
 В начале года мы решили научиться хранить и читать отладочные логи ВКонтакте более эффективно, чем раньше. Отладочные логи — это, к примеру, логи конвертации видео (в основном вывод команды ffmpeg и список шагов по предварительной обработке файлов), которые иногда бывают нам нужны лишь спустя 2-3 месяца после обработки проблемного файла.
В начале года мы решили научиться хранить и читать отладочные логи ВКонтакте более эффективно, чем раньше. Отладочные логи — это, к примеру, логи конвертации видео (в основном вывод команды ffmpeg и список шагов по предварительной обработке файлов), которые иногда бывают нам нужны лишь спустя 2-3 месяца после обработки проблемного файла.На тот момент у нас было 2 способа хранения и обработки логов — наш собственный logs engine и rsyslog, которые мы использовали параллельно. Стали рассматривать другие варианты и поняли, что нам вполне подходит ClickHouse от Яндекса — решили его внедрять.
В этой статье я расскажу о том, как мы начали использовать ClickHouse ВКонтакте, на какие грабли при этом наступили, и что такое KittenHouse и LightHouse. Оба продукта выложены в open-source, ссылки в конце статьи.
Задача сбора логов
Требования к системе:
- Хранение сотен терабайт логов.
- Хранение месяцами или (редко) годами.
- Высокая скорость записи.
- Высокая скорость чтения (чтение происходит редко).
- Поддержка индексов.
- Поддержка длинных строк (>4 Кб).
- Простота эксплуатации.
- Компактное хранение.
- Возможность вставки с десятков тысяч серверов (UDP будет плюсом).
Возможные решения
Давайте вкратце перечислим варианты, которые мы рассматривали, и их минусы:
Logs Engine
Наш самописный микросервис для логов.
– Умеет отдавать только последние N строк, которые помещаются в RAM.
– Не очень компактное хранение (нет прозрачного сжатия).
Hadoop
– Не во всех форматах есть индексы.
– Скорость чтения могла быть и выше (зависит от формата).
– Сложность настройки.
– Нет возможности вставки с десятков тысяч серверов (нужна Kafka или аналоги).
Rsyslog + файлы
– Нет индексов.
– Низкая скорость чтения (обычный grep/zgrep).
– Архитектурно не поддерживаются строки >4 Кб, по UDP ещё меньше (1,5 Кб).
± Компактное хранение достигается путем logrotate по крону
Мы использовали rsyslog как запасной вариант для долговременного хранения, но длинные строки обрезались, поэтому его сложно назвать идеальным.
LSD + файлы
– Нет индексов.Отличия от rsyslog в нашем случае в том, что LSD поддерживает длинные строки, но для вставки с десятков тысяч серверов требуются существенные доработки внутреннего протокола, хотя это и можно сделать.
– Низкая скорость чтения (обычный grep/zgrep).
– Не особо расчитан на вставку с десятков тысяч серверов.
± Компактное хранение достигается путем logrotate по крону.
ElasticSearch
– Проблемы с эксплуатацией.ELK стек является уже почти промышленным стандартом для хранения логов. По нашему опыту — всё хорошо со скоростью чтения, а вот с записью бывают проблемы, например, во время слияния индексов.
– Нестабильная запись.
– Нет UDP.
– Плохое сжатие.
ElasticSearch прежде всего предназначен для полнотекстового поиска и относительно частых запросов на чтение. Нам же важнее стабильная запись и возможность более-менее быстро прочитать наши данные, причём по точному совпадению. Индекс у ElasticSearch заточен под полнотекстовый поиск, и занимаемый объём на диске довольно велик по сравнению с gzip оригинального содержимого.
ClickHouse
— Нет UDP.
По большому счёту, единственное, что нас не устраивало в ClickHouse — отсутствие общения по UDP. По факту, из перечисленных вариантов оно было только у rsyslog, но при этом rsyslog не поддерживал длинные строки.
По остальным критериям ClickHouse нам подошел, и мы решили использовать его, а проблемы с транспортом решить в процессе.
Зачем нужен KittenHouse
Как Вы, наверное, знаете, ВКонтакте работает на PHP/KPHP, с «движками» (микросервисами) на C/C++ и немножко на Go. У PHP нет концепции «состояния» между запросами, кроме, возможно, общей памяти и открытых соединений.
Поскольку у нас десятки тысяч серверов, с которых мы хотим иметь возможность отправлять логи в ClickHouse, держать открытым соединения из каждого PHP-worker'а было бы накладно (на каждый сервер может приходиться по 100+ воркеров). Поэтому нам нужен какой-то прокси между ClickHouse и PHP. Мы назвали этот прокси KittenHouse.
KittenHouse, v1
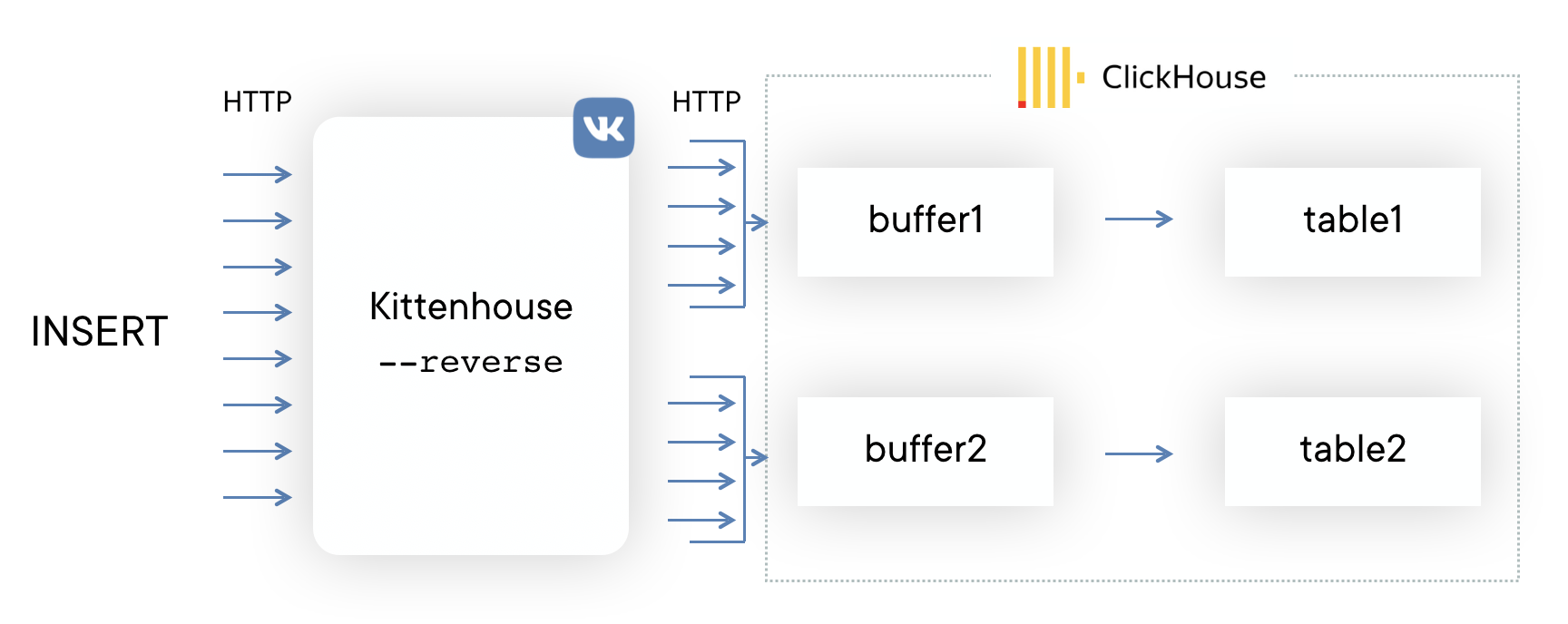
Сначала решили попробовать как можно более простую схему, чтобы понять, будет наш подход работать или нет. Если Вам на ум при решении этой задачи приходит Kafka, то Вы не одиноки. Мы, однако, не хотели использовать дополнительные промежуточные сервера — в этом случае можно было легко упереться в производительность этих серверов, а не самого ClickHouse. К тому же, мы собирали логи и нам нужна была предсказуемая и небольшая задержка вставки данных. Схема выглядит следующим образом:

На каждом из серверов ставится наш локальный прокси (kittenhouse), и каждый инстанс держит строго одно HTTP-соединение с нужным ClickHouse-сервером. Вставка осуществляется в буферные таблицы, поскольку в MergeTree часто вставлять не рекомендуется.
Возможности KittenHouse, v1
Первая версия KittenHouse умела довольно мало, однако для тестов этого было достаточно:
- Общение через наш RPC (TL Scheme).
- Поддержание 1 TCP/IP соединения на сервер.
- Буферизация в памяти по умолчанию, с ограниченным размером буфера (остальное выбрасывается).
- Возможность записи на диск, в этом случае есть гарантия доставки (не менее одного раза).
- Интервал вставки — раз в 2 секунды.
Первые проблемы
С первой проблемой мы столкнулись, когда «погасили» ClickHouse сервер на несколько часов и потом включили обратно. Ниже можно видеть load average на сервере после того, как он «поднялся»:
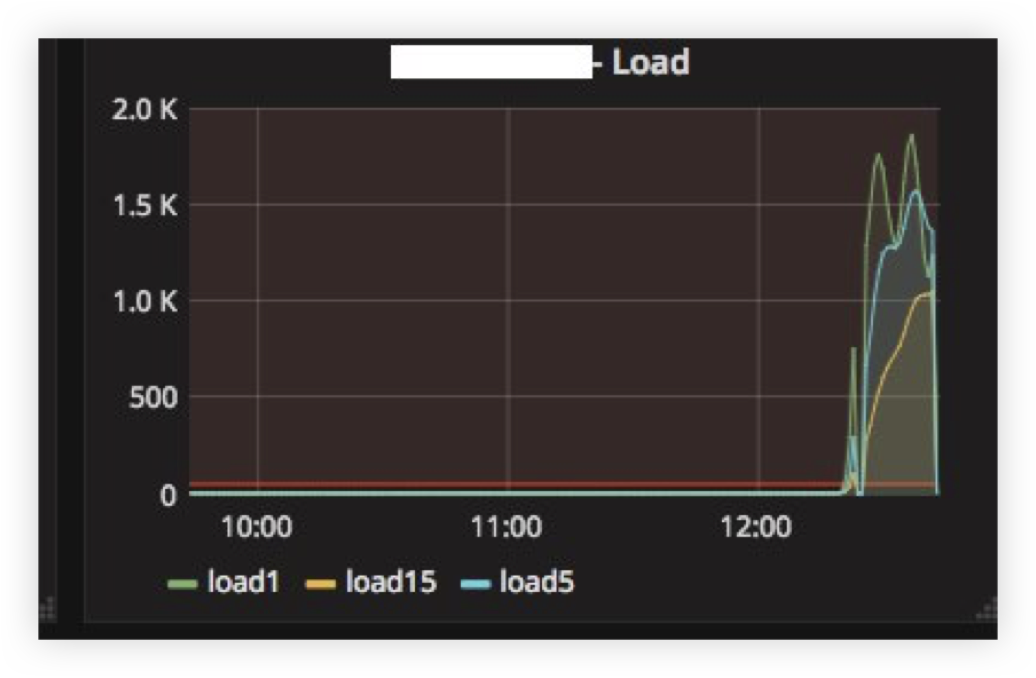
Объясняется это довольно просто: у ClickHouse модель работы по сети — thread per connection, поэтому при попытке сделать INSERT с тысячи узлов одновременно, началась очень сильная конкуренция за ресурсы CPU и сервер еле отвечал. Тем не менее, все данные в конечном счёте вставились и ничего не упало.
Для решения этой проблемы мы поставили nginx перед ClickHouse и, в целом, это помогло.
Дальнейшее развитие
В процессе эксплуатации столкнулись ещё с некоторым количеством проблем, в основном связанных не с ClickHouse, а с нашим способом его эксплуатации. Вот ещё грабли, на которые мы наступили:
Большое количество «кусков» у Buffer таблиц приводит к частым сбросам буфера в MergeTree
В нашем случае было 16 кусков буфера и интервал сброса раз в 2 секунды, а таблиц 20 штук, что давало до 160 вставок в секунду. Это периодически очень плохо сказывалось на производительности вставки — появлялось много фоновых слияний и утилизация дисков достигала 80% и выше.
Решение: увеличили интервал сброса буфера по умолчанию, уменьшили число кусков до 2.
Nginx отдает 502, когда заканчиваются соединения с upstream
Само по себе это не является проблемой, но в сочетании с частым сбросом буфера это давало достаточно высокий фон 502 ошибок при попытке вставки в любую из таблиц, а также при попытке выполнить SELECT.
Решение: написали свою reverse proxy с использованием библиотеки fasthttp, которая группирует вставку по таблицам и очень экономно расходует соединения. Также она различает SELECT и INSERT и имеет раздельные пулы соединений для вставки и для чтения.
Начала заканчиваться память при интенсивной вставке
У библиотеки fasthttp есть свои достоинства и недостатки. Один из недостатков — то, что запрос и ответ полностью буферизуются в памяти перед тем, как отдать управление обработчику запроса. У нас это выливалось в то, что если вставка в ClickHouse «не успевала», то буферы начинали расти и в конечном итоге заканчивалась вся память на сервере, что приводило к убийству reverse proxy по OOM. Коллеги нарисовали демотиватор:

Решение: патчинг fasthttp для поддержки стриминга тела POST-запроса оказался непростой задачей, поэтому решили использовать Hijack() соединения и апгрейдить соединение на свой протокол, если пришел запрос с HTTP-методом KITTEN. Поскольку сервер должен ответить MEOW в ответ, если понимает этот протокол, вся схема называется протоколом KITTEN/MEOW.
Мы читаем только из 50 случайных соединений одновременно, поэтому, благодаря TCP/IP, остальные клиенты «ждут» и мы не расходуем память на буферы, пока до соответствующих клиентов не дошла очередь. Это сократило потребление памяти минимум в 20 раз, и больше подобных проблем у нас не было.
ALTER таблиц может идти долго, если есть долгие запросы
У ClickHouse неблокирующий ALTER — в том смысле, что он не мешает выполняться как SELECT-запросам, так и INSERT-запросам. Но ALTER не может начаться, пока не закончили исполняться запросы в эту таблицу, отправленные до ALTER.
Если у вас на сервере есть фон «долгих» запросов в какие-нибудь таблицы, то вы можете столкнуться с ситуацией, что ALTER на эту таблицу не будет успевать выполняться за дефолтный таймаут в 60 секунд. Но это не значит, что ALTER не пройдет: он выполнится, как только закончат выполняться те самые SELECT-запросы.
Это означает, что вы не знаете, в какой на самом деле момент времени произошел ALTER, и у вас нет возможности автоматически пересоздать Buffer-таблицы, чтобы их схема всегда была одинаковой. Это может приводить к проблемам при вставке.


Решение: Планируем в итоге полностью отказаться от использования буферных таблиц. В целом, у буферных таблиц есть сфера применения, мы пока используем их и не испытываем огромных проблем. Но сейчас мы наконец дошли до момента, когда проще реализовать функциональность буферных таблиц на стороне reverse proxy, чем продолжать мириться с их недостатками. Примерная схема будет выглядеть вот так (пунктирной линией показана асинхронность ACK на INSERT).

Чтение данных
Допустим, мы разобрались со вставкой. Как читать эти логи из ClickHouse? К нашему сожалению, удобных и простых в эксплуатации инструментов для чтения сырых данных (без построения графиков и прочего) из ClickHouse мы не нашли, поэтому написали своё решение — LightHouse. Его возможности довольно скромные:
- Быстрый просмотр содержимого таблиц.
- Фильтрация, сортировка.
- Редактирование SQL-запроса.
- Просмотр структуры таблицы.
- Показ примерного количества строк и занимаемого на диске места.
Однако, LightHouse быстрый и умеет делать то, что нужно именно нам. Вот пара скриншотов:
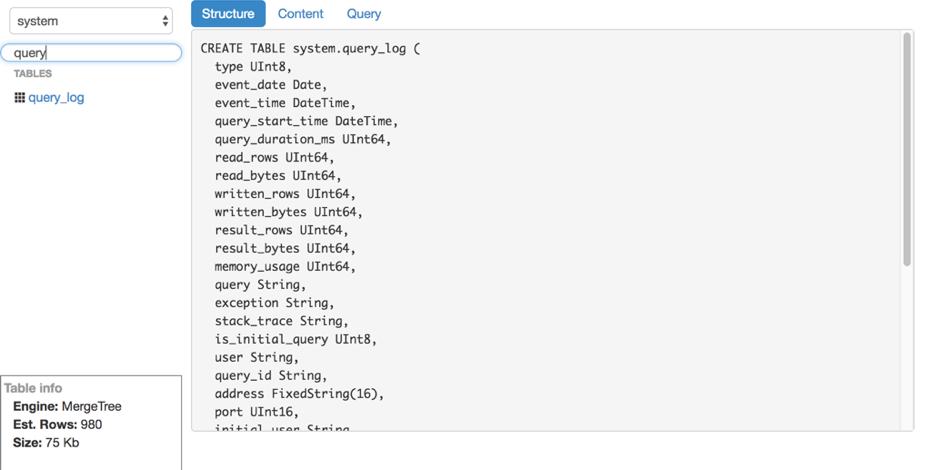
Просмотр структуры таблицы
Фильтрация содержимого

Результаты
ClickHouse — практически единственная open-source база данных, которая «прижилась» ВКонтакте. Мы довольны скоростью её работы и готовы мириться с недостатками, о которых ниже.
Сложности в работе
В целом, ClickHouse — очень стабильная база данных и очень быстрая. Однако, как и с любым продуктом, особенно таким молодым, есть особенности в работе, которые нужно учитывать:
- Не все версии одинаково стабильны: не обновляйтесь на продакшене сразу на новую версию, лучше подождать несколько bugfix-релизов.
- Для оптимальной производительности крайне желательно настраивать RAID и некоторые другие вещи согласно инструкциям. Об этом недавно был доклад на highload.
- Репликация не имеет встроенных ограничений по скорости и может вызывать существенную деградацию производительности сервера, если её не ограничивать самим (но это обещают исправить).
- В Linux есть неприятная особенность механизма работы виртуальной памяти: если вы активно пишете на диск и данные не успевают сбрасываться, в какой-то момент сервер полностью «уходит в себя», начинает активно сбрасывать page cache на диск и практически полностью блокирует процесс ClickHouse. Это иногда происходит при больших мержах, и за этим нужно следить, например периодически сбрасывать буферы самим или делать sync.
Open-source
KittenHouse и LightHouse теперь доступны в open-source в нашем github-репозитории:
- KittenHouse: github.com/vkcom/kittenhouse
- LightHouse: github.com/vkcom/lighthouse
Спасибо!
Юрий Насретдинов, разработчик в отделе backend-инфраструктуры ВКонтакте
