
Недавно в ВТБ поменялись некоторые аппаратные и программные компоненты системы документооборота. Изменения были слишком существенными, чтобы продолжать работу без полномасштабного нагрузочного тестирования: любая проблема с системой документационного обеспечения (СДО) чревата огромными убытками.

Специалисты компании «Интертраст» протестировали СДО ВТБ на оборудовании Huawei — комплексе из серверной фермы, сети передачи данных и СХД на базе твердотельных накопителей. Для тестов мы создали среду, которая воспроизводила реальные сценарии с максимально возможной нагрузкой. Результаты и выводы — под катом.
СДО в ВТБ — сложный программный комплекс, на котором завязаны все ключевые процессы управления. Система предоставляет общие сервисы документирования, электронного взаимодействия, аналитики. Правильно организованный оборот документации ускоряет управленческие решения, делает процедуру их принятия прозрачной и контролируемой, повышает качество управления и усиливает конкурентоспособность банка.
СДО должна обеспечивать четкое исполнение решений в соответствии с принятыми регламентами. Это требует высокой производительности, отказоустойчивости, гибкого масштабирования. К системе предъявляются высокие требования к управлению доступами, объему одновременно обрабатываемых документов, к количеству пользователей. Сейчас в СДО ВТБ их насчитывается 65 тысяч, и это число продолжает расти.
Система постоянно развивается: меняется архитектура, на смену устаревающим технологиям приходят современные. А недавно часть компонентов системы заменили на импортонезависимые, без проприетарного ПО. Справится ли новая архитектура СДО на базе ПО CompanyMedia и аппаратного комплекса Huawei с повышенной нагрузкой? Однозначно ответить на этот вопрос, не дожидаясь возникновения подобной ситуации в реальности, можно было только с помощью нагрузочного тестирования.
Кроме проверки нового программного продукта на стрессоустойчивость перед нами стояли такие задачи:
Нагрузочное тестирование систем электронного документооборота часто проводят по упрощенным сценариям. В них имитируется быстрое нахождение и открытие карточек документов, которые не связаны с другими файлами и не имеют истории жизненного цикла. При этом, как правило, никто не учитывает права доступа и другие ресурсозатратные факторы, характерные для реальных условий.
Зачастую такие оторванные от реальности тесты проводят поставщики решений. Оно и понятно: для вендора важно продемонстрировать потенциальному клиенту высокую производительность и скорость работы системы. Неудивительно, что упрощенные модели тестов показывают рекордное время отклика системы, даже если количество пользователей и документов существенно увеличивается.
Нам же требовалось воспроизвести реальные условия эксплуатации. Поэтому вначале мы целый месяц собирали статистику: фиксировали активности пользователей, наблюдали за фоновой работой всех сервисов. Большим подспорьем в этом деле стали интегрированные в СДО системы мониторинга. Корректировать полученные в результате данные по документопотокам помогали сотрудники банка, при этом мы делали поправку на прогнозируемый рост потоков.
Итогом стала методология тестирования, с помощью которой получилось смоделировать протекающие в системе процессы с учетом всех реально существующих нагрузок. На тестовом стенде мы воспроизвели — по отдельности и в различных комбинациях — самые распространенные бизнес-операции, а также наиболее времязатратные запросы. В ходе тестирования производительности все компоненты подвергались нагрузке. Проводились операции по вычислению прав доступа пользователей к объектам системы, открытию документов со сложной разветвленной иерархией и большим количеством связей, поиска по системе и так далее.
Данные приложения консолидировали на единой системе хранения Huawei OceanStor Dorado 6000 V3 со 117 SSD дисками по 3,6 ТБ каждый, общий полезный объем — более 300 ТБ. Вычислительные мощности разместили на модульной серверной системе Huawei E9000, а передачу данных вели по сети на базе коммутаторов уровня ЦОД Huawei серии CE. В ходе теста мы круглосуточно наблюдали за всеми показателями работы системы. Все результаты, включая исторические данные, фиксировали в виде графиков и таблиц для последующего анализа.

Благодаря высокой производительности СХД Huawei OceanStor Dorado 6000 V3 задержки при выполнении любых пользовательских запросов редко превышали 1 мс. Такая скорость работы дисковой подсистемы приложения вдохновила нас на дополнительное исследование. Мы решили путем анализа исторических данных определить влияние различных типов нагрузки на техническую инфраструктуру. Полученные результаты позволяют гибко и точно планировать развитие системы в соответствии с требованиями к аппаратной платформе.
Одной из главных задач было выявление возможных проблем с работоспособностью СДО. В ходе работ были выявлены следующие узкие места и найдены способы их устранения.
Блокировки синхронной записи в лог. Операции записи в лог в стандартной конфигурации WildFly выполняются синхронно и сильно влияют на производительность. Было решено перейти на асинхронный логер, а заодно писать не на диск, а в систему агрегации логов ELK.
Инициализация лишних сессий при работе с хранилищем данных. Каждый поток, который получал данные из хранилища, дважды инициализировал сессию для аутентификации в режиме SSO. Эта операция ресурсоемкая и сильно увеличивает время выполнения пользовательского запроса, а также уменьшает общую пропускную способность сервера.
Блокировки при работе с объектами кэша приложения. В приложении использовались довольно тяжелые блокировки reentrantLock (Java 7), которые отрицательно сказывались на скорости выполнения запросов. Был изменен тип блокировки на stampedLock, что позволило значительно сократить время на работу с объектами кеша.
После этого мы снова запустили нагрузочное тестирование, чтобы определить среднее время типовых операций работы в системе СДО с реляционным хранилищем на профиле банка. Мы получили такие результаты:
Помимо выявления проблем, нагрузочное тестирование подтвердило и некоторые наши предположения.
Будем рады ответить на ваши вопросы в комментариях — возможно, о каких-нибудь аспектах тестирования вам интересно узнать подробнее.

Специалисты компании «Интертраст» протестировали СДО ВТБ на оборудовании Huawei — комплексе из серверной фермы, сети передачи данных и СХД на базе твердотельных накопителей. Для тестов мы создали среду, которая воспроизводила реальные сценарии с максимально возможной нагрузкой. Результаты и выводы — под катом.
Для чего нужна система документооборота в банке и зачем ее тестировать
СДО в ВТБ — сложный программный комплекс, на котором завязаны все ключевые процессы управления. Система предоставляет общие сервисы документирования, электронного взаимодействия, аналитики. Правильно организованный оборот документации ускоряет управленческие решения, делает процедуру их принятия прозрачной и контролируемой, повышает качество управления и усиливает конкурентоспособность банка.
СДО должна обеспечивать четкое исполнение решений в соответствии с принятыми регламентами. Это требует высокой производительности, отказоустойчивости, гибкого масштабирования. К системе предъявляются высокие требования к управлению доступами, объему одновременно обрабатываемых документов, к количеству пользователей. Сейчас в СДО ВТБ их насчитывается 65 тысяч, и это число продолжает расти.
Система постоянно развивается: меняется архитектура, на смену устаревающим технологиям приходят современные. А недавно часть компонентов системы заменили на импортонезависимые, без проприетарного ПО. Справится ли новая архитектура СДО на базе ПО CompanyMedia и аппаратного комплекса Huawei с повышенной нагрузкой? Однозначно ответить на этот вопрос, не дожидаясь возникновения подобной ситуации в реальности, можно было только с помощью нагрузочного тестирования.
Кроме проверки нового программного продукта на стрессоустойчивость перед нами стояли такие задачи:
- определить точные параметры горизонтального и вертикального сайзинга серверов под профиль нагрузки банка;
- проверить компоненты на отказоустойчивость в условиях высокой нагрузки;
- выявить коэффициент энтропии межкластерного взаимодействия при горизонтальном масштабировании;
- попробовать масштабировать запросы на чтение при использовании платформенного балансировщика;
- определить коэффициент горизонтального масштабирования всех узлов и компонентов системы;
- определить максимально возможные аппаратные параметры серверов разного функционального назначения (вертикальное масштабирование);
- исследовать профиль нагрузки приложения на техническую инфраструктуру, аппроксимировать полученные результаты для планирования развития информационной системы;
- исследовать влияние консолидации данных приложения на одной системе хранения данных на оптимизацию ресурсов, повышение надежности и производительности.
Методология и оборудование
Нагрузочное тестирование систем электронного документооборота часто проводят по упрощенным сценариям. В них имитируется быстрое нахождение и открытие карточек документов, которые не связаны с другими файлами и не имеют истории жизненного цикла. При этом, как правило, никто не учитывает права доступа и другие ресурсозатратные факторы, характерные для реальных условий.
Зачастую такие оторванные от реальности тесты проводят поставщики решений. Оно и понятно: для вендора важно продемонстрировать потенциальному клиенту высокую производительность и скорость работы системы. Неудивительно, что упрощенные модели тестов показывают рекордное время отклика системы, даже если количество пользователей и документов существенно увеличивается.
Нам же требовалось воспроизвести реальные условия эксплуатации. Поэтому вначале мы целый месяц собирали статистику: фиксировали активности пользователей, наблюдали за фоновой работой всех сервисов. Большим подспорьем в этом деле стали интегрированные в СДО системы мониторинга. Корректировать полученные в результате данные по документопотокам помогали сотрудники банка, при этом мы делали поправку на прогнозируемый рост потоков.
Итогом стала методология тестирования, с помощью которой получилось смоделировать протекающие в системе процессы с учетом всех реально существующих нагрузок. На тестовом стенде мы воспроизвели — по отдельности и в различных комбинациях — самые распространенные бизнес-операции, а также наиболее времязатратные запросы. В ходе тестирования производительности все компоненты подвергались нагрузке. Проводились операции по вычислению прав доступа пользователей к объектам системы, открытию документов со сложной разветвленной иерархией и большим количеством связей, поиска по системе и так далее.
Профиль нагрузочного тестирования:
- зарегистрированных пользователей: 65 тыс. с увеличением до 150 тыс.;
- частота входов пользователей в систему (аутентификаций): 50 тыс. в час;
- пользователей, одновременно работающих в системе: 10 тыс.;
- регистрируемых документов: 10 млн в год;
- объем файлов-вложений: 1 Тб в год;
- процессов согласования документов: 1,5 млн в год;
- виз участников согласования: 7,5 млн в год;
- резолюций и поручений: 15 млн в год;
- отчетов по резолюциям и поручениям: 15 млн в год;
- пользовательских задач: 18 млн в год.
Данные приложения консолидировали на единой системе хранения Huawei OceanStor Dorado 6000 V3 со 117 SSD дисками по 3,6 ТБ каждый, общий полезный объем — более 300 ТБ. Вычислительные мощности разместили на модульной серверной системе Huawei E9000, а передачу данных вели по сети на базе коммутаторов уровня ЦОД Huawei серии CE. В ходе теста мы круглосуточно наблюдали за всеми показателями работы системы. Все результаты, включая исторические данные, фиксировали в виде графиков и таблиц для последующего анализа.
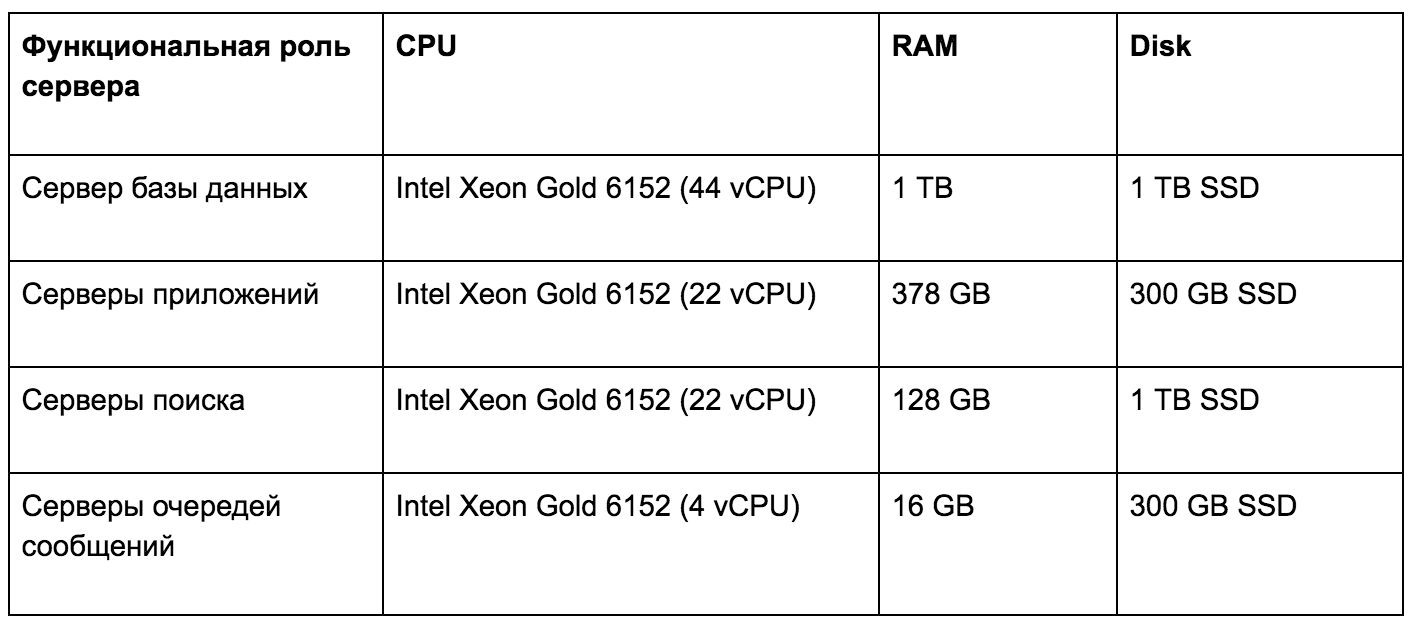
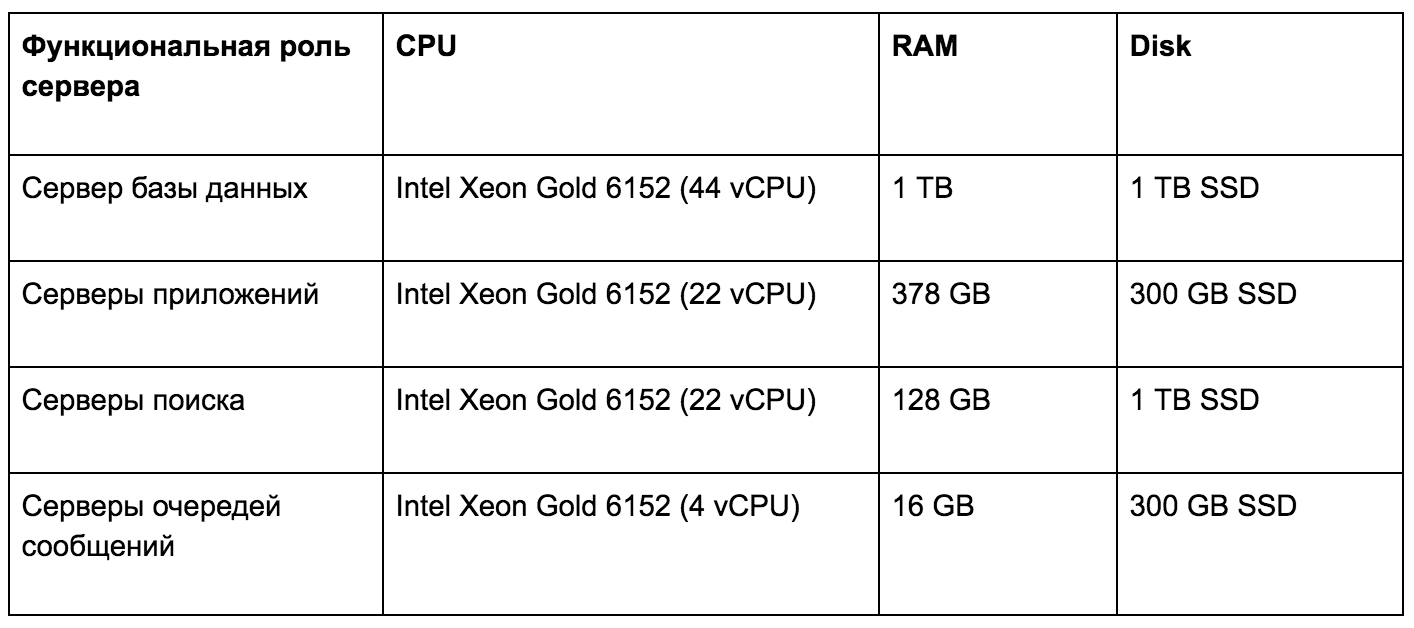
Серверы аппаратной инфраструктуры нагрузочного тестирования

Благодаря высокой производительности СХД Huawei OceanStor Dorado 6000 V3 задержки при выполнении любых пользовательских запросов редко превышали 1 мс. Такая скорость работы дисковой подсистемы приложения вдохновила нас на дополнительное исследование. Мы решили путем анализа исторических данных определить влияние различных типов нагрузки на техническую инфраструктуру. Полученные результаты позволяют гибко и точно планировать развитие системы в соответствии с требованиями к аппаратной платформе.
С точки зрения масштабирования мы проверили:
- предел вертикального масштабирования сервера приложения (CMJ), ресурсы по степени критичности: количество ядер и частота, объем ОЗУ;
- поддержку горизонтального масштабирования сервера приложения (CMJ) за счет дублирования функционально идентичных сервисов и балансировки между ними;
- пределы вертикального и горизонтального масштабирования сервера клиента (Web-GUI);
- пределы вертикального масштабирования файлового хранилища (FS), ресурсы по степени критичности: пропускная способность сети, скорость дисков;
- поддержку горизонтального масштабирования файлового хранилища (FS) за счет распределенной файловой системы — CEPH, GLUSTERFS;
- пределы вертикального масштабирования базы данных (PostgreSQL), ресурсы по степени критичности: объем ОЗУ, скорость дисков, количество ядер и частота;
- поддержку горизонтального масштабирования базы данных (PostgreSQL): масштабирование читающей нагрузки по slave-серверам, масштабирование пишущей нагрузки по принципу деления на функциональные модули;
- пределы вертикального и горизонтального масштабирования брокера сообщений (Apache Artemis);
- пределы вертикального и горизонтального масштабирования сервера поиска (Apache Solr).
Проблемы и решения
Одной из главных задач было выявление возможных проблем с работоспособностью СДО. В ходе работ были выявлены следующие узкие места и найдены способы их устранения.
Блокировки синхронной записи в лог. Операции записи в лог в стандартной конфигурации WildFly выполняются синхронно и сильно влияют на производительность. Было решено перейти на асинхронный логер, а заодно писать не на диск, а в систему агрегации логов ELK.
Инициализация лишних сессий при работе с хранилищем данных. Каждый поток, который получал данные из хранилища, дважды инициализировал сессию для аутентификации в режиме SSO. Эта операция ресурсоемкая и сильно увеличивает время выполнения пользовательского запроса, а также уменьшает общую пропускную способность сервера.
Блокировки при работе с объектами кэша приложения. В приложении использовались довольно тяжелые блокировки reentrantLock (Java 7), которые отрицательно сказывались на скорости выполнения запросов. Был изменен тип блокировки на stampedLock, что позволило значительно сократить время на работу с объектами кеша.
После этого мы снова запустили нагрузочное тестирование, чтобы определить среднее время типовых операций работы в системе СДО с реляционным хранилищем на профиле банка. Мы получили такие результаты:
- авторизация пользователя в системе — 400 мс;
- просмотр хода исполнения в среднем — 2,5 с;
- создание регистрационно-контрольной карточки — 1,4 с;
- регистрация регистрационно-контрольной карточки — 600 мс;
- создание резолюции — 1 с.
Выводы
Помимо выявления проблем, нагрузочное тестирование подтвердило и некоторые наши предположения.
- Система гораздо лучше функционирует на ОС семейства Linux.
- Заявленные принципы обеспечения отказоустойчивости работают на уровне каждого компонента в «горячем» режиме.
- Ключевой компонент — сервис бизнес-логики (принимающий пользовательские запросы) — имеет «зеркальное» горизонтальное масштабирование и практически линейное масштабирование пропускной способности при росте числа экземпляров.
- Оптимальный сайзинг сервиса бизнес-логики на 1200 одновременных пользователей — 8 vCPU для сервиса и 1,5 vCPU для СУБД.
- Консолидация данных приложения на единой СХД существенно увеличивает производительность и надежность, повышает масштабируемость.
Будем рады ответить на ваши вопросы в комментариях — возможно, о каких-нибудь аспектах тестирования вам интересно узнать подробнее.
