

Стандартный способ хранения логов Kubernetes на ноде неудобен: память ограничена, данные разбросаны, а многие аналитические инструменты просто не получится применять. Чтобы сделать хранение и работу с логами удобнее для разработки аналитических инструментов, логи можно перенести в бакет объектного хранилища S3.
Меня зовут Илья Нырков, я программист компании VK Cloud Solutions и разработчик облачных решений. На примере нашего облака я расскажу, почему вообще стоит обратить внимание на S3, как перенести и хранить логи кластера Kubernetes в бакет S3 и в чем преимущество этого решения.
Зачем в K8s нужно централизованное хранение логов
По умолчанию в Kubernetes логи хранятся на отдельных нодах. Для небольших проектов с низкой нагрузкой и редким обновлением этот вариант оптимален. Но из-за базовых ограничений памяти ноды он не подходит для больших систем с огромным количеством логом. Кроме того:
Данные, генерируемые в контейнеризированных приложениях, существуют, пока существует контейнер. Если перезагрузить или удалить под, логи вместе с другими данными будут удалены. Исправить подобные ошибки можно, но это создает дополнительные трудности.
Ротация логов в контейнере — дополнительный процесс. Чтобы запустить в контейнере больше одного процесса, нужен «костыль» в виде Supervisor. Но такое решение нарушает философию Docker: «1 контейнер — 1 процесс».
Обойти ограничения позволяет хранение логов во внешнем хранилище, в котором данные будут защищены от перезаписи и удаления.
Почему именно S3
S3 — распространенный стандарт хранилищ. Он подходит для больших объемов информации, может работать с любыми ее типами. То есть в S3 можно структурированно хранить практически неограниченное количество логов.
Еще одно его преимущество в совместимости с большинством приложений для аналитики больших данных, например со Spark, ClickHouse и Greenplum. Также в объектном хранилище можно организовать доступ к логам через сервис на базе EFK (Elasticsearch, Fluentd, Kibana) для просмотра информации в виде дашбордов и графиков. Это упрощает работу с большими данными и нахождение зависимостей.
Дополнительное достоинство S3 заключается в гибкости конфигурирования: можно взять любую из многочисленных готовых конфигураций S3 и легко адаптировать под свою «железную» или облачную инфраструктуру. Это позволяет быстро собирать нужные конфигурации без сложной перенастройки.
А еще после переноса логов в бакет S3 они начинают храниться отдельно от ноды. Это повышает надежность: даже если нода упадет, логи сохранятся. Но важно исключить риски отключения ноды от сети — в таком случае логи в S3 не запишутся.
Как настроить отправку логов кластера Kubernetes в бакет S3: пошаговая инструкция
Подробно рассмотрим все действия на примере S3 VK Cloud Solutions (Cloud Storage). Для справки: все описанные команды выполняются в консоли Linux (bash).
Регистрируемся на платформе VK Cloud Solutions. После входа в «Личный кабинет» нужно зайти в «Личный проект» или получить приглашение и перейти в проект другого пользователя.
Создаем виртуальную машину (ВМ) в облаке VK Cloud Solutions. Сделать это можно через соответствующий раздел интерфейса облака. При создании ВМ выбираем нужные параметры, в том числе подходящую под задачи операционную систему (ОС). При этом важно, чтобы на образ ОС можно было установить kubectl и Helm. Для примера берем Ubuntu 20.04.1.

Примечание: пункт необязательный — эти действия можно выполнить с обычной машиной на Linux. Настраиваем сеть виртуальной машины. Главное на этом этапе — указать настройки Firewall. Default стоит по умолчанию, дополнительно прописываем правило «ssh + www»: оно позволяет получать доступ к SSH, а также открывает порты ВМ для получения по протоколам HTTP и HTTPS.


Настройки резервного копирования не изменяем, для примера они не имеют значения.
Примечание: пункт необязательный — эти действия можно выполнить с обычной машиной на Linux.
Создаем простой кластер Kubernetes. Используем соответствующий раздел облака. При создании выбираем нужную конфигурацию и набор предустановленных сервисов.

Остальные шаги создания кластера можем пропустить.
Скачиваем конфигурационный файл кластера. Для этого через меню «Личного кабинета» переходим во вкладку «Контейнеры» и раздел «Кластеры Kubernetes».
