
На протяжении всей жизни мне приходится экономить вычислительные и сетевые ресурсы: сначала были компьютеры с 300 кГц (кило — не гига!) и 32 Кбайт RAM, интернет по dial-up. Потом я решал олимпиадные задачки. Теперь имею дело с терабайтами трафика и 50 млрд событий в сутки. И хотя современные телефоны в 1 000 раз мощнее любого оборудования двадцатилетней давности, я до сих пор оптимизирую. Думал даже, что это со мной что-то не так. Но потом понял, что все постоянно что-нибудь оптимизируют.

Эта статья в меньшей степени о том, почему нужно бороться за производительность, и в большей о том, на что сейчас стоит заменить устаревший стек из JPEG, JSON, gzip и TCP — и как это сделать.
Спойлер: у нас есть решение и мы его не только показываем — ссылки на open source в конце статьи.
Примечание: в основе статьи доклад на Saint HighLoad++ — вместо чтения можно посмотреть запись выступления.
Зачем вообще что-то ускорять?
Исследования уважаемых компаний показывают, что лишние 100 мс задержки ощутимо просаживают продуктовые метрики — и отрицательный эффект со временем становится всё заметнее.
По данным Amazon:
10 лет назад с каждыми 100 мс задержки конверсия падала на 1%;
5 лет назад с каждыми 100 мс задержки продажи падали уже на 7%.
Google говорит:
15 лет назад лишние 400 мс задержки уменьшали трафик на 20%;
5 лет назад, если Largest Contentful Paint (LCP) уменьшалось на 300 мс, то это давало +12% к вовлечённости и +9% к просмотрам.
Deloitte заявляет, что ускорение времени загрузки страницы на 100 мс может увеличить конверсию на 8%.
Всего одна десятая секунды — и такие результаты. Но давайте посмотрим, что такое эти 100 мс с когнитивной точки зрения:
за 13 мс человеческий мозг способен уловить изображение, то есть при FPS меньше 77 можно заметить «эффект 25-го кадра»;
за 100 мс — разобрать, что изображение означает;
за 150 мс (в среднем) обработать изображение и как-то среагировать;
за 17–50 мс мозг способен сформировать эстетическую реакцию на веб-страницу, говорят исследователи UX YouTube.
В этой статье условимся, что «быстро» — это меньше 100 мс.
В рекомендациях по созданию веб-сайтов 100 мс — это хорошее значение для показателя интерактивности. Но некоторые другие величины всё ещё измеряются в секундах, то есть в реальном мире контент грузится целые секунды. Мы все далеки от идеала в 100 мс, и у нас впереди ещё много работы.

Конечно, и мы ВКонтакте боремся за каждые 100 мс отдачи контента, отрисовки страниц, старта приложений и других операций.
Что ускорять?
Чтобы понять, где можно добиться максимального эффекта, вспомним, как устроены почти все интернет-сервисы. Базово их можно описать примерно так:

На уровне логики и клиентов интернет-сервис может работать очень быстро, если вы хорошо написали код, — поэтому на схеме блоки выделены зелёным. Скорость обращения к оперативной памяти или SSD напрямую зависит от качества кода: она в вашей власти, её можно оптимизировать понятными способами.
Работа с данными обычно чуть медленнее, но базы данных и системы хранения всё эффективнее в обращении к дискам, кешировании и прочем. Так что блок оранжевый: при должных разумных усилиях latency здесь порядка 10–30 мс и неплохо предсказуема.
Самый медленный и самый сложный для оптимизации уровень — сетевой. Разработчики редко до него добираются: чтобы что-то оптимизировать на сетевом уровне, нужно оптимизировать и бэкенд, и клиент — и выкатывать это одновременно.

При этом в «Latency numbers every programmer should know» на сеть отводится гораздо больше, чем на все остальные операции, вместе взятые, — 150 мс. 150 мс — это каждый round-trip на другой континент. Если ваши пользователи и серверы находятся на разных континентах, то latency всего вашего сервиса точно больше 150 мс. Это, как мы выяснили, уже создаёт ощущение, будто что-то тормозит.
Какие у нас сети и зачем их оптимизировать
Мы помним, что «преждевременная оптимизация — корень всех бед». Перед тем как оптимизировать, нужно остановиться и подумать: зачем что-то ускорять, если за последние 20 лет пропускная способность интернет-сети стала больше в 1 000 раз.

Это всё так. Но давайте посмотрим, как в последнее время изменились другие характеристики сети, в частности round-trip time (RTT).
Если верить ребятам, которые в 2001 году замерили пинг от Сан-Диего до всех точек мира и показали результаты на IEEE Telecommunications Symposium, то в пределах одного побережья тогда пинг был около 25 мс, до другого — в среднем 100 мс, на любой другой континент — около 200 мс.

Спасибо сервису RIPE Atlas: в 2021 году я нашёл дата-центр в Сан-Диего и попинговал его со всего мира. Прошло 20 лет, а что изменилось?

За 20 лет мы ускорились не в 1 000 раз, а всего на треть.
Трейдерские компании готовы потратить 300 млн долларов, чтобы проложить новый кабель по дну океана и получать данные на 6 мс быстрее. Почему? Потому что нас ограничивает скорость света: на ней облететь экватор Земли займёт 134 мс — и ни миллисекундой быстрее. RTT сейчас уже близок к скорости света, и пока никто не знает, как её преодолеть, ожидать серьёзных изменений в RTT не приходится.
Я также протестировал, какой пинг у всего мира до сервисов ВКонтакте (в условиях без участия CDN и кешируемого контента).

Если смотреть со всего мира, то 90-й перцентиль будет равен 300 мс. То есть пинг в 200 мс — это повседневная реальность. Из Петропавловска-Камчатского, например, пинг меньше 150 мс не бывает.
Mobile first
Мы живём в век преобладания мобильных устройств, и это обязывает нас учитывать ещё одну важную характеристику — процент потерянных пакетов. В беспроводных сетях они теряются легче: для 4G и Wi-Fi packet loss составляет примерно 0,1–0,5%. Это не очень много, но так как 92% аудитории ВКонтакте использует мобильные, нам нужно уметь с этим работать.

