
Меня зовут Сергей Петренко, я работаю в команде кластерных технологий Tarantool. В прошлом году я рассказывал о том, как в Tarantool появилась синхронная репликация и поддержка автоматических выборов лидера на основе Raft. Теперь предлагаю погрузиться во «внутренности» репликации в Tarantool. Я расскажу, как устроена репликация, по какой логике она работает и почему самые очевидные решения не всегда самые оптимальные.
Если вы давно хотели углубиться в эту тему и разобраться в устройстве репликации на живом примере, то эта статья для вас.
Tarantool — платформа in-memory вычислений, поэтому данные хранятся в оперативной памяти. При этом, для большей надежности, данные параллельно сохраняются в виде полного снимка состояния сервера, а также в файлах журнала упреждающей записи.
Снимок состояния — снапшот (.snap) — ускоряет восстановление данных с диска после перезапуска сервера. Как правило, для этого достаточно полной копии данных, поэтому снапшот не содержит информации обо всех изменениях, произошедших с данными. Например, у вас есть поле, отражающее занятость туалета. Оно может принимать значения ЗАНЯТО/СВОБОДНО. Снапшот будет хранить только текущее состояние (ЗАНЯТО).
Создание полного снимка данных — операция затратная. Помимо прочего, если создавать снапшот на каждое изменение, то потребуется очень много места на диске. Поэтому снимки дополняются файлами журнала упреждающей записи — WAL (.xlog). Снапшоты обычно делаются по расписанию, например, раз в час, а журнал ведется постоянно, и в него попадает каждое изменение базы данных. В примере с занятостью туалета журнал будет хранить полную историю изменения значений: ЗАНЯТО, СВОБОДНО, ЗАНЯТО, и так далее.
Как только делается новый снимок данных, файлы журнала, созданные ранее, становятся ненужными и их можно удалять. Таким образом оптимизируется место на диске: хранится лишь один полный снимок данных на сервере и ограниченное количество файлов журнала.
В Tarantool реализована транзакционная репликация, которую иногда называют логической (например, в PostgreSQL). Транзакционная репликация, в отличие от других видов, позволяет достигнуть консистентности. Она естественным образом повторяет восстановление из журнала на диске: можно представить, что реплика восстанавливается из журнала, находящегося на диске другого сервера. Таким образом реплицируются не сами данные, а операции над ними и даже целые транзакции, состоящие из операций.
Существует несколько настроек ведения журнала:
В режимах
Настройка
При настройке
В случае с
Любой сервер, прежде чем начать обработку запросов клиентов, должен быть инициализирован определенным образом. Для этого должны быть созданы и заполнены начальными данными все системные спейсы (таблицы):
Кроме того, каждый сервер идентифицируется уникальным значением
Изначально ни один из узлов не принадлежит кластеру, так как они запущены впервые, и, по логике, кто-то должен обозначить эту принадлежность. Для этого выбирается bootstrap leader — сервер, инициализирующий кластер. Bootstrap leader самостоятельно генерирует первый снимок данных, который наполняется перечисленными выше системными данными, объемом около пяти килобайт. Как только bootstrap leader заканчивает создание первого снапшота, он готов обслуживать остальные узлы: регистрировать их в кластере и отправлять им начальный снимок. Таким образом, в момент начальной конфигурации сервер либо самостоятельно генерирует начальный снимок данных, либо получает его от одного из инициализированных узлов. О том, каким образом свежесозданный сервер выбирает, от кого получить снапшот, мы поговорим ниже.
При этом, как бы ни проводилась инициализация, начальный снимок данных самодостаточен: новый сервер в нем уже учтен. Это значит, что спейс
Версию набора данных на сервере определяет vclock — массив LSN (log sequence number), то есть количество логических операций, выполненных конкретно на этом сервере. На каждом узле содержатся данные, отвечающие не конкретному LSN, а массиву LSN — по одному компоненту на каждого члена кластера. Это достигается с помощью передачи операций каждого из зарегистрированных членов кластера (за исключением анонимных реплик) на остальные узлы посредством транзакционной репликации.
Tarantool поддерживает репликацию «мастер-мастер», то есть независимые друг от друга изменения могут происходить одновременно на нескольких узлах. Именно поэтому мы используем vclock вместо единого монотонно растущего LSN. Вооружившись этим знанием, давайте разберемся, для чего нужен спейс
Выше я писал, что спейс
В Tarantool общение с мастером на всех стадиях инициирует реплика. С точки зрения сервера все удаленные узлы, к которым он подключен, считаются мастерами. «Настоящего» мастера пользователь назначает самостоятельно, делая какой-то из серверов rw, а остальные — ro (или же оставляя всех rw в случае репликации «мастер-мастер»). Для этого необходимо сконфигурировать
Дальше здесь будем называть мастером сервер, принимающий подключения, а репликой — сервер, который подключается к удаленному узлу. Например, при рекомендуемом в Tarantool соединении full-mesh (все подключаются ко всем) каждый сервер будет одновременно и мастером, — потому что обслуживает входящие подключения и посылает им изменения, — и репликой, потому что подключается ко всем остальным. Список URI мастеров, от которых нужно получать изменения, передается в
Подключение к каждому из мастеров обслуживает отдельный файбер, называемый applier. Логика работы applier очень грубо описывается таким циклом:
Идея в том, что applier старается постоянно поддерживать соединение с мастером, и при его разрыве или другой устранимой неполадке пытается восстановить соединение после небольшого тайм-аута.
Со стороны мастера для общения с каждой репликой создается отдельный поток, называемый relay. Главная и в то же время самая простая задача relay — чтение журнала с нужного места и пересылка его содержимого подключенной реплике.
За состоянием репликации проще следить на реплике. Ее applier последовательно проходит следующие состояния: CONNECT, AUTH, JOIN (INITIAL + FINAL), SUBSCRIBE (SYNC + FOLLOW). Разберемся, что это за состояния и как они работают.
