Комментарии 35
Может быть «байесовы»?
P.S.
Очень круто людей заинтересовывать конечно, спасибо автору. Но вообще кому интересно советую полноценную книгу взять и почитать.
P.S.
Очень круто людей заинтересовывать конечно, спасибо автору. Но вообще кому интересно советую полноценную книгу взять и почитать.
Ну тогда следует добавить и эту книгу.
P(D | θ) – это так называемое правдоподобие (likelihood), вероятность данных при условии зафиксированных параметров модели
а разве не наоборот
 ?
?из вами приведенной ссылки
из английской педивикии
вы называете словом likelihood
а вообще как бы наоборот, функция правдоподобия, likelihood function, или просто likelihood это функция от параметров мадели, при данных данных, простите за тавтологию; я хочу сказать что вероятность данных при фиксированных параметрах это просто условная вероятность данных P(D | θ), а likelihood наоборот
как раз суть maximization шага в EM алгоритме, максимизировать функцию правдоподобия от параметров модели, найти argmax параметров в общем
Фу́нкция правдоподо́бия в математической статистике — это совместное распределение выборки из параметрического распределения, рассматриваемое как функция параметра.
из английской педивикии
In statistics, a likelihood function (often simply the likelihood) is a function of the parameters of a statistical model, defined as follows: the likelihood of a set of parameter values, θ, given some observed outcomes, x, is equal to the probability of those observed outcomes given those parameter values
вы называете словом likelihood
вероятность данных при условии зафиксированных параметров модели
а вообще как бы наоборот, функция правдоподобия, likelihood function, или просто likelihood это функция от параметров мадели, при данных данных, простите за тавтологию; я хочу сказать что вероятность данных при фиксированных параметрах это просто условная вероятность данных P(D | θ), а likelihood наоборот
как раз суть maximization шага в EM алгоритме, максимизировать функцию правдоподобия от параметров модели, найти argmax параметров в общем
Не очень понял посыл. Собственно я отреагировал на Ваше замечание о том, что тождество:
L(\theta) = p( D | \theta)
неверно.
Правдоподобие (Likehood) — вероятность полученной выборки (D) при заданных значениях некоторых параметров модели (\theta), рассматриваемая как функция этих параметров.
Исторически она вводилась для статистических моделей в которых \theta рассматривалась как неизвестная, но не случайная величина. Но потом её обобщили и на СВ.
В этом смысле автор использует понятие верно.
L(\theta) = p( D | \theta)
неверно.
Правдоподобие (Likehood) — вероятность полученной выборки (D) при заданных значениях некоторых параметров модели (\theta), рассматриваемая как функция этих параметров.
Исторически она вводилась для статистических моделей в которых \theta рассматривалась как неизвестная, но не случайная величина. Но потом её обобщили и на СВ.
В этом смысле автор использует понятие верно.
нене, я не сказал
а то что по likelihood function подразумевается не при фиксированных параметрах модели θ, а как раз функция от параметров
вспомните expectation maximization алгоритм, на шаге expectation мы ищем ожидаемые значения данных при фиксированных параметрах θ, а на шаге максимизации мы как раз строим функцию, при фиксированных ожиданиях модели, от параметров модели, затем ищем такие параметры модели, что бы максимизировать вероятность данных. в этом то и суть likelihood function. например можно вычислить градиент f(θ) при данных D, найти максимум функции, и на следующем шаге expectation использовать как раз уже фиксированные θ
что тождество:
L(\theta) = p( D | \theta)
неверно.
а то что по likelihood function подразумевается не при фиксированных параметрах модели θ, а как раз функция от параметров
вспомните expectation maximization алгоритм, на шаге expectation мы ищем ожидаемые значения данных при фиксированных параметрах θ, а на шаге максимизации мы как раз строим функцию, при фиксированных ожиданиях модели, от параметров модели, затем ищем такие параметры модели, что бы максимизировать вероятность данных. в этом то и суть likelihood function. например можно вычислить градиент f(θ) при данных D, найти максимум функции, и на следующем шаге expectation использовать как раз уже фиксированные θ
Фразой «зафиксированных параметров» автор подметил тот факт, что данная вероятность данных D рассматривается при реализованных параметрах \theta. То есть речь об условной плотности вероятности p (D| \theta). То, что \theta нельзя варьировать и тем самым получать функцию от детерминированной величины — автор не утверждал.