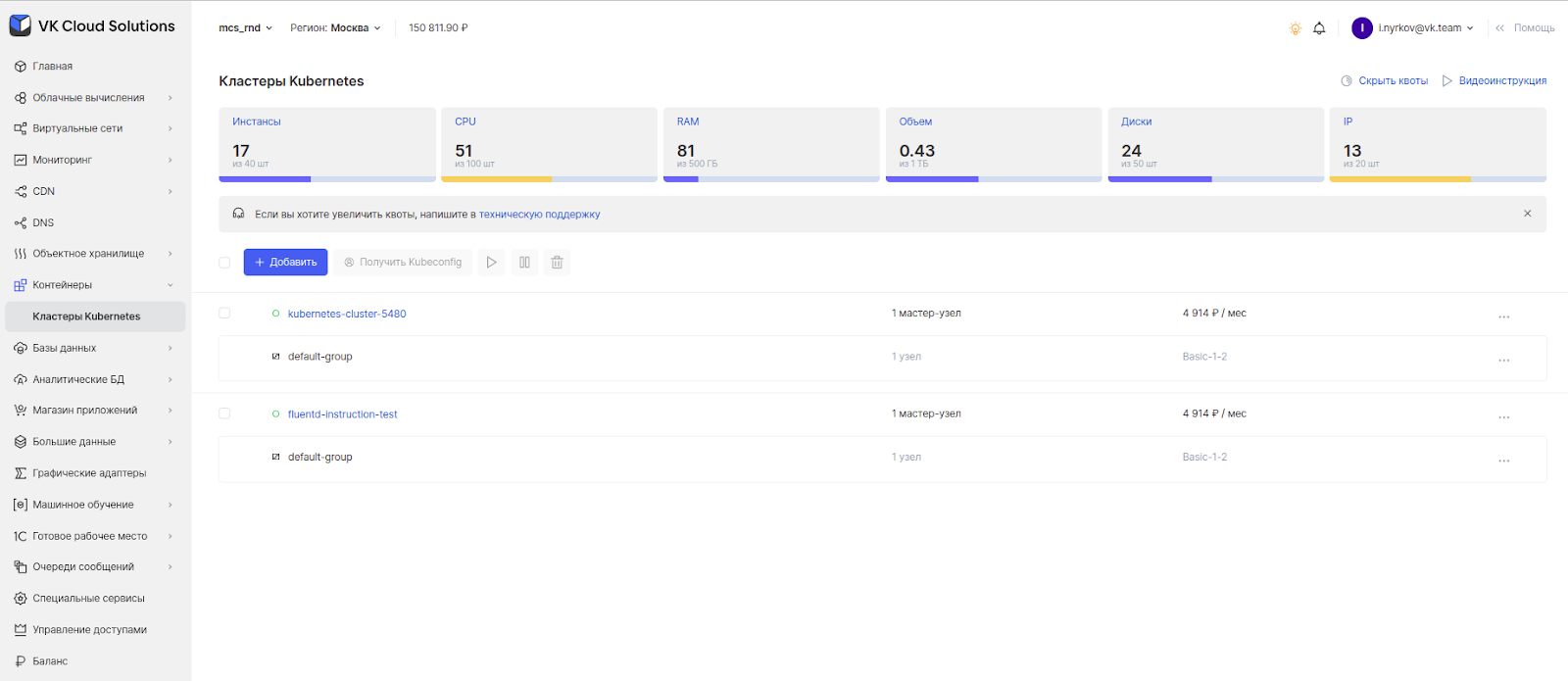
Выбираем созданный кластер и в разделе «Общие данные» скачиваем файл.
