
Развитие глубоких нейронных сетей для распознавания изображений вдыхает новую жизнь в уже известные области исследования в машинном обучении. Одной из таких областей является доменная адаптация (domain adaptation). Суть этой адаптации заключается в обучении модели на данных из домена-источника (source domain) так, чтобы она показывала сравнимое качество на целевом домене (target domain). Например, source domain может представлять собой синтетические данные, которые можно «дёшево» сгенерировать, а target domain — фотографии пользователей. Тогда задача domain adaptation заключается в тренировке модели на синтетических данных, которая будет хорошо работать с «реальными» объектами.
В группе машинного зрения Vision@Mail.Ru мы работаем над различными прикладными задачами, и среди них часто встречаются такие, для которых мало тренировочных данных. В этих случаях сильно может помочь генерация синтетических данных и адаптация обученной на них модели. Хорошим прикладным примером такого подхода является задача детектирования и распознавания товаров на полках в магазине. Получение фотографий таких полок и их разметка довольно трудозатратны, зато их можно достаточно просто сгенерировать. Поэтому мы решил глубже погрузиться в тему доменной адаптации.

Исследования в доменной адаптации затрагивают вопросы использования в новой задаче предыдущего накопленного нейросетью опыта. Сможет ли сеть выделить некоторые характерные особенности из домена-источника и использовать их в целевом домене? Хотя нейронная сеть в машинном обучении имеет лишь отдалённое отношение к нейронным сетям в человеческом мозге, всё же Священным Граалем исследователей искусственного интеллекта является обучение нейросетей тем возможностям, которыми обладает человек. А люди способны использовать предыдущий опыт и накопленные знания для понимания новых концепций.
Кроме того, доменная адаптация может помочь решить одну из фундаментальных проблем глубокого обучения: для тренировки больших сетей с высоким качеством распознавания необходимо очень большое количество данных, которые на практике не всегда доступны. Одним из решений может быть использование методов domain adaptation на синтетических данных, которые можно нагенерировать практически в неограниченном количестве.
Довольно часто в прикладных задачах встречается случай, когда для обучения доступны данные только из одного домена, а применять модель необходимо на другом домене. Например, сеть, определяющую эстетическое качество фотографии, можно обучить на доступной в сети базе, собранной с сайта фотолюбителей. А применять эту сеть планируется на обычных фотографиях, уровень качества которых в среднем отличается от уровня фото со специализированного фотосайта. В качестве варианта решения можно рассматривать адаптацию модели под обычные неразмеченные фотографии.
Такие теоретические и прикладные вопросы лежат в области domain adaptation. В этой статье я расскажу об основных на данный момент исследованиях в этой сфере, основанных на глубоком обучении, и о датасетах для сравнения различных методов. Главная идея deep domain adaptation заключается в том, чтобы обучить на домене-источнике глубокую нейронную сеть, которая будет переводить изображение в такое векторное представление (embedding) (обычно это последний слой сети), что при использовании его на целевом домене получится высокое качество.
Основные бенчмарки
Как и в любой области машинного обучения, в доменной адаптации со временем накапливается определённое количество исследований, которые необходимо сравнивать между собой. Для этого сообщество вырабатывает датасеты, на тренировочной части которых модели обучаются, а на тестовой — сравниваются. Несмотря на то, что область исследований deep domain adaptation ещё сравнительно молода, уже существует довольно большое число статей и баз данных, которые используются в этих статьях. Я перечислю основные из них, сделав акцент на адаптацию домена синтетических данных на «реальные».
Цифры
Видимо, по традиции, заведённой Янном ЛеКуном (один из пионеров глубокого обучения, директор Facebook AI Research), в компьютерном зрении самые простые датасеты связаны с рукописными цифрами или буквами. Существуют несколько наборов данных с цифрами, которые изначально появились для экспериментов с моделями по распознаванию изображений. В статьях по доменной адаптации можно встретить самые разные их комбинации в парах source — target domain. Среди этих датасетов:
- MNIST — рукописные цифры, не нуждается в дополнительном представлении;
- USPS — рукописные цифры в низком разрешении;
- SVHN — номера домов с Google Street View;
- Synth Numbers — синтетические числа, как следует из названия.
С точки зрения задачи обучения на синтетических данных для использования в «реальном» мире наибольший интерес представляют пары:
- Source: MNIST, Target: SVHN;
- Source: USPS, Target: MNIST;
- Source: Synth Numbers, Target: SVHN.

Большинство методов имеют бенчмарки на «цифровых» датасетах. А вот остальные виды доменов можно встретить далеко не во всех статьях.
Office
Этот датасет содержит 31 категорию различных предметов, каждый из которых представлен в 3 доменах: изображение из Амазона, фотография с веб-камеры и фотография с цифрового фотоаппарата.

Он полезен для проверки того, как модель будет реагировать на добавление фона и качества съёмки в целевой домен.
Дорожные знаки
Ещё одна пара датасетов для обучения модели на синтетических данных и применения её на «реальных» данных:
- Source: Synth Signs — изображения дорожных знаков, сгенерированные так, чтобы они были похожи настоящие знаки на улице;
- Target: GTSRB — довольно известная база для распознавания, содержащия знаки с немецких дорог.

Особенностью этой пары баз является то, что данные из Synth Signs сделаны довольно похожими на «реальные» данные, поэтому домены достаточно близки.
Из окна машины
Датасеты для сегментации. Довольно интересная пара, наиболее приближенная к реальным условиям. Исходные данные получают с помощью игрового движка (GTA 5), а целевые — из реальной жизни. Похожие подходы применяются для обучения моделей, которые используются в автономных автомобилях.
- SYNTHIA или движок GTA 5 — картинки с видом на город из окна автомобиля, сгенерированные с помощью игрового движка;
- Cityscapes — фото из автомобиля, сделанные в 50 различных городах.

VisDA
Этот датасет используется в конкурсе Visual Domain Adaptation Challenge, который проводится в рамках воркшопа на ECCV и ICCV. В домене-источнике представлено 12 категорий размеченных объектов, сгенерированных с помощью CAD'а, таких как самолёт, лошадь, человек и т.п. Целевой домен содержит неразмеченные изображения из тех же 12 категорий, взятых из ImageNet. В конкурсе, который проводился в 2018 году, была добавлена 13-ая категория: Unknown.
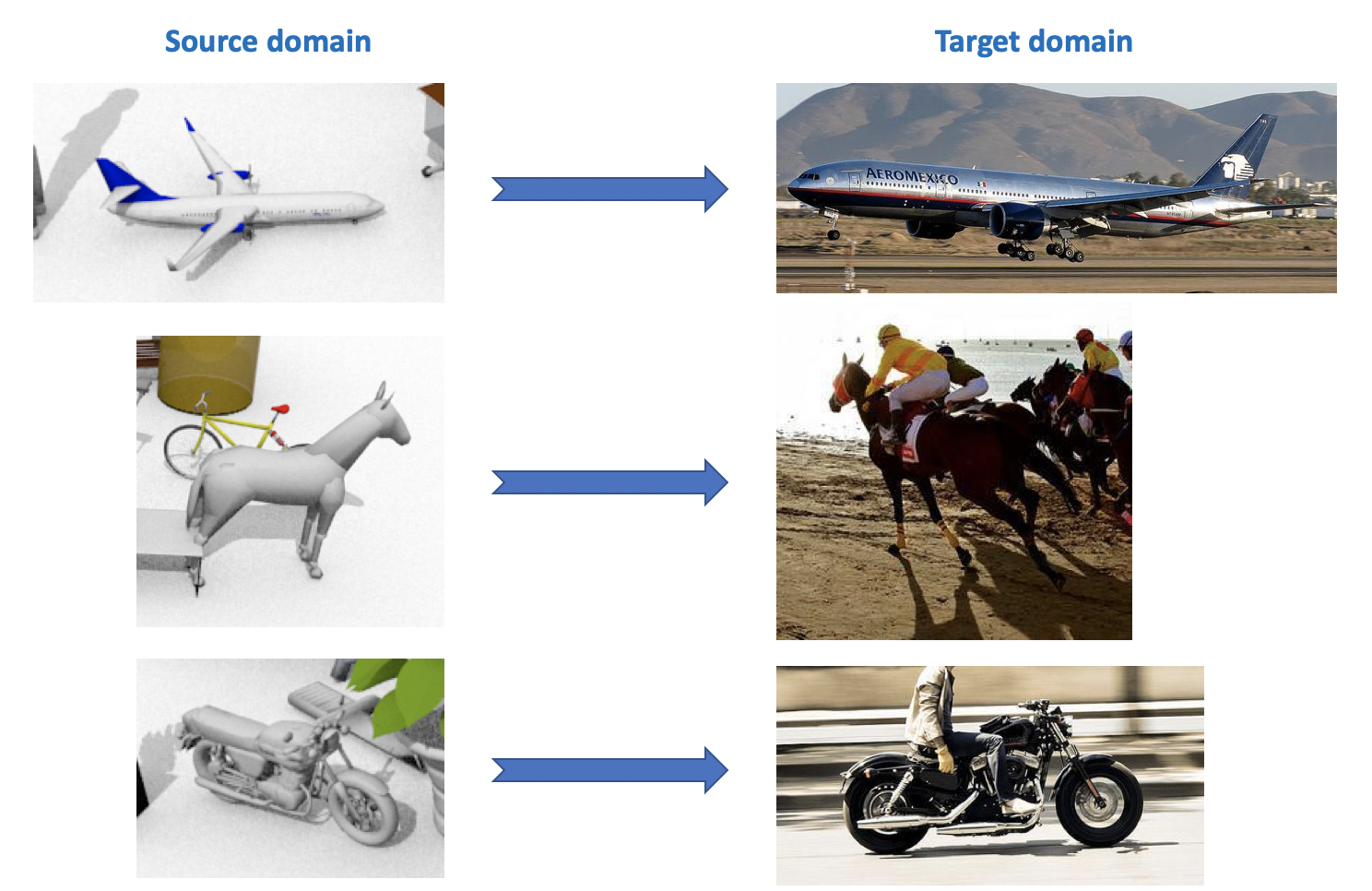
Как видно из всего перечисленного выше, интересных и разнообразных датасетов для доменной адаптации довольно много, на них можно обучать и проверять модели для различных задач (классификация, сегментация, детектирование) и различных условий (синтетические данные, фотографии, виды улиц).
Deep Domain Adaptation
Существует довольно обширная и разнообразная классификация методов доменной адаптации (ознакомиться можно например здесь). Я приведу в данной статье упрощённое деление методов по их ключевым особенностям. Современные методы deep domain adaptation можно разделить на 3 большие группы:
- Discrepancy-based: подходы, основанные на минимизации расстояния между векторными представлениями на исходном и целевом доменах с помощью введения этого расстояния в loss-функцию.
- Adversarial-Based: эти подходы используют состязательную (adversarial) loss-функцию, появившуюся в GAN'ах, для обучения сети, инвариантной относительно домена. Методы этого семейства активно развиваются в последние пару лет.
- Смешанные методы, которые не используют adversarial loss, но применяют идеи из discrepancy-based семейства, а также последние наработки из глубокого обучения: self-ensembling, новые слои, loss-функции и т.п. Эти подходы показывают лучшие результаты в конкурсе VisDA.
Из каждого раздела будет рассмотрено несколько основных, на мой взгляд, результатов, полученных за последние 1-3 года.
Discrepancy-based
Когда возникает задача адаптации модели под новые данные, первое, что приходит на ум, это использование fine-tuning, т.е. дообучения модели на новых данных. Для этого необходимо учитывать меру несоответствия (discrepancy) между доменами. Такой вид доменной адаптации можно разделить на три подхода: Class Criterion, Statistical criterion и Architecture Criterion.
Class Criterion
Методы из этого семейства в основном применяются, когда нам доступны размеченные данные из целевого домена. Одним из популярных вариантов Class Criterion является подход Deep transfer metric learning. Как следует из названия, он основан на metric learning, суть которого заключается в обучении такого векторного представления, получаемого из нейронной сети, что представители одного класса будут близки друг к другу в этом представлении по заданной метрике (чаще всего используют  или косинусную метрики). В статье Deep transfer metric learning (DTML) для реализации этого подхода используется loss, состоящий из суммы слагаемых:
или косинусную метрики). В статье Deep transfer metric learning (DTML) для реализации этого подхода используется loss, состоящий из суммы слагаемых:
- Близость представителей одного класса друг к другу (intraclass compactness);
- Увеличение расстояния между представителями разных классов (interclass separability);
- Метрика Maximum Mean Discrepancy (MMD) между доменами. Эта метрика относится к семейству statistical criterion (см. ниже), но используется и в class criterion.
MMD между доменами записывается в виде

где  — это некоторое ядро, в нашем случае — векторное представление сети,
— это некоторое ядро, в нашем случае — векторное представление сети,  — данные из исходного домена,
— данные из исходного домена,  — данные из целевого домена. Таким образом, при минимизации метрики MMD во время обучения подбирается такая сеть , чтобы её средние векторные представления на обоих доменах были близки. Основная идея DTML:
— данные из целевого домена. Таким образом, при минимизации метрики MMD во время обучения подбирается такая сеть , чтобы её средние векторные представления на обоих доменах были близки. Основная идея DTML:
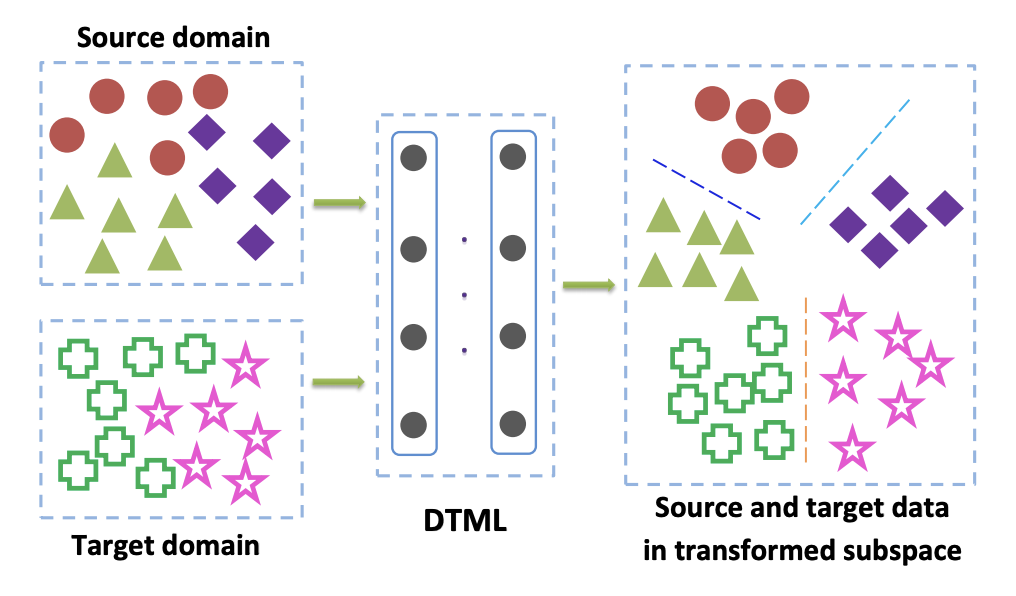
Если данные в целевом домене не размечены (unsupervised domain adaptation), метод, описанный в Mind the Class Weight Bias: Weighted Maximum Mean Discrepancy for Unsupervised Domain Adaptation, предлагает обучить модель на домене-источнике и использовать её для получения псевдо-лэйблов (pseudo-labels) на целевом домене. Т.е. данные из target domain прогоняются через сеть и полученный результат называется псевдо-лэйблами. Затем они используются как разметка для целевого домена, что позволяет применять в loss-функции MMD-критерий (с разными весами для компонент, отвечающих за разные домены).
