Наш сегодняшний перевод посвящен Data Science. Аналитик данных из Дублина рассказал, как искал себе жилье на рынке с высоким спросом и низким предложением.
Я всегда завидовал тем профессионалам, которые могут применить свои рабочие навыки в повседневной жизни. Взять к примеру сантехника, стоматолога или шеф-повара: их умения полезны не только на работе.
У аналитика данных и инженера-программиста такие преимущества обычно менее ощутимы. Конечно, я разбираюсь в технологиях, но по работе мне в основном приходится иметь дело с бизнес-сектором, поэтому сложновато подобрать интересные случаи применения своих навыков для решения задач семейного масштаба.
Когда мы с женой решили приобрести новый дом в Дублине, я сразу увидел возможность использовать знания!
Содержание статьи:
- Высокий спрос, низкое предложение
- В поисках данных
- От идеи к инструменту
- Основные данные
- Улучшение качества данных
- Google Data Studio
- Некоторые подробности реализации (а потом переходим к самому интересному)
- Геокодирование адресов
- Расчет времени, которое объект недвижимости находится на рынке
- Анализ
- Выводы
- Заключение
Данные ниже получены не путем скрапинга (scraping), а были сгенерированы с помощью этого скрипта.
Высокий спрос, низкое предложение
Чтобы понять, с чего всё началось, можно ознакомиться с моим личным опытом покупки недвижимости в Дублине. Должен признать, что это было непросто: на рынке очень высокий спрос (благодаря отличным экономическим показателям Ирландии в последние годы), а жилье стоит крайне дорого. Согласно отчету Евростата, в 2019 году в Ирландии была самая высокая стоимость жилья по сравнению с ЕС (на 77% выше среднего показателя по ЕС).

Что означает эта диаграмма?
1. Очень мало домов, подходящих нам по бюджету, а в районах города с высоким спросом таких еще меньше (с более-менее нормальной транспортной инфраструктурой).
2. Состояние вторичного жилья иногда очень плохое, так как владельцам не выгодно вкладываться в ремонт перед продажей. Дома, выставленные на продажу, часто имеют низкий рейтинг энергоэффективности, плохую сантехнику и электрику, а значит, покупателям придется добавить расходы на ремонт к и без того высокой цене.
3. Продажи основаны на аукционной системе, и в большинстве случаев предложения покупателей превышают начальную цену. Насколько я понял, это не относится к новостройкам, но они значительно выходили за рамки нашего бюджета, поэтому мы вообще не рассматривали этот сегмент.
Думаю, что многим людям по всему миру знакома эта ситуация, так как, скорее всего, в крупных городах дела обстоят так же.
Как и все, в поисках недвижимости мы хотели найти идеальный дом в идеальном районе по доступной цене. Давайте посмотрим, как аналитика данных помогла нам в этом!
В поисках данных
В любом Data Science проекте есть этап сбора данных, и для этого конкретного случая я искал источник, содержащий информацию обо всем жилье, доступном на рынке. В Ирландии это два типа сайтов:
- веб-сайты агентств по продаже недвижимости,
- агрегаторы.
Оба варианта являются очень полезными и значительно облегчают жизнь продавцам и покупателям. К сожалению, пользовательский интерфейс и предлагаемые фильтры не всегда позволяют наиболее эффективно извлечь необходимую информацию и сравнить разные объекты недвижимости. Далее перечислены некоторые вопросы, на которые сложно найти ответ с помощью поисковых систем, наподобие Google:
1. Сколько времени займет дорога на работу?
2. Сколько объектов недвижимости находится в том или ином районе? На классических веб-сайтах можно сравнивать районы города, но они обычно охватывают несколько квадратных километров. Это недостаточный уровень детализации, чтобы понять, например, что слишком высокое предложение на конкретной улице говорит о каком-то подвохе. На большинстве специализированных сайтов есть карты, но они не настолько информативны, как хотелось бы.
3. Какие удобства есть рядом с домом?
4. Какая средняя запрашиваемая цена по группе объектов недвижимости?
5. Как давно жилье выставлено на продажу? Даже если эта информация имеется, она не всегда надежна, так как риелтор мог удалить объявление и разместить его заново.
Реорганизация пользовательского интерфейса с учетом удобства для покупателя и улучшение качества данных значительно упростили поиск жилья и позволили нам сделать несколько очень интересных выводов.
От идеи к инструменту
Основные данные
Первым шагом стало написание скрапера (scraper) для сбора базовой информации:
- необработанный адрес объекта недвижимости,
- текущая цена продавца,
- ссылка на страницу с объектом недвижимости,
- основные характеристики, такие как количество комнат, количество ванных комнат, рейтинг энергоэффективности,
- количество просмотров объявления (если доступно),
- тип объекта недвижимости (дом, квартира, новостройка).
Вот, собственно, и все данные, которые я смог найти в Интернете. Для более глубокого анализа мне нужно было улучшить этот набор данных.
Улучшение качества данных
При выборе жилья моим главным аргументом в пользу покупки является удобная дорога на работу, для меня — это не больше 50 минут на всю дорогу от двери до двери. Для этих расчетов я решил использовать Google Cloud Platform:
1. С помощью API геокодирования (Geocoding API) я получил координаты широты и долготы, используя адрес объекта недвижимости.
2. С помощью API направлений (Directions API) я рассчитал время, необходимое чтобы добраться от дома до работы пешком и на общественном транспорте. Примечание: На велосипеде получается примерно в 3 раза быстрее, чем пешком.
