В чем залог успешной настройки Continuous Delivery на проектах? Слаженная работа команд разработки, тестирования и инженеров по инфраструктуре. Спасибо, кэп, как говорится :) Но как это реализовать на практике? В этой статье поделимся нашими наработками, как это всё организовать и воплотить в жизнь.
Мы обобщили базовые основы в одну шпаргалку для себя и делимся с вами:
Опытные инженеры вряд ли узнают из статьи что-то новое, но надеемся, что начинающим специалистам эта информация пригодится.

Перед каждым проектом стоит ряд требований. Важно все их понимать и не путать.
Бизнес-требования определяют, что система должна делать с точки зрения бизнеса.
Например: приложение должно позволять пользователю осуществлять продажу билетов и дополнительных услуг с целью увеличения продаж агентов.
Пользовательские требования описывают цели и задачи пользователей, которые будут осуществлять работу в системе для реализации бизнес-требований. Пользовательские требования часто представляют в виде User cases.
Например: как пользователю, мне необходимо осуществлять продажу услуг за мили.
Функциональные требования — что система должна делать. Определяют функциональность (поведение) системы, которая должна быть создана разработчиками для того, чтобы пользователи смогли выполнить пользовательские требования.
Нефункциональные требования — как система должна работать. Сюда входят требования к производительности, качеству, ограничения, usability и т. д.
Итак, мы описали виды требований. Теперь разобьём их на типы задач, расшифруем каждый тип и расскажем, как правильно его описывать.

Начнём с самой эпичной, то есть с Epic.
Epic — это общая задача, в которой собраны все User Story с учётом времени разработки сервиса. Он описывает главную цель продукта или сервиса. Основная цель Epic — собрать задачи и хранить их в одном месте независимо от того, какие новые требования выдвигаются к продукту. Epic всегда больше user story и может даже не умещаться в одной итерации.
Решение Epic-задачи позволяет создать MVP (Minimal Viable Product) — минимальный жизнеспособный продукт. Другими словами, то, что необходимо выпустить, чтобы изучать и адаптировать продукт по откликам от конечных пользователей.
Чем Epic отличается от User Story?
Отличие User story и Tech story в том, что Tech Story относится к функциональным требованиям, которые нужно учесть и описать в задаче при разработке продукта. И в роли потребителей здесь выступают части системы.
Описывать их несложно. Главное помнить, зачем все это делается.

Какую информацию нужно указывать, когда репортим баг:
1. Название / Summary / Title кратко описывает суть ошибки и указывает на место, где находится проблема.
2. Описание / Description содержит следующие шаги:
• как воспроизвести ошибку / шаги по воспроизведению,
• текущий результат,
• ожидаемый результат.
3. Вложения / Attachments — все необходимые логи, скриншоты, ссылки на Kibana и другие файлы.
4. Среда / Environment — отметка, в какой среде воспроизводится ошибка, и категория, к которой относится проблема. Например, ошибка на UI, ошибка CORE, ошибка SWS и т. д.
5. Приоритет / Priority позволит каждому члену команды оценить серьёзность проблемы, а менеджеру — увидеть её в списке первых кандидатов в sprint.
И не забывайте ставить корректный уровень приоритета :)
Теперь, когда разобрались с общими принципами работы, расскажем, как организовали конвейер развёртывания.
Чтобы ускорить поставку наших сервисов до продакшна, мы внедряем новый конвейер развертывания и используем GitFlow для работы с кодом.
Чтобы делать это быстро и динамически, мы развернули несколько GitLab-раннеров, которые запускали все задачи по пушу разработчиков. Благодаря подходу GitLab Flow, у нас появилось несколько серверов: Develop, QA, Release-candidate и Production.
Continuous Integration начал собирать и прогонять тесты по каждому комиту, прогонять unit-тесты и интеграционные тесты, складывать артефакты с поставкой приложения.
Разработка происходит так:
Если на каком-то этапе находятся ошибки, то именно в этой ветке мы их и решаем, после чего выкладываем результат в Develop.
Также мы сделали небольшой плагин, чтобы Redmine мог сообщать нам, на каком этапе находится фича. Это помогает тестировщикам оценить, на каком этапе нужно подключаться к задаче, а разработчикам — править ошибки. Так они видят, на каком этапе произошёл сбой, могут пойти в определенную ветку и воспроизвести её там.
Надеемся, вам было полезно.
Мы обобщили базовые основы в одну шпаргалку для себя и делимся с вами:
- Какие бывают требования и чем они характеризуются,
- Типы задач и порядок их описания в Issue tracker,
- Как оформлять User story и Tech story,
- Как описывать баги,
- Настройка конвейера развертывания.
Опытные инженеры вряд ли узнают из статьи что-то новое, но надеемся, что начинающим специалистам эта информация пригодится.

Какие бывают требования и чем они характеризуются
Перед каждым проектом стоит ряд требований. Важно все их понимать и не путать.
Бизнес-требования определяют, что система должна делать с точки зрения бизнеса.
Например: приложение должно позволять пользователю осуществлять продажу билетов и дополнительных услуг с целью увеличения продаж агентов.
Пользовательские требования описывают цели и задачи пользователей, которые будут осуществлять работу в системе для реализации бизнес-требований. Пользовательские требования часто представляют в виде User cases.
Например: как пользователю, мне необходимо осуществлять продажу услуг за мили.
Функциональные требования — что система должна делать. Определяют функциональность (поведение) системы, которая должна быть создана разработчиками для того, чтобы пользователи смогли выполнить пользовательские требования.
Нефункциональные требования — как система должна работать. Сюда входят требования к производительности, качеству, ограничения, usability и т. д.
Типы задач и порядок их описания в Issue tracker
Итак, мы описали виды требований. Теперь разобьём их на типы задач, расшифруем каждый тип и расскажем, как правильно его описывать.

Начнём с самой эпичной, то есть с Epic.
Epic — это общая задача, в которой собраны все User Story с учётом времени разработки сервиса. Он описывает главную цель продукта или сервиса. Основная цель Epic — собрать задачи и хранить их в одном месте независимо от того, какие новые требования выдвигаются к продукту. Epic всегда больше user story и может даже не умещаться в одной итерации.
Решение Epic-задачи позволяет создать MVP (Minimal Viable Product) — минимальный жизнеспособный продукт. Другими словами, то, что необходимо выпустить, чтобы изучать и адаптировать продукт по откликам от конечных пользователей.
Чем Epic отличается от User Story?
- Epic — это просто большая история пользователя, отличительной особенностью которой является наличие явной ценности для пользователя.
- Начиная формировать истории пользователей, т. е. собирая требования к проекту, мы обычно движемся от общего к частному — сначала определяемся с концепцией проекта, выделяем основные персоны (пользователей системы), формируем перечень основных фич, и дальше эти фичи детализируем в отдельные пожелания — User story.
Порядок описания Epic таков:
- Название / Summary Title — название нового функционала.
- Описание / Description — пишется по шаблону:
Роль пользователя (как такой-то пользователь, я…) / Действие пользователя (хочу сделать что-то…) / Результат действия (чтобы получить такой результат, который…) / Интерес или выгода (позволит мне получить такие-то выгоды…). - Примерный план реализации или краткое описание основных User Stories, которые будут выполнены в рамках Epic с учетом MVP.
- Вложения / Attachments — прикрепляем переписку, технологии и другую необходимую информацию.
Как оформлять User story и Tech story
Отличие User story и Tech story в том, что Tech Story относится к функциональным требованиям, которые нужно учесть и описать в задаче при разработке продукта. И в роли потребителей здесь выступают части системы.
Описывать их несложно. Главное помнить, зачем все это делается.

Порядок описания User story вполне стандартный:
- Название / Summary / Title — краткое описание нового функционала или доработки на языке, понятном заказчику.
- Описание / Description включает в себя основную цель и желаемый результат. Как, <роль пользователя>, я <хочу получить>, с целью <результат действий>.
- Критерии приёмки / Acceptance Criteria — это список приоритетных критериев продукта. То есть измеримое определение того, что следует сделать с продуктом, чтобы он был принят заинтересованными сторонами проекта.
- Технические заметки, модели, макеты, структурные схемы страниц.
- Вложения / Attachments — все необходимые технологии, документы, переписка с заказчиком.
Как описывать баги
Какую информацию нужно указывать, когда репортим баг:
1. Название / Summary / Title кратко описывает суть ошибки и указывает на место, где находится проблема.
2. Описание / Description содержит следующие шаги:
• как воспроизвести ошибку / шаги по воспроизведению,
• текущий результат,
• ожидаемый результат.
3. Вложения / Attachments — все необходимые логи, скриншоты, ссылки на Kibana и другие файлы.
4. Среда / Environment — отметка, в какой среде воспроизводится ошибка, и категория, к которой относится проблема. Например, ошибка на UI, ошибка CORE, ошибка SWS и т. д.
5. Приоритет / Priority позволит каждому члену команды оценить серьёзность проблемы, а менеджеру — увидеть её в списке первых кандидатов в sprint.
И не забывайте ставить корректный уровень приоритета :)
Теперь, когда разобрались с общими принципами работы, расскажем, как организовали конвейер развёртывания.
Настройка конвейера развертывания
Чтобы ускорить поставку наших сервисов до продакшна, мы внедряем новый конвейер развертывания и используем GitFlow для работы с кодом.
Чтобы делать это быстро и динамически, мы развернули несколько GitLab-раннеров, которые запускали все задачи по пушу разработчиков. Благодаря подходу GitLab Flow, у нас появилось несколько серверов: Develop, QA, Release-candidate и Production.
Continuous Integration начал собирать и прогонять тесты по каждому комиту, прогонять unit-тесты и интеграционные тесты, складывать артефакты с поставкой приложения.

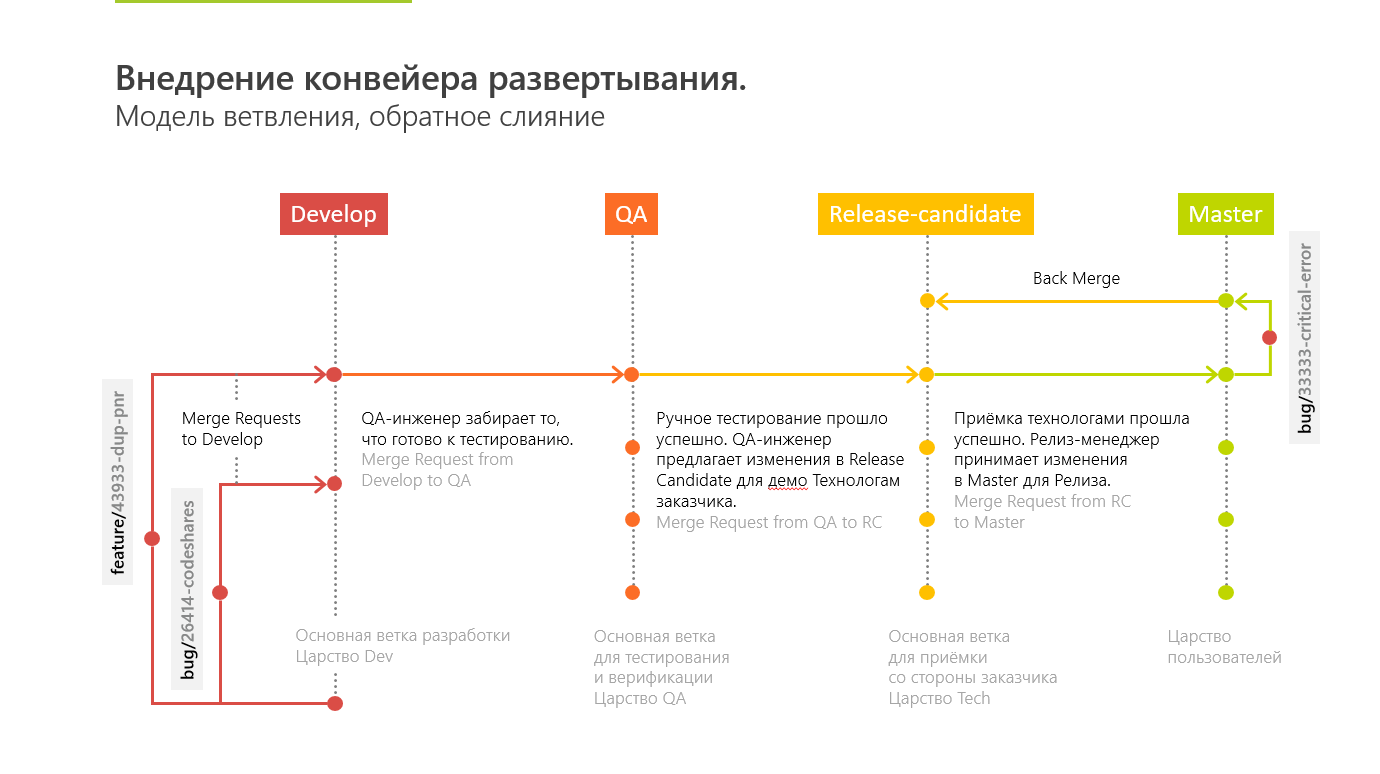
Разработка происходит так:
- Разработчик добавляет новый функционал в отдельной ветке (feature branch). После этого он создает запрос на слияние его ветки с магистральной веткой разработки (Merge Request to Develop branch).
- Запрос на слияние смотрят другие разработчики, принимают его (или нет) и исправляют замечания. После слияния в магистральную ветку разворачивается специальное окружение, на котором выполняются тесты на поднятие окружения.
- Когда все эти этапы закончены, QA инженер забирает изменения к себе в ветку “QA” и проводит тестирование.
- Если QA инженер согласовывает проделанную работу, изменения переходят в ветку Release-Candidate и разворачиваются на окружении, которое доступно для внешних пользователей. На этом окружении заказчик производит приемку и сверку технологий. Затем мы перегоняем всё в Production.
Если на каком-то этапе находятся ошибки, то именно в этой ветке мы их и решаем, после чего выкладываем результат в Develop.
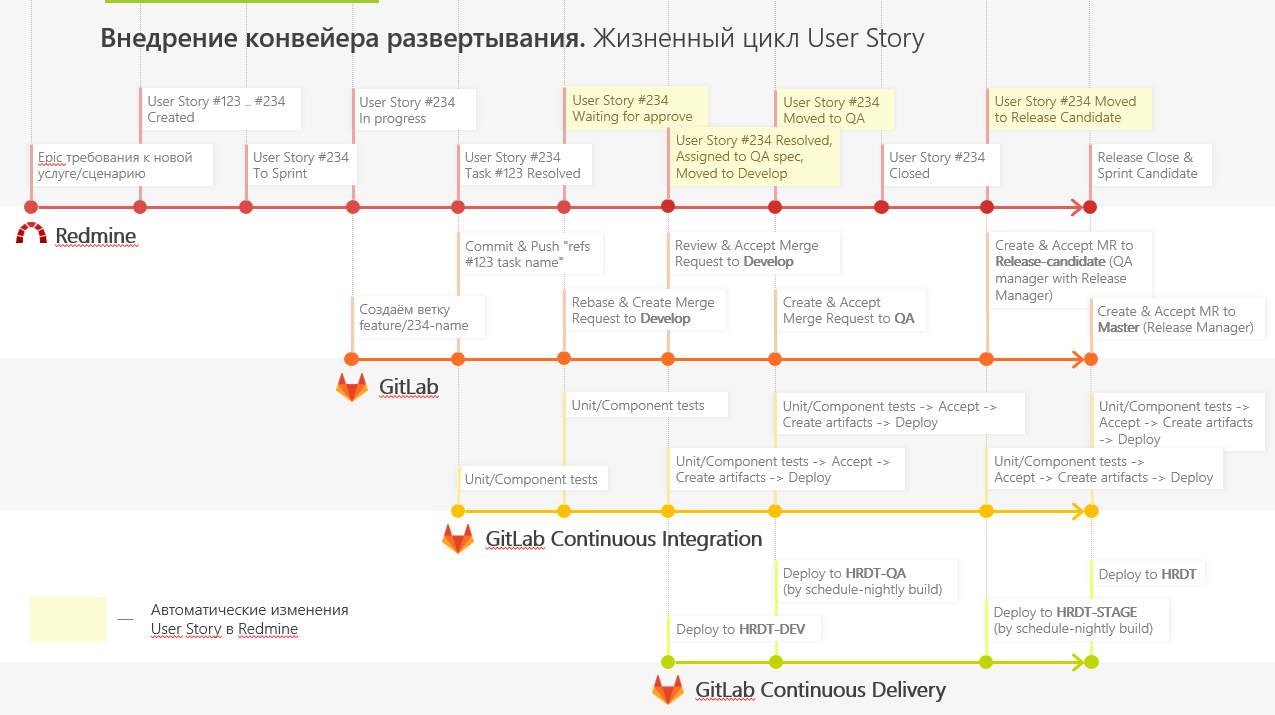
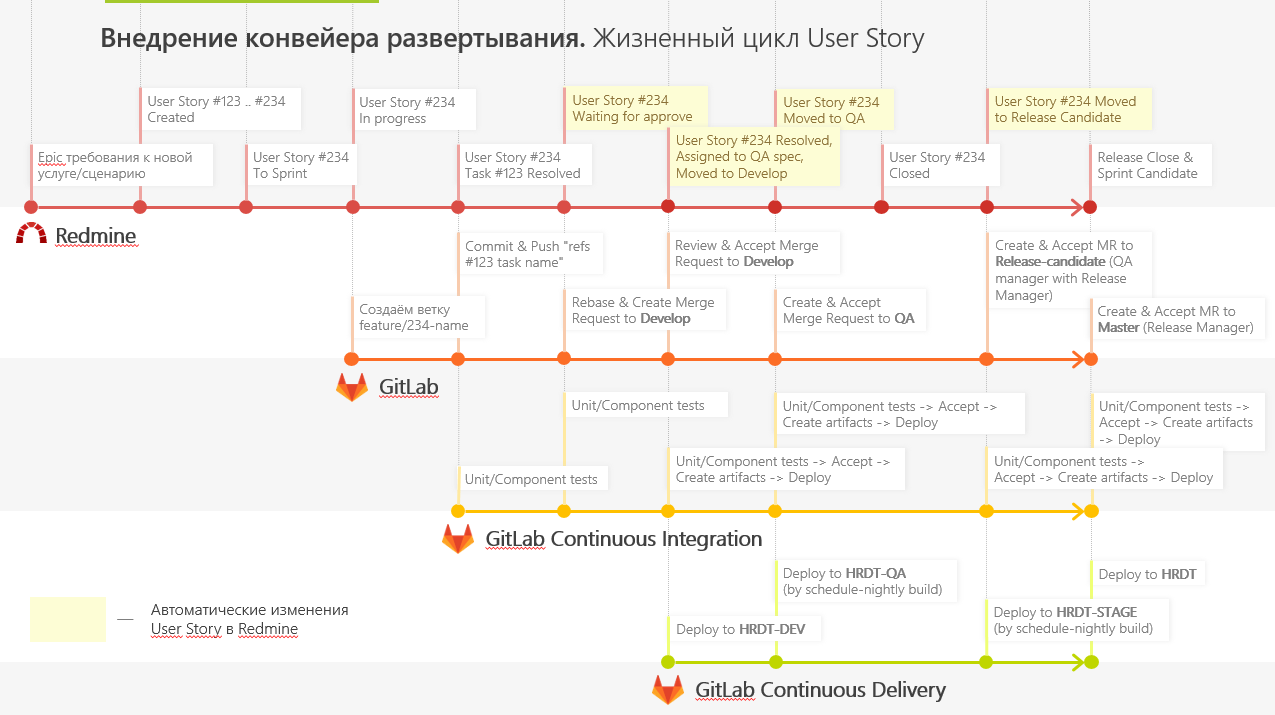
Также мы сделали небольшой плагин, чтобы Redmine мог сообщать нам, на каком этапе находится фича. Это помогает тестировщикам оценить, на каком этапе нужно подключаться к задаче, а разработчикам — править ошибки. Так они видят, на каком этапе произошёл сбой, могут пойти в определенную ветку и воспроизвести её там.
Надеемся, вам было полезно.
