
Docker Swarm, Kubernetes и Mesos являются наиболее популярными фреймворками для оркестровки контейнеров. В своем выступлении Арун Гупта сравнивает следующие аспекты работы Docker, Swarm, и Kubernetes:
В результате вы получите четкое представление о том, что может предложить каждый инструмент оркестровки, и изучите методы эффективного использования этих платформ.
Арун Гупта — главный технолог open-source продуктов Amazon Web Services, который уже более 10 лет развивает сообщества разработчиков Sun, Oracle, Red Hat и Couchbase. Имеет большой опыт работы в ведущих кросс-функциональных командах, занимающихся разработкой и реализацией стратегии маркетинговых кампаний и программ. Руководил группами инженеров Sun, является одним из основателей команды Java EE и создателем американского отделения Devoxx4Kids. Арун Гупта является автором более 2 тысяч постов в IT-блогах и выступил с докладами более чем в 40 странах.

Добрый день, я знаю, что это последнее выступление перед обедом, но надеюсь, у вас осталось еще немного энергии от завтрака, чтобы меня выслушать. Меня зовут Арун Гупта, я работаю на AWS, о котором мы сейчас поговорим, как и о Docker и Kubernetes, чтобы вы могли выбрать для себя наиболее подходящий из этих фреймворков.
Я капитан Docker, чем очень горжусь, нас во всем мире всего 70 человек, признанных компанией Docker в этом статусе. Мы начинали с самой ранней версии системы 0.3, я написал книгу о Docker, так что кое-что знаю об этой технологии. Кроме того, я уже 4 года подряд я являюсь рок-звездой JavaOne, так что разбираюсь в теме. Я всегда учусь у своей аудитории и обмениваюсь с ней полезными советами, так что благодарю вас за участие.
Начнем рассмотрение вопроса с самого высокого уровня. Это не Docker 1.01, так что не ждите, что я стану учить вас основам. Поднимите руки, кто на сегодня пользуется Docker в какой-либо форме?

Отлично, почти 90% присутствующих. Итак, на глобальном уровне рабочий процесс Docker состоит из 3-х основных компонентов: клиентской части, хоста Docker и реестра Docker. Предположим, вы хотите запустить контейнер для какого-то конкретного образа. Вы говорите клиенту: «Загрузи этот образ и запусти контейнеры!». Для общения с хостом клиент использует команды docker build, docker pull и docker run. Он дает команду хосту, тот говорит: «Ага, этого образа у меня нет!», затем по умолчанию обращается к реестру Docker-хаб на hubdocker.com, загружает нужный образ, сохраняет его у себя и запускает в контейнерах. В этом смысле клиент совершенно не имеет состояний вне рабочего местоположения, он просто отдает команду типа CLI по проводам, она как REST API поступает на хост, и хост, понимая требования API, загружает образ с хаба или автоматизированного реестра Docker -контейнеров Amazon ECR, а затем запускает контейнеры на основе этого образа. Это полностью статичное состояние, управляемое только на хосте. В данном случае у нас имеется один хост, но достаточно легко использовать мультихостовое решение.
Это именно то, для чего нужен фреймворк оркестровки – вы не хотите создавать распределенную систему приложений на единственном хосте, потому что это самое слабое место, которое при неполадке обрушит всю работу системы. Вы хотите распределить задачу на несколько хостов, чтобы избежать глобального сбоя. Например, вы хотите запустить приложение Java, которое задействует сервер приложений, сервер базы данных, кэширование, множество различных компонентов. Причем часто требуется одновременная работа нескольких экземпляров данного приложения, поскольку типичное Java-приложение – это мультиконтейнерное приложение, которое использует контейнеры на нескольких хостах. Поэтому вам необходим фреймворк оркестровки, не только для планирования контейнеризации, но и для создания возможности управлять своим кластером, жизненными циклами и прочими необходимыми операциями.
В этом выступлении я расскажу, чем отличаются два основных инструмента оркестровки приложений – Docker и Kubernetes, их возможности, плюсы и минусы использования. Я буду рассматривать эти вопросы с точки зрения разработчика, который начинает создание любого приложения с ключевой, основополагающей концепции. Эта концепция включает в себя такие компоненты, как кластер, одиночный контейнер, множество контейнеров, их взаимодействие друг с другом, обнаружение сервисов (или каталогизацию сервисов, которая позволяет им знать друг о друге), балансировку нагрузки, постоянные хранилища, предназначенные для stateful-контейнеров, а также знание того, как будет выполняться локальная разработка.

От перспективы Dev мы перейдем к перспективе Ops, к архитектурной стороне системы: как мультиплицировать мастер-нод, как должен работать алгоритм планировщика при работе на нескольких хостах, каковы правила и ограничения, с помощью которых я смогу запустить контейнер на определенном хосте, как я смогу выполнять мониторинг и скользящее обновление, как пользоваться облачной поддержкой. Сегодня мы обо всем этом поговорим.
Начнем с Docker Swarm – это одна из функций Docker Engine, начиная с версии 1.2, стандартный инструмент кластеризации. Он преобразует набор Docker-хостов в один последовательный кластер Swarm. Если вы зайдете на сайт docker.com, то сможете скачать одно из двух изданий: Community Edition или Enterprise Edition (на сегодня эти версии носят название Stable и Edge). Первая сборка это то, я использую, она стабильна и обновляется раз в 3 месяца, в отличие от самой свежей сборки Edge, которая обновляется каждый месяц. Я пользуюсь версией Docker CE для Mac. Итак, когда я загружаю Docker CE на свой компьютер, то при установке отмечаю содержащийся в нем Swarm, и после этого могу сразу приступить к созданию кластеров, оркестровке и планированию контейнеров.
Обратите внимание, что для работы модуля Docker Swarm необходима связь с хостом, поэтому при использовании сетевой карты с мультихостовой системой нужно обеспечить прослушивание конкретного адреса Docker-хоста с помощью команды docker swarm unit — - listen-addr :2377.
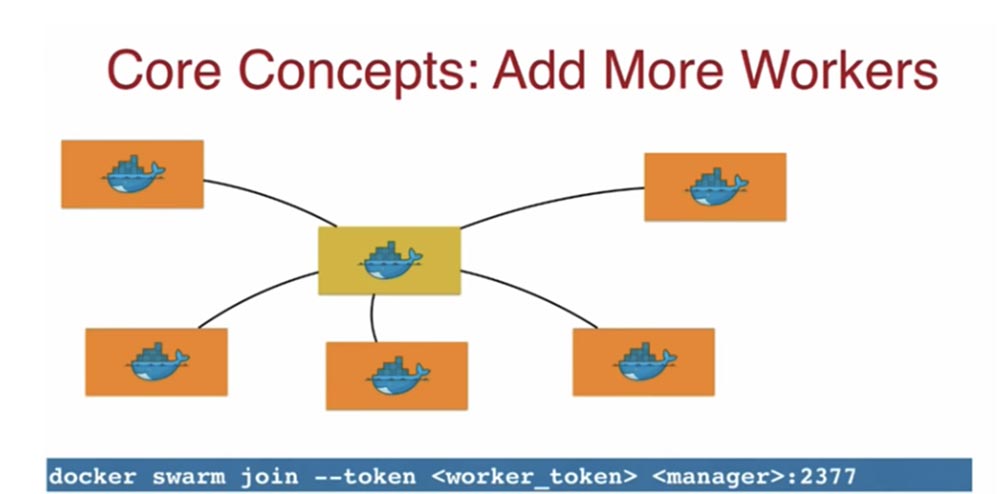
Желтая индикация значка обозначает по умолчанию единственный мастер-нод. Мастер выдает мне токен управления worker-token, я беру его и использую для присоединения нового рабочего узла, физической или виртуальной машины, это не имеет значения.

Это токен указывает, что данный нод должен присоединится к оригинальному мастеру. Используя worker-token, я могу сформировать собственный кластер Docker. Таким образом, используя Docker, очень легко создать кластер из нескольких нодов. На следующем слайде показан кластер из одного мастер-нода и 5 рабочих нод.

С такой же легкостью можно создавать кластеры с несколькими мастер-нодами – первичным мастер-нодом и вторичным мастер-нодом, связав их с рабочими узлами.

С клиентской стороны, когда вы присылаете запрос вторичному мастеру, он как прокси переадресует его первичному мастеру, и тот уже выполняет запрос, распределяя нагрузку между рабочими узлами. По умолчанию ваш контейнер также может работать в manager-ноде, но при создании кластера контейнеры должны размещаться только в рабочих узлах, а менеджер будет лишь администрировать кластер.
Следующее основное понятие, кластер, означает архитектуру из нескольких мастер-нодов и нескольких рабочих нодов, в которых запущены контейнеры. Это строго согласованная схема, реплицируемая на основе алгоритма консенсуса Raft, обладающая высочайшей скоростью за счет чтения из оперативной памяти.
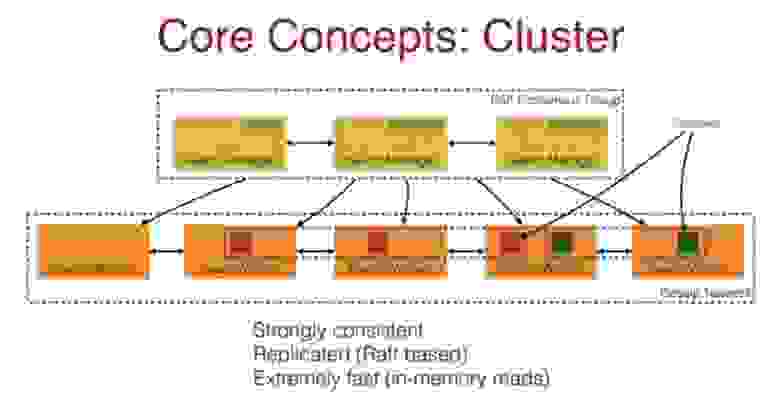
Я настоятельно рекомендую использовать шаблон с протоколом Raft, потому что если вы разделите сети, системе не придется задумываться, кто теперь играет роль мастера, так как с помощью Raft выбор будет осуществлен автоматически. На нижнем уровне расположены рабочие ноды Swarm, которые общаются друг с другом по протоколу Gossip. Вы видите, что красные контейнеры работают на 3 узлах, а зеленые на двух – это говорит о том, что Swarm Worker позволяет запускать и выполнять несколько разных задач.
Как работает Docker-концепт реплицированных сервисов Replicated Service? Поскольку я Java-разработчик, то в данном случае использую WildFly контейнер.
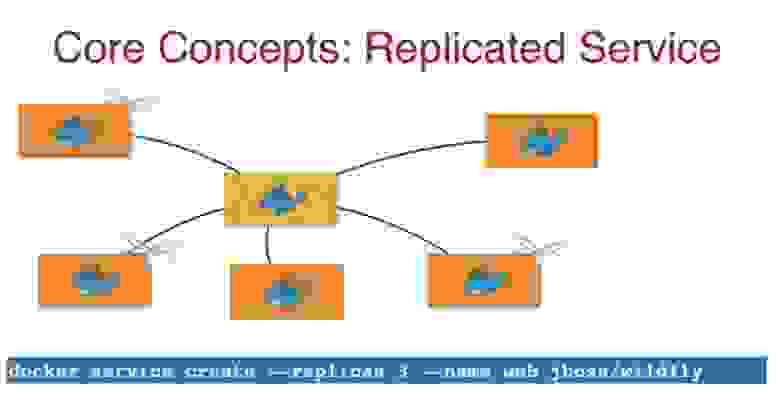
Для этого я через командную строку Docker ввожу команду docker service create — - replicas 3 — - name web jboss/wildfly, указывая необходимое мне число реплик, название сервиса – web, и добавляю образ wildfly. Этот образ будет загружен на 3 хоста Docker и запустит контейнер.
Еще один важный концепт – это сбой узла Node Failure. Что при этом происходит?

Docker видит, что текущее состояние системы не совпадает с желаемым, один узел выпал из кластера, значит, необходимо перенести контейнеры из этого нода на другой хост. То есть если вы объявили необходимость работы трех реплик, Docker позаботится о том, что эти 3 реплики существовали при любых условиях. Может произойти ситуация, когда в работоспособном ноде происходит сбой контейнера. Аналогично предыдущему случаю, Docker отслеживает заданное число контейнеров, и если оно уменьшилось, задействуется планировщик, который немедленно восстанавливает контейнер, приводя текущее состояние кластера к желаемому состоянию. То есть если вы объявили 3 реплики, все эти реплики должны работать в любой момент времени.
Конференция DEVOXX UK. Выбираем фреймворк: Docker Swarm, Kubernetes или Mesos. Часть 2
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
- Локальный девелопмент.
- Функции развертывания.
- Мультиконтейнерные приложения.
- Обнаружение служб service discovery.
- Масштабирование сервиса.
- Run-once задания.
- Интеграция с Maven.
- «Скользящее» обновление.
- Создание кластера БД Couchbase.
В результате вы получите четкое представление о том, что может предложить каждый инструмент оркестровки, и изучите методы эффективного использования этих платформ.
Арун Гупта — главный технолог open-source продуктов Amazon Web Services, который уже более 10 лет развивает сообщества разработчиков Sun, Oracle, Red Hat и Couchbase. Имеет большой опыт работы в ведущих кросс-функциональных командах, занимающихся разработкой и реализацией стратегии маркетинговых кампаний и программ. Руководил группами инженеров Sun, является одним из основателей команды Java EE и создателем американского отделения Devoxx4Kids. Арун Гупта является автором более 2 тысяч постов в IT-блогах и выступил с докладами более чем в 40 странах.

Добрый день, я знаю, что это последнее выступление перед обедом, но надеюсь, у вас осталось еще немного энергии от завтрака, чтобы меня выслушать. Меня зовут Арун Гупта, я работаю на AWS, о котором мы сейчас поговорим, как и о Docker и Kubernetes, чтобы вы могли выбрать для себя наиболее подходящий из этих фреймворков.
Я капитан Docker, чем очень горжусь, нас во всем мире всего 70 человек, признанных компанией Docker в этом статусе. Мы начинали с самой ранней версии системы 0.3, я написал книгу о Docker, так что кое-что знаю об этой технологии. Кроме того, я уже 4 года подряд я являюсь рок-звездой JavaOne, так что разбираюсь в теме. Я всегда учусь у своей аудитории и обмениваюсь с ней полезными советами, так что благодарю вас за участие.
Начнем рассмотрение вопроса с самого высокого уровня. Это не Docker 1.01, так что не ждите, что я стану учить вас основам. Поднимите руки, кто на сегодня пользуется Docker в какой-либо форме?
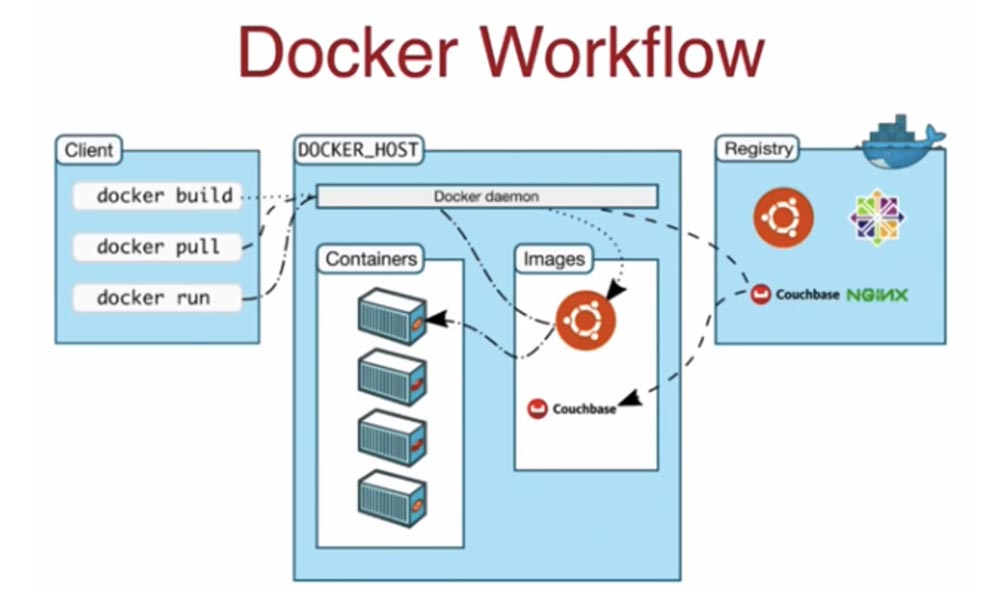
Отлично, почти 90% присутствующих. Итак, на глобальном уровне рабочий процесс Docker состоит из 3-х основных компонентов: клиентской части, хоста Docker и реестра Docker. Предположим, вы хотите запустить контейнер для какого-то конкретного образа. Вы говорите клиенту: «Загрузи этот образ и запусти контейнеры!». Для общения с хостом клиент использует команды docker build, docker pull и docker run. Он дает команду хосту, тот говорит: «Ага, этого образа у меня нет!», затем по умолчанию обращается к реестру Docker-хаб на hubdocker.com, загружает нужный образ, сохраняет его у себя и запускает в контейнерах. В этом смысле клиент совершенно не имеет состояний вне рабочего местоположения, он просто отдает команду типа CLI по проводам, она как REST API поступает на хост, и хост, понимая требования API, загружает образ с хаба или автоматизированного реестра Docker -контейнеров Amazon ECR, а затем запускает контейнеры на основе этого образа. Это полностью статичное состояние, управляемое только на хосте. В данном случае у нас имеется один хост, но достаточно легко использовать мультихостовое решение.
Это именно то, для чего нужен фреймворк оркестровки – вы не хотите создавать распределенную систему приложений на единственном хосте, потому что это самое слабое место, которое при неполадке обрушит всю работу системы. Вы хотите распределить задачу на несколько хостов, чтобы избежать глобального сбоя. Например, вы хотите запустить приложение Java, которое задействует сервер приложений, сервер базы данных, кэширование, множество различных компонентов. Причем часто требуется одновременная работа нескольких экземпляров данного приложения, поскольку типичное Java-приложение – это мультиконтейнерное приложение, которое использует контейнеры на нескольких хостах. Поэтому вам необходим фреймворк оркестровки, не только для планирования контейнеризации, но и для создания возможности управлять своим кластером, жизненными циклами и прочими необходимыми операциями.
В этом выступлении я расскажу, чем отличаются два основных инструмента оркестровки приложений – Docker и Kubernetes, их возможности, плюсы и минусы использования. Я буду рассматривать эти вопросы с точки зрения разработчика, который начинает создание любого приложения с ключевой, основополагающей концепции. Эта концепция включает в себя такие компоненты, как кластер, одиночный контейнер, множество контейнеров, их взаимодействие друг с другом, обнаружение сервисов (или каталогизацию сервисов, которая позволяет им знать друг о друге), балансировку нагрузки, постоянные хранилища, предназначенные для stateful-контейнеров, а также знание того, как будет выполняться локальная разработка.

От перспективы Dev мы перейдем к перспективе Ops, к архитектурной стороне системы: как мультиплицировать мастер-нод, как должен работать алгоритм планировщика при работе на нескольких хостах, каковы правила и ограничения, с помощью которых я смогу запустить контейнер на определенном хосте, как я смогу выполнять мониторинг и скользящее обновление, как пользоваться облачной поддержкой. Сегодня мы обо всем этом поговорим.
Начнем с Docker Swarm – это одна из функций Docker Engine, начиная с версии 1.2, стандартный инструмент кластеризации. Он преобразует набор Docker-хостов в один последовательный кластер Swarm. Если вы зайдете на сайт docker.com, то сможете скачать одно из двух изданий: Community Edition или Enterprise Edition (на сегодня эти версии носят название Stable и Edge). Первая сборка это то, я использую, она стабильна и обновляется раз в 3 месяца, в отличие от самой свежей сборки Edge, которая обновляется каждый месяц. Я пользуюсь версией Docker CE для Mac. Итак, когда я загружаю Docker CE на свой компьютер, то при установке отмечаю содержащийся в нем Swarm, и после этого могу сразу приступить к созданию кластеров, оркестровке и планированию контейнеров.
Обратите внимание, что для работы модуля Docker Swarm необходима связь с хостом, поэтому при использовании сетевой карты с мультихостовой системой нужно обеспечить прослушивание конкретного адреса Docker-хоста с помощью команды docker swarm unit — - listen-addr :2377.
Желтая индикация значка обозначает по умолчанию единственный мастер-нод. Мастер выдает мне токен управления worker-token, я беру его и использую для присоединения нового рабочего узла, физической или виртуальной машины, это не имеет значения.
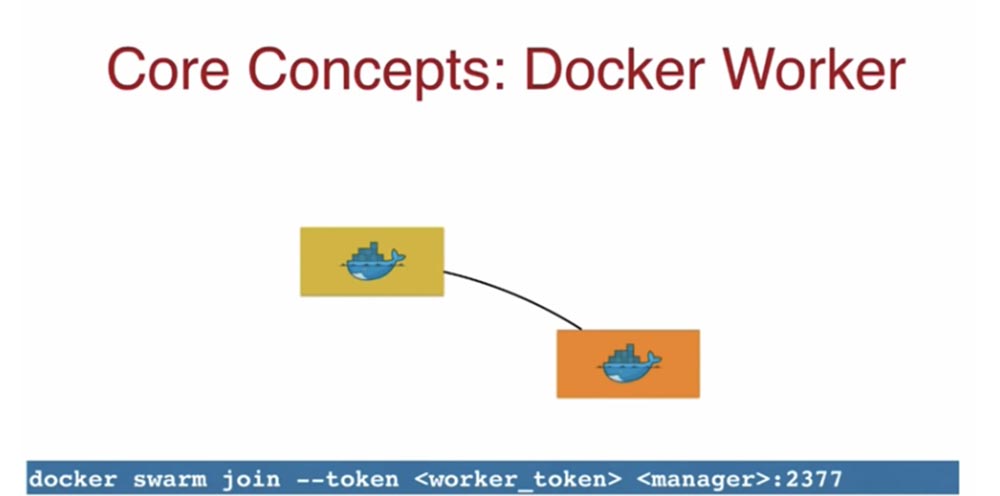
Это токен указывает, что данный нод должен присоединится к оригинальному мастеру. Используя worker-token, я могу сформировать собственный кластер Docker. Таким образом, используя Docker, очень легко создать кластер из нескольких нодов. На следующем слайде показан кластер из одного мастер-нода и 5 рабочих нод.
С такой же легкостью можно создавать кластеры с несколькими мастер-нодами – первичным мастер-нодом и вторичным мастер-нодом, связав их с рабочими узлами.

С клиентской стороны, когда вы присылаете запрос вторичному мастеру, он как прокси переадресует его первичному мастеру, и тот уже выполняет запрос, распределяя нагрузку между рабочими узлами. По умолчанию ваш контейнер также может работать в manager-ноде, но при создании кластера контейнеры должны размещаться только в рабочих узлах, а менеджер будет лишь администрировать кластер.
Следующее основное понятие, кластер, означает архитектуру из нескольких мастер-нодов и нескольких рабочих нодов, в которых запущены контейнеры. Это строго согласованная схема, реплицируемая на основе алгоритма консенсуса Raft, обладающая высочайшей скоростью за счет чтения из оперативной памяти.

Я настоятельно рекомендую использовать шаблон с протоколом Raft, потому что если вы разделите сети, системе не придется задумываться, кто теперь играет роль мастера, так как с помощью Raft выбор будет осуществлен автоматически. На нижнем уровне расположены рабочие ноды Swarm, которые общаются друг с другом по протоколу Gossip. Вы видите, что красные контейнеры работают на 3 узлах, а зеленые на двух – это говорит о том, что Swarm Worker позволяет запускать и выполнять несколько разных задач.
Как работает Docker-концепт реплицированных сервисов Replicated Service? Поскольку я Java-разработчик, то в данном случае использую WildFly контейнер.

Для этого я через командную строку Docker ввожу команду docker service create — - replicas 3 — - name web jboss/wildfly, указывая необходимое мне число реплик, название сервиса – web, и добавляю образ wildfly. Этот образ будет загружен на 3 хоста Docker и запустит контейнер.
Еще один важный концепт – это сбой узла Node Failure. Что при этом происходит?
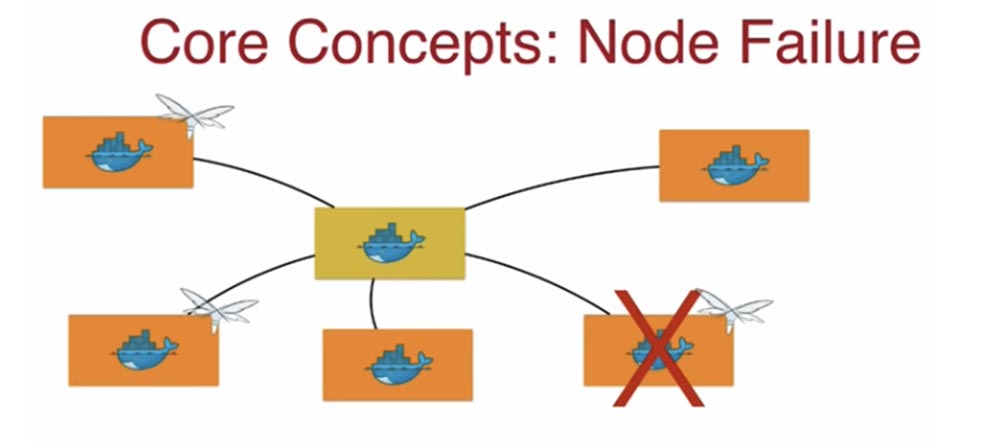
Docker видит, что текущее состояние системы не совпадает с желаемым, один узел выпал из кластера, значит, необходимо перенести контейнеры из этого нода на другой хост. То есть если вы объявили необходимость работы трех реплик, Docker позаботится о том, что эти 3 реплики существовали при любых условиях. Может произойти ситуация, когда в работоспособном ноде происходит сбой контейнера. Аналогично предыдущему случаю, Docker отслеживает заданное число контейнеров, и если оно уменьшилось, задействуется планировщик, который немедленно восстанавливает контейнер, приводя текущее состояние кластера к желаемому состоянию. То есть если вы объявили 3 реплики, все эти реплики должны работать в любой момент времени.
Конференция DEVOXX UK. Выбираем фреймворк: Docker Swarm, Kubernetes или Mesos. Часть 2
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
