Прошлые посты в корпоративном блоге не содержали ни одной консольной команды, и мы решили наверстать упущенное.
В нашей компании есть метрика, созданная для предотвращения больших факапов на виртуальном хостинге. На каждом сервере виртуального хостинга расположен тестовый сайт на WordPress, к которому периодически идут обращения.
Так выглядит тестовый сайт на каждом сервере виртуального хостинга
Замеряется скорость и успешность ответа сайта. Любой сотрудник компании может посмотреть на общую статистику и увидеть, насколько хорошо идут у компании дела. Может увидеть процент успешных ответов тестового сайта по всему хостингу или по конкретному серверу. Не обязательно быть сотрудником компании – в панели управления клиенты тоже видят статистику по серверу, где размещён их аккаунт.
Мы назвали эту метрику uptime (процентное отношение успешных ответов от тестового сайта ко всем запросам к тестовому сайту). Не очень удачное название, легко перепутать с uptime-который-общее-время-после-последней-перезагрузки-сервера.
Лето прошло, и график uptime медленно ушёл вниз.
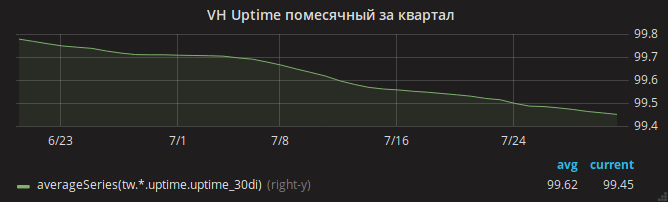
Администраторы сразу же определили причину – нехватка оперативной памяти. В логах легко было увидеть случаи OOM, когда на сервере кончалась память и ядро убивало nginx.
Руководитель отдела Андрей рукой мастера разбивает одну задачу на несколько и распараллеливает их на разных администраторов. Один идёт анализировать настройки Apache – возможно, настройки не оптимальные и при большой посещаемости Apache использует всю память? Другой анализирует потребление памяти mysqld – вдруг остались какие-либо устаревшие настройки с тех времён, когда виртуальный хостинг использовал ОС Gentoo? Третий смотрит на недавние изменения настроек nginx.
Один за другим администраторы возвращаются с результатами. Каждому удалось уменьшить потребление памяти в выделенной ему области. В случае nginx, например, был обнаружен включённый, но не используемый mod_security. OOM тем временем всё также часты.
Наконец, удаётся заметить, что потребление памяти ядром (в частности, SUnreclaim) страшно большое на некоторых серверах. Ни в выводе ps, ни в htop этот параметр не виден, поэтому мы не заметили его сразу! Пример сервера с адским SUnreclaim:
root@vh28.timeweb.ru:~# grep SU /proc/meminfo
SUnreclaim: 25842956 kB24 гигабайта оперативной памяти отдано ядру, и ядро тратит их неизвестно на что!
Администратор (назовём его Гавриил) бросается в бой. Пересобирает ядро с опциями KMEMLEAK для поиска утечек.
Для включения KMEMLEAK достаточно указать опции, указанные ниже, и загрузить ядро с параметром kmemleak=on.
CONFIG_HAVE_DEBUG_KMEMLEAK=y
CONFIG_DEBUG_KMEMLEAK=y
CONFIG_DEBUG_KMEMLEAK_DEFAULT_OFF=y
CONFIG_DEBUG_KMEMLEAK_EARLY_LOG_SIZE=10000KMEMLEAK пишет (в /sys/kernel/debug/kmemleak) такие строки:
unreferenced object 0xffff88013a028228 (size 8):
comm "apache2", pid 23254, jiffies 4346187846 (age 1436.284s)
hex dump (first 8 bytes):
00 00 00 00 00 00 00 00 ........
backtrace:
[<ffffffff818570c8>] kmemleak_alloc+0x28/0x50
[<ffffffff811d450a>] kmem_cache_alloc_trace+0xca/0x1d0
[<ffffffff8136dcc3>] apparmor_file_alloc_security+0x23/0x40
[<ffffffff81332d63>] security_file_alloc+0x33/0x50
[<ffffffff811f8013>] get_empty_filp+0x93/0x1c0
[<ffffffff811f815b>] alloc_file+0x1b/0xa0
[<ffffffff81728361>] sock_alloc_file+0x91/0x120
[<ffffffff8172b52e>] SyS_socket+0x7e/0xc0
[<ffffffff81003854>] do_syscall_64+0x54/0xc0
[<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a
[<ffffffffffffffff>] 0xffffffffffffffff
unreferenced object 0xffff880d67030280 (size 624):
comm "hrrb", pid 23713, jiffies 4346190262 (age 1426.620s)
hex dump (first 32 bytes):
01 00 00 00 03 00 ff ff 00 00 00 00 00 00 00 00 ................
00 e7 1a 06 10 88 ff ff 00 81 76 6e 00 88 ff ff ..........vn....
backtrace:
[<ffffffff818570c8>] kmemleak_alloc+0x28/0x50
[<ffffffff811d4337>] kmem_cache_alloc+0xc7/0x1d0
[<ffffffff8172a25d>] sock_alloc_inode+0x1d/0xc0
[<ffffffff8121082d>] alloc_inode+0x1d/0x90
[<ffffffff81212b01>] new_inode_pseudo+0x11/0x60
[<ffffffff8172952a>] sock_alloc+0x1a/0x80
[<ffffffff81729aef>] __sock_create+0x7f/0x220
[<ffffffff8172b502>] SyS_socket+0x52/0xc0
[<ffffffff81003854>] do_syscall_64+0x54/0xc0
[<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a
[<ffffffffffffffff>] 0xffffffffffffffffГавриил не раскрыл нам всех своих тайн и не рассказал, как он из вышеуказанных строк выяснил точную причину утечки памяти. Скорее всего, он использовал команду addr2line /usr/lib/debug/lib/modules/`uname -r`/vmlinux ffffffff81722361 для поиска точной строки. Или просто открыл файл net/socket.c и смотрел на него, пока файлу стало неуютно.
Проблема оказалась в патче на файл net/socket.c, который много лет назад был добавлен в наш репозиторий. Цель его в том, чтобы запретить клиентам использовать системный вызов bind(), это простая защита от запуска прокси-серверов клиентами. Патч свою цель выполнял, но не очищал после себя память.
Возможно, появились новые модные вредоносы на PHP, которые пробовали запустить в цикле прокси-сервер – что и привело к сотням тысяч заблокированных вызовов bind() и потерянным гигабайтам оперативной памяти.
Дальше было просто – Гавриил поправил патч и пересобрал ядро. Добавил мониторинг значения SUnreclaim на всех серверах под ОС Linux. Инженеры предупредили клиентов и перезагрузили хостинг в новое ядро.
OOM исчезли.
Но проблема с доступностью сайтов осталась
На всех серверах тестовый сайт несколько раз в день переставал отвечать.
Здесь автор начал бы рвать волосы на разных частях тела. Но Гавриил сохранял спокойствие и включил запись трафика на части хостинговых серверов.
В дампе трафика было видно, что чаще всего запрос к тестовому сайту падает после внезапного получения пакета TCP RST. Другими словами, запрос до сервера доходил, но соединение в итоге разрывалось со стороны nginx.
Дальше ещё интереснее! Запущенная Гавриилом утилита strace показывает, что демон nginx не отправляет этот пакет. Как такое может быть, ведь только nginx слушает 80-й порт?
Причиной оказалась совокупность нескольких факторов:
- в настройках nginx указана опция
reuseport(включающая опцию сокетаSO_REUSEPORT), позволяющая разным процессам принимать соединения на одинаковом адресе и порту - в (на тот момент, самой новой) версии nginx 1.13.0 есть баг, из-за которого при запуске теста конфигурации nginx через
nginx -tи использовании опцииSO_REUSEPORTэтот тестовый процесс nginx действительно начинал слушать 80-й порт и перехватывать запросы реальных клиентов. И при завершении процесса теста конфигурации клиенты получалиConnection reset by peer - наконец, в мониторинге заббикса был настроен мониторинг корректности конфигурации nginx на всех серверах с установленным nginx: команда
nginx -tвызывалась на них раз в минуту.
Только после обновления nginx можно было выдохнуть спокойно. График uptime сайтов пошёл вверх.
Какая мораль у всей этой истории? Сохраняйте оптимизм и избегайте использования самостоятельно собранных ядер.
