Добрый день, сообщество!
Наверняка кто-то из вас сталкивался с такой проблемой: медленно работает сайт на реальном сервере.
Важно оперативно выяснить в каких местах возникли сложности. Использовать для этого xdebug нельзя, так как он создает большую нагрузку на сервер и сам вносит погрешность в измерения. Для решения этой задачи мы выбрали систему, которая позволяет очень быстро собирать древовидную статистику по работе сайта — pinba.
На хабре уже рассказывали о специфике работы с pinba. Если вы не читали, можете ознакомиться по ссылке.
Для нетерпеливых сразу дам ссылку на результат.
Plus1 WapStart работает в штатном режиме при нагрузке более 1000 запросов в секунду на один инстанс.
Pinba отправляет на свой сервер (по UDP, очень быстро) метки начала и конца отрезка времени (далее — таймеры) и складывает данные в MySQL таблицы (легко прочитать). Например
Для построения древовидной структуры мы добавляем 2 дополнительных тега — tree_id (каждый раз уникальный id) и tree_parent_id — это tree_id от того таймера, в который вложен текущий. Например
Таким образом, на сервере можно воспроизвести вложенность таймеров и построить удобочитаемое дерево.
Мы разместили во всех интересных местах проекта таймеры, чтобы засекать время (например, при sql запросах, при записи в файлы и т.д.).
К сожалению, pinba не использует индексы для запросов (кроме PRIMARY), так как используется свой pinba ENGINE (таблицы фактически хранятся в memory, и данные старше N минут удаляются, в нашем случае — 5 минут). Но нельзя сетовать на pinba, так как она предназначена не для запросов по индексам.
Для нас индексы важны, потому мы копируем все данные из таблиц pinba в обычные MyISAM таблицы.
Как видно из запросов, у нас система работает в базе pinba, а копия — в базе pinba_cache.
Так же для работы нам понадобится ещё одна таблица, в которой будут поля tree_id и tree_parent_id.
Структура таблицы timer_tag_tree приведена ниже. Структура остальных таблиц такая же как в pinba.
Теперь — самое интересное. Мы собрали данные, сложили их так, как нам необходимо для последующей работы. Далее необходимо написать скрипт, который все эти данные выдаст в удобном виде.
Как вывести одно дерево (от одного запроса к сайту) — писать не буду, так как это тривиальная задача.
Проблема в том, что для оценки узких мест нужно проанализировать сотни запросов к php, каждый из которых имеет свое дерево вызова функций (таймеров). Нам нужно из этих деревьев собрать одно обобщенное дерево.
Алгоритм объединения следующий:
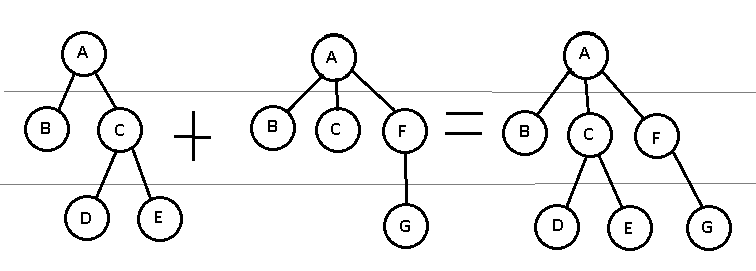
Для каждого узла считаем сумму времен выполнения этого узла по всем деревьям.
Написав функцию для объединения двух деревьев, можно пройтись циклом по всем и получить сумму.
Но тут нас ждет неприятный сюрприз — медленное время работы.
Как видим из картинки, сложность объединения 2 деревьев — O(N*N) (внимательные мне подскажут, что можно сделать это за N*log(N), но далее будет более простой метод оптимизации, в 3 строчки), где N — к-во узлов в дереве. Соответственно выгодно объединять маленькие деревья, и очень невыгодно большие.
Постараемся эту особенность использовать. Давайте определим дерево выполнения одного скрипта как дерево 1 уровня, сумма двух деревьев первого уровня — дерево второго уровня и т.д. В таких терминах нам нужно объединять побольше деревьев первого уровня, и минимум большого уровня. Делать это будем так:
как видим, суммарное к-во объединений было N-1, из которых N/2 — первого уровня, N/4 — второго уровня, N/8 — третьего и т.д.
Реализуется эта хитрость крайне просто с помощью рекурсии (при желании её можно разложить в цикл, но для большей понятности я этого делать не буду).
Таким образом, мы сначала объединим изначальные деревья в 2х, а потом уже их будет объединять в деревья побольше. Выигрыш по времени у нас составил в ~10 раз (1000 деревьев).
Полезные файлы:
Скрипт для отображения дерева: index.php
MySQL скрипт для преобразования данных cron.sql
PinbaClient.class.php — обертка над pinba для более удобного использования с автоматическим добавлением tree_id, tree_parent_id
Так же хочется упомянуть фреймворк onphp, в котором есть нативная поддержка pinba
https://github.com/ents/pinba-php-profiler/ — исходные файлы, чтобы поднять все у себя
http://pinba.org/ — тут можно скачать pinba
Дисклаймер: Данная статья носит популярный характер и не может рассматриваться как руководство к действию. Все действия, описанные ниже не есть истина в последней инстанции, а скорее один из немногих способов сделать визуализацию информации из pinba
Наверняка кто-то из вас сталкивался с такой проблемой: медленно работает сайт на реальном сервере.
Важно оперативно выяснить в каких местах возникли сложности. Использовать для этого xdebug нельзя, так как он создает большую нагрузку на сервер и сам вносит погрешность в измерения. Для решения этой задачи мы выбрали систему, которая позволяет очень быстро собирать древовидную статистику по работе сайта — pinba.
На хабре уже рассказывали о специфике работы с pinba. Если вы не читали, можете ознакомиться по ссылке.
Для нетерпеливых сразу дам ссылку на результат.
Plus1 WapStart работает в штатном режиме при нагрузке более 1000 запросов в секунду на один инстанс.
Как это все работает?
Сбор данных
Pinba отправляет на свой сервер (по UDP, очень быстро) метки начала и конца отрезка времени (далее — таймеры) и складывает данные в MySQL таблицы (легко прочитать). Например
$timer = pinba_timer_start(array('tag' => 'some_logic'));
....
pinba_timer_stop($timer);
Для построения древовидной структуры мы добавляем 2 дополнительных тега — tree_id (каждый раз уникальный id) и tree_parent_id — это tree_id от того таймера, в который вложен текущий. Например
$parent_timer = pinba_timer_start(array('tag' =>'some_logic', 'tree_id' => 1, 'tree_parent_id' => 'root'));
$child_timer = pinba_timer_start(array('tag' =>'child_logic', 'tree_id' => 2, 'tree_parent_id' => 1));
pinba_timer_stop($child_timer);
pinba_timer_stop($parent_timer);
Таким образом, на сервере можно воспроизвести вложенность таймеров и построить удобочитаемое дерево.
Мы разместили во всех интересных местах проекта таймеры, чтобы засекать время (например, при sql запросах, при записи в файлы и т.д.).
Подготовка данных
К сожалению, pinba не использует индексы для запросов (кроме PRIMARY), так как используется свой pinba ENGINE (таблицы фактически хранятся в memory, и данные старше N минут удаляются, в нашем случае — 5 минут). Но нельзя сетовать на pinba, так как она предназначена не для запросов по индексам.
Для нас индексы важны, потому мы копируем все данные из таблиц pinba в обычные MyISAM таблицы.
truncate table pinba_cache.request;
truncate table pinba_cache.tag;
truncate table pinba_cache.timer;
truncate table pinba_cache.timertag;
insert ignore into pinba_cache.request select * from pinba.request;
insert ignore into pinba_cache.tag select * from pinba.tag;
insert ignore into pinba_cache.timer select * from pinba.timer;
insert ignore into pinba_cache.timertag select * from pinba.timertag;
Как видно из запросов, у нас система работает в базе pinba, а копия — в базе pinba_cache.
Так же для работы нам понадобится ещё одна таблица, в которой будут поля tree_id и tree_parent_id.
truncate table pinba_cache.timer_tag_tree;
insert ignore into pinba_cache.timer_tag_tree
SELECT * FROM (
SELECT null, timer_id, request_id, hit_count, timer.value, GROUP_CONCAT(timertag.value) as tags
, (select timertag.value from pinba_cache.timertag where timertag.timer_id=timer.id and tag_id = (select id from pinba_cache.tag where name='treeId')) as tree_id
, (select timertag.value from pinba_cache.timertag where timertag.timer_id=timer.id and tag_id = (select id from pinba_cache.tag where name='treeParentId')) as tree_parent_id
FROM pinba_cache.timertag force index (timer_id)
LEFT JOIN pinba_cache.timer ON timertag.timer_id=timer.id
where not tag_id in ((select id from pinba_cache.tag where name='treeId'), (select id from pinba_cache.tag where name='treeParentId'))
group by timertag.timer_id
order by timer_id
) as tmp
GROUP BY tree_id;
Структура таблицы timer_tag_tree приведена ниже. Структура остальных таблиц такая же как в pinba.
CREATE TABLE `timer_tag_tree` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`timer_id` INT(10) NOT NULL DEFAULT '0',
`request_id` INT(10) NULL DEFAULT NULL,
`hit_count` INT(10) NULL DEFAULT NULL,
`value` FLOAT NULL DEFAULT NULL,
`tags` VARCHAR(128) NULL DEFAULT NULL,
`tree_id` VARCHAR(35) NOT NULL DEFAULT '',
`tree_parent_id` VARCHAR(35) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
INDEX `timer_id` (`timer_id`),
INDEX `tree_id_tree_parent_id` (`tree_id`, `tree_parent_id`),
INDEX `tree_parent_id_tree_id` (`tree_parent_id`, `tree_id`)
)
COLLATE='utf8_general_ci'
ENGINE=MyISAM
Анализ данных
Теперь — самое интересное. Мы собрали данные, сложили их так, как нам необходимо для последующей работы. Далее необходимо написать скрипт, который все эти данные выдаст в удобном виде.
Как вывести одно дерево (от одного запроса к сайту) — писать не буду, так как это тривиальная задача.
Проблема в том, что для оценки узких мест нужно проанализировать сотни запросов к php, каждый из которых имеет свое дерево вызова функций (таймеров). Нам нужно из этих деревьев собрать одно обобщенное дерево.
Алгоритм объединения следующий:

Для каждого узла считаем сумму времен выполнения этого узла по всем деревьям.
Написав функцию для объединения двух деревьев, можно пройтись циклом по всем и получить сумму.
Но тут нас ждет неприятный сюрприз — медленное время работы.
Как видим из картинки, сложность объединения 2 деревьев — O(N*N) (внимательные мне подскажут, что можно сделать это за N*log(N), но далее будет более простой метод оптимизации, в 3 строчки), где N — к-во узлов в дереве. Соответственно выгодно объединять маленькие деревья, и очень невыгодно большие.
Постараемся эту особенность использовать. Давайте определим дерево выполнения одного скрипта как дерево 1 уровня, сумма двух деревьев первого уровня — дерево второго уровня и т.д. В таких терминах нам нужно объединять побольше деревьев первого уровня, и минимум большого уровня. Делать это будем так:
как видим, суммарное к-во объединений было N-1, из которых N/2 — первого уровня, N/4 — второго уровня, N/8 — третьего и т.д.
Реализуется эта хитрость крайне просто с помощью рекурсии (при желании её можно разложить в цикл, но для большей понятности я этого делать не буду).
//принимает на вход массив деревьев, на выход - объединенное дерево
function mergeTreeList(array $treeList) {
if (count($treeList) > 2) {
return mergeTreeList( половина($treeList), вторая_половина($treeList));
}
//...
//тут идет код объединения
}
Таким образом, мы сначала объединим изначальные деревья в 2х, а потом уже их будет объединять в деревья побольше. Выигрыш по времени у нас составил в ~10 раз (1000 деревьев).
Итого
- Мы разместили pinba-таймеры в нашем приложении, где посчитали нужным
- Мы сформировали агрегированное дерево выполнения на основании многих запросов к скриптам
- По построенному дереву можно анализировать узкие места проекта, можно строить графики скорости выполнения отдельных кусков проекта
- Все это происходит прямо на живом сервере с большой нагрузкой
Подводные камни и минусы
- На нашем проекте пинба так быстро пишет (и удаляет старое), что запрос insert into table_copy select * from table копирует в 2-3 раза больше данных, чем изначально было в таблице. Потому на время копирования таблиц нужно останавливать запись в pinba (я останавливал сеть на сервере фаерволом)
- Pinba потребляет много памяти (у нас — 2 Gb чтобы хранить данные за 5 минут), так как мы вместо одного тега пишем 3 (+tree_id, +tree_parent_id)
- При копировании приходится отключать сеть, чтобы остановить запись в таблицы (на 5-10 секунд), из-за чего теряются данные за эти 5-10 секунд
Полезные файлы:
Скрипт для отображения дерева: index.php
MySQL скрипт для преобразования данных cron.sql
PinbaClient.class.php — обертка над pinba для более удобного использования с автоматическим добавлением tree_id, tree_parent_id
Так же хочется упомянуть фреймворк onphp, в котором есть нативная поддержка pinba
https://github.com/ents/pinba-php-profiler/ — исходные файлы, чтобы поднять все у себя
http://pinba.org/ — тут можно скачать pinba
Дисклаймер: Данная статья носит популярный характер и не может рассматриваться как руководство к действию. Все действия, описанные ниже не есть истина в последней инстанции, а скорее один из немногих способов сделать визуализацию информации из pinba
