Про “лучшие практики” слышали многие – это рекомендации, которым стоит следовать при развертывании системы для ее оптимальной работы. Однако сегодня я хочу рассказать о “худших практиках” или о распространенных ошибках администраторов в области задач резервного копирования. Поскольку пользователям продуктов не всегда хватает времени, чтобы прочитать множество статей с “лучшими практиками”, а также ресурсов, чтобы внедрить их все, я решил обобщить информацию о том, чего точно следует избегать при работе с продуктами резервного копирования. За “вредными советами” добро пожаловать под кат.

Отсутствие планирования резервного копирования и оценки характеристик хранилища резервных копий – самая распространенная “худшая практика”. Многие пользователи устанавливают продукт резервного копирования со стандартными настройками, просто последовательно нажимая кнопку «Далее» в мастерах продукта. Более того, многие оставляют стандартные настройки и для заданий резервного копирования, не учитывая особенностей инфраструктуры, политик удаления старых копий и других важных аспектов. В результате возникают ошибки при запуске и выполнении заданий, преждевременное заполнение репозитория и, как следствие, приятное, но времязатратное общение со службой техподдержки.
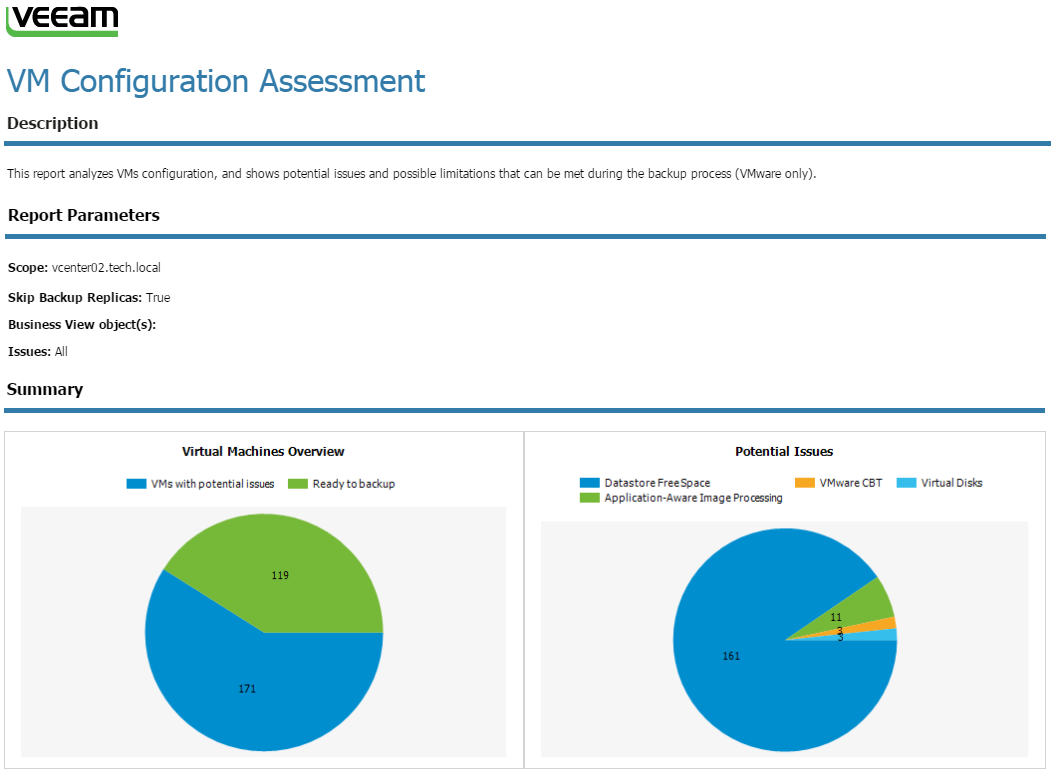
А как правильно? На примере продуктов Veeam: во избежание подобных сценариев перед установкой Veeam Backup & Replication рекомендуется использовать, например, Veeam ONE – инструмент для мониторинга и создания отчетов о работе инфраструктуры. Так, открыв отчет VM Configuration Assessment (проверка конфигурации виртуальных машин), вы поймете, готовы ли ваши виртуальные машины к резервному копированию, и, если нет, – то по какой причине. Отчет VM Change Rate Estimation (оценка частоты изменения ВМ) строится на основе статистики по изменению блоков виртуальных машин и позволяет правильно рассчитать необходимый размер репозитория.