Statistical criterion
Методы, относящиеся к этому семейству, используются для решения задачи unsupervised domain adaptation. Случай, когда целевой домен неразмечен, встречается во многих задачах, и все методы доменной адаптации, которые будут рассмотрены дальше в этой статье, решают именно такую задачу.
Подходы, основанные на статистическом критерии, пытаются измерить разницу между распределениями векторного представления сети, получаемыми из данных исходного и целевого доменов. Затем они используют вычисленную разницу для сближения этих двух распределений.
Одним из таких критериев является уже описанный выше Maximum Mean Discrepancy (MMD). Его варианты используются в нескольких методах:
- Deep adaptation network (DAN);
- Joint adaptation network (JAN);
- Residual transfer network (RTN). RTN показывает неплохие результаты для пары MNIST -> SVHN: 90,66 % точности на целевом домене.
Схемы этих трёх методов представлены ниже. В них варианты MMD используются для определения разницы между распределениями на слоях свёрточной нейронной сети, применённой к исходному и целевому доменам. Обратите внимание, что каждый их них использует модификацию MMD в качестве loss'а между слоями свёрточных сетей (жёлтые фигуры на схеме).

Критерий CORAL (CORrelation ALignment) и его расширение с помощью глубоких сетей Deep CORAL направлены на то, чтобы выучить такое представление данных, чтобы максимально совпадали между собой статистики второго порядка между доменами. Для этого используются ковариационные матрицы векторных представлений сети. Сближение статистик второго порядка на обоих доменах в некоторых случаях позволяет получить лучшие, чем для MMD, результаты адаптации.

где  — квадрат матричной нормы Фробениуса, а
— квадрат матричной нормы Фробениуса, а  и
и  — ковариационные матрицы данных из исходного и целевого доменов соответственно,
— ковариационные матрицы данных из исходного и целевого доменов соответственно,  — размерность векторного представления.
— размерность векторного представления.
На датасете Office среднее качество адаптации с использованием Deep CORAL для пар доменов Amazon и Webcam: 72,1 %. На доменах дорожных знаков Synth Signs -> GTSRB результат также весьма средний: 86,9 % точности на target domain.
Развитием идей MMD и CORAL является критерий Central Moment Discrepancy (CMD), который сравнивает центральные моменты данных из исходного и целевого доменов всех порядков до  включительно ( — параметр алгоритма). На датасете Office среднее качество адаптации CMD для пар доменов Amazon и Webcam составляет 77,0 %.
включительно ( — параметр алгоритма). На датасете Office среднее качество адаптации CMD для пар доменов Amazon и Webcam составляет 77,0 %.
Architecture Criterion
Алгоритмы этого типа строятся на предположении, что основная информация, которая отвечает за адаптацию на новый домен, заложена в параметрах нейронной сети.
В ряде работ [1], [2] при обучении сетей для исходного и целевого доменов с помощью loss-функций для каждой пары слоёв изучается на весах этих слоёв информация, инвариантная относительно домена. Пример таких архитектур приведён ниже.
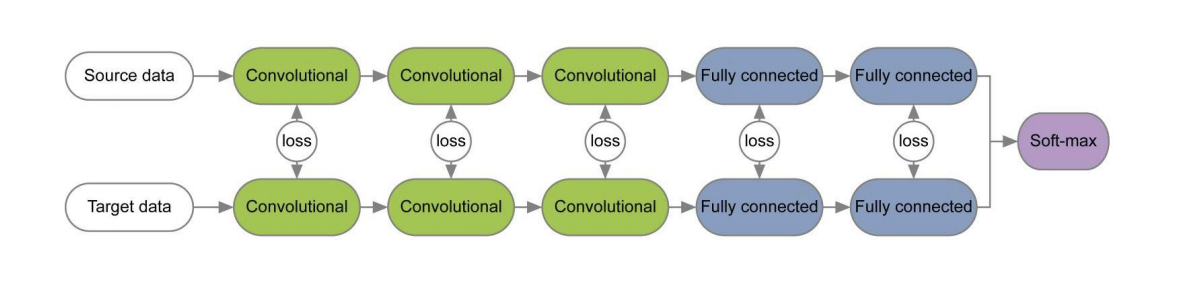
В статье Revisiting Batch Normalization For Practical Domain Adaptation была высказана идея, что в весах сети заложена информация, связанная с классами, на которых учится сеть, а доменная информация заложена в статистиках (среднем и стандартном отклонении) слоёв Batch Normalization (BN). Следовательно, для адаптации необходимо пересчитать эти статистики на данных из целевого домена. Использование этого приёма вместе с CORAL способно улучшить качество адаптации на датасете Office для пар доменов Amazon и Webcam до 75,0 %. Затем было показано, что использование слоя Instance Normalization (IN) вместо BN ещё больше улучшает качество адаптации. В отличие от BN, который нормализует входной тензор по батчам, IN вычисляет статистику для нормализации по каналам и, следовательно, не зависит от батча.