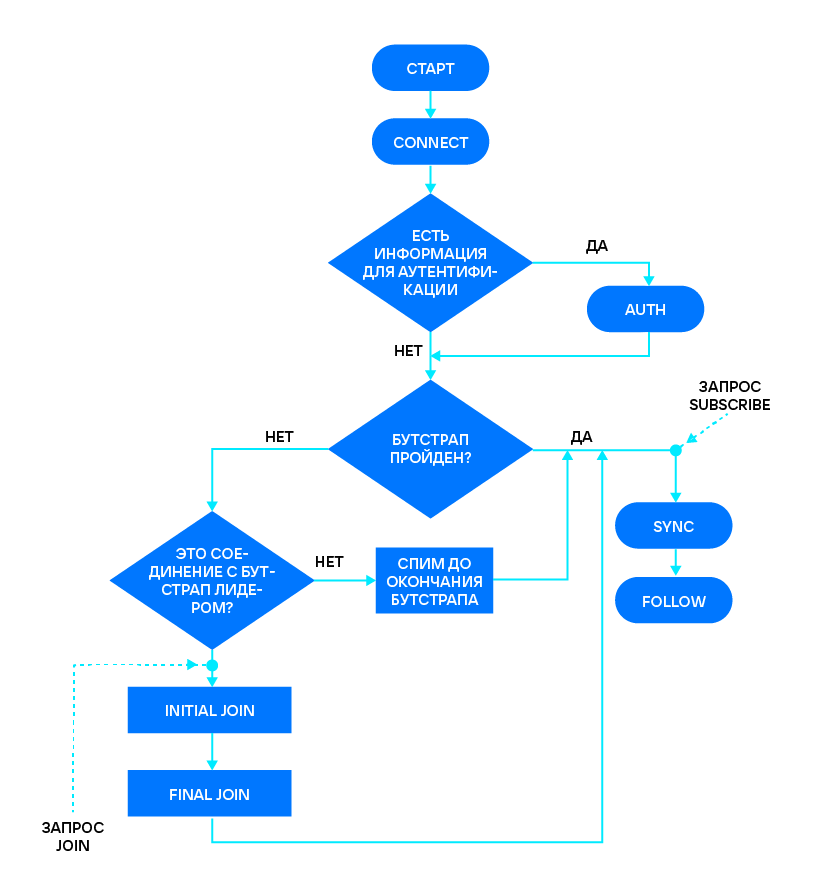
При подключении реплики ее applier входит в состояние CONNECT. Для нового соединения мастер сразу же выдает greeting — текстовое приветствие следующего вида:
Идентификатор во второй строке — это UUID сервера, а

AUTH — это необязательный шаг, выполняемый только если вместе с URI передана информация для аутентификации. Например, в
Для работы репликации реплики должны подключаться от имени пользователя, у которого есть права чтения на universe, позволяющие читать всю базу, и записи в спейс

Пройдя (или нет) аутентификацию, мы переходим к выбору bootstrap leader’а. В этой главе я подробнее расскажу, по какому принципу определяется лучший узел для регистрации.
Примечание: здесь мы не будем касаться механизма «выборов лидера» Raft. Эти понятия, к сожалению, часто путают. Bootstrap leader — это узел, который проводит начальную конфигурацию кластера. После того, как начальная конфигурация пройдена, не имеет никакого значения, кто был bootstrap leader’ом. Про «выбор лидера» с помощью алгоритма Raft я рассказывал в прошлой статье.
Как только реплика получила greeting и проверила его подлинность (мы действительно подключились к Tarantool), она отправляет мастеру запрос VOTE.
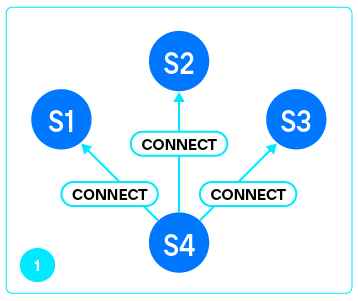
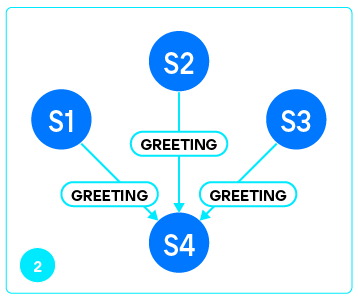
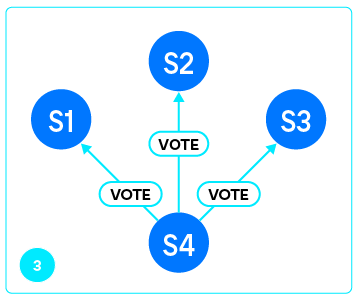

В ответ на это мастер отправляет ответы на вопросы, на основании которых реплика может сделать выбор:
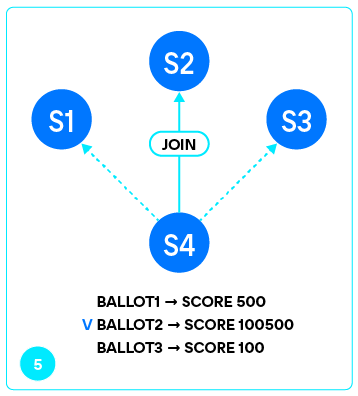
Собрав ответы от каждого из серверов, перечисленных в

Если вдруг несколько серверов ответили одинаково на все вопросы, среди них выбирается сервер с наибольшим vclock. Если же и vclock серверов совпали, то побеждает узел с наименьшим

Также можно указать в
Если нода оказалась bootstrap leader’ом для самой себя, то она переходит к наполнению начального снапшота. В других случаях узел посылает запрос JOIN выбранному bootstrap leader’у, чтобы получить снапшот от него. Каждый узел выбирает независимо, основываясь на полученных ответах на VOTE.

Что стоит запомнить?
Какие ошибки в настройке можно совершить?
Антипример №1. Попробуем инициализировать кластер из двух узлов. В конфигурации каждого из узлов укажем только URI соседа, например,
Сервер ищет bootstrap leader’а среди всех, кто перечислен в
Антипример №2. Предположим, что в кластере уже сконфигурировано два узла, слушающих на портах 3301 и 3302. Попробуем добавить к ним еще два узла, но каждому из них передадим свою настройку репликации:
Каждый из узлов зарегистрировал реплику, подключившуюся к нему, под одним и тем же id — 3. Чтобы такого не произошло, при одновременном бутстрапе нескольких серверов на каждом из них нужно указывать идентичный список
Также избежать одновременной регистрации на разных узлах помогают опции
По умолчанию
Определившись с bootstrap leader’ом, реплика отправляет запрос на присоединение к кластеру — JOIN. Он состоит из двух стадий: INITIAL JOIN и FINAL JOIN (это внутреннее деление). И реплика, и мастер переходят ко второй стадии сразу после первой, без отправки дополнительных запросов.
Вместе с запросом JOIN реплика посылает мастеру свой
После отправки данных снапшота (фазы INITIAL_JOIN), мастер регистрирует присоединяющуюся реплику в кластере, вставляя в свободный слот спейса
Стадия FINAL_JOIN состоит из отправки накопившихся в журнале за время INITIAL_JOIN операций. Поток данных FINAL_JOIN выглядит так же, как поток SUBSCRIBE, о котором речь пойдет ниже. Разница лишь в том, что FINAL_JOIN, в отличие от SUBSCRIBE, конечен, и заканчивается, как только мастер посылает запись журнала, соответствующую stop_vclock.
Вы спросите, а зачем вообще нужна стадия FINAL_JOIN? Действительно, почему бы не перейти к SUBSCRIBE сразу после отправки снапшота? Тем более, что FINAL_JOIN практически и есть стадия SUBSCRIBE, только урезанная. Дело в том, что в снапшоте, пришедшем от мастера во время INITIAL_JOIN, еще нет записи о новом узле: регистрация происходит только после успешной отправки снапшота. Поэтому прежде, чем сохранять на диск начальный снапшот, реплике необходимо получить от мастера свою регистрацию. Чтобы «промотать» репликационный поток до своей регистрации, реплике нужно дождаться записи, соответствующей stop_vclock.
Итак, фаза FINAL_JOIN нужна реплике по единственной причине: в снапшоте реплики должна быть ее регистрация в спейсе
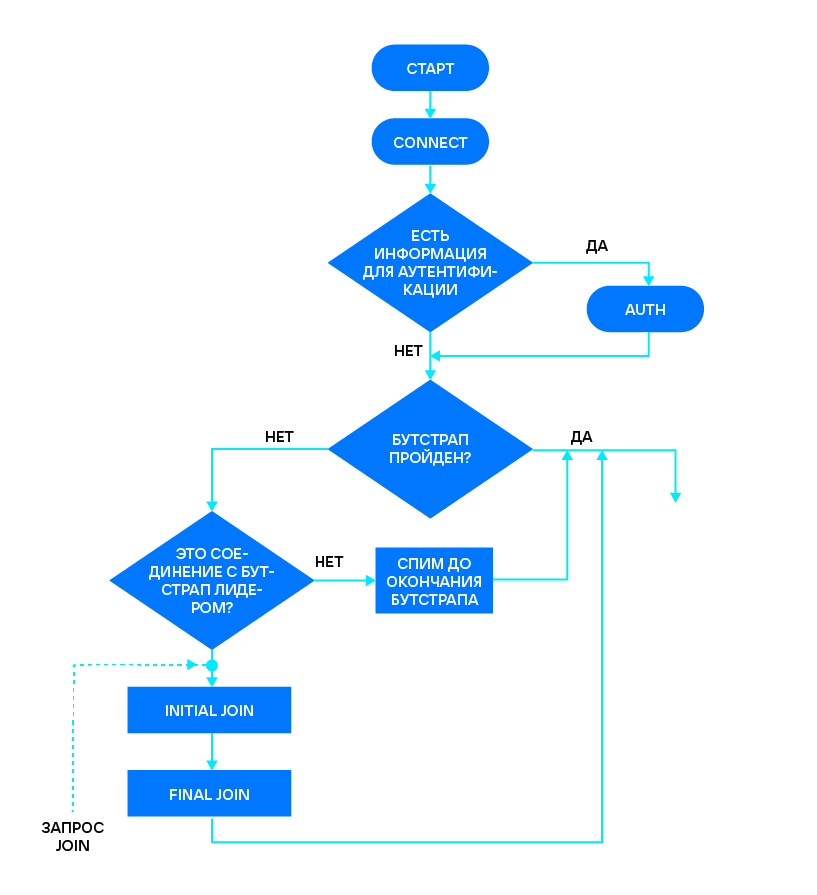
SUBSCRIBE — подписка на все изменения, происходящие на мастере. Присоединенная к кластеру реплика посылает запрос одновременно всем узлам, перечисленным в
Никаких явных признаков окончания одной стадии и начала следующей в репликационном потоке нет: реплика сама переходит из состояния SYNC в FOLLOW по определенному правилу.
Состояние SYNC нужно, чтобы не дать отстающей и только что запущенной реплике перейти в состояние writeable до того, как она нагонит все изменения в кластере. До тех пор, пока соединения со всеми членами кластера не перейдут в состояние FOLLOW, реплика будет read-only. При этом ее
Также можно менять параметр
Вместе с SUBSCRIBE реплика посылает свой
Если все проверки пройдены, то мастер отвечает реплике своим текущим vclock. Будем называть его start_vclock. За start_vclock следует бесконечный — до разрыва соединения или другой ошибки — репликационный поток, содержащий все выполнявшиеся и выполняющиеся на мастере операции (начиная с instance_vclock). На мастере этот поток генерирует отдельный поток — relay, — читающий все файлы журнала с нужного места и построчно отправляющий их реплике.
Чтобы можно было понять, к какой транзакции относится операция в журнале и репликационном потоке, мы присваиваем каждой операции не только LSN, про который я рассказывал в главе про хранение данных, но и TSN — transaction sequence number. TSN для каждой операции в транзакции одинаковый и равен LSN первой операции. Реплика, руководствуясь TSN приходящих в потоке репликации операций, собирает их обратно в транзакции, после чего применяет и пишет их в свой журнал. Таким образом журнал реплики становится почти полной копией журнала мастера (при условии, что не используются триггеры на репликацию).
Теперь поговорим о правиле, по которому соединение с мастером переходит из состояния SYNC в FOLLOW. Одна из основных характеристик соединения — отставание реплики от мастера, то есть время между попаданием записи в журнал мастера и получением этой записи репликой. Мы это отставание называем «лагом» репликации.
Переход соединения из состояния SYNC в FOLLOW происходит, как только начинают выполняться два условия:
Как упоминалось выше, процесс SUBSCRIBE бесконечен, он может быть прерван лишь из-за возникновения ошибки или пропажи мастера/реплики. Для обнаружения пропажи другой стороны общения и мастер, и реплика используют тайм-ауты. Тайм-аут репликации конфигурируется опцией
В отсутствие новых изменений для отправки мастер посылает реплике пинги с частотой раз в
По vclock в ACK-пакете реплики мастер следит за тем, какие данные реплика действительно получила и применила, управляет сборкой старых файлов журнала и считает количество узлов, применивших синхронную транзакцию (ждать кворума).
Если от мастера или реплики нет вестей в течение четырехкратного
Следить за репликацией помогает таблица
Поля
Upstream — сверху по течению к нам что-то приходит. Это состояние входящего потока репликации (от удалённого сервера к нам), который обрабатывается applier’ом.
Поля upstream:
Downstream — от нас что-то утекает вниз по течению. Это состояние исходящего потока репликации (от нас к удалённому серверу), который генерируется relay’ем.
Поля downstream:
Если соединение будет разорвано, то соответствующий upstream или downstream приобретает новые поля
Или
Количество хранящихся на диске снапшотов регулируется опцией
В начале статьи я говорил, что Tarantool хранит все файлы журнала после самого старого снапшота. Это нужно для того, чтобы можно было восстановиться из любого из
Как мастер понимает, какие файлы нужны репликам?
Для каждой реплики хранится информация о последнем полученном ею vclock. Эта информация заполняется в момент JOIN тем vclock, который реплика получает изначально, а также в момент SUBSCRIBE vclock, присланный репликой. Далее vclock, нужный каждой реплике, обновляется по мере прихода от нее ACK-пакетов.
Информация о том, какие файлы журнала ещё нужны репликам, не сохраняется на диске, поэтому после перезапуск сервер может удалить все лишние, по его мнению, .xlog. Если такое происходит, то вернуть реплику в кластер можно только с помощью повторного JOIN: нужно удалить все ее данные с диска и запустить заново. Во избежание таких ситуаций, существует параметр
Исторически сложилось, что в кластере не может быть зарегистрировано более 31 узла. Связано это с тем, что каждый узел получает свой уникальный id и занимает место в vclock. Vclock не может расти бесконечно, ведь им регулярно обмениваются узлы кластера: его содержит каждый ACK-пакет. Слишком длинные vclock могут занимать больше пропускной способности канала, чем полезные данные, поэтому размер vclock ограничен 31 «ячейкой» для сервера, и значит зарегистрированных членов в кластере не может быть больше 31.
Обойти это ограничение помогают анонимные реплики — особые подписчики на изменения, не занимающие места в спейсе

Для того, чтобы создать анонимную реплику, ей нужно передать при начальной конфигурации параметр
Снапшот, созданный на анонимной реплике, не самодостаточен: в нем нет записи о реплике в спейсе
Не все данные нужно реплицировать: бывает, нужно хранить данные только на одном сервере без репликации. Для этого существуют локальные — или replica-local — спейсы.
Все данные, хранящиеся в таком спейсе, попадают в журнал, но не реплицируются.
