Очень часто при разработке мобильных приложений (возможно с веб-приложениями та же проблема) разработчики попадают в ситуацию, когда бэкэнд не работает или не предоставляет нужных методов.
Такая ситуация может происходить по разным причинам. Однако, чаще всего на старте разработки, бэкэнд просто не написан и клиент начинает без него. В таком случае начало разработки затягивается на 2-4 месяца.
Иногда сервер просто отключился (упал), иногда не успевает выкатывать нужные методы, иногда есть проблемы с данными и т.п. Все эти проблемы привели нас к написанию небольшого сервиса Mocker, который позволяет подменить реальный бэкэнд.

Как правило, любое клиент-серверное приложение выглядит примерно вот так:

На каждый экран приходится как минимум 1 запрос (а часто больше). Переходя по экранам вглубь, нам нужно сделать все больше и больше запросов. Иногда мы даже не можем сделать переход, до тех пор пока сервер не скажет нам «Покажи кнопку». То есть мобильное приложение очень сильно завязано на сервер, не только во время своей непосредственной работы, но и на этапе разработки. Рассмотрим абстрактный цикл разработки продукта:

Каждый из этих процессов очень важен. Особенно последний, так как заказчик должен понимать на каком этапе мы действительно находимся, а иногда ему нужно отчитываться о результатах перед руководством или инвесторами. Как правило, подобные отчеты происходят, в том числе, в формате демонстрации мобильного приложения. На моей практике был случай, когда заказчик демонстрировал буквально половину MVP, которая работала только на моках. Приложение на моках выглядит как настоящее и крякает как настоящее. Значит оно настоящее (:
Однако это розовая мечта. Давайте рассмотрим, что произойдет на самом деле, если у нас не будет сервера.

В общем, все идет по наклонной. И к сожалению, такие ситуации случаются почти всегда: иногда сервера нет пару месяцев, иногда пол года, иногда просто в процессе сервер сильно опаздывает или необходимо быстро проверить граничные случаи, которые воспроизвести с помощью манипуляций данными на реальном сервере практически невозможно.
Например, мы хотим проверить как поведет себя приложение если у пользователя платеж проходит дольше положенного срока. Воспроизвести такую ситуацию на сервере очень сложно (и долго) и нам надо делать это искусственно.
Таким образом, есть следующие проблемы:
Чтобы бороться с этими проблемами и был создан Mocker.
Mocker — небольшой веб-сервис, который где-то хостится, слушает трафик на каком-то определенном порту и умеет отвечать заранее заготовленными данными на конкретные сетевые запросы.
Последовательность следующая:
1. Клиент отправляет запрос.
2. Mocker получает запрос.
3. Mocker находит нужный мок.
4. Mocker возвращает нужный мок.
Если с пунктами 1,2 и 4 все понятно, то 3 вызывает вопросы.
Для того, чтобы понять, как сервис находит нужный клиенту мок, сначала рассмотрим структуру самого мока.
Мок — это файл с JSON-ом в следующем формате:
Разберем каждое поле отдельно.
Этот параметр используется для того, чтобы указать URL запроса, по которому обращается клиент.
Например, если мобильное приложение делает запрос на url
То есть это поле хранит относительный путь до эндпоинта.
Это поле должно быть отформатировано в формате url-template, то есть допускается использовать следующие форматы:
Таким образом, управляя URL параметрами можно явно определить, что на какой-то определенный url вернется какой-то определенный мок.
Это ожидаемый http method. Например
Строка обязательно должна содержать только заглавные буквы.
Это код http статуса для ответа. То есть запросив этот мок, клиент получит ответ со статусом записанным в поле statusCode.
Это поле содержит JSON объект, который будет отправлен клиенту в теле ответа на его запрос.
Здесь записывается тело запроса, которые ожидается получить от клиента.Это будет использоваться для того, чтобы отдать нужный response в зависимости от тела запроса request. Например, если мы хотим менять ответы в зависимости от параметров запроса.
Если клиент отправит запрос с телом:
То в ответ он получит:
А в случае, если мы хотим проверить, как будет работать приложение если пароль введен неверно, то отправится запрос с телом:
То в ответ он получит:
И мы сможем проверить кейс с неверным паролем. И так для всех остальных кейсов.
А теперь разберемся как работает группировка и поиск нужного мока.