Иначе говоря, мы сейчас по-существу доказываем друг другу одно и то же. Просто Вы слова автора интерпретировали по-своему. Тем не менее, я настаиваю, изначальная формулировка верна. Правдоподобие — это действительно «вероятность выборки при фиксированных параметрах», то есть тождественно равно P(D | \theta) и от этого никуда не деться.
Иначе говоря, мы сейчас по-существу доказываем друг другу одно и то же. Просто Вы слова автора интерпретировали по-своему. Тем не менее, я настаиваю, изначальная формулировка верна. Правдоподобие — это действительно «вероятность выборки при фиксированных параметрах», то есть тождественно равно P(D | \theta) и от этого никуда не деться.
Функция правдоподобия – это функция от той переменной, по которой условие; в данном случае от θ.
Поэтому функция правдоподобия – не распределение вероятностей.
Поэтому функция правдоподобия – не распределение вероятностей.
Тачикома для привлечения внимания? o_O
Кстати, возвращаясь к недавнему обсуждению Stand Alone Complex, хочу отметить, что второй сезон, который я досмотрел на днях, получился лучше первого. Если качество сюжетной части можно обсуждать, то построение эпизодов, чередование филлеров и сюжетных серий сделано на порядок лучше, что делает сериал ещё более захватывающим.
Solid State Society тоже крутой.
Так что рекомендую.
Solid State Society тоже крутой.
Так что рекомендую.
Мы назвали нашу рекомендательную систему Тачикома, в честь понятно какого персонажа.
в офисе есть статуэтка Тачикомы, ей делаются подарки и жертвоприношения. А вот и автор статьи вместе с Тачикомой clip2net.com/clip/m7004/1365791351-clip-167kb.png
Не очень понятно, зачем Вы рисуете направленные стрелки. В теории вероятностей нет понятия о причине и следствии. Есть понятие независимости и условной вероятности. Нарисовав направленную стрелку вы приумножили сущности без надобности: все три приведенных связи описывают одни и те же взаимосвязи, только циклически переставляются имена переменных.
Я понимаю, что так проще делать интерпретации с помощью обыденных понятий. Но это в итоге может завести в тупик.
PS Рад что математика у Вас используется во благо технике
Я понимаю, что так проще делать интерпретации с помощью обыденных понятий. Но это в итоге может завести в тупик.
PS Рад что математика у Вас используется во благо технике
Причин и следствий нет, а понятие зависимости одной переменной от другой есть.
И направление стрелок/зависимостей произвольно менять нельзя — случаи «x и y сходятся в z» и «x и y исходят из z» отличаются своими свойствами, как видно из текста.
И направление стрелок/зависимостей произвольно менять нельзя — случаи «x и y сходятся в z» и «x и y исходят из z» отличаются своими свойствами, как видно из текста.
Рассмотрим первую «последовательную картинку». Как вы не меняйте в ней стрелки, всё равно будут верны тождества:
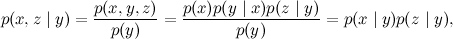
p(x,z) = p(x)p(z)
Если математическая модель неизменна, то в чем разница? По мне, так только в интерпретации.
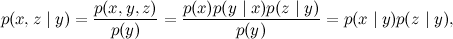
p(x,z) = p(x)p(z)
Если математическая модель неизменна, то в чем разница? По мне, так только в интерпретации.
- x и y исходят из z: x и y зависимы, если z неизвестна. Если z известна — становятся независимы
- x и y сходятся в z: x и y независимы, если z неизвестна. Если z известна — становятся зависимы
Советую посмотреть курс Probabilistic Graphical Models Дафны Коллер на coursera.org, у Вас не останется сомнений, что направленность стрелок очень важна для сетей Байеса. Есть, безусловно, и ненаправленные графические модели, но данная статья ведет речь именно о байесовских
edit: исправил последнее слово

{kind=link}
Судя по приведенной Вами ниже ссылке, стрелки, вероятно, относятся к:
«Байесовская сеть, в которой дуги помимо отношений условной независимости кодируют также отношения причинности, называют причинно-следственными Байесовыми сетями (Causal Bayesian networks[1]).»
