 Итак, настало время подвести итоги прошедшего майского хабрасоревнования. Было прислано 49 решений, удовлетворяющих требованиям по оформлению и 8 решений вне конкурса (позже дедлайна, с ошибками оформления, на неверный адрес). Что-ж, посмотрим, кто что написал.
Итак, настало время подвести итоги прошедшего майского хабрасоревнования. Было прислано 49 решений, удовлетворяющих требованиям по оформлению и 8 решений вне конкурса (позже дедлайна, с ошибками оформления, на неверный адрес). Что-ж, посмотрим, кто что написал.Хотя в обсуждении топика с самой задачей люди переживали, что самое компактное и самое быстрое решение — это разные вещи, оказалось что решение победителя lany — является и самым компактным, удовлетворяющим всем требованиям. Решение Frommi было вдвое компактнее, 863 байта — но не смогло пройти все тесты. Следующим шло решение ibessonov на 1613 байта — но оно внезапно показало большую ошибку на первом тесте.
Если у меня читатели не найдут ошибки, тройка победителей будет выглядеть так:
- lany — двойной победитель, 89.9448 баллов и самое компактное решение.
Самый большой тест (2.4Гб) пройден за 0.61 секунду.
Смотреть исходник//@lany public class G{java.io.InputStream I=System.in;int c,i=0,j,m,M;double[]S=new double[512],C=new double[512];byte[]P="111001100011101101".getBytes(),d=new byte[999999];double N=4.0678884e13,L=29.9792458,X,Y,q,F,G,H=1e99;S[]z;S f,g;class S{double x,y,r,q,R,Q;S(){x=new Double(l());y=new Double(l());try{I.read(d);I.skip(9000001);}catch(Exception e){}q=L*o()+L/2;Q=q*q;r=q-L;R=r*r;l();}int o(){int o=0,p;for(;;o+=10){for(p=0;p<18;p++)if(P[p]!=d[o+p*10])break;if(p==18){while(d[--o]>48);return o+1;}}}}void u(double X,double Y){if(X*X+Y*Y<N){double S=d(X,Y);if(S<H){H=S;F=X;G=Y;}}}double d(double x,double y){double q=0,Q=-1,X,Y;for(S s:z){X=x-s.x;Y=y-s.y;X=X*X+Y*Y;if(X>s.Q)q+=X-s.Q;else if(X<s.R)q+=s.R-X;else if(q==0){Y=Math.sqrt(X);Q*=Math.min(s.q-Y,Y-s.r)*.1;}}return q>0?q:Q;}void b(double r,double R){if(r+R>q){double d=Math.abs(r*r-R*R+q*q)/2/q,h=Math.sqrt(r*r-d*d),x=f.x+X*d,y=f.y+Y*d;u(x-Y*h,y+X*h);u(x+Y*h,y-X*h);}}String l(){char[]o=new char[99];int p=0,b;try{while((b=I.read())!=10)o[p++]=(char)b;}catch(Exception e){}return new String(o,0,p).trim();}public static void main(String[]a){new G();}G(){for(;i<512;i++){q=Math.PI*i/256;S[i]=Math.sin(q);C[i]=Math.cos(q);}c=new Short(l());z=new S[c];for(i=0;i<c;)z[i++]=new S();for(i=1;i<c&&H>0;i++)for(j=0;j<i&&H>0;j++){f=z[i];g=z[j];X=g.x-f.x;Y=g.y-f.y;q=Math.sqrt(X*X+Y*Y);X/=q;Y/=q;b(f.q,g.q);b(f.r,g.q);b(f.q,g.r);b(f.r,g.r);}double x=F,y=G,r=d(x,y),t=r<1e10?1e3:3e6,u,v,w,R;while(t>.1&&(i++<999||r>0)){R=r;X=x;Y=y;for(M=4;M<513&&R==r;M*=2){for(m=0;m<M;m++)if(M<5||m%2>0){j=m*512/M;u=x+S[j]*t;v=y+C[j]*t;if(u*u+v*v<N){w=d(u,v);if(w<R){X=u;Y=v;R=w;}}}}if(R<r){x=X;y=Y;r=R;}else t/=2;}System.out.println(x+" "+y);}} - @AKashta — 86.9558 балла, на самом большом тесте вдвое быстрое lany, но немного проиграл по точности.