Подробнее о полезных для планирования отчетах можно почитать, например, здесь.
Еще один инструмент от Veeam – онлайн-калькулятор размера точек восстановления – также поможет при планировании среды резервного копирования.
Хотите завалить все задания резервного копирования из-за ошибки в одном из них? Тогда скорее объединяйте их в цепочки зависимых заданий, чтобы при завершении одного задания сразу начиналось другое. В этом случае вы гарантированно получите увеличение окон резервного копирования, задержку старта заданий и прочие неприятные последствия.
А как правильно? На самом деле, объединять задачи следует только в определенных случаях. Например, если вы не хотите бэкапить два приложения одновременно, то вы можете настроить старт бэкапа одного из них только после завершения бэкапа другого приложения. В случае Veeam вам лучше доверить продукту спланировать ресурсы за вас. Планировщик Veeam Backup & Replication умеет запускать несколько заданий одновременно для оптимизации окон резервного копирования, применяя “умные алгоритмы” для распределения нагрузки на компоненты инфраструктуры, выбирая оптимальный режим передачи данных и работая в установленных пределах пропускной способности канала до репозитория.
Жизненный опыт показывает, что часто компании “экономят” на тестировании резервных копий. Это может быть связано как с недостаточной осведомленностью в отношении возможных проблем на фазе восстановления, так и с экономическими факторами, так как полноценный процесс тестирования восстановления системы из резервной копии, если проводить его вручную, — очень трудоемкая операция. Такая ситуация чревата негативными последствиями, ведь в случае сбоя критические данные могут быть не восстановлены в заданное время или, что еще хуже, могут быть частично или полностью потеряны.
Что случилось в 1998 году в реальном случае студии Pixar, когда едва не были потеряны все рабочие материалы мультфильма “История Игрушек 2”, можете прочитать в нашем посте “Случай в Pixar или еще раз о важности тестирования резервных копий”.
А как правильно? Тестирование восстановления из резервных копий необходимо производить регулярно. Следует различать тестирование целостности самой резервной копии и тестирование восстановления из резервной копии. В первом случае вы проверяете только целостность копии по контрольным суммам блоков данных. Во втором вы проводите тестирование, отражающее тот или иной моделируемый сценарий отдельного сбоя или полномасштабной “катастрофы” продуктивной сети. Крайне важно делать не только первое, но и второе, потому что в конечном счете вас интересует именно реальное восстановление данных в случае сбоя, и даже если целостность самой резервной копии не нарушена, восстановление может пройти неудачно.
Вероятных причин неудачного восстановления может быть много, приведу только некоторые из них:
Как эти проблемы можно решить? Например, технология Veeam SureBackup позволяет автоматически протестировать виртуальные машины из резервных копий и удостовериться в возможности их восстановления. Задание SureBackup (см. пост “SureBackup – автоматическая проверка возможности восстановления данных из резервной копии”) автоматически запускает все машины, с учетом их зависимостей (например, сначала контроллер домена и только потом Exchange сервер), в изолированной виртуальной лаборатории, проверяет их работоспособность (в том числе с помощью скриптов, написанных пользователем) и отправляет соответствующие отчеты по электронной почте.
