
На рынке доступно большое количество накопителей различных скоростей, различных производителей. Далеко не все четко понимают, какой диск лучше приобрести и для какой задачи и зачем порой лучше заплатить больше, а когда можно сэкономить. В этой статье я постараюсь прояснить основные моменты и сделать проблему выбора более простой. Статья будет полезна не только тем, кто хочет купить/арендовать выделенный сервер, но и тем, кто хочет получить надежное хранилище информации дома. После прочтения материала станет понятным, почему не всегда целесообразно арендовать desktop-решения в low-cost дата-центрах и лучше остановить выбор на более надежном, серверном железе.
Начнем с того, что все имеющиеся на рынке накопители, можно четко разделить на классы:
— диски для обычных desktop-ов (применяются в домашних ПК, в ноутбуках и в desktop-серверах low-cost дата-центров);
— серверные диски со скоростью 7200 оборотов в минуту (RPM);
— Enterprise-диски со скорость 10 000 и 15 000 RPM;
— твердотельные накопители.
Особенности выбора твердотельных накопителей мы, пожалуй, рассмотрим в отдельной статье, а сейчас остановимся преимущественно на жестких дисках и рассмотрим какой диск где и когда целесообразно применять.
Начнем с обычных дисков для PC. Это отличные диски с довольно большой емкостью и хорошей производительностью, но их главный недостаток в том, что они не рассчитаны на работу в RAID-массиве в силу своих конструктивных особенностей. В этих дисках вибрации, вызываемые вращением шпинделя, практически никак не компенсируются. Конечно эти вибрации минимальны и в случае применения 1-2 дисков в домашних условиях они не являются проблемой. Однако, если рассматривать серверный случай, когда дисков много, влияние вибраций может быть довольно существенным, так как возникают взаимные вибрации, резонанс усиливает эффект. Так, когда в корпусе установлено сразу 12 дисков, да еще и работают довольно мощные серверные вентиляторы по 5000-9000 оборотов в минуту — уровень вибрации нарастает довольно значительно, а с ними и % ошибок, потерь, что и оказывает негативное влияние на производительность. Производительность дисков десктопного типа падает в этих случаях в разы, так как они испытывают значительные трудности с позиционированием головок, теряют дорожку. Это хорошо можно видеть из популярного графика зависимости производительности от вибрационной нагрузки:
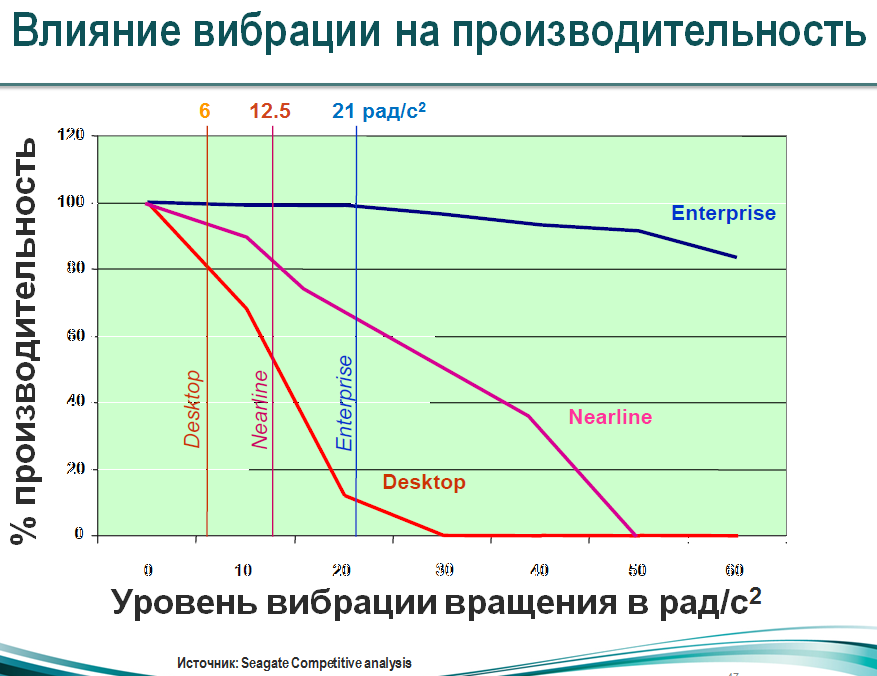
Другое дело диски SATA RE (RAID Edition) или же серверные диски со скоростью 7200 RPM. Они менее подвержены вибрациям и в меньшей степени зависят от них. Как видим из графика — вероятность возникновения ошибки в результате вибраций на 50% ниже для них.
Но не только вибрации являются проблемой, другая основная проблема всех дисков — уровень невозобновимых ошибок. Что это означает на практике?
Для SATA PC дисков уровень невозобновимых ошибок 1 ошибка на 1014 бит, или 1 ошибка на 12,5 ТБ данных. Диск на 1ТБ имеет 1000/12500х1014 бит. 5 дисков имеют емкость 5х(1000/12500х1014) бит, а вероятность возникновения ошибки при работе этих дисков в массиве RAID5 будет составлять (5х(1000/12500х1014))/1014x100% = 40%.
Как видим, использовать 5 PC-дисков в RAID5 просто нельзя, так как вероятность возникновения невосстановимой ошибки при ребилде очень высока и ребилд завершится скорее неудачно. Таким образом мы получим массив, который заведомо выйдет из строя в случае ребилда и данные будут утеряны. Ранее я не знал об этой особенности и в 2008-м году, когда собирал свой первый сервер еще на PC-шных накопителях, построил именно RAID5-массив, с целью экономии дискового пространства и денег, и менее, чем через месяц, данные были потеряны. Сейчас мне удивительно, что массив прожил так долго :)
Конечно, можно применять более надежные уровни RAID, такие, как RAID10 или в крайнем случае RAID6, но при большом количестве дисков мы также будем получать довольно высокую степень вероятности возникновения невосстановимой ошибки во время ребилда.
Другое дело серверные диски со скоростью 7200 оборотов в минуту (RPM) SATA RE или диски Near Line (NL) SAS. Вероятность невосстановимой ошибки для них на порядок меньше уже за счет их технических особенностей, 1 ошибка возникает на 1015 бит данных. Тем не менее, при использовании не только большого количества накопителей, но и накопителей большого объема — этого может быть уже недостаточным и в таких случаях все же придется применять SAS-накопители Enterprise класса, степень надежности которых 1 невосстановимая ошибка на 1016 бит данных.
Стоит также отметить, что на самом деле для дисков SATA RE, Near Line (NL) SAS и дисков SAS Enterprise-класса, по сути дисков, которые умеют эффективно взаимодействовать с RAID-контроллером, вероятность возникновения невосстановимой ошибки еще значительно меньше, как раз за счет этой способности. Так, при работе с нагруженным массивом (базы данных, с которыми работают сразу много пользователей, активная запись и считывание данных) начинают играть роль уже восстановимые ошибки, с которыми обычные диски работают неэффективно. Они пытаются перечитать проблему многократно — в тех же Western Digital значение установлено на 64 прохода головки с разными параметрами высоты, угла, только после чего головка переходит к обработке других задач. За счет этого сильно возрастает время ожидания, которое RAID не терпит и непременно сочтет диск потерянным и попытается восстанавливать диск, в результате чего нагрузка на массив приобретет критичный характер, так как одновременно с рабочей нагрузкой будет идти еще и ребилд. Результат предсказуем — крах всего массива.
Диски, которые умеют работать с RAID, могут сообщить RAID-контроллеру, что есть проблема с чтением блока данных, запросить этот блок с других дисков и в это время обрабатывать другие запросы, а получив блок — перезаписать его в другом месте проблемного диска. За счет этого никакого падения производительности RAID-массива не происходит и вероятность потери данных снижается значительно. Однако следует отметить, что не все софтовые рейд-контроллеры, установленные на чипсетах, умеют «понимать» такие диски, потому порой недостаточно иметь диски RE для надежного массива, а все же требуется применение аппаратного контроллера или другой платформы, которая корректно работает с RAID.
Тем не мене, если есть желание собрать более надежное хранилище, нежели хранилище на PC-накопителях, можно купить более дешевые диски, нежели диски RE, к примеру Constellation CS, которые предназначены для работы исключительно с софтовыми рейдами и лишены недостатка десктопных (попыток многократного перечитывания данных в ущерб другим задачам), при этом полноценно, само собой, с контроллерами они не взаимодействуют, так что cбои RAID полностью не исключены.