3. С помощью API мест (Places API) я получил информацию об удобствах вокруг каждого объекта недвижимости. В частности, нас интересовали аптеки, супермаркеты и рестораны. Примечание: Places API очень дорогие: с базой данных, содержащей 4,000 объектов недвижимости, вам потребуется выполнить 12,000 запросов, чтобы найти информацию по трем видам удобств. Поэтому я исключил эти данные из окончательного дашборда.
Помимо географического расположения, меня интересовал еще один вопрос: как долго объект недвижимости находится на рынке? Если недвижимость не продается слишком долго — это тревожный звоночек: возможно, что-то не так с районом или самим домом, либо запрашиваемая цена слишком высока.
И наоборот, если недвижимость только выставили на продажу, стоит иметь в виду, что владельцы не согласятся на первое полученное предложение. К сожалению, эту информацию довольно легко скрыть. С помощью базового машинного обучения я оценил этот аспект, используя количество просмотров объявления и некоторые другие характеристики.
Наконец, я улучшил набор данных с помощью нескольких служебных полей, чтобы упростить фильтрацию (например, добавив столбец с диапазоном цен).
Google Data Studio
Получив улучшенный набор данных, который меня устраивал, я собирался создать мощный дашборд. В качестве инструмента визуализации данных для этой задачи я выбрал Google Data Studio. Этот сервис имеет некоторые недостатки (его возможности очень и очень ограничены), но есть и преимущества: он бесплатный, имеет веб-версию и может считывать данные из Google-таблиц. Ниже приведена диаграмма, описывающая весь рабочий процесс.

Некоторые подробности реализации
Честно говоря, реализация была довольно простой, и здесь нет ничего нового или особенного: просто набор скриптов для сбора данных и некоторые базовые преобразования Pandas. Разве что стоит отметить взаимодействие с Google API и расчет времени, в течение которого недвижимость находилась на рынке.
Данные ниже получены не путем скрапинга (scraping), а были сгенерированы с помощью этого скрипта.
Давайте рассмотрим необработанные данные.
Как я и ожидал, файл содержит следующие столбцы:
id: Идентификатор объявления._address: Адрес объекта недвижимости._d_code: Код района Дублина. Каждый район Дублина имеет кодовое обозначение в формате D<число>. Если <число> четное, значит дом расположен на южном берегу Лиффи (река, пересекающая город), а если число нечетное — на северном._link: Ссылка на исходную страницу, где было размещено объявление._price: Запрашиваемая цена объекта недвижимости в евро.type: Тип недвижимости (дома, квартиры, новостройки)._bedrooms: Количество комнат (спален)._bathrooms: Количество ванных комнат._ber_code: Код, обозначающий рейтинг энергоэффективности: чем ближе к букве «А», тем лучше рейтинг._views: Количество просмотров объявления (если доступно)._latest_update: Когда объявление было обновлено или создано (если доступно).days_listed: В этом столбце показан результат вычисления — разница между датой, когда я собирал данные, и датой в столбце_last_update.
Геокодирование адресов
Суть в том, чтобы перенести все это на карту и задействовать возможности геолокализованных данных. Чтобы сделать это, давайте посмотрим, как получить широту и долготу при помощи Google API.
Для этого вам потребуется учетная запись в сервисе Google Cloud Platform, а затем вы можете воспользоваться руководством по ссылке, чтобы получить ключ API и включить соответствующий API. Как я писал ранее, для этого проекта я использовал Geocoding API, Directions API и Places API (так что вам нужно будет включить эти конкретные API при создании ключа API). Ниже фрагмент кода для взаимодействия с Google Cloud Platform.
