
Джош Эванс рассказывает о хаотичном и ярком мире микросервисов Netflix, начиная с самых основ — анатомии микросервисов, проблем, связанных с распределенными системами и их преимуществ. Опираясь на этот фундамент, он исследует культурные, архитектурные и операционные методы, которые ведут к овладению микросервисами.
Около 15 лет назад моя мачеха, назовем ее Фрэнсис, стала чувствовать боль и слабость во всем теле, ей стало трудно стоять, и когда врачи в больнице немного привели ее в себя, у нее обнаружился паралич рук и ног. Это было ужасное испытание для нее и для нас, как оказалось, диагнозом стал синдром Гийона-Барре. Мне просто любопытно, кто-нибудь из вас слышал о такой болезни? О, довольно много людей! Надеюсь, вы получили эту информацию не из первых рук. Это аутоиммунное заболевание, острый полирадикулоневрит, при котором иммунная система человека поражает собственные периферические нервы.
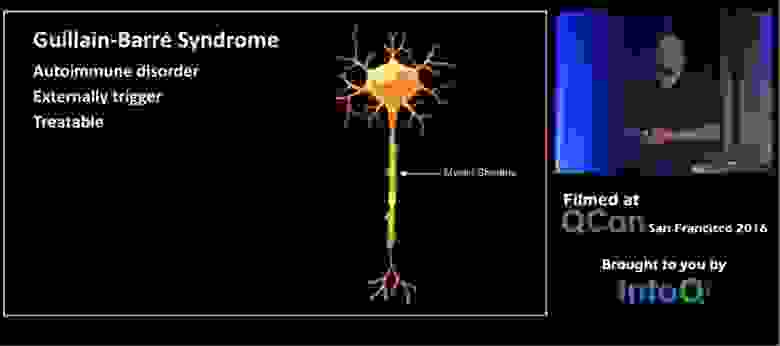
Обычно эту болезнь провоцирует какой-то внешний фактор, но интересно в ней то, что антитела атакуют непосредственно миелиновую оболочку аксона так, что повреждают ее по всей длине нерва, и его сигналы становятся очень рассеянными. Поэтому можно логично объяснить все симптомы боли, слабости и паралич, понимая, что происходит с нервной системой. Хорошие новости состоят в том, что это заболевание можно вылечить либо через плазмаферез, когда кровь фильтруется вне вашего тела, либо с помощью антительной терапии.
Лечение Френсис прошло успешно, но болезнь заставила ее более дисциплинированно относиться к своему здоровью. Она начала правильно питаться, заниматься спортивными упражнениями, освоила цигун и тайцзи и делала все, чтобы исключить риск повторения подобных болезней.
Этот случай подчеркивает, насколько удивительно человеческое тело. Простой акт дыхания или взаимодействие с окружающим миром представляют собой чудесные вещи и являются настоящим подвигом, ведь в окружающем нас мире существует множество вредоносных сил, аллергенов и бактериальных инфекций, способных вызвать огромные проблемы.
Вы можете спросить: «Какое отношение этот рассказ имеет к теме микросервисов»? Так вот, трафик в архитектуре микросервисов являет собой такой же подвиг, как и человеческое дыхание. У вас могут возникать всплески трафика, иметь место враждебная DDoS атака, хакер может внести изменения в вашу рабочую среду, отрезав клиентам доступ. Вот почему сегодня мы собираемся поговорить об архитектуре микросервисов, об их огромных преимуществах, проблема и решениях, которые Netflix обнаружил в течение последних 7 лет борьбы с большим количеством сбоев разного рода.
Я начну со вступления, в котором вам представлюсь, затем займу немного времени объяснением базовых основ микросервисов. Большую часть доклада я посвящу проблемам и их решениям, которые предлагает Netflix. В завершении я расскажу о зависимостях организации процессов и соответствующей им архитектуры.
Я Джош Эванс, который начал работу в Netflix в 1999 году, перед этим сделав карьеру в схожей области. Я пришел в проект за месяц до запуска DVD-сервиса, работал инженером, менеджером и был участником интеграции коммерческого продукта и стриминга в существующий DVD-бизнес. В 2009 я попал прямо в «сердце» потокового мультимедиа, возглавив команду Playback Service – службу, которая занимается доставкой DRM, манифестов и записью телеметрии, возвращающейся из устройств пользователей. Я также управлял этой командой во время международного внедрения Netflix, когда наш сервис заработал практически на всех устройствах, воспроизводящих потоковое видео, и участвовал в переносе проекта с дата-центров в облачный сервис. Можно сказать, что последние 3 года были самыми захватывающими. Я возглавлял команду инженеров Operations Engineering, которая фокусируется на высокопрофессиональных операциях контроля скорости, мониторинге и предупреждении сбоев, доставке потокового мультимедиа и широком спектре функций, поиогающих инженерам Netflix успешно эксплуатировать свои собственные облачные сервисы.
Примерно месяц назад я ушел из Netflix и сегодня наверстываю упущенное с книгой Арианны Хаффингтон «The Sleep Revolution: Transforming Your Life, One Night at a Time». Впервые за довольно долгое время я взял отпуск и провожу его с семьей, пытаясь выяснить, как создать баланс между работой и личной жизнью.
Как известно, Netflix является лидером в области абонентского интернет-телевидения, предоставляющим пользователям голливудскую кинопродукцию, инди, локальные передачи, растущий пласт оригинального контента. У нас 86 млн. пользователей в 190 странах, стриминг на 10 языках и поддержка более 1000 типов устройств. Все это работает на основе микросервисов AWS.

Давайте поговорим о микросервисах с абстрактной точки зрения. Начнем с того, какими они не должны быть. Дата-центр Netflix DVD образца 2000 года имел достаточно простую инфраструктуру: аппаратный балансировщик нагрузки, кстати, достаточно дорогой, хост Linux стандартной конфигурации с Apache Reverse Proxy и Tomcat, и всего одно приложение, названное нами Javaweb.
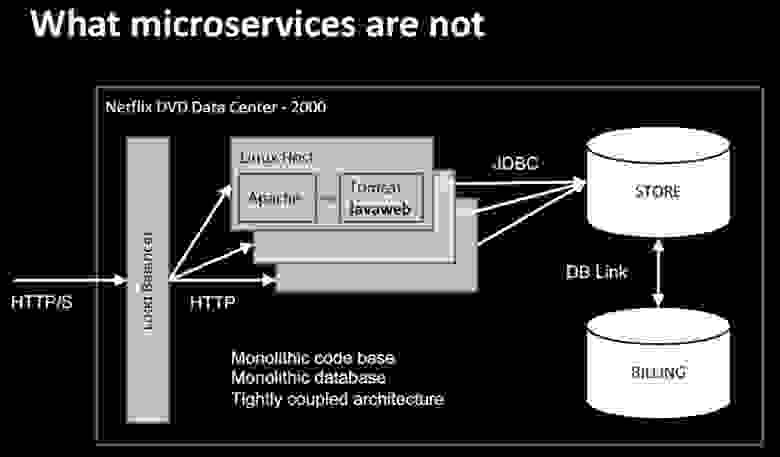
Хост напрямую соединялся через JDBC с базой данных Oracle, которая, в свою очередь, соединялась с другой, биллинговой базой данных Oracle через DB link. Первой проблемой данной архитектуры была монолитность кодовой базы Javaweb, то есть все вкладывалось в одну единственную программную базу, обновляемую еженедельно или раз в 2 недели. Любое внеочередное изменение становилось проблемой, которую было достаточно трудно диагностировать. Например, мы потратили почти неделю, разбираясь с «медленной» памятью. Мы вытягивали куски кода, запускали его, смотрели, что при этом происходит и так далее, поэтому внесение любых изменений занимало много времени. База данных представляла собой еще более строгий монолит – это был один сегмент оборудования, работающй с одной большой базой данных Oracle, которую мы называли «Базой данных магазина». Если она выходила из строя, то из строя выходило абсолютно все. Каждый год с началом периода отпусков мы наращивали аппаратные мощности, чтобы вертикально масштабировать наше приложение.
Наиболее болезненным был недостаток оперативности – мы не могли вносить изменения достаточно быстро, поскольку все компоненты архитектуры были жестко связаны друг с другом. У нас были прямые обращения к базе данных, множество приложений, обращавшихся к табличным схемам, поэтому даже добавление столбца в таблицу становилось большой проблемой для кросс-функционального проекта. Это хороший пример того, как сегодня не нужно создавать сервисы, хотя подобная картина была типичной для конца 90-х – начала 2000 годов.
Так что же такое микросервис? Кто-нибудь хочет дать ему определение? Мне нравится, что вы сказали: «привязка к контексту и владение данными». Я приведу вам определение Мартина Фаулера: «Архитектурный стиль микросервисов представляет собой подход к разработке одного приложения как совокупности мелких сервисов, каждый из которых имеет собственный рабочий процесс и осуществляет коммуникацию с помощью легких механизмов, преимущественно в виде API на основе HTTP-ресурсов».
Думаю, мы все это знаем. Это несколько абстрактное, технически правильное определение, но оно не дает возможности почувствовать «дух» микросервисов. Я считаю, что микросервисы – это эволюционная реакция на опыт применения монолитных структур. Разделение компонентов — одна из самых важных вещей, обеспечиваемая модульностью и способностью к инкапсуляции структур данных, причем вам не придется иметь дело с организацией координации их взаимодействия.
Микросервисы – это масштабируемость, преимущественно горизонтальная, и разбиение рабочих нагрузок на разделы, позволяющее создание распределенной системы для компонентов меньших размеров с целью облегчить управление. По моему мнению, никакой микросервис не будет работать достаточно хорошо, если его не запускать в виртуальной эластичной среде. Кроме того, вы должны обеспечить максимально возможную автоматизацию и предоставление услуг по первому требованию, что является огромным преимуществом для ваших клиентов.
Возвращаясь к аналогии с человеческим телом и биологией, вы можете воспринимать микросервисы как систему из жизненно важных органов, формирующих цельный организм.
Давайте рассмотрим архитектуру Netflix и то, как она мапируется.
Слева вы видите клиентский сервис – конечный уровень ELB-прокси под названием Zuul, который осуществляет динамическую маршрутизацию. Здесь же расположен NCCP (Netflix Content Control Plane), который поддерживает предыдущие поколения наших устройств и обеспечивает воспроизводящую способность контента. API-шлюз, являющийся ядром нашей современной архитектуры, обращается ко всем другим сервисам для выполнения запросов клиентов.
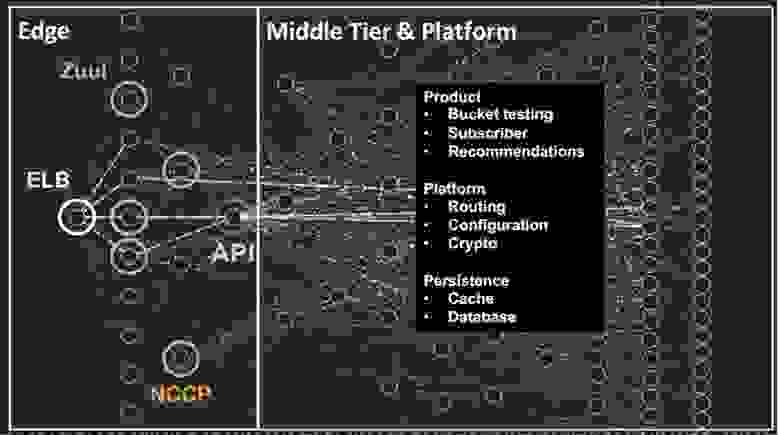
Справа расположена подсистема среднего уровня Middle Tier и платформа сервиса. Это среда, состоящая из множества компонентов, таких как A/B тестирование, сообщающее результаты пользовательских проверок. Абонентский сервис Subscriber предоставляет развернутую информацию о клиентах, система рекомендаций Recommendations обеспечивает информацию, необходимую для создания списка фильмов, которые будут представлены каждому клиенту.
К платформенным сервисам относятся маршрутизация микросервисов, позволяющая службам находить друг друга, динамическая конфигурация, операции шифрования. Здесь также имеется уровень хранения Persistence, где расположены кеш и база данных.
Эти виды объектов формируют экосистему Netflix. Хочу подчеркнуть, что так как микросервисы являются абстракцией, мы склонны думать о них очень упрощенно. На этом слайде показан мой любимый горизонтально масштабируемый микросервис. Прекрасно, что микросервисы кажутся простыми, однако в реальности почти никогда таковыми не являются. В какой-то момент вам потребуются данные, которые нужно вытянуть из базы данных. Это может быть абонентская информация Subscriber или рекомендации Recommendations. Обычно эти данные находятся на уровне хранения Persistence. На схеме показан обычный подход к получению пользовательских данных, который использует не только сервис Netflix.
Service Client начинает предоставлять клиентские библиотеки на основе Java, которые обеспечивают доступ к базовым данным. Наступает момент, когда вам потребуется масштабировать сервис, привлекая к этому EVCashe Client, потому что сервис с разросшейся базой данных недостаточно хорошо справляется с клиентской нагрузкой. EVCache — это распределенное решение для кэширования в памяти, основанное на memcached & spymemcached, интегрированное с инфраструктурой Netflix OSS и AWS EC2. После подключения клиента EVCashe вы должны будете заняться оркестровкой, чтобы, если это хранилище выйдет из строя, вы смогли бы обратиться к Service Client, который вызовет базу данных и вернет ответ обратно. При этом вы должны убедиться в том, что произошло наполнение EVCashe так, что при следующем обращении к нему спустя несколько миллисекунд все будет в порядке.
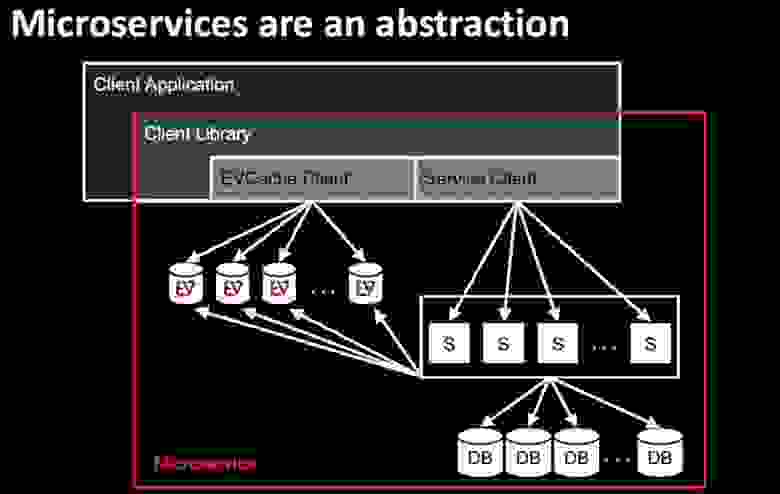
Эта клиентская библиотека встраивается в клиентское приложение, которое использует микросервис, представляющий собой цельный набор технологий и комплекс конфигураций. Это не простая stateless-структура, которой легко управлять, а сложная комплексная структура.
Итак, рассмотрев основы архитектуры микросервисов, перейдем к проблемам, с которыми мы сталкивались на протяжении последних 7 лет, и их решениям. Я люблю «нездоровую» пищу и мне нравится эта картинка, потому что я думаю, что во многих случаях проблемы и их решения должны быть связаны с нашими привычками, в нашем случае с тем, как мы подходим к микросервисам. Поэтому во многих случаях нашей целью является «организовать здоровое питание и потреблять как можно больше овощей».
Выделим четыре области, которые нужно исследовать: зависимости, масштабирование, различия, зависящие от вашей архитектуры, и то, как следует вносить изменения. Начнем с зависимостей и разобьем их на 4 случая использования.

Первый случай – это внутренние запросы на обслуживание Intra-service requests, например, запросы микросервиса А микросервису В. По аналогии с нервными клетками и нервной проводимостью все идет прекрасно, пока нам не приходится перепрыгивать через бездну — в случае, когда один сервис вызывает другой, существует огромный риск сбоя.
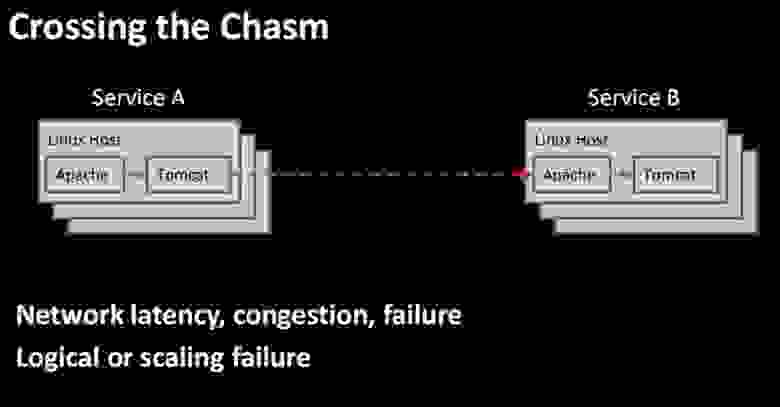
Этот риск вызван задержками сети, перегрузкой, отказами аппаратной части. Вызываемый сервис может иметь логические ошибки или неполадки масштабирования. Он может работать очень медленно и выдавать при вызове ошибку таймаута. Самый ужасный сценарий, который реализовывался чаще, чем хотелось, это когда сбой всего одного сервиса при развертывании приводил к отказу всей системы, из-за чего клиент утрачивал с ней всякую связь. И упаси вас боже развернуть эти ошибочные изменения на несколько регионов при использовании мультирегиональной стратегии, потому что вам просто некуда будет отступить, чтобы восстановить и отремонтировать систему.
Конференция QCon. Овладение хаосом: руководство Netflix для микросервисов. Часть 2
Продолжение будет совсем скоро…
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Около 15 лет назад моя мачеха, назовем ее Фрэнсис, стала чувствовать боль и слабость во всем теле, ей стало трудно стоять, и когда врачи в больнице немного привели ее в себя, у нее обнаружился паралич рук и ног. Это было ужасное испытание для нее и для нас, как оказалось, диагнозом стал синдром Гийона-Барре. Мне просто любопытно, кто-нибудь из вас слышал о такой болезни? О, довольно много людей! Надеюсь, вы получили эту информацию не из первых рук. Это аутоиммунное заболевание, острый полирадикулоневрит, при котором иммунная система человека поражает собственные периферические нервы.
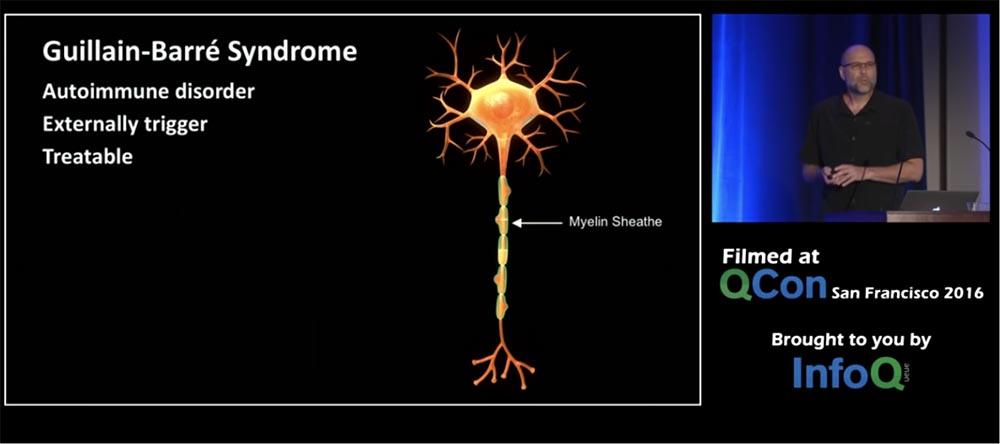
Обычно эту болезнь провоцирует какой-то внешний фактор, но интересно в ней то, что антитела атакуют непосредственно миелиновую оболочку аксона так, что повреждают ее по всей длине нерва, и его сигналы становятся очень рассеянными. Поэтому можно логично объяснить все симптомы боли, слабости и паралич, понимая, что происходит с нервной системой. Хорошие новости состоят в том, что это заболевание можно вылечить либо через плазмаферез, когда кровь фильтруется вне вашего тела, либо с помощью антительной терапии.
Лечение Френсис прошло успешно, но болезнь заставила ее более дисциплинированно относиться к своему здоровью. Она начала правильно питаться, заниматься спортивными упражнениями, освоила цигун и тайцзи и делала все, чтобы исключить риск повторения подобных болезней.
Этот случай подчеркивает, насколько удивительно человеческое тело. Простой акт дыхания или взаимодействие с окружающим миром представляют собой чудесные вещи и являются настоящим подвигом, ведь в окружающем нас мире существует множество вредоносных сил, аллергенов и бактериальных инфекций, способных вызвать огромные проблемы.
Вы можете спросить: «Какое отношение этот рассказ имеет к теме микросервисов»? Так вот, трафик в архитектуре микросервисов являет собой такой же подвиг, как и человеческое дыхание. У вас могут возникать всплески трафика, иметь место враждебная DDoS атака, хакер может внести изменения в вашу рабочую среду, отрезав клиентам доступ. Вот почему сегодня мы собираемся поговорить об архитектуре микросервисов, об их огромных преимуществах, проблема и решениях, которые Netflix обнаружил в течение последних 7 лет борьбы с большим количеством сбоев разного рода.
Я начну со вступления, в котором вам представлюсь, затем займу немного времени объяснением базовых основ микросервисов. Большую часть доклада я посвящу проблемам и их решениям, которые предлагает Netflix. В завершении я расскажу о зависимостях организации процессов и соответствующей им архитектуры.
Я Джош Эванс, который начал работу в Netflix в 1999 году, перед этим сделав карьеру в схожей области. Я пришел в проект за месяц до запуска DVD-сервиса, работал инженером, менеджером и был участником интеграции коммерческого продукта и стриминга в существующий DVD-бизнес. В 2009 я попал прямо в «сердце» потокового мультимедиа, возглавив команду Playback Service – службу, которая занимается доставкой DRM, манифестов и записью телеметрии, возвращающейся из устройств пользователей. Я также управлял этой командой во время международного внедрения Netflix, когда наш сервис заработал практически на всех устройствах, воспроизводящих потоковое видео, и участвовал в переносе проекта с дата-центров в облачный сервис. Можно сказать, что последние 3 года были самыми захватывающими. Я возглавлял команду инженеров Operations Engineering, которая фокусируется на высокопрофессиональных операциях контроля скорости, мониторинге и предупреждении сбоев, доставке потокового мультимедиа и широком спектре функций, поиогающих инженерам Netflix успешно эксплуатировать свои собственные облачные сервисы.
Примерно месяц назад я ушел из Netflix и сегодня наверстываю упущенное с книгой Арианны Хаффингтон «The Sleep Revolution: Transforming Your Life, One Night at a Time». Впервые за довольно долгое время я взял отпуск и провожу его с семьей, пытаясь выяснить, как создать баланс между работой и личной жизнью.
Как известно, Netflix является лидером в области абонентского интернет-телевидения, предоставляющим пользователям голливудскую кинопродукцию, инди, локальные передачи, растущий пласт оригинального контента. У нас 86 млн. пользователей в 190 странах, стриминг на 10 языках и поддержка более 1000 типов устройств. Все это работает на основе микросервисов AWS.

Давайте поговорим о микросервисах с абстрактной точки зрения. Начнем с того, какими они не должны быть. Дата-центр Netflix DVD образца 2000 года имел достаточно простую инфраструктуру: аппаратный балансировщик нагрузки, кстати, достаточно дорогой, хост Linux стандартной конфигурации с Apache Reverse Proxy и Tomcat, и всего одно приложение, названное нами Javaweb.
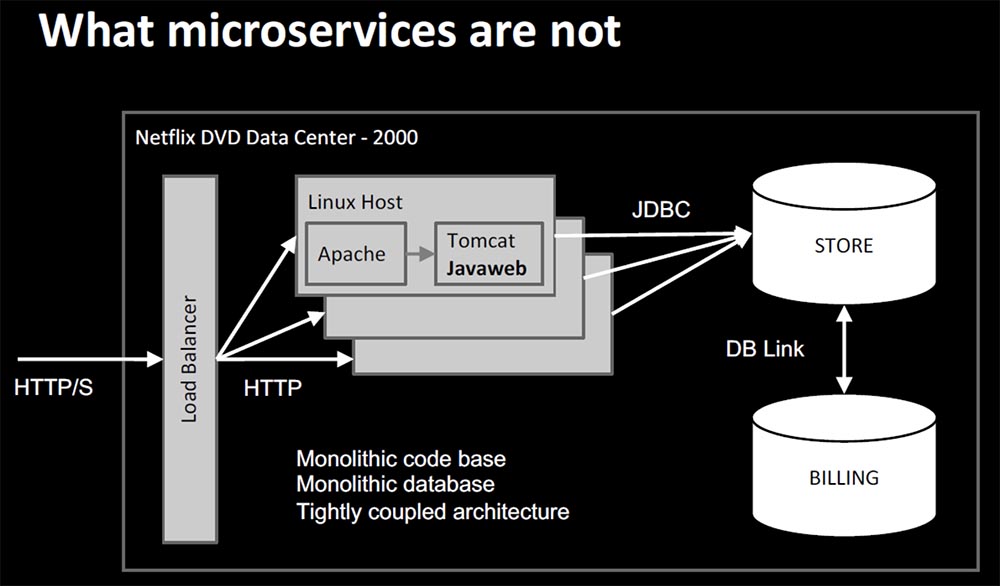
Хост напрямую соединялся через JDBC с базой данных Oracle, которая, в свою очередь, соединялась с другой, биллинговой базой данных Oracle через DB link. Первой проблемой данной архитектуры была монолитность кодовой базы Javaweb, то есть все вкладывалось в одну единственную программную базу, обновляемую еженедельно или раз в 2 недели. Любое внеочередное изменение становилось проблемой, которую было достаточно трудно диагностировать. Например, мы потратили почти неделю, разбираясь с «медленной» памятью. Мы вытягивали куски кода, запускали его, смотрели, что при этом происходит и так далее, поэтому внесение любых изменений занимало много времени. База данных представляла собой еще более строгий монолит – это был один сегмент оборудования, работающй с одной большой базой данных Oracle, которую мы называли «Базой данных магазина». Если она выходила из строя, то из строя выходило абсолютно все. Каждый год с началом периода отпусков мы наращивали аппаратные мощности, чтобы вертикально масштабировать наше приложение.
Наиболее болезненным был недостаток оперативности – мы не могли вносить изменения достаточно быстро, поскольку все компоненты архитектуры были жестко связаны друг с другом. У нас были прямые обращения к базе данных, множество приложений, обращавшихся к табличным схемам, поэтому даже добавление столбца в таблицу становилось большой проблемой для кросс-функционального проекта. Это хороший пример того, как сегодня не нужно создавать сервисы, хотя подобная картина была типичной для конца 90-х – начала 2000 годов.
Так что же такое микросервис? Кто-нибудь хочет дать ему определение? Мне нравится, что вы сказали: «привязка к контексту и владение данными». Я приведу вам определение Мартина Фаулера: «Архитектурный стиль микросервисов представляет собой подход к разработке одного приложения как совокупности мелких сервисов, каждый из которых имеет собственный рабочий процесс и осуществляет коммуникацию с помощью легких механизмов, преимущественно в виде API на основе HTTP-ресурсов».
Думаю, мы все это знаем. Это несколько абстрактное, технически правильное определение, но оно не дает возможности почувствовать «дух» микросервисов. Я считаю, что микросервисы – это эволюционная реакция на опыт применения монолитных структур. Разделение компонентов — одна из самых важных вещей, обеспечиваемая модульностью и способностью к инкапсуляции структур данных, причем вам не придется иметь дело с организацией координации их взаимодействия.
Микросервисы – это масштабируемость, преимущественно горизонтальная, и разбиение рабочих нагрузок на разделы, позволяющее создание распределенной системы для компонентов меньших размеров с целью облегчить управление. По моему мнению, никакой микросервис не будет работать достаточно хорошо, если его не запускать в виртуальной эластичной среде. Кроме того, вы должны обеспечить максимально возможную автоматизацию и предоставление услуг по первому требованию, что является огромным преимуществом для ваших клиентов.
Возвращаясь к аналогии с человеческим телом и биологией, вы можете воспринимать микросервисы как систему из жизненно важных органов, формирующих цельный организм.
Давайте рассмотрим архитектуру Netflix и то, как она мапируется.
Слева вы видите клиентский сервис – конечный уровень ELB-прокси под названием Zuul, который осуществляет динамическую маршрутизацию. Здесь же расположен NCCP (Netflix Content Control Plane), который поддерживает предыдущие поколения наших устройств и обеспечивает воспроизводящую способность контента. API-шлюз, являющийся ядром нашей современной архитектуры, обращается ко всем другим сервисам для выполнения запросов клиентов.
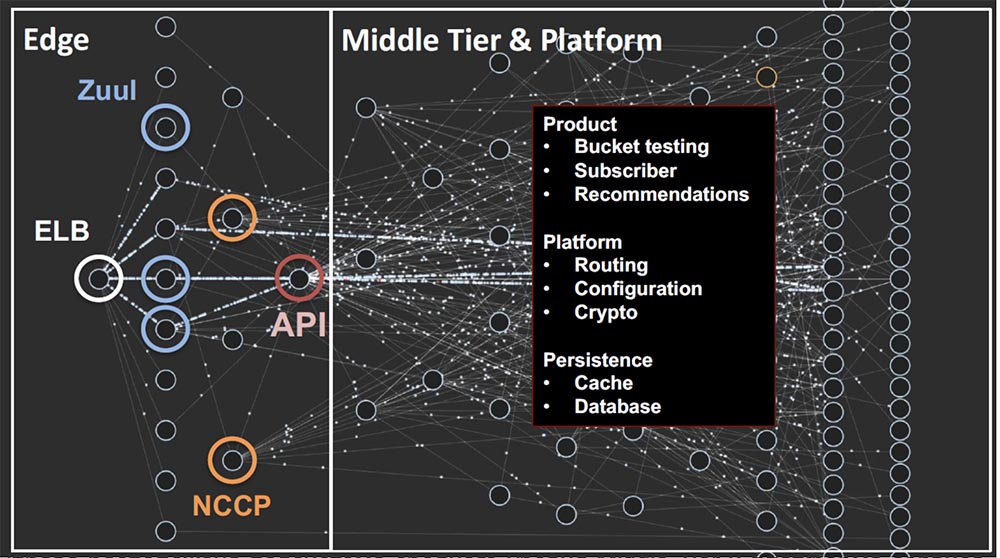
Справа расположена подсистема среднего уровня Middle Tier и платформа сервиса. Это среда, состоящая из множества компонентов, таких как A/B тестирование, сообщающее результаты пользовательских проверок. Абонентский сервис Subscriber предоставляет развернутую информацию о клиентах, система рекомендаций Recommendations обеспечивает информацию, необходимую для создания списка фильмов, которые будут представлены каждому клиенту.
К платформенным сервисам относятся маршрутизация микросервисов, позволяющая службам находить друг друга, динамическая конфигурация, операции шифрования. Здесь также имеется уровень хранения Persistence, где расположены кеш и база данных.
Эти виды объектов формируют экосистему Netflix. Хочу подчеркнуть, что так как микросервисы являются абстракцией, мы склонны думать о них очень упрощенно. На этом слайде показан мой любимый горизонтально масштабируемый микросервис. Прекрасно, что микросервисы кажутся простыми, однако в реальности почти никогда таковыми не являются. В какой-то момент вам потребуются данные, которые нужно вытянуть из базы данных. Это может быть абонентская информация Subscriber или рекомендации Recommendations. Обычно эти данные находятся на уровне хранения Persistence. На схеме показан обычный подход к получению пользовательских данных, который использует не только сервис Netflix.
Service Client начинает предоставлять клиентские библиотеки на основе Java, которые обеспечивают доступ к базовым данным. Наступает момент, когда вам потребуется масштабировать сервис, привлекая к этому EVCashe Client, потому что сервис с разросшейся базой данных недостаточно хорошо справляется с клиентской нагрузкой. EVCache — это распределенное решение для кэширования в памяти, основанное на memcached & spymemcached, интегрированное с инфраструктурой Netflix OSS и AWS EC2. После подключения клиента EVCashe вы должны будете заняться оркестровкой, чтобы, если это хранилище выйдет из строя, вы смогли бы обратиться к Service Client, который вызовет базу данных и вернет ответ обратно. При этом вы должны убедиться в том, что произошло наполнение EVCashe так, что при следующем обращении к нему спустя несколько миллисекунд все будет в порядке.