Вне зависимости от того, какой накопитель Вы применяете, Вы также должны помнить о том, что у дисков есть кеш — 32, 64 МБ и более. Что это значит для RAID-массива? С точки зрения производительности кеш является плюсом, как для чтения, так и для записи. Однако с точки зрения надежности записи — это минус. Используя кеш, рейд-контроллер будет думать, что уже записал данные на массив, но на самом деле они могут быть только в кеше, а на диск записаны быть позднее. В зависимости от размера массива растет и размер общего кеша, и в случае 12 накопителей кеш составляет уже почти гигабайт. Что произойдет с данными при отключении питания? Правильно. Они будут утеряны. И если речь идет о файлопомойке, тут, наверное, не на столько критично, но если же речь идет о базах данных — будет весело. Потому рекомендуется для данных особой критичности, такие, как базы данных, все же отключать кеш на запись. Это снизит производительность диска на 8-15% в режиме баз данных, однако в значительной степени увеличит надежность. По этой причине, если Вы приобретаете хранилище данных большой емкости, крупные производители отключают там кеш по умолчанию и включить его невозможно. Применяя же диски в серверах, особенно в low-сost дата-центре, где питание к серверу не резервировано, нужно помнить об этом риске и учитывать его.
Также отметим еще одну ключевую особенность дисков SAS Enterprise-класса, на них данные хранятся еще более надежно, так как минимальный размер кластера составляет 520 байт, а не 512, добавляется еще 8 байт для проверки четности. Применяется большое количество алгоритмов восстановления данных без участия контроллера. Именно по этой причине объем этих дисков не бывает очень большой.
К слову на счет объема, крайняя рекомендация, если у Вас есть задача хранить данные надежно, не пытайтесь использовать диски большего объема, нежели это необходимо, так как в случае ребилда восстановление будет занимать больше времени. Как правило контроллеры не анализируют то, сколько реально занято на диске и восстанавливают весь диск в целом, потому разница во времени восстановления между 1 ТБ и 6 ТБ накопителем будет более, чем в 6 раз.
Подведем итоги. Исходя из вышеизложенного понятно, что для небольшого RAID-массива, применение самых дорогостоящих дисков Enterprise класса не принципиально и не дает никаких преимуществ в надежности. Тем не менее, применение серверных дисков весьма желательно, так как в этом варианте на порядок большая вероятность того, что ребилд завершится успешно. Не следует применять диски большего объема, чем это необходимо, за исключением случаев, когда нужно обеспечить более высокую производительность по IOPS (в некоторых дисках большего объема все же может быть выигрыш по скорости за счет большего количества головок и пластин). В случаях, когда необходим большой объем и много дисков и при этом достаточный уровень надежности — можно смотреть в сторону SAS NL, которые по сути являются модифицированным вариантом накопителей SATA RE за счет интерфейса SAS, однако имеют все те же 7200 RPM. Для повышения уровня надежности целесообразно применять RAID более высокого уровня. Когда же объем массива не принципиален и требуется максимальная надежность, нужно однозначно применять SAS 15000 RPM Enterprise.
Теперь, выбирая в аренду сервер в Нидерландах, у нас на площадке Switch, при помощи конфигуратора, расположенного в нижней части страницы http://www.ua-hosting.company/servers, либо, модифицируя одно из спец. предложений:



Приходит понимание того, какие диски и какой из серверов лучше использовать и для каких задач, когда лучше использовать диски в RAID, а когда по отдельности, распределяя файлы софтом в зависимости от популярности (скрипт балансера в зависимости от нагрузки). Почему 4 диска большего объема, в плане надежности, может быть лучше, чем 12 меньшего, но хуже в плане времени восстановления в случае ребилда. Ну и самое важное — почему наше предложение реально крутое для серверного сегмента и мы реально приблизили цену к desktop-площадкам, при этом сохранив на порядок более высокую надежность без преувеличений! Так что если Вам, либо Вашим знакомым нужен хороший сервер — welcome, распродажа некоторых конфигураций из списка ниже ограничена, очень скоро цены на эти конфигурации будут выше, мы хоть и щедры, но не безгранично :):




Да, если у кого-то есть реальный опыт применения тех или других накопителей для определенных задач — не стесняйтесь делиться им в комментариях. Интересно все, вплоть до статистики отказов. На эту тему, как и по поводу проблематики выбора SSD-накопителя, мы постараемся опубликовать материал позднее.