И, наконец, худший совет по сегодняшней теме конкретно по Veeam: запустите виртуальную машину с помощью Instant VM recovery и забудьте про нее. Совсем забудьте. В этом случае вам гарантирована целая тонна проблем. Работа машины прямо из репозитория приведет к блокировке точки восстановления, поэтому другие задания (например, SureBackup или BackupCopy) просто не запустятся. Происходит это из-за того, что машина запускается прямо из файла резервной копии в режиме чтения, то есть без записи каких-либо изменений в сам файл. При этом создается отдельный файл на диске C: сервера резервного копирования Veeam, который разрастется до невероятных размеров, если оставить машину работающей хотя бы на несколько дней.
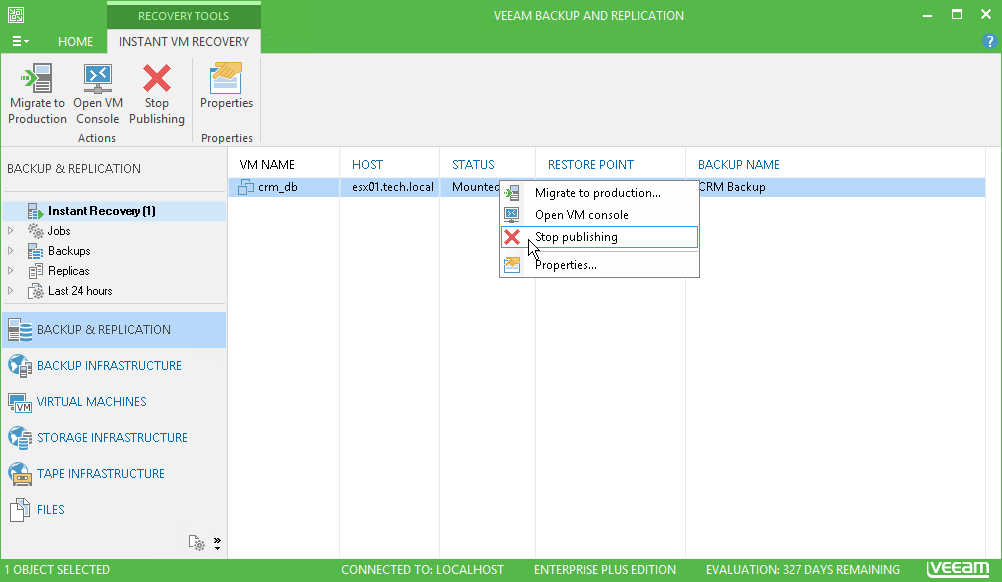
А как правильно? Чтобы избежать этого, сразу после завершения Instant VM recovery обязательно переносите машину в продакшен-среду. Подробнее об этом процессе можно узнать в руководстве пользователя Veeam.
Надеюсь, эта статья поможет сэкономить время, деньги и избавит от головной боли от описанных проблем. Есть что добавить к списку «худших практик»? Тогда поделитесь этим в комментариях!
А в заключение привожу ссылки на наши лучшие посты про лучшие практики резервного копирования, какой бы продукт вы не использовали:

Запуск заданий бэкапа с настройками, не учитывающими конкретную конфигурацию
Отсутствие планирования резервного копирования и оценки характеристик хранилища резервных копий – самая распространенная “худшая практика”. Многие пользователи устанавливают продукт резервного копирования со стандартными настройками, просто последовательно нажимая кнопку «Далее» в мастерах продукта. Более того, многие оставляют стандартные настройки и для заданий резервного копирования, не учитывая особенностей инфраструктуры, политик удаления старых копий и других важных аспектов. В результате возникают ошибки при запуске и выполнении заданий, преждевременное заполнение репозитория и, как следствие, приятное, но времязатратное общение со службой техподдержки.