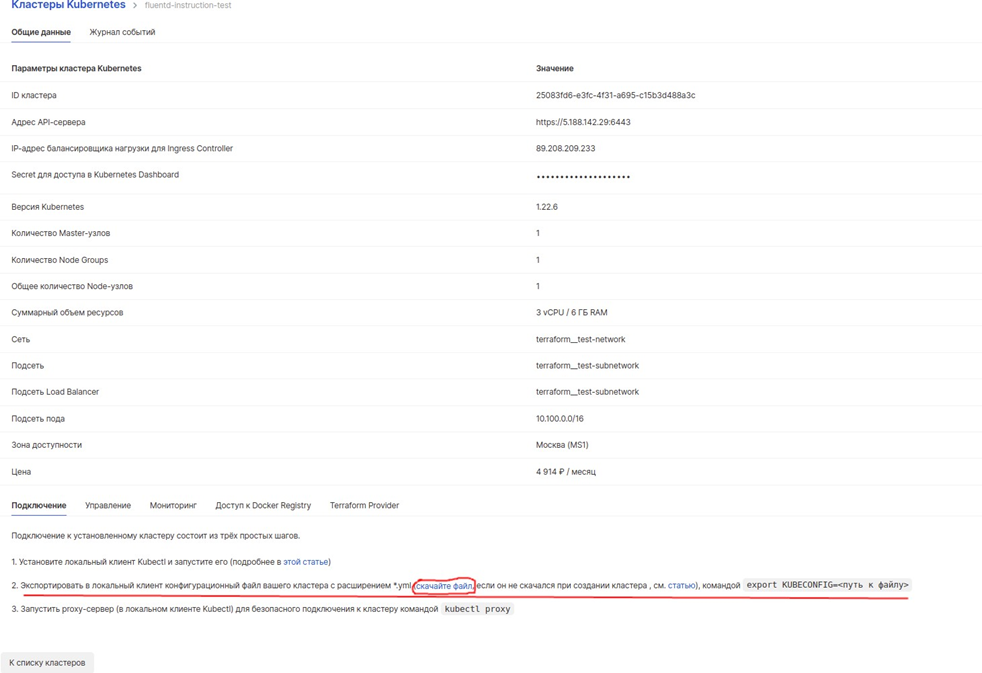
Через консоль Linux (bash) отправляем скачанный файл в ранее созданную ВМ.

Устанавливаем kubectl на ВМ (если не установлен ранее). Используем команды:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
После этого проверяем, установился ли kubectl:
kubectl version --client
Устанавливаем на виртуальную машину Helm (если не установлен ранее):
curl -L https://git.io/get_helm.sh | bash
Подключаемся к кластеру Kubernetes через ВМ:
export KUBECONFIG=<название файла конфигурации кластера>
Проверяем подключение:
kubectl config current-context
Устанавливаем Tiller (если не установлен ранее). Сначала создаем Kubernetes Account для Tiller:
kubectl --namespace kube-system create serviceaccount tiller
kubectl --namespace kube-system create clusterrolebinding tiller-cluster-admin --clusterrole=cluster-admin --serviceaccount=kube-system:tiller
Устанавливаем Tiller:
helm init
kubectl --namespace kube-system patch deploy tiller-deploy -p '{"spec":{"template":{"spec":{"serviceAccount":"tiller"}}}}'
Проверяем правильность установки:
helm list
Если ошибок нет, Tiller установлен корректно.
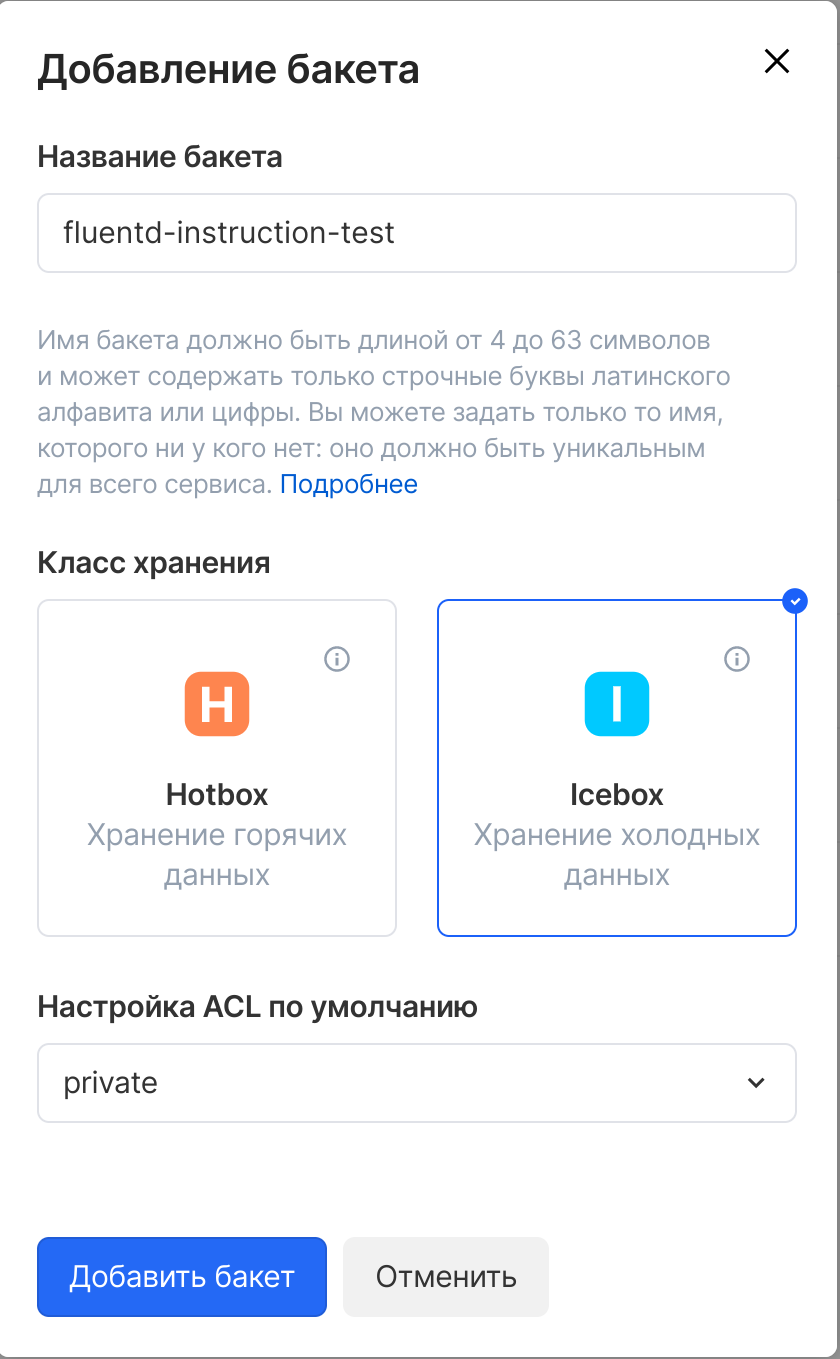
Создаем бакет S3. Делаем это через интерфейс облака в «Личном кабинете». В классе хранения выбираем тип — горячее или холодное. Icebox — трафик дороже, но хранение дешевле. Подходит для ситуаций, когда записывается много логов, но обращаются к ним редко. Hotbox — дешевый трафик, хранение дороже. Оптимален, когда к логам обращаются часто.
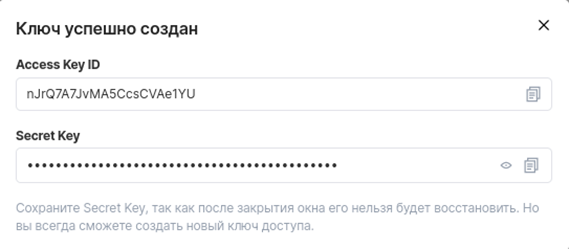
Следом создаем ключ для доступа к бакету.
Запускаем под с fluent-bit. В консоли Linux создаем файл с названием fluent-bit-fd-values-2.8.11.yaml со следующим содержимым:
Код
# если запускаем на minikube
on_minikube: false
image:
fluent_bit:
repository: fluent/fluent-bit
tag: 1.3.7
pullPolicy: Always
testFramework:
image: "dduportal/bats"
tag: "0.4.0"
nameOverride: ""
fullnameOverride: ""
metrics:
enabled: false
service:
annotations: {}
port: 2020
type: ClusterIP
serviceMonitor:
enabled: false
additionalLabels: {}
trackOffsets: false
priorityClassName: ""
backend:
type: forward
forward:
host: fluentd-es-s3 # имя пода с fluentd, можно получить командой: kubectl get svc
port: 24224 # порт пода с fluentd
tls: "off"
tls_verify: "on"
tls_debug: 1
shared_key:
es:
host: elasticsearch
port: 9200
# Elastic Index Name
index: kubernetes_cluster
type: flb_type
logstash_prefix: kubernetes_cluster
replace_dots: "On"
logstash_format: "On"
retry_limit: "False"
time_key: "@timestamp"
http_user:
http_passwd:
tls: "off"
tls_verify: "on"
tls_ca: ""
tls_debug: 1
splunk:
host: 127.0.0.1
port: 8088
token: ""
send_raw: "on"
tls: "on"
tls_verify: "off"
tls_debug: 1
message_key: "kubernetes"
stackdriver: {}
http:
host: 127.0.0.1
port: 80
uri: "/"
http_user:
http_passwd:
tls: "off"
tls_verify: "on"
tls_debug: 1
format: msgpack
headers: []
parsers:
enabled: false
regex: []
logfmt: []
json: []
env: []
podAnnotations: {}
fullConfigMap: false
existingConfigMap: ""
rawConfig: |-
@INCLUDE fluent-bit-service.conf
@INCLUDE fluent-bit-input.conf
@INCLUDE fluent-bit-filter.conf
@INCLUDE fluent-bit-output.conf
extraEntries:
input: |-
audit: |-
filter: |-
output: |-
extraPorts: []
extraVolumes: []
extraVolumeMounts: []
resources: {}
hostNetwork: false
dnsPolicy: ClusterFirst
tolerations: []
nodeSelector: {}
affinity: {}
service:
flush: 1
logLevel: info
input:
tail:
memBufLimit: 5MB
parser: docker
path: /var/log/containers/*.log
ignore_older: ""
systemd:
enabled: false
filters:
systemdUnit:
- docker.service
- kubelet.service
- node-problem-detector.service
maxEntries: 1000
readFromTail: true
stripUnderscores: false
tag: host.*
audit:
enable: false
input:
memBufLimit: 35MB
parser: docker
tag: audit.*
path: /var/log/kube-apiserver-audit.log
bufferChunkSize: 2MB
bufferMaxSize: 10MB
skipLongLines: On
key: kubernetes-audit
filter:
kubeURL: https://kubernetes.default.svc:443
kubeCAFile: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
kubeTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
kubeTag: kube
kubeTagPrefix: kube.var.log.containers.
mergeJSONLog: true
mergeLogKey: ""
enableParser: true
enableExclude: true
useJournal: false
rbac:
create: true
pspEnabled: false
taildb:
directory: /var/lib/fluent-bit
serviceAccount:
create: true
annotations: {}
name:
securityContext: {}
podSecurityContext: {}
После создания файла выполняем команду:
helm install --name fluent-bit stable/fluent-bit --version 2.8.11 -f fluent-bit-fd-values-2.8.11.yaml

Запускаем под с fluentd. Создаем файл fluentd-es-s3-values-2.3.2.yaml со следующим содержимым:
Код
replicaCount: 1
image:
repository: gcr.io/google-containers/fluentd-elasticsearch
tag: v2.4.0
pullPolicy: IfNotPresent
host: elasticsearch-client.logging
port: 9200
scheme: http
sslVersion: TLSv1
buffer_chunk_limit: 2M
buffer_queue_limit: 8
env: {}
extraEnvVars:
plugins:
enabled: true
pluginsList:
- fluent-plugin-s3
- fluent-plugin-rewrite-tag-filter
service:
annotations: {}
type: ClusterIP
ports:
- name: "monitor-agent"
protocol: TCP
containerPort: 24220
- name: "forward"
protocol: TCP
containerPort: 24224
metrics:
enabled: false
service:
port: 24231
serviceMonitor:
enabled: false
additionalLabels: {}
annotations: {}
ingress:
enabled: false
annotations:
kubernetes.io/ingress.class: nginx
labels: []
hosts:
tls: {}
configMaps:
general.conf: |
<match fluentd.**>
@type null
</match>
# Used for health checking
<source>
@type http
port 9880
bind 0.0.0.0
</source>
<source>
@type monitor_agent
bind 0.0.0.0
port 24220
tag fluentd.monitor.metrics
</source>
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
forward-input.conf: |
<source>
@type forward
port 24224
bind 0.0.0.0
</source>
output.conf: |
<filter kube.**>
@type record_transformer
enable_ruby
<record>
