

Меня зовут Андрей, я разработчик библиотеки ETNA в Тинькофф. В статье расскажу, как быстро и легко анализировать временные ряды с помощью ETNA, зачем временным рядам столько фич, и покажу, что даже простой линейной моделью можно получить хороший результат прогнозирования.
Использую ETNA для решения соревнования Tabular Playground Series — Jan 2022. В соревновании нужен прогноз продаж мерча: кружек, стикеров и шапок. Прогнозы строятся для шести воображаемых магазинов, по два в Финляндии, Норвегии и Швеции. Задача: спрогнозировать продажи на год вперед и оценить качество прогноза по SMAPE.
Если вы еще не знакомы с ETNA, о ней рассказала моя коллега Юля:
Как загружать данные в ETNA
Данные собраны в таблицу: row_id — номер строки, date — временная метка, country — страна продажи, store — название магазина, product — вид товара, num_sold — количество проданного товара. Нужно спрогнозировать комбинации country-store-item.
Чтобы подсчитать общее количество комбинаций country-store-item посмотрим на уникальные значения в колонках country, store и product.
Чтобы привести данные в формат, с которым работает ETNA, нужно выделить отдельные временные ряды — сегменты. Для этого добавим колонку segment — именно такое имя будет ждать ETNA — и положим в нее комбинацию country-store-item. Это позволит фреймворку в дальнейшем отделять разные временные ряды друг от друга. Получается 18 временных рядов: нужно спрогнозировать три различных товара в двух магазинах, каждый из которых находится в трех странах.
Пример, как получить колонку segment:
Посмотрим на то, что получилось:
Теперь каждый временной ряд имеет свою метку, которая лежит в колонке segment. Но Dataset все еще не в формате, который сможет «переварить» ETNA. Добавим пару штрихов:
Это минимально необходимый Dataset для ETNA. Target — специальное зарезервированное имя для обозначения колонки, которую мы хотим спрогнозировать. А timestamp — для обозначения временной метки, так как ETNA умеет работать с разной частотностью данных. Timestamp, segment и target — именно из таких колонок должен состоять Dataset для ETNA. Остальные колонки я удалил, но в следующих туториалах мы покажем, как ими можно было бы воспользоваться.
Подготовительный этап закончен, и можно импортировать в ETNA. В первую очередь нам понадобится TSDataset, в котором будут храниться данные. Внутри TSDataset они лежат в особом формате. Для конвертации уже существует специальный метод TSDataset.to_dataset(). Используем его и посмотрим, как изменились данные, а точнее их формат:

Теперь можно создать TSDataset с данными.
Зачем тратить столько сил на конвертацию данных из одного формата в другой и пользоваться специальным форматом данных?
Плюсы использования TSDataset:
удобно индексирует данные по времени, сегменту и имени колонки;
проводит валидацию данных;
взаимодействует с другими частями пайплайна прогнозирования;
помогает проводить базовую аналитику данных;
генерирует будущие значения ряда для прогнозирования;
удобно индексироваться по рядам: первый индекс отвечает за временное измерение, второй за сегмент, а третий за отдельную колонку.
Покажу еще несколько важных этапов работы с временными рядами, где функции TSDataset оказываются незаменимыми.


Анализ рядов
Посмотреть данные после загрузки и проанализировать можно с помощью метода describe. Видно, что с данными все хорошо: пропущенных значений нет и они заканчиваются в одну дату.

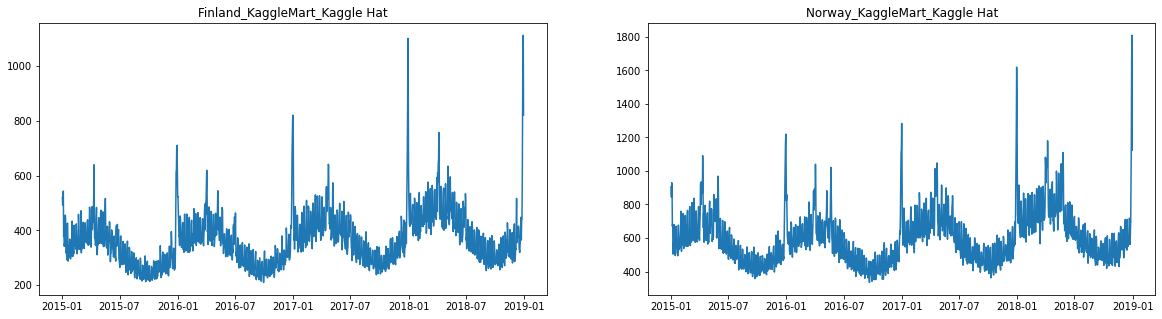
У TSDataset есть встроенный метод plot, с помощью которого можно посмотреть на временные ряды. Ряды имеют годовую сезонность, пики распределены не случайным образом — это праздники. Можно предположить, что в рядах присутствует тренд.

Генерация признаков
Сгенерирую различные признаки с помощью ETNA и постараюсь объяснить, что они значат.
Лаги — это некоторое предыдущее значение временного ряда. Например, первый лаг — это вчерашнее значение. А пятый лаг — значение пять дней назад. Такие признаки необходимы для регрессионных моделей, например линейной регрессии или бустинга, чтобы получить информацию о прошлом ряда.


Попробуем применить лаг с шагом 1 и посмотреть, что получится.
Укажем список нужных нам лагов. В этом случае lags=[1]. Видим, что появилась новая колонка и в ней лежит наш лаг. Причем этот лаг мы сразу получили для всех сегментов благодаря тому, что ETNA способна работать с несколькими рядами одновременно.

Но что, если нам нужно сгенерировать несколько лагов? Это тоже легко сделать с помощью ETNA. Нужно указать в списке все лаги, которые нам нужны.


Статистики — еще один важный признак. Он хорошо себя показывает в регрессионных моделях, так как дает возможность передать моделям информацию о прошлом, но в отличном от лагов формате. Статистики бывают такие: среднее, медиана, среднеквадратичное отклонение, минимум или максимум на отрезке.
Покажу, как этот признак работает на примере среднего. Запустить MeanTransform не сложнее, чем лаги.


С помощью такой фичи можно передавать модели информацию о среднем значении за последний месяц и неделю. А можно получать информацию о среднем значении за конкретные дни недели.


Даты — это временные метки, и их можно использовать. Например, для того, чтобы указывать дни недели, месяца, номер недели в месяце и в году или информацию о том, выходной сегодня или нет.
Попробуем это сделать для нашего Dataset:

Праздники. C временными метками работает и HolidayTransform. Для работы он использует библиотеку holidays, в которой уже записаны основные праздники для большинства стран. Нам нужно указать только ISO-код страны, и готово:

Логарифмирование. Я уже рассказал про трансформы, которые для генерации новых признаков используют сам ряд и которые используют его временную метку. Расскажу еще про один тип трансформов — те, что меняют сам ряд, или inplace-трансформы. Среди них самый простой — LogTransform. Он логарифмирует значения временного ряда.

Если мы хотим вернуть ряду его исходный вид, нужно воспользоваться методом inverse_transform:

Если мы хотим получить логарифмированные значения ряда, но не хотим «затирать» исходное, это можно сделать с помощью параметра inplace=False.

Прогнозирование
Мы получили значения, с помощью которых можно спрогнозировать ряды. Для прогноза я использовал обычную линейную модель. Это регрессионная модель, поэтому для нее нужно собственноручно сгенерировать фичи.
О разнице между регрессионными и авторегрессионными моделями и о разных стратегиях прогнозирования мы расскажем в одном из следующих туториалов.
Прогнозируем продажи на год вперед, поэтому горизонт прогноза — 365 дней. Предварительный анализ показал, что у рядов есть недельная сезонность, поэтому попробую использовать семь лагов: с 365 до 371 включительно.
Используем сдвиг в год, а не лаги с первого по седьмой, потому что модель не сможет ничего спрогнозировать. В таком случае почти на всех точках мы не сможем получить значение признака для прогнозирования. Горизонт прогноза определяет минимальный лаг, которым модель может воспользоваться.


Для дат синтаксис, кажется, понятен без слов, так что посмотрим на праздники. Магазины в соревновании находятся в трех разных странах: Швеции, Норвегии и Финляндии. Задаем праздники этих стран и учитываем, что перед праздниками люди могут вести себя иначе. С помощью лагов передадим эту информацию модели.
Переходим к коду обучения. LinearPerSegmentModel — это модель. PerSegment значит, что для каждого временного ряда — сегмента — будет обучена своя линейная регрессия. Также есть LinearMultiSegmentModel, которая учится сразу на всех сегментах.
Pipeline — это класс, который объединяет модель и трансформации временного ряда и позволяет делать backtest над временным рядом. Это снимает довольно много головной боли с исследователя.
SMAPE — это метрика, относительная ошибка прогноза. SMAPE можно интерпретировать как процент, на который мы ошиблись при прогнозе. Pipeline знает, как применять метрики к временным рядам, и выдает подробный отчет с их значениями под каждый ряд.
Важно упомянуть, что я запускаю не прогнозирование, а backtest, чтобы посчитать метрики, сравнить результаты модели с последним известным годом и оценить качество модели. Для этого в ETNA есть несколько специальных функций. Я воспользуюсь plot_backtest.

Подробнее про backtest мы расскажем в будущих туториалах, а пока можно посмотреть jupyter notebook с примером.
Кажется, модель показывает себя хорошо. Попробуем спрогнозировать будущее.

Упакуем наши прогнозы в формат для submission и загрузим в Kaggle.
Заключение
Для этого соревнования мы подготовили более сложный, но робастный Kaggle-ноутбук.
В этой статье я:
показал, как работать с TSDataset;
рассказал, как работают лаги, статистики, флаги дат, праздники и логарифмирование;
познакомил с интерфейсами моделей и пайплайнов;
написал, как запускать backtest, строить графики и запускать прогноз.
В следующих туториалах мы расскажем про более сложные, но интересные признаки, которые можно найти в ETNA, а также про другие модели и инструменты для анализа рядов. Stay tuned =)
Если вы хотите предложить новую фичу, задать вопрос или предложить тему для статьи, залетайте в наш GitHub — там все контакты.
