора это цветочки, ягодки это ограничения относительно результатов родительского запроса. Рассмотрим выполнение подобного запроса.
| Представим, что наши документы состоят из шаров с цифрами. Попробуем найти все шары “6”, находящиеся не более чем в двух шарах правее “5”. Вы уже поняли, что номера шаров включены в индекс Solr, а дистанция между шарами нет. |
 |
Найдем все документы с шарами “6” и “5”. В качестве MainQuery используем запрос для шаров “5”, а запрос для “6” отправим в FilterQuery. Как итог Solr подсветит в результатах поиска шары “5”, что сильно упростит нам жизнь на следующем шаге. |
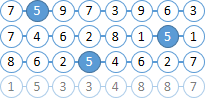 |
| Экранируем все шары кроме тех, которые находятся на нужном нам удалении от “5”. Полученные документы (документы с искомыми шарами) поместим в отдельную коллекцию. |  |
Выполним FilterQuery по шарам “6” в получившейся коллекции, результат — искомые нами документы. |
 |
На практике за шариками 5 и 6 обычно скрываются запросы, занимающие несколько экранов в своём текстовом представлении. Радует, что реализовали мы такой поиск не зря — аналитики очень часто используют запросы с ограничениями от родительских.
Заключение
Что мы узнали, чему научились и чего достигли в результате проекта?
Мы знаем, как эффективно использовать Solr для работы с данными разного типа, можем “научить” Solr обрабатывать запросы с параметрами, не входящими в его поисковый индекс.
Мы разработали промышленную систему речевой аналитики, работающую под высокой нагрузкой: сложные поисковые запросы аналитиков рассчитываются для выборок до пяти миллионов текстовых документов. Можно и больше, но не возникало практической необходимости. Обычная рабочая выборка аналитика, примерно, до 500 тысяч текстов распознанных телефонных звонков, а общие количество звонков может достигать 15 миллионов.
Для наших клиентов в контактных центрах система предоставляет невиданные ранее возможности для аналитики самого разного характера: анализ тем и причин обращений, анализ удовлетворенности клиентов и многие другие.
Сейчас мы подключаем к нашей аналитике новые источники — текстовые чаты клиентов с операторами. Реализуем единое приложение для аналитики клиентских обращений по всем каналам контактного центра: телефон, чат, формы на сайтах и др.
С удовольствием ответим на ваши вопросы.
Спасибо.
P.S. Solr очень непростая штука и для получение хороших результатов требует хорошей настройки. О нашем опыте на этом поле мы расскажем в следующих статьях.