Начнем с того, что все имеющиеся на рынке накопители, можно четко разделить на классы:
— диски для обычных desktop-ов (применяются в домашних ПК, в ноутбуках и в desktop-серверах low-cost дата-центров);
— серверные диски со скоростью 7200 оборотов в минуту (RPM);
— Enterprise-диски со скорость 10 000 и 15 000 RPM;
— твердотельные накопители.
Особенности выбора твердотельных накопителей мы, пожалуй, рассмотрим в отдельной статье, а сейчас остановимся преимущественно на жестких дисках и рассмотрим какой диск где и когда целесообразно применять.
Начнем с обычных дисков для PC. Это отличные диски с довольно большой емкостью и хорошей производительностью, но их главный недостаток в том, что они не рассчитаны на работу в RAID-массиве в силу своих конструктивных особенностей. В этих дисках вибрации, вызываемые вращением шпинделя, практически никак не компенсируются. Конечно эти вибрации минимальны и в случае применения 1-2 дисков в домашних условиях они не являются проблемой. Однако, если рассматривать серверный случай, когда дисков много, влияние вибраций может быть довольно существенным, так как возникают взаимные вибрации, резонанс усиливает эффект. Так, когда в корпусе установлено сразу 12 дисков, да еще и работают довольно мощные серверные вентиляторы по 5000-9000 оборотов в минуту — уровень вибрации нарастает довольно значительно, а с ними и % ошибок, потерь, что и оказывает негативное влияние на производительность. Производительность дисков десктопного типа падает в этих случаях в разы, так как они испытывают значительные трудности с позиционированием головок, теряют дорожку. Это хорошо можно видеть из популярного графика зависимости производительности от вибрационной нагрузки:
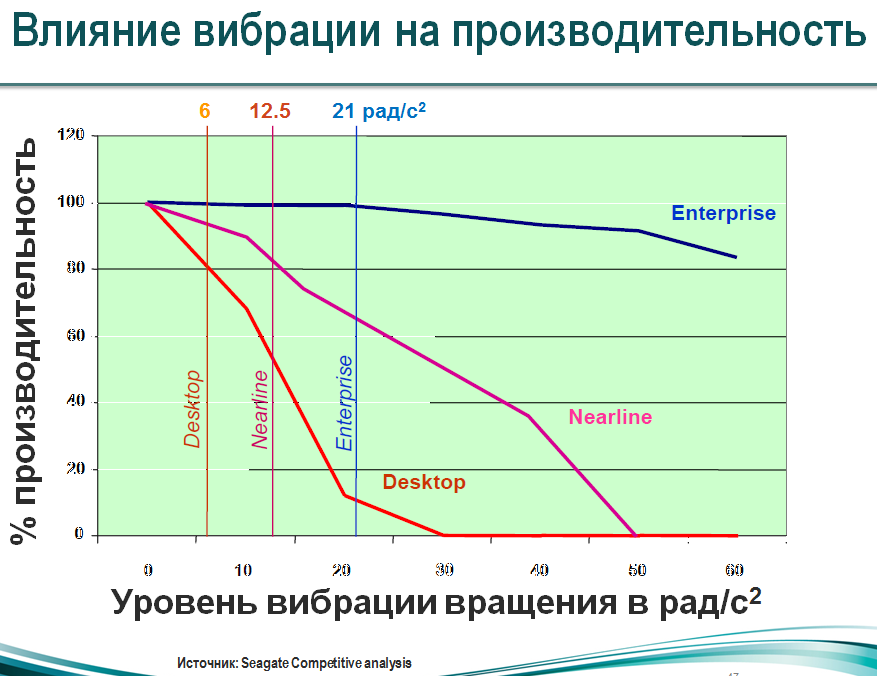
Другое дело диски SATA RE (RAID Edition) или же серверные диски со скоростью 7200 RPM. Они менее подвержены вибрациям и в меньшей степени зависят от них. Как видим из графика — вероятность возникновения ошибки в результате вибраций на 50% ниже для них.
Но не только вибрации являются проблемой, другая основная проблема всех дисков — уровень невозобновимых ошибок. Что это означает на практике?
Для SATA PC дисков уровень невозобновимых ошибок 1 ошибка на 1014 бит, или 1 ошибка на 12,5 ТБ данных. Диск на 1ТБ имеет 1000/12500х1014 бит. 5 дисков имеют емкость 5х(1000/12500х1014) бит, а вероятность возникновения ошибки при работе этих дисков в массиве RAID5 будет составлять (5х(1000/12500х1014))/1014x100% = 40%.
Как видим, использовать 5 PC-дисков в RAID5 просто нельзя, так как вероятность возникновения невосстановимой ошибки при ребилде очень высока и ребилд завершится скорее неудачно. Таким образом мы получим массив, который заведомо выйдет из строя в случае ребилда и данные будут утеряны. Ранее я не знал об этой особенности и в 2008-м году, когда собирал свой первый сервер еще на PC-шных накопителях, построил именно RAID5-массив, с целью экономии дискового пространства и денег, и менее, чем через месяц, данные были потеряны. Сейчас мне удивительно, что массив прожил так долго :)
Конечно, можно применять более надежные уровни RAID, такие, как RAID10 или в крайнем случае RAID6, но при большом количестве дисков мы также будем получать довольно высокую степень вероятности возникновения невосстановимой ошибки во время ребилда.
Другое дело серверные диски со скоростью 7200 оборотов в минуту (RPM) SATA RE или диски Near Line (NL) SAS. Вероятность невосстановимой ошибки для них на порядок меньше уже за счет их технических особенностей, 1 ошибка возникает на 1015 бит данных. Тем не менее, при использовании не только большого количества накопителей, но и накопителей большого объема — этого может быть уже недостаточным и в таких случаях все же придется применять SAS-накопители Enterprise класса, степень надежности которых 1 невосстановимая ошибка на 1016 бит данных.
Стоит также отметить, что на самом деле для дисков SATA RE, Near Line (NL) SAS и дисков SAS Enterprise-класса, по сути дисков, которые умеют эффективно взаимодействовать с RAID-контроллером, вероятность возникновения невосстановимой ошибки еще значительно меньше, как раз за счет этой способности. Так, при работе с нагруженным массивом (базы данных, с которыми работают сразу много пользователей, активная запись и считывание данных) начинают играть роль уже восстановимые ошибки, с которыми обычные диски работают неэффективно. Они пытаются перечитать проблему многократно — в тех же Western Digital значение установлено на 64 прохода головки с разными параметрами высоты, угла, только после чего головка переходит к обработке других задач. За счет этого сильно возрастает время ожидания, которое RAID не терпит и непременно сочтет диск потерянным и попытается восстанавливать диск, в результате чего нагрузка на массив приобретет критичный характер, так как одновременно с рабочей нагрузкой будет идти еще и ребилд. Результат предсказуем — крах всего массива.
Диски, которые умеют работать с RAID, могут сообщить RAID-контроллеру, что есть проблема с чтением блока данных, запросить этот блок с других дисков и в это время обрабатывать другие запросы, а получив блок — перезаписать его в другом месте проблемного диска. За счет этого никакого падения производительности RAID-массива не происходит и вероятность потери данных снижается значительно. Однако следует отметить, что не все софтовые рейд-контроллеры, установленные на чипсетах, умеют «понимать» такие диски, потому порой недостаточно иметь диски RE для надежного массива, а все же требуется применение аппаратного контроллера или другой платформы, которая корректно работает с RAID.
Тем не мене, если есть желание собрать более надежное хранилище, нежели хранилище на PC-накопителях, можно купить более дешевые диски, нежели диски RE, к примеру Constellation CS, которые предназначены для работы исключительно с софтовыми рейдами и лишены недостатка десктопных (попыток многократного перечитывания данных в ущерб другим задачам), при этом полноценно, само собой, с контроллерами они не взаимодействуют, так что cбои RAID полностью не исключены.
Вне зависимости от того, какой накопитель Вы применяете, Вы также должны помнить о том, что у дисков есть кеш — 32, 64 МБ и более. Что это значит для RAID-массива? С точки зрения производительности кеш является плюсом, как для чтения, так и для записи. Однако с точки зрения надежности записи — это минус. Используя кеш, рейд-контроллер будет думать, что уже записал данные на массив, но на самом деле они могут быть только в кеше, а на диск записаны быть позднее. В зависимости от размера массива растет и размер общего кеша, и в случае 12 накопителей кеш составляет уже почти гигабайт. Что произойдет с данными при отключении питания? Правильно. Они будут утеряны. И если речь идет о файлопомойке, тут, наверное, не на столько критично, но если же речь идет о базах данных — будет весело. Потому рекомендуется для данных особой критичности, такие, как базы данных, все же отключать кеш на запись. Это снизит производительность диска на 8-15% в режиме баз данных, однако в значительной степени увеличит надежность. По этой причине, если Вы приобретаете хранилище данных большой емкости, крупные производители отключают там кеш по умолчанию и включить его невозможно. Применяя же диски в серверах, особенно в low-сost дата-центре, где питание к серверу не резервировано, нужно помнить об этом риске и учитывать его.
Также отметим еще одну ключевую особенность дисков SAS Enterprise-класса, на них данные хранятся еще более надежно, так как минимальный размер кластера составляет 520 байт, а не 512, добавляется еще 8 байт для проверки четности. Применяется большое количество алгоритмов восстановления данных без участия контроллера. Именно по этой причине объем этих дисков не бывает очень большой.
К слову на счет объема, крайняя рекомендация, если у Вас есть задача хранить данные надежно, не пытайтесь использовать диски большего объема, нежели это необходимо, так как в случае ребилда восстановление будет занимать больше времени. Как правило контроллеры не анализируют то, сколько реально занято на диске и восстанавливают весь диск в целом, потому разница во времени восстановления между 1 ТБ и 6 ТБ накопителем будет более, чем в 6 раз.
Подведем итоги. Исходя из вышеизложенного понятно, что для небольшого RAID-массива, применение самых дорогостоящих дисков Enterprise класса не принципиально и не дает никаких преимуществ в надежности. Тем не менее, применение серверных дисков весьма желательно, так как в этом варианте на порядок большая вероятность того, что ребилд завершится успешно. Не следует применять диски большего объема, чем это необходимо, за исключением случаев, когда нужно обеспечить более высокую производительность по IOPS (в некоторых дисках большего объема все же может быть выигрыш по скорости за счет большего количества головок и пластин). В случаях, когда необходим большой объем и много дисков и при этом достаточный уровень надежности — можно смотреть в сторону SAS NL, которые по сути являются модифицированным вариантом накопителей SATA RE за счет интерфейса SAS, однако имеют все те же 7200 RPM. Для повышения уровня надежности целесообразно применять RAID более высокого уровня. Когда же объем массива не принципиален и требуется максимальная надежность, нужно однозначно применять SAS 15000 RPM Enterprise.
Теперь, выбирая в аренду сервер в Нидерландах, у нас на площадке Switch, при помощи конфигуратора, расположенного в нижней части страницы http://www.ua-hosting.company/servers, либо, модифицируя одно из спец. предложений:



Приходит понимание того, какие диски и какой из серверов лучше использовать и для каких задач, когда лучше использовать диски в RAID, а когда по отдельности, распределяя файлы софтом в зависимости от популярности (скрипт балансера в зависимости от нагрузки). Почему 4 диска большего объема, в плане надежности, может быть лучше, чем 12 меньшего, но хуже в плане времени восстановления в случае ребилда. Ну и самое важное — почему наше предложение реально крутое для серверного сегмента и мы реально приблизили цену к desktop-площадкам, при этом сохранив на порядок более высокую надежность без преувеличений! Так что если Вам, либо Вашим знакомым нужен хороший сервер — welcome, распродажа некоторых конфигураций из списка ниже ограничена, очень скоро цены на эти конфигурации будут выше, мы хоть и щедры, но не безгранично :):




Да, если у кого-то есть реальный опыт применения тех или других накопителей для определенных задач — не стесняйтесь делиться им в комментариях. Интересно все, вплоть до статистики отказов. На эту тему, как и по поводу проблематики выбора SSD-накопителя, мы постараемся опубликовать материал позднее.