Поскольку данные в локальных спейсах влияют лишь на состояние сервера, но не всего кластера, операции с локальными спейсами не увеличивают LSN сервера и не меняют его компонент в vclock. Вместо этого операции с локальными спейсами увеличивают выделенный LSN, хранящийся в
Существуют ещё и временные спейсы. Данные в них не только не реплицируются, но и не попадают в журнал и снапшот. Во временные спейсы тоже можно писать на read_only-сервере. Записанные данные будут храниться в спейсе, пока работает сервер. После перезапуска сервера временный спейс опустеет.
Поскольку данные в локальном или временном спейсе никак не влияют на соседние узлы, заполнять локальный спейс может даже сервер, находящийся в режиме read_only. Это значит, что такими спейсами могут пользоваться анонимные реплики. Есть лишь одна особенность: создать локальный или временный спейс можно только на writeable-сервере, после этого он появится на всех серверах. Каждый сервер сможет наполнять его независимо от остальных.
Очень широкий простор для воображения дают триггеры. Проще продемонстрировать все возможности с помощью примеров. Не все примеры пригодятся вам в обозримом будущем, но знать о своих возможностях всегда полезно :)
Пример 1.
На реплике заменим движок спейса
Триггер
Пример 2.
На реплике будем игнорировать все приходящие с мастера изменения спейса
В триггере
Скачать Tarantool можно на официальном сайте, а получить помощь — в Telegram-чате.
Если вы давно хотели углубиться в эту тему и разобраться в устройстве репликации на живом примере, то эта статья для вас.
Немного про хранение данных
Tarantool — платформа in-memory вычислений, поэтому данные хранятся в оперативной памяти. При этом, для большей надежности, данные параллельно сохраняются в виде полного снимка состояния сервера, а также в файлах журнала упреждающей записи.
Снимок состояния — снапшот (.snap) — ускоряет восстановление данных с диска после перезапуска сервера. Как правило, для этого достаточно полной копии данных, поэтому снапшот не содержит информации обо всех изменениях, произошедших с данными. Например, у вас есть поле, отражающее занятость туалета. Оно может принимать значения ЗАНЯТО/СВОБОДНО. Снапшот будет хранить только текущее состояние (ЗАНЯТО).
Создание полного снимка данных — операция затратная. Помимо прочего, если создавать снапшот на каждое изменение, то потребуется очень много места на диске. Поэтому снимки дополняются файлами журнала упреждающей записи — WAL (.xlog). Снапшоты обычно делаются по расписанию, например, раз в час, а журнал ведется постоянно, и в него попадает каждое изменение базы данных. В примере с занятостью туалета журнал будет хранить полную историю изменения значений: ЗАНЯТО, СВОБОДНО, ЗАНЯТО, и так далее.
Как только делается новый снимок данных, файлы журнала, созданные ранее, становятся ненужными и их можно удалять. Таким образом оптимизируется место на диске: хранится лишь один полный снимок данных на сервере и ограниченное количество файлов журнала.
В Tarantool реализована транзакционная репликация, которую иногда называют логической (например, в PostgreSQL). Транзакционная репликация, в отличие от других видов, позволяет достигнуть консистентности. Она естественным образом повторяет восстановление из журнала на диске: можно представить, что реплика восстанавливается из журнала, находящегося на диске другого сервера. Таким образом реплицируются не сами данные, а операции над ними и даже целые транзакции, состоящие из операций.
Существует несколько настроек ведения журнала:
Box.cfg{wal_mode = ‘write’}
Box.cfg{wal_mode = ‘fsync’}
Box.cfg{wal_mode = ‘none’}В режимах
write и fsync мастер подтверждает транзакцию только после того, как запишет данные в журнал (системный вызов write()вернёт ОК). В обоих случаях предоставляются гарантии при записи. Настройки отличаются друг от друга процедурой открытия файлов журнала. Настройка
write используется по умолчанию. В этом режиме файлы журнала синхронизируются только при закрытии: каждый вызов write() возвращается сразу после того, как данные записаны в специальный буфер операционной системы, но не факт, что уже записаны на диск.При настройке
fsync файлы журнала открываются с флагом O_SYNC. Это значит, что write() возвращает ОК только после того, как операционная система отправит данные на диск.В случае с
none, журнал не ведется, единственный способ сохранить данные на диск в таком режиме — сделать снапшот. Все изменения, совершенные после снапшота, будут храниться только в памяти и исчезнут при перезапуске. Репликация в принципе не работает в режиме none, так как отсутствует журнал — источник данных для репликации.Что происходит при создании нового сервера?
Любой сервер, прежде чем начать обработку запросов клиентов, должен быть инициализирован определенным образом. Для этого должны быть созданы и заполнены начальными данными все системные спейсы (таблицы):
_cluster— список всех зарегистрированных в кластере серверов;_userи_priv— системные спейсы, которые содержат информацию о пользователях и их правах;_space,_index— системные спейсы, содержащие информацию о созданных спейсах и индексах над ними.
Кроме того, каждый сервер идентифицируется уникальным значением
instance_uuid, а кластер — cluster_uuid.Изначально ни один из узлов не принадлежит кластеру, так как они запущены впервые, и, по логике, кто-то должен обозначить эту принадлежность. Для этого выбирается bootstrap leader — сервер, инициализирующий кластер. Bootstrap leader самостоятельно генерирует первый снимок данных, который наполняется перечисленными выше системными данными, объемом около пяти килобайт. Как только bootstrap leader заканчивает создание первого снапшота, он готов обслуживать остальные узлы: регистрировать их в кластере и отправлять им начальный снимок. Таким образом, в момент начальной конфигурации сервер либо самостоятельно генерирует начальный снимок данных, либо получает его от одного из инициализированных узлов. О том, каким образом свежесозданный сервер выбирает, от кого получить снапшот, мы поговорим ниже.
При этом, как бы ни проводилась инициализация, начальный снимок данных самодостаточен: новый сервер в нем уже учтен. Это значит, что спейс
_cluster в начальном снапшоте (и во всех последующих) всегда содержит запись вида {id, instance_uuid}, соответствующую серверу. Исключение из этого правила составляют лишь анонимные узлы, которых мы тоже коснемся ниже.Vclock
Версию набора данных на сервере определяет vclock — массив LSN (log sequence number), то есть количество логических операций, выполненных конкретно на этом сервере. На каждом узле содержатся данные, отвечающие не конкретному LSN, а массиву LSN — по одному компоненту на каждого члена кластера. Это достигается с помощью передачи операций каждого из зарегистрированных членов кластера (за исключением анонимных реплик) на остальные узлы посредством транзакционной репликации.
Tarantool поддерживает репликацию «мастер-мастер», то есть независимые друг от друга изменения могут происходить одновременно на нескольких узлах. Именно поэтому мы используем vclock вместо единого монотонно растущего LSN. Вооружившись этим знанием, давайте разберемся, для чего нужен спейс
_cluster.Да кто такой этот ваш _cluster?
Выше я писал, что спейс
_cluster содержит в себе список всех зарегистрированных в кластере серверов. Но какой в этом смысл? Зачем вообще хранить информацию о членах кластера? Эти данные важны для составления маппинга server_uuid : id, который используется для определения, на каком сервере были сделаны изменения. Вы можете спросить: «А почему бы не подписать изменения идентификатором сервера (instance_uuid)?». Конечно, это проще, но потребовало бы отправки лишних 18 байт UUID (+ нескольких байт на его кодирование в msgpack) в дополнение к каждой операции. Вместо этого используется байт id, представляющий собой int. Его значения ограничены константой VCLOCK_MAX = 32, поэтому id всегда кодируется в msgpack ровно в один байт.Стадии репликации
В Tarantool общение с мастером на всех стадиях инициирует реплика. С точки зрения сервера все удаленные узлы, к которым он подключен, считаются мастерами. «Настоящего» мастера пользователь назначает самостоятельно, делая какой-то из серверов rw, а остальные — ro (или же оставляя всех rw в случае репликации «мастер-мастер»). Для этого необходимо сконфигурировать
box.cfg{read_only = true} и box.cfg{read_only = false}.Дальше здесь будем называть мастером сервер, принимающий подключения, а репликой — сервер, который подключается к удаленному узлу. Например, при рекомендуемом в Tarantool соединении full-mesh (все подключаются ко всем) каждый сервер будет одновременно и мастером, — потому что обслуживает входящие подключения и посылает им изменения, — и репликой, потому что подключается ко всем остальным. Список URI мастеров, от которых нужно получать изменения, передается в
box.cfg.replication.Подключение к каждому из мастеров обслуживает отдельный файбер, называемый applier. Логика работы applier очень грубо описывается таким циклом:
while (true) {
try {
applier_connect();
if (!joined)
applier_join();
applier_subscribe();
} catch (RecoverableError) {
goto Reconnect;
} catch (UnrecoverableError) {
goto LogErrorAndExit;
}
Reconnect:
sleep(replication_timeout);
}
LogErrorAndExit:
…
Идея в том, что applier старается постоянно поддерживать соединение с мастером, и при его разрыве или другой устранимой неполадке пытается восстановить соединение после небольшого тайм-аута.
Со стороны мастера для общения с каждой репликой создается отдельный поток, называемый relay. Главная и в то же время самая простая задача relay — чтение журнала с нужного места и пересылка его содержимого подключенной реплике.
За состоянием репликации проще следить на реплике. Ее applier последовательно проходит следующие состояния: CONNECT, AUTH, JOIN (INITIAL + FINAL), SUBSCRIBE (SYNC + FOLLOW). Разберемся, что это за состояния и как они работают.

CONNECT
При подключении реплики ее applier входит в состояние CONNECT. Для нового соединения мастер сразу же выдает greeting — текстовое приветствие следующего вида:
“Tarantool 2.10.0 (Binary)”
“68387c01-c9be-4dc5-842a-a2bee66f5b4d”
“<salt>”
Идентификатор во второй строке — это UUID сервера, а
<sаlt> — соль для паролей, которая будет использоваться при аутентификации (состояние AUTH).
AUTH
AUTH — это необязательный шаг, выполняемый только если вместе с URI передана информация для аутентификации. Например, в
box.cfg.replication можно передать box.cfg{replication="127.0.0.1:3301"} или box.cfg{replication="user:password@127.0.0.1:3301"}. В первом случае AUTH не будет выполнено, а во втором — будет. В противном случае подключение выполняется от имени пользователя guest.Для работы репликации реплики должны подключаться от имени пользователя, у которого есть права чтения на universe, позволяющие читать всю базу, и записи в спейс
_cluster. Такие (или более сильные) права можно выдать явно, а можно выдать пользователю роль replication, что будет иметь тот же эффект. Наличие необходимых прав проверяется мастером при обработке как запроса JOIN, так и SUBSCRIBE.
Как выбирается bootstrap leader?
Пройдя (или нет) аутентификацию, мы переходим к выбору bootstrap leader’а. В этой главе я подробнее расскажу, по какому принципу определяется лучший узел для регистрации.
Примечание: здесь мы не будем касаться механизма «выборов лидера» Raft. Эти понятия, к сожалению, часто путают. Bootstrap leader — это узел, который проводит начальную конфигурацию кластера. После того, как начальная конфигурация пройдена, не имеет никакого значения, кто был bootstrap leader’ом. Про «выбор лидера» с помощью алгоритма Raft я рассказывал в прошлой статье.
Как только реплика получила greeting и проверила его подлинность (мы действительно подключились к Tarantool), она отправляет мастеру запрос VOTE.
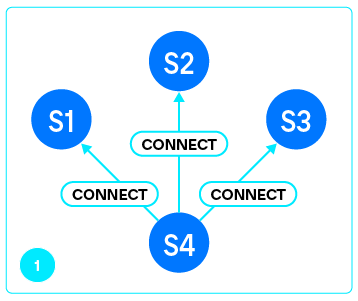
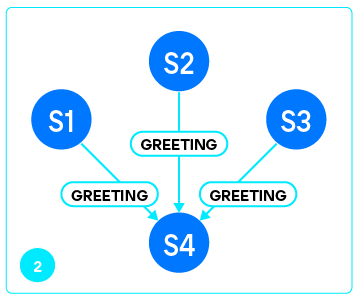
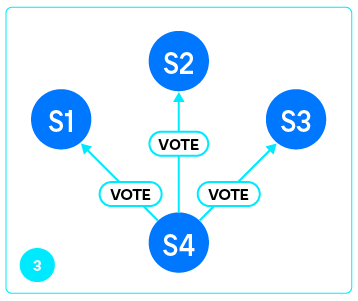

В ответ на это мастер отправляет ответы на вопросы, на основании которых реплика может сделать выбор:
- Сервер сконфигурирован?
- Сервер сконфигурирован как НЕ
read_only? - Сейчас сервер НЕ
read_only? - Сервер сконфигурирован с
election_mode manualилиcandidate?