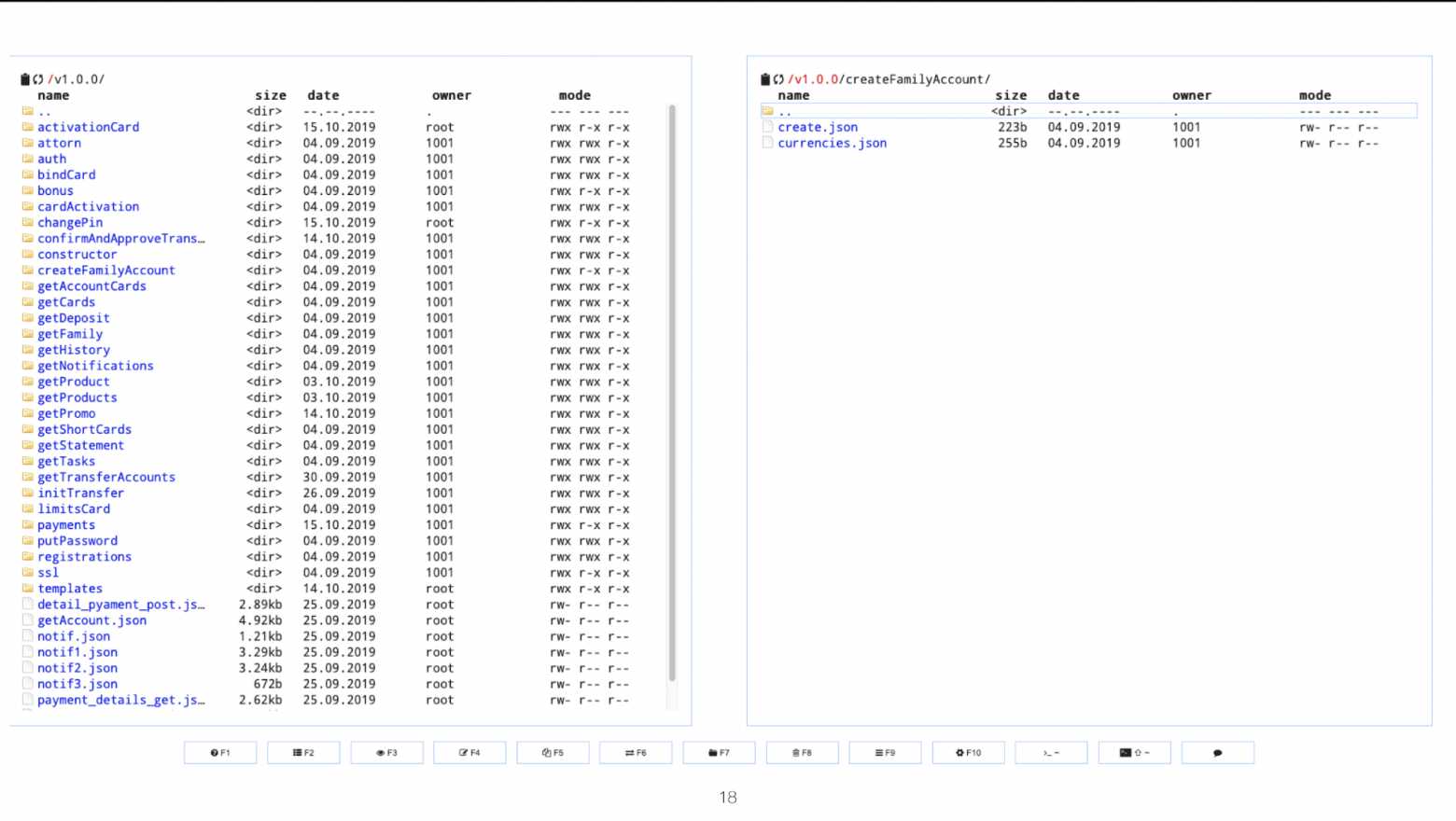
Для того, чтобы быстрее и проще искать нужный мок, сервер загружает все моки в память и нужным образом их группирует. На картинке выше продемонстрирован пример группировки.
Сервер объединяет разные моки по url и method. Это необходимо в том числе и для того, чтобы мы могли создать на один url много разных моков.
Например, мы хотим, чтобы постоянно дергая Pull-To-Refresh, приходили разные ответы и состояние экрана все время менялось (чтобы проверить все граничные кейсы).
Тогда мы можем создать много разных моков с одинаковыми параметрами method и url, а сервер будет возвращать их нам итеративно (по очереди).
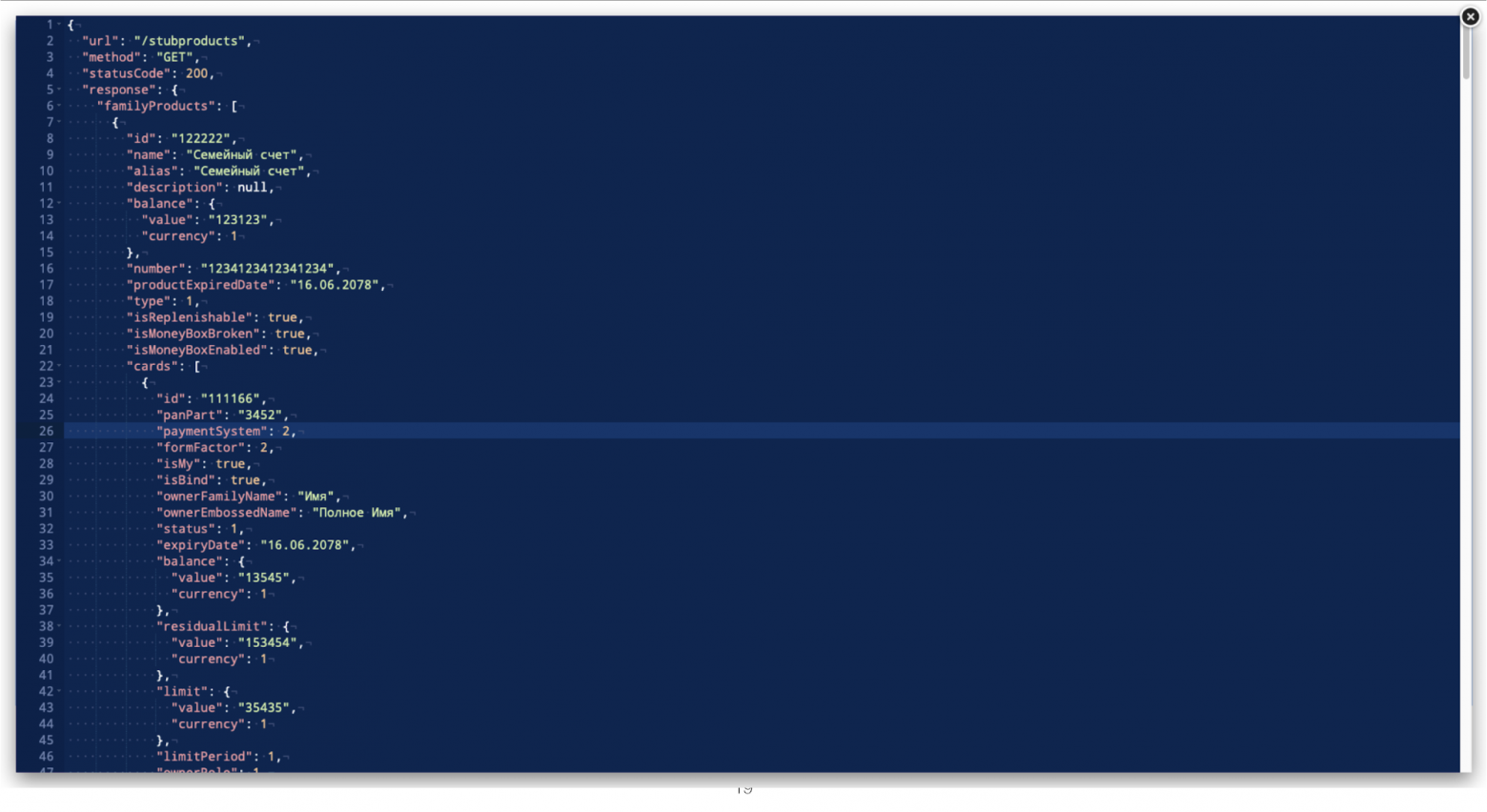
Например, пусть у нас будут такие моки:
Тогда, когда мы первый раз вызовем метод GET /products, то сначала получим в ответ:
Когда вызовем второй раз — указатель итератора сместится на следующий элемент и нам вернется:
И мы сможем проверить как поведет себя приложение если мы получим какие-то большие значения. И так далее.
Ну, а когда мы дойдем до последнего элемента и еще раз вызовем метод, то нам вернется снова первый элемент, потому что итератор возвратится к первому элементу.
Mocker умеет работать в режиме кэширующего прокси. Это означает, что когда сервис получает запрос от клиента, он достает из него адрес хоста, на котором расположен реальный сервер и схему (для определения протокола). Далее берет полученный запрос (со всеми его хедерами, так что если метод требует аутентификации, то ничего страшного, ваш
Получив ответ с 200-м кодом Mocker сохраняет ответ в моковый файл (да, вы потом можете его скопировать или поменять) и возвращает клиенту то, что он получил от реального сервера. Причем, он не просто сохраняет файл в случайное место, а организует файлы так, чтобы с ними можно было затем работать вручную Например, Mocker отправляет запрос по следующему URL:
Чтобы моки не дублировались, название формируется на основе http-метода (GET, PUT...) и хеша от тела ответа реального сервера. В таком случае, если на конкретный ответ уже существует мок, то он просто перезапишется.
Эту фичу можно активировать индивидуально для каждого запроса. Для этого нужно добавить три хедера к запросу:
Иногда хочется, чтобы Mocker возвращал только те моки, которые мы хотим, а не все которые есть в проекте.
Особенно актуально для тестировщиков. Им было бы удобно иметь какой-то заготовленный набор моков для каждого из тест-кейсов. И тогда, во время тестирования, QA просто выбирает нужную ему папку и спокойно работает, потому что больше нет шума из сторонних моков.
Сейчас такое возможно. Для того, чтобы включить эту функцию нужно использовать специальный хедер:
К примеру, пусть у Mocker-а в корне вот такая структура папок
Если необходимо прогнать тест-кейс о заблокированных картах, тогда
Если необходимо прогнать тест-кейс связанный с блокировкой главного экрана, тогда
Сначала мы работали с моками напрямую по по ssh, но с ростом числа моков и пользователей перешли на более удобный вариант. Сейчас мы используем CloudCommander.
В примере docker-compose, он связывается с контейнером Mocker-а.
Выглядит это примерно так:
Ну и бонусом идет web-редактор, который позволяет добавлять/изменять моки прямо из браузера.
Это также временное решение. В в планах уйти от работы с моками через файловую систему к какой-нибудь базе данных. И соответственно, управлять самими моками можно будет из GUI к этой DB.
Для того, чтобы развернуть Mocker проще всего использовать Docker. К тому же, развернув сервис из докера, автоматически развернется web-интерфейс через который удобнее работать с моками. Файлы необходимые для развертывания через Docker лежат в репозитории.
Однако, если вас не устраивает этот вариант, можете самостоятельно собрать сервис из исходников. Для этого достаточно:
Затем нужно написать конфиг файл (пример) и запустить сервис:
Mocker— это web-сервис, который решает проблемы разработки клиент-серверных приложений в том случае, когда сервер по каким-то причинам не готов.
Сервис позволяет создавать множество разных моков на один URL, позволяет связать между собой Request и Response с помощью явного указания параметров в url, либо прямо с помощью задания ожидаемого тела запроса. У сервиса есть web-интерфейс, который сильно упрощает жизнь пользователям.
Каждый пользователь сервиса может самостоятельно добавить нужный endpoint и нужный ему запрос. При этом на клиенте, для того чтобы перейти на настоящий сервер, достаточно просто заменить константу с адресом хоста.
Я надеюсь, что это статья поможет людям, которые страдают от схожих проблем и, возможно, мы вместе будем трудиться над развитием этого инструмента.
Репозиторий на GitHub.
Такая ситуация может происходить по разным причинам. Однако, чаще всего на старте разработки, бэкэнд просто не написан и клиент начинает без него. В таком случае начало разработки затягивается на 2-4 месяца.
Иногда сервер просто отключился (упал), иногда не успевает выкатывать нужные методы, иногда есть проблемы с данными и т.п. Все эти проблемы привели нас к написанию небольшого сервиса Mocker, который позволяет подменить реальный бэкэнд.

Как я к этому пришел
Как я вообще к этому пришел? Заканчивался мой первый год работы в Surf и меня поставили на новенький e-commerce проект. Менеджер сказал, что проект нужно сделать за 4 месяца, но бэкэнд команда (на стороне заказчика) начнет разработку только через 1.5 месяца. А мы за это время должны накидать уже много UI-фич.
Я предложил написать моковый бэкэнд (до того как стать iOS разработчиком я игрался с .NET в универе). Идея реализации была проста: нужно было по заданной спецификации написать методы-заглушки, которые бы брали данные из заранее подготовленных JSON-файлов. На том и порешили.
Через 2 недели я ушел в отпуск и задумался: «А чего бы мне не генерировать все это автоматически?». Так за 2 недели отпуска я написал подобие интерпретатора, который берет спецификацию APIBlueprint и генерит из нее .NET Web App (код на C#).
В итоге появилась первая версия этой штуки и мы жили на ней почти 2.5 месяца. Я не могу привести реальных цифр, насколько это нам помогло, но помню, как на ретроспективе говорили, что если бы не эта система, никакого релиза не было бы.
Сейчас, спустя несколько лет, я учел допущенные мной ошибки (а их было очень много) и полностью переписал инструмент.