# The Google Maps library
import googlemaps
# Date time for easy computations between dates
from datetime import datetime
# JSON handling
import json
# Pandas
import pandas as pd
# Regular expressions
import re
# TQDM for fancy loading bars
from tqdm import tqdm
import time
import random
# !!! Define the main access point to the Google APIs.
# !!! This object will contain all the functions needed
geolocator = googlemaps.Client(key="<YOUR API KEY>")
WORK_LAT_LNG = (<LATITUDE>, <LONGITUDE>)
# You can set this parameter to decide the time from which
# Google needs to calculate the directions
# Different times affect public transport
DEPARTURE_TIME = datetime.now
# Load the source data
data = pd.read_csv("/path/to/raw/data/data.csv")
# Define the columns that we want in the geocoded dataframe
geo_columns = [
"_link",
"lat",
"lng",
"_time_to_work_seconds_transit",
"_time_to_work_seconds_walking"
]
# Create an array where we'll store the geocoded data
geo_data = []
# For each element of the raw dataframe, start the geocoding
for index,
in tqdm(data.iterrows()):
# Google Geo coding
_location = ""
_location_json = ""
try:
# Try to retrieve the base location,
# i.e. the Latitude and Longitude given the address
_location = geolocator.geocode(row._address)
_location_json = json.dumps(_location[0])
except:
pass
_time_to_work_seconds_transit = 0
_directions_json = ""
_lat_lon = {"lat": 0, "lng": 0}
try:
# Given the work latitude and longitude, plus the property latitude and longitude,
# retrieve the distance with PUBLIC TRANSPORT (`mode=transit`)
_lat_lon = _location[0]["geometry"]["location"]
_directions = geolocator.directions(WORK_LAT_LNG,
(_lat_lon["lat"], _lat_lon["lng"]), mode="transit")
_time_to_work_seconds_transit = _directions[0]["legs"][0]["duration"]["value"]
_directions_json = json.dumps(_directions[0])
except:
pass
_time_to_work_seconds_walking = 0
try:
# Given the work latitude and longitude, plus the property latitude and longitude,
# retrieve the WALKING distance (`mode=walking`)
_lat_lon = _location[0]["geometry"]["location"]
_directions = geolocator.directions(WORK_LAT_LNG, (_lat_lon["lat"], _lat_lon["lng"]), mode="walking")
_time_to_work_seconds_walking = _directions[0]["legs"][0]["duration"]["value"]
except:
pass
# This block retrieves the number of SUPERMARKETS arount the property
'''
_supermarket_nr = 0
_supermarket = ""
try:
# _supermarket = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="supermarket")
_supermarket_nr = len(_supermarket["results"])
except:
pass
'''
# This block retrieves the number of PHARMACIES arount the property
'''
_pharmacy_nr = 0
_pharmacy = ""
try:
# _pharmacy = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="pharmacy")
_pharmacy_nr = len(_pharmacy["results"])
except:
pass
'''
# This block retrieves the number of RESTAURANTS arount the property
'''
_restaurant_nr = 0
_restaurant = ""
try:
# _restaurant = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="restaurant")
_restaurant_nr = len(_restaurant["results"])
except:
pass
'''
geo_data.append([row._link, _lat_lon["lat"], _lat_lon["lng"], _time_to_work_seconds_transit,
_time_to_work_seconds_walking])
geo_data_df = pd.DataFrame(geo_data)
geo_data_df.columns = geo_columns
geo_data_df.to_csv("geo_data_houses.csv", index=False)Расчет времени, которое объект недвижимости находится на рынке
Давайте внимательно рассмотрим данные:
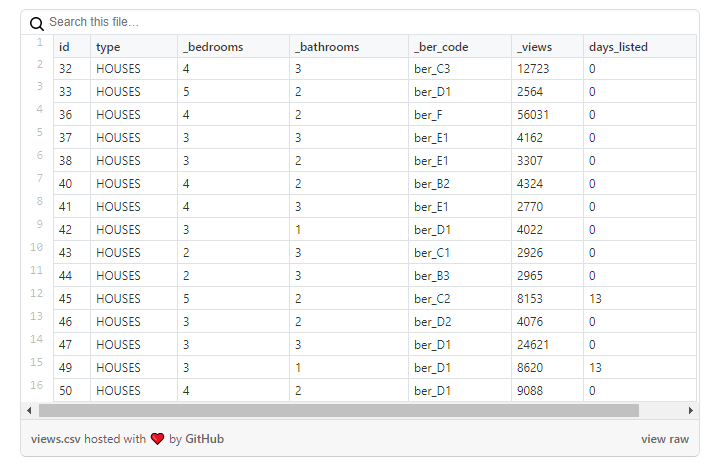
Как вы можете видеть на этой выборке, количество просмотров объектов недвижимости не отражается в количестве дней, в течение которых объявление было активным: например, дом с id = 47 имеет ~ 25 тысяч просмотров, но появилось оно в тот день, когда я загружал данные.
Однако эта проблема характерна не для всех объектов недвижимости. В приведенном ниже примере количество просмотров более сопоставимо с количеством дней, в течение которых объявление было активным:

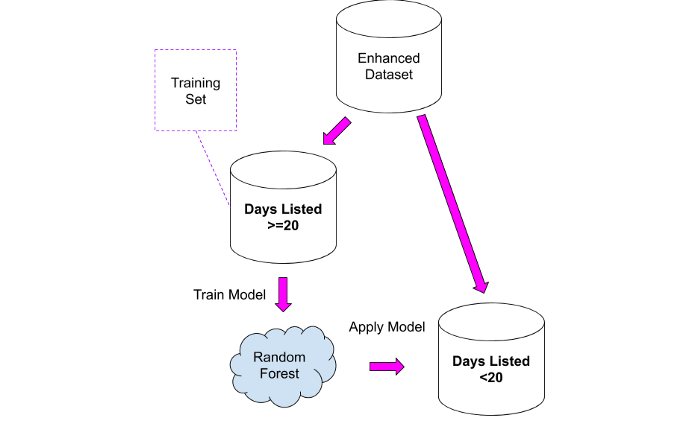
Как мы можем использовать информацию, приведенную выше? Легко! Мы можем использовать второй набор данных в качестве обучающей выборки для модели, которую мы можем затем применить к первому набору данных.
Я протестировал два подхода:
1. Берем «сопоставимый» набор данных и вычисляем среднее количество просмотров в день, затем применяем это значение к первому набору данных. Данный подход не лишен здравого смысла, но в нем есть следующая проблема: все объекты недвижимости объединены в одну группу, при этом вполне вероятно, что объявление о продаже дома стоимостью 10 миллионов евро наберет меньше просмотров в день, поскольку такой бюджет доступен узкой группе людей.
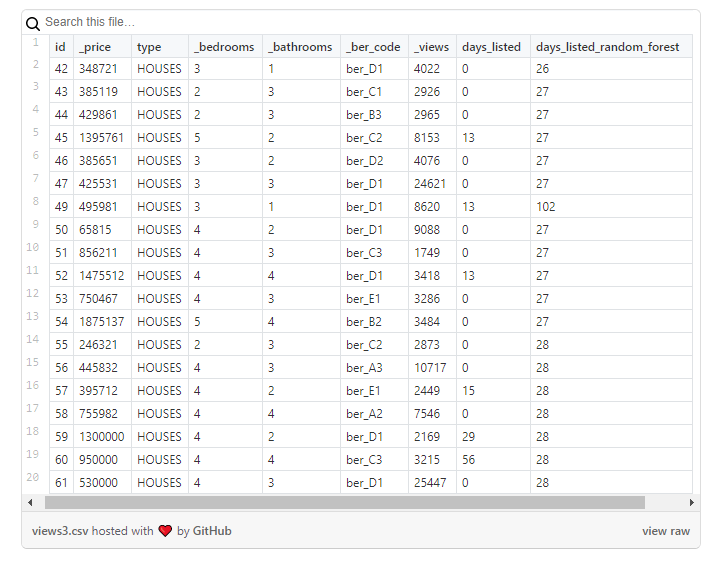
2. Обучаем модель Random Forest на втором наборе данных и затем применяем ее к первому набору.
Результаты следует рассматривать очень внимательно с учетом того, что новый столбец будет содержать лишь приблизительные значения: я использовал их как отправную точку, чтобы более подробно проанализировать объекты недвижимости, где что-то казалось странным.
Анализ
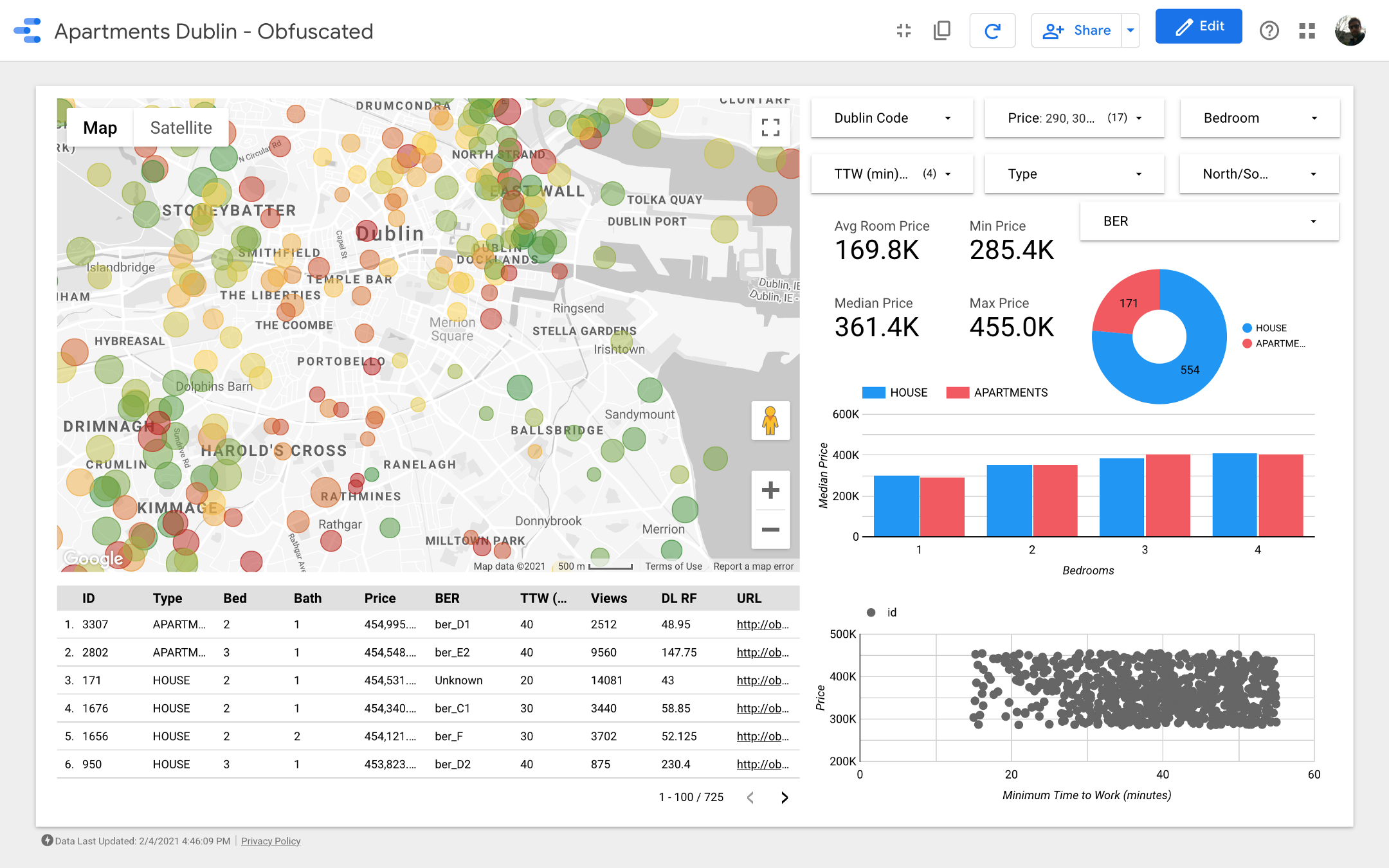
Дамы и господа, представляю вашему вниманию итоговый дашборд. Если вы хотите покопаться в нем, перейдите по ссылке.
Примечание: К сожалению, модуль Google Maps не работает при встраивании в статью, поэтому мне пришлось использовать скриншоты.
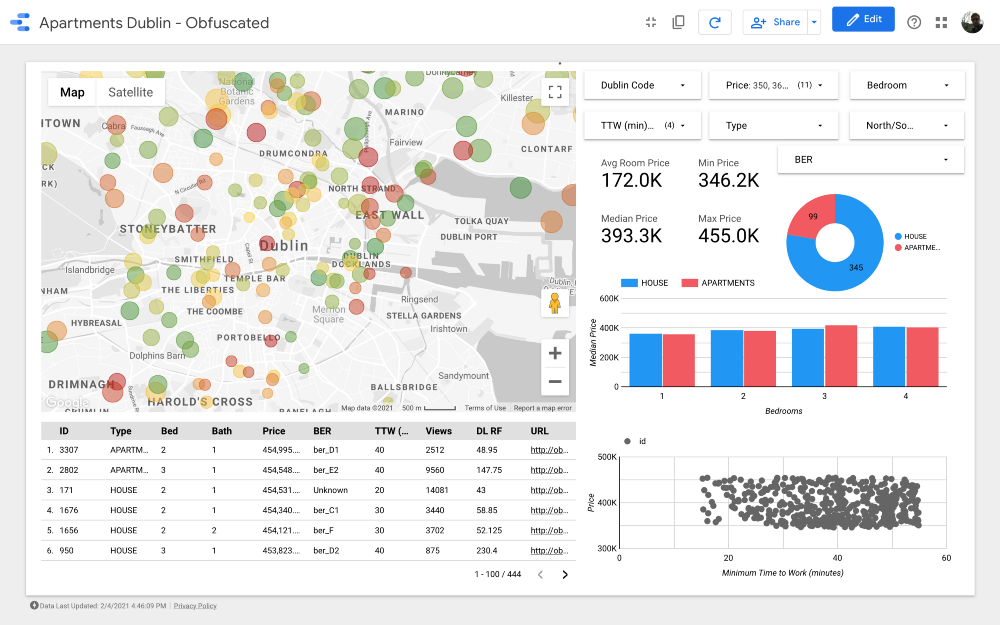
https://datastudio.google.com/s/qKDxt8i2ezE
Карта является самой важной частью дашборда. Цвет пузырей зависит от цены дома /квартиры, и расцветка учитывает только доступные объекты недвижимости (соответствующие настройкам фильтров в правом верхнем углу); размер пузырей указывает на расстояние до работы: чем он меньше, тем короче дорога.
Графики позволяют анализировать, как меняется запрашиваемая цена в зависимости от некоторых характеристик (например, типа здания или количества комнат), а в диаграмме разброса сопоставляется расстояние до работы и запрашиваемая цена.
И наконец, таблица с необработанными данными (
DL RF расшифровывается как Days Listed Random Forest и показывает количество дней, в течение которых объявление было активным, модель Random Forest).Выводы
Давайте погрузимся в анализ и посмотрим, какие выводы мы можем сделать, опираясь на дашборд.
Набор данных включает около 4, 000 домов и квартир: конечно, мы не можем просмотреть их все, поэтому наша задача — определить подгруппу записей, содержащую один или несколько объектов недвижимости, которые мы готовы рассмотреть к покупке.
Для начала нам нужно уточнить критерии поиска. Для примера представим, что мы ищем недвижимость, соответствующую следующим характеристикам:
1. Тип объекта недвижимости: Дом.
2. Количество комнат (спален): 3.
3. Расстояние до работы: меньше 60 минут.
4. Рейтинг энергоэффективности: A, B, C, или D.
5. Цена: от 250 до 540 тысяч евро.
Давайте применим все фильтры, кроме цены, и посмотрим на карту (отфильтровывая только то, что дороже 1 миллиона и дешевле 200 тысяч евро).
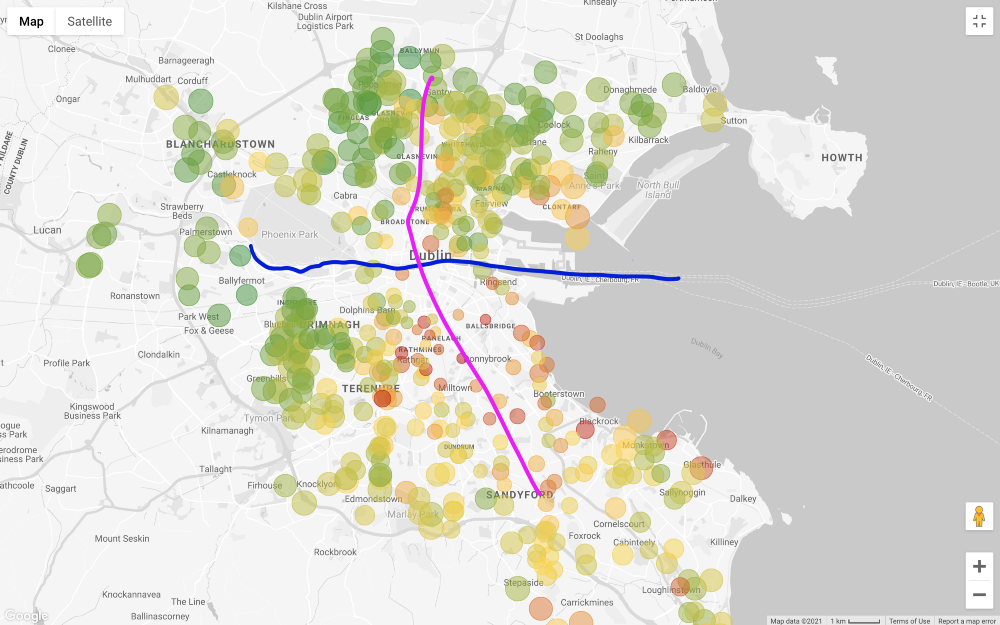
В целом запрашиваемая цена на недвижимость на юге от Лиффи намного выше, чем на севере, за некоторыми исключениями на юго-западе города. Даже «внешние районы» на севере, то есть северо-восток и северо-запад, кажутся менее дорогими, чем северная часть города по центру. Одна из причин такого ценообразования заключается в том, что главная трамвайная линия в Дублине (LUAS) пересекает город с севера на юг по прямой (есть еще одна линия, которая идет с запада на восток, но она не проходит по всем деловым районам).
Обратите внимание, что я высказываю эти соображения только на основе визуального осмотра. Более тщательный подход требует проверки корреляции между ценой на дом и его удаленностью от маршрутов общественного транспорта, но мы не заинтересованы в доказательстве этой связи.
Ситуация становится еще более интересной, если установить фильтр цены в соответствии с нашим бюджетом (не забывайте, что на карте выше показаны дома с 3 спальнями, а дорога на работу занимает менее 60 минут, а на карте ниже добавлен только фильтр по цене):
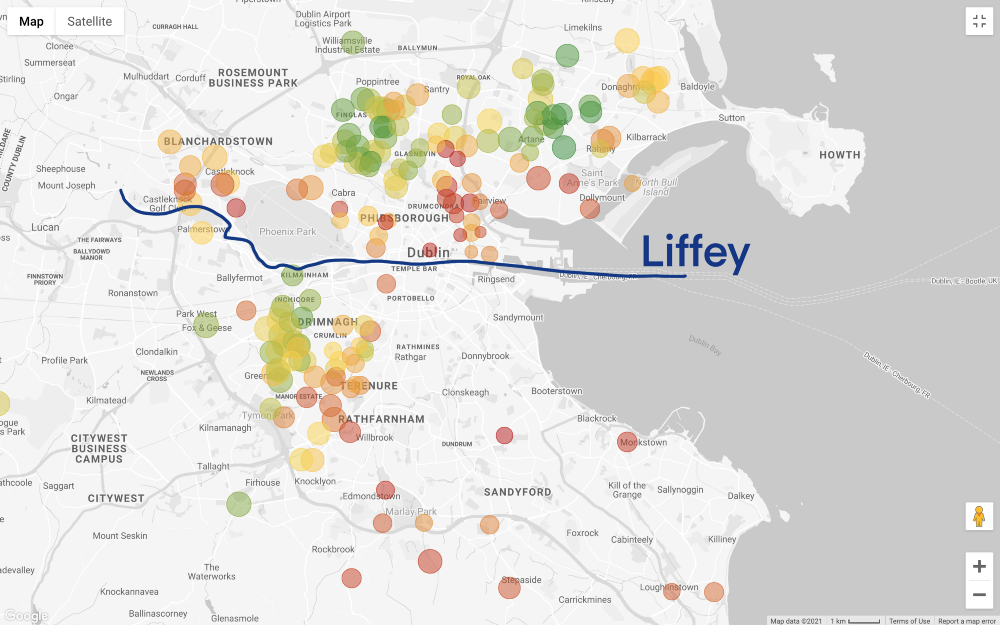
Давайте сделаем шаг назад. Мы имеем общее представление о тех районах, которые нам по карману, но теперь предстоит самое сложное — поиск компромиссов! Хотим ли мы подобрать более бюджетный вариант? Или же мы рассмотрим лучший дом, который можно купить на наши заработанные большим трудом сбережения? К сожалению, аналитика данных не может дать ответ на эти вопросы, это деловое (и сугубо личное) решение.
Предположим, мы выбрали второй вариант: отдаем предпочтение качеству дома или района, а не более низкой цене.
В таком случае нам нужно рассматривать следующие варианты:
1. Районы с низкой концентрацией предложений — изолированный дом на карте, может указывать на то, что в этом районе не так много предложений, а значит, владельцы не спешат расставаться со своим домом в таком хорошем районе.
2. Дом, расположенный в скоплении дорогой недвижимости — если все остальные объекты недвижимости рядом с определенным домом дорогие, это может означать, что район пользуется высоким спросом. Это просто дополнительное примечание, но мы могли бы количественно оценить это явление с помощью пространственной автокорреляции (например, рассчитав Индекс I Морана).
Даже если первый вариант кажется привлекательным, следует учитывать, что очень низкая цена на недвижимость по сравнению с другими предложениями в этом же районе может подразумевать какой-то подвох в самом доме (например, маленькие комнаты или очень большие затраты на ремонт). По этой причине мы продолжим анализ, сосредоточившись на втором варианте, который, на мой взгляд, является наиболее многообещающим с учетом нашей цели.
Давайте более подробно рассмотрим, какие есть предложения в этом районе:

Мы уже сократили наши варианты с 4,000 до менее 200, а теперь нам нужно получше разбить точки и сравнить кластеры.
Автоматизация поиска в кластере не дополнит этот анализ значительно, но давайте все равно применим алгоритм DBSCAN. Мы используем DBSCAN, потому что некоторые группы могут быть неглобулярными (например, метод k-средних не сработает должным образом на этой базе данных). В теории нам нужно вычислить географическое расстояние между точками, но мы будем использовать евклидову систему, так как она дает хорошее приближение:
import pandas as pd
from sklearn.cluster import DBSCAN
data = pd.read_csv("data.csv")
data["labels"] = DBSCAN(eps=0.01, min_samples=3).fit(data[["lat","lng"]].values).labels_
print(data["labels"].unique())
data.to_csv("out.csv")
Алгоритм показал довольно хороший результат, но я бы пересмотрел кластеры следующим образом (с учетом знаний о деловых районах Дублина):

Мы отказываемся от районов с более низкими ценами, так как для нас в приоритете максимальное качество жилья и удобная дорога на работу в рамках нашего бюджета, поэтому можно исключить кластеры 2, 3, 4, 6 и 9. Обратите внимание, что кластеры 2, 3 и 4 расположены в одних из самых бюджетных районах северного Дублина (вероятно, это связано с менее развитой инфраструктурой общественного транспорта). В кластере 11 представлены дорогие варианты, расположенные далеко от работы, поэтому его мы тоже можем исключить.
Если посмотреть на более дорогие скопления, номер 7 является одним из лучших с точки зрения расстояния до работы. Это Драмкондра, красивый жилой район на севере Дублина; несмотря на то, что он не очень удобно расположен относительно трамвайной линии, по нему проходят автобусные маршруты; в кластере 8 цены на жилье и расстояние до работы такие же, как и в Драмкондре. Еще один кластер, который стоит проанализировать, это номер 10: кажется, что он находится в районе с более низким предложением, а это означает, что люди здесь, вероятно, редко продают жилье, к тому же у этого района довольно удобное расположение относительно маршрутов общественного транспорта (при условии, что все районы имеют одинаковую плотность населения).
И наконец кластеры 1 и 5, расположенные рядом с парком Феникс, крупнейшим огороженным общественным парком.
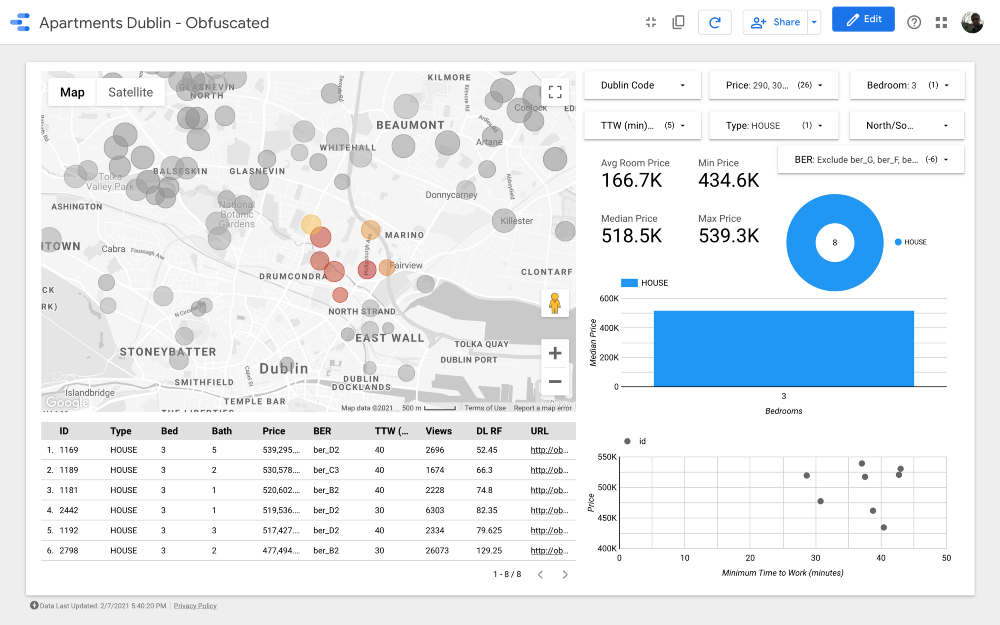
Кластер 7

Кластер 8
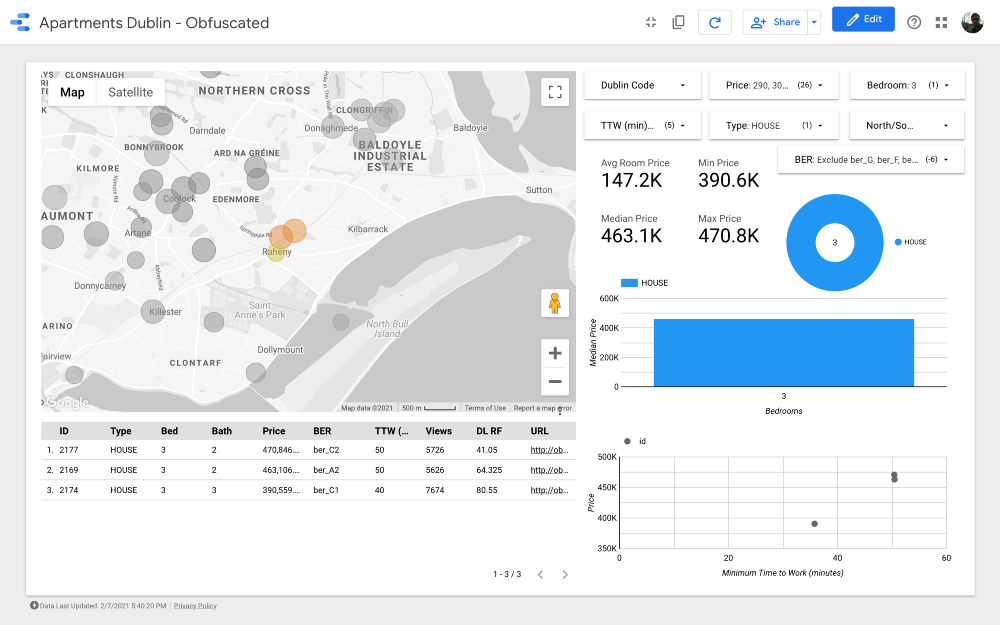
Кластер 10
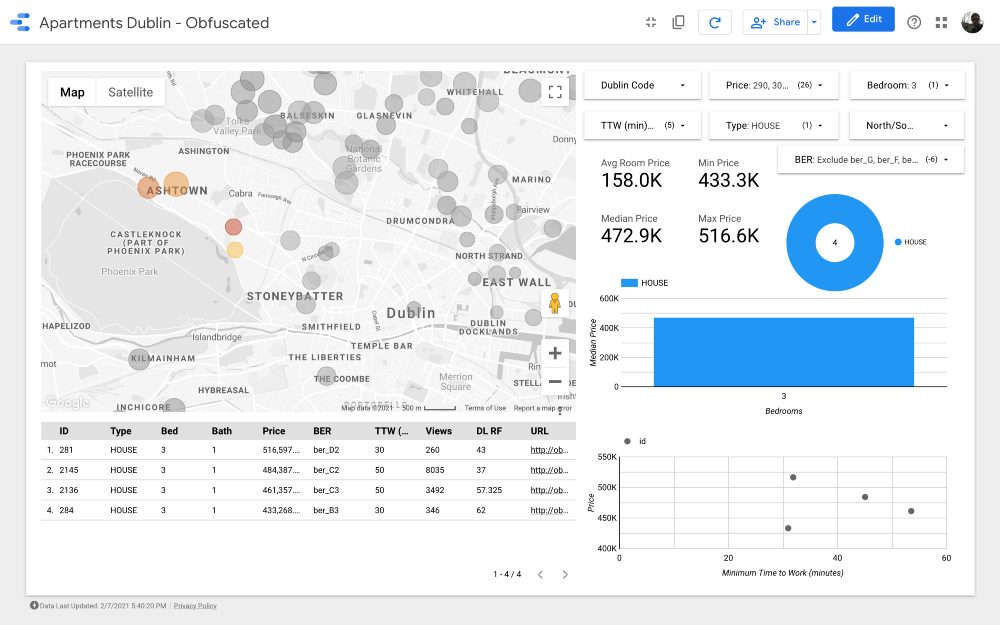
Кластер 1

Кластер 5
Отлично! Мы нашли 26 объектов недвижимости, которые стоит посмотреть прежде всего. Теперь мы можем тщательно проанализировать каждое предложение и, в конечном итоге, организовать просмотр с риелтором!
Заключение
Мы начали поиск, практически ничего не зная о Дублине, а в итоге хорошенько разобрались, какие районы города особенно востребованы при покупке жилья.
Заметьте, мы даже не смотрели фотографии этих домов и ничего о них не читали! Просто взглянув на хорошо организованный дашборд, мы сделали несколько полезных выводов, к которым мы не смогли бы прийти в самом начале!
Эти данные больше ничем не могут быть полезны, а для улучшения анализа можно провести некоторые интеграции. Несколько мыслей:
1. Мы не интегрировали в исследование набор данных об удобствах (тот, что мы составили с использованием Places API). При наличии большего бюджета для облачных сервисов мы могли бы легко добавить эту информацию в дашборд.
2. В Ирландии публикуется много интересных данных на сайте статистической службы: например, можно найти информацию о количестве звонков в каждый участок полиции по кварталу и по типу преступления. Таким образом, мы могли бы узнать, в каких районах наблюдается наибольшее количество краж. Так как можно получить данные переписи для каждого избирательного участка, мы могли бы также рассчитать уровень преступности на душу населения. Обратите внимание, что для таких расширенных функций нам потребуется соответствующая геоинформационная система (например, QGIS) или база данных, которая может обрабатывать географические данные (например, PostGIS).
3. В Ирландии имеется база данных с предыдущими ценами на жилье, которая называется Residential Property Register (Реестр жилой недвижимости). На их сайте зафиксирована информация о каждом объекте жилой недвижимости, приобретенном в Ирландии начиная с 1 января 2010 года, включая дату продажи, цену и адрес. Сравнив текущие цены на дома с прошлыми, можно понять, как со временем менялся спрос.
4. Расценки на страхование жилья во многой степени зависят от местоположения дома. Приложив некоторые усилия, мы могли бы выполнить скрапинг сайтов страховых компаний, чтобы интегрировать в наш дашборд их «модель факторов риска».
На таком рынке, как Дублин, поиск нового дома может стать непростой задачей, особенно для человека, который переехал в этот город совсем недавно и еще не очень хорошо его знает.
Благодаря этому инструменту мы с женой сэкономили себе (и риелтору) время: 4 раза сходили на просмотр, предложили свою цену 3 продавцам, и один из них принял наше предложение.