Смотреть исходник//@AKashta import java.io.*; import java.util.ArrayList; public class Main { public static final boolean ADVANCED_MODE = true; public static final int MAX_POINTS = 50; public static final double PRECISION = 30; public static final int THRESHOLD = 300; public static final String START_TOKEN = "111001100011101101"; public static final long DATA_LENGTH = 10000000; public static final long SPEED = 299792458; public static final long EARTH_R = 6378000; public static final long MIN_SAT_POS = 10000000; public static final long MAX_SAT_POS = 20000000; public static final int MIN_OFFSET = (int)((MIN_SAT_POS - EARTH_R) * DATA_LENGTH / SPEED); public static final int MAX_OFFSET = (int)((MAX_SAT_POS + EARTH_R) * DATA_LENGTH / SPEED); public static void main(String args[ ]) { //long startTime = System.currentTimeMillis(); try { DataInputStream in = new DataInputStream(System.in); DataReader reader = new DataReader(in); Point result = null; int q = reader.readInt(); ArrayList<Circle> sats = new ArrayList<Circle>(q); for(int i = 0; i < Math.min(q, MAX_POINTS); i++) { double x = reader.readDouble(); double y = reader.readDouble(); int offset = reader.readOffset(); double radius = ((double)SPEED / DATA_LENGTH * offset); sats.add(new Circle(new Point(x, y), radius)); } if(sats.size() == 2) { ArrayList<Point> points = sats.get(0).intersect(sats.get(1)); for(Point p : points) { result = p; break; } } else { if(ADVANCED_MODE) { result = advancedCalc(sats); } else { result = simpleCalc(sats); } } System.out.println(result.x + " " + result.y); //long time = (System.currentTimeMillis() - startTime); //System.out.println("Time: " + time); } catch (Exception e) { System.out.println(e.getMessage()); } } public static Point findRefPoint(ArrayList<Circle> sats){ ArrayList<Point> points = new ArrayList<Point>(); for(int i = 0; i < 2; i++) { for(int j = i + 1; j < 3; j++) { points.addAll(sats.get(i).intersect(sats.get(j))); } } Point p0 = null, p1 = null, p2 = null; for(Point p : points) { for(Point t : points) { if(p1 == null && t != p && p.distance(t) < THRESHOLD){ p1 = t; continue; } if(p1 != null && t != p && t != p1 && p.distance(t) < THRESHOLD){ p2 = t; break; } } if(p1 != null && p2 != null) { p0 = p; break; } else { p1 = null; p2 = null; } } return new Point((p0.x + p1.x + p2.x) / 3, (p0.y + p1.y + p2.y) / 3); } public static Point advancedCalc(ArrayList<Circle> sats){ ArrayList<Point> allPoints = new ArrayList<Point>(); for(int i = 0; i < sats.size() - 1; i++) { for(int j = i + 1; j < sats.size(); j++) { allPoints.addAll(sats.get(i).intersect(sats.get(j))); } } int count = 0; double sumX = 0; double sumY = 0; for(Point p : allPoints) { boolean containsInAll = true; for (Circle sat : sats){ if(!sat.hasPoint(p)) { containsInAll = false; break; } } if(containsInAll) { count++; sumX += p.x; sumY += p.y; } } return new Point(sumX / count, sumY / count); } public static Point simpleCalc(ArrayList<Circle> sats){ int count = 0; double sumX = 0; double sumY = 0; Point refPoint = findRefPoint(sats); for(int i = 0; i < sats.size() - 1; i++) { for(int j = i + 1; j < sats.size(); j++) { for(Point p : sats.get(i).intersect(sats.get(j))) { if(refPoint.distance(p) < THRESHOLD) { count++; sumX += p.x; sumY += p.y; } } } } return new Point(sumX / count, sumY / count); } public static class DataReader { private DataInputStream _in; public DataReader(DataInputStream in){ _in = in; } public int readOffset() throws Exception { byte firstByte = _in.readByte(); int offset = 1; while( _in.readByte() == firstByte) { offset++; } int needToSkip = ((MIN_OFFSET - offset) / 10) * 10; _in.skipBytes(needToSkip); offset += needToSkip; byte[] buffer = new byte[MAX_OFFSET - offset]; _in.read(buffer); _in.skipBytes((int) DATA_LENGTH - offset - buffer.length - 1 + 2); StringBuilder sb = new StringBuilder(buffer.length / 10); for(int i = 0; i < buffer.length / 10; i++ ){ sb.append((char) buffer[i * 10]); } int index = sb.indexOf(START_TOKEN)* 10; return index + offset; } public String readLine() throws Exception { StringBuilder sb = new StringBuilder(); char c; while((c = (char)_in.readByte()) != '\r') { sb.append(c); } _in.readByte(); // read '\n' char return sb.toString(); } public int readInt() throws Exception { String s = readLine(); return Integer.parseInt(s); } public Double readDouble() throws Exception { String s = readLine(); return Double.parseDouble(s); } } public static class Point { public double x; public double y; public Point(double x, double y) { this.x = x; this.y = y; } public double distance() { return Math.sqrt(x*x + y*y); } public double distance(Point p) { return Math.sqrt(Math.pow(x - p.x, 2) + Math.pow(y - p.y, 2)); } } public static class Circle { public Point center; public double radius; public Circle(Point p, double r) { center = p; radius = r; } public ArrayList<Point> intersect(Circle c) { ArrayList<Point> result = new ArrayList<Point>(); double dx = c.center.x - center.x; double dy = c.center.y - center.y; double d = Math.sqrt((dy * dy) + (dx * dx)); if(d < Math.abs(radius - c.radius)) { if(radius < c.radius) radius += Math.abs(radius - c.radius) - d + 0.1; else c.radius += Math.abs(radius - c.radius) - d + 0.1; } if (d > (radius + c.radius)) { double add = (d - (radius + c.radius))/ 2.0 + 0.1; radius += add; c.radius += add; } if (d > (radius + c.radius) || d < Math.abs(radius - c.radius)) { //System.out.println("do not intersect"); return result; } double a = ((radius * radius) - (c.radius * c.radius) + ( d *d)) / (2.0 * d); Point p2 = new Point(center.x + (dx * a/d), center.y + (dy * a/d)); double h = