

Процессы и продукты банка всё время совершенствуются, и в какой-то момент приходит понимание, что рутинные операции нужно автоматизировать. Так случилось и у нас: возникла необходимость в автоматизации обработки текстовой информации. Это не только банковская тенденция — во многих сферах бизнеса сейчас растёт спрос на подобные решения, поэтому мы подумали, что хабровчанам тоже могут быть интересны наши изыскания в этой сфере. Так что сегодня расскажем о том, как работает наш прототип AutoML для распознавания именованных сущностей (named entity recognition, NER). Ну и о том, какие результаты в итоге показала обученная модель.
Предпосылки создания
Итак, для начала — в каких задачах бизнес-подразделений нам нужна автоматизированная обработка текста? Вот несколько примеров:
Мониторинг новостей в целях:
оценки кредитных рисков компаний,
рекомендаций покупки/продажи ценных бумаг,
выявления взаимосвязанных компаний / бенефициаров.
Обработка внутренних и входящих документов для выявления отправителей, получателей, определения дат, названий организаций, номеров телефонов, номеров банковских карт.
Разбор команд, произнесённых клиентом голосовому помощнику, для идентификации получателя платежа, номера карты и счёта, суммы и цели перевода.
Вышеперечисленные задачи могут быть декомпозированы на несколько подзадач, одной из которых как раз и является задача распознавания именованных сущностей (named entity recognition).
По определению NER — это задача поиска и классификации именованных сущностей в неструктурированном тексте. Таких как организации, локации, телефоны, имена людей, даты, денежные суммы и т. д.
Задача довольно хорошо изучена, и для её решения разработано несколько подходов:
Rule-based-системы, построенные на регулярных выражениях, грамматиках и словарях сущностей.
Статистические методы, основанные на выделении признаков сущностей, таких как части речи, морфология, количество цифр, количество прописных букв и т. п.
Supervised-learning-подходы, такие как conditional random fields и нейронные сети.
Rule-based-системы отлично справляются с извлечением определённых типов сущностей — таких как даты, номера телефонов и кредитных карт — довольно быстро работают, но требуют знаний о грамматиках и регулярных выражениях. При этом такие системы чаще ошибаются на более сложных сущностях, например адресах или именах. Этот недостаток можно устранить, используя статистические методы. Они не требуют от пользователей знания регулярных выражений, но для применения потребуется обучающая выборка и умение придумывать признаки. Но и статистические методы не дают наилучшего качества, потому что не учитывают контекст. В свою очередь, supervised-learning-подходы позволяют учитывать контекст, но также требуют обучающей выборки.
Сейчас количество заказов на NER в рамках различных процессов и продуктов всё возрастает, и это увеличивает нагрузку на data scientist’a: необходим инструмент, который бы реализовывал типовые модели с минимальным участием data scientist’ов, разработчиков и конечных пользователей. Для этого и была разработана библиотека NER AutoML.
Выбор модели
В настоящее время практически во всех задачах natural language processing (NLP) используются языковые модели. Важное свойство языковых моделей — возможность существенного сокращения обучающей выборки (200–300 примеров) за счёт использования fine-tuning’a для дообучения модели при наличии весов предобученной нейронной сети на корпусе соответствующего языка. Архитектуры типа Transformer являются state-of-the-art (SOTA) для многих задач NLP. Например, question answering, text classification, named entity recognition и т. д. Актуальные бенчмарки трансформеров на различных наборах данных для задачи NER можно посмотреть здесь.
Для начала необходимо найти предобученную модель с SOTA-архитектурой, которая удовлетворяет следующим условиям:
модель обучена на корпусе русскоязычных текстов;
модель показывает хорошие результаты на открытых данных;
модель можно адаптировать для решения задачи NER.
NLP-моделей, обученных на корпусах русскоязычных текстов, не так много. Одна из наиболее известных библиотек для NLP, которая предоставляет веса моделей (BERT, RNN и др.), обученных на русскоязычных корпусах, — это DeepPavlov.
В таблице, взятой с сайта DeepPavlov, приведено сравнение результатов применения этих моделей на корпусе Named_Entities_3 для решения задачи NER.

Для дальнейшей работы мы выбрали предобученную модель BERT, поскольку она показала наилучшее качество применительно к задаче NER на русскоязычном корпусе.
В комплекте с моделью идёт словарь для токенизатора WordPiece. Токенизатор преобразует исходный текст в токены и их идентификаторы, которые подаются на вход модели. Очень важно использовать для fine-tuning именно тот токенизатор и его словарь, которые были использованы для обучения модели. В противном случае на вход модели будут подаваться совершенно новые токены, которые модель никогда не видела, что, по сути, будет обучением с нуля.
Формат входных и выходных данных для модели
Рассмотрим иллюстрацию fine-tuning для NER из оригинальной статьи про BERT.
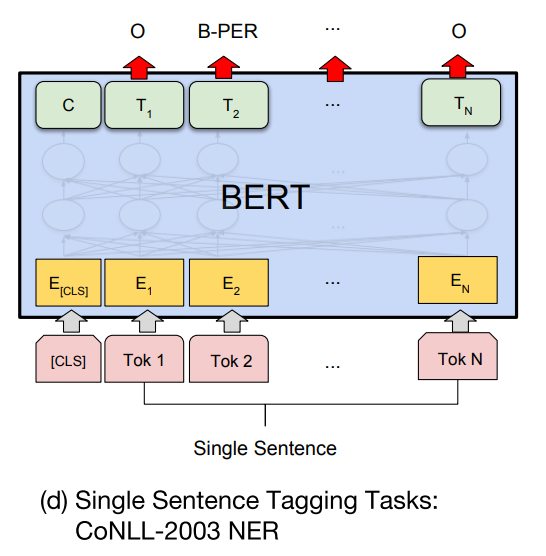
На вход модели подаётся последовательность из 512 идентификаторов токенов, на выходе получается последовательность из 512 меток, каждая из которых принимает значение соответствующего класса именованной сущности. Модель хорошо согласуется с форматами разметки BIO, BIOE и BIOES, которые можно использовать для формирования выборки текстов для обучения.
В формате BIO метка первого слова именованной сущности имеет префикс «B-» (beginning), метки последующих слов имеют префикс «I-» (inside), а метки слов, не являющиеся сущностями, обозначаются префиксом «O» (outside). Формат позволяет идентифицировать первый и последний токен сущности в последовательности. Это свойство необходимо в случае, если в тексте встречаются несколько подряд идущих именованных сущностей одного класса. Вот так выглядит пример разметки:
Токен | Метка |
Сегодня | O |
На | O |
Пресненской | B-address |
набережной | I-address |
д | I-address |
. | I-address |
10 | I-address |
ничего | O |
не | O |
произошло | O |
. | O |
Ограничения модели
Пересекающиеся и вложенные сущности
У формата BIO и BERT есть проблема — именованные сущности не должны пересекаться и не должны быть вложенными:
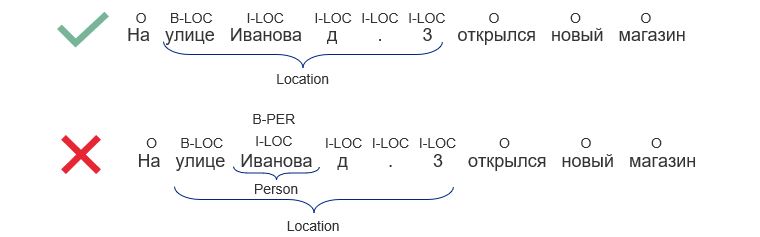
В этой статье предложены два способа устранения проблемы. Если вкратце, первый способ: для всех входных токенов, которым соответствует множество меток, формируется новая мультиметка (путём конкатенации всех меток из множества). Таким образом, если сущности «Иванова» соответствуют две метки «B-PER» и «I-LOC», формируется новая метка «B-PER|I-LOC»:

Второй способ: задача распознавания сводится к задаче seq2seq путём представления токенов в виде входной последовательности, а вложенных сущностей — в виде выходной последовательности. Модель состоит из энкодера, который обрабатывает входные последовательности, и декодера, который прогнозирует метки для каждого токена, пока не будет предсказана специальная метка <eow> (конец слова), после чего декодер переходит к обработке следующего токена.
В рамках своего решения мы выбрали первый способ. Его достоинство — простота реализации, но есть и существенный недостаток: в результате конкатенации меток их количество увеличивается, а частота встречаемости меток в датасете уменьшается. В худшем случае метка может встретиться в датасете один раз, и модель не сумеет её запомнить. Результаты применения этого способа смотрите в разделе «Результаты на открытых данных».
Удобство для пользователя
Перед тем как обучить модель, пользователь должен сделать разметку своих текстов. Как правило, инструмент для разметки получает на вход исходный текст, а после ручной разметки возвращает список именованных сущностей. Каждый список содержит имена сущностей и соответствующие им позиции начала и окончания в тексте. В частности, так работает инструмент разметки, который используется у нас.
В этом случае, чтобы обучить модель, пользователю кроме разметки нужно сделать дополнительную обработку текста, разбив его на токены и сопоставив им метки именованных сущностей, учитывая их пересечения. Это лишняя работа для пользователя, так что имеет смысл автоматизировать преобразование выходного формата инструмента разметки в формат BIO.
Для удобства пользователя мы выбрали более универсальный формат входных данных. Пользователь предоставляет данные в формате jsonlines, где каждая строка — JSON, содержащий текст и список сущностей, которые содержат позиции начала и окончания сущности, а также имя сущности. Такой формат упрощает и представление пересекающихся именованных сущностей. Вот пример нормализованной строки:
Пример
{
"text": "Сегодня на Пресненской набережной д. 10 ничего не произошло.",
"entities": [
{"label": "address", "start": 11, "end": 39},
{"label": "house_number", "start": 37, "end": 39}
]
}Соответствие токенов и сущностей исходному тексту
Предположим, что необходимо сделать подсветку именованных сущностей в тексте. Например, для текста с лишними разделителями:

…результат должен выглядеть так:

После препроцессинга и токенизации текст преобразуется в список токенов, а в результате инференса получится список меток:

Таким образом, NER AutoML должен находить соответствие между токенами и их позициями в тексте, чтобы сделать подсветку. В результате формируется список сущностей, аналогичный тому, который подаётся на вход модели при обучении:
Код
[
{"label": "person", "start": 17, "end": 37},
{"label": "location", "start": 62, "end": 70}
]4. Длина входной последовательности
BERT не может обработать тексты произвольной длины, потому что длина входной последовательности ограничена 512 токенами, при этом первый токен всегда должен быть [CLS]. Есть способ устранить этот недостаток — токенизировать исходный текст, и если длина входной последовательности превышает установленный лимит, то она разбивается на подпоследовательности, длины которых не превышают этот лимит.
Обзор возможностей библиотеки transformers от HuggingFace
Библиотека transformers от сообщества HuggingFace — это одна из самых популярных библиотек для работы с трансформерами. HuggingFace поддерживает репозиторий, где можно найти веса предобученных моделей практически для любого языка, а также словари для токенизаторов. Там же есть и ruBERT от DeepPavlov, который использовался для разработки прототипа AutoML. Дообучить модель можно с помощью pytorch. Каждая модель в репозитории содержит следующие файлы:
config.json — описание архитектуры трансформера,
pytorch_model.bin — веса модели,
vocab.txt — словарь для токенизатора.
Загрузить веса модели довольно просто. Импортируем класс для работы с конфигом и моделью для классификации токенов с выходным линейным слоем над эмбеддингами и указываем количество классов для меток:
Код
from transformers import BertConfig, BertForTokenClassification
config = BertConfig.from_pretrained('config.json', num_labels=5)
model = BertForTokenClassification.from_pretrained('pytorch_model.bin', config=config)
На этапе обучения модель принимает на вход три тензора:
input_ids — входные последовательности идентификаторов токенов.
attention_mask — соответствующие идентификаторам токенов attention маски. Нуль ставится на те позиции, на которых во входной последовательности находятся [PAD]-токены, дополняющие её до нужной длины. На остальных позициях ставятся единицы.
labels — идентификаторы классов именованных сущностей.
На этапе инференса модель принимает на вход только тензор input_ids.
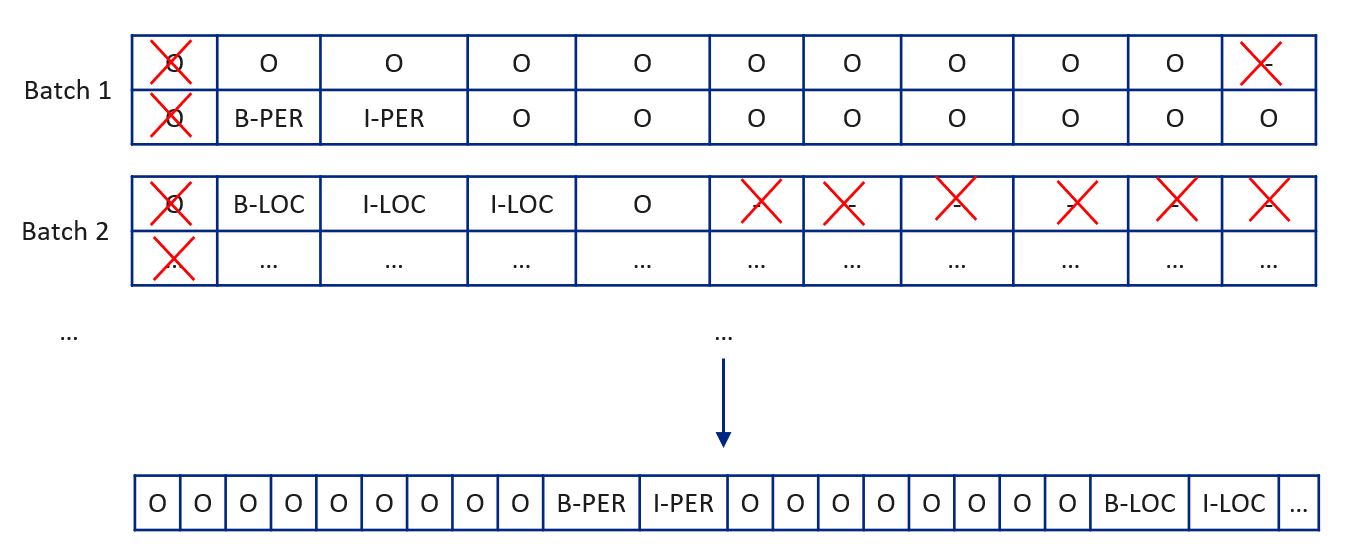
Пример батча для двух последовательностей токенов длины 11:

Чтобы получить последовательности идентификаторов токенов, нужно загрузить словарь для токенизатора, после чего передать в него исходный текст. Токенизатор возвращает объект encoding, у которого есть свойства tokens и ids, содержащие соответственно последовательность токенов и их идентификаторов.
Код
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast(vocab_file='vocab.txt', do_lower_case=False)
text = 'Сегодня утром Иван Иванович решил зайти в кафе Круассан, чтобы позавтракать'
encoding = tokenizer(text, add_special_tokens=False)[0]
for i, (token, token_id) in enumerate(zip(encoding.tokens, encoding.ids)):
print((i, token, token_id))
(0, 'Сегодня', 20530)
(1, 'утром', 16833)
(2, 'Иван', 11876)
(3, 'Иванович', 14582)
(4, 'решил', 14041)
(5, 'зайти', 68771)
(6, 'в', 845)
(7, 'кафе', 23751)
(8, 'Кру', 30577)
(9, '##асса', 9207)
(10, '##н', 858)
(11, ',', 128)
(12, 'чтобы', 5247)
(13, 'поза', 37404)
(14, '##вт', 94966)
(15, '##рака', 63023)
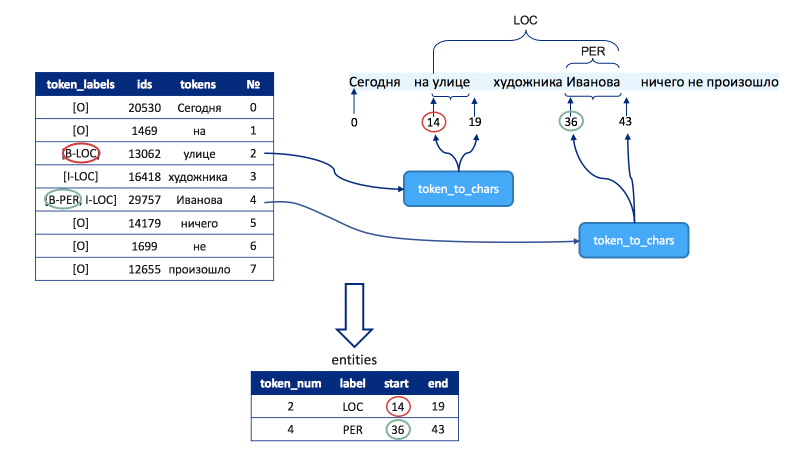
(16, '##ть', 4099)Кроме того, в объекте encoding есть два замечательных метода char_to_token и token_to_chars.
Первый метод получает на вход позицию символа в тексте, например начальную позицию сущности, и возвращает номер токена в списке encoding.tokens (или encoding.ids). Этот метод позволяет преобразовать формат jsonline в формат BIO.
Второй метод получает на вход номер токена из списка encoding.tokens (или encoding.ids), например номер первого токена, который соответствует именованной сущности, и возвращает начальную и конечную позицию этого токена в исходном тексте. Метод позволяет сопоставить спрогнозированные сущности с их позициями в тексте.

Пример
data = {
'text': 'Сегодня утром Иван Иванович решил зайти в кафе Круассан, чтобы позавтракать',
'entities' : [
{"label": "person", "start": 17, "end": 37},
{"label": "location", "start": 62, "end": 70}
]
}
encoding = tokenizer(data['text'], add_special_tokens=False)[0]
start_token_pos = encoding.char_to_token(data['entities'][1]['start'])
end_token_pos = encoding.char_to_token(data['entities'][1]['end'] - 1)
all_pos = list(range(start_token_pos, end_token_pos + 1))
print('Номера всех токенов именованной сущности:', all_pos)
start, _ = encoding.token_to_chars(start_token_pos)
_, end = encoding.token_to_chars(end_token_pos)
print('Начальная и конечная позиция именованной сущности в тексте:', [start, end])# output
Номера всех токенов именованной сущности: [8, 9, 10]
Начальная и конечная позиция именованной сущности в тексте: [62, 70]
Все вышеперечисленные возможности помогают обойти ограничения модели.
Реализация библиотеки NER AutoML
Состав компонентов библиотеки приведён на диаграмме.
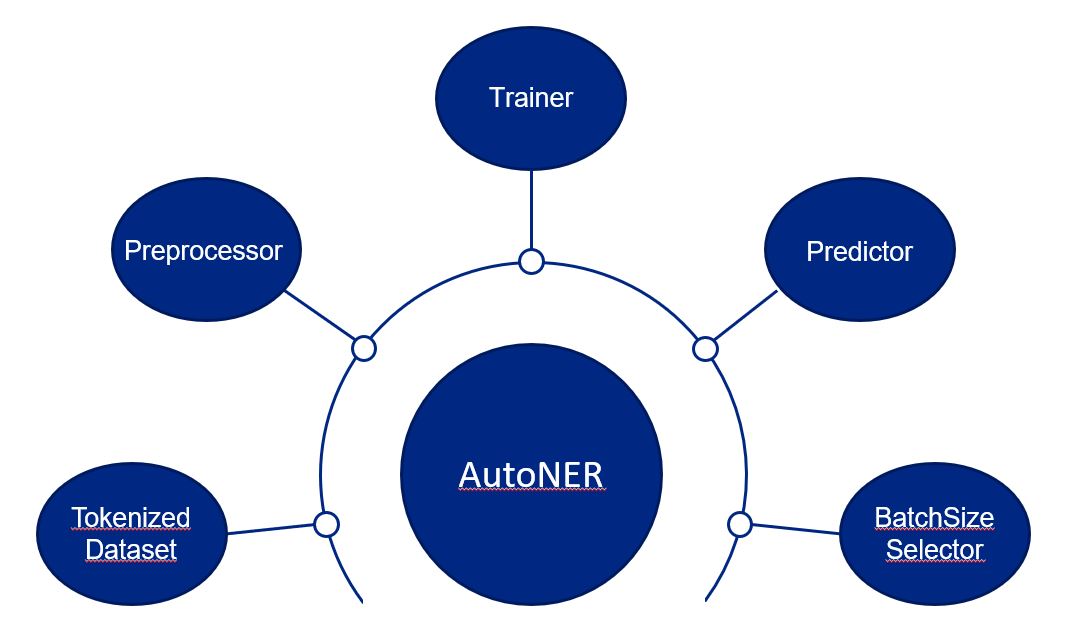
Tokenized Dataset | Хранит выборку. Реализует методы для генерации батчей во время обучения и инференса модели. |
Preprocessor | Преобразует формат jsonline в формат BIO, формируя последовательности токенов и соответствующих меток. Формирует мультиметки в случае пересечения сущностей. Разбивает слишком длинные последовательности на подпоследовательности длиной не более 512 токенов. |
Trainer | Дообучает BERT для решения задачи NER и сохраняет наилучшую версию. Сохраняет отчёт с метриками качества модели (Precision, Recall, F1-Score) и данные для визуализации кривых обучения и валидации модели. |
Predictor | Загружает дообученный BERT для инференса. Прогнозирует метки для токенов. Сопоставляет метки токенов соответствующим позициям в исходном тексте. |
BatchSize Selector | Определяет максимальный размера батча, который может поместиться в памяти или видеопамяти. |
AutoNER | Реализует API-библиотеки для обучения и инференса. |
Каждый компонент удобно реализовать в виде класса. Рассмотрим особенности реализации каждого из классов подробнее.
1. TokenizedDataSet
Класс можно реализовать, следуя документации pytorch. TokenizedDataSet наследуется от класса Dataset и переопределяет методы __init__, __len__ и __getitem__. Экземпляр этого класса хранит выборку в поле sequence в таком же формате, который подаётся на вход модели. Небольшое напоминание из раздела про обзор библиотеки transformers.

Код
from torch.utils.data import Dataset
class TokenizedDataset(Dataset):
def __init__(self, sequences):
self.sequences = sequences
def __len__(self):
return len(self.sequences['input_ids'])
def __getitem__(self, idx):
return {k: v[idx] for k, v in self.sequences.items()}Реализация класса TokenizedDataset находится в модуле ner_automl.preprocessing
2. Preprocessor
Определим класс, который будет использоваться для обработки текстов. Экземпляр этого класса хранит токенизатор (tokenizer), словари отображения меток в их идентификаторы и обратно (label_to_id и id_to_label), имена входных тензоров для модели (tensor_names) и максимальную длину последовательности.
Словари отображения меток инициализируются одной парой значений 0: ' [PAD] ' ('[PAD] ':0), которые есть в свойствах токенизатора.
Исходная максимальная длина последовательности равна 511 токенов, а не 512. Это связано с тем, что первый токен последовательности всегда должен быть [CLS].
Код
import os
import jsonlines
import torch
class Preprocessor:
def __init__(self, tokenizer):
self.tokenizer = tokenizer
self.label_to_id = {self.tokenizer.pad_token: self.tokenizer.pad_token_id}
self.id_to_label = {self.tokenizer.pad_token_id: self.tokenizer.pad_token}
self.tensor_names = ('input_ids', 'attention_mask', 'labels')
self.max_len = 511Реализуем метод, который преобразует текст jsonline в BIO-формат. Метод принимает на вход один аргумент — dictionary содержащий текст и список именованных сущностей, в котором каждый элемент представляет собой dictionary с именем сущности и позициями её начала и окончания в тексте.
На первом шаге применяем токенизатор к тексту, в результате получается объект encoding со списком токенов и списком их идентификаторов. Чтобы поставить в соответствие токенам их метки, инициализируется список label_names такой же длины, как и список токенов. Каждый элемент списка — это множество, которое при инициализации содержит только одну метку «O», а после обработки размеченных текстов будет содержать соответствующие токену метки. Если именованные сущности пересекаются, то одному токену будет соответствовать несколько меток.
Для каждой сущности из списка именованных сущностей её начальная позиция передаётся в метод char_to_token объекта encoding, чтобы определить start_token_pos — индекс первого токена сущности в списке encoding.ids. Та же операция повторяется для конечной позиции сущности в тексте, чтобы определить end_token_pos — индекс последнего токена сущности в списке encoding.ids. Затем для каждой позиции в диапазоне start_token_pos и end_token_pos метод добавляет имя сущности в множество на соответствующей позиции в списке labels_names, удаляя метку «O» из этого множества. Первая метка добавляется с префиксом «B-», а остальные с префиксом «I-».
Если множество в списке labels_names содержит несколько меток (в случае пересечения сущностей), метки объединяются в одну при помощи конкатенации.
На последнем шаге метод добавляет метки в словари отображения label_to_id и id_to_label и формирует список идентификаторов меток labels, соответствующий списку label_names, после чего возвращает объект encoding и список labels.
Код
def tokenize_text(self, json_line):
text = json_line['text']
entities = json_line['entities']
encoding = self.tokenizer(text, add_special_tokens=False)[0]
labels_names = [{'O'} for i in range(len(encoding.tokens))]
for entity in entities:
start_token_pos = encoding.char_to_token(entity['start'])
end_token_pos = encoding.char_to_token(entity['end'] - 1) + 1
label_name = entity['label']
for pos in range(start_token_pos, end_token_pos):
labels_names[pos].discard('O')
token_label = f'B-{label_name}' if pos == start_token_pos else f'I-{label_name}'
labels_names[pos].add(token_label)
labels_names = list(map(lambda x: '|'.join(sorted(x)), labels_names))
labels = []
for label_name in labels_names:
if label_name not in self.label_to_id:
self.label_to_id[label_name] = self.tokenizer.pad_token_id + len(self.label_to_id)
self.id_to_label[self.label_to_id[label_name]] = label_name
labels.append(self.label_to_id[label_name])
return encoding, labelsСледующий метод вызывается для обработки всех текстов, которые находятся в файле по указанному пути. Он возвращает список объектов encoding для каждого текста и соответствующие им последовательности меток.
Код
def tokenize_texts(self, file_path):
encodings = []
labels = []
with jsonlines.open(file_path, mode='r') as f:
for json_line in f:
e, l = self.tokenize_text(json_line)
encodings.append(e)
labels.append(l)
return encodings, labelsПеред тем как реализовать метод разбиения последовательности, нужно создать вспомогательный метод для дополнения последовательности специальными токенами. Метод принимает на вход два параметра: последовательность идентификаторов и тип: input_ids, attention_mask или labels. В конец последовательности всегда добавляются идентификаторы [PAD] токена, дополняющие её до максимальный длины. В начало последовательности добавляется один идентификатор. Для типа input_ids добавляется идентификатор [CLS], для attention_mask — 1, для labels — идентификатор метки «O».
Код
def add_special_tokens(self, array, type_='input_ids'):
CLS_ID = self.tokenizer.cls_token_id
PAD_ID = self.tokenizer.pad_token_id
pad_len = self.max_len - len(array)
if type_ == 'input_ids':
new_array = [CLS_ID] + array + [PAD_ID] * pad_len
elif type_ == 'attention_mask':
new_array = [1] + array + [PAD_ID] * pad_len
elif type_ == 'labels':
l_id = self.label_to_id['O']
new_array = [l_id] + array + [PAD_ID] * pad_len
return new_arrayТеперь можно создать метод разбиения последовательностей, длина которых превышает установленную максимальную длину max_length.
Метод принимает на вход обязательный параметр — объект encoding, полученный в результате обработки одного текста, и один необязательный параметр labels — список идентификаторов меток именованных сущностей, который есть только на этапе обучения модели.
Если длина последовательности не превышает максимальную длину, то к ней просто добавляются специальные токены, иначе она разбивается на последовательности поменьше.
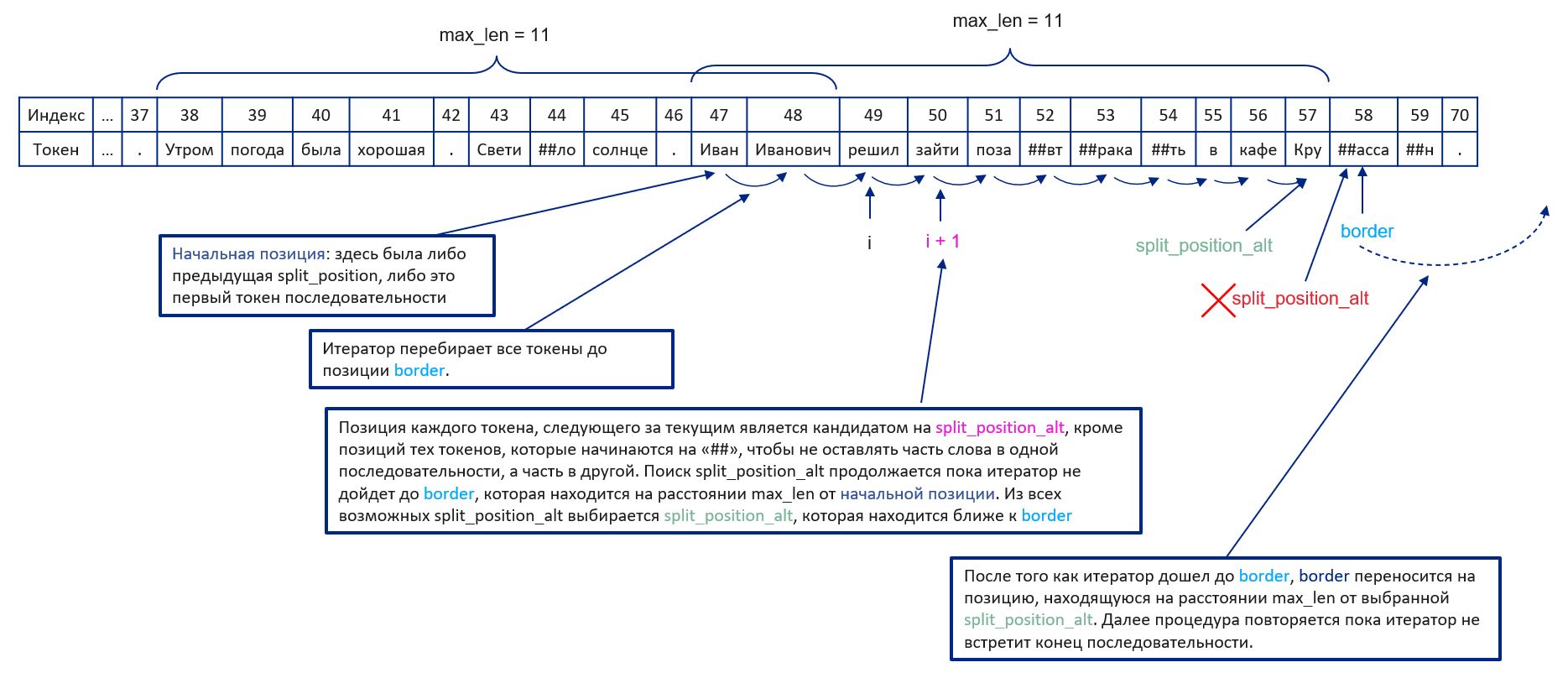
Рассмотрим случай разбиения последовательности, когда отсутствуют метки, то есть на этапе инференса. Естественный способ разбиения последовательности — по предложениям в тексте, чтобы учитывать контекст. В этом случае необходимо просмотреть все токены последовательности слева направо и найти индекс символа конца предложения, находящийся слева от позиции max_length, но максимально близкий к ней. Назовём такой индекс split_position и запомним его значение. Позицию max_length обозначим как border. Теперь необходимо передвинуть border на новую позицию, которая находится на расстоянии max_length от split_position. Процедура повторяется пока не закончится последовательность.
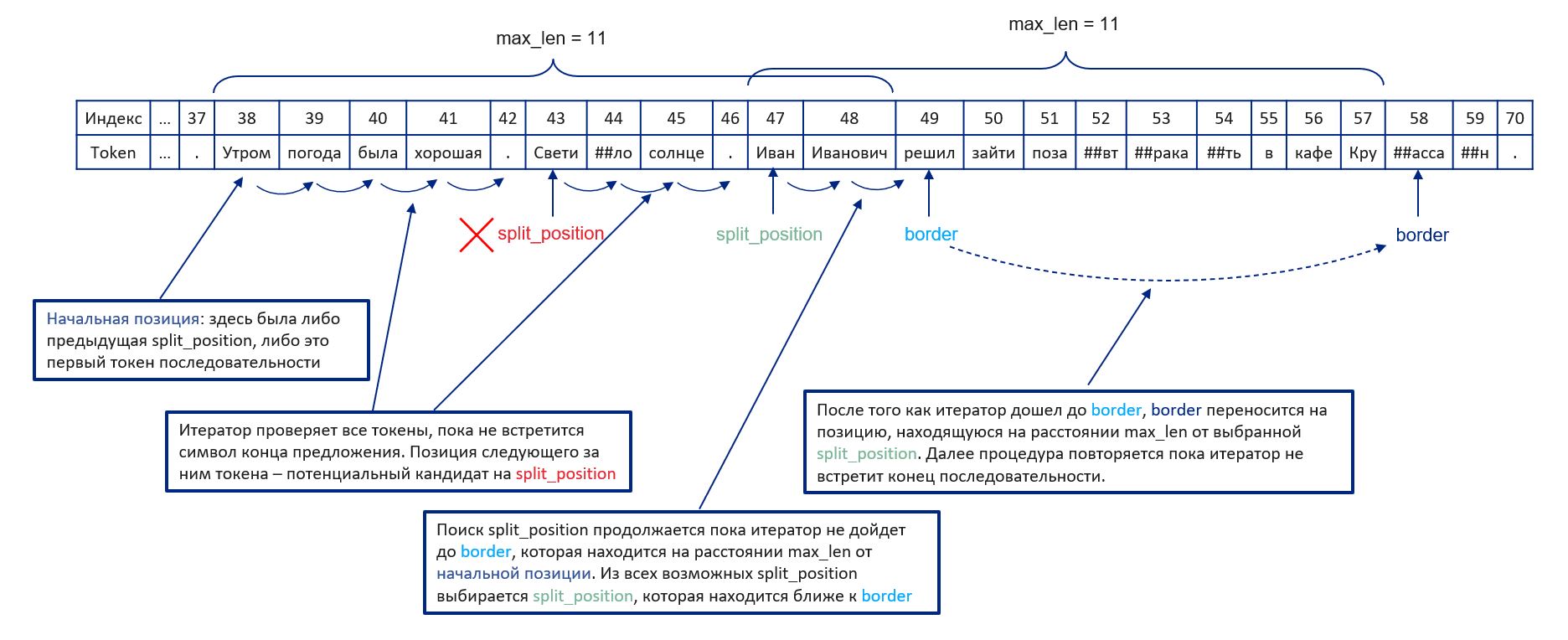
В качестве разделителей предложений используются символы «.», «!» и «?». Если предложение заканчивается на «…», «!!!» или другие сложные знаки препинания, то разбиение всё равно происходит по первому символу. В таком случае следующее предложение будет начинаться со знаков «..», «!!» и. т. п, но это не сильно влияет на качество распознавания именованных сущностей.
Может получиться, что длина предложения превышает максимальную длину или знаки препинания вовсе отсутствуют в тексте. В этом случае нужно искать альтернативные позиции для разбиения: split_position_alt — это позиция ближайшего к border токена, который не начинается на «##». Это сделано для того, чтобы не разбивать последовательность посередине слова. В случае если split_position не была найдена, используется split_position_alt.
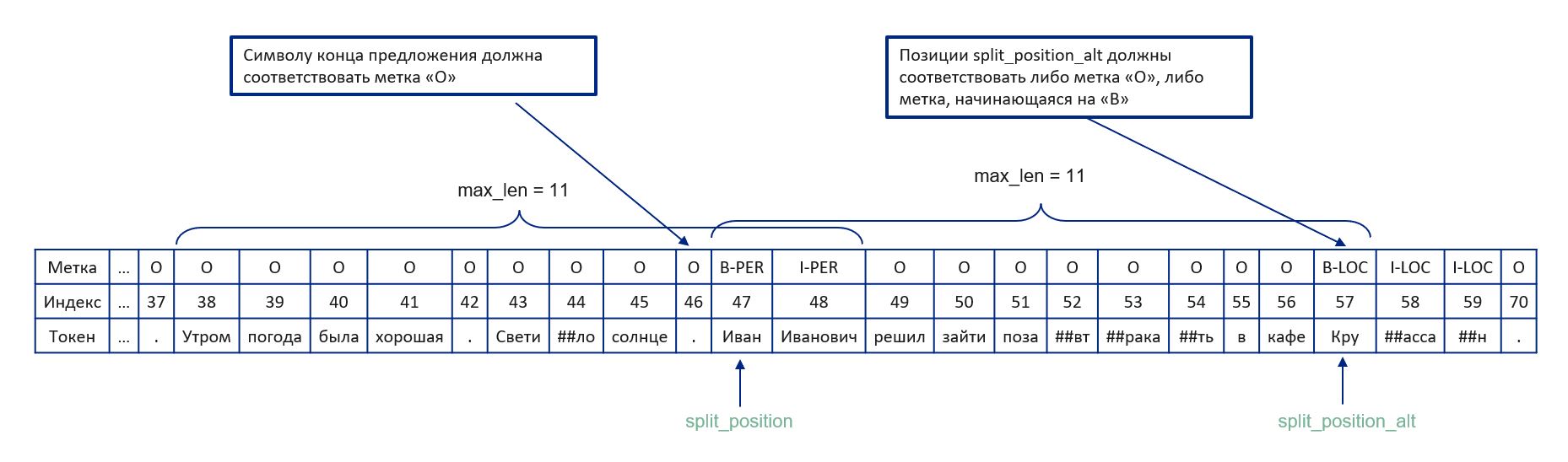
Если метки сущностей передаются в метод в качестве параметра, то в алгоритме появляются дополнительные условия: именованная сущность должна полностью принадлежать подпоследовательности, получившейся в результате разбиения.
Для поиска split_position в алгоритм добавляется проверка метки, соответствующей символу конца предложения. Если метка принимает значение «O», значит, этот токен не принадлежит именованной сущности, а следующая позиция — это кандидат на split_position. В таком случае такие именованные сущности, как, например, «И. И. Иванов», «ул. Иванова», не будут разбиты по точке и отнесены к разным подпоследовательностям.
Для поиска split_position_alt в алгоритм добавляется проверка метки, которая соответствует позиции-кандидату на split_position_alt. Метка должна либо принимать значение «O», либо начинаться на «B».
После разбиения последовательности метод возвращает dictionary со списками подпоследовательностей.
Код
def cut_long_sequence(self, encoding, labels=None):
end_symbols = frozenset(('.', '?', '!'))
split_labels_types = frozenset(('O', 'B'))
border = self.max_len
split_position = None
split_position_alt = None
split_positions = [0]
sequences = {t: [] for t in self.tensor_names}
sequence_len = len(encoding.ids)
if sequence_len < self.max_len:
s_input_ids = self.add_special_tokens(encoding.ids, 'input_ids')
sequences['input_ids'].append(s_input_ids)
if labels is not None:
s_attention_mask = self.add_special_tokens(encoding.attention_mask, 'attention_mask')
sequences['attention_mask'].append(s_attention_mask)
s_labels = self.add_special_tokens(labels, 'labels')
sequences['labels'].append(s_labels)
else:
for i in range(sequence_len):
if i < border:
if labels is not None:
if encoding.tokens[i] in end_symbols and self.id_to_label[labels[i]] == 'O':
split_position = i + 1
if i + 1 < sequence_len:
if encoding.tokens[i + 1][:2] != '##' and self.id_to_label[labels[i + 1]][0] in split_labels_types:
split_position_alt = i + 1
else:
if encoding.tokens[i] in end_symbols:
split_position = i + 1
if i + 1 < sequence_len:
if encoding.tokens[i + 1][:2] != '##':
split_position_alt = i + 1
else:
if split_position is not None:
split_positions.append(split_position)
border = split_position + self.max_len
split_position = None
else:
split_positions.append(split_position_alt)
border = split_position_alt + self.max_len
split_position_alt = None
split_positions.append(sequence_len)
for i in range(len(split_positions) - 1):
s_input_ids = self.add_special_tokens(
encoding.ids[split_positions[i]:split_positions[i + 1]],
'input_ids'
)
sequences['input_ids'].append(s_input_ids)
if labels is not None:
s_attention_mask = self.add_special_tokens(
encoding.attention_mask[split_positions[i]:split_positions[i + 1]],
'attention_mask'
)
sequences['attention_mask'].append(s_attention_mask)
s_labels = self.add_special_tokens(
labels[split_positions[i]:split_positions[i + 1]],
'labels'
)
sequences['labels'].append(s_labels)
return sequencesТеперь нужно реализовать метод, который обрабатывает обучающую, валидационную и тестовую выборку. Метод принимает на вход пути до файлов, в которых эти выборки находятся. Далее он делает токенизацию текстов для каждой выборки. Определяется максимальная длина входной последовательности, которая равна длине самой длинной последовательности из обучающей выборки, но не более 511 токенов. Это делается для того, чтобы последовательности не дополнялись большим количеством [PAD]-токенов, например, в случае, если в выборках содержатся очень короткие фразы. При таком подходе можно сформировать батч большего размера. На последнем шаге последовательности из каждой выборки разбиваются и формируется dictionary с ключами train, valid, test и соответствующими им результатами работы метода cut_long_sequence.
Код
def preprocess(self, train_path, valid_path, test_path):
datasets_paths = {
'train': train_path,
'valid': valid_path,
'test': test_path
}
sequences = dict()
for sample_name in ['train', 'valid', 'test']:
sequences[sample_name] = {t: [] for t in self.tensor_names}
encodings, labels = self.tokenize_texts(datasets_paths[sample_name])
if sample_name == 'train':
self.max_len = min(self.max_len, max(map(lambda e: len(e.ids), encodings)))
for i in range(len(labels)):
sequence = self.cut_long_sequence(encodings[i], labels[i])
for t in self.tensor_names:
sequences[sample_name][t].extend(sequence[t])
for t in self.tensor_names:
sequences[sample_name][t] = torch.tensor(sequences[sample_name][t], dtype=torch.long)
return sequencesНа этапе инференса будет удобно иметь в распоряжении два очень простых метода, чтобы инициализировать препроцессор словарями отображения меток и значением максимальной длины последовательности, созданными на этапе обучения.
Код
def set_id_to_label(self, id_to_label):
self.id_to_label = id_to_label
self.label_to_id = {l: i for i, l in id_to_label.items()}
def set_max_len(self, max_len):
self.max_len = max_lenРеализация класса Preprocessor находится в модуле ner_automl.preprocessing.
3. Trainer
Класс для обучения модели и формирования отчёта с метриками. Конструктор принимает на вход экземпляр класса Preprocessor, путь до каталога, в который нужно сохранить веса модели, путь до файла конфигурации BERT, путь до файла с весами модели и количество эпох для обучения. По умолчанию указано 10 эпох, поскольку, как показывает практика, BERT дообучается довольно быстро. При создании экземпляра класса Trainer загружаются веса модели и выбирается место, где будет обучаться модель — GPU или CPU.
Код
import numpy as np
import torch
from tqdm.auto import tqdm
from torch.nn.utils import clip_grad_norm_
from transformers import BertConfig, BertForTokenClassification, AdamW, get_scheduler
from seqeval.metrics import classification_report
torch.manual_seed(0)
torch.backends.cudnn.deterministic = True
class Trainer:
def __init__(
self,
preprocessor,
checkpoint_path,
bert_config_path,
bert_weights_path,
epochs=10,
):
self.preprocessor = preprocessor
self.config = BertConfig.from_pretrained(bert_config_path, num_labels=len(self.preprocessor.id_to_label))
self.model = BertForTokenClassification.from_pretrained(bert_weights_path, config=self.config)
self.epochs = epochs
self.checkpoint_path = checkpoint_path
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.model.to(self.device);Для валидации и тестирования удобно сделать метод, который будет применять модель к соответствующим датасетам. На вход он принимает два параметра — генератор батчей и необязательный параметр, в зависимости от которого возвращается либо значение функции потерь, либо оно же с метриками, precision, recall, f1-score для каждой сущности, а также micro и macro average для каждой из метрик. Для вычисления метрик используется библиотека seqeval, предоставляющая удобные методы для валидации моделей, работающих с последовательностями.
Код
def evaluate(self, dataloader, all_metrics=False):
self.model.eval()
eval_loss = 0
true_labels = []
pred_labels = []
for batch in dataloader:
batch = {k: v.to(self.device) for k, v in batch.items()}
with torch.no_grad():
outputs = self.model(**batch)
logits = outputs.logits.detach().cpu().numpy()
eval_loss += outputs.loss.item()
labels = batch['labels'].to('cpu').numpy()
if all_metrics:
true_labels.extend(labels)
pred_labels.extend([list(p) for p in np.argmax(logits, axis=2)])
eval_loss = eval_loss / len(dataloader)
if all_metrics:
true_labels_names = []
pred_labels_names = []
for tls, pls in zip(true_labels, pred_labels):
t_labels_names = []
p_labels_names = []
for t, p in zip (tls, pls):
if self.preprocessor.id_to_label[t] != '[PAD]':
t_labels_names.append(self.preprocessor.id_to_label[t])
p_labels_names.append(self.preprocessor.id_to_label[p])
true_labels_names.append(t_labels_names)
pred_labels_names.append(p_labels_names)
metrics = classification_report(true_labels_names, pred_labels_names, output_dict=True)
for k in metrics:
del metrics[k]['support']
metrics['eval_loss'] = eval_loss
else:
metrics = dict()
metrics['eval_loss'] = eval_loss
return metricsНиже представлен код метода обучения модели. На вход он принимает два генератора батчей, первый из который выбирает батчи из обучающей выборки, а второй — из валидационной. Внутри реализован обычный цикл обучения модели. На каждой эпохе обучения веса модели сохраняются при условии, что loss на валидации уменьшился по сравнению с наилучшим. Кроме того, сохраняются словарь отображения идентификаторов меток в их значениях, максимальная длина последовательности и размер батча, поскольку эта информация требуется на этапе инференса, когда модель загружается. Экземпляр этого класса также хранит внутри себя массивы со значениями loss на обучении и валидации для каждой эпохи.
Код
def fit(self, train_dataloader, valid_dataloader):
optimizer = AdamW(self.model.parameters(), lr=5e-5)
max_grad_norm = 1.0
num_training_steps = self.epochs * len(train_dataloader)
scheduler = get_scheduler(
'linear',
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
self.train_losses = []
self.valid_losses = []
best_loss = np.inf
with tqdm(range(num_training_steps)) as progress_bar:
for epoch in range(self.epochs):
self.model.train()
train_loss = 0
for batch in train_dataloader:
batch = {k: v.to(self.device) for k, v in batch.items()}
outputs = self.model(**batch)
loss = outputs.loss
loss.backward()
train_loss += loss.item()
clip_grad_norm_(parameters=self.model.parameters(), max_norm=max_grad_norm)
optimizer.step()
scheduler.step()
self.model.zero_grad()
progress_bar.update(1)
train_loss = train_loss / num_training_steps
eval_loss = self.evaluate(valid_dataloader)['eval_loss']
self.train_losses.append(train_loss)
self.valid_losses.append(eval_loss)
if eval_loss < best_loss:
best_loss = eval_loss
torch.save(
{
'model': self.model.state_dict(),
'id_to_label': self.preprocessor.id_to_label,
'max_len': self.preprocessor.max_len,
'batch_size': train_dataloader.batch_size
},
self.checkpoint_path
)
checkpoint = torch.load(self.checkpoint_path)
self.model = BertForTokenClassification.from_pretrained(pretrained_model_name_or_path=None, state_dict=checkpoint['model'], config=self.config)
self.model.to(self.device);Класс Trainer реализован в модуле ner_automl.trainer.
4. Predictor
Для инференса модели потребуется класс, который реализует загрузку весов модели и преобразование спрогнозированной последовательности меток из формата BIO в формат jsonline.
Конструктор принимает на вход экземпляр класса Preprocessor, путь до весов дообученной модели и путь до файла конфигурации, после чего загружает веса модели и сопутствующую информацию, сохранённую на этапе обучения. Поскольку экземпляр класса «препроцессор» не содержит информацию об обучающей выборке, в него загружается словарь отображения идентификаторов именованных сущностей в их метки, а также максимальная длина последовательности и размер батча. Далее модель загружается на GPU/CPU.
Код
import numpy as np
import torch
from transformers import BertConfig, BertForTokenClassification
from torch.utils.data import TensorDataset, DataLoader, SequentialSampler
class Predictor:
def __init__(
self,
preprocessor,
checkpoint_path,
bert_config_path,
):
self.preprocessor = preprocessor
checkpoint = torch.load(checkpoint_path)
self.preprocessor.set_id_to_label(checkpoint['id_to_label'])
self.preprocessor.set_max_len(checkpoint['max_len'])
self.batch_size = checkpoint['batch_size']
self.config = BertConfig.from_pretrained(bert_config_path, num_labels=len(self.preprocessor.id_to_label))
self.model = BertForTokenClassification.from_pretrained(pretrained_model_name_or_path=None, state_dict=checkpoint['model'], config=self.config)
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.model.to(self.device);Единственный метод этого класса принимает на вход текст и возвращает список именованных сущностей, где каждая сущность — это dictionary с именем сущности и позициями её начала и окончания.
На первом шаге препроцессор токенизирует текст и возвращает encoding с последовательностью токенов.

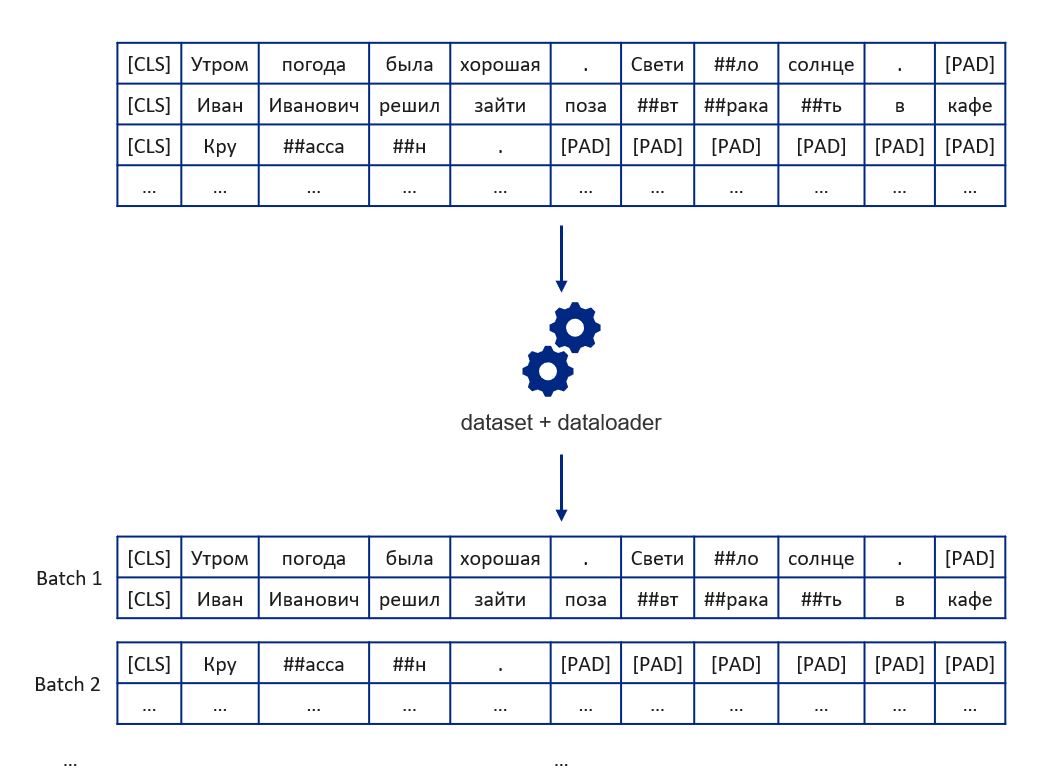
Затем препроцессор разбивает полученную последовательность на подпоследовательности, не превышающие максимальную длину. Для удобства восприятия картинок идентификаторы токенов и меток заменили на токены и метки соответственно.

Если тексты очень длинные, список подпоследовательностей для них может не поместиться в видеопамяти, так что лучше разбить список подпоследовательностей на батчи. Поскольку на этапе инференса есть только один тип последовательностей — input_ids, генератор батчей создаётся за счёт стандартной связки TensorDataset и DataLoader из pytorch.
Для каждого батча модель делает инференс, возвращая тензор размерности (размер батча x количество токенов x количество меток). Каждый элемент тензора — это вероятность того, что токену в последовательности соответствует метка с некоторым названием (B-PER, I-LOC и т. д.). Выбирается самый вероятный класс для каждого токена, то есть получается тензор, состоящий из подпоследовательностей, элементами которых являются идентификаторы меток именованных сущностей.
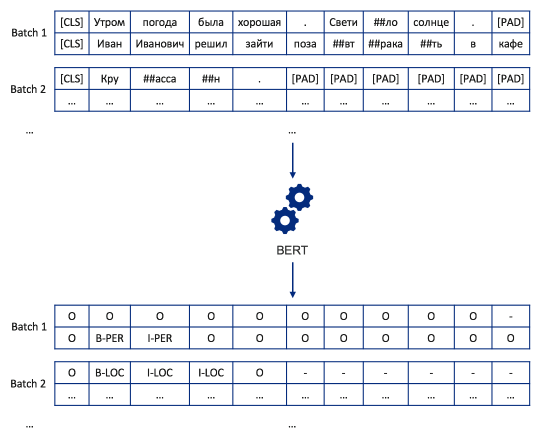
Далее из каждой подпоследовательности исключаются идентификаторы, находящихся на тех позициях, которые соответствуют позициям [CLS]- и [PAD]-токенов во входных подпоследовательностях. После этого очищенные подпоследовательности объединяются. В результате получается последовательность идентификаторов меток labels такой же длины, как и исходная последовательность токенов в объекте encoding.
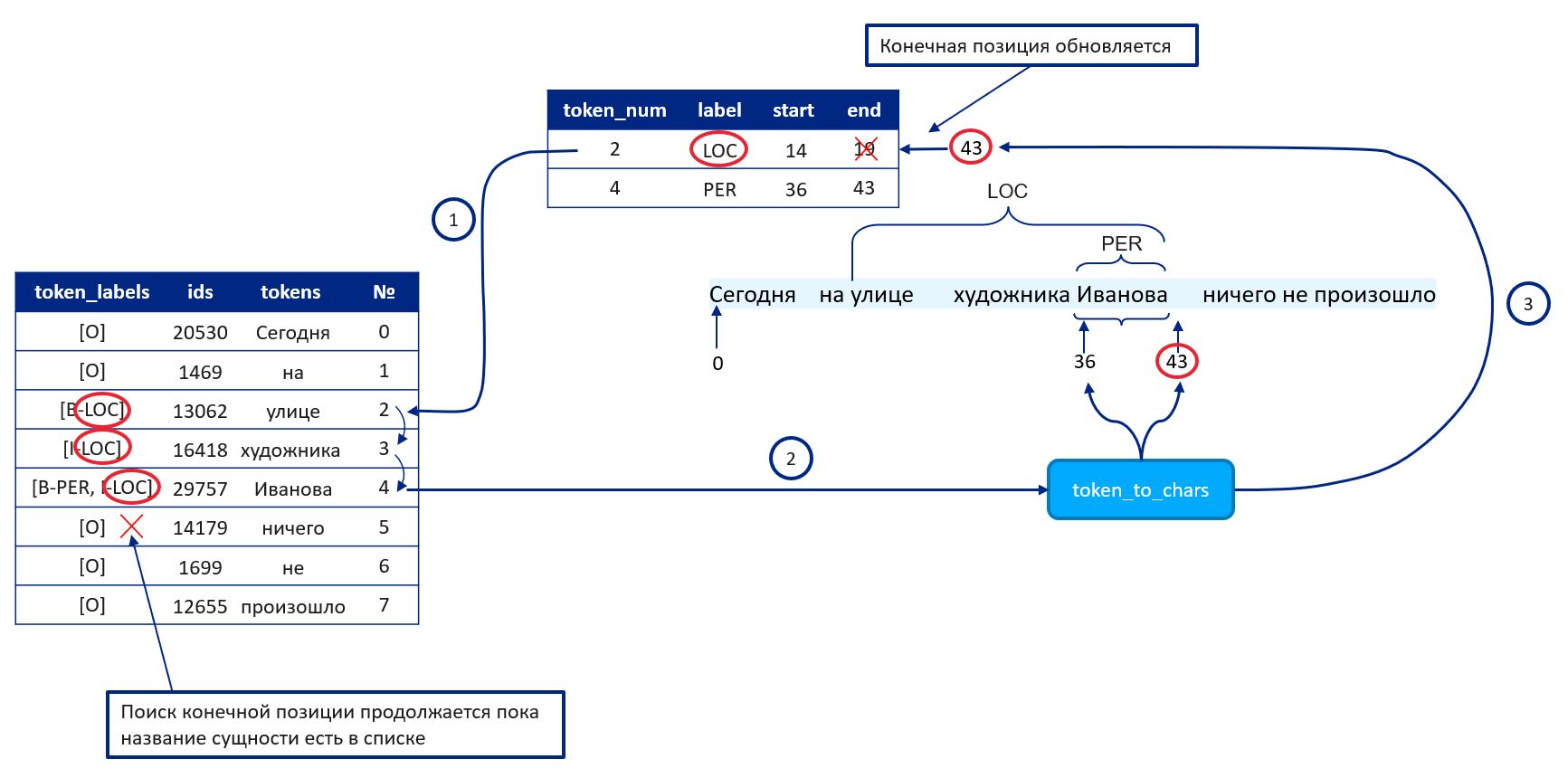
Мы помним, что модель может возвращать мультиметку, если сущности пересекаются. Поэтому для каждого входного токена определяется список меток — путём сопоставления ему идентификатора метки из последовательности labels и преобразования этого идентификатора в название метки с помощью словаря отображения препроцессора. Далее метка разбивается на список меток token_labels разбиением по символу «|».

Если метка из списка token_labels начинается с «B», то есть является первой меткой сущности, тогда по номеру соответствующего ей входного токена с помощью функции token_to_chars объекта encoding определяется начальная и конечная позиция токена, с которого начинается именованная сущность, а также создаётся новый элемент в списке именованных сущностей entities, состоящий из названия именованной сущности (label), её начальной (start) и конечной (end) позиции и номера первого входного токена (token_num), которому она соответствует. Пока конечная позиция представляет собой место в тексте, где заканчивается первый токен именованной сущности, поэтому её необходимо обновить.
Для каждой сущности из списка entities просматриваются токены, начиная от позиции, следующей за token_num, до конца последовательности. Аналогичным образом для каждого токена создаётся список соответствующих ему меток token_labels. Если название сущности есть в списке token_labels, то с помощью функции token_to_chars вычисляется конечная позиция данного токена и обновляется конечная позиция сущности. Просмотр токенов заканчивается, как только название сущности не будет обнаружено в списке token_labels.
Код
def predict(self, text):
encoding = self.preprocessor.tokenizer(text, add_special_tokens=False)[0]
sequences = self.preprocessor.cut_long_sequence(encoding)['input_ids']
input_ids = torch.tensor(sequences)
dataset = TensorDataset(input_ids)
dataloader = DataLoader(dataset, batch_size=self.batch_size, sampler=SequentialSampler(dataset))
labels = []
for batch in dataloader:
batch = batch[0]
with torch.no_grad():
outputs = self.model(batch.to(self.device))
labels_array = np.argmax(outputs.logits.detach().cpu().numpy(), axis=2)
for i in range(len(labels_array)):
l = labels_array[i][(batch[i] != self.preprocessor.tokenizer.pad_token_id) & (batch[i] != self.preprocessor.tokenizer.cls_token_id)]
labels.extend(l)
entities = []
for i in range(len(encoding.tokens)):
token_labels = set(self.preprocessor.id_to_label[labels[i]].split('|'))
for label in token_labels:
if label[0] == 'B':
start, end = encoding.token_to_chars(i)
entity = {
'token_num': i,
'label': label[2:],
'start': start,
'end': end
}
entities.append(entity)
for e in entities:
for i in range(e['token_num'] + 1, len(encoding.tokens)):
token_labels = set(self.preprocessor.id_to_label[labels[i]].split('|'))
label = e['label']
label = f'I-{label}'
if label in token_labels:
end = encoding.token_to_chars(i)[1]
e['end'] = end
else:
break
del e['token_num']
return entitiesКласс Predictor реализован в модуле ner_automl.predictor.
5. BatchSizeSelector
Тут опишем только основную идею определения выбора размера батча.
В основе автоматического определения размера батча лежит метод проб и ошибок. Идея заключается в том, чтобы последовательно генерировать батчи, размер которых увеличивается с каждой итерацией:

На каждой итерации необходимо загрузить модель и батч в GPU, а потом применить модель к батчу, при этом после каждой итерации необходимо чистить видеопамять вызовом метода torch.cuda.empty_cache(). На некоторой итерации с номером k+1 GPU выбросит исключение «CUDA out of memory». Тогда в качества размера батча выбирается 2^k.
В случае работы с CPU всё несколько сложнее и пока задача автоматического определения батча не решена. Если используется CPU, то рекомендуется указывать размер батча вручную.
Код
import psutil
import torch
from transformers import BertConfig, BertForTokenClassification
torch.backends.cudnn.deterministic = True
class BatchSizeSelector:
def __init__(
self,
preprocessor,
bert_config_path,
bert_weights_path,
):
self.preprocessor = preprocessor
self.config = BertConfig.from_pretrained(bert_config_path, num_labels=len(self.preprocessor.id_to_label))
self.model = BertForTokenClassification.from_pretrained(bert_weights_path, config=self.config)
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.model.to(self.device);
def generate_batch(self, size):
torch.manual_seed(0)
batch = dict()
batch['attention_mask'] = torch.ones(size=size, dtype=torch.long)
batch['input_ids'] = torch.randint(low=1, high=self.preprocessor.tokenizer.vocab_size, size=size, dtype=torch.long)
batch['labels'] = torch.randint(low=0, high=len(self.preprocessor.id_to_label), size=size, dtype=torch.long)
return batch
def try_size_cuda(self, size):
try:
batch = self.generate_batch(size)
batch = {k: v.to(self.device) for k, v in batch.items()}
outputs = self.model(**batch)
return True
except RuntimeError as e:
if len(e.args) == 1 and 'CUDA out of memory.' in e.args[0]:
return False
else:
raise e
def try_size_cpu(self, size):
batch = self.generate_batch(size)
batch = {k: v.to(self.device) for k, v in batch.items()}
outputs = self.model(**batch)
vm = psutil.virtual_memory()
if vm.percent >= 85:
return False
else:
return True
def get_optimal_size(self):
batch_size = 1
sequence_len = self.preprocessor.max_len + 1
self.model.train()
while True:
size = (batch_size, sequence_len)
if self.device.type == 'cuda':
success = self.try_size_cuda(size)
torch.cuda.empty_cache()
else:
success = self.try_size_cpu(size)
if success:
batch_size *= 2
else:
batch_size //= 2
return batch_size
def release_memory(self):
device_type = self.device.type
del self.preprocessor
del self.config
del self.model
del self.device
if device_type == 'cuda':
torch.cuda.empty_cache()Класс BatchSizeSelector реализован в модуле ner_automl.batch_size_selector.
6. AutoNER
Класс с двумя статическими методами реализует интерфейс для работы с AutoML.
Первый метод — fit, который выполняет препроцессинг выборок, обучает модель и формирует отчёт с метриками. На вход методу передаются следующие параметры:
checkpoint_path — путь до каталога, в который сохраняется модель;
report_path — путь до каталога, в который сохраняется отчёт;
bert_vocab_path — путь до словаря токенизатора;
bert_config_path — путь до файла конфигурации BERT;
bert_weights_path — путь до предобученных весов BERT;
train_path — путь до обучающей выборки;
valid_path — путь до валидационной выборки;
test_path — путь до тестовой выборки;
batch_size — размер батча. Либо «auto», либо числовое значение;
epochs — количество эпох обучения. По умолчанию 10.
Метод загружает токенизатор и инициализирует препроцессор, который затем возвращает dictionary sequences с ключами train, valid, test. Значениями будут dictionary с входными тензорами для модели.
Опционально определяется размер батча.
Для генерации батчей используется DataLoader в связке с TokenizedDataSet. Для каждой выборки создаётся train_dataloader, valid_dataloader и test_dataloader.
Далее модель дообучается с помощью экземпляра класса Trainer, и рассчитываются метрики качества на всех трёх выборках.
Затем формируется отчёт с метриками качества в формате JSON.
Код
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from transformers import BertTokenizerFast
from ner_automl.preprocessing import Preprocessor, TokenizedDataset
from ner_automl.batch_size_selector import BatchSizeSelector
from ner_automl.trainer import Trainer
from ner_automl.predictor import Predictor
import json
import torch
class AutoNER:
@staticmethod
def fit(
checkpoint_path,
report_path,
bert_vocab_path,
bert_config_path,
bert_weights_path,
train_path,
valid_path,
test_path,
batch_size='auto',
epochs=10
):
tokenizer = BertTokenizerFast(vocab_file=bert_vocab_path, do_lower_case=False)
preprocessor = Preprocessor(tokenizer)
sequences = preprocessor.preprocess(train_path, valid_path, test_path)
if batch_size == 'auto':
batch_size_selector = BatchSizeSelector(preprocessor, bert_config_path, bert_weights_path)
bs = batch_size_selector.get_optimal_size()
batch_size_selector.release_memory()
else:
bs = batch_size
train_dataset = TokenizedDataset(sequences['train'])
valid_dataset = TokenizedDataset(sequences['valid'])
test_dataset = TokenizedDataset(sequences['test'])
train_dataloader = DataLoader(train_dataset, batch_size=bs, sampler=RandomSampler(train_dataset))
valid_dataloader = DataLoader(valid_dataset, batch_size=bs, sampler=SequentialSampler(valid_dataset))
test_dataloader = DataLoader(test_dataset, batch_size=bs, sampler=SequentialSampler(test_dataset))
trainer = Trainer(
preprocessor,
checkpoint_path,
bert_config_path,
bert_weights_path,
epochs
)
trainer.fit(train_dataloader, valid_dataloader)
train_metrics = trainer.evaluate(train_dataloader, all_metrics=True)
valid_metrics = trainer.evaluate(valid_dataloader, all_metrics=True)
test_metrics = trainer.evaluate(test_dataloader, all_metrics=True)
report = {
'loss': {
'train': trainer.train_losses,
'valid': trainer.valid_losses
},
'metrics': {
'train': train_metrics,
'valid': valid_metrics,
'test': test_metrics
}
}
with open(report_path, 'w') as f:
json.dump(report, f)
del trainer
torch.cuda.empty_cache()Второй метод from_pretrained создаёт экземпляр класса predictor и возвращает его. На вход метод принимает checkpoint_path, bert_vocab_path и bert_config_path.
Код
@staticmethod
def from_pretrained(
checkpoint_path,
bert_vocab_path,
bert_config_path,
):
tokenizer = BertTokenizerFast(vocab_file=bert_vocab_path, do_lower_case=False)
preprocessor = Preprocessor(tokenizer)
predictor = Predictor(preprocessor, checkpoint_path, bert_config_path)
return predictorКласс AutoNER реализован в модуле ner_automl.auto.
Работа с библиотекой
1. Дообучение модели
На этапе обучения необходимо выполнить следующие шаги:
Импортировать класс AutoNER из модуля ner_automl.auto:
from ner_automl.auto import AutoNER2. Задать следующие пути:
путь до словаря токенизатора
bert_vocab_path = 'bert_path/vocab.txt'путь до конфигурационного файла BERT
bert_config_path = 'bert_path/bert_config.json'путь до предобученных весов BERT
bert_weights_path = 'bert_path/pytorch_model.bin'путь до файла, в который будут сохраняться веса модели
checkpoint_path = 'checkpoint/model.bin'путь до файла, в который будут сохраняться метрики в формате JSON
report_path = 'report_path/report.json'пути до обучающей, валидационной и тестовой выборки
train_path = 'data/train.jsonl'
valid_path = 'data/valid.jsonl'
test_path = 'data/test.jsonl'3. Вызвать статический метод fit класса AutoNER для обучения модели:
AutoNER.fit(
checkpoint_path,
report_path,
bert_vocab_path,
bert_config_path,
bert_weights_path,
train_path,
valid_path,
test_path,
batch_size='auto',
epochs=10,
)2. Инференс
На этапе инференса нам необходимо выполнить следующие шаги:
Импортировать класс AutoNER из модуля ner_automl.auto:
from ner_automl.auto import AutoNER2. Задать следующие пути:
путь до словаря токенизатора
bert_vocab_path = 'bert_path/vocab.txt'путь до конфигурационного файла BERT
bert_config_path = 'bert_path/bert_config.json'путь до файла, в который были сохранены веса модели на этапе обучения
checkpoint_path = 'checkpoint/model.bin'3. Вызвать статический метод from_pretrained класса AutoNER, возвращающий экземпляр класса Predictor:
predictor = AutoNER.from_pretrained(
checkpoint_path,
bert_vocab_path,
bert_config_path
)4. Задать текст:
text = '''
Здесь могла бы быть ваша реклама.
'''5. Сделать прогноз именованных сущностей:
entities = predictor.predict(text)Результаты на открытых данных
Мы тестировали библиотеку на датасетах Named_Entities_3, Named_Entities_5 и factRuEval. Во всех датасетах есть длинные тексты, но пересечение именованных сущностей встречается только в датасете factRuEval.
Метрики качества для датасетов Named_Entities_3, Named_Entities_5 приведены в таблицах:
Named_Entities_3 | precision | recall | f1-score | |
Train | location | 99.39% | 99.55% | 99.47% |
organization | 97.49% | 97.73% | 97.61% | |
person | 99.78% | 99.80% | 99.79% | |
micro avg | 98.93% | 99.06% | 98.99% | |
macro avg | 98.89% | 99.03% | 98.96% | |
Valid | location | 98.22% | 99.40% | 98.81% |
organization | 93.24% | 94.88% | 94.05% | |
person | 99.76% | 99.76% | 99.76% | |
micro avg | 97.23% | 98.11% | 97.67% | |
macro avg | 97.07% | 98.01% | 97.54% | |
Test | location | 96.98% | 98.38% | 97.68% |
organization | 93.08% | 94.34% | 93.71% | |
person | 99.87% | 99.81% | 99.84% | |
micro avg | 96.88% | 97.68% | 97.27% | |
macro avg | 96.64% | 97.51% | 97.08% | |
Named_Entities_5 | precision | recall | f1-score | |
Train | GEOPOLIT | 99.38% | 99.21% | 99.30% |
LOC | 98.94% | 98.80% | 98.87% | |
MEDIA | 96.86% | 97.83% | 97.34% | |
ORG | 98.02% | 98.29% | 98.15% | |
PER | 99.99% | 99.97% | 99.98% | |
micro avg | 99.06% | 99.14% | 99.10% | |
macro avg | 82.20% | 82.35% | 82.27% | |
Valid | GEOPOLIT | 97.24% | 96.76% | 97.00% |
LOC | 92.07% | 93.93% | 92.99% | |
MEDIA | 92.39% | 95.79% | 94.06% | |
ORG | 88.92% | 92.03% | 90.45% | |
PER | 99.60% | 99.60% | 99.60% | |
micro avg | 95.08% | 96.30% | 95.69% | |
macro avg | 94.04% | 95.62% | 94.82% | |
Test | GEOPOLIT | 97.69% | 98.21% | 97.95% |
LOC | 94.78% | 95.65% | 95.22% | |
MEDIA | 96.19% | 93.95% | 95.06% | |
ORG | 88.71% | 92.67% | 90.65% | |
PER | 99.18% | 99.59% | 99.39% | |
micro avg | 95.24% | 96.64% | 95.93% | |
macro avg | 95.31% | 96.02% | 95.65% | |
В целом модель обучилась достаточно хорошо. Ниже приведён пример подсветки длинного текста, взятого с сайта, выданного гуглом по запросу «очень длинная статья». Даже при наличии лишних разделителей между словами именованные сущности корректно подсвечиваются.

На датасете factRuEval модель работает хуже. Во-первых, из-за того, что он небольшой, во-вторых, из-за пересекающихся сущностей. Результаты для непересекающихся сущностей приведены в таблице.
precision | recall | f1-score | ||
Train | job | 74.17 % | 82.04 % | 77.91 % |
loc_name | 89.25 % | 94.51 % | 91.81 % | |
name | 94.33 % | 97.83 % | 96.05 % | |
org_descr | 55.06 % | 72.73 % | 62.67 % | |
org_name | 77.63 % | 80.82 % | 79.19 % | |
surname | 96.28 % | 97.98 % | 97.12 % | |
micro avg | 83.78 % | 79.45 % | 81.56 % | |
macro avg | 16.20 % | 11.29 % | 11.43 % | |
Valid | job | 53.85 % | 66.67 % | 59.57 % |
loc_name | 80.14 % | 91.05 % | 85.25 % | |
name | 95.15 % | 97.03 % | 96.08 % | |
org_descr | 42.31 % | 57.89 % | 48.89 % | |
org_name | 56.61 % | 57.53 % | 57.07 % | |
surname | 95.59 % | 99.30 % | 97.41 % | |
micro avg | 75.72 % | 70.12 % | 72.82 % | |
macro avg | 11.75 % | 10.67 % | 10.42 % | |
Test | job | 61.25 % | 75.53 % | 67.64 % |
loc_name | 85.56 % | 89.95 % | 87.70 % | |
name | 87.89 % | 91.32 % | 89.57 % | |
org_descr | 47.67 % | 46.68 % | 47.17 % | |
org_name | 73.37 % | 78.49 % | 75.84 % | |
surname | 92.93 % | 97.35 % | 95.09 % | |
micro avg | 76.97 % | 69.02 % | 72.78 % | |
macro avg | 8.11 % | 7.95 % | 7.75 % | |
С пересечениями всё ещё хуже. Почти везде значения метрик упали до 0 в связи с низкой частотой встречаемости меток. Отсюда следует, что алгоритм работы с пересекающимися сущностями нужно изменить, а текущую реализацию применять только для датасетов, в которых сущности не пересекаются.
Пути улучшения библиотеки
Что ж, нужно признать, что библиотека пока не идеальна и требует доработок. Но её уже можно использовать для автоматизации решения задачи NER. А доработки можно начать с рефакторинга кода.
Первая проблема, которую нужно решить, — это работа с пересекающимися и иерархическими именованными сущностями. Возможно, потребуется использование других моделей, которые лучше справляются с данной задачей.
Вторая немаловажная проблема, которая стала возникать чаще, — это отсутствие у пользователя выборок большого объёма. Обычно пользователь располагает выборкой в 10–15 примеров. Поэтому необходимо решать задачу Few-shot NER. Пока мы проводим эксперименты на основе этих статей: раз, два.
Третья проблема — это разбиение последовательностей на этапе инференса. Алгоритм может разбить последовательность таким образом, что часть именованной сущности попадёт в разные подпоследовательности. В таком случае модель вернёт две именованные сущности, идущие друг за другом. Один из путей решения этой проблемы — делать скользящее окно, которое передвигается по всей последовательности, а инференс осуществлять в рамках скользящего окна. В результате выбирать тот вариант инференса, в котором нет одинаковых подряд идущих именованных сущностей, а только одна.
Ещё одним выходом из ситуации может быть ∞-former. Авторы решили проблему длинных последовательностей.
Кроме того, есть планы добавить обучение других моделей, чтобы потом можно было выбрать наилучшую по некоторому критерию качества.
Если у вас есть какие-то вопросы или мысли по теме — пишите в комментариях. Может быть, у вас тоже был опыт работы с подобной задачей и вам есть что сказать.