А как правильно? На примере продуктов Veeam: во избежание подобных сценариев перед установкой Veeam Backup & Replication рекомендуется использовать, например, Veeam ONE – инструмент для мониторинга и создания отчетов о работе инфраструктуры. Так, открыв отчет VM Configuration Assessment (проверка конфигурации виртуальных машин), вы поймете, готовы ли ваши виртуальные машины к резервному копированию, и, если нет, – то по какой причине. Отчет VM Change Rate Estimation (оценка частоты изменения ВМ) строится на основе статистики по изменению блоков виртуальных машин и позволяет правильно рассчитать необходимый размер репозитория.

Подробнее о полезных для планирования отчетах можно почитать, например, здесь.
Еще один инструмент от Veeam – онлайн-калькулятор размера точек восстановления – также поможет при планировании среды резервного копирования.
Объедините все задания в цепочки
Хотите завалить все задания резервного копирования из-за ошибки в одном из них? Тогда скорее объединяйте их в цепочки зависимых заданий, чтобы при завершении одного задания сразу начиналось другое. В этом случае вы гарантированно получите увеличение окон резервного копирования, задержку старта заданий и прочие неприятные последствия.
А как правильно? На самом деле, объединять задачи следует только в определенных случаях. Например, если вы не хотите бэкапить два приложения одновременно, то вы можете настроить старт бэкапа одного из них только после завершения бэкапа другого приложения. В случае Veeam вам лучше доверить продукту спланировать ресурсы за вас. Планировщик Veeam Backup & Replication умеет запускать несколько заданий одновременно для оптимизации окон резервного копирования, применяя “умные алгоритмы” для распределения нагрузки на компоненты инфраструктуры, выбирая оптимальный режим передачи данных и работая в установленных пределах пропускной способности канала до репозитория.
Никогда не верифицируйте бэкапы
Жизненный опыт показывает, что часто компании “экономят” на тестировании резервных копий. Это может быть связано как с недостаточной осведомленностью в отношении возможных проблем на фазе восстановления, так и с экономическими факторами, так как полноценный процесс тестирования восстановления системы из резервной копии, если проводить его вручную, — очень трудоемкая операция. Такая ситуация чревата негативными последствиями, ведь в случае сбоя критические данные могут быть не восстановлены в заданное время или, что еще хуже, могут быть частично или полностью потеряны.
Что случилось в 1998 году в реальном случае студии Pixar, когда едва не были потеряны все рабочие материалы мультфильма “История Игрушек 2”, можете прочитать в нашем посте “Случай в Pixar или еще раз о важности тестирования резервных копий”.
А как правильно? Тестирование восстановления из резервных копий необходимо производить регулярно. Следует различать тестирование целостности самой резервной копии и тестирование восстановления из резервной копии. В первом случае вы проверяете только целостность копии по контрольным суммам блоков данных. Во втором вы проводите тестирование, отражающее тот или иной моделируемый сценарий отдельного сбоя или полномасштабной “катастрофы” продуктивной сети. Крайне важно делать не только первое, но и второе, потому что в конечном счете вас интересует именно реальное восстановление данных в случае сбоя, и даже если целостность самой резервной копии не нарушена, восстановление может пройти неудачно.
Вероятных причин неудачного восстановления может быть много, приведу только некоторые из них:
- при восстановлении системы могут требоваться дополнительные шаги, которые автоматически не выполняет продукт резервного копирования (скажем, перенастройка удаленных сервисов, взаимодействующих с восстанавливаемой системой),
- может произойти отказ в доступе к репозиторию резервных копий с нового ноутбука админа (просто потому что это будет первая попытка такого доступа – и на это уйдет лишнее драгоценное время),
- низкая пропускная способность канала “подвесит” процесс off-site восстановления (когда резервную копию нужно подтянуть из другого офиса),
- вдруг выяснится, что ежедневный бэкап последние полгода постоянно увеличивался в размере (практически все исходные системы постоянно растут в размере) – и в какой-то момент не поместился на ленту, а ошибка осталась незамеченной (вышеупомянутый пример с Pixar),
- старая резервная копия может не восстановиться на новом железе,
- при восстановлении может выясниться, что не все файлы или машины попали в область задания резервного копирования.
Как эти проблемы можно решить? Например, технология Veeam SureBackup позволяет автоматически протестировать виртуальные машины из резервных копий и удостовериться в возможности их восстановления. Задание SureBackup (см. пост “SureBackup – автоматическая проверка возможности восстановления данных из резервной копии”) автоматически запускает все машины, с учетом их зависимостей (например, сначала контроллер домена и только потом Exchange сервер), в изолированной виртуальной лаборатории, проверяет их работоспособность (в том числе с помощью скриптов, написанных пользователем) и отправляет соответствующие отчеты по электронной почте.
Не завершайте процесс моментального восстановления машины (Instant VM recovery)
И, наконец, худший совет по сегодняшней теме конкретно по Veeam: запустите виртуальную машину с помощью Instant VM recovery и забудьте про нее. Совсем забудьте. В этом случае вам гарантирована целая тонна проблем. Работа машины прямо из репозитория приведет к блокировке точки восстановления, поэтому другие задания (например, SureBackup или BackupCopy) просто не запустятся. Происходит это из-за того, что машина запускается прямо из файла резервной копии в режиме чтения, то есть без записи каких-либо изменений в сам файл. При этом создается отдельный файл на диске C: сервера резервного копирования Veeam, который разрастется до невероятных размеров, если оставить машину работающей хотя бы на несколько дней.
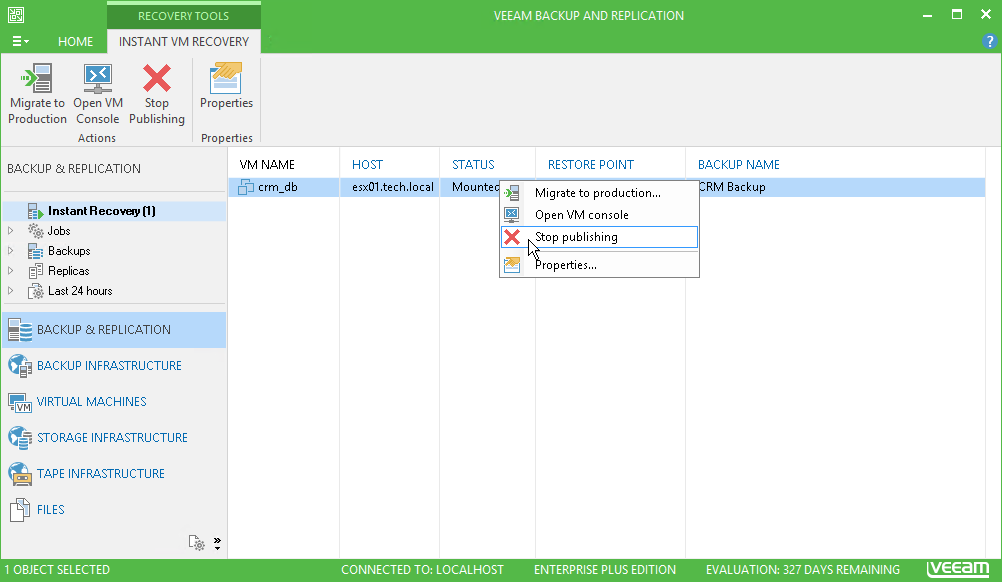
А как правильно? Чтобы избежать этого, сразу после завершения Instant VM recovery обязательно переносите машину в продакшен-среду. Подробнее об этом процессе можно узнать в руководстве пользователя Veeam.
Заключение
Надеюсь, эта статья поможет сэкономить время, деньги и избавит от головной боли от описанных проблем. Есть что добавить к списку «худших практик»? Тогда поделитесь этим в комментариях!
А в заключение привожу ссылки на наши лучшие посты про лучшие практики резервного копирования, какой бы продукт вы не использовали:
