
Существует много технологий, которые позволяют сохранить важную информацию в случае выхода носителей из строя, а также ускорить доступ к важным данным. Но наше гиперконвергентное хранилище Virtuozzo Storage по ряду параметров опережает программно-определяемые решения с открытым исходным кодом, а также готовые системы SAN или NAS. И сегодня мы говорим об архитектуре системы и ее преимуществах.
Для начала стоит сказать о том, что же такое Virtuozzo Storage (в среде разработчиков — VZ Storage). Решение представляет собой распределенное хранилище, использующее ту же самую инфраструктуру, на которой работают ваши виртуальные машины и контейнеры (так называемую, гиперконвергентную инфраструктуру — hyper-converged). Изначально продукт развивался вместе с виртуализацией Virtuozzo. Однако, если вам не нужна полноценная система виртуализации, теперь проект доступен и в виде отдельного распределенного хранилища, которое может работать с любыми клиентами.
Если говорить в общем, то VZ Storage использует диски в тех же самых серверах, которые обслуживают систему виртуализации. Таким образом, у вас пропадает необходимость закупать отдельное оборудование, например, дорогостоящий контроллер SAN/NAS, чтобы создать сетевую среду хранения. Одна из отличительных особенностей VZ Storage заключается в выборе способа хранения данных (схему избыточности) для разных категорий данных. Временные логи, например, можно вообще не резервировать, а для важных данных предусмотрены различные технологии защиты – репликация (полное дублирование) или самовосстанавливающиеся коды (Erasure Coding).
Железо
Так как VZ Storage является гиперконвергентной системой хранения, она может быть развернута с использованием любых серверов стандартной архитектуры x86. Впрочем, чтобы работа системы была эффективной, в каждом сервере должно быть установлено как минимум три жестких диска не менее 100 Гб емкостью каждый, двухъядерный процессор (одно ядро отдаем хранилищу), и 2Гб оперативной памяти. В более мощных конфигурациях мы рекомендуем ставить одно процессорное ядро и 4ГБ памяти на каждые 8 жестких дисков. То есть, используя на узле, например, 15 дисков для создания хранилища, для поддержки работы кластера хранения вам потребуется всего 2 ядра и 8ГБ RAM.
Поскольку мы говорим о распределенном хранилище, серверы должны быть объединены в сеть. Теоретически можно использовать ту же самую сеть передачи данных, на которой работает кластер виртуализации, но намного эффективнее иметь второй сетевой адаптер с пропускной способностью не менее 1Гб/c, ведь скорость чтения и записи данных будет напрямую зависеть от характеристик сети. Кроме этого отдельная сеть будет полезна и с точки зрения безопасности.
Архитектура
Распределенная архитектура VZ Storage подразумевает, что мы устанавливаем разные компоненты системы на физические или виртуальные серверы: панель управления с графическим интерфейсом, сервер хранения данных (Chunk Server – CS), сервер метаданных (MetaData Server – MDS), монтирование хранилища для чтения/записи данных (Client). Один узел может запускать несколько компонент в любом сочетании. То есть, один сервер, например, может одновременно хранить и данные, и метаданные, и запускать виртуальные машины, и предоставлять панель управления кластером.

Все данные в кластере разбиваются на блоки фиксированного размера («chunks» — чанки). Для каждого «чанка» создается несколько реплик (его копий), причем размещаются они на различных машинах (чтобы обеспечить отказоустойчивость в случае выхода из строя целой машины). При установке кластера вы задаете параметр нормального и минимального количества реплик. Если какая-то машина выходит из строя или перестает работать диск, силами кластера все утраченные реплики будут воспроизведены на оставшихся – вплоть до параметра нормального количества (обычно 3). В это время система по-прежнему позволяет писать и часть данных без задержек. Но, если же из-за сбоя количество копий упало ниже минимального значения (обычно 2), то есть произошел одновременных отказ двух компонент, кластер позволяет только читать данные, а для записи клиентам придётся подождать пока не будет восстановлено хотя бы минимальное количество копий. Система восстанавливает такие чанки, с которыми идёт работа, с наивысшим приоритетом.
Количество CS и MDS на каждом сервере определяется количеством физических дисков. VZ Storage привязывает один компонент к одному накопителю, создавая тем самым четкое разделение ресурсов и реплик между разным физическим оборудованием.
В чем плюсы?
Мы немного познакомились со структурой и требованиями VZ Storage, и теперь возникает вопрос, зачем все это нужно? Какие плюсы дает система? Самое главное преимущество VZ Storage – это надежность. Используя то же самое оборудование (возможно, добавив в него сетевые контроллеры и диски), вы получаете высокоэффективную легко-масштабируемую систему с отлаженным механизмом работы с данными, метаданными. VZ Storage позволяет обеспечить постоянное и надежное хранение данных, включая диски ВМ и данные контейнерных приложений для Docker, Kubernetes или Rancher.
Второй плюс – это низкая стоимость владения (TCO). Кроме того, что для работы решения не нужно приобретать отдельное дорогостоящее «железо» и вы можете выбирать опции резервирования для различных данных, в VZ Storage имеется возможность использования erasure coding (кодов избыточности, таких как Reed-Solomon). Это позволяет снизить требования к общей емкости, сохраняя возможность восстановления данных в случае сбоя. Метод подходит для хранения больших объемов данных, когда высочайшая скорость доступа – это далеко не самое главное.
Какие именно плюсы дает erasure coding (EC)? Erasure codding позволяет значительно сократить расход использования дискового пространства. Достигается это счёт специальной обработки данных.
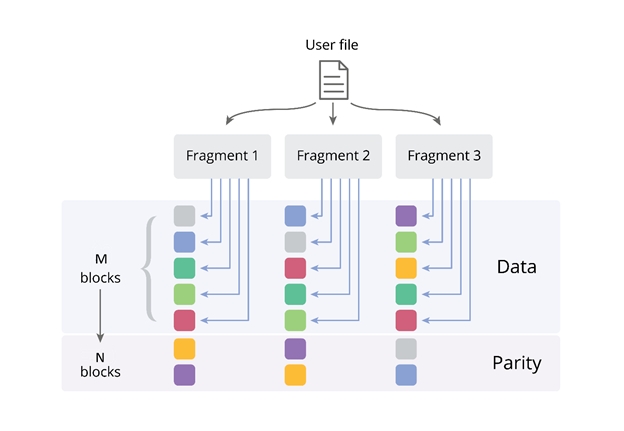
При формуле избыточности M+N[/X], EC позволяет использовать намного меньше дискового пространства. Если M – это количество блоков данных, N – количество блоков специальных контрольных сумм («Parity»), а X – параметр допустимости записи (он характеризуется тем, сколько узлов системы хранения могут быть недоступны, когда клиент по-прежнему может записывать данные в свои файлы). Чтобы система работала, минимальное количество узлов в VZ Storage должно составлять 5 (в этом случае M=3,N=2, или “3+2”). На картинке изображен пример, где M=5, N=2 или “5+2”.
На примере инсталляции системы с конфигурацией 5 + 2 и включенным EC, мы можем гарантировать дополнительную нагрузку на емкость лишь в 40%, создавая только 2Гб резервных данных на каждые 5Гб данных приложений).
В этом случае для защищенного хранения 100 Тб данных вам потребуется всего 140 Тб емкости. Такой подход помогает оптимизировать бюджет или обеспечить хранение больших объемов данных в тех случаях, когда в кластер уже физически нельзя установить больше дисков, в стойку – больше серверов, в серверную – больше стоек. При этом мы сохраняем высокую доступность данных – даже при выходе из строя двух элементов системы хранения, оставшиеся узлы системы позволят восстановить все данные вплоть до бита, не останавливая работу приложения. В таблице приведены значения резервной емкости, и, как вы можете видеть, результаты использования erasure coding оказываются действительно впечатляющими, когда в кластере используется много машин. Например, в конфигурации 17+3 с erasure coding резервная емкость составляет всего 18%

Другое дело – производительность. Конечно, erasure coding повышает нагрузку на ЦП, но совершенно незначительно. За счёт SSE инструкций на современных процессорах одно ядро может обрабатывать до ~2GB/s данных.
В том и плюс распределенной системы хранения, что вы можете задать разные типы резервирования для разных нагрузок. И в случае с прямыми репликами, кластер с большим количеством узлов, напротив, дает намного большую производительность. Впрочем, именно о производительности VZ Storage мы поговорим более подробно в следующем посте, так как измерения эффективности гиперконвергентной системы хранения данных зависят от огромного количества факторов, включая характеристики «железа», тип сетевой архитектуры, особенности нагрузки и так далее.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Что вы считаете наиболее важной характеристикой современной системы хранения?
6.52%
Высокая производительность
3
50%
Надежность хранения данных
23
8.7%
Использование стандартного «железа»
4
4.35%
Гиперконвергентность
2
6.52%
Простота управления
3
21.74%
Открытый исходный код
10
2.17%
Интеграции с различными API и платформами (aka Kubernetes)
1
Проголосовали 46 пользователей.
Воздержались 13 пользователей.