Собрав ответы от каждого из серверов, перечисленных в
box.cfg.replication, узел переходит к выбору bootstrap leader’а. Каждый утвердительный ответ добавляет очков серверу, и в результате побеждает сильнейший.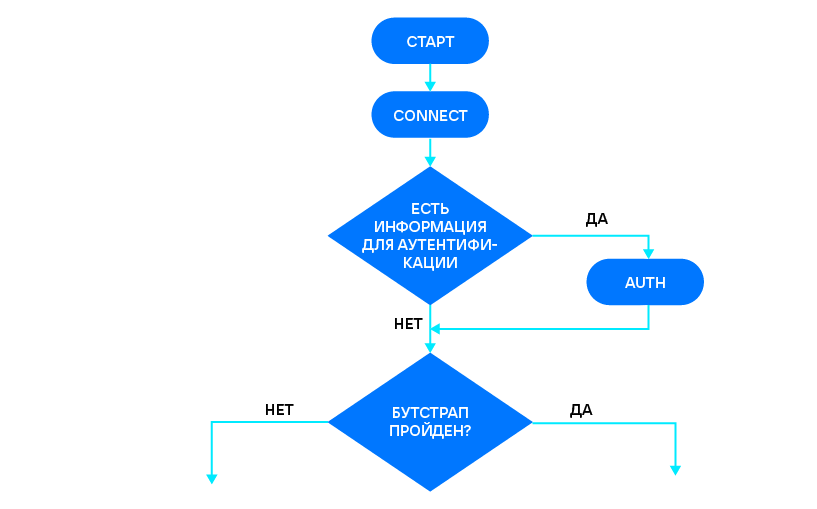
Если вдруг несколько серверов ответили одинаково на все вопросы, среди них выбирается сервер с наибольшим vclock. Если же и vclock серверов совпали, то побеждает узел с наименьшим
instance_uuid.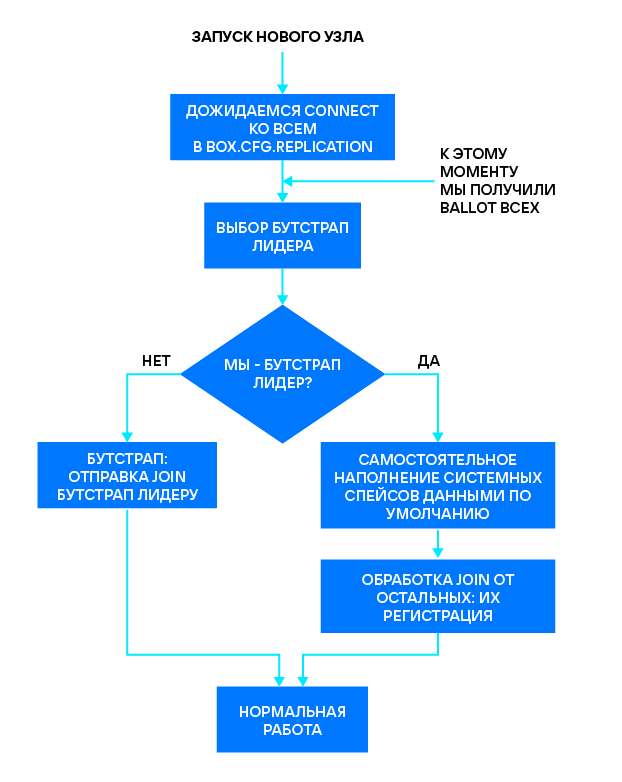
Также можно указать в
box.cfg.replication саму реплику. Тогда, при выполнении условий выше, именно она может стать bootstrap leader’ом. Явно указывать реплику имеет смысл практически во всех случаях. Иначе может возникнуть ситуация, когда все узлы считают лидером конкретный сервер, который уверен в «лидерстве» кого-то другого, из-за чего bootstrap зависает.Если нода оказалась bootstrap leader’ом для самой себя, то она переходит к наполнению начального снапшота. В других случаях узел посылает запрос JOIN выбранному bootstrap leader’у, чтобы получить снапшот от него. Каждый узел выбирает независимо, основываясь на полученных ответах на VOTE.
Что стоит запомнить?
- Когда ни один из серверов в кластере ещё не инициализирован, bootstrap leader’ом станет узел с наименьшим
instance_uuid. - Передавая серверам параметр
box.cfg.instance_uuid, можно заставить конкретный сервер стать bootstrap leader’ом. - Если в кластере есть серверы, сконфигурированные в
election_mode=’candidate’или‘manual’, то bootstrap leader’ом станет один из них. Этот же сервер станет Raft-лидером в первом терме после инициализации кластера. - Если среди серверов есть уже прошедшие инициализацию, то bootstrap leader будет выбираться среди них.
Какие ошибки в настройке можно совершить?
Антипример №1. Попробуем инициализировать кластер из двух узлов. В конфигурации каждого из узлов укажем только URI соседа, например,
box.cfg{listen=3301, replication=3302}. Оба узла зависнут, так и не создав снапшот. Причина в том, что первый узел выбрал второго bootstrap leader’ом, а второй узел — первого. Каждый из них ждет, когда другой инициализирует кластер и пришлет начальный снапшот.Сервер ищет bootstrap leader’а среди всех, кто перечислен в
box.cfg.replication. Поэтому на каждом из серверов нужно указать и себя, и коллегу, чтобы они выбирали из одинакового набора вариантов. Правильно будет оба узла сконфигурировать так: box.cfg{listen=..., replication={3301,3302}}.Антипример №2. Предположим, что в кластере уже сконфигурировано два узла, слушающих на портах 3301 и 3302. Попробуем добавить к ним еще два узла, но каждому из них передадим свою настройку репликации:
box.cfg{replication=3301} и box.cfg{replication=3302}. В результате репликация между узлами 3301 и 3302 остановится с ошибкой вида:main/111/applier/ memtx_tree.cc:870 E> ER_TUPLE_FOUND: Duplicate key exists in unique index "primary" in space "_cluster" with old tuple - [3, "3af63a1e-9e35-4ce8-b76c-5c51100c36e8"] and new tuple - [3, "c611e878-4869-47d9-80b4-7ed9859e2403"]
Каждый из узлов зарегистрировал реплику, подключившуюся к нему, под одним и тем же id — 3. Чтобы такого не произошло, при одновременном бутстрапе нескольких серверов на каждом из них нужно указывать идентичный список
box.cfg.replication, включая себя самого.Также избежать одновременной регистрации на разных узлах помогают опции
replication_connect_timeout и replication_connect_quorum. При бутстрапе replication_connect_timeout работает так: прежде чем выбирать bootstrap leader’а, сервер пытается подключиться ко всем серверам из box.cfg.replication в течение replication_connect_timeout. Если же подключиться ко всем не удалось, то сервер довольствуется подключением к хотя бы replication_connect_quorum серверов, после чего переходит к выбору.По умолчанию
replication_connect_timeout равен 30 секундам, а replication_connect_quorum — количеству перечисленных в box.cfg.replication серверов. Эти опции будут правильно работать, только если передавать запускающимся серверам одинаковые списки box.cfg.replication.JOIN
Определившись с bootstrap leader’ом, реплика отправляет запрос на присоединение к кластеру — JOIN. Он состоит из двух стадий: INITIAL JOIN и FINAL JOIN (это внутреннее деление). И реплика, и мастер переходят ко второй стадии сразу после первой, без отправки дополнительных запросов.
Вместе с запросом JOIN реплика посылает мастеру свой
instance_uuid. При получении запроса мастер сперва проверяет права, а затем cоздаёт снапшот текущего состояния в памяти (который не пишет на диск). Началом ответа на JOIN-запрос является vclock мастера на момент JOIN (это vclock только что созданного снапшота). Следом отправляются состояние Raft (текущий терм, в котором находится мастер) и очереди синхронных транзакций (ее владелец и терм, в котором он ею завладел). После этого мастер последовательно проходит по всему снимку данных, итерируясь по спейсам по возрастанию их id, а внутри каждого спейса — по первичному ключу, и отправляет на реплику поток INSERT, соответствующий содержимому спейсов.После отправки данных снапшота (фазы INITIAL_JOIN), мастер регистрирует присоединяющуюся реплику в кластере, вставляя в свободный слот спейса
_cluster пару {id, replica_uuid}. Этим начинается стадия FINAL_JOIN, о которой мастер сообщает реплике, снова послав ей свой обновленный vclock. Этому vclock будет соответствовать начальный снапшот, сделанный самой репликой на основе всех полученных от мастера данных. В этой стадии будем называть его stop_vclock.Стадия FINAL_JOIN состоит из отправки накопившихся в журнале за время INITIAL_JOIN операций. Поток данных FINAL_JOIN выглядит так же, как поток SUBSCRIBE, о котором речь пойдет ниже. Разница лишь в том, что FINAL_JOIN, в отличие от SUBSCRIBE, конечен, и заканчивается, как только мастер посылает запись журнала, соответствующую stop_vclock.