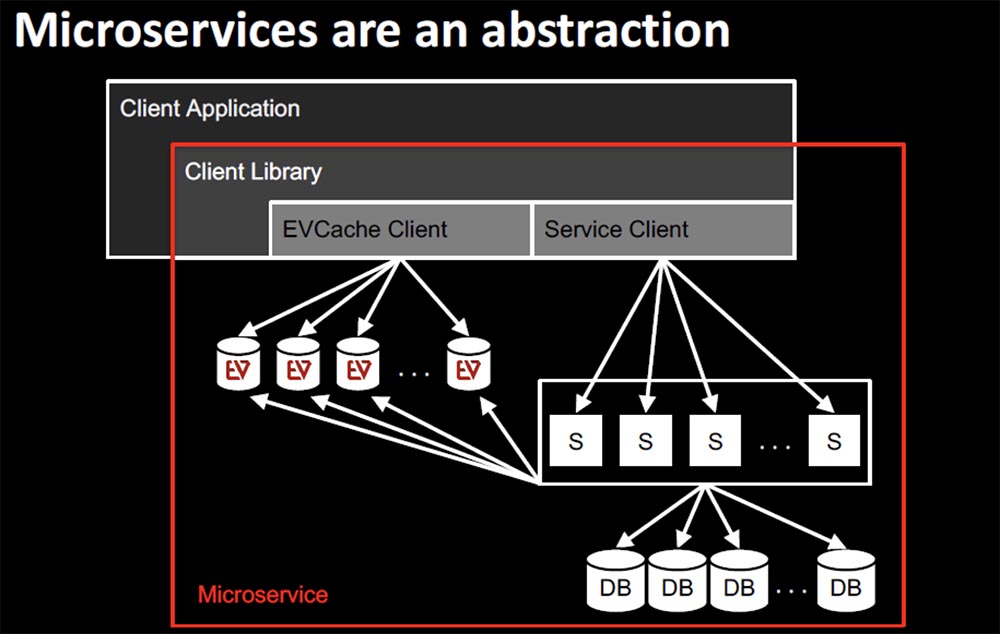
Эта клиентская библиотека встраивается в клиентское приложение, которое использует микросервис, представляющий собой цельный набор технологий и комплекс конфигураций. Это не простая stateless-структура, которой легко управлять, а сложная комплексная структура.
Итак, рассмотрев основы архитектуры микросервисов, перейдем к проблемам, с которыми мы сталкивались на протяжении последних 7 лет, и их решениям. Я люблю «нездоровую» пищу и мне нравится эта картинка, потому что я думаю, что во многих случаях проблемы и их решения должны быть связаны с нашими привычками, в нашем случае с тем, как мы подходим к микросервисам. Поэтому во многих случаях нашей целью является «организовать здоровое питание и потреблять как можно больше овощей».
Выделим четыре области, которые нужно исследовать: зависимости, масштабирование, различия, зависящие от вашей архитектуры, и то, как следует вносить изменения. Начнем с зависимостей и разобьем их на 4 случая использования.

Первый случай – это внутренние запросы на обслуживание Intra-service requests, например, запросы микросервиса А микросервису В. По аналогии с нервными клетками и нервной проводимостью все идет прекрасно, пока нам не приходится перепрыгивать через бездну — в случае, когда один сервис вызывает другой, существует огромный риск сбоя.
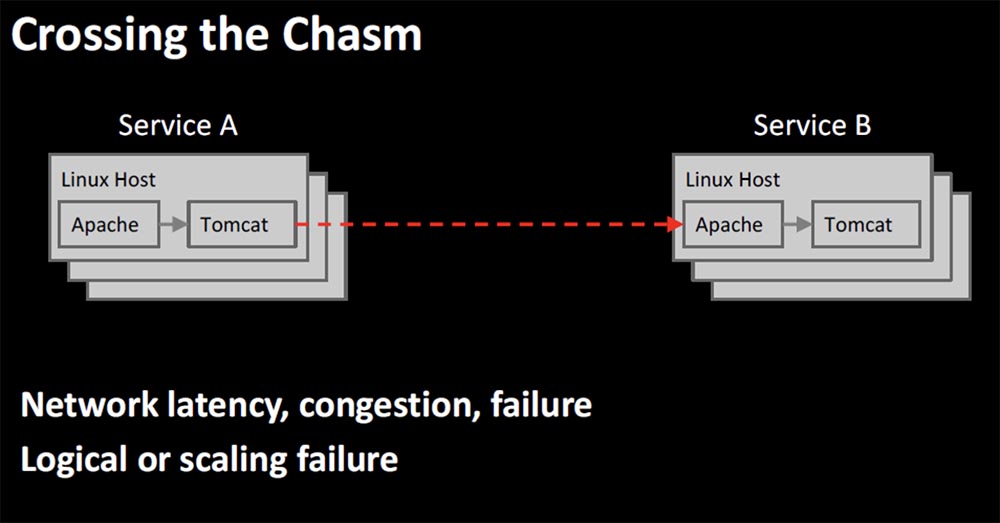
Этот риск вызван задержками сети, перегрузкой, отказами аппаратной части. Вызываемый сервис может иметь логические ошибки или неполадки масштабирования. Он может работать очень медленно и выдавать при вызове ошибку таймаута. Самый ужасный сценарий, который реализовывался чаще, чем хотелось, это когда сбой всего одного сервиса при развертывании приводил к отказу всей системы, из-за чего клиент утрачивал с ней всякую связь. И упаси вас боже развернуть эти ошибочные изменения на несколько регионов при использовании мультирегиональной стратегии, потому что вам просто некуда будет отступить, чтобы восстановить и отремонтировать систему.
Конференция QCon. Овладение хаосом: руководство Netflix для микросервисов. Часть 2
Продолжение будет совсем скоро…
Немного рекламы
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