Пользуясь случаем — большое спасибо коллегам, которые помогали обратной связью и советами. А также руководителям, которые терпели весь мой «инженерный произвол».
Я предложил написать моковый бэкэнд (до того как стать iOS разработчиком я игрался с .NET в универе). Идея реализации была проста: нужно было по заданной спецификации написать методы-заглушки, которые бы брали данные из заранее подготовленных JSON-файлов. На том и порешили.
Через 2 недели я ушел в отпуск и задумался: «А чего бы мне не генерировать все это автоматически?». Так за 2 недели отпуска я написал подобие интерпретатора, который берет спецификацию APIBlueprint и генерит из нее .NET Web App (код на C#).
В итоге появилась первая версия этой штуки и мы жили на ней почти 2.5 месяца. Я не могу привести реальных цифр, насколько это нам помогло, но помню, как на ретроспективе говорили, что если бы не эта система, никакого релиза не было бы.
Сейчас, спустя несколько лет, я учел допущенные мной ошибки (а их было очень много) и полностью переписал инструмент.
Пользуясь случаем — большое спасибо коллегам, которые помогали обратной связью и советами. А также руководителям, которые терпели весь мой «инженерный произвол».
Введение
Как правило, любое клиент-серверное приложение выглядит примерно вот так:
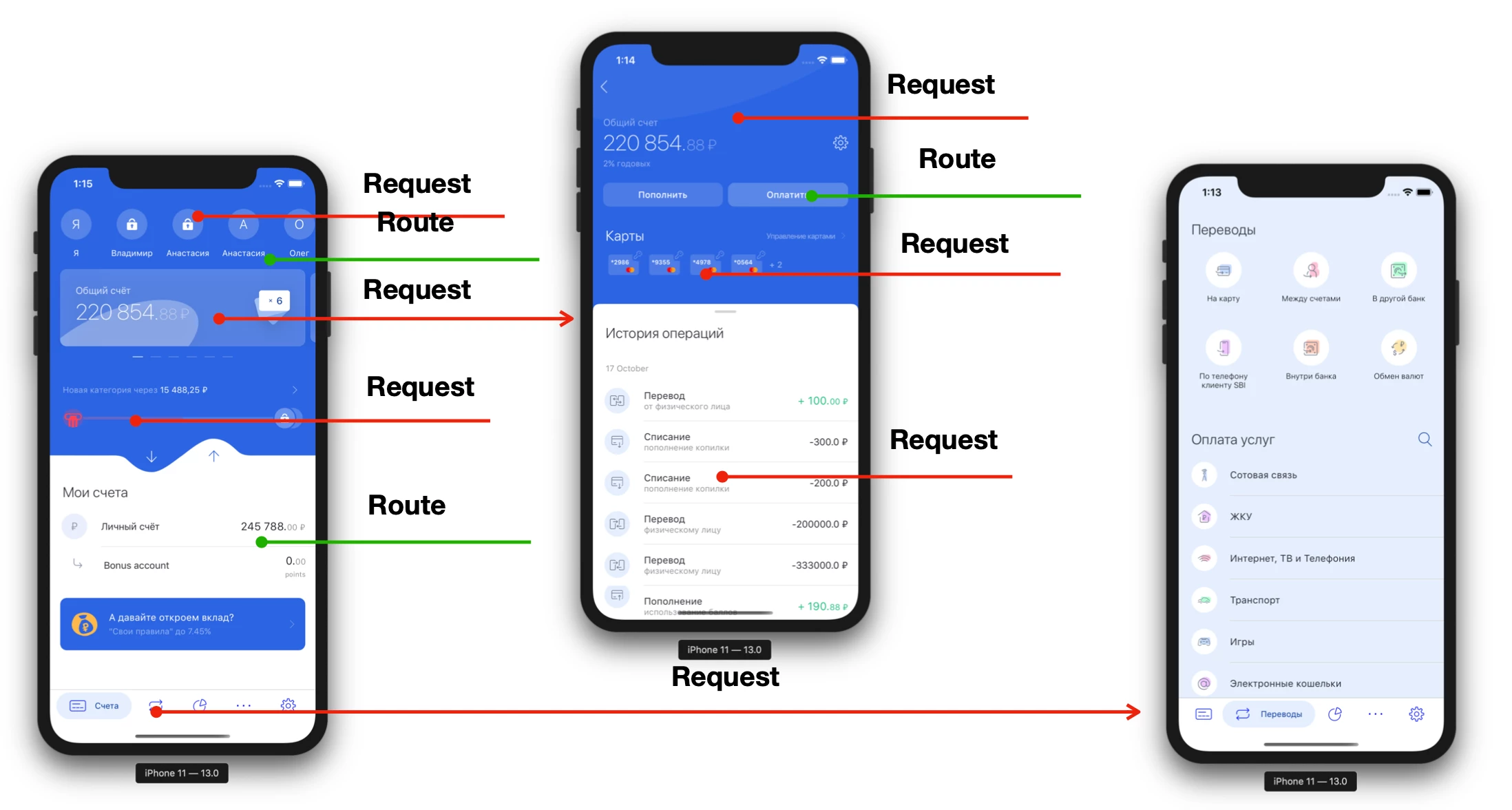
На каждый экран приходится как минимум 1 запрос (а часто больше). Переходя по экранам вглубь, нам нужно сделать все больше и больше запросов. Иногда мы даже не можем сделать переход, до тех пор пока сервер не скажет нам «Покажи кнопку». То есть мобильное приложение очень сильно завязано на сервер, не только во время своей непосредственной работы, но и на этапе разработки. Рассмотрим абстрактный цикл разработки продукта:

- Сначала мы проектируем. Декомпозируем, описываем и обсуждаем.
- Получив задачи и требования, начинаем разработку. Пишем код, верстаем и т.п.
- После того, как мы что-то реализовали, готовится сборка, которая уходит на ручное тестирование, где работа приложения проверяется по разным кейсам.
- Если у нас все нормально, и тестеры апрувят сборку, она уходит заказчику, который выполняет приемку.
Каждый из этих процессов очень важен. Особенно последний, так как заказчик должен понимать на каком этапе мы действительно находимся, а иногда ему нужно отчитываться о результатах перед руководством или инвесторами. Как правило, подобные отчеты происходят, в том числе, в формате демонстрации мобильного приложения. На моей практике был случай, когда заказчик демонстрировал буквально половину MVP, которая работала только на моках. Приложение на моках выглядит как настоящее и крякает как настоящее. Значит оно настоящее (:
Однако это розовая мечта. Давайте рассмотрим, что произойдет на самом деле, если у нас не будет сервера.

- Процесс разработки будет проходить медленнее и болезненнее, так как сервисы мы написать нормально не можем, проверить все кейсы тоже не можем, приходится писать заглушки, которые потом нужно будет удалить.
- После того, как мы с горем пополам сделали сборку, она попадает тестерам, которые смотрят на нее и не понимают что с ней делать. Проверить ничего нельзя, половина вообще не работает, потому что сервера нет. Как следствие — пропускают много багов: как логических, так и визуальных.
- Ну а после «как смогли посмотрели», надо отдать сборку заказчику и тут начинается самое неприятное. Заказчик не может толком оценить работу, он видит 1-2 кейса из всех возможных и уж точно не может показать это своим инвесторам.
В общем, все идет по наклонной. И к сожалению, такие ситуации случаются почти всегда: иногда сервера нет пару месяцев, иногда пол года, иногда просто в процессе сервер сильно опаздывает или необходимо быстро проверить граничные случаи, которые воспроизвести с помощью манипуляций данными на реальном сервере практически невозможно.
Например, мы хотим проверить как поведет себя приложение если у пользователя платеж проходит дольше положенного срока. Воспроизвести такую ситуацию на сервере очень сложно (и долго) и нам надо делать это искусственно.
Таким образом, есть следующие проблемы:
- Сервер отсутствует полностью. Из-за этого невозможно разрабатывать, проверять и презентовать.
- Сервер не успевает, что мешает разрабатывать и может мешать тестировать.
- Мы хотим тестировать граничные кейсы, а сервер не может этого позволить без долгих телодвижений.
- Аффектит тестирование и угрожает презентации.
- Сервер падает (однажды мы уже во время стабильной разработки лишились сервера на 3.5 дня).
Чтобы бороться с этими проблемами и был создан Mocker.
Принцип работы
Mocker — небольшой веб-сервис, который где-то хостится, слушает трафик на каком-то определенном порту и умеет отвечать заранее заготовленными данными на конкретные сетевые запросы.
Последовательность следующая:
1. Клиент отправляет запрос.
2. Mocker получает запрос.
3. Mocker находит нужный мок.
4. Mocker возвращает нужный мок.
Если с пунктами 1,2 и 4 все понятно, то 3 вызывает вопросы.
Для того, чтобы понять, как сервис находит нужный клиенту мок, сначала рассмотрим структуру самого мока.
Мок — это файл с JSON-ом в следующем формате:
{
"url": "string",
"method": "string",
"statusCode": "number",
"response": "object",
"request": "object"
}
Разберем каждое поле отдельно.
url
Этот параметр используется для того, чтобы указать URL запроса, по которому обращается клиент.
Например, если мобильное приложение делает запрос на url
host.dom/path/to/endpoint, то в поле url нам нужно написать /path/to/endpoint.То есть это поле хранит относительный путь до эндпоинта.
Это поле должно быть отформатировано в формате url-template, то есть допускается использовать следующие форматы:
/path/to/endpoint— обычный url адрес. Во время получения запроса сервис будет сравнивать строки посимвольно./path/to/endpoint/{number}— url с path-паттерном. Мок с таким URL будет реагировать на любой запрос, который удовлетворяет этому шаблону./path/to/endpoint/data?param={value}— url c parameter-паттерном. Мок с таким url сработает на запрос, содержащий заданные параметры. При этом, если одного из параметров не будет в запросе, то он не будет соответствовать шаблону.
Таким образом, управляя URL параметрами можно явно определить, что на какой-то определенный url вернется какой-то определенный мок.
method
Это ожидаемый http method. Например
POST или GET. Строка обязательно должна содержать только заглавные буквы.
statusCode
Это код http статуса для ответа. То есть запросив этот мок, клиент получит ответ со статусом записанным в поле statusCode.
response
Это поле содержит JSON объект, который будет отправлен клиенту в теле ответа на его запрос.
request
Здесь записывается тело запроса, которые ожидается получить от клиента.Это будет использоваться для того, чтобы отдать нужный response в зависимости от тела запроса request. Например, если мы хотим менять ответы в зависимости от параметров запроса.
{
"url": "/auth",
"method": "POST",
"statusCode": 200,
"response": {
"token": "cbshbg52rebfzdghj123dsfsfasd"
},
"request": {
"login": "Tester",
"password": "Valid"
}
}
{
"url": "/auth",
"method": "POST",
"statusCode": 400,
"response": {
"message": "Bad credentials"
},
"request": {
"login": "Tester",
"password": "Invalid"
}
}
Если клиент отправит запрос с телом:
{
"login": "Tester",
"password": "Valid"
}
То в ответ он получит:
{
"token": "cbshbg52rebfzdghj123dsfsfasd"
}
А в случае, если мы хотим проверить, как будет работать приложение если пароль введен неверно, то отправится запрос с телом:
{
"login": "Tester",
"password": "Invalid"
}
То в ответ он получит:
{
"message": "Bad credentials"
}
И мы сможем проверить кейс с неверным паролем. И так для всех остальных кейсов.
А теперь разберемся как работает группировка и поиск нужного мока.

Для того, чтобы быстрее и проще искать нужный мок, сервер загружает все моки в память и нужным образом их группирует. На картинке выше продемонстрирован пример группировки.
Сервер объединяет разные моки по url и method. Это необходимо в том числе и для того, чтобы мы могли создать на один url много разных моков.
Например, мы хотим, чтобы постоянно дергая Pull-To-Refresh, приходили разные ответы и состояние экрана все время менялось (чтобы проверить все граничные кейсы).
Тогда мы можем создать много разных моков с одинаковыми параметрами method и url, а сервер будет возвращать их нам итеративно (по очереди).
Например, пусть у нас будут такие моки:
{
"url": "/products",
"method": "GET",
"statusCode": 200,
"response": {
"name": "product",
"currency": 1,
"value": 20
}
}
{
"url": "/products",
"method": "GET",
"statusCode": 200,
"response": {
"name": "gdshfjshhkfhsdgfhshdjgfhjkshdjkfsfgbjsfgskdf",
"currency": 5,
"value": 100000000000
}
}
{
"url": "/products",
"method": "GET",
"statusCode": 200,
"response": null
}
{
"url": "/products",
"method": "GET",
"statusCode": 400,
"response": null
}
Тогда, когда мы первый раз вызовем метод GET /products, то сначала получим в ответ:
{
"name": "product",
"currency": 1,
"value": 20
}
Когда вызовем второй раз — указатель итератора сместится на следующий элемент и нам вернется:
{
"name": "gdshfjshhkfhsdgfhshdjgfhjkshdjkfsfgbjsfgskdf",
"currency": 5,
"value": 100000000000
}
И мы сможем проверить как поведет себя приложение если мы получим какие-то большие значения. И так далее.
Ну, а когда мы дойдем до последнего элемента и еще раз вызовем метод, то нам вернется снова первый элемент, потому что итератор возвратится к первому элементу.