К тому же утверждение, что «скоро везде будет 5G» — сильное преувеличение. Ниже карта покрытия 3G-интернета в России. 4G ещё меньше.

В крупных городах мы привыкли, что почти везде есть 4G. Но на самом деле даже 3G есть далеко не везде — и его уже недостаточно для быстрой работы многим сервисам.
Чаще всего мы проверяем скорость работы наших сервисов, сидя в московских и питерских офисах. С проводным интернетом и находясь близко к дата-центру, мы видим действительно хорошие цифры и думаем, что всё всегда работает быстро. Но если взять Петропавловск-Камчатский, то картина, например, по доставке изображений изменится.

В Москве и Санкт-Петербурге у нас 25-й перцентиль времени появления картинок 78 мс, 75-й перцентиль — 428 мс. На Дальнем Востоке P25 — 238 мс, P75 — 939 мс. То есть четверть пользователей ВКонтакте замечают задержку до появления изображений.
Поэтому рекомендую: настройте себе на рабочем месте сеть с профилем, как в Петропавловске-Камчатском, и попользуйтесь своим сервисом так хотя бы один день — обязательно заметите что-нибудь интересное.
Что оптимизировать?
Теперь, когда мы выяснили, что у части нашей аудитории приложения работают не так быстро, как хотелось бы, давайте посмотрим, что можно оптимизировать.
Обычный стек (таким был и стек ВКонтакте до недавнего времени) включает в себя:
доставку изображений — JPEG в качестве графического формата, HTTP 1.1/2.0 на прикладном уровне и TCP на транспортном;
web — те же TCP/IP, HTTP 1.1/2.0 плюс gzip и deflate;
API/RPC — снова TCP/IP, HTTP 1.1/2.0 и WebSocket, а главное, JSON в API мобильных клиентов.
Плохая новость: этот стек устарел.

Это всё довольно старые протоколы. Нельзя сказать, что они не развиваются, но прогресс не стоит на месте и на всех уровнях появляются новые решения.
Порядка двух лет назад мы начали отказываться от legacy-форматов и стека в пользу чего-то более производительного. Дальше расскажу, на что перешли и какие результаты это принесло.
Изображения, или Как отказаться от JPEG
Среди всех типов контента у наших пользователей больше всего востребованы картинки: на них уходит больше 1 Тбит/с трафика. Поэтому начнём именно с изображений и посмотрим, на что можно заменить JPEG.
На рынке форматов изображений конкурируют Google и Apple, которые предлагают разные интересные алгоритмические решения для сжатия.

Google выигрывает по распространённости за счёт своего большого стека, браузеров и массовости использования Android. Поэтому мы в данном случае выбираем стек от Google.
Между WebP и AVIF выбираем WebP, несмотря на то что он без потери качества сжимает на 30% эффективнее, чем JPEG, а AVIF на целых 50%. Потому что WebP поддерживается у 98% пользователей, а AVIF пока только у 50% (см. подробное сравнение WebP и AVIF).
Каждый следующий новый формат сжатия требует больше вычислительных ресурсов и на 20–40% уменьшает размер данных. Поэтому нужно наращивать мощности и всё равно сохранить JPEG для фолбэка.
Соответственно, нужно пережать хранящиеся фотографии из JPEG в WebP. Но есть проблема: у нас больше 600 Пбайт изображений, которые пользователи запрашивают примерно миллион раз в секунду. У этой задачи два варианта решения: либо увеличить в два раза storage, либо научиться пережимать изображения на лету и очень быстро.

Кеширование помогло нам снизить показатель RPS с 1 млн до 160 тысяч. Немного легче, но 160 тысяч фотографий в секунду всё равно нужно как-то перекодировать, причём желательно подгоняя под разрешение экрана. Этим занимается небольшой кластер из GPU и FPGA.
FPGA от Intel — это специальное программируемое полупроводниковое устройство, которое может, например, обрабатывать 1 000 фотографий в секунду. Оно больше подходит нам с точки зрения производительности для IMP-задач, чем GPU. Мы постепенно увеличиваем количество используемых FPGA в кластере, чтобы пользователи получали фотографии в самом современном формате.
Результат перехода с JPEG на WebP:
на 40% в среднем уменьшили размер фотографий;
на 15% сократили время доставки изображений, это 50–100 мс в зависимости от региона;
на 1,1% вырос просмотр этих фотографий, что схоже с данными Amazon;
на 1,3% в пике увеличилось количество смотрящих уникальных пользователей.
API, или Как отказаться от JSON и gzip
Окрылённые успехом оптимизации изображений, мы взялись за API.
Во-первых, сменили формат представления данных. JSON, конечно, очень удобный и human-readable, но есть более современные решения, например: BSON, CBOR, MessagePack.
Мы установили следующие требования к новому формату представления данных:
бинарный;
быстрый (с поддержкой Zero-copy);
без схемы;
поддерживаются существующие в JSON типы для конвертации.
Выбрали MessagePack, ускорились на 46% относительно JSON, стали компактнее.
Во-вторых, заменили классический gzip для сжатия на zstd со словарём (см. исследование форматов сжатия). Учитывая, что алгоритм сжатия у нас должен справляться с более чем 100 Гбит/с трафика и 1,5 млн/с запросов, для нас очень важна производительность.

Есть более эффективные алгоритмы сжатия и можно настроить zstd на больший уровень компрессии, но в определённой точке это начинает расходовать слишком много ресурсов. Тогда сжатие занимает больше времени, чем передача данных по сети.
Результат перехода с gzip (JSON) на zstd (msgpack):
в 7 раз быстрее сжатие (–1 мкс);
на 10% меньше размер данных (8 Кбайт вместо 9 Кбайт);
продуктовый эффект не статзначимый :(
А ещё на вебе для сжатия старый добрый gzip или примерно такой же алгоритм deflate можно заменить на brotli.

Он очень эффективен для статики, но для остальных страниц результаты спорные. На малых запросах brotli может не уменьшать количество передаваемых пакетов — поэтому, как всегда, надо смотреть, сколько потребуется ресурсов и будет ли это иметь смысл.
На вебе мы используем brotli для статики, для динамики у нас по-прежнему gzip.
QUIC, или Как отказаться от TCP
И самое сложное и важное в этой статье — отказаться от ТСР-стека и полностью перевести ВКонтакте на QUIC и HTTP/3.
Напомню минимум теории: чем отличаются HTTP/2 и HTTP/3 и что такое QUIC.
Классический стек — это HTTP/2, TLS, TCP, IP. Минимум половина участников Saint HighLoad++ используют именно его в своих приложениях.

Альтернативное решение — HTTP/3. QUIC — это протокол поверх UDP, который реализует всё то же самое, что было в TCP, инкапсулирует в себе TLS, но лучше. Если поверх QUIC запустить HTTP/2, получится HTTP/3.
Данные по QUIC передаются быстрее, особенно в плохой сети, потому что в QUIC есть:
Zero-RTT — возможность отправить запрос сразу, без долгих handshake и acknowledgement;
Multiplexing — передача нескольких потоков в одном соединении;
IP Migration — смена IP-адреса, например, при переключении с мобильного интернета на Wi-Fi, происходит прозрачно (на TCP это может занять секунд 30);
User Space implementation — это означает, что протокол не встроен в операционную систему, каждое приложение может иметь свою реализацию на клиенте;
Congestion control — чтобы понять, что это и как влияет на скорость передачи данных, погрузимся глубже в устройство сетевого слоя.
DeepDive на сетевой уровень
Пойдём снизу вверх и разберём, что происходит в маршрутизаторах. А как это реализуется с точки зрения сетевого стека, рассмотрим в отдельной статье.

Чтобы перестать думать о сети как о чёрном ящике, и понять, как она вообще работает, давайте представим: дата-центр, в котором серверы соединены с внешним миром интерфейсами в 100 Гбит/с; домашнего провайдера с оптикой на 1 Гбит/с; и пользователя, заплатившего за 30 Мбит/с.

Во-первых, конечно, сервер 100 Гбит/с на пользователя не шлёт. Во-вторых, ему нужно как-то узнать, что у пользователя интернет в 30 Мбит/с. Как нашему серверу это сделать? Сейчас разберёмся.
Проведём эксперимент: запустим speed test и с помощью Wireshark или сетевого профайлера посмотрим на пропускную способность.

На старте теста пропускная способность высокая, а потом стабилизируется на каком-то значении. Это та пропускная способность, за которую вы как конечный пользователь заплатили — и которую провайдеру нужно как-то ограничить, чтобы вы не перегрузили ему всю сеть.

Реализуется это ограничение следующим образом: у вас есть какая-то корзина токенов, которая наполняется со скоростью 30 Мбит/с; корзина имеет определённый размер. Когда вы в первый раз приходите за токенами (на старте теста), корзина полная — все токены можно забрать быстро. Но потом корзина пустеет, и дальше сеть уже работает в рамках корзины — например, тех самых купленных 30 Мбит/с.

Запустив speed test, можно аккуратно измерить размер этой корзины — например, мне провайдер даёт 4 Мбайта.

То есть первые 4 Мбайта данных я получаю на максимальной скорости — сайт, на который я захожу, открывается быстро. И только потом провайдер ограничивает пропускную способность, чтобы я не занял весь канал скачиванием какого-нибудь тяжёлого контента. В целом это очень удобно, потому что и интернет кажется быстрым, и ограничение выполняется.
Но есть проблема: ни клиент, ни сервер не знают о пропускной способности — только провайдер знает про корзину и ограничения на её размер.

Поэтому на клиенте есть congestion avoidance — алгоритмы, подстраивающие интенсивность отправки пакетов данных под пропускную способность. Раньше он был в ядре, а теперь — на клиенте. Грубо говоря, с помощью congestion avoidance клиент постепенно увеличивает скорость отправки пакетов, пока не происходит packet drop.

В этот момент в Wireshark можно увидеть DUP ACK (duplicate acknowledgements) — значит, корзина кончилась и оператор решил, что вы вышли за отведённую вам пропускную способность.
Есть разные алгоритмы congestion avoidance, но обычно они действуют примерно следующим образом:
начинают с совсем небольшого количества отправляемых пакетов и постепенно его удваивают — это slow start на схеме ниже;
дойдя до значения, близкого к тому, на котором в прошлый запуск произошёл перегруз маршрутизатора, выходят на плато и увеличивают количество пакетов совсем по чуть-чуть — это как раз стадия congestion avoidance;
потом маршрутизатор таки перегружается и пакет теряется — packet loss на схеме;
всё повторяется сначала, количество пакетов снова постепенно наращивается.

При этом обратите внимание, что интервал между пиками составляет 100–200 мс. Потому что speed test ходит на сервер, который расположен близко к пользователю, и фидбэк о пропаже пакета приходит очень быстро.
На маршрутизаторе тоже есть congestion avoidance. В простом варианте он просто дропает лишние пакеты — это называется TailDrop. А может быть чуть умнее и учитывать, что алгоритмы congestion avoidance на клиентах снизят скорость, если маршрутизатор дропнет пакеты. Алгоритмы RED/WRED, когда приближается перегрузка маршрутизатора, дропают случайные пакеты. Чтобы те, кто сидит на этом канале, увидели packet loss и снизили скорость.

RED/WRED даёт более честное распределение канала связи, чем TailDrop. С TailDrop, если вы пришли последними на перегруженный маршрутизатор, то вам ничего не досталось и все пакеты пропали.
Чтобы делить полосу ещё честнее, можно сделать больше сетевой буфер. Буфер гасит бёрсты (burst) и позволяет лучше утилизировать канал. Но если сделать слишком большой буфер, случится bufferbloat — пакеты в буфере будут находиться слишком долго и вырастет задержка.
Посмотрим на примере: попингуем vk.com, измерим задержку и посмотрим, есть ли bufferbloat и какого размера буфер у моего маршрутизатора. Этот тест я проводил в Питере, и пинг до сервера был порядка 2–3 мс (первые строчки на скриншоте ниже). Параллельно я запустил speed test и утилизировал весь канал — пинг начал расти.