Вы спросите, а зачем вообще нужна стадия FINAL_JOIN? Действительно, почему бы не перейти к SUBSCRIBE сразу после отправки снапшота? Тем более, что FINAL_JOIN практически и есть стадия SUBSCRIBE, только урезанная. Дело в том, что в снапшоте, пришедшем от мастера во время INITIAL_JOIN, еще нет записи о новом узле: регистрация происходит только после успешной отправки снапшота. Поэтому прежде, чем сохранять на диск начальный снапшот, реплике необходимо получить от мастера свою регистрацию. Чтобы «промотать» репликационный поток до своей регистрации, реплике нужно дождаться записи, соответствующей stop_vclock.
Итак, фаза FINAL_JOIN нужна реплике по единственной причине: в снапшоте реплики должна быть ее регистрация в спейсе
_cluster. Вместе с регистрацией реплика получает все изменения, произошедшие на мастере во время отправки снапшота. От них никуда не деться. 
SUBSCRIBE
SUBSCRIBE — подписка на все изменения, происходящие на мастере. Присоединенная к кластеру реплика посылает запрос одновременно всем узлам, перечисленным в
box.cfg.replication. SUBSCRIBE с точки зрения реплики разделён на две части: SYNC и FOLLOW.Никаких явных признаков окончания одной стадии и начала следующей в репликационном потоке нет: реплика сама переходит из состояния SYNC в FOLLOW по определенному правилу.
Состояние SYNC нужно, чтобы не дать отстающей и только что запущенной реплике перейти в состояние writeable до того, как она нагонит все изменения в кластере. До тех пор, пока соединения со всеми членами кластера не перейдут в состояние FOLLOW, реплика будет read-only. При этом ее
box.info.status будет orphan.Также можно менять параметр
box.cfg.replication_connect_quorum. Он управляет количеством соединений, которые должны перейти в состояние FOLLOW, прежде чем узел выйдет из состояния orphan и станет writeable.Вместе с SUBSCRIBE реплика посылает свой
instance_vclock (по vclock мастер находит первый нужный ей файл журнала), instance_uuid и cluster_uuid (для проверки регистрации в кластере). При обработке SUBSCRIBE мастер сперва проверяет права, а затем зарегистрированность реплики в кластере. Далее мастер проверяет, что файлы журнала (.xlog), содержащие данные с instance_vclock, еще не удалены сборкой мусора, о которой я расскажу ниже.Если все проверки пройдены, то мастер отвечает реплике своим текущим vclock. Будем называть его start_vclock. За start_vclock следует бесконечный — до разрыва соединения или другой ошибки — репликационный поток, содержащий все выполнявшиеся и выполняющиеся на мастере операции (начиная с instance_vclock). На мастере этот поток генерирует отдельный поток — relay, — читающий все файлы журнала с нужного места и построчно отправляющий их реплике.
Чтобы можно было понять, к какой транзакции относится операция в журнале и репликационном потоке, мы присваиваем каждой операции не только LSN, про который я рассказывал в главе про хранение данных, но и TSN — transaction sequence number. TSN для каждой операции в транзакции одинаковый и равен LSN первой операции. Реплика, руководствуясь TSN приходящих в потоке репликации операций, собирает их обратно в транзакции, после чего применяет и пишет их в свой журнал. Таким образом журнал реплики становится почти полной копией журнала мастера (при условии, что не используются триггеры на репликацию).
Теперь поговорим о правиле, по которому соединение с мастером переходит из состояния SYNC в FOLLOW. Одна из основных характеристик соединения — отставание реплики от мастера, то есть время между попаданием записи в журнал мастера и получением этой записи репликой. Мы это отставание называем «лагом» репликации.
Переход соединения из состояния SYNC в FOLLOW происходит, как только начинают выполняться два условия:
- Лаг репликации не больше
box.cfg.replication_sync_lag(по умолчанию 10 секунд). - Реплика получила все данные вплоть до start_vclock (то есть до vclock, который был у мастера на момент соединения).
Как упоминалось выше, процесс SUBSCRIBE бесконечен, он может быть прерван лишь из-за возникновения ошибки или пропажи мастера/реплики. Для обнаружения пропажи другой стороны общения и мастер, и реплика используют тайм-ауты. Тайм-аут репликации конфигурируется опцией
box.cfg.replication_timeout, по умолчанию равной одной секунде.В отсутствие новых изменений для отправки мастер посылает реплике пинги с частотой раз в
box.cfg.replication_timeout. На пинг, как и на получение обычной транзакции, реплика отвечает пакетом ACK, содержащим ее текущий vclock.По vclock в ACK-пакете реплики мастер следит за тем, какие данные реплика действительно получила и применила, управляет сборкой старых файлов журнала и считает количество узлов, применивших синхронную транзакцию (ждать кворума).
Если от мастера или реплики нет вестей в течение четырехкратного
replication_timeout, то другая сторона рвет соединение. По чьей бы вине это ни происходило, после каждого разрыва реплика пытается переподключиться к мастеру раз в replication_timeout.Как реализован мониторинг репликации?
Следить за репликацией помогает таблица
box.info.replication. Она содержит информацию обо всех узлах, зарегистрированных в спейсе _cluster. Вся доступная информация о реплике с идентификатором id находится в box.info.replication[id]. Выглядит это так:> box.info.replication[3]
—--
id: 3
uuid: 67d66a88-59ad-4348-881f-09ebb6eb119f
lsn: 5
upstream:
status: follow
idle: 0.73756800000046
peer: localhost:3303
lag: 0.0002129077911377
downstream:
status: follow
idle: 0.064674000001105
vclock: {1: 3, 3: 5}
lag: 0
...
Поля
id, uuid и lsn обозначают именно то, что вам кажется. А вот в upstream и downstream я и сам путался, пока не выработал правило «большого пальца»:Upstream — сверху по течению к нам что-то приходит. Это состояние входящего потока репликации (от удалённого сервера к нам), который обрабатывается applier’ом.
Поля upstream:
status— повторяет состояние соединения (например,connect,auth,sync,follow);Idle— время (в секундах) с получения последнего пакета;peer— соответствущая строка изbox.cfg.replication;lag— лаг репликации.
Downstream — от нас что-то утекает вниз по течению. Это состояние исходящего потока репликации (от нас к удалённому серверу), который генерируется relay’ем.
Поля downstream:
status— либоfollow, либоstoppedв зависимости от того, порвано соединение, или нет;Idle— то же, что вupstream: время, прошедшее с получения последнего пакета от реплики;vclock— последний сообщенный репликой vclock;lag— лаг, вычисленный с точки зрения мастера. Это время, прошедшее с попадания очередной операции в журнал мастера и получением подтверждения этой операции от реплики. Если представить, что часы на реплике и мастере идеально синхронизированы; и если посмотреть на upstream.lag реплики и downstream.lag мастера, то выяснится, что downstream.lag равен upstream.lag + время на доставку ACK-пакета от реплики мастеру.
Если соединение будет разорвано, то соответствующий upstream или downstream приобретает новые поля
message и system_message, дающие информацию о произошедшей ошибке. Например: upstream:
peer: localhost:3303
lag: 9.8943710327148e-05
status: disconnected
idle: 4.1842909999978
message: 'connect, called on fd 19, aka 127.0.0.1:65001: Connection refused'
system_message: Connection refused
Или
downstream:
status: stopped
message: 'unexpected EOF when reading from socket, called on fd 26, aka [::1]:3302,
peer of [::1]:64955: Broken pipe'
system_message: Broken pipe
Сборка мусора XLOG/SNAP
Количество хранящихся на диске снапшотов регулируется опцией
box.cfg.checkpoint_count, а периодичность создания снапшотов — box.cfg.checkpoint_interval. Новый снапшот создается раз в checkpoint_interval секунд, и, как только количество снапшотов достигает checkpoint_count, создание каждого нового приводит к удалению самого старого снимка.В начале статьи я говорил, что Tarantool хранит все файлы журнала после самого старого снапшота. Это нужно для того, чтобы можно было восстановиться из любого из
checkpoint_count-снапшотов. Также хранятся файлы, которые востребованы хотя бы одной из реплик.Как мастер понимает, какие файлы нужны репликам?
Для каждой реплики хранится информация о последнем полученном ею vclock. Эта информация заполняется в момент JOIN тем vclock, который реплика получает изначально, а также в момент SUBSCRIBE vclock, присланный репликой. Далее vclock, нужный каждой реплике, обновляется по мере прихода от нее ACK-пакетов.
Информация о том, какие файлы журнала ещё нужны репликам, не сохраняется на диске, поэтому после перезапуск сервер может удалить все лишние, по его мнению, .xlog. Если такое происходит, то вернуть реплику в кластер можно только с помощью повторного JOIN: нужно удалить все ее данные с диска и запустить заново. Во избежание таких ситуаций, существует параметр
box.cfg.wal_cleanup_delay. Он измеряется в секундах и задает время простоя сборщика мусора сразу после перезапуска сервера. По умолчанию box.cfg.wal_cleanup_delay равен 4 часам, и первые 4 часа после запуска мастер не удаляет старые .xlog-файлы, чтобы дать репликам возможность переподключиться и сообщить, какие файлы им действительно нужны. Посмотреть на состояние сборки мусора можно в box.info.gc() — там будут перечислены все реплики и требующиеся им vclock, а также все снапшоты.Анонимные реплики
Исторически сложилось, что в кластере не может быть зарегистрировано более 31 узла. Связано это с тем, что каждый узел получает свой уникальный id и занимает место в vclock. Vclock не может расти бесконечно, ведь им регулярно обмениваются узлы кластера: его содержит каждый ACK-пакет. Слишком длинные vclock могут занимать больше пропускной способности канала, чем полезные данные, поэтому размер vclock ограничен 31 «ячейкой» для сервера, и значит зарегистрированных членов в кластере не может быть больше 31.
Обойти это ограничение помогают анонимные реплики — особые подписчики на изменения, не занимающие места в спейсе
_cluster. Им не требуется регистрация для работы, но платой за это является то, что они не могут генерировать никакие изменения (кое-какие все же могут: в локальные и временные спейсы, про это в следующей главе). В кластере может быть сколько угодно анонимных реплик. Каждая из них read-only, обладает полным набором данных и может обслуживать read-запросы. Можно строить различные сложные топологии: цеплять одну анонимную реплику к другой, а ту, в свою очередь, к основной части кластера
Для того, чтобы создать анонимную реплику, ей нужно передать при начальной конфигурации параметр
replication_anon = true. Тогда вместо запроса JOIN реплика отправит мастеру FETCH_SNAPSHOT — тот же JOIN, но без регистрации реплики в кластере, поэтому он ограничивается только стадией INITIAL. После FETCH_SNAPSHOT последует SUBSCRIBE, его Единственное отличие от обычного — отсутствие проверки регистрации в кластере.Снапшот, созданный на анонимной реплике, не самодостаточен: в нем нет записи о реплике в спейсе
_cluster. Восстановиться из такого снапшота может только анонимная реплика.Локальные и временные спейсы
Не все данные нужно реплицировать: бывает, нужно хранить данные только на одном сервере без репликации. Для этого существуют локальные — или replica-local — спейсы.
Все данные, хранящиеся в таком спейсе, попадают в журнал, но не реплицируются.
Поскольку данные в локальных спейсах влияют лишь на состояние сервера, но не всего кластера, операции с локальными спейсами не увеличивают LSN сервера и не меняют его компонент в vclock. Вместо этого операции с локальными спейсами увеличивают выделенный LSN, хранящийся в
vclock[0] и не закреплённый ни за одним узлом. Таким образом, нулевой по счету компонент vclock на каждом сервере свой и не совпадает с vclock[0] других серверов. Существуют ещё и временные спейсы. Данные в них не только не реплицируются, но и не попадают в журнал и снапшот. Во временные спейсы тоже можно писать на read_only-сервере. Записанные данные будут храниться в спейсе, пока работает сервер. После перезапуска сервера временный спейс опустеет.
Поскольку данные в локальном или временном спейсе никак не влияют на соседние узлы, заполнять локальный спейс может даже сервер, находящийся в режиме read_only. Это значит, что такими спейсами могут пользоваться анонимные реплики. Есть лишь одна особенность: создать локальный или временный спейс можно только на writeable-сервере, после этого он появится на всех серверах. Каждый сервер сможет наполнять его независимо от остальных.
Триггеры
Очень широкий простор для воображения дают триггеры. Проще продемонстрировать все возможности с помощью примеров. Не все примеры пригодятся вам в обозримом будущем, но знать о своих возможностях всегда полезно :)
Пример 1.
На реплике заменим движок спейса
huge_space c memtx (in-memory) на vinyl (дисковый):function _space_before_replace(old, new)
if old == nil and new ~= nil and new[3] == 'huge_space' and
new[4] == 'memtx' then
return new:update{{'=', 4, 'vinyl'}}
end
end
box.ctl.on_schema_init(function()
box.space._space:before_replace(_space_before_replace)
end)
Триггер
on_schema_init работает в момент инициализации узла. Он позволяет поставить триггер на системный спейс _space, хранящий информацию обо всех спейсах в базе, позволяющий заменяет запись о движке требуемого спейса прямо в момент попадания записи о создании спейса на реплику.Пример 2.
На реплике будем игнорировать все приходящие с мастера изменения спейса
unneeded_space и считать количество проигнорированных изменений в переменной skipped_changes.local skipped_changes
function empty_space_trig(old, new)
if box.session.type() == 'applier' then
skipped_changes = skipped_changes + 1
return old
end
return new
end
function make_space_empty(old, new)
if old == nil and new[3] == 'unneeded_space' then
box.on_commit(function()
box.space.unneeded_space:before_replace(empty_space_trig)
end)
end
end
box.ctl.on_schema_init(function()
box.space._space:on_replace(make_space_empty)
end)
В триггере
empty_space_trig будем проверять, откуда пришло изменение. Если оно пришло от мастера, то игнорируем его. Чтобы не пропустить ни одного изменения с мастера, ставим триггер на спейс unneeded_space прямо в момент создания этого спейса. Этим занимается функция make_space_empty. Как только создание спейса будет закоммичено (см. box.on_commit() в коде примера), на спейс будет повешен before_replace триггер. Как мы знаем из первого примера, чтобы поймать момент создания нужного нам спейса необходимо поставить триггер на спейс _space.Скачать Tarantool можно на официальном сайте, а получить помощь — в Telegram-чате.
