
Вместо вступления
Всем привет! Сегодня хотелось бы поговорить о том, как просто и с удовольствием писать тестируемый код. Дело в том, что в нашей компании мы постоянно контролируем и очень ценим качество наших продуктов. Еще бы – ведь с ними ежедневно работают миллионы человек, и для нас просто недопустимо подвести наших пользователей. Только представьте, наступил срок сдачи отчетности, и вы тщательно и с удовольствием, используя заботливо разработанный нами пользовательский интерфейс СБИС, подготовили документы, еще раз перепроверили каждую циферку и вновь убедились, что встречи с вежливыми людьми из налоговой в ближайшее время не будет. И вот, легким нажатием мыши кликаете на заветную кнопку «Отправить» и тут БАХ! приложение вылетает, документы уничтожаются, жарким пламенем пылает монитор, и кажется, люди в погонах уже настойчиво стучат в двери, требуя сдачи отчетности. Вот как-то так все может и получиться:

Фух… Ну, согласен, с монитором, наверное, все-таки погорячился ;) Но все же возникшая ситуация может оставить пользователя нашего продукта не в самом благостном состоянии духа.
Так вот, поскольку мы в Тензоре дорожим моральным состоянием наших клиентов, то для нас очень важно, чтобы разработанные нами продукты были всеобъемлюще протестированы — у нас в компании во многом это обеспечивают почти что 300 тестировщиков, контролирующих качество наших продуктов. Однако мы стараемся, чтобы качество контролировалось на всех этапах разработки. Поэтому в процессе разработки мы стараемся использовать автоматизированное юнит-тестирование, не говоря уже об интеграционных, нагрузочных и приемных тестах.
Однако на сегодняшний день из нашего опыта собеседований можно отметить, что не все владеют навыками создания тестируемого кода. Поэтому мы хотим рассказать «на пальцах» о принципах создания тестируемого кода, а также показать, как можно создавать юнит-тесты, которые легки в поддержке и модернизации.
Изложенный ниже материал во многом был представлен на конференции C++ Russia, так что вы можете его почитать, послушать и даже посмотреть.
Характеристики хороших юнит-тестов
Одной из первых задач, с которой приходится сталкиваться при написании любого автоматически выполняемого теста, является обработка внешних зависимостей. Под внешней зависимостью будем понимать сущности, с которыми взаимодействует тестируемый код, но над которыми у него нет полного контроля. К таким неподконтрольным внешним зависимостям можно отнести операции, требующие взаимодействия с жестким диском, базой данных, сетевым соединением, генератором случайных чисел и прочим.
Надо сказать, что автоматизированное тестирование можно производить на разных уровнях системы, но мы рассмотрим вопросы, связанные именно с юнит-тестами.
Для наиболее ясного понимания принципов, положенных в основу приведенных ниже примеров, код был упрощен (так, например, опущены квалификаторы const). Сами же примеры тестов реализованы с использованием библиотеки GoogleTest.
Одно из наиболее важных отличий интеграционного теста от юнит-теста в том, что юнит-тест имеет полный контроль над всеми внешними зависимостями. Это позволяет достичь того, что отдельно взятый юнит-тест обладает следующими свойствами:
- повторяем — в результате запуска тест на выходе всегда выдает одно и то же значение (всегда приводит систему в одно и то же состояние);
- стабилен — в какое бы время дня и ночи тест бы не запускался, он либо всегда проходит, либо всегда не проходит;
- изолирован — порядок запуска всех имеющихся юнит-тестов, а также действия, выполняемые внутри тестов, никак не влияют на результат выполнения отдельно взятого юнит-теста.
Все это приводит к тому, что запуск множества юнит-тестов, обладающих описанными свойствами, можно автоматизировать и осуществлять, по сути, нажатием одной кнопки.
Хороший юнит-тест выполняется быстро. Потому что если в проекте тестов много, и прогон каждого из них будет длительным, то прогон всех тестов займет уже значительное время. Это может привести к тому, что при изменениях кода прогон всех юнит-тестов будет производиться все реже, из-за этого время получения реакции системы на изменения увеличится, а значит увеличится и время обнаружения внесенной ошибки.
Говорят, что у некоторых с тестированием приложений все складывается гораздо проще, но нам, простым смертным, не обладающим такой скоростной вертушкой, приходится не так сладко. Так что будем разбираться дальше.

