Комментарии 55
Прошу прощения, сразу бросилось в глаза
От использования ANTLR (от англ. ANother Tool for Language Recognition — «ещё одно средство распознавания языков») — генератора нисходящих анализаторов для формальных языков, я решил сразу отказать из-за того, что он написан на Java. В этом нет никаких религиозных предпочтений, просто голый расчет и отсутствие желания использовать JRE только для парсера, когда были еще варианты.
Собственно почему ??? ANTLR прекрасно умеет генерировать код и на С, и на питоне и на джаваскрипте и ещё на куче всего. По-моему оптимальный выбор.
Согласен, что умеет генерить, но я искал парсер, который можно было бы сделать встроенным прямо в среду выполнения, так как изначально была задумка - изменять грамматику языка с помощью самого языка, а в случае использования ANTLR это было бы затруднительно.
Ну если быть точным, то на C++, а не на C.
Все описанные выше эксперименты заняли в общем итоге несколько месяцев
Мой совет, не используйте все эти flex/bison, а напишите вручную простой нисходящий парсер без отдельного лексера. При таком подходе фактически лексемами будут отдельные символы. У меня это заняло 2 недели, и поддержка UTF-8 получилась автоматически.
Это время заняло в первую очередь различные экскременты с грамматикой языка, а не непосредственная борьба с лексерами - парсерами. Я конечно думал насчет собственной реализации, но здраво рассудив, что буду делать очередной велосипед, решил сосредоточится на других задачах.
На связке flex+bison тоже никто не мешает перенести всю работу на bison, так чтобы flex просто выплёвывал буковки по одной. Принципиальная разница между bison и самодельным top-down парсером в том что бизон будет на вас орать увидев неоднозначные конструкции, а top-down будет их молча КАК-ТО парсить полагаясь на порядок веток кода, который далеко не факт что обдумывался, а не получился спонтанно в процессе добавления ветвей.
Неоднозначность в стандартных инструментах обычно решается приоритетами, в каком порядке парсить, реорганизацией грамматики. Особых отличий от кода нет, тут передвинули правило, там вызов функции. Можно для контроля иметь рядом грамматику в файле. И насколько я могу судить, неоднозначность часто возникает из-за того, что сначала мы пытаемся разбить на лексемы регулярными выражениями без учета контекста, а потом построить дерево с учетом контекста. Хотя логичнее парсить следующий токен с учетом контекста, так меньше возможных вариантов.
Лексер может быть имел смысл, когда компьютеры были медленными, у них было мало оперативной памяти, и для простых языков, возможно там это заметно ускоряло компиляцию. Но сейчас он только добавляет сложностей.
Особых отличий от кода нет, тут передвинули правило, там вызов функции.
В Bison'е приоритеты работают не так. Вы должны пойти и в явном виде написать %prec. Я подчёркиваю, это осознанное и умышленное действие. А не "ну вот как-то я ветки кода расположил и в результате там сидит незаметная невооружённым взглядом неоднозначность, которая втихаря резолвится порядком веток".
Ведь в жизни практически любого программиста может наступить момент, когда ему в голову приходит светлая идея — разработать свой собственный язык программированияПрямо сейчас борюсь с непреодолимым желания сделать то же, ориентированное на математические вычисления. За 30 лет накопилось слишком много идей, что можно сделать лучше и как именно. Но решил, что сначала нужно придумать крутое название. Варианты типа «NewSuperLang» выглядят не очень убедительно)
Рациональные числа без ограничений точности и тензорные вычисления как раз и были добавлены для ориентации на математические вычисления. А с помощью макросов и собственного DSL можно кастомизировать и непосредственно синтаксис языка с учетом тех или иных математических операций.
Так что присоединяйтесь со своими идеями, подумаем над ними вместе :-)
Компилировать не в машинный код, а в c++ или c#. Сильно облегчает сложность а заодно позволяет использовать в качестве скриптов из уже существующих проектов.