Параллельный поток заполнил все буферы внутри оператора, и пинг вырос. Разница между максимальным и минимальным пингом позволяет примерно оценить размер буфера. У меня получилось 840 Кбайт, то есть, скорее всего, часть пакетов RED/WRED дропает заранее и оператор мне как пользователю даёт буфер в 1 Мбайт.
Что интересно, если провести speed test на 4G-интернете, то пиков не будет. На 4G нет пиков — нет token bucket.

Скорость мобильного интернета ограничивается по-другому — скорее, средой пропускания. Динамика передачи пакетов несколько другая, но периодический packet drop всё равно есть.
А ещё нужно учитывать, что в сети бывают микробёрсты. Они возникают, когда суммарная пропускная способность нескольких каналов, входящих в маршрутизатор, меньше, чем исходящая. С одной стороны, это даёт хорошую утилизацию канала, с другой — исходящего канала просто не хватает. Получаются те самые микробёрсты, которых не видно на графике скорости.

Итого на сетевом уровне: есть элементы с предсказуемым влиянием — token bucket и congestion avoidance, а есть непредсказуемая часть вроде bufferbloat и microburst.
Добавим RTT
А теперь давайте представим, что сервер немного дальше от клиента — буквально на 100 мс. Посмотрим, что станет с пропускной способностью.

От 30 Мбит/с осталось только 3 Мбит/с. И это притом, что дополнительные 100 мс RTT — это пока внутри одного континента, то есть ещё не сервер с другого полушария.
Если посмотреть внимательнее, то окажется, что сервис на скачивание отработал хорошо, а на загрузку плохо.

Так произошло, потому что у сервиса, с которого speed test скачивает данные, чтобы измерить скорость, хорошо настроен сетевой стек и RTT особо не повлиял. А вот на моём устройстве стек настроен абы как, congestion control не смог адаптироваться, канал простаивал, скорость загрузки просела.
На графике справа, как и в примерах до этого, видно: скорость увеличивается, происходит потеря пакета, маршрутизатор восстанавливается, пакеты отправляются с минимальной скоростью, которая постепенно увеличивается. То, как быстро она будет расти, зависит от времени подтверждения сервером, что пакет доставлен. Чем дальше сервер, тем медленнее увеличивается скорость отправки пакетов, — скорость адаптации зависит от RTT.

И чем больше RTT, тем ниже утилизация канала. С увеличением пинга на 100 мс скорость будет падать примерно в два раза — это верно и для кабельного интернета, и для мобильного.
Справиться с влиянием RTT раз и навсегда можно, только если всем пользователям поставить свои серверы прямо дома. Пока мы не можем так сделать, нужно иметь в виду, что:
с RTT трудно бороться, он определяется расстоянием и скоростью света;
в сети есть ограничения по скорости (от провайдеров) — вы изначально не знаете этих значений и можете определить их только примерно, чтобы как-то использовать, посылая контент пользователям;
полностью утилизировать канал трудно, в том числе из-за RTT.
Но, может быть, можно построить такой алгоритм congestion control, который смог бы полностью утилизировать пропускную способность канала связи?
В поисках идеального congestion control
Со стандартным congestion control (CC) пропускная способность сети утилизируется, как на графике слева. А мы хотели бы, чтобы было, как справа: когда мы можем точно знать пропускную способность и сразу использовать её по максимуму.
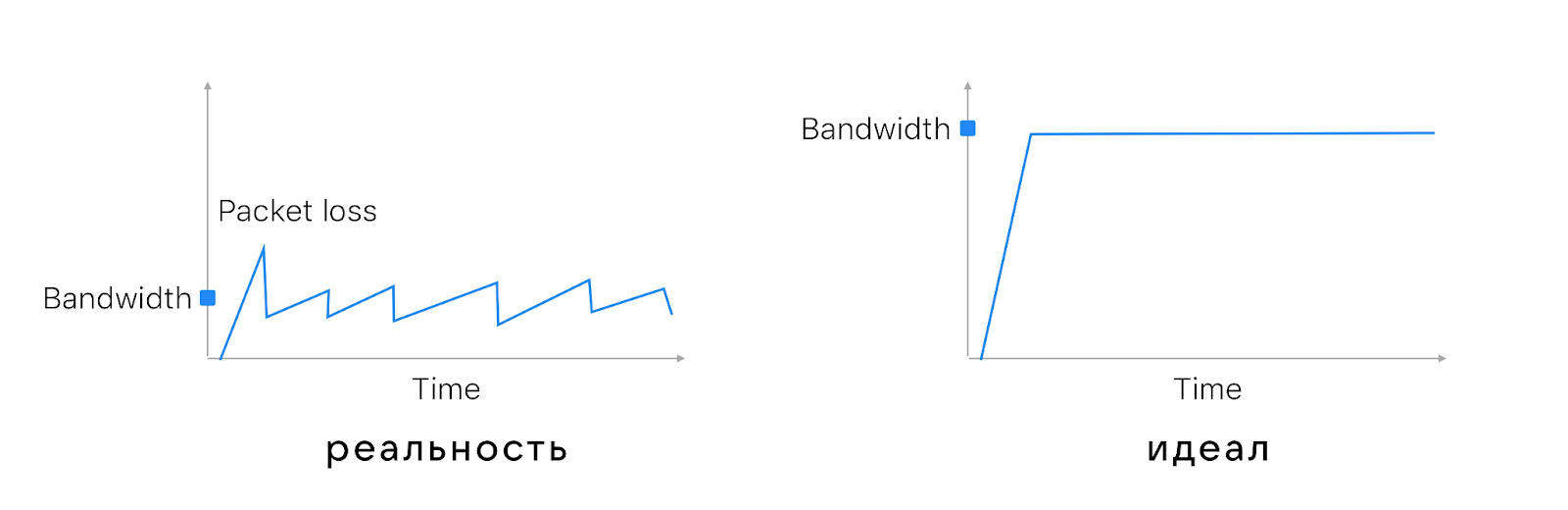
Такие сongestion сontrol тоже есть. Кроме старых классических Loss based CC, например Cubic и Reno, которые смотрят на пропажу пакетов в маршрутизаторе, бывают Delay based CC.

Современные алгоритмы сongestion сontrol, например BBR, смотрят на время задержки: если в маршрутизаторе растёт очередь пакетов, значит, где-то что-то перегружено и нужно снизить нагрузку. Кажется, это хорошая стратегия.

На графике задержки от времени BBR выглядит отлично. Он вообще не перегружает маршрутизатор, и задержки не растут. А вот Cubic перегружает маршрутизатор, очередь переполняется, пакеты пропадают, скорость падает, восстанавливается и так далее.
Но вот что будет, если канал начнут делить клиенты с BBR и Cubic.

Если один человек смотрит видео в сервисе, у которого в качестве congestion-control алгоритма используется Cubic, а второй по этому же каналу приходит посмотреть видео в сервисе с BBR, то он забирает себе всю полосу.
Да, распределение перегруженной сети между пользователями случается нечасто. Но если оно произошло, то ни один congestion control не обеспечит честное (fair) деление. Например, потому что тот, кто ближе к серверу, адаптируется быстрее и лучше утилизирует сеть.
Итого, что нужно запомнить о congestion control:
все СС не fair;
чем более продвинутый у сервиса СС, тем быстрее адаптация, лучше утилизация канала — и тем чаще он выигрывает конкуренцию за сеть; сервисам с более медленной адаптацией достаётся меньше пропускной способности, они работают медленнее;
BBR настолько не fair к другим CC, что IETF попросил Google убрать его и сделать BBR2 (не забудьте обновить на серверах).

BBR2 по-прежнему лучше утилизирует полосу, чем Cubic, и более fair. Мы когда-нибудь перейдём на BBR2, но пока не успели.
Однозначно выбрать лучший CC нельзя. Вы можете изучить тонну чужих исследований на эту тему и попытаться следовать, например, таким схемам:

Но на самом деле всё будет зависеть от ваших клиентов, от того, какие устройства у ваших пользователей, от творящегося внутри «сетевого ада» и прочего. Поэтому любой congestion control нужно проверять по A/B.
Мы ВКонтакте используем: QUIC NewReno для API, фото и статики; TCP BBR для стриминга, потому что пока по A/B это даёт лучшие результаты.
QUIC быстрее, потому что:
New Reno QUIC != Reno TCP;
BBR QUIC != BBR TCP;
QUIC лучше TCP утилизирует полосу. ACK в QUIC устраняет неоднозначность, точнее оценивается RTT и полоса пропускания;
QUIC не fair к TCP в 2 раза.
Forward Error Correction
QUIC позволяет реализовать превентивное исправление ошибок — Forward Error Correction (FEC). Самый простой, знакомый всем вариант избыточного кодирования: в поток данных на каждые K пакетов добавить XOR от них. Тогда в случае потери одного пакета из этой пачки пропажу можно будет восстановить без ретрансмита. Для восстановления нескольких пакетов есть более сложные алгоритмы — например, использующие коды Рида — Соломона.
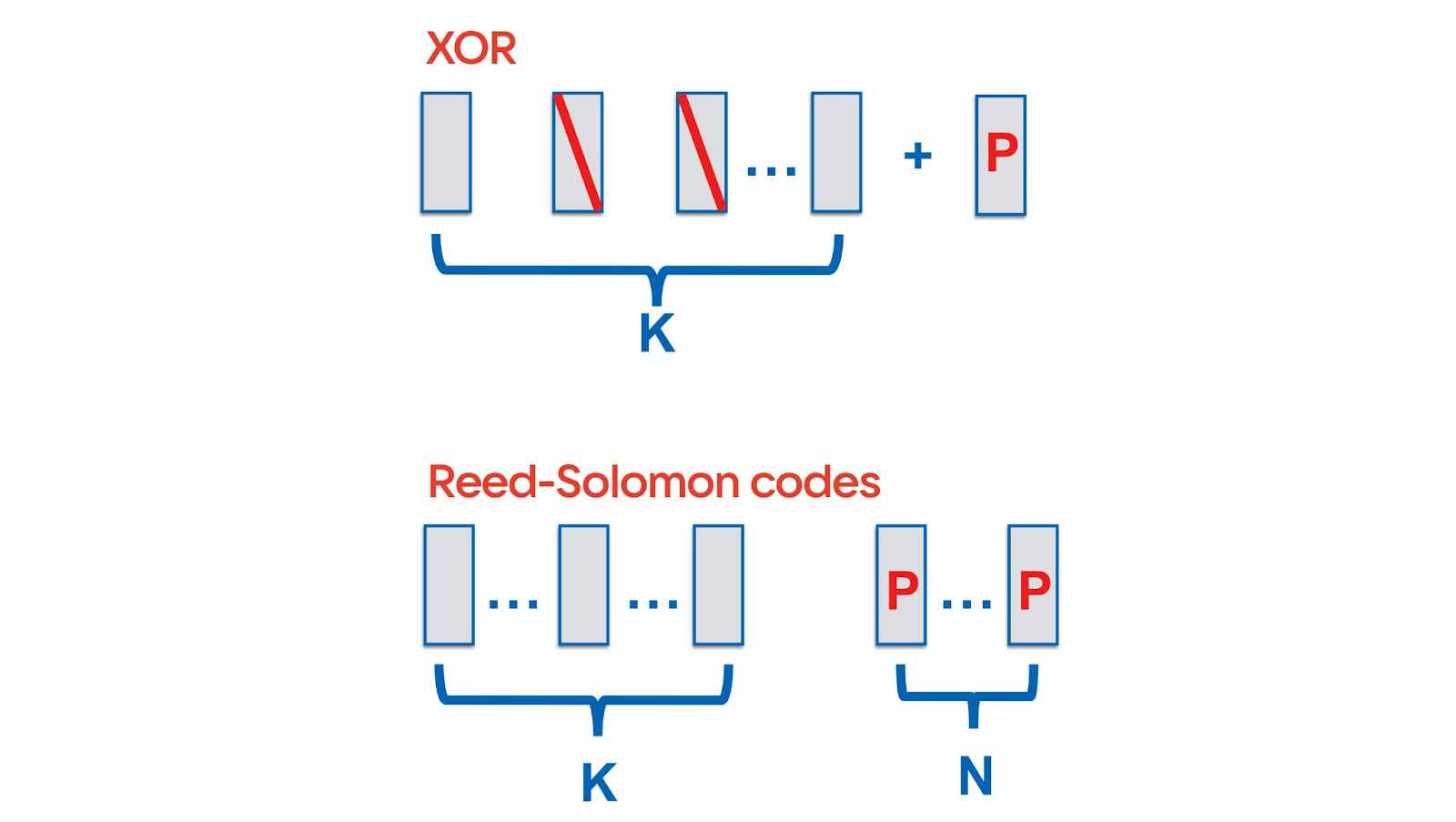
Не так важно, какое именно избыточное кодирование применить. Важно, что в принципе QUIC разрешает FEC.
Наличие FEC значит, что можно вообще игнорировать факты packet loss и packet drop. Неважно, какой congestion avoidance на маршрутизаторе, RED/WRED, взвешенная потеря пакетов — с QUIC и FEC можно обходить принцип честного распределения и использовать сетевой канал без ограничений.
Всё предельно просто: в сети ваши пакеты дропнули; вы это видите и добавляете, скажем, 10% пакетов сверху, чтобы чинить потери; при этом остальные сервисы, работающие через этот же маршрутизатор, сбрасывают скорость из-за перегруженной сети. Другими словами: все сбрасывают скорость, а вы добавляете FEC — и тут же выигрываете конкуренцию за полосу пропускания.
На самом деле, спецификация протокола предусматривает возможность FEC, но не содержит реализации. Но так как многие сервисы, использующие QUIC, реализуют протокол самостоятельно, то вполне возможно, что кто-то из них внедрит FEC у себя.
QUIC hacks the internet:
congestion control лучше адаптируется к сети и не обязательно fair;
congestion control можно тюнить на лету;
congestion control можно написать свой, какой угодно;
FEC позволяет игнорировать потери в сети;
и это всё неконтролируемо.
Вы можете понять, принять и запустить это в своём сервисе.
Скептицизм вокруг QUIC, или Реальные проблемы
Если поискать информацию о QUIC по разным тематическим интернет-ресурсам, то, конечно, встретится много вопросов и сомнений. Разберём самые популярные из них.
«Zero-RTT есть в TCP, зачем нам QUIC?»
Действительно, можно сделать Zero-RTT в старом стеке. Для этого нужны изменения на каждом уровне сетевого стека:
TCP Fast Open на уровне TCP (см. грустную историю о TFO здесь);
TLS 1.3 на уровне TLS — только Android 10+. В iOS и Android сетевой API не предоставляет возможности воспользоваться TLS 1.3 0-RTT Handshake, а встроенные реализации выбрасывают session ticket задолго до истечения его TTL;
Early Data в HTTP.
Это заняло лет 10 — пока на каждом уровне были найдены решения, пока операционные системы обновились, пока изменения были внедрены в браузеры и так далее. Zero-RTT реально начал работать, только когда обновились все элементы. У нас до сих пор он срабатывает только в 80% случаев.
Вместо того чтобы тратить столько времени, можно взять с собой личный сетевой стек с QUIC — и Zero-RTT заработает сразу.
«QUIC подвержен Replay attack»
Рядом с Zero-RTT всегда стоит replay-атака и теоретическая возможность на передачу пакета сразу же получить ответ от сервера, не дожидаясь никаких хендшейков. Такая атака может заключаться, например, в том, чтобы 100 раз повторить пакет «перевести 100 рублей» и получить уже совсем другую сумму.
Чтобы защититься от Replay-атаки в ТСР с Zero-RTT, нужно поддержать 425 Too Early из спецификации HTTP Early Data — грубо говоря, отменять исполнение write-запросов без подтверждения.
В QUIC есть подобное решение — Zero-RTT только для immutable-запросов. Нельзя ничего модифицировать по Zero-RTT, но можно узнать состояние ленты или даже кошелька — потому что это не позволит злоумышленнику провести невалидную транзакцию.
«QUIC не такой быстрый, как говорят»
В блогах и статьях можно встретить мнения вроде такого: «While Google-reported performance for QUIC is promising — 3% page load time (PLT) improvement on Google search and 18% reduction in buffer time on YouTube — they are aggregated statistics and not reproducible by others (such as ourselves)».
Есть даже целые наукообразные исследования, которые показывают в основном то, как не надо проводить измерения.

Осторожно, ссылка на вредное исследование
Дело в том, что измерять эффект QUIC на localhost не имеет никакого смысла: на localhost не воспроизводятся все те особенности сетей, которые мы обсуждали выше и которые так сильно влияют на скорость передачи данных. Чтобы действительно сравнивать сетевые протоколы, нужно делать это на реальной сети.
Другой вопрос, что для теста невозможно получить доступ к реальному серверу другого сервиса. Google показывает результаты, которые его команда получила для своей реализации на своём окружении. Мы — свои. И когда мы только запускали QUIC и пробовали доступные решения, он тоже был не очень быстрый, но потом мы его немножко подтюнили и стало гораздо лучше.
«UDP заблокирован на провайдере»
QUIC работает поверх UDP, не поверх TCP, и провайдеры действительно иногда его блокируют. Но сейчас, когда на волне пандемии очень выросло число интернет-звонков, которые работают исключительно по UDP, всего 1% провайдеров пытаются блокировать UDP.
По нашим данным, UDP недоступен только у 1% пользователей. Это бывает, например, в отельных сетях, а в остальных случаях — всё хорошо и UDP с QUIC работает.
«Сетевой протокол в User Space?»
Следующий вопрос в разных вариациях связан с тем, что QUIC реализуется в User Space. Производительность чего-либо в User Space обычно ниже, чем в ядре: там есть прерывания, конкурентный вызов и так далее.
На самом деле, User Space — это фича.
Кроме «Latency numbers every programmer should know», предлагаю каждому разработчику выучить «Release cycle numbers» и всегда иметь их в виду.

Новый код для фронтенда и бэкенда можно раскатать за час — мы ВКонтакте деплоим раз в час. На iOS и Android доставка изменений до пользователей занимает примерно неделю. Браузеры обновляются за месяц, операционная система — раз в год. Обновить что-то в ядре операционной системы на всех серверах компании меньше чем за год нереально.
Соответственно, adoption, или скорость распространения изменений, для операционных систем измеряется в годах. На бэкенде, фронтенде и для мобильных клиентов adoption в 99% достигается максимум в течение нескольких месяцев — обновлять сетевой стек можно гораздо быстрее, чем это возможно для ядра ОС. Поэтому то, что QUIC в User Space, — это фича.
«Performance and Linux Kernel»
Говорят, что QUIC не очень эффективен в Linux. И действительно, писать протокол в User Space невыгодно.
Но сейчас производительность в Linux Kernel у QUIC сравнима с ТСР.

В Linux добавили ряд оптимизаций. Мы их тоже активно используем и видим не более 10% CPU дополнительных издержек с QUIC по сравнению с использованием TCP.
«Вся сеть в User Space, как отлаживать?»
Если сеть в User Space, то и за шифрование отвечает User Space. Это значит, что перехватив трафик на kernel и ниже, вы вообще его не видите. Идеальная security, но отлаживать невозможно — факт. TCP-дампов и возможности подебажить удалённо больше нет.
«Нет уровневой структуры»
Раньше всё было понятно — TCP, TLS, HTTP. А теперь какой-то хаос устроили, всё перемешали.

С этим трудно спорить, но я попробую. Все знают фразу: «Любую проблему можно решить введением дополнительного уровня абстракции. Кроме одной — слишком большого количества уровней абстракции». Мне кажется, что с сетевой моделью OSI происходит именно это — у нас просто слишком много абстракций.
«UDP подвержен Amplification attack»
Когда DNS работает по UDP, его можно использовать для amplification-атаки. Её суть в том, чтобы от имени жертвы отправить запрос на публичный DNS-сервер, в ответ на который он отправит очень много данных и перегрузит сервер жертвы. Это возможно, потому что в UDP нет проверки IP-адресов источника. То есть в теории можно послать на какой-нибудь крупный сервис вроде ВКонтакте запрос, ответом на который будет 10 Гбит/с трафика, выбрать destination вроде Хабра и уложить Хабр.
Протокол QUIC работает поверх UDP, почему бы не провернуть то же самое здесь.
Главное, что можно сделать, чтобы защититься от amplification-атаки, — не отвечать на запрос больше, чем вас просили. Поэтому QUIC всегда делает запросы большими, он просто дополняет их нулями до 1 350 байт (у нас ВКонтакте запросы как раз занимают около 1 000 байт). И отвечая на первые Zero-RTT запросы, мы не превышаем определённый порог по размеру данных. Поэтому провести amplification-атаки с помощью серверов ВКонтакте должно не получиться.
«Как защититься от DDoS?»
Короткий ответ — так же, как в TCP, кроме UDP-флуда.
Для защиты от DDoS на TCP есть большой стек решений, есть сервисы и компании, которые специализируются на защите от атак. Например, есть технологии на базе DPDK, которые защищают от SYN-флуда в TCP.
В UDP есть UDP-флуд, и от него нужно научиться защищаться, потому что решения для TCP напрямую работать не будут. Но при этом принципы атак те же, поэтому нужно по сути воспроизвести для UDP такие же задачи, какие уже решены для TCP.
Но если вам не удалось защититься от DDoS на UDP, то у вас всегда остаётся простое решение: в любой непонятной ситуации блокируйте UDP на маршрутизаторе.
Можно просто сделать фолбэк на старый протокол, пережить DDoS, а потом уже разбираться — нормальная agile-стратегия.
Наш вывод: QUIC уже быстрый, есть риски внедрения, но все они решаемы.
Нет времени объяснять — внедряем!
В любом случае конкуренты уже вовсю внедряют QUIC, надо тоже что-то делать.
Мы начали внедрять QUIC ещё в 2019 году и с тех пор попробовали три подхода:
gQUIC — open-source решение не совсем стандартизованного QUIC из Chromium. Оно не держало нагрузку, и по сути завести сервер не удалось;
quiche — решение на Rust от Cloudflare. Оно оказалось несовместимо с некоторыми нашими клиентами (см. картинку ниже);
решение от Nginx — его мы активно доработали, чтобы оно стало нас устраивать.

Эта табличка показывает совместимость серверных и клиентских реализаций QUIC. Все серверы проваливают какие-нибудь тесты и часто не могут нормально общаться даже между собой, не то что с другими. Никто ещё не сделал стандартную реализацию — у всех QUIC немного свой. И, конечно, крупные проекты свои продакшен-решения для сервера не отдают.
Наше решение nginx-quic мы хотим отправить в upstream, но уже сейчас его можно взять с нашего GitHub и использовать у себя. В нём мы сделали много всего, например:
изменили приоритеты для отправки системных пакетов;
MTU discovery — определение максимального размера пакета;
новый congestion control;
и множество менее значительных изменений и фиксов.
Подробнее можно посмотреть в докладе Ильи Щербака или позже в виде статьи в нашем блоге.
Кроме того, мы перепробовали несколько клиентских решений под iOS и Android, выбрали одно из них и доработали так, что для внедрения протокола потребуется добавить всего несколько строк кода. Наш клиент для QUIC также доступен в open source.
Продуктовые результаты от смены стека
Из названия статьи понятно, что оптимизации сработали и мы получили очень существенное ускорение в работе сервиса. Но рассмотрим полученный эффект детальнее, чтобы вы могли лучше прикинуть пользу для своих задач.
Результат перехода на QUIC:
на 45% снизилось время доставки изображений;
на 2% сократилось время ответа API, потому что основной вклад в него вносит работа бэкенда. И несмотря на то, что доставка API стала быстрее в десятки раз, пользовательский эффект небольшой;
на 1,6% выросло число просмотров контента — мы ускорили доставку, и за то же время пользователи могут посмотреть больше контента.
Перемножив результаты от внедрения QUIC и алгоритмов сжатия, получили суммарное ускорение в 2 раза.

Причём сначала мы обкатывали новинки на Германии, Бразилии и Молдавии — странах с тем самым RTT в районе 100 мс — там ускорение достигало 4 раз.
Полный результат ускорений:
на 55% быстрее доставка;
на 2,7% больше просмотров контента;
на 250 млн больше просмотров событий в рамках ВКонтакте.
Может показаться, что год работы не стоит того, чтобы повысить просмотры контента на 2,7%. Но давайте решим школьную задачку.
Дано: рост просмотров по всей ВКонтакте равен 2,7%. Предположим, что у четверти нашей аудитории слабый интернет.
Найти: на сколько вырастут просмотры у тех, кто пользуется ВКонтакте в плохих сетях — где наши оптимизации действительно имеют значение.
Решение: 0,027 / 0,25 = 10,8%
То есть люди, у которых не очень хороший интернет и которые из-за этого в принципе не очень активно пользуются интернет-сервисами, стали смотреть на 10% больше контента. Да, в абсолюте это может быть всего 2,7%, но на самом деле это очень существенный прирост на части аудитории.

Будущее, которое уже наступило
Вычислительные ресурсы растут быстрее, чем качество сетей. Поэтому, скорее всего, появятся ML-кодеки, которые будут сжимать фотографии в 10 раз лучше, чем привычные нам алгоритмы. Возможно, им будет требоваться очень много CPU-ресурсов и они будут жрать батарею, но для этого телефоны и становятся мощнее и эффективнее.
С алгоритмами сжатия, думаю, будет примерно то же самое, что и с форматами кодирования.
В сетевом стеке всё ещё интереснее — QUIC и его реализации в User Space позволяют теперь добавить много эвристик.
Во-первых, можно и хитро восстанавливать данные с помощью FEC, и обрабатывать потери так, чтобы это ни на что не влияло. Например, видео или фотографию можно отобразить, даже если пропали пакеты с несколькими пикселями — думаю, скоро это будет добавлено.
Во-вторых, можно строить congestion control не на точных измерениях, а на основе ML-моделей или статистики. Сейчас мы пытаемся измерить пропускную способность и подстроиться под неё, а могли бы взять статистику по IP-адресу пользователя, учесть в ML что-нибудь ещё и сразу выйти на новый нужный порог congestion.
В-третьих, можно предсказывать параметры сети, например пропускную способность, процент потери пакетов и другое.

Наш ML-отдел просчитал, можно ли угадать скорость доставки изображения и что для этого нужно. Оказалось, что её можно предсказать с AUC 0,75 в зависимости от размера картинки, уровня сигнала сети на телефоне, IP-адреса, гео, ошибок и других параметров.

Используя такое предсказание, можно понять, например, что загрузка картинки займёт секунду, и на бэкенде принять решение, что лучше её сначала сжать или отправить в другом разрешении.
Также с неплохой точностью можно угадать качество сети. Главными характеристиками будут IP и сила сигнала на мобильном телефоне. А потом уже такие показатели, как оператор, тип устройства, ОС, количество ошибок в подсети и другие. С AUC 0,75 можем классифицировать сеть и сразу же подстроить под неё congestion control.
Сетевая конкуренция
Раньше congestion control конфигурировался в ядре, все были «почти» равны — IETF принимал правила игры, а разработчики могли только чуть-чуть менять настройки. Теперь можно сделать свой congestion control чуть ли не для каждого пользователя. С одной стороны, это даёт простор для манёвра и позволяет нам лучше утилизировать сетевые ресурсы. С другой — этим могут воспользоваться и другие сервисы. У кого лучше алгоритм CC, тот получает преимущество — возникает сетевая конкуренция.
Раньше всё управление интернетом проходило через IETF, который следил, чтобы изменения в протоколах не ломали надёжность, безопасность и прочее, в том числе баланс. Теперь и IT-корпорации, и энтузиасты могут не советоваться с IETF и использовать особенности интернет-протоколов для собственной выгоды.
Распространение QUIC
По данным W3Techs, 22,2% всех сайтов используют HTTP/3.

Хотя, возможно, эти 22,2% измеряются в трафике или количестве запросов. В списке сайтов, работающих по HTTP/3, там приводится только Google, Facebook и Cloudflare.
Поэтому я провёл своё небольшое исследование: проверил российский топ-50 сайтов из списка Alexa с помощью сервиса HTTP/3 CHECK. В нём можно вбить адрес сайта и узнать, поддерживаются ли QUIC и HTTP/3.

Итого, если судить по W3Techs, HTTP/3 CHECK и новостям в интернете, то QUIC уже внедрили:
Google для всех своих сайтов, в том числе YouTube и Gmail;
Uber — и получил классный прирост, так как его пользователи как раз часто перемещаются и переключаются между станциями;
Facebook (вместе с Instagram и WhatsApp) запилил собственный стек — с абсолютно своей реализацией и для сервера, и для клиентов;
Snapchat присоединился к этому списку совсем недавно;
и ВКонтакте, единственная из крупных российских платформ, успешно внедрила QUIC в сентябре 2021 года.
Выводы
Доставку контента можно и нужно оптимизировать.
Крупные компании развивают протоколы доставки и форматы сжатия — используйте их и не отставайте.
Существует реальная сетевая конкуренция в сфере доставки контента и, хотите вы или нет, в ней придётся участвовать.
Теперь вы знаете, какой профит можно получить и где взять решение: сервер — github.com/VKCOM/nginx-quic, клиенты — github.com/VKCOM/KNet.
QUIC уже можно использовать, он позволяет ускориться в разы. Но никому не верьте на слово — проводите A/B, используйте метрики, проверяйте работу различных решений в своём случае.