Юнит-тестирование. С чего все начинается
Написание любого юнит-теста начинается с выбора его имени. Один из рекомендуемых подходов к наименованию юнит-теста – формировать его имя из трех частей:
— имя тестируемой рабочей единицы
— сценарий теста
— ожидаемый результат
Таким образом, мы можем получить, например, такие имена: Sum_ByDefault_ReturnsZero, Sum_WhenCalled_CallsTheLogger. Они читаются как завершенное предложение, а это повышает простоту работы с тестами. Чтобы понять, что тестируется, достаточно, без вникания в логику работы кода, просто прочитать названия тестов.
Но в ряде случаев с логикой работы тестового кода все-таки нужно разбираться. Чтобы упростить эту работу, структуру юнит-теста можно формировать из трех частей:
— часть Arrange — здесь производится создание и инициализация требуемых для проведения теста объектов
— часть Act — собственно проведение тестируемого действия
— часть Assert — здесь производится сравнение полученного результата с эталонным
Для того чтобы повысить читабельность тестов рекомендуется эти части отделять друг от друга пустой строкой. Это сориентирует тех, кто читает ваш код, и поможет быстрее найти ту часть теста, которая их интересует больше всего.
При покрытии логики работы кода юнит-тестами каждый модуль тестируемого кода должен выполнять одно из следующих действий. Так, тестированию можно подвергать:
— возвращаемый результат
— изменение состояния системы
— взаимодействие между объектами
В первых двух случаях мы сталкиваемся с задачей разделения. Она заключается в том, чтобы не вводить в средства тестирования код, над которым мы не имеем полного контроля. В последнем случае приходится решать задачу распознавания. Она заключается в том, чтобы получить доступ к значениям, которые недоступны для тестируемого кода: например, когда нужен контроль получения логов удаленным web-сервером.
Чтобы писать тестируемый код, надо уметь реализовывать и применять по назначению поддельные объекты (fake objects).
Существует несколько подходов к классификации поддельных объектов, Мы рассмотрим одну из базовых, которая соответствует задачам, решаемым в процессе создания тестируемого кода.
Она выделяет два класса поддельных объектов: stub-объекты и mock-объекты. Они предназначены для решения разных задач: stub-объект – для решения задачи разделения, а mock-объект – для решения задачи распознавания. Наибольшая разница заключается в том, что при использовании stub-объекта assert (операция сравнения полученного результата с эталонным) производится между тестовым и тестируемым кодом, а использование mock-объекта предполагает его анализ, который и показывает пройден тест или нет.
Если логику работы можно протестировать на основе анализа возвращаемого значения или изменения состояния системы, то так и сделайте. Как показывает практика, юнит-тесты, которые используют mock-объекты сложнее создавать и поддерживать, чем тесты, использующие stub-объекты.
Рассмотрим приведенные принципы на примере работы с унаследованным (legacy) кодом. Пусть у нас есть класс EntryAnalyzer, представленный на рис. 1, и мы хотим покрыть юнит-тестами его публичный метод Analyze. Это связано с тем, что мы планируем изменять этот класс, или же хотим таким образом задокументировать его поведение.
Для покрытия кода тестами определим его внешние зависимости. В нашем случае этих зависимостей две: работа с базой данных и работа с сетевым соединением, которая проводится в классах WebService и DatabaseManager соответственно.
class EntryAnalyzer {
public:
bool Analyze( std::stringename ) {
if( ename.size() < 2 ) {
webService.LogError( "Error: "+ ename );
return false;
}
if( false== dbManager.IsValid( ename ) )
return false;
return true;
}
private:
DatabaseManager dbManager;
WebService webService;
};Рис.1. Код тестируемого класса, не пригодный для покрытия юнит-тестами
Таким образом, для класса EntryAnalyzer они и являются внешними зависимостями. Потенциально, между проверкой dbManager.IsValid и финальной инструкцией «return true» может присутствовать код, требующий тестирования. При написании тестов получить доступ к нему мы сможем только после избавления от существующих внешних зависимостей. Для упрощения дальнейшего изложения такой дополнительный код не приведен.
Теперь рассмотрим способы разрыва внешних зависимостей. Структура данных классов приведена на рис. 2.
class WebService {
public:
void LogError( std::string msg ) {
/* логика, включающая
работу с сетевым соединением*/
}
};
class DatabaseManager {
public:
bool IsValid( std::string ename ) {
/* логика, включающая
операции чтения из базы данных*/
}
};Рис.2. Структура классов для работы с сетевым соединением и базой данных
Для написания тестируемого кода очень важно уметь разрабатывать, опираясь на контракты, а не на конкретные реализации. В нашем случае контрактом исходного класса является определение, валидно или нет имя ячейки (entry).
На языке С++ данный контракт может быть задокументирован в виде абстрактного класса, который содержит виртуальный метод IsValid, тело которого определять не требуется. Теперь можно создать два класса, реализующих этот контракт: первый будет взаимодействовать с базой данных и использоваться в «боевой» (production) версии нашей программы, а второй будет изолирован от неподконтрольных зависимостей и будет использоваться непосредственно для проведения тестирования. Описанная схема приведена на рис. 3.
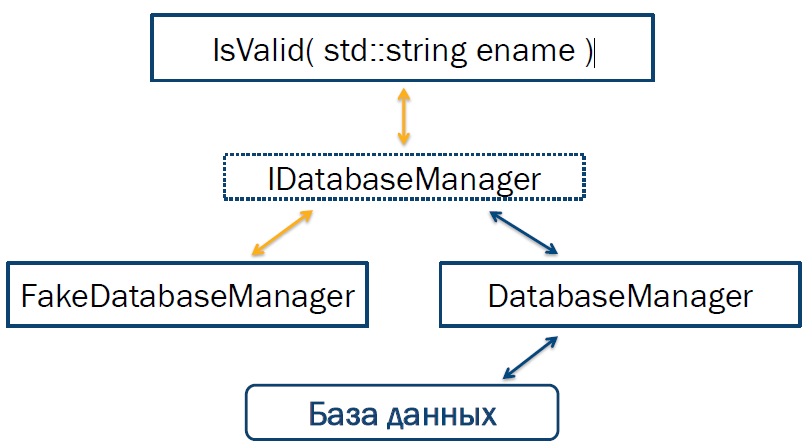
Рис.3. Введение интерфейса для разрыва зависимости от взаимодействия с базой данных
Пример кода, позволяющий осуществить разрыв зависимости, в нашем случае от базы данных, представлен на рис. 4.

Рис.4. Пример классов, позволяющих осуществить разрыв зависимости от базы данных
В приведенном коде следует обратить внимание на спецификатор override у методов, реализующих функционал, заданный в интерфейсе. Это повышает надежность создаваемого кода, так как он явно указывает компилятору, что сигнатуры этих двух функций должны совпадать.
Также следует обратить внимание на объявление деструктора абстрактного класса виртуальным. Если это выглядит удивительно и неожиданно, то можно сгонять за книгой С. Майерса “Эффективное использование С++” и читать ее взахлеб, причем особое внимание уделить приведенному там правилу №7;).
Спойлер для особо нетерпеливых
это необходимо, чтобы избежать утечек памяти при уничтожении объекта производного класса через указатель на базовый класс.
Разрыв зависимости с использованием stub-объектов
Рассмотрим шаги, которые нужны для тестирования нашего класса EntryAnalyzer. Как было сказано выше, реализация тестов с использованием stub-объектов несколько проще, чем с использование mock-объектов. Поэтому сначала рассмотрим способы разрыва зависимости от базы данных.
Способ 1. Параметризация конструктора
Вначале избавимся от жестко заданного использования класса DatabaseManager. Для этого перейдем к работе с указателем, типа IDatabaseManager. Для сохранения работоспособности класса нам также нужно определить конструктор «по умолчанию», в котором мы укажем необходимость использования «боевой» реализации. Внесенные изменения и полученный видоизмененный класс представлены на рис. 5.

Рис.5. Класс после рефакторинга, который позволяет осуществить разрыв зависимости от базы данных
Для внедрения зависимости следует добавить еще один конструктор класса, но теперь уже с аргументом. Этот аргумент как раз и будет определять, какую реализацию интерфейса следует использовать. Конструктор, который будет использоваться для тестирования класса, представлен на рис. 6.

Рис.6. Конструктор, используемый для внедрения зависимости
Теперь наш класс выглядит следующим образом (зеленой рамкой обведен конструктор, используемый для тестирования класса):
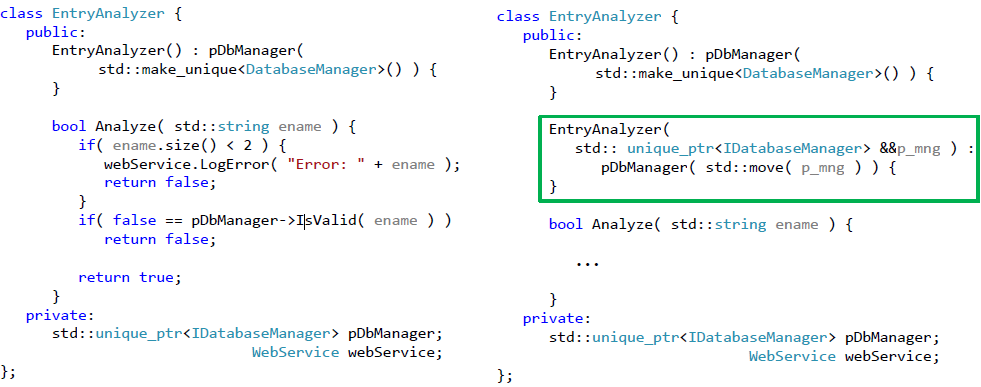
Рис.7. Рефакторинг класса, позволяющий осуществить разрыв зависимости от базы данных
Теперь мы можем написать следующий тест, демонстрирующий результат обработки валидного имени ячейки (см. рис. 8):
TEST_F( EntryAnalyzerTest, Analyze_ValidEntryName_ReturnsTrue )
{
EntryAnalyzer ea( std::make_unique<FakeDatabaseManager>( true ) );
bool result = ea.Analyze( "valid_entry_name" );
ASSERT_EQ( result, true );
}
class FakeDatabaseManager : public IDatabaseManager {
public:
bool WillBeValid;
FakeDatabaseManager( bool will_be_valid ) :
WillBeValid( will_be_valid ) {
}
bool IsValid( std::string ename ) override {
return WillBeValid;
}
};Рис.8. Пример теста, не взаимодействующего с реальной базой данных
Изменение значения параметра конструктора fake-объекта влияет на результат выполнения функции IsValid. Кроме того, это позволяет повторно использовать fake-объект в тестах, требующих как утвердительные, так и отрицательные результаты обращения к базе данных.
Рассмотрим второй способ параметризации конструктора. В этом случае нам потребуется использование фабрик — объектов, которые являются ответственными за создание других объектов.
Вначале проделаем все те же шаги по замене жестко заданного использования класса DatabaseManager – перейдем к использованию указателя на объект, реализующий требуемый интерфейс. Но теперь в конструкторе «по умолчанию» возложим обязанности по созданию требуемых объектов на фабрику.
Получившаяся реализация приведена на рис. 9.
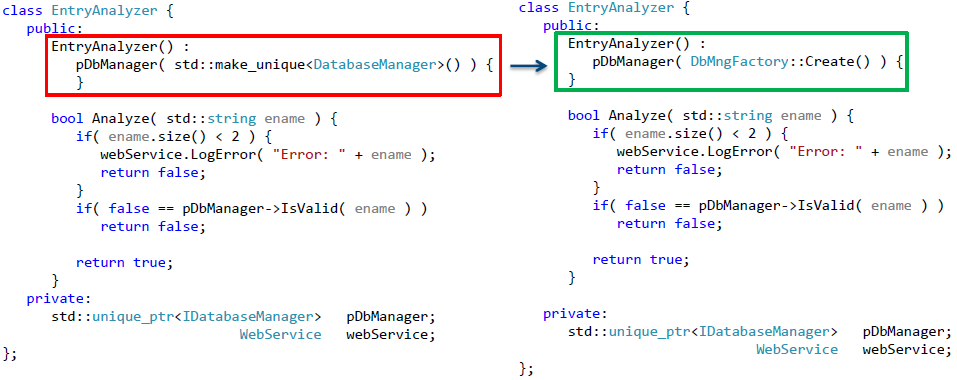
Рис. 9. Рефакторинг класса с целью использования фабрик для создания объекта, взаимодействующего с базой данных
С учетом введенного фабричного класса, сам тест теперь можно написать следующим образом:
TEST_F( EntryAnalyzerTest,
Analyze_ValidEntryName_ReturnsTrue )
{
DbMngFactory::SetManager(
std::make_unique<FakeDatabaseManager>( true ) );
EntryAnalyzer ea;
bool result = ea.Analyze( "valid_entry_name" );
ASSERT_EQ( result, true );
}
class DbMngFactory {
public:
static std::unique_ptr<IDatabaseManager> Create() {
if( nullptr == pDbMng )
return std::make_unique<DatabaseManager>();
return std::move( pDbMng );
}
static void SetManager(
std::unique_ptr<IDatabaseManager> &&p_mng ) {
pDbMng = std::move( p_mng );
}
private:
static std::unique_ptr<IDatabaseManager> pDbMng;
};Рис.10. Еще один пример теста, не взаимодействующего с реальной базой данных
Важное отличие данного подхода от ранее рассмотренного – использование одного и того же конструктора для создания объектов как для «боевого», так и для тестового кода. Всю заботу по созданию требуемых объектов берет на себя фабрика. Это позволяет разграничить зоны ответственности классов. Конечно, человеку, который будет разбираться с вашим кодом, потребуется некоторое время для понимания взаимоотношений этих классов. Однако в перспективе этот подход позволяет добиться более гибкого кода, приспособленного для долгосрочной поддержки.
Способ 2. «Выделить и переопределить»
Рассмотрим еще один поход к разрыву зависимости от базы данных — «Выделить и переопределить» (Extract and override). Возможно, его применение покажется более простым и таких вот эмоций не вызовет:

Его основная идея в том, чтобы локализовать зависимости «боевого» класса в одной или нескольких функциях, а затем переопределить их в классе-наследнике. Рассмотрим на практике этот подход.
Начнем с локализации зависимости. В нашем случае зависимость заключается в обращении к методу IsValid класса DatabaseManager. Мы можем выделить эту зависимость в отдельную функцию. Обратите внимание, что изменения следует вносить максимально осторожно. Причина – в отсутствии тестов, с помощью которых можно удостовериться, что эти изменения не сломают существующую логику работы. Для того чтобы вносимые нами изменения были наиболее безопасными, необходимо стараться максимально сохранять сигнатуры функций. Таким образом, вынесем код, содержащий внешнюю зависимость, в отдельный метод (см. рис. 11).

Рис.11. Вынесение кода, содержащего внешнюю зависимость в отдельный метод
Каким же образом можно провести тестирование нашего класса в этом случае? Все просто – объявим выделенную функцию виртуальной, отнаследуем от исходного класса новый класс, в котором и переопределим функцию базового класса, содержащего зависимость. Так мы получили класс, свободный от внешних зависимостей – и теперь его можно смело вводить в средства тестирования для покрытия тестами. На рис. 12 представлен один из способов реализации такого тестируемого класса.
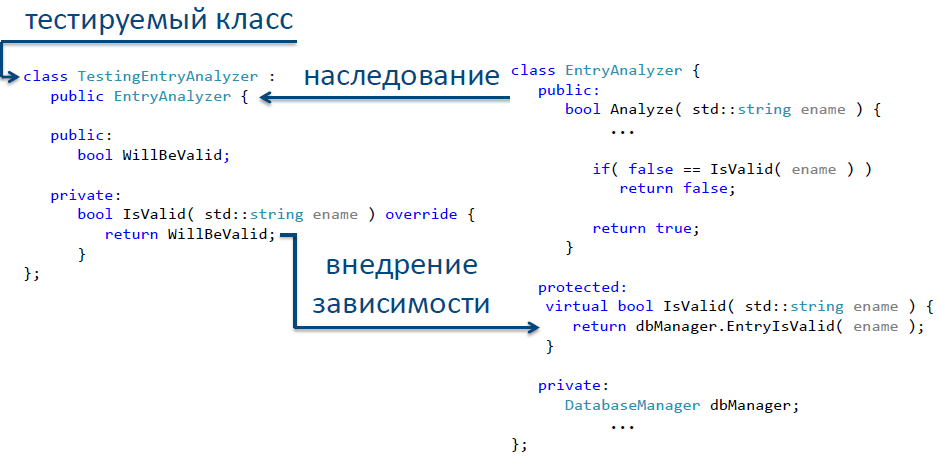
Рис.12. Реализация метода «Выделить и переопределить» для разрыва зависимости
Сам тест теперь можно написать следующим образом:
TEST_F( EntryAnalyzerTest, Analyze_ValidEntryName_ReturnsTrue)
{
TestingEntryAnalyzer ea;
ea.WillBeValid = true;
bool result = ea.Analyze( "valid_entry_name" );
ASSERT_EQ( result, true );
}
class TestingEntryAnalyzer : public EntryAnalyzer {
public:
bool WillBeValid;
private:
bool IsValid( std::string ename ) override {
return WillBeValid;
}
};Рис.13. И еще один пример теста, не взаимодействующего с реальной базой данных
Описанный подход является одним из самых простых в реализации, и его полезно иметь в арсенале своих навыков.
Разрыв зависимости с использованием mock-объектов
Теперь мы умеем разрывать зависимости от базы данных с использованием stub-объектов. Но у нас еще осталась необработанной зависимость от удаленного web-сервера. С помощью mock-объекта мы можем разорвать эту зависимость.
Что же надо для этого сделать? Здесь нам пригодится комбинация из уже рассмотренных методов. Вначале локализуем нашу зависимость в одной из функций, которую затем объявим виртуальной. Не забываем при этом сохранять сигнатуры функций! Теперь выделим интерфейс, определяющий контракт класса WebService и вместо явного использования класса будем использовать указатель unique_ptr требуемого типа. И создадим класс-наследник, в котором эта виртуальная функция будет переопределена. Полученный после рефакторинга класс представлен на рис. 14.

Рис.14. Класс после рефакторинга, подготовленный для разрыва зависимости от сетевого взаимодействия
Введем в класс-наследник указатель shared_ptr на объект, реализующий выделенный интерфейс. Все, что нам осталось — это использовать метод параметризации конструктора для внедрения зависимости. Теперь наш класс, который теперь можно протестировать, выглядит следующим образом:
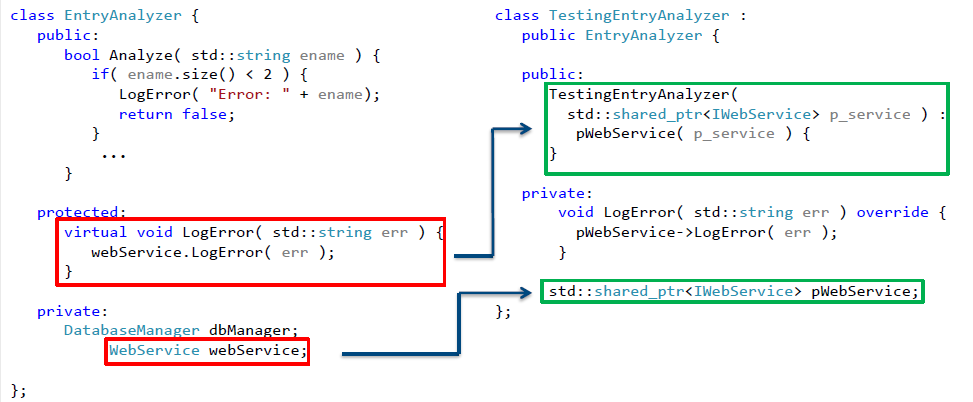
Рис.15. Тестируемый класс, позволяющий осуществить разрыв зависимости от сетевого взаимодействия
И теперь мы можем написать следующий тест:
TEST_F( EntryAnalyzerTest, Analyze_TooShortEntryName_LogsErrorToWebServer )
{
std::shared_ptr<FakeWebService> p_web_service =
std::make_shared<FakeWebService>();
TestingEntryAnalyzer ea( p_web_service );
bool result = ea.Analyze( "e" );
ASSERT_EQ( p_web_service->lastError, "Error: e" );
}
class TestingEntryAnalyzer : public EntryAnalyzer {
public:
TestingEntryAnalyzer(
std::shared_ptr<IWebService> p_service ) :
pWebService( p_service ) {
}
private:
void LogError( std::string err ) override {
pWebService->LogError( err );
}
std::shared_ptr<IWebService> pWebService;
};
class FakeWebService : public IWebService {
public:
void LogError( std::string error ) override {
lastError = error;
}
std::string lastError;
};Рис.16. Пример теста, не взаимодействующего с сетевым соединением
Таким образом, внедрив зависимость с помощью параметризации конструктора, на основе анализа состояния mock-объекта мы можем узнать, какие сообщения будет получать удаленный web-сервис.
Рекомендации для создания тестов, легких для поддержки и модернизации
Рассмотрим же теперь подходы к построению юнит-тестов, которые легки в поддержке и модернизации. Возможно, во многом это опять же связано с недоверием к самому себе.

Первая рекомендация заключается в том, что один тест должен тестировать только один результат работы. В этом случае, если тест не проходит, то можно сразу однозначно сказать, какая часть логики работы «боевого» кода не прошла проверку. Если же в одном тесте содержится несколько assert, то без повторного прогона теста и последующего дополнительного анализа тяжело однозначно сказать, где именно была нарушена логика.
Вторая рекомендация в том, что тестированию следует подвергать только публичные методы класса. Это связано с тем, что публичные методы, по сути, определяют контракт класса — то есть тот функционал, который он обязуется выполнить. Однако конкретная реализация его выполнения остается на его усмотрение. Таким образом, в ходе развития проекта может быть изменен способ выполнения того или иного действия, что может потребовать изменения логики работы приватных методов класса. В итоге это может привести к непрохождению ряда тестов, написанных для приватных методов, хотя сам публичный контракт класса при этом не нарушен. Если тестирование приватного метода все-таки требуется, рекомендуется найти публичный метод у класса, который его использует и написать тест уже относительно него.
Однако порой тесты не проходят, и приходится разбираться, что же пошло не так. При этом довольно неприятная ситуация может возникнуть, если ошибка содержится в самом тесте. Как правило, в первую очередь причины непрохождения мы начинаем искать именно в логике работы тестируемого «боевого» кода, а не самого теста. В этом случае на поиск причины непрохождения может быть потрачена куча времени. Для того чтобы этого избежать, надо стремиться к тому, чтобы сам тестовый код был максимально простым – избегайте использования в тесте каких-либо операторов ветвления (switch, if, for, while и пр.). Если же необходимо протестировать ветвление в «боевом» коде, то лучше написать два отдельных теста для каждой из веток. Таким образом, типовой юнит-тест можно представить как последовательность вызовов методов с дальнейшим assert.
Рассмотрим теперь следующую ситуацию: есть класс, для которого написано большое количество тестов, например, 100. Внутри каждого из них требуется создание тестируемого объекта, конструктору которого требуется один аргумент. Однако с ходом развития проекта, ситуация изменилась — и теперь одного аргумента недостаточно, и нужно два. Изменение количества параметров конструктора приведет к тому, что все 100 тестов не будут успешно компилироваться, и для того чтобы привести их в порядок придется внести изменения во все 100 мест.
Чтобы избежать такой ситуации, давайте следовать хорошо известному нам всем правилу: «Избегать дублирования кода». Этого можно добиться за счет использования в тестах фабричных методов для создания тестируемых объектов. В этом случае при изменении сигнатуры конструктора тестируемого объекта достаточно будет внести соответствующую правку только в одном месте тестового проекта.
Это может значительно сократить время, затрачиваемое на поддержку существующих тестов в работоспособном состоянии. А это может оказаться особенно важным в ситуации, когда в очередной раз нас будут поджимать все сроки со всех сторон.

Стало интересно? Можно погрузиться глубже.
Для дальнейшего и более подробного погружения в тему юнит-тестирования советую книгу Roy Osherove «The art of unit testing». Кроме того, довольно часто также возникает ситуация, когда требуется внести изменения в уже существующий код, который не покрыт тестами. Один из наиболее безопасных подходов заключается в том, чтобы вначале создать своеобразную «сетку безопасности» — покрыть его тестами, а затем уже внести требуемые изменения. Такой подход очень хорошо описан в книге М. Физерса «Эффективная работа с унаследованным кодом». Так что освоение описанных авторами подходов может принести нам, как разработчикам, в арсенал очень важные и полезные навыки.
Спасибо за уделенное время! Рад, если что-то из выше изложенного окажется полезным и своевременным. С удовольствием постараюсь ответить в комментариях на вопросы, если такие возникнут.
Автор: Виктор Ястребов vyastrebov