Снизить количество круглых и фигурных скобок, с чем у c++ и c# явный перебор. А квадратных скобок наоборот побольше, визуально они хорошо выделяются из сплошного текста.
Поддержка постфиксной/префксной записи, чтобы вместо
t = log(cosh(x));можно было писать
t = log<<cosh<<x;или
x>>cosh>>log>>t;вариант с двумя переменными:
x = cos<<arctan<<x,y;И чтобы так тоже можно было:
x,y = x+y,x-y;Ну то есть не обязательно перечисления оборачивать в круглые или фигурные скобки, если их границы очевидны.
Поддержка инфиксной записи для произвольных символов, например вместо
conjmul(a,b)в Вольфраме можно писать
a~conjmul~bНо я бы левый и правый символ всё же сделал бы разными для наглядности, типа
a]conjmul[bЕстественно, с поддержкой односимвольных псевдонимов.
Допускать неявное умножение, как у Вольфрама, типа
t = 5(x+1)sin(x);Или даже так
t = sin^3(x);а с нижним индексом например так
t = ChebyshevT.5(x);Допускать другие символы для перечисления, чтобы мочь писать
dt = 2023.01.01 11:12:13.777;tcp.connect<<127.0.0.1:5000;В переменную dt и метод connect придёт уже распарсенная строка древовидного типа. А также из этого следует, что запись 5.5 ещё не тип double, а может быть и fixed point, и rational, и кортеж из двух целых.
Комплексные и дуальные числа как минимум должны быть. И не обязательно в формате
a+i*b (алгебраическом), но и в векторном, например a:b:i, a`b`i или как-то ещё.Некомутативное умножение нужно, и отдельные символы для умножений из линейной алгебры;
Массив как дискретная функция. Чтобы выхода за диапазоны не могло быть в принципе. Либо 0, либо по остатку от деления на длину массива, либо вызыв callback функции. А также иметь значение смещения, чтобы и с 1 нумеровать можно было.
Привязка псевдонимов к вложенным циклам. Чтобы не просто break, а с произвольной степени вложенности, включая выход из процедуры.
Возможность контроля времени выполнения цикла не отходя от кассы.
Контроль доверия к внешним переменным — отслеживать, была ли сделана проверка на корректность значений или нет.
Отдельный тип index для циклов и массивов, и никаких больше int! Кто получал бесконечный цикл с unsigned int, тот поймёт.
Один символ # для комментариев как человеку, так и компилятору. Непонятные инструкции просто пропускаются. И никаких условных компиляций! В котёл тех, кто такое придумал. Не должна логика программы зависеть от ключей компиляции и #defin-ов, раскиданных неизвестно где.
Более продвинутые switch-case конструкции для описания автоматной логики. Или даже отдельная абстракция для этого, как class у структур.
Поддержка data-flow стиля, в DSP крайне полезная штука. Визуально выглядит так, наброски SDK для такого у меня уже имеются.
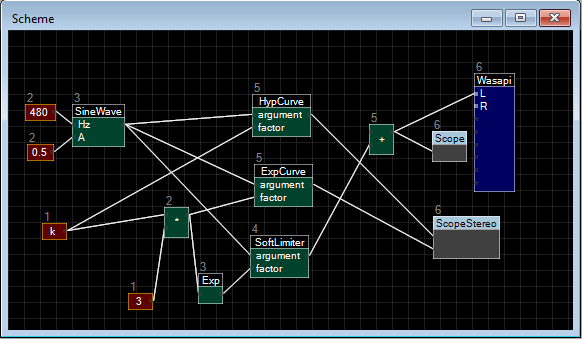{kind=link}
Как бы это не было странно, но большинство ваших предложений уже так или иначе реализовано или может быть реализовано с уже имеющимися возможностями языка:
Компилятор языка делается именно как транспайлер на С++.
Для снижения количества скобок пришлось специально ограничить систему встроенных типов (есть только тензоры в квадратных скобках и словари в круглых скобках), а от все остальные типы (tuple, enum и пр.) можно реализовать на базе этих двух.