Adversarial-Based Approaches
В последние 1-2 года большинство результатов в deep domain adaptation связаны с adversarial-based подходом. Это во многом обусловлено стремительным развитием и ростом популярности Генеративно-состязательных сетей (Generative Adversarial Networks, GAN), потому что adversarial-based подход к доменной адаптации использует ту же состязательную (adversarial) целевую функцию при обучении, что и GAN. Оптимизируя её, такие методы deep domain adaptation минимизируют расстояние между эмпирическими распределениями векторных представлений данных на исходном и целевом доменах. Обучая сеть таким образом, её стараются сделать инвариантной относительно домена.
GAN состоит из двух моделей: генератора  , на выходе из которого получаются данные из некоторого целевого распределения; и дискриминатора
, на выходе из которого получаются данные из некоторого целевого распределения; и дискриминатора  , который определяет, подали ему на вход данные из обучающей выборки или сгенерированные с помощью . Обучаются эти две модели с помощью состязательной (adversarial) целевой функции:
, который определяет, подали ему на вход данные из обучающей выборки или сгенерированные с помощью . Обучаются эти две модели с помощью состязательной (adversarial) целевой функции:
![$\min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{data}(x)} [\log D(x)] + \mathbb{E}_{z \sim p(z)} [1 - \log D(G(z))].$](https://habrastorage.org/getpro/habr/formulas/c5c/dcb/727/c5cdcb72788cc76ae21240afb8020d90.svg)
При таком обучении генератор учится «обманывать» дискриминатор, что позволяет сблизить распределения целевого и исходного доменов.
Существует два больших подхода в adversarial-based domain adaptation, которые отличаются тем, используется или нет генератор .
Non-Generative Models
Ключевой особенностью методов из этого семейства является обучение нейронной сети с инвариантным по отношению к исходному и целевому доменам векторным представлением. Тогда обученную на размеченном source domain сеть можно будет использовать на target domain, в идеале — практически без потери качества классификации.
Представленный в 2015 году алгоритм Domain-Adversarial Training of Neural Networks (DANN) (код) состоит из 3 частей:
- Основной сети, с помощью которой получается векторное представление (feature extractor) (зелёная часть на иллюстрации ниже);
- "Головы", отвечающей за классификацию на исходном домене (синяя часть на иллюстрации);
- "Головы", которая обучается отличать данные из исходного домен от целевого (красная часть на иллюстрации).
При обучении с помощью градиентного спуска (SGD) (стрелки к input на иллюстрации) минимизируются классификационный и доменный loss'ы. К тому же при обратном распространении ошибки в обучении для "головы", отвечающей за домены, используется слой Gradient reversal layer (чёрная часть на иллюстрации), который умножает проходящий через него градиент на негативную константу, увеличивая доменный loss. Этим добиваются того, что распределения векторных представлений на обоих доменах становятся близки.
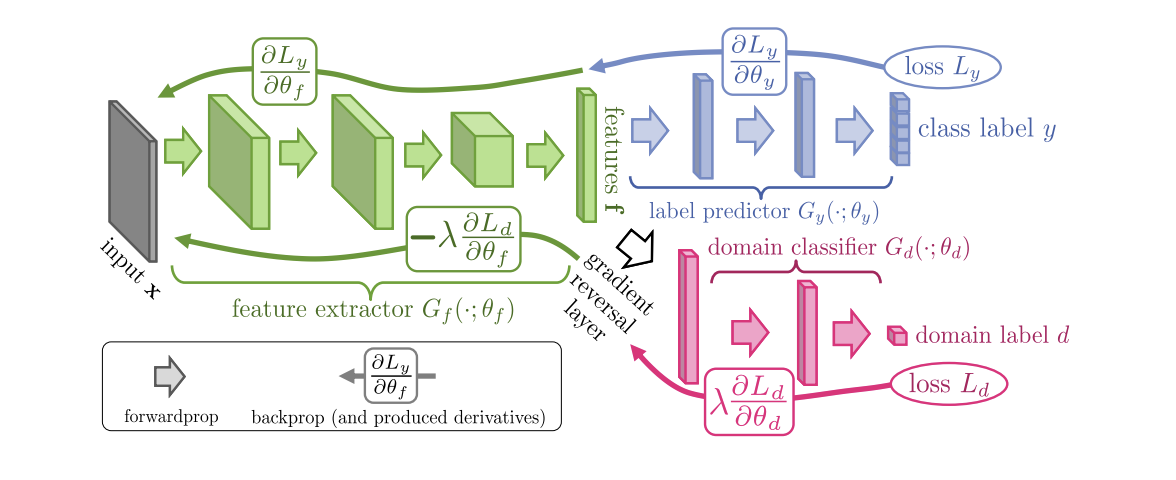
Результаты DANN на бенчмарках:
- На паре цифровых доменов Synth Numbers -> SVHN: 91,09 %.
- На дорожных знаках Synth Signs -> GTSRB он превосходит CORAL с результатом 88,7 %.
- На датасете Office среднее качество адаптации для пар доменов Amazon и Webcam: 73,0 %.
Следующим важным представителем семейства non-generative models является метод Adversarial Discriminative Domain Adaptation (ADDA) (код), который подразумевает разделение сети для исходного домена и сети для целевого домена. Алгоритм состоит из следующих шагов:
- Сначала классифицирующую сеть обучаем на исходном домене. Её векторное представление обозначим
 , а
, а  — исходный домен.
— исходный домен. - Теперь инициализируем нейронную сеть для целевого домена с помощью обученной сети из предыдущего шага. Обозначим её
 , а
, а  — целевой домен.
— целевой домен. - Перейдём к adversarial-тренировке: будем обучать дискриминатор при фиксированных и с помощью следующей целевой функции:
![$\min_D L_{adv_D}(\mathbf{X}_s, \mathbf{X}_t, M_s, M_t) = - \mathbb{E}_{x_s \sim \mathbf{X}_s}[\log D(M_s(x_s))] - \mathbb{E}_{x_t \sim \mathbf{X}_t}[\log (1 - D(M_t(x_t)))]$](https://habrastorage.org/getpro/habr/formulas/24c/fa4/f68/24cfa4f68a0e2eaf0c8582bf59201395.svg)
- Заморозим дискриминатор и дообучим на целевом домене:
![$\min_{M_s, M_t} L_{adv_M}(\mathbf{X}_s, \mathbf{X}_t, D) = - \mathbb{E}_{x_t \sim \mathbf{X}_t}[\log D(M_t(x_t))]$](https://habrastorage.org/getpro/habr/formulas/2c7/44d/bf3/2c744dbf3f430d5ab2c73dfb8869bfa3.svg)
Шаги 3 и 4 повторяются несколько раз. Суть ADDA заключается в том, что мы сначала обучаем хороший классификатор на размеченном исходном домене, а затем с помощью adversarial-обучения адаптируем так, чтобы векторные представления классификатора на обоих доменах были близки. Графически алгоритм можно представить следующим образом:
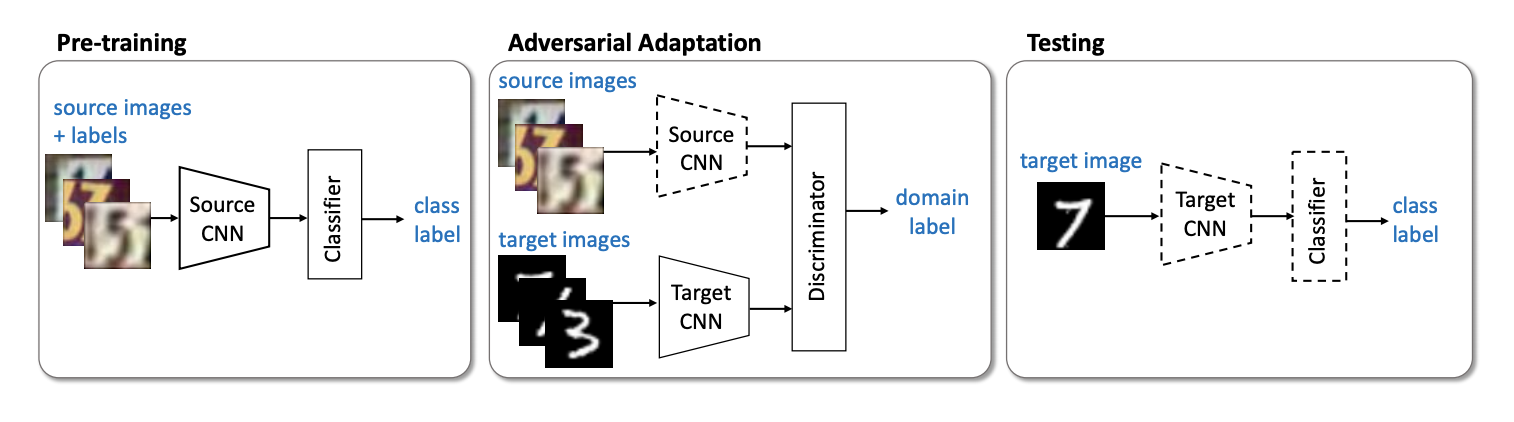
На паре цифровых доменов USPS -> MNIST ADDA показал результат 90,1 % точности на целевом домене.
Модификация ADDA была представлена в этом году на конференции ICML-2018 M-ADDA: Unsupervised Domain Adaptation with Deep Metric Learning (код).
Поскольку основная идея оригинального алгоритма заключается в сближении векторных представлений на разных доменах, авторы M-ADDA используют metric learning, чтобы классы лучше разделялись по -метрике. Для этого на шаге 1 ADDA при обучении сети на домене-источнике используется Triplet loss (он одновременно минимизирует расстояние между позитивными примерами (из одного класса) и максимизирует между негативными). В результате такого обучения векторные представления данных стремятся к тому, чтобы разбиться на кластеров (где — число классов). Для каждого кластера вычисляется его центр  .
.
Затем происходит обучение как в ADDA, т.е. выполняются шаги 2-4. Только после шага 4 добавляется регуляризация, которая заставляет векторные представления на целевом домене стягиваться к ближайшему кластеру  , обеспечивая тем самым лучшую разделимость классов в целевом домене:
, обеспечивая тем самым лучшую разделимость классов в целевом домене:
![$\mathbb{E}_{x_t \sim \mathbf{X}_t}[\min_j || M_t(x_t) - C_j ||^2].$](https://habrastorage.org/getpro/habr/formulas/07d/224/0d1/07d2240d132a6d688557b7d47054493f.svg)
Схема обучения модели на целевом домене представлена ниже.
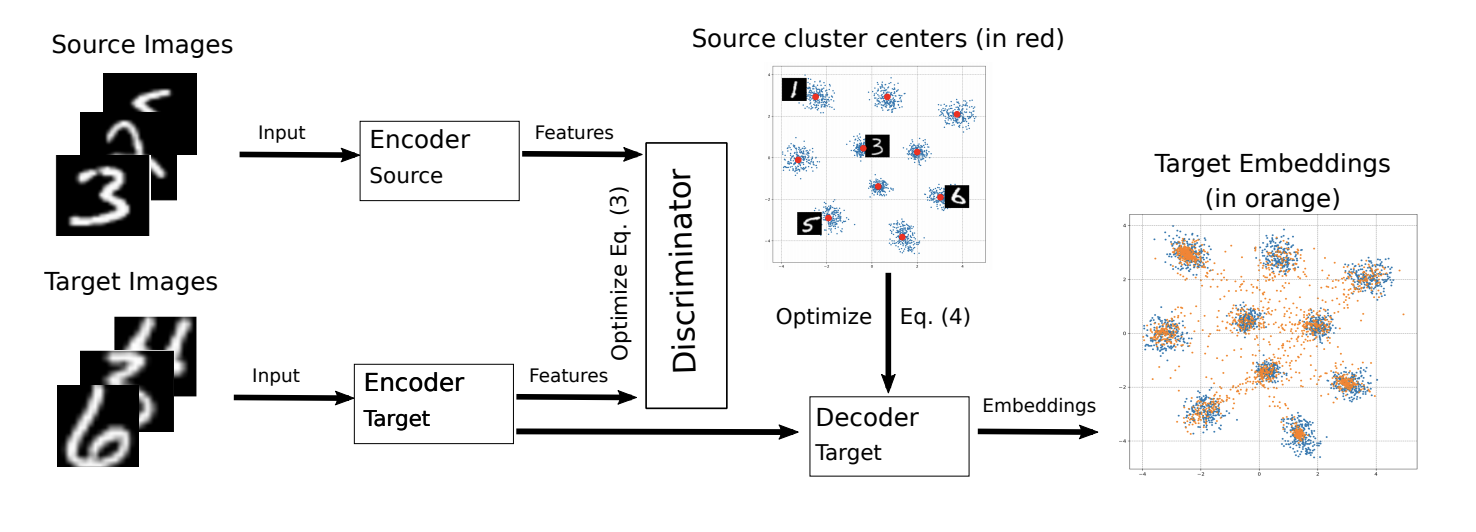
M-ADDA улучшил результат оригинального алгоритма на паре USPS -> MNIST до 94,0 %.
Достаточно нетипичным представителем non-generative семейства является метод Maximum Classifier Discrepancy for Unsupervised Domain Adaptation (код). Он также обучает такие векторные представления (генератор), чтобы они были как можно ближе друг к другу на исходном и целевом доменах. Однако, в качестве дискриминатора этот метод использует различия в предсказании между двумя классификаторами, обученными на генераторе.
Пусть генератор — это некая свёрточная сеть,  и
и  — два классификатора, которые в качестве входного вектора признаков используют выход генератора. Идея метода заключается в том, что , и обучаются на домене-источнике; затем классификаторы дообучаются так, чтобы максимизировать их несогласие на целевом домене; после этого генератор перестраивается, чтобы несогласие минимизировалось; и в конце обновляются и .
— два классификатора, которые в качестве входного вектора признаков используют выход генератора. Идея метода заключается в том, что , и обучаются на домене-источнике; затем классификаторы дообучаются так, чтобы максимизировать их несогласие на целевом домене; после этого генератор перестраивается, чтобы несогласие минимизировалось; и в конце обновляются и .
Как видно из описания, алгоритм построен на минимаксной adversarial-процедуре, результатом которой должна получиться сеть , инвариантная относительно домена.
В качестве меры несогласия (Discrepancy Loss) используется

где — число классов, 
 — значения softmax
— значения softmax  -ого класса для классификаторов и соответственно.
-ого класса для классификаторов и соответственно.
Более формально метод состоит из 3 шагов:
- A. На исходном домене обучаются , и .
- B. Генератор фиксируется, а несогласие классификаторов максимизируется на данных из целевого домена.
- C. Теперь фиксируются классификаторы, а параметры генератора обучаются так, чтобы минимизировать Discrepancy Loss.
Все три шага повторяются  раз (параметр алгоритма). Шаги B и C:
раз (параметр алгоритма). Шаги B и C:
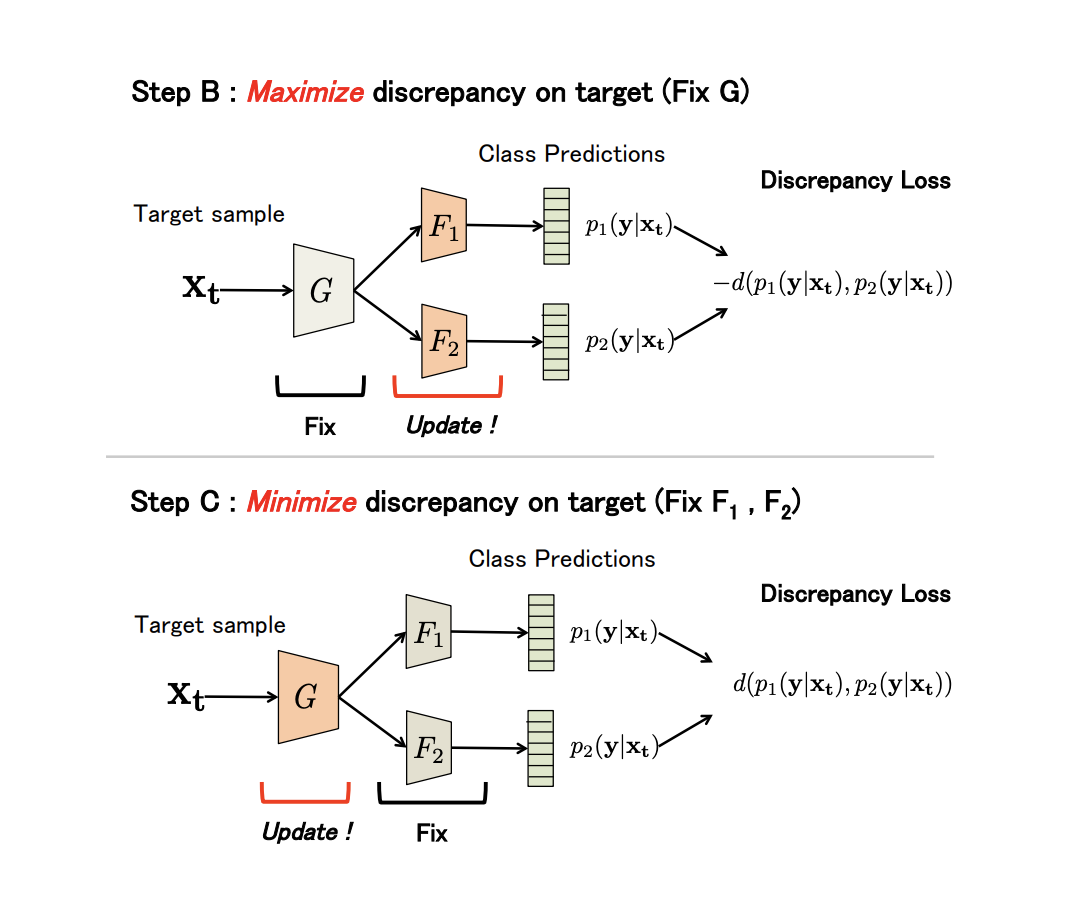
Результаты экспериментов:
- На паре цифровых доменов USPS -> MNIST: 94,1 %.
- На дорожных знаках Synth Signs -> GTSRB метод превосходит все предыдущие: 94,4 %.
- На базе VisDA среднее значение качества по 12 категориям без класса Unknown: 71,9 %.
- На паре GTA 5 -> Cityscapes: Mean IoU = 39,7 %, на Synthia -> Cityscapes: Mean IoU = 37,3 %
Ещё можно обратить внимание на следующие интересные алгоритмы из семейства non-generative models:
На этом пока прервёмся.
Мы рассмотрели основные датасеты для доменной адаптации, discrepancy-based подходы: сlass сriterion, statistical criterion и architecture criterion, а также первое семейство adversarial-based методов — non-generative. Модели из этих подходов неплохо показывают себя на бенчмарках и применимы для многих задач адаптации. В следующей части мы рассмотрим самые сложные и эффективные подходы: generative models и смешанные не adversarial-based методы.
