
Команда Netflix Cloud Data Engineering работает с различными приложениями для JVM, включая такие популярные хранилища данных, как Cassandra и Elasticsearch. Хотя большинство наших кластеров стабильно работают, обходясь выделенной им памятью, иногда «запрос смерти» или ошибка в самом хранилище данных приводят к перерасходу памяти, что может спровоцировать лишние циклы сборки мусора или даже привести к исчерпанию памяти в JVM.
Мы создали инструмент jvmkill для исправления таких ситуаций. Jvmkill — это агент, который запускается в процессе JVM с помощью API JVMTI. Когда в JVM заканчивается память, или машина не может породить новый поток, jvmkill вмешивается в ситуацию и убивает весь процесс. Мы сочетаем jvmkill с Hotspot флагом -XX:HeapDumpOnOutOfMemoryError, чтобы можно было вернуться и проанализировать массив данных. Цель — получить представление о том, почему у нас закончились ресурсы. Для наших прикладных задач эта ситуация идеальна: JVM, у которой закончилась память, не может продвигаться вперед, и как только jvmkill вмешается, systemd перезапустит сбойный процесс с чистого листа.
Даже с защитой jvmkill мы продолжаем испытывать проблемы с теми JVM, у которых почти — но не совсем — закончилась память. Эти Java-процессы тормозят работу, снова и снова отвлекаясь на сборку мусора. При этом в паузах между циклами сборки не выполняется практически никакой полезной работы. Поскольку ресурсы JVM исчерпаны не на 100%, jvmkill не замечает проблемы. Наши клиенты, с другой стороны, быстро замечают, что пропускная способность их узлов с хранилищами данных, как правило, снижается на четыре порядка.
Чтобы проиллюстрировать это поведение, продемонстрируем «запрос смерти» против Cassandra JVM¹, приказав Cassandra загрузить весь набор данных в память несколько раз:
cqlsh> PAGING OFF
Disabled Query paging.
cqlsh> SELECT * FROM large_ks.large_table;
OperationTimedOut: errors={}, last_host=some host
cqlsh> SELECT * FROM large_ks.large_table;
Warning: schema version mismatch detected, which might be caused by DOWN nodes; if this is not the case, check the schema versions of your nodes in system.local and system.peers.
Schema metadata was not refreshed. See log for details.Затем мы используем jstat и логи сборки мусора — и видим, что машина действительно попала в порочный круг сборки мусора:
$ sudo -u cassandra jstat -gcutil $(pgrep -f Cassandra) 100ms
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 100.00 100.00 100.00 97.96 95.10 21 8.678 11 140.498 149.176
0.00 100.00 100.00 100.00 97.96 95.10 21 8.678 11 140.498 149.176
0.00 100.00 100.00 100.00 97.96 95.10 21 8.678 11 140.498 149.176$ grep "stopped" gclog | tail
2019-03-05T02:59:15.111+0000: 1057.680: Total time for which application threads were stopped: 18.0113457 seconds, Stopping threads took: 0.0001798 seconds
2019-03-05T02:59:16.159+0000: 1058.728: Total time for which application threads were stopped: 1.0472826 seconds, Stopping threads took: 0.0001542 seconds
2019-03-05T02:59:40.461+0000: 1083.030: Total time for which application threads were stopped: 24.3016592 seconds, Stopping threads took: 0.0001809 seconds
2019-03-05T03:00:16.263+0000: 1118.832: Total time for which application threads were stopped: 35.8020625 seconds, Stopping threads took: 0.0001307 seconds
2019-03-05T03:00:51.599+0000: 1154.168: Total time for which application threads were stopped: 35.3361231 seconds, Stopping threads took: 0.0001517 seconds
2019-03-05T03:01:09.470+0000: 1172.039: Total time for which application threads were stopped: 17.8703301 seconds, Stopping threads took: 0.0002151 secondsВ данных логов, характеризующих сборку мусора, хорошо видны повторяющиеся 20+ секундные паузы, и мы можем использовать инструмент GCViewer для графической интерпретации данных, присутствующих в логах:
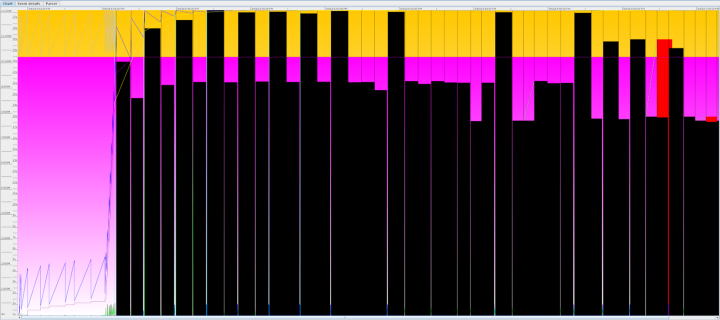
В этой ситуации JVM, безусловно, не дает нужной нам производительности, и мало шансов, что требуемая производительность восстановится. Эта спираль смерти сохраняется до тех пор, пока дежурный инженер не вмешается в ситуацию, остановив сбойные JVM. Когда случаи такого вмешательства чрезмерно участились, мы решили, что эта проблема:
1. Легко выявляется;
2. Имеет простое решение;
3. Располагает к быстрому вмешательству.
Другими словами, мы решили, что нам нужно автоматизировать работу, которая раньше выполнялась вручную.
❯ Решение: Проактивное выявление и уничтожение плохих JVM
Нам очень понравился подход jvmkill, поэтому мы рассмотрели, как можно добавить нужное нам поведение при помощи расширений jvmkill. jvmkill перехватывает обратный вызов ResourceExhausted JVMTI, посылая неисправной JVM сигнал SIGKILL. Этот сигнал основан на собственной оценке JVM, считающей, что у нее закончились ресурсы. К сожалению, этот простой классификатор плохо применим с не такими явными сбойными режимами, когда JVM тратит слишком много времени на сборку мусора, но ресурсы не исчерпаны. Мы также рассмотрели другие имеющиеся опции JVM, такие как GCHeapFreeLimit, GCTimeLimit, OnOutOfMemoryError, ExitOnOutOfMemoryError и CrashOnOutOfMemoryError. Мы обнаружили, что эти опции либо не работают последовательно на всех JVM и сборщиках мусора, либо их трудно настроить или понять, либо они просто не работают в разных пограничных случаях. Из-за непоследовательности и сложности/невозможности настройки существующих классификаторов исчерпания ресурсов JVM мы решили создать собственный классификатор в дополнение к имеющимся.
Наше решение, jvmquake, зародилось из вечерних размышлений на тему «насколько на самом деле сложна такая задача?». Мы исходили из того, что при любой заданной рабочей нагрузке JVM должна тратить существенную часть времени на выполнение программного кода, а не на паузы, отводимые на сборку мусора. Если доля времени, затрачиваемого на выполнение кода, слишком долго остается ниже некоторого уровня, JVM явно неисправна и должна быть остановлена.
Мы реализовали эту идею, смоделировав время, проведенное JVM в паузе для сборки мусора, как «долг». Если JVM тратит 200 мс на сборку мусора, она добавляет 200 мс к своему счетчику долга. Время, затраченное на выполнение программного кода, «гасит» накопленный долг и может довести его до нуля. Поэтому если та же программа затем выполняется в течение ≥200 мс, счетчик долга снова падает до нуля. Если время, затрачиваемое JVM на сборку мусора, не превышает время, затрачиваемое на выполнение кода – то есть, данное соотношение не равно 1:1, а на работу с кодом расходуется >50% пропускной способности, то ее долг будет стремиться к нулю. С другой стороны, если на выполнение кода уходит менее 50% пропускной способности, ее долг будет стремиться к бесконечности. Этот подход «счетчика долгов» напоминает алгоритм протекающего ведра, применяемый для отслеживания пропускной способности программы. В этом случае мы добавляем воду со скоростью, пропорциональной времени сборки мусора, и удаляем ее пропорционально времени работы приложения:
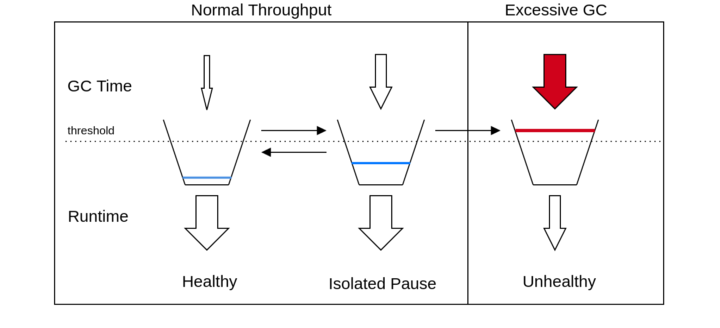
По мере увеличения счетчика долгов для JVM мы все больше убеждаемся в том, что машина неисправна, и в конце концов, решаемся на какие-то действия. Например, спираль сборки мусора в реальных условиях с применением jvmquake может выглядеть следующим образом:
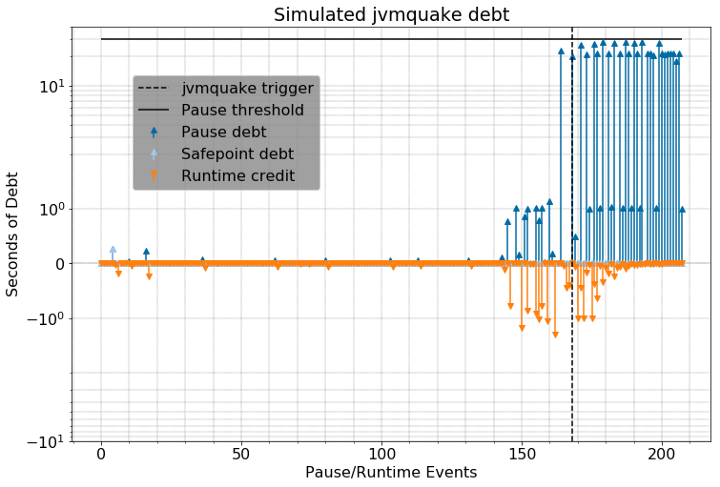
Если бы jvmquake был подключен к этой JVM, она была бы остановлена там, где проведена прерывистая линия.
Мы выбрали настраиваемый порог, задав по умолчанию довольно щадящее значение: 30 секунд. Если JVM завершила сборку мусора, а счетчик долга накрутил больше 30 секунд, то jvmquake убивает процесс. Мы измерили эти значения, перехватывая обратные вызовы GarbageCollectionStart и GarbageCollectionFinish JVMTI.
Кроме порога задолженности мы добавили еще две настройки:
- runtime_weight: применяет коэффициент к времени выполнения программного кода, чтобы можно было задать целевое соотношение по пропускной способности, отличное от 1:1 (50%/50%). Например, runtime_weight 2 — это целевое соотношение 1:2 (пропускная способность 33%). В более общем случае runtime_weight, равный x, подразумевает соотношение 1:x (100%/(x+1) пропускная способность). Серверные JVM обычно работают с пропускной способностью более 95%, поэтому даже минимальная пропускная способность 50% является достаточно консервативной.
- action: jvmkill будет посылать процессу сигнал SIGKILL только один раз, но в jvmquake мы добавили возможность намеренного ввода JVM в состояние OOM, а также сделали так, чтобы машина могла посылать себе произвольные сигналы до SIGKILL. В следующем разделе мы объясним, почему эти другие действия могут быть желательны.
После применения jvmquake, если мы запустим тот же запрос смерти, что и раньше, на узле Cassandra, мы увидим:

Как и раньше, JVM устремляется по спирали смерти сборки мусора, но на этот раз jvmquake замечает это после того, как JVM накапливает 30 секунд долга сборки мусора (при весе 4:1 во время выполнения) и останавливает JVM. JVM в таком случае не будет существовать вечно, как это было бы раньше, а быстро погибает.
❯ Не уничтожайте улики!
Когда мы использовали jvmkill или вручную завершали JVM, у нас всегда была возможность собрать файл дампа кучи, используя -XX:HeapDumpOnOutOfMemoryError или jmap, соответственно. Эти файлы дампов кучи очень важны для отладки первопричины утечки памяти. К сожалению, ни один из этих методов не работает, когда jvmquake посылает SIGKILL в JVM, которая еще не столкнулась с OutOfMemoryError. Наше решение простое: когда срабатывает jvmquake, активируется поток, который выделяет большие массивы на куче, чтобы намеренно вызвать исчерпание памяти (OOM) в JVM. В результате срабатывает функциональность -XX:HeapDumpOnOutOfMemoryError, и, наконец, завершается процесс.
Однако здесь есть серьезная проблема: файлы дампов кучи Java записываются и хранятся на диске. Поэтому при многократном автоматическом уничтожении процессов диски могут переполниться. Поэтому мы начали изыскивать, как получать дампы ядра, характеризующие ОС, а не дампы кучи, специфичные для JVM. Мы поняли, что если мы сможем заставить неисправную JVM посылать себе SIGABRT вместо SIGKILL, ядро Linux автоматически напишет для нас файл дампа ядра. Нам нравится этот подход, поскольку он является стандартным для всех языков исполнения (включая, в частности, node.js и Python), а главное — он позволяет нам собирать даже очень большие файлы дампов ядра и кучи и записывать их в канал без выделения дополнительного дискового пространства для их хранения.
Когда Linux делает дамп ядра, по умолчанию записывается файл с именем «core» в рабочий каталог аварийного процесса. Чтобы исключить ситуации, когда запись файла ядра привела бы к нехватке места на диске, Linux предусматривает ограничение ресурсов (ulimit -c) на размер записываемых файлов ядра. По умолчанию ограничение ресурсов равно нулю, поэтому ядро вообще не записывает файл ядра. Но при помощи sysctl kernel.core_pattern, можно указать программу, в которую должен быть передан дамп ядра (см. «Передача дампов ядра в программу» в man-справке по ядру). Придерживаясь этого интерфейса, мы написали скрипт для сжатия файла ядра и в режиме потоковой загрузки отправили его в S3, где он хранится вместе с метаданными об отказавшей программе.
После завершения потоковой выгрузки systemd перезапустит JVM, ранее исчерпавшую память (оказавшуюся в состоянии OOM). Это компромисс: мы синхронно выгружаем файл ядра в S3, избавляясь от необходимости решать, хранить ли файл ядра локально. На практике нам удается надежно выгружать файлы дампов ядра объемом 16 ГБ менее чем за две минуты.
❯ Скажи мне, что пошло не так
Теперь, когда файл дампа ядра получен, мы можем просмотреть его, чтобы выявить причину неприятностей — был ли это некорректный запрос, проблема с оборудованием или проблема конфигурации? В большинстве случаев причину можно определить по используемым классам и их размеру.
Наша команда внедрила jvmquake во все наши хранилища данных Java. На данный момент устранены десятки инцидентов — каждый раз за считанные минуты — и повышена доступность некоторых из наших наиболее важных производственных кластеров баз данных. Более того, потоковые дампы ядра и средства автономного преобразования позволили нам отладить и исправить сложные ошибки в наших хранилищах данных Cassandra и Elasticsearch, тем самым обеспечив нашим приложениям «всегда доступные» хранилища данных, которые так нужны. Многие из этих исправлений мы уже передали сообществу, и мы с нетерпением ждем возможности перейти к устранению новых проблем, если они возникнут в будущем.
❯ Сноски
¹В частности, Cassandra 2.1.19, с примерно 20 Гб данных и 12 Гб кучи. Для этого эксперимента мы отключили DynamicEndpointSnitch, чтобы гарантировать, что запрос будет направлен к локальной реплике, и отключили подкачку, чтобы гарантировать, что узел будет хранить весь датасет в памяти.