Таким образом, стрелки лишь показывают «причинно-следственные связи». И нужны лишь для простоты составления цепи, вряд ли такая абстрактная вещь как причинно-следственная связь может влиять на теор.вер. ИМХО
«Байесовская сеть, в которой дуги помимо отношений условной независимости кодируют также отношения причинности, называют причинно-следственными Байесовыми сетями (Causal Bayesian networks[1]).»
Таким образом, стрелки лишь показывают «причинно-следственные связи». И нужны лишь для простоты составления цепи, вряд ли такая абстрактная вещь как причинно-следственная связь может влиять на теор.вер. ИМХО
Кроме того, если посмотреть прямо определение Байесовской сети, то это направленный граф.
Вообще-то я ровно об этом и пишу. :)
В примерах ниже я несколько погрешу против истины и буду интуитивно интерпретировать ребро, стрелочку между двумя переменными, как «x влияет на y», т.е. по сути как причинно-следственную связь. На самом деле это, конечно, не совсем так – например, часто можно развернуть ребро, не потеряв смысла (вспомните: в графе из двух переменных было всё равно, в какую сторону проводить ребро). Да и вообще это непростой философский вопрос – что такое «причинно-следственные связи» и зачем они нужны. Но для рассуждений на пальцах сойдёт.
И вопрос с подвохом :) А почему именно  ?
?
 ?
?Это был ко мне вопрос? Тогда лучше его пояснить, я его не понял.
Вообще говоря, конечная цель обычно даже не в том, чтобы найти апостериорное распределение, а в том, чтобы потом сделать предсказание. Т.е. найти надо не столько, сколько
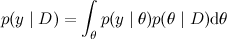
(где y – то, что мы предсказываем, например значение функции, для которой мы строим регрессию, в новой точке, или значение класса для нового объекта в классификаторе). Но часто это посчитать слишком сложно или не нужно; например, часто ожидание предсказательного распределения совпадает со значением в точке максимума θ, а при пересчёте по-байесовски меняется только форма предсказательного распределения, т.е. наша «уверенность» в ответе.
Для этой статьи это было бы уже чересчур; я к этому вернусь позже, когда буду (если до этого вообще дойдёт :) ) говорить о методах, которые сразу считают именно интеграл (например, MCMC сэмплирование часто это делает), а не максимизируют правдоподобие в явном виде сначала.
Вообще говоря, конечная цель обычно даже не в том, чтобы найти апостериорное распределение, а в том, чтобы потом сделать предсказание. Т.е. найти надо не столько
, сколько
(где y – то, что мы предсказываем, например значение функции, для которой мы строим регрессию, в новой точке, или значение класса для нового объекта в классификаторе). Но часто это посчитать слишком сложно или не нужно; например, часто ожидание предсказательного распределения совпадает со значением в точке максимума θ, а при пересчёте по-байесовски меняется только форма предсказательного распределения, т.е. наша «уверенность» в ответе.
Для этой статьи это было бы уже чересчур; я к этому вернусь позже, когда буду (если до этого вообще дойдёт :) ) говорить о методах, которые сразу считают именно интеграл (например, MCMC сэмплирование часто это делает), а не максимизируют правдоподобие в явном виде сначала.
Сформулирую иначе: в своих задачах Вы используете простую функцию потерь при минимизации среднего риска (aka максимум АПВ), а нельзя ли получить какой-то новый профит, воспользовавшись другой ф.п. Скажем, квадратичной (что даст 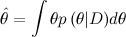 ).
).
Я почитал ваши статьи и материал по ссылкам. Стало понятно, что Вы в основном занимаетесь классификацией, и у Вас набор категорий вместо случайных величин. Тут максимум АПВ логичен. Но если придется рекомендовать что-то количественное, и получится вот такая АПВ:

то с аргументом максимума выйдет промах.
 ).
).Я почитал ваши статьи и материал по ссылкам. Стало понятно, что Вы в основном занимаетесь классификацией, и у Вас набор категорий вместо случайных величин. Тут максимум АПВ логичен. Но если придется рекомендовать что-то количественное, и получится вот такая АПВ:

то с аргументом максимума выйдет промах.
Интересно было бы почитать также и про скрытые марковские сети.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Вероятностные модели: байесовские сети