Комментарии 5
Хотелось бы посмотреть последние четыре графика с более точной детализацией, как у синих вначале. Такое ощущение, что значение списка
years осталось урезанным после построения бар чартов.Оставил это в качестве тренировки, всем кому интересна эта тема) Можете добавить свои варианты кода в комментарии. Я добавлю свой код, если так и не появятся хорошие предложения
Код так никто и не написал. Поэтому прилагаю свой вариант:
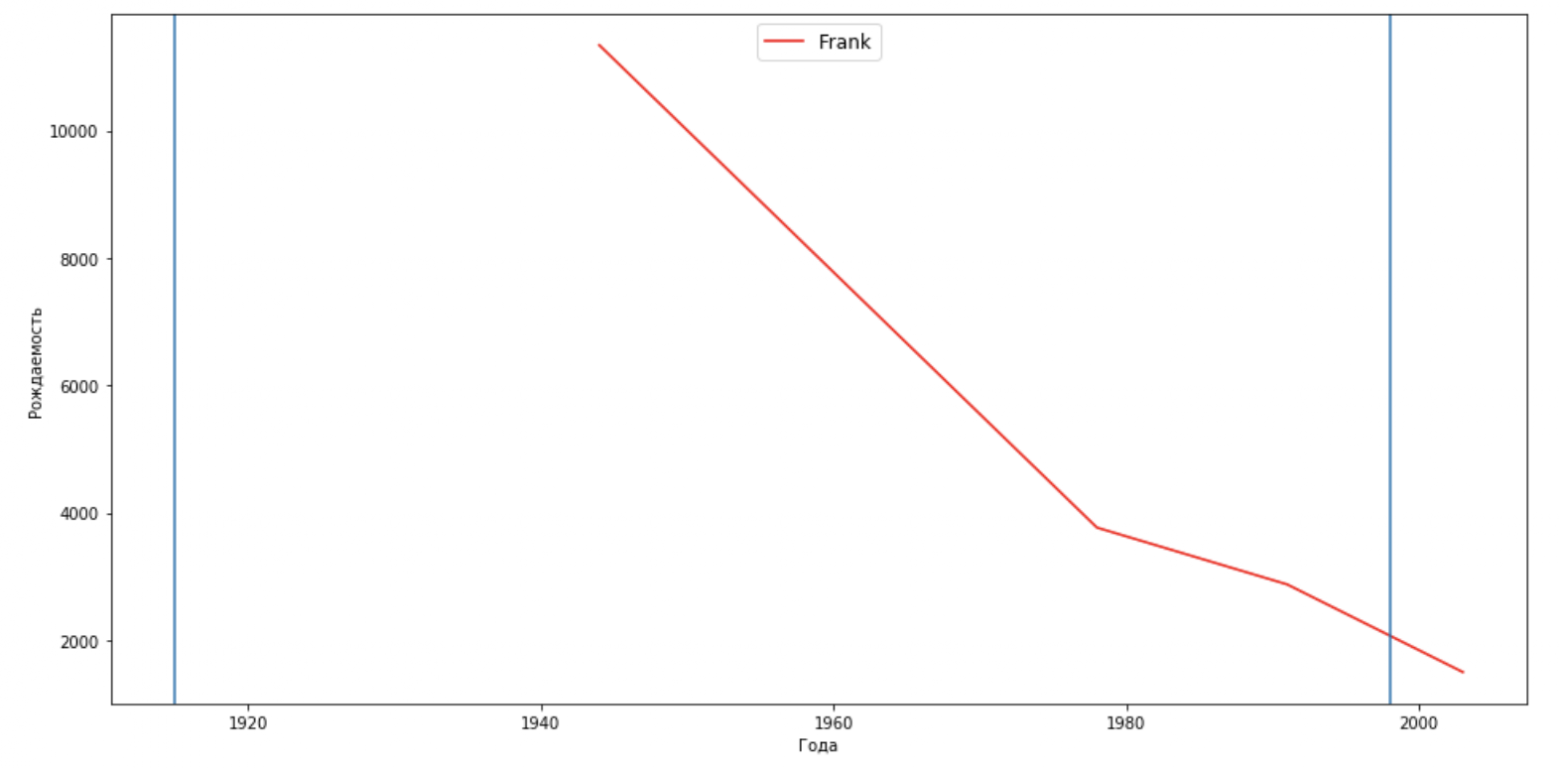

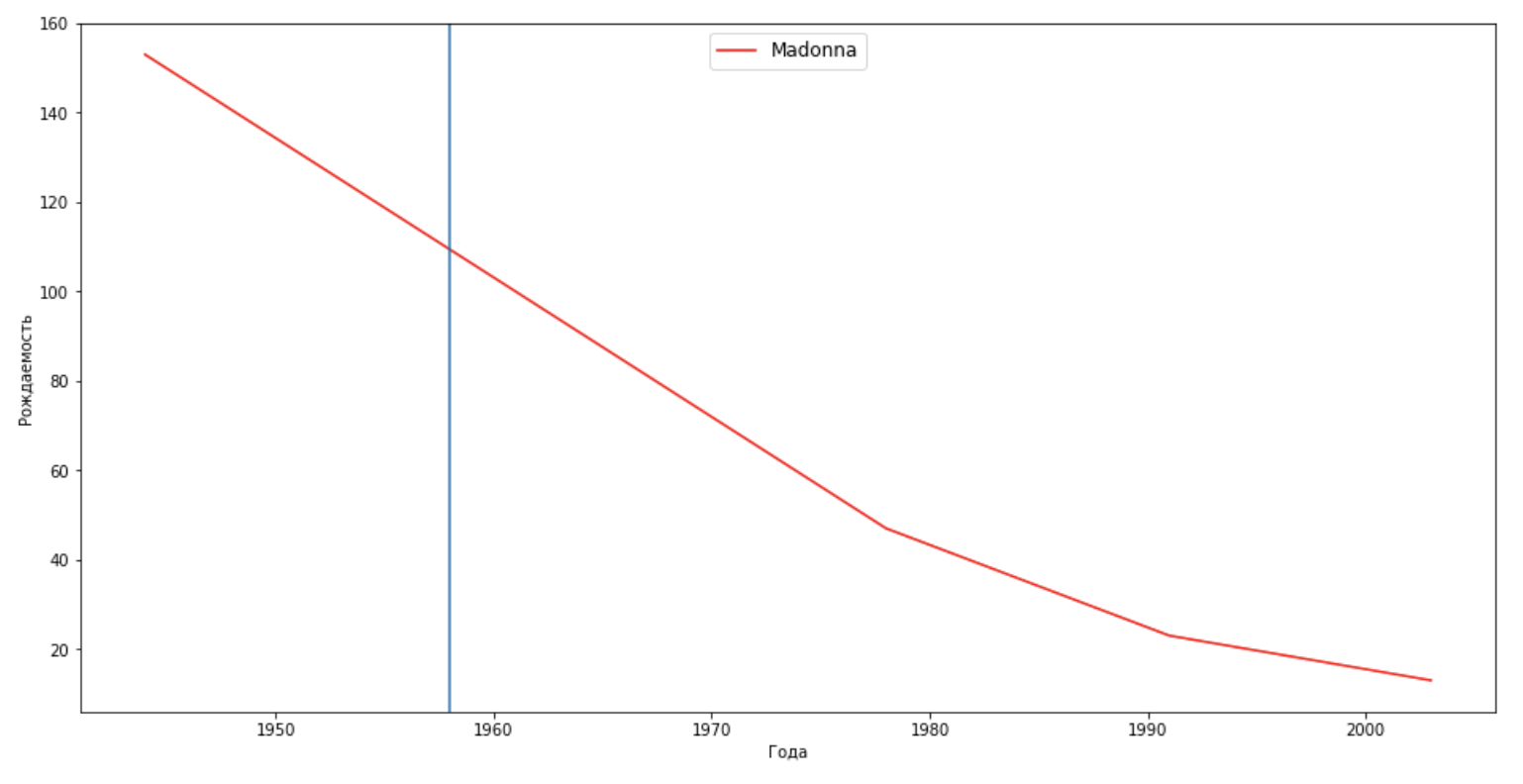
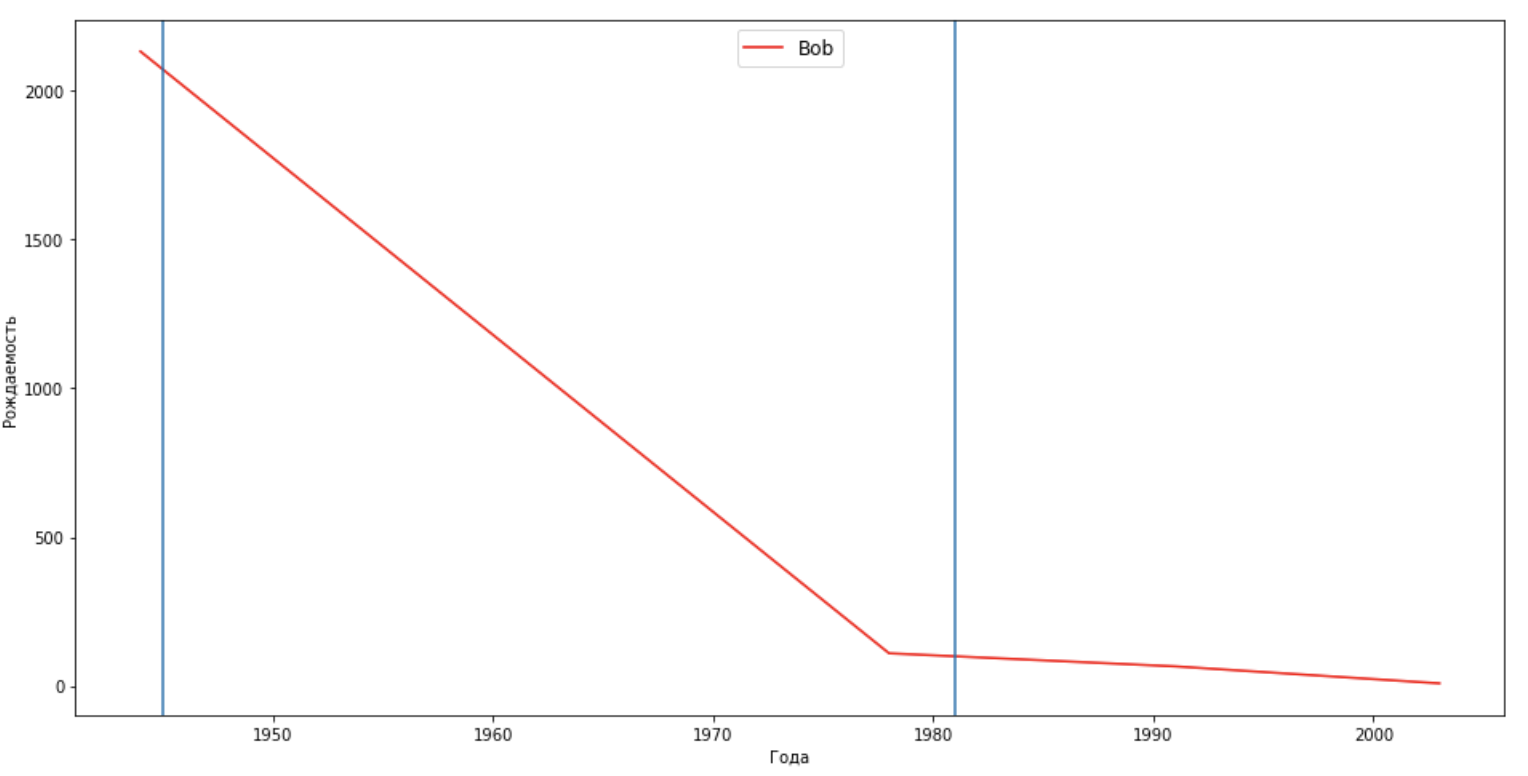
celebritiesFrank = {'Frank': 'M'}
celebritiesBritney = {'Britney': 'F'}
celebritiesMadonna = {'Madonna': 'F'}
celebritiesBob = {'Bob': 'M'}
dataframes = []
for year in years:
dataset = datalist.format(year=year)
dataframe = pd.read_csv(dataset, names=['name', 'sex', 'count'])
dataframes.append(dataframe.assign(year=year))
result = pd.concat(dataframes)
for celebrity, sex in celebritiesFrank.items():
names = result[result.name == celebrity]
dataframe = names[names.sex == sex]
fig, ax = plt.subplots(1, 1, figsize=(16,8))
ax.set_xlabel('Года', fontsize = 10)
ax.set_ylabel('Рождаемость', fontsize = 10)
ax.plot(dataframe['year'], dataframe['count'], label=celebrity, color='r', ls='-')
ax.legend(loc=9, fontsize=12)
plt.axvline(x=1915)
plt.axvline(x=1998)
for celebrity, sex in celebritiesBritney.items():
names = result[result.name == celebrity]
dataframe = names[names.sex == sex]
fig, ax = plt.subplots(1, 1, figsize=(16,8))
ax.set_xlabel('Года', fontsize = 10)
ax.set_ylabel('Рождаемость', fontsize = 10)
ax.plot(dataframe['year'], dataframe['count'], label=celebrity, color='r', ls='-')
ax.legend(loc=9, fontsize=12)
plt.axvline(x=1981)
for celebrity, sex in celebritiesMadonna.items():
names = result[result.name == celebrity]
dataframe = names[names.sex == sex]
fig, ax = plt.subplots(1, 1, figsize=(16,8))
ax.set_xlabel('Года', fontsize = 10)
ax.set_ylabel('Рождаемость', fontsize = 10)
ax.plot(dataframe['year'], dataframe['count'], label=celebrity, color='r', ls='-')
ax.legend(loc=9, fontsize=12)
plt.axvline(x=1958)
for celebrity, sex in celebritiesBob.items():
names = result[result.name == celebrity]
dataframe = names[names.sex == sex]
fig, ax = plt.subplots(1, 1, figsize=(16,8))
ax.set_xlabel('Года', fontsize = 10)
ax.set_ylabel('Рождаемость', fontsize = 10)
ax.plot(dataframe['year'], dataframe['count'], label=celebrity, color='r', ls='-')
ax.legend(loc=9, fontsize=12)
plt.axvline(x=1945)
plt.axvline(x=1981)
plt.show()




Подскажу инструмент — seaborn. Часть группировок можно смело перенести на его стандартные средства. Ну и графики выглядят приятнее для глаза.
Плюсую за seaborn, ну и конечно plotly — за интерактивность графиков, с возможностью их масштабирования.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Прорабатываем навык использования группировки и визуализации данных в Python