Комментарии 11
KVM бекапит?
В КВ-1931 не увидел детального описания механизма устаревания, а очень хотелось сравнить с IBM, который тоже умеет incremental forever.
Впрочем, там хватает нюансов и легко сделать систему с очень плохим RTO.
Впрочем, там хватает нюансов и легко сделать систему с очень плохим RTO.
Попробуйте посмотреть HelpCenter «Retention Policy» — там более детально описаны эти механизмы для разных схем работы.
Ткните носом, где там написано когда запускается процесс очистки? Если понимать справку буквально, то он срабатывает при запуске задания резервного копирования, что противоречит написанному в статье:
будет происходить уже вне окна резервного копирования без нагрузки на производственную среду
Ткнуть носом не могу, но могу пояснить, что каждый раз по окончании задания резервного копирования (и не важно успешно ли оно завершилось) программа инициализирует проверку на соответствие политике хранения и после анализа решает, что делать. Таким образом, процесс работает без нагрузки на производственную среду, но все еще относится к самому заданию.
Приложу скриншот задания, на котором все видно.
Приложу скриншот задания, на котором все видно.
Скрин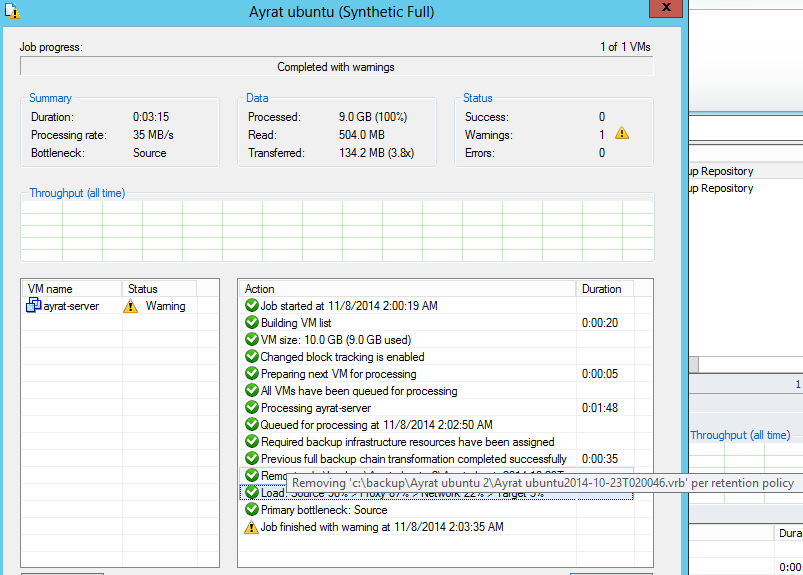

Под термином "окно резервного копирования" в статье имелось в виду допустимый диапазон времени, когда бэкап-продукт может нагружать работой производственную СХД.
Если посмотреть на алгоритм, который по шагам описан здесь: «Retention Policy for Forward Incremental-Forever Backup», то:
Если посмотреть на алгоритм, который по шагам описан здесь: «Retention Policy for Forward Incremental-Forever Backup», то:
- п.3 (создание инкремента) — выполняется именно на производственной СХД (в частности создается снапшот, копируются данные инкремента, работа со снапшотом завершается) и на этот этап распространяется требование уложиться в «окно резервного копирования»
- п.4 (transform) — действительно, вы правильно заметили — этот пункт не имеет отдельного расписания, он запускается каждый раз после предыдущего этапа, однако он выполняется исключительно на бэкап-СХД и только если есть устаревшая точка восстановления. Так как этот пункт не затрагивает производственную СХД, то на него НЕ распространяется требование уложиться в «окно резервного копирования» — он может спокойно выйти за его пределы — вот что имелось в виду в статье.
Спасибо, теперь в качестве одного из важных критериев системы/утилит резервного копирования буду проверять наличие подобных алгоритмов, а то и правда обидно за избыточное хранение
Что-то я не пойму, как в описанном случае быть если файл полного бэкапа будет поврежден?
Т.е. по сути это просто уменьшает количество файлов с инкрементами, так как их дописывает в полный бэкап. Но ведь в таком случае еще больше снижается надежность по сравнению даже с прямым инкрементным методом с одним полный бэкапом. Так как регулярно будут вноситься правки в файл полного бэкапа и соответственно не нулевая вероятность его запороть в процессе обновления.
Т.е. по сути это просто уменьшает количество файлов с инкрементами, так как их дописывает в полный бэкап. Но ведь в таком случае еще больше снижается надежность по сравнению даже с прямым инкрементным методом с одним полный бэкапом. Так как регулярно будут вноситься правки в файл полного бэкапа и соответственно не нулевая вероятность его запороть в процессе обновления.
Строго говоря ничего революционного в новом методе нет. Полная «перестраиваемая копия» («синтетическая полная») была придумана уже много лет назад (как только СХД начали применять как бэкап-таргет вместо лент) и реально применяется многими компаниями. Еще более «агрессивным» (по интенсивности модификации данных) ее аналогом является репликация. Просто есть категории клиентов, для которых время восстановления очень важно, и они готовы пойти на небольшое увеличения риска. В любом случае нельзя полагаться лишь на одну резервную копию — нужно использовать «правило 3-2-1», про которое я в свое время написал отдельный пост на Хабре, и тогда можно пренебречь небольшим повышением риска повреждения файла полной копии — от этого не застрахован ни один метод резервного копирования.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Преимущества нового метода резервного копирования виртуальных машин перед классическими схемами