Присвоение нескольких значений сразу нескольким переменным уже давно сделано, т.е. можно записать и так: x,y = x+y,x-y; и x, dict = ... dict; В последнем случае из словаря в переменную переносится первый элемент.
Комплексные числа заложены в планах, а для представления векторов наверно достаточно будет уже существующих тензоров.
Чтобы обезопасить разработчиков от использования индексов и проверок выхода за границы массивов, реализованы итераторы по элементам тензоров и словарей, хотя проверки выхода за границы массивов все равно присутствуют.
Любые дополнительные операции для своего DSL можно реализовать с помощью макросов.
Выход из циклов или даже из вложенных функций тоже уже реализован
Test0(arg) := { if($arg==0) return("DONE - 0"); «FAIL» };
Test1(arg) := { if($arg==1) return("DONE - 1"); Test0($arg); };
Test(arg) := {+ if($arg >= 0) Test1($arg); $arg; +};
Test(0); # Вернет «DONE — 0» возврат из вложенной функции Test0
Test(1); # Вернет «DONE — 1» возврат из вложенной функции Test1
Test(2); # Вернет «FAIL» возврат из вложенной функции Test0
Test(-2); # Вернет -2 — возврат из функции Test
Насчет контроля внешних переменных, не уверен, что такое вообще возможно, но все внутренние переменные контролируются на корректность значений, в том числе, на инициализацию и возможность конвертирования из одного типа в другой.
Отдельный тип для индексов не требуется, т. к. все числа знаковые, а отдельный тип (для без знаковых чисел отсутствует).
Символ # уже используется для однострочных комментариев, в том числе и для того, чтобы можно было запускать программы как обычные скрипты
Пример вычисления факториала 40 на NewLang
#!../output/nlc --eval
fact := 1\1; # Рациональное число без ограничений точности
mult := 40..1..-1?; # Получить итератор для множителей от 40 до 2
[mult ?!] <-> { # Цикл, пока не закончатся данные итератора
fact *= mult !; # Множитель из текущего элемента итератора
};
fact # Вывести итоговый результат
Вывод:
815915283247897734345611269596115894272000000000\1
Нет никаких условных компиляций и ifdef-ов!!!
Вместо switch-case реализован оператор оценки выражений, это более продвинутая версия Pattern Matching, для которой можно указать, какой их операторов сравнения нужно использовать:
==> — сравнение на равенство с приведением типов;
===> — сравнение на точное равенство;
~> — проверка типа (имени класса);
~~> — утиная типизация;
~~~> — строгая утиная типизация.
Правда поддержку инфиксной записи для произвольных символов как Вольфраме в настоящий момент делать не планирую, т. к. очень сильно сбивает с толку, так же как и не явное умножение. Может быть это и здорово выглядит на бумаге, но для парсера это будет сущий ад и море ошибок. И я не понял, что имеется ввиду под «Поддержкой data-flow стиля»
Компилятор языка делается именно как транспайлер на С++Конкретно для меня в приоритете именно c#.
Для снижения количества скобок пришлось специально ограничить систему встроенных типов (есть только тензоры в квадратных скобках и словари в круглых скобках)А вот у меня прямо противоположное видение — увеличить количество встроенных примитивных типов. Перечисление через пробел, запятую, точку, двоеточие и т.д. — это всё отдельные типы, а круглые/квадратные/угловые скобки — это контейнеры, позволяющих вложение друг в друга.
Отдельный тип для индексов не требуется, т. к. все числа знаковыеВам не требуется. Требуется мне) И не только чтобы к нему диапазон привязать, а дополнительную безопасность обеспечить и оптимизацию доступа.
Вместо switch-case реализован оператор оценки выражений, это более продвинутая версия Pattern MatchingТак я не о Pattern Matching говорил, а об автоматном программировании, когда есть принципиальная разница между switch(внутреннее состояние) и switch(внешние переменные), который это самое внутреннее состояние и меняет.
Насчет контроля внешних переменных, не уверен, что такое вообще возможноЭто возможно введением дополнительной языковой конструкции помимо if, например с названием check.
очень сильно сбивает с толку, так же как и неявное умножение. Может быть это и здорово выглядит на бумаге, но для парсера это будет сущий ад и море ошибокТак я именно от этого отталкивался — чтобы это здорово выглядело на бумаге и как мне самому бы хотелось писать. Парсер, конечно, придётся писать самостоятельно, но такой опыт у меня уже есть и не раз. Представление, как преобразовать неявное умножение к явному тоже есть — это можно сделать просто через пару текстовых замен по шаблону и определить операцию умножения для токена функции.
==> — проверка на равенство с приведением типовК слову, её нельзя выполнить однозначно. Равенство int64 c double может отличаться от того, к какому именно типу их приводить. Я бы запретил любые неявные сравнения.
fact := 1\1;
mult := 40..1..-1?;
[mult ?!] <-> {fact *= mult !;};Не хотелось бы критиковать ваш в код. Но в чём здесь преимущество перед
bigint x=1;
for(k=2..n) x*=k;?
(А обратный слэш обычно для спец.символов зарезервирован, я бы не стал его занимать — мало ли, может и до латеха дело дойдёт).
что имеется ввиду под «Поддержкой data-flow стиля»Это такой стиль программирования, когда вы не пишите, в каком порядке вызываются ваши функции. Вместо этого вы пишите, откуда и куда посылаются данные, в любом порядке. Таким образом получается ориентированный граф, который перед выполнением сортируется, а заодно и исследуется на наличие обратных связей и «мёртвых» объектов, которые не получают и не отдают данных. Также заодно можно выяснить (также полностью автоматически) что из этого можно выполнить параллельно. Все переменные хранятся непосредственно в памяти, что также снижает вероятность stack overflow.
UPD: неявное умножение можно ещё задать через правило "константа/переменная — тоже функция". тогда записи sin(x), y(x), 5(x) будут совершенно равнозначны.
По поводу рациональных чисел: в них можно корректно обрабатывать деление на ноль. У вас учитываются такие случаи?
Я продолжаю считать, что неявное умножение, которое принято использовать в письменной записи формул, слабо применимо в языках программирования, так как добавляет сильную неоднозначность из-за похожести на вызов функции.
В текущей реализации рациональных чисел, деление на ноль обрабатывается корректно за счет того, что рациональное число представляется двумя частями и перед конвертацией в обычную форму делитель проверяется на ноль. А если делать вывод в форме рационального числа как дроби, например 123\0, то проблемы с делением на ноль не возникает, т.к. тут деление на ноль выполнять не требуется.
Я продолжаю считать, что неявное умножение, которое принято использовать в письменной записи формул, слабо применимо в языках программирования, так как добавляет сильную неоднозначность из-за похожести на вызов функции.Так я об этом и написал. Раз это похоже на вызов функции — то и обработать это можно корректно тоже как вызов функции. В своём скриптовом калькуляторе уже частично реализовал, пока не нашёл никаких неоднозначностей.
деление на ноль обрабатывается корректноЧто у вас получится в результате
123/0 + 1/1 =?
123/0 + 1/0 =?
пока не нашёл никаких неоднозначностей.
Тут ключевое слово пока
Что у вас получится в результате
Ничего не получится, так как это деление на ноль, а не рациональные числа. При записи литералов в форме рациональных чисел используется обратный слеш:
123 \ 0 + 1 \ 1 =?
123 \ 0 + 1 \ 0 =?
но их создать не выйдет, так как у литералов знаменатель должен быть отличным от нуля, поэтому эти примеры просто не скомпилируются.
Тут ключевое слово покаЕсли вы эти неоднозначности сможете продемонстрировать — я буду очень, очень благодарен. Wolfram Mathematica использует неявное умножение давно и успешно.
Ничего не получитсяЭто неправильный ответ, по крайне мере с точки зрения классической алгебры.
но их создать не выйдетТо есть у вас нельзя писать типа
a=1\1;
b=0\1;
c=a/b;?
Wolfram Mathematica использует неявное умножение давно и успешно.
Я очень рад за Wolfram Mathematica, так как у меня это сделать не получилось, по описанной выше причине. После чего дальнейшие эксперименты в данном направлении я решил прекратить, но если у вас это получится сделать, я с удовольствием изучу использованный вами подход к реализации неявного умножения в синтаксисе языка.
То есть у вас нельзя писать типа
Можно и вы привели пример записи рациональных числе в виде литералов. А выше я писал, что таком образом записать в знаменателе 0 не получится, т.е. при записи 123 \ 0 или 1 \ 0 произойдет ошибка компиляции.
Так в с какой результат будет? 1\0 или ошибка "деление на ноль" или что-то ещё?
Будет ошибка компилятора - "Знаменатель рационального числа должен быть отличен от нуля"
Прошу прощения, я не совсем правильно сформулировал мысль. Под "корректно" понималось "не вываливаться с ошибкой деления на ноль — а продолжать вычисления и в итоге получить корректный результат".
Простите, а как при делении на ноль в итоге получить корректный результат?
 .
.Рациональное число можно спроецировать на комплексную плоскость и там и
, и  будут совершенно равнозначны по статусу, равно как и
будут совершенно равнозначны по статусу, равно как и  . Вы же наверняка знаете о функции
. Вы же наверняка знаете о функции atan(x,y) и как она соотносится с atan(y/x).Барицентрическая рациональная интерполяция так и определяется — там в промежуточных вычислениях получается деление на ноль в узловых точках. В известных мне реализациях эта проблема обходится через явную проверку, попадает ли аргумент в узловую точку или нет. Рабочее решение, но только если узловые точки известны заранее и есть уверенность в отсутствии особых точек в других местах.
Ваш пример основан на символьных вычислениях, которые хочется реализовать, но пока на это нет времени. Да если честно, и насущной необходимости в этом функционале не наблюдается. Хотя не скрою, мне лично было бы очень интересно в покопаться в этой задаче.
Нет, именно численно. Всё по классике — определяешь класс/структуру, перегружаешь операторы и вперёд. Вот только писать постоянно типа new Rational(a,b) не очень интересно, интересно писать a/b или a:b. До кучи хочется поныть — в с++ можно перегрузить () << >> но нельзя [], а в c# можно [], но нельзя остальное. Сколько уже можно за наследие си держаться, чисто битовые операции используются не так уж и часто, чтобы выделять им элементарные символы.
Вы описание символьное решение, так результатами численных выражений 5/0 и 0/0 будут ошибки.
А что касается перегрузки, то я к ней отношусь как к раздражающей необходимости. Она возникла в С++ из-за слабой статической типизации языка и в купе с манглингом имен, как способ статической линковки.
В NewLang я изначально отказался от перегрузки, так как это язык с со строгой динамической типизацией, и вместо перегрузки функций реализовано их переопределение, что, как мне кажется проще и при отладке и при последующей поддержке.
Не будет ошибки, оно же как структура хранится — числитель отдельно, знаменатель отдельно. И пересчитываются они тоже по отдельности. Точно так же, как и комплексное число. На практике уже испробовано.
Давайте мухи отдельно, котлеты отдельно.
Я понимаю, что числитель и знаменатель хранятся отдельно (у меня именно так сейчас и сделано), и пересчитываются по отдельно так же как и комплексные числа. Это один момент который не вызывает споров и разночтений.
Второй момент, результатами выражений 5/0 и 0/0 будут ошибки при численных вычисления. Вычислить подобные выражения можно только во время символьных вычислений, например с помощью SymPy, но это никаким образом не связано и не зависит от способа хранения данных.
с удовольствием изучу использованный вами подход к реализации неявного умножения в синтаксисе языка
Так вроде я уже рассказал, как. Можно ли это сделать в парсерах общего назначения и как — вопрос уже другой. Я предпочитаю писать парсеры самостоятельно, это не так уж и сложно.
Тут проблема не в парсере. Естественно парсер сможет распознать такую конструкцию. Проблема возникает в последующей интерпретации полученных выражений.
В нормальной математической записи скобки используются только для группировки выражений и указания приоритетов выполнения операций. Но когда скобки используются еще и для передачи аргументов в функции, для записи литералов-словарей, для форматирования строк, то мало того, что вы можете пропустить ошибку из-за обычной опечатки, так еще и сами будете путаться в подобных записях.
Забыли упомянуть классику - lex+yacc
Хотя это в приципе переросло в flex+bison
Bison сам вызывает лексер для получения очередной порции данных
Но ведь... %define api.push-pull push
Могу порекомендовать пару Ragel + Lemon.
Какую цель ставишь для парсера языка?
Немного не понял вопроса.
Какая может быть цель у парсера в отрыве от языка программирования для которого он делается?
Может быть речь идет о вариантах оптимизации его работы (если судить по твоей собственной статье на эту тему)?
Но в моем случае оптимизация не главное, так как синтаксис не очень сложный.
В у моего парсера цель - подготовить данные к машинному обучению. Поэтому из XML формата извлекаются данные (слова языка программирования) и преобразуются в формат подходящий для языкового анализа. Оптимизация в моей статье - это попутное явление, пришлось делать ради обработки за хоть какое-то разумное время.
Я читал вашу статью, но все равно не понял смысла. Часто машинное обучение это тоже не цель, а средство (способ) для достижения конечной цели (нарисовать кантинку, сгенерировать текст, сделать чатбота который бы осмысленно отвечал на сообщения т.д.)
Может быть я упустил из виду назначение вашей модели? Для чего она делается? Если у нее на входе слова языка программирования, то что должно быть на выходе?
Всё вы правильно поняли, машинное обучение тоже не цель моей задачи, это средство, которое должно связать язык программирования с данными обработки текстов пользовательского уровня.
которое должно связать язык программирования с данными обработки текстов пользовательского уровня.
А можно побольше конкретики? Я все равно не понимаю, что должно получиться.
На входе размеченный текст на каком то языке программирования, правильно?
А на выходе результат обработки текстов с помощью переданной на вход текста программы?
Если это так, то не проще ли будет обработать входные данные непосредственно самой программой вообще без машинного обучения или я чего-то не понимаю?
А вы не рассматривали Pratt parsing?
Эта невероятно простая и гибкая техника используется в синтаксическом анализаторе транспайлера для языка 11l.
Нет, не рассматривал. Но даже если бы и смотрел в его сторону, то все равно отказался бы от его использовании по такой же самой причине, что и от ANTLR
по такой же самой причине, что и от ANTLR
А это по какой причине?
Что "он написан на Java"?
Pratt parser — это не библиотека, а алгоритм/техника синтаксического разбора, описанная Воном Праттом в его статье полувековой давности.
Есть реализации этой техники на Java, JavaScript, C#, Rust, Python, C++, Scheme и наверняка на каких-то других языках.
А это по какой причине?
Все из-за поговорки: "лучшее враг хорошего". Я понимаю, что абсолютно все парсеры не перепробовать, но у меня и нет такой цели. Мне нужно, чтобы он работал и выполнял нужные мне задачи.
В настоящий момент со всеми задачами успешно справляется связка flex + bison. Поэтому нет особого смысла тратить время на попытку прикрутить новый вариант парсера вместо уже работающих, так как не понятно зачем это делать.
Фактически, сейчас у меня ситуация "если работает, то не трогай". Конечно, если будет очередной затык, с чем flex + bison справится не сможет, тогда я обязательно посмотрю Pratt parser.
Но в любом случае спасибо за наводку!
Нюансы разработки парсера для своего языка программирования