

Привет! На связи Олег Уткин из отдела архитектуры систем хранения данных Tarantool. Я хочу рассказать, как в ходе проекта для Московской биржи мы консолидировали потоки данных из разных торговых систем и наладили их доставку клиентам. По пути мы собрали много граблей и сделали несколько интересных выводов, которыми я далее поделюсь.
Краткий экскурс в нашу задачу
В прошлом году к нам обратились коллеги с Московской биржи с задачей разделения торговых ядер. Это нужно, чтобы проводить сделки на разных торговых ядрах по различным критериям и со своими инструментами. Например, одни валютные пары на одном торговом ядре, другие — на другом. Или выделить отдельное ядро для конкретной ценной бумаги и всех сделок с ней.
Для чего это нужно. Такие серьезные архитектурные изменения очевидно должны окупаться. Зачем это бирже? В первую очередь для масштабирования на запись — чтобы обрабатывать больше сделок в секунду.
Еще это позволяет минимизировать риски. Представьте себе выход на биржу очень крупной компании вроде Сбербанка. Поскольку на бирже так или иначе происходит много разных процессов, листинг ценных бумаг может каким-то образом аффектиться другими процессами. Для минимизации рисков, чтобы сделка не сорвалась, биржи запускают такие вещи на отдельных торговых ядрах.
При переходе на отдельные ядра важно, чтобы клиенты не видели, что происходит. То есть уже есть существующие протоколы, трейдеры и брокеры каким-то образом уже получают нужные данные, они не должны заметить изменений или задержек. Плюс важно, чтобы система масштабировалась и на чтение, и на запись, не возникало узкого горлышка.
Как работает торговля на бирже
Чтобы понимать, с какой именно задачей мы столкнулись, давайте обсудим, как работает биржа. Буквально на пальцах.
Сперва мы определим, что такое заявка, или торговый ордер. Это желание кого-то одного купить что-то при каких-то ограниченных условиях. Эта заявка попадает в биржевой стакан, и встречается с другой заявкой, которая находится там же – получается сделка.
В результате заявка меняет свой статус вместе с той, с которой она встретилась, и что-то происходит. Либо если заявка долго находится в стакане, а сделка не происходит, инициатор может ее снять.
Так работает мастер торгового ядра. Это однопоточное приложение, которое занимает всю память на сервере и горизонтально масштабируется на чтение за счет реплик. Реплики — это такие же копии торговых ядер, только на них направляются абсолютно такие же заявки в том же порядке. Когда все хорошо (а так почти всегда) реплики практически не отстают от мастера. Иногда даже опережают. Они периодически сверяются по чек-суммам и являются серверами доступа. К репликам и подключаются трейдеры и брокеры.
Структура системы реплик
Мы в первую очередь работали с ордерами, то есть торговыми заявками и их доставке потребителям. Определим некоторые вещи, которые с ними связаны:
Глобальные счетчики. В бирже в торговом ядре есть счетчик, который монотонно увеличивается при добавлении каждой новой записи. Очень похоже на первичный инкрементированный ключ. Это rec, он же record number.
Есть еще другой счетчик – seq (sequence number), который работает более интересно — увеличивается с каждым апдейтом, который происходит на торговом ядре. То есть если какая-либо заявка обновляется, что-то с ней происходит, этот счетчик увеличивается на 1.
Эти два поля есть во всех заявках, чтобы клиенты могли получать максимально свежие данные.
Система доставки. Клиент имеет пару rec и seq и знает — в бирже был какой-то апдейт с каким-то номером и есть запись с другим номером. Он просит максимально свежие данные, изменившиеся или новые. Получает их, берет из последней заявки следующую пару rec и seq, и использует ее как continuation token. Таким образом, клиенты получают данные постоянным поллингом. Они хотят, чтобы данные всегда были самыми свежими.
Также здесь есть запрос на чтение по вторичным ключам, поскольку не все пользователи хотят видеть все данные. Некоторым нужна только фирма, в которой происходит торговля, либо данные конкретного брокера.
Требования к системе доставки данных и выбор решения
Зная все условия, мы готовы сформулировать требования к этому черному ящику. На один узел система должна уметь принимать до 200 тысяч транзакций в секунду. При этом между сделкой на бирже и информированием о ней клиента должно быть в среднем 1 мс. А в 99% случаев нужно укладываться в 5 мс.

Кажется, что это похоже на очередь: какие-то события происходят, а клиенты получают эти события. Но фактически все не совсем так. Биржа дает только изменившиеся данные, а клиенты хотят видеть картину целиком. Соответственно, нужно отдавать состояние. А если клиент отстал на несколько микросекунд или миллисекунду, то появились более свежие данные. И клиент не хочет видеть старые, он хочет видеть свежие.
Поэтому нам и требуется такая производительность и отставание. При этом клиент не должен знать о разделении, то есть нужно отдавать данные без пропусков и гарантировать их порядок.
На самом деле мы имеем дело одновременно с базой данных, очередью c индексами и кешем со вторичными индексами. Получается, что нужно либо писать систему полностью с нуля, либо взять инструмент, который обладает всеми этими свойствами: может быть очередью и очередью с индексами, может гарантировать latency.
Мы предположили, что для этой задачи может подойти Tarantool, поскольку он:
Такой же однопоточный in-memory, как ядро биржи.
Написан на С.
Имеет эффективный асинхронный протокол с мультиплексированием.
Фактически является фреймворком для строительства баз данных.
Уже имеет систему хранения и индексации, то есть есть вторичные ключи таблицы и первичные ключи.
Может хранить данные на диске и их восстанавливать, есть репликация с шардингом.
Кажется, что все сходится, но есть нюансы. Дальше когда будем говорить о технологии, станем вести некий счетчик целесообразности использования технологии.
Работа с индексами
У нас есть два ключевых поля: rec и seq. Они означают номер заявки и номер изменения. Эти поля позволяют клиентам пагинироваться по данным. При каждом insert у нас инкрементируется rec, а при каждом update — seq. Когда клиент приходит за данными, мы можем быть уверены, что он получит самые свежие версии данных об ордерах в нужном порядке и у нас не будет пропусков. Чтобы понять, как это реализовать, давайте разберемся, как работают составные индексы.
У нас есть составной индекс, состоящий из двух полей: field1 и field2. Допустим, мы хотим выбрать некоторую запись, которая будет сходится по ключу 2 и 3. Что нужно для этого сделать? Мы идем по первому полю, ищем двойку. И уже отсюда дальше двигаемся и ищем тройку. Такой прыжок будет у нас занимать логарифмическое время.

Найдя этот момент в индексе, мы можем дальше продолжать итерироваться по данным, как по связанному списку, поскольку у нас используются В+ деревья, в которых все листы прошиты связанным списком. То есть мы дошли до некоторого места в индексе, и дальше спокойно можем за константное время переходить к следующему элементу.
Как это будет выглядеть в нашем случае? У нас есть поля rec и seq. На первое место мы ставим seq, поскольку это поле означает свежесть данных. В индексе лежит некоторый ордер, который мы хотим обновить. Для этого инкрементируется seq, и ордер дальше прыгает в индексе. Затем инкрементируется rec. Так мы уверены, что ордер находится в самом конце индекса.

Аналогичная ситуация со вставкой — у данных, которые приходят от торгового ядра, всегда будет максимальный seq.
Нам достаточно выставить максимальный rec и вставить данные. Так мы гарантируем, что самые свежие данные находятся в конце индекса. Когда клиент придет, он сможет проитерироваться и забрать данные, которых у него еще нет. В этом случае Tarantool очень хорошо нам подходит, потому что в нем есть такая возможность.
Реализация хранилища и проблемы с операциями чтения
Хранилище у нас было реализовано на Tarantool. Очевидно, хранилище хранит данные. Кроме того, внутри оно содержит логику обработки этих данных.
В рамках тестирования у нас не было доступа к реальному стенду заказчика — мы не могли проверить работу на реальных данных и нагрузке от клиента. Поэтому нам нужно разработать некоторые эмуляторы для локальной отладки. Эти эмуляторы позволили нам собирать большое количество метрик, чтобы делать какие-то выводы о производительности и способах ее оптимизации.
Мы начали с максимально простой архитектуры. У нас было две процедуры: ApplyEvent просто принимает данные и кладет их в хранилище, а GetOrders умеет отдавать данные клиенту.

Работает все следующим образом. Клиент приходит с некоторым ключом — rec и seq, которые означают, в какой момент времени клиент начал читать данные. Когда он в следующий раз приходит с этим ключом, он может быть уверенным, что данные будут свежее прошлых.
Данные, которые приходят с торгового ядра — это события: о том, что заявка создана, удалена или обновлена. Клиенту данные уже идут в виде конечного состояния. То есть клиент получает последнее обновление, которое было в торговом ядре.
Тестировать мы начали с нагрузки по записи. Нам нужно было 200 тысяч транзакций в секунду на запись, но мы легко выжимали больше 250 тысяч и даже доходили до 340 тысяч.

Затем решили протестировать чтение и обнаружили проблему. В какой-то момент времени при увеличении количества клиентов отставание клиента от торгового ядра резко возрастает. Причем рост происходит бесконечно — система уже не может из него вернуться. Наше хранилище перестает успевать принимать данные из торгового ядра, поэтому отставание увеличивается все сильнее.

Анализ и решение проблемы с отставанием при чтении
Чтобы решить эту проблему, нам нужно было наглядно замерить, насколько отстают клиенты. При генерации ордера в него кладется время создания. Когда клиент его получает, он может сравнить время создания и время прибытия, чтобы отдать это в систему мониторинга. Так мы обнаружили резкий рост задержки.
Мы начали искать источник проблемы. И при анализе потребления CPU обнаружили, что сетевой поток Tarantool перегружен. То есть он не может адекватно обрабатывать не только запросы от клиентов, но и данные из торгового ядра.
Обнаружили и еще одну странность — у нас резко возрастал RPS от клиента. То есть клиент начинал часто ходить в нашу систему. При этом latency таких запросов очень низкий — то есть клиент приходит часто, но запросы у него короткие. Значит, он не получает нужные данные.
Получился целый набор симптомов: перегружен сетевой поток, резко выросли RPS клиентов, клиентские запросы стали очень короткими. Почему такое могло произойти?

В норме клиенты забирают данные из очереди, с отставанием от торгового ядра. Но бывает, что клиент становится быстрее ядра — и кусочки данных, которые он берет, становятся очень маленькими. В итоге он делает все больше запросов, сильнее нагружает систему и замедляет прием данных от торгового ядра, еще больше усугубляя ситуацию.
Чтобы это прекратить, мы решили мониторить, какое количество пустых ответов мы отдаем клиенту. После замеров оказалось, что таких ответов более 80%. И связь роста количества пустых ответов как раз совпадает с тем моментом, когда у нас происходит резкий рост задержки клиента торгового ядра. Так мы нашли проблему — теперь ее нужно было решать.
Мы решили сделать так. Когда новые данные приходят в систему, мы смотрим, насколько эти данные свежи, и сохраняем информацию о самом последнем ордере, который пришел в нашу систему.
Когда клиент приходит с некоторым ключом, мы понимаем, что этих данных в системе может не быть. В таком случае мы усыпляем клиента, пока не придут новые данные, либо пока не пройдет таймаут. Это очень удобно реализовать в Tarantool, поскольку у него есть некое подобие корутин, файберы и есть condition variable, которые умеют усыпить файбер и разбудить его. То есть когда приходят новые данные, мы можем разбудить клиента просто из процедуры, которая пишет данные.
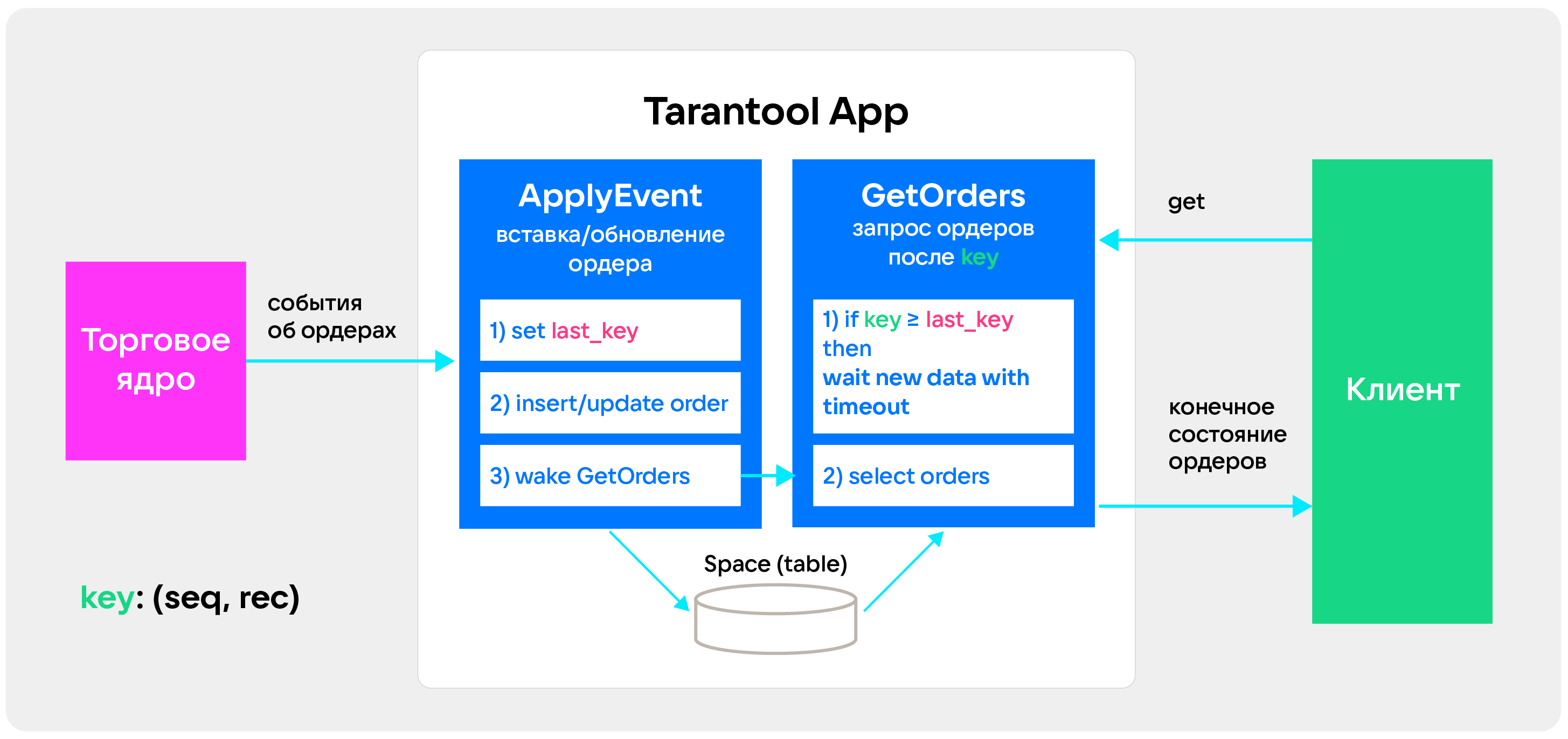
Когда клиент просыпается, ему не приходится пересоздавать новый итератор — он переиспользует свой. То есть чтобы продолжить итерацию, нам не нужно за логарифмическое время опять искать позицию в итераторе, в индексе.
В итоге у нас почти не осталось пустых ответов и резко снизилось количество пакетов в секунду — мы разгрузили поток Tarantool более чем на 15%.
Работа с размером ответов
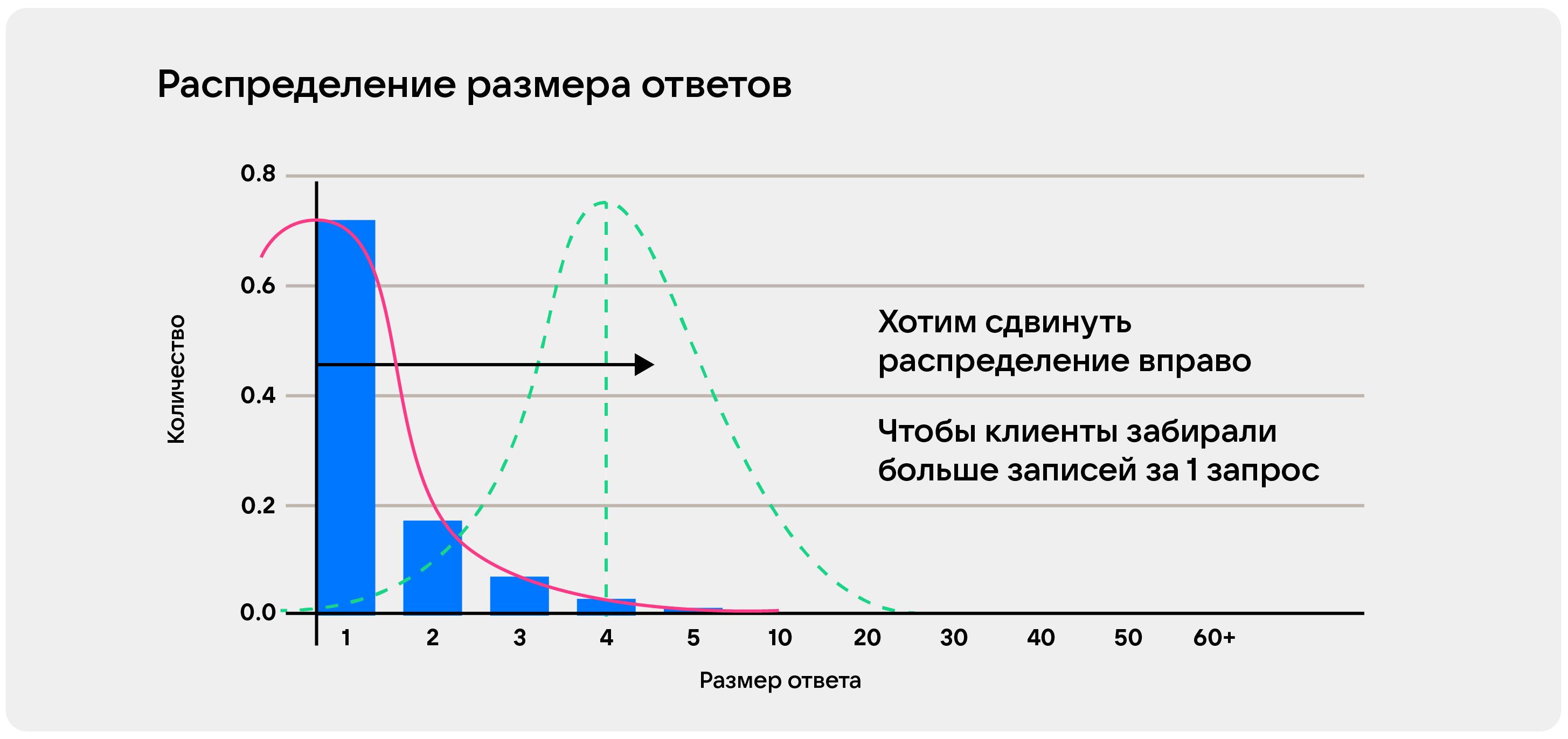
Мы поняли, что число отдаваемых данных – очень важная метрика, за которой нужно следить. Тогда мы решили собирать, сколько данных приходит клиенту. Это было удобно сделать в вид, гистограммы по времени:

Здесь хорошо видно, что пустых ответов уже нет. Но при этом пачки все еще очень маленькие— пик приходится на единицу. Хорошо бы этот пик сдвинуть правее, то есть увеличить размер пачки, которую будут получать клиенты.
В итоге мы упростили систему. Функция, которая принимает данные, вернулась в изначальное состояние — она просто кладет данные в хранилище. Процедура, которая собирает данные, делает select. Если она понимает, что нужных данных нет и клиенту уйдет слишком маленькая пачка, она засыпает. А через некоторое время делает select снова. Если мы укладываемся в latency запроса, можем сделать это еще раз — в противном случае отдаем данные, как есть. Такая оптимизация дала серьезный прирост размера пачки— с 1 до 20.
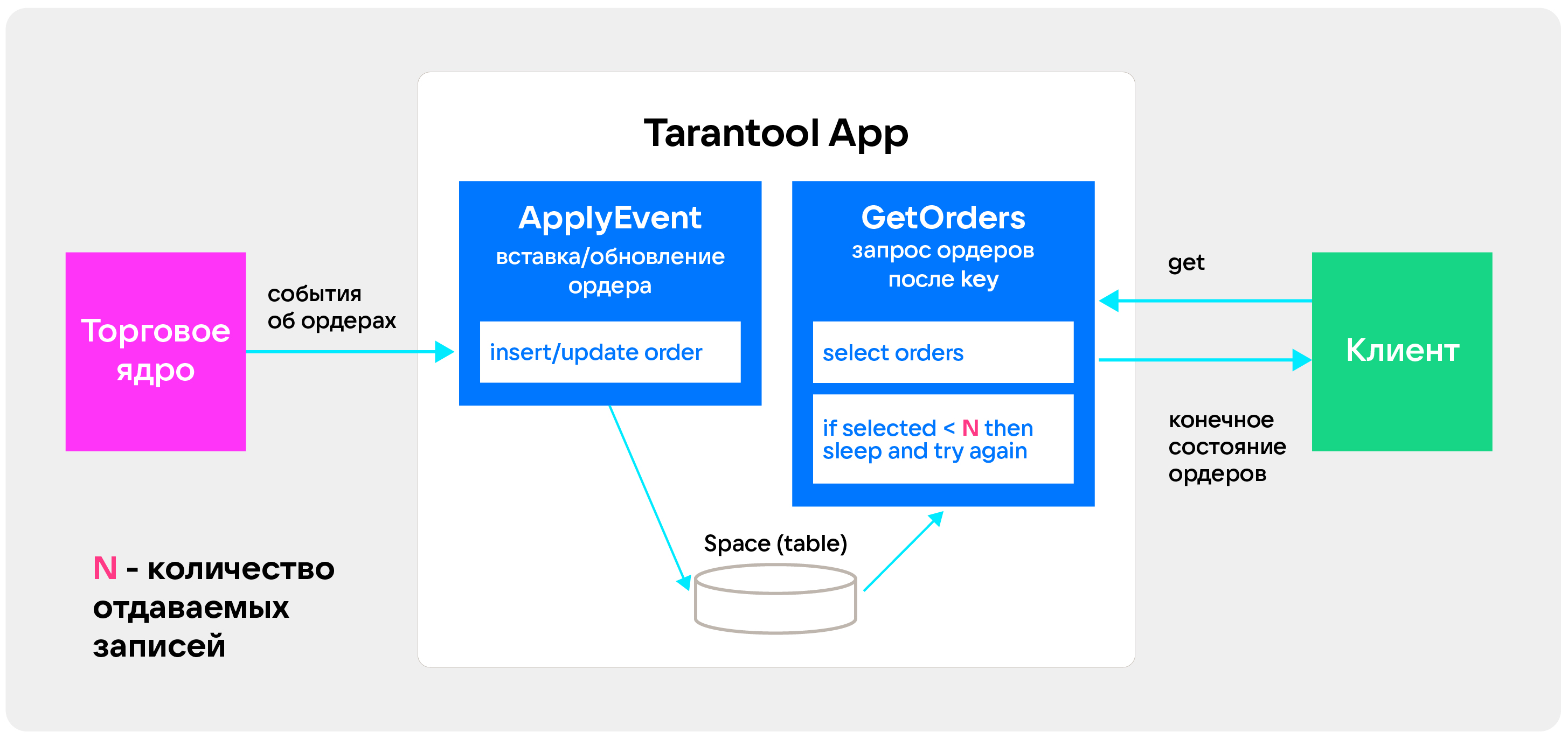
Время ожидания зависит от того, насколько большую пачку мы хотим отправлять. Размер лучше выбирать экспериментально. В этом нам очень помогает метрика, которую мы собираем по отставанию клиента от торгового ядра, а также размер пачки. Мы решили померить, и вот что получилось:

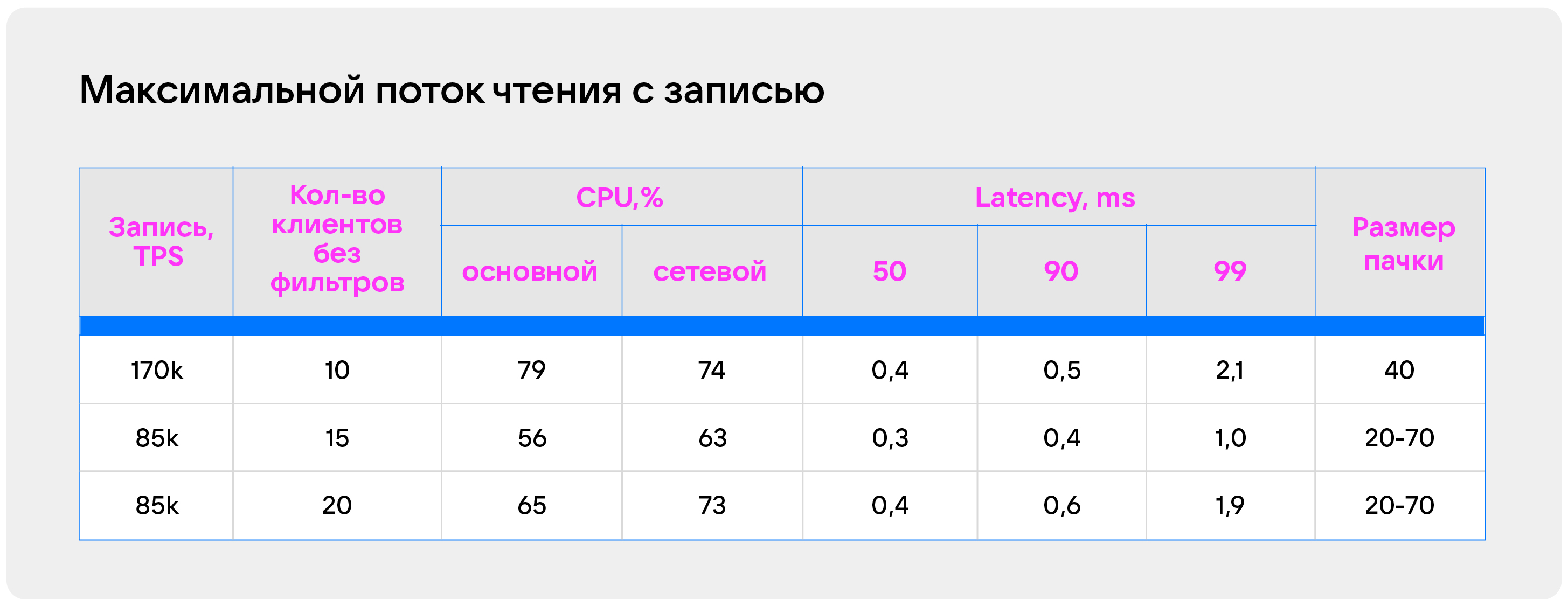
При таком подходе можно накапливать пачки до 70 элементов, что сильно разгружает сетевой поток и позволяет нам оставить latency очень низким. Тут надо понимать, что это лонгполлинг, но только в размере 0,5 мс. Как правило, данные приходили в течение сотен микросекунд. . Поэтому можем это назвать шортполлингом в каком-то смысле.
Разделение торгового ядра на шарды
Нам нужно было поделить торговое ядро на кусочки — шарды. Но так, чтобы клиент не знал о сложности шардирования и продолжал получать данные в нужном порядке.
Изначально у нас есть одно торговое ядро. Чтобы клиент получил данные, ему нужен один ключ, seq и rec. Он может по этому ключу забирать данные из одного торгового ядра. Но с двумя ядрами возникает проблема: клиенту нужно знать, где какие данные лежат и иметь ключ для каждого ядра.
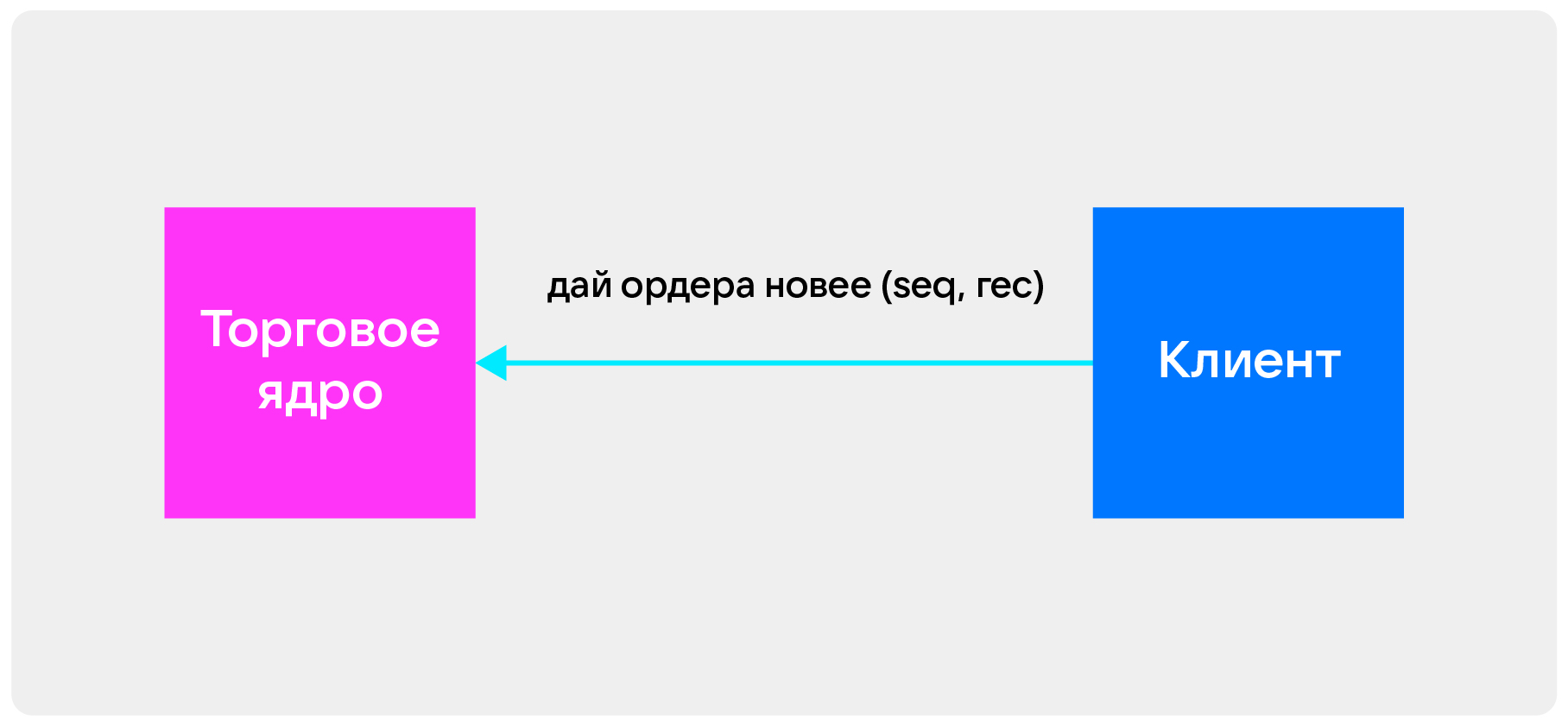
Для решения этой проблемы можно ввести распределенный суррогатный ключ. Он может работать на том же протоколе, что и раньше. Но либо появляется единая точка отказа, либо данные должны быть согласованы — а это сильно замедлит работу.
Мы решили не брать суррогатный ключ и использовать векторные часы. Они скрывают сложность шардинга — клиенту достаточно иметь ключ, который ему отдаст наша система. В следующий раз он может с этим ключом прийти, дать этот ключ роутеру — и роутер сам определит, из какого шарда нужно забрать данные и как их смержить.
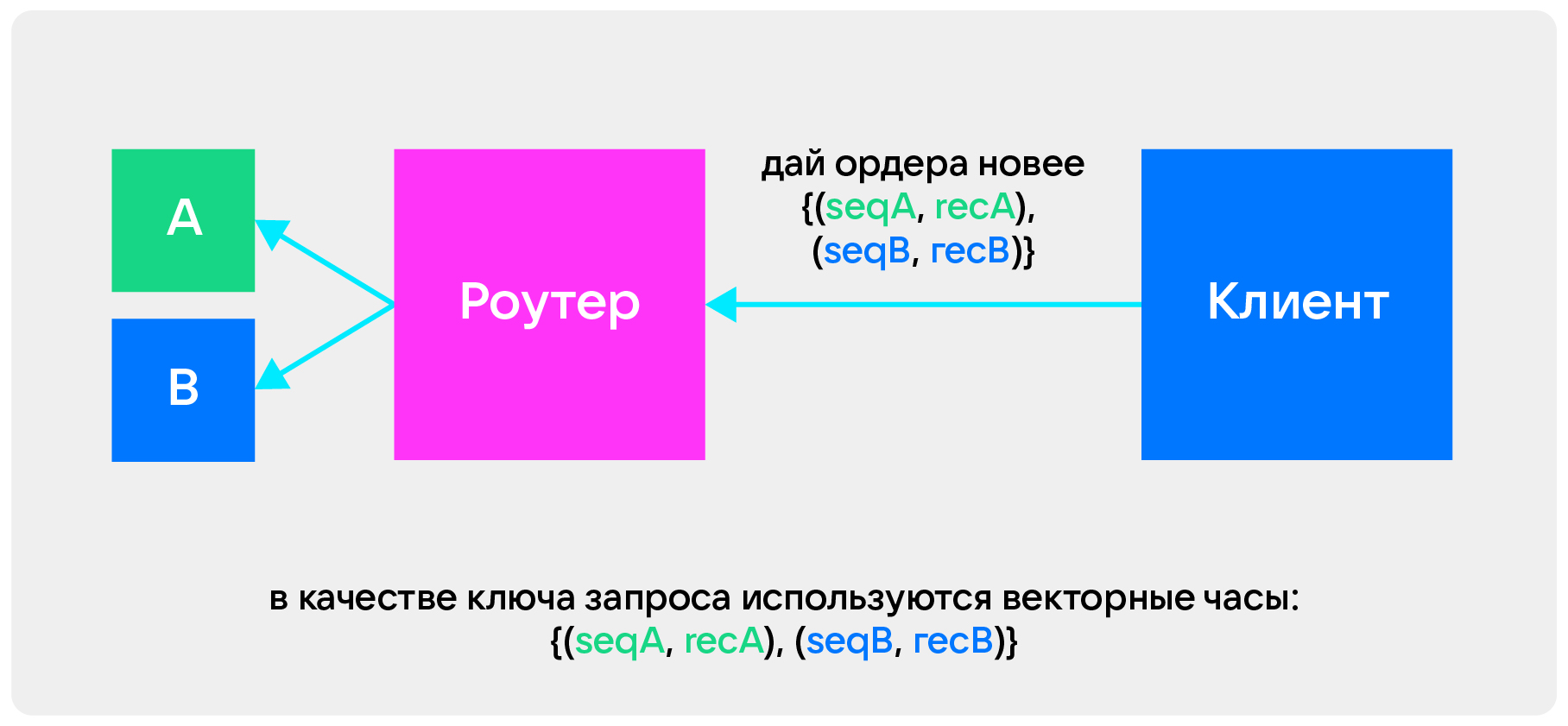
В итоге шардинг у нас стал выглядеть так:

У нас есть несколько источников — кусочков разделенного торгового ядра. Эти кусочки мы можем как хотим поделить на шарды: дублировать, делать реплики, — все для гибкого масштабирования по чтению.
Тут стоит вспомнить, что у нас два вида клиентов:
Первый вид — клиенты, которые хотят получать некоторое подмножество данных, фильтруя его. Им важна низкая задержка. Это могут быть различные брокеры и трейдеры, которым нужен только какой-то определенный инструмент, например свои заявки.
Второй вид — клиенты, которым не нужна фильтрация. Они получают весь поток данных, который приходит с торгового ядра. При этом им минимальная задержка не нужна.
Поскольку мы знаем, что минимальная задержка в нашей системе находится на мастерах, туда мы можем вынести клиентов с фильтрацией. Остальных можно унести в реплику:

Мы знаем, что клиентам без фильтрации не нужны не только фильтры, но и индексы. Поэтому мы можем сделать реплики, в которых не будет индексов — так мы сэкономим на репликации и на памяти. С таким подходом мы получаем следующую картину:

Нам удается сохранить очень низкую задержку у клиентов, которым она важна, потому что большое количество клиентов мы выносим на реплики. Причем реплики имеют некоторое отставание — это позволяет поддерживать низкое время отставания клиентов от источников, сохраняя среднее время отставания в одной миллисекунде.
Метаданные для диагностики и оптимизации
Есть некоторое тело ответа, которое приходит от системы клиенты. И есть некоторые метаданные — информация о том, сколько времени какие операции в хранимой процедуре происходили. В итоге во время диагностики системы мы будем понимать, где и что медленно работает.
В метаданные мы кладем самый последний курсор в пачке. То есть клиент может взять этот курсор, не читая данные дальше, и сразу же делать следующий запрос.
Еще мы читаем, когда была создана самая старая запись в пачке. Причем все эти данные у нас находятся в заголовке в самом начале. В итоге чтобы сделать следующий запрос, клиенту достаточно читать только заголовок. То есть он считывает следующий курсор, сразу делает запрос и декодирует тело ответа до конца.
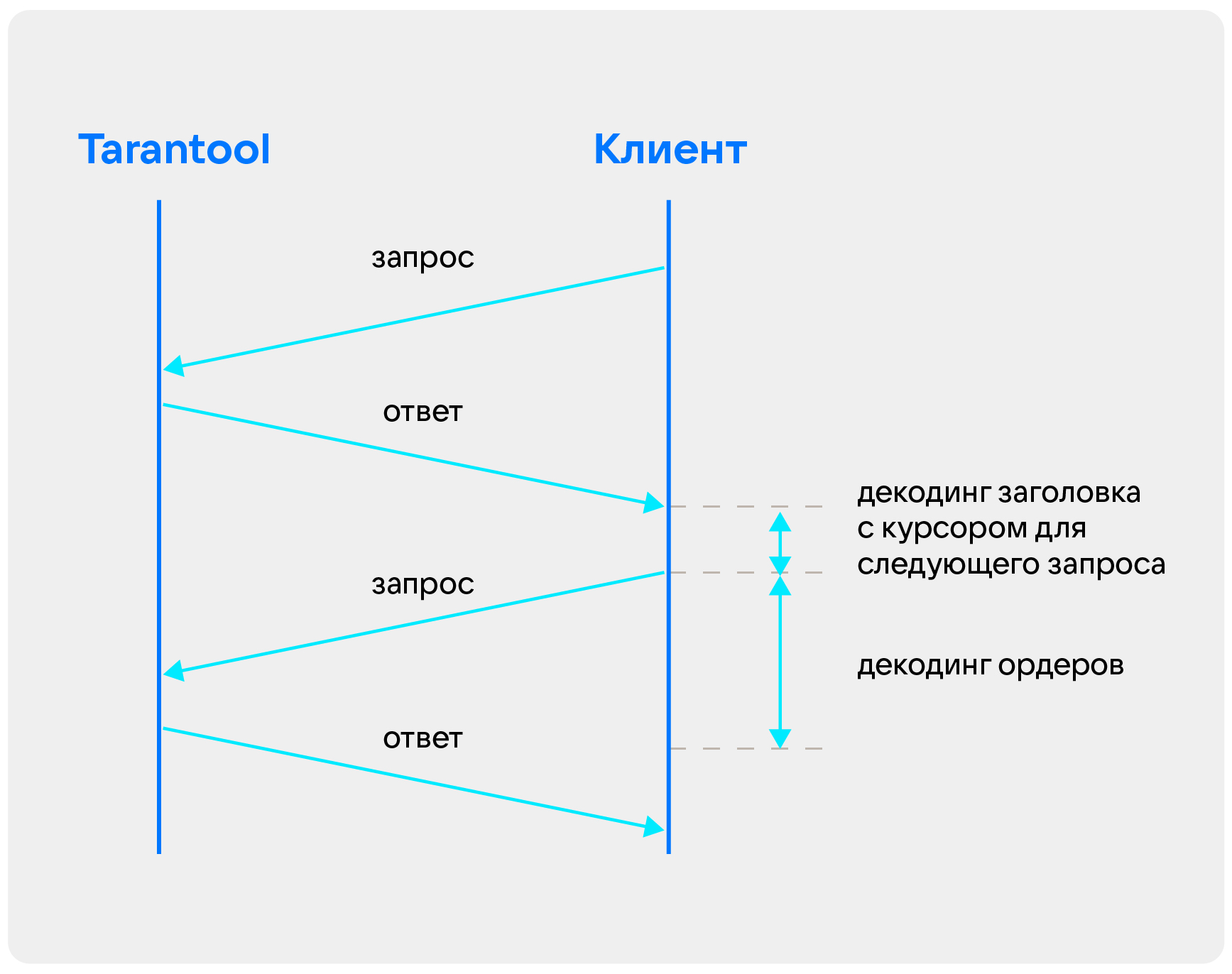
Это важно потому, что тело одного ордера занимает около 600 байт. И их целая пачка по 20-70 элементов. В итоге клиенту для чтения нужно было тратить большое количество данных — курсор в начале сообщения это оптимизирует.
Подробнее об эмуляторах
Выше мы писали, что для работы нам нужен был эмулятор. У нас их два типа: для торгового ядра и для клиента.
Эмулятор торгового ядра умеет генерировать ордера, которые дальше пойдут в систему. Причем в этот ордер он кладет время создания. Таким образом, когда ордер придет на клиента, мы можем посчитать время, за которое заявка прошла от торгового ядра до клиента. Еще он может изображать всплески — когда какие-то инструменты начинают торговаться намного интенсивнее. Умеет сохранять нужную нам скорость генерации данных и считать скорость, с которой на самом деле будут отдаваться данные. А потом все это отдавать в Prometheus.
Эмулятор клиента собирает большое количество метрик, в том числе трейсы, которые приходят из самого хранилища, и тоже отдает их в Prometheus, считая размер пачки. Так мы можем проследить, как работает система.
Есть еще ряд метрик, которые находятся в самом хранилище — Tarantool позволяет это сделать. Он собирает данные о том, насколько нагружены потоки по CPU, собирает метрики о хранилище (например скорость вставок, апдейтов и селектов), замеряет скорость роста таблицы. И тоже все это отдает.
Сначала работу мы тестировали на своем личном стенде. Для этого мы пользовались эмуляторами в виде утилит командной строки. Затем потребовалось протестировать систему на стенде заказчика. Причем без прямого доступа — у нас был человек, с которым мы могли говорить по Zoom, давать ему какие-то команды.
Мы решили как-то это оптимизировать объединили эмулятор торгового ядра в единый демон, который умеет автоматически по некому конфигу, профилю нагрузки, запускать нужные источники на нужный эмулятор торгового ядра и клиентов.

У нас есть некоторые полные описания, как должен выглядеть тест, конфигурация кластера, как должны быть настроены эмуляторы, клиенты и торговые ядра. Человеку на другом конце провода достаточно ввести одну команду, которая полностью все раздеплоит и запустит тест. Останется только отдать нам данные, которые накопились в Prometheus — и мы сможем эти данные анализировать у себя в дашбордах. По сути, у нас есть полная картина всего, что происходит в кластере во время теста.
Итоги проекта
Система умеет принимать 200 тысяч транзакций в секунду на один узел на запись.
Задержка в рамках нормы.
Клиент не знает о разделении, сложности шардирования и как наша система устроена внутри.
Данные клиенту даются в нужном порядке без пропусков.
Клиент всегда получает самые актуальные данные.
Система умеет быстро давать не только горячие данные, которые пришли потоково, но и холодные в пределах минуты или в пределах дня.
Мы успешно пропилотировали архитектуру распределенной системы доставки торговой информации с помощью Tarantool. Пилот был признан заказчиком успешным. В будущем будет развиваться дальше.
Мы сделали несколько выводов:
Если возникает какая-то проблема, прежде чем решать, надо научиться ее измерять. Находить ту метрику, которая коррелирует с моментом возникновения проблемы. ожно несколько недель биться над тем, что что-то не работает. Но пока нет метрики, бесполезно это решать. Сложную систему нужно строить итеративно от самого простого. На самом простом, как правило, возникают ошибки, в том числе самые сложные и необычные.
Важно мерить все бизнес-метрики и технические метрики: время прохождения через систему, iptraf-ng, утилизацию различных потоков и так далее.
Важно хранить это все в одном дашборде, чтоб наблюдать корреляцию происходящего. Например, вы видите рост количества пакетов в секунду, потребления сетевого потока и количества запросов. Можно сделать гипотезу, но не бежать и чинить, а найти метрику, которая эту гипотезу подтвердит или опровергнет.
Важно понимать, как работают алгоритмы. Мы описывали В+ дерево. Поэтому смогли складывать данные так, чтобы все свежие или обновленные были в конце дерева. Это позволило нам использовать итератор, который будет идти по этому дереву как по связанному списку.
Для скорости иногда полезно замедлиться. Если этого не сделать, можно наступить на любопытные грабли. Например, клиенты могут получать ошибки и приходить еще раз. Их нужно каким-то образом замедлять. Для этого можно использовать circuit breaker, либо вставлять искусственные задержки в само приложение.
Несмотря на то, что нам нужны доли миллисекунд задержки при высокой производительности, при высокой нагрузке мы все равно клиентов замедляем. Это эффективно работает вместе с контролем того, сколько записей мы отдаем клиентам.
И очень важно не бояться тестировать разные инструменты. Мы в ходе этого пилота брали в тест совершенно разные инструмент и версии — смотрели, как все работает. В итоге выбрали именно Tarantool, потому что он максимально подошел, и не пожалели.
Скачать Tarantool можно на официальном сайте, а получить помощь — в Telegram-чате.