Кэширующий прокси
Mocker умеет работать в режиме кэширующего прокси. Это означает, что когда сервис получает запрос от клиента, он достает из него адрес хоста, на котором расположен реальный сервер и схему (для определения протокола). Далее берет полученный запрос (со всеми его хедерами, так что если метод требует аутентификации, то ничего страшного, ваш
Authorization: Bearer ... перенесется) и вырезает из него служебную информацию (тот самый host и scheme) и отправляет запрос на реальный сервер. Получив ответ с 200-м кодом Mocker сохраняет ответ в моковый файл (да, вы потом можете его скопировать или поменять) и возвращает клиенту то, что он получил от реального сервера. Причем, он не просто сохраняет файл в случайное место, а организует файлы так, чтобы с ними можно было затем работать вручную Например, Mocker отправляет запрос по следующему URL:
hostname.dom/main/products/loans/info. Тогда он создаст папку hostname.dom, затем внутри нее он создаст папку main, внутри нее папку products…Чтобы моки не дублировались, название формируется на основе http-метода (GET, PUT...) и хеша от тела ответа реального сервера. В таком случае, если на конкретный ответ уже существует мок, то он просто перезапишется.
Эту фичу можно активировать индивидуально для каждого запроса. Для этого нужно добавить три хедера к запросу:
X-Mocker-Redirect-Is-On: "true",
X-Mocker-Redirect-Host: "hostaname.ex:1234",
X-Mocker-Redirect-Scheme: "http"
Явное указание пути к мокам
Иногда хочется, чтобы Mocker возвращал только те моки, которые мы хотим, а не все которые есть в проекте.
Особенно актуально для тестировщиков. Им было бы удобно иметь какой-то заготовленный набор моков для каждого из тест-кейсов. И тогда, во время тестирования, QA просто выбирает нужную ему папку и спокойно работает, потому что больше нет шума из сторонних моков.
Сейчас такое возможно. Для того, чтобы включить эту функцию нужно использовать специальный хедер:
X-Mocker-Specific-Path: path
К примеру, пусть у Mocker-а в корне вот такая структура папок
root/
block_card_test_case/
mocks....
main_test_case/
blocked_test_case/
mocks...
Если необходимо прогнать тест-кейс о заблокированных картах, тогда
X-Mocker-Specific-Path: block_card_test_caseЕсли необходимо прогнать тест-кейс связанный с блокировкой главного экрана, тогда
X-Mocker-Specific-Path: main_test_case/blocked_test_caseИнтерфейс
Сначала мы работали с моками напрямую по по ssh, но с ростом числа моков и пользователей перешли на более удобный вариант. Сейчас мы используем CloudCommander.
В примере docker-compose, он связывается с контейнером Mocker-а.
Выглядит это примерно так:
Ну и бонусом идет web-редактор, который позволяет добавлять/изменять моки прямо из браузера.

Это также временное решение. В в планах уйти от работы с моками через файловую систему к какой-нибудь базе данных. И соответственно, управлять самими моками можно будет из GUI к этой DB.
Развертывание
Для того, чтобы развернуть Mocker проще всего использовать Docker. К тому же, развернув сервис из докера, автоматически развернется web-интерфейс через который удобнее работать с моками. Файлы необходимые для развертывания через Docker лежат в репозитории.
Однако, если вас не устраивает этот вариант, можете самостоятельно собрать сервис из исходников. Для этого достаточно:
git clone https://github.com/LastSprint/mocker.git
cd mocker
go build .
Затем нужно написать конфиг файл (пример) и запустить сервис:
mocker config.json
Известные проблемы
- После каждого нового файла надо делать
curl mockerhost.dom/update_modelsдля того, чтобы сервис прочел файлы заново. Я не нашел быстрый и элегантный способ обновлять его иначе - Иногда CloudCommander багует (или я что-то не так сделал) и он не дает редактировать моки, которые были созданы через web-интерфейс. Лечится чисткой кэша у браузера.
- Сервис работает только с
application/json. В планах поддержкаform-url-encoding.
Итог
Mocker— это web-сервис, который решает проблемы разработки клиент-серверных приложений в том случае, когда сервер по каким-то причинам не готов.
Сервис позволяет создавать множество разных моков на один URL, позволяет связать между собой Request и Response с помощью явного указания параметров в url, либо прямо с помощью задания ожидаемого тела запроса. У сервиса есть web-интерфейс, который сильно упрощает жизнь пользователям.
Каждый пользователь сервиса может самостоятельно добавить нужный endpoint и нужный ему запрос. При этом на клиенте, для того чтобы перейти на настоящий сервер, достаточно просто заменить константу с адресом хоста.
Я надеюсь, что это статья поможет людям, которые страдают от схожих проблем и, возможно, мы вместе будем трудиться над развитием этого инструмента.
Репозиторий на GitHub.