kubernetes_tag ${"%s" % [record["kubernetes"]["labels"]["app"] || record["kubernetes"]["labels"]["k8s-app"] || record["kubernetes"]["labels"]["name"] || "unspecified-app-label"]}
</record>
</filter>
<match kube.**>
@type rewrite_tag_filter
<rule>
key kubernetes_tag
pattern ^(.+)$
tag $1
</rule>
</match>
<match **>
@type s3
aws_key_id # Access Key ID из ключа к бакету который мы создали ранее
aws_sec_key # Secret Key ID из ключа к бакету который мы создали ранее
s3_bucket fluentd-instruction-test # название созданного бакета
s3_endpoint https://hb.bizmrg.com # url s3 облака vkcs
s3_object_key_format "${tag}/%{time_slice}-events_%{index}.%{file_extension}"
time_slice_format %Y/%m/%d/%H
time_slice_wait 10m
path test-logs
<buffer tag,time>
@type file
flush_mode interval
flush_interval 30s
path /var/log/fluent/s3
timekey 300 # 1 hour partition
timekey_wait 1m
timekey_use_utc true # use utc
chunk_limit_size 100m
</buffer>
<format>
@type json
</format>
</match>
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
rbac:
create: false
serviceAccount:
create: true
name:
persistence:
enabled: false
accessMode: ReadWriteOnce
size: 10Gi
nodeSelector: {}
tolerations: []
affinity: {}
autoscaling:
enabled: false
minReplicas: 2
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 90
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
terminationGracePeriodSeconds: 30
В полях aws_key_id, aws_sec_key, s3_bucket подставляем свои значения. После создания файла выполняем команду:
helm install --name fluentd-es-s3 stable/fluentd --version 2.3.2 -f fluentd-es-s3-values-2.3.2.yaml

После этого все новые логи будут появляться в S3.

На этом настройка завершена.
Что дает хранение логов в S3-хранилище
Повышается безопасность хранения. В облаке VK Cloud Solutions объектное хранилище S3 выделено в отдельный сервис с собственной технической поддержкой и механизмами бэкапов. Уровень доступности данных — 99,95 %. Надежность хранения данных — 99,99999 %. Логи не потеряются и всегда будут доступны.
Масштабируемость. Перенос в бакет S3 позволяет не ограничиваться объемом памяти на ноде, где запущено приложение. В Cloud Storage объем архитектурно практически не ограничен, хранилище масштабируется вместе с данными.
Появляется возможность комбинированного хранения. S3 от VK Cloud Solutions позволяет организовать как горячее, так и холодное хранение данных. Холодное хранение подойдет, когда логов пишется много, а запросы к ним редкие. Горячее — когда к логам обращаются часто. Кроме того, часть логов можно хранить в сжатом виде: это позволяет экономить, поскольку тарификация в S3 идет по объему хранимых файлов.
Но в S3 есть тарификация и за исходящий трафик с более низкой скоростью, чем у баз данных. Поэтому, если нужно постоянно работать с данными, лучше использовать БД, например Elasticsearch.
Таким образом, S3 можно комбинировать с другими типами хранилищ — например, хранить логи за последний месяц в Elasticsearch, а в S3 — за последние 6 месяцев.
Создается единое хранилище логов. По умолчанию логи разбросаны по разным нодам, их сложно собирать и обрабатывать. При переносе в S3 все логи «складываются» в один бакет, поэтому работать с единым хранилищем удобнее.
Что в итоге
Стандартный способ хранения логов на ноде неудобен: память ограничена, данные разбросаны, а многие инструменты для аналитики несовместимы.
S3-объектные хранилища отлично подходят для хранения логов: в них можно хранить практически неограниченный объем данных и работать с любыми типами информации. Кроме того, S3 совместимы с большинством приложений для аналитики больших данных и позволяют организовать доступ к логам через сервис на основе EFK.
Можно быстро настроить отправку логов кластера Kubernetes в бакет. Задача упрощена тем, что, например, через пользовательский интерфейс S3 VK Cloud Solutions (Cloud Storage) весь процесс можно выполнить без сложного программирования и конфигурирования.
Перенос логов в бакет S3 VK Cloud Solutions (Cloud Storage) позволяет создать безопасное единое хранилище с неограниченным объемом и возможностью комбинирования способов хранения.
Вы можете попробовать наше объектное хранилище Cloud Storage. Для тестирования мы начисляем пользователям при регистрации 3000 бонусных рублей.
Что еще почитать:
