Большая часть оптимизаций запросов к базам PostgreSQL может выполняться "механически", следуя разного рода маркерам в плане выполнения запроса, которые подскажут, что и как можно ускорить. Но "глубинные" переработки алгоритма, вроде описанных в статье про DBA-детектив, требуют от разработчика детального понимания используемой структуры логических связей.
И хорошо, когда эта структура уже где-то описана и детально задокументирована. Но плохо, когда такая документация ничтожно мала, избыточно велика, сложно доступна...
А ведь она уже и так находится "под ногами" в момент анализа плана запроса - надо только лишь удобно увидеть ее!

Давайте проведем анализ на примере совсем простого запроса:
EXPLAIN (ANALYZE, COSTS OFF)
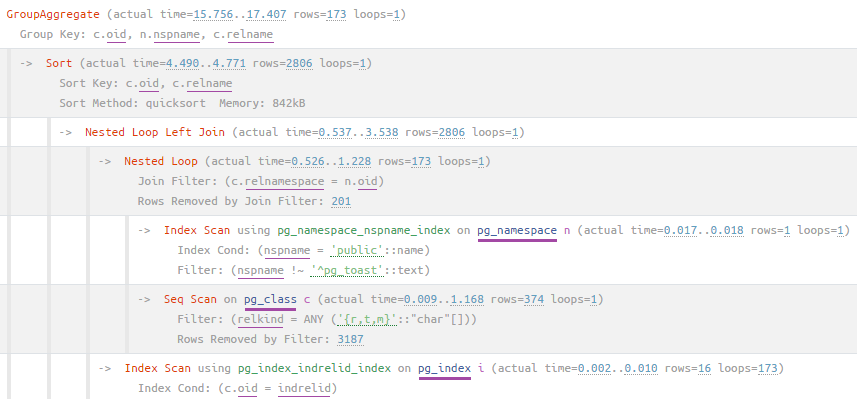
SELECT * FROM pg_stat_user_tables WHERE schemaname = 'public';GroupAggregate (actual time=15.756..17.407 rows=173 loops=1)
Group Key: c.oid, n.nspname, c.relname
-> Sort (actual time=4.490..4.771 rows=2806 loops=1)
Sort Key: c.oid, c.relname
Sort Method: quicksort Memory: 842kB
-> Nested Loop Left Join (actual time=0.537..3.538 rows=2806 loops=1)
-> Nested Loop (actual time=0.526..1.228 rows=173 loops=1)
Join Filter: (c.relnamespace = n.oid)
Rows Removed by Join Filter: 201
-> Index Scan using pg_namespace_nspname_index on pg_namespace n (actual time=0.017..0.018 rows=1 loops=1)
Index Cond: (nspname = 'public'::name)
Filter: (nspname !~ '^pg_toast'::text)
-> Seq Scan on pg_class c (actual time=0.009..1.168 rows=374 loops=1)
Filter: (relkind = ANY ('{r,t,m}'::"char"[]))
Rows Removed by Filter: 3187
-> Index Scan using pg_index_indrelid_index on pg_index i (actual time=0.002..0.010 rows=16 loops=173)
Index Cond: (c.oid = indrelid)
Planning time: 2.398 ms
Execution time: 17.660 msВо-первых, конечно, воспользуемся нашим сервисом визуализации планов explain.tensor.ru, чтобы увидеть структуру более наглядно:
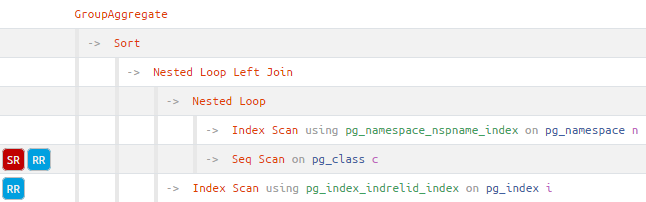
Маркеры-подсказки сразу акцентируют внимание на тех узлах, которые можно попробовать относительно легко оптимизировать. Но нам интересны сейчас не они, а те три таблицы, которые присутствуют в плане, и их поля:
Итак, мы получили следующую информацию:
при выполнении запроса к системному представлению
pg_stat_user_tablesзадействуются три таблицы:pg_namespace(алиасn),pg_class(алиасc) иpg_index(алиасi)
дополнительно мы получили информацию о существовании в них полей
c.oid, c.relname, c.relnamespace, c.relkind, n.oid, n.nspname, i.indrelidтакже мы видим информацию о значениях некоторых из них, что позволяет сделать выводы об их типе:
n.nspname = 'public'::name => nspname::namec.relkind = ANY ('{r,t,m}'::"char"[]) => relkind::"char"
и, наконец, связи этих полей между собой:
c.relnamespace = n.oidc.oid = i.indrelid
Теперь нам остается только аккуратно отразить на вкладке "Структура" в нашем сервисе полученную информацию - таблицы и использованные индексы, их поля и связи:

Хотим знать больше полей? Используем VERBOSE:
EXPLAIN (ANALYZE, VERBOSE, COSTS OFF)
SELECT * FROM pg_stat_user_tables WHERE schemaname = 'public';GroupAggregate (actual time=26.777..29.790 rows=173 loops=1)
Output: c.oid, n.nspname, c.relname, pg_stat_get_numscans(c.oid), pg_stat_get_tuples_returned(c.oid), (sum(pg_stat_get_numscans(i.indexrelid)))::bigint, ((sum(pg_stat_get_tuples_fetched(i.indexrelid)))::bigint + pg_stat_get_tuples_fetched(c.oid)), pg_stat_get_tuples_inserted(c.oid), pg_stat_get_tuples_updated(c.oid), pg_stat_get_tuples_deleted(c.oid), pg_stat_get_tuples_hot_updated(c.oid), pg_stat_get_live_tuples(c.oid), pg_stat_get_dead_tuples(c.oid), pg_stat_get_mod_since_analyze(c.oid), pg_stat_get_last_vacuum_time(c.oid), pg_stat_get_last_autovacuum_time(c.oid), pg_stat_get_last_analyze_time(c.oid), pg_stat_get_last_autoanalyze_time(c.oid), pg_stat_get_vacuum_count(c.oid), pg_stat_get_autovacuum_count(c.oid), pg_stat_get_analyze_count(c.oid), pg_stat_get_autoanalyze_count(c.oid)
Group Key: c.oid, n.nspname, c.relname
-> Sort (actual time=13.829..14.284 rows=2806 loops=1)
Output: c.oid, n.nspname, c.relname, i.indexrelid
Sort Key: c.oid, c.relname
Sort Method: quicksort Memory: 842kB
-> Nested Loop Left Join (actual time=0.720..11.421 rows=2806 loops=1)
Output: c.oid, n.nspname, c.relname, i.indexrelid
-> Hash Join (actual time=0.660..1.490 rows=173 loops=1)
Output: c.oid, c.relname, n.nspname
Inner Unique: true
Hash Cond: (c.relnamespace = n.oid)
-> Seq Scan on pg_catalog.pg_class c (actual time=0.015..1.376 rows=374 loops=1)
Output: c.oid, c.relname, c.relnamespace
Filter: (c.relkind = ANY ('{r,t,m}'::"char"[]))
Rows Removed by Filter: 3187
-> Hash (actual time=0.024..0.024 rows=1 loops=1)
Output: n.nspname, n.oid
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Index Scan using pg_namespace_nspname_index on pg_catalog.pg_namespace n (actual time=0.020..0.021 rows=1 loops=1)
Output: n.nspname, n.oid
Index Cond: (n.nspname = 'public'::name)
Filter: (n.nspname !~ '^pg_toast'::text)
-> Index Scan using pg_index_indrelid_index on pg_catalog.pg_index i (actual time=0.026..0.054 rows=16 loops=173)
Output: i.indexrelid, i.indrelid, i.indnatts, i.indisunique, i.indisprimary, i.indisexclusion, i.indimmediate, i.indisclustered, i.indisvalid, i.indcheckxmin, i.indisready, i.indislive, i.indisreplident, i.indkey, i.indcollation, i.indclass, i.indoption, i.indexprs, i.indpred
Index Cond: (c.oid = i.indrelid)
Planning time: 3.151 ms
Execution time: 30.219 msТеперь, зная структуру связей в базе, мы можем написать более эффективный запрос, если нам не нужна информация из самой схемы:
EXPLAIN (ANALYZE, COSTS OFF)
SELECT * FROM pg_class WHERE relnamespace = (
SELECT oid FROM pg_namespace WHERE nspname = 'public'
);Seq Scan on pg_class (actual time=0.020..1.002 rows=2992 loops=1)
Filter: (relnamespace = $0)
Rows Removed by Filter: 569
InitPlan 1 (returns $0)
-> Index Scan using pg_namespace_nspname_index on pg_namespace (actual time=0.010..0.011 rows=1 loops=1)
Index Cond: (nspname = 'public'::name)
Planning time: 0.110 ms
Execution time: 1.185 msИ да, связь со вложенным InitPlan мы тоже увидим при визуализации структуры:

Поделиться анализом плана с иностранными коллегами стало еще проще - у нашего сервиса появилось англоязычное "зеркало" explain-postgresql.com.
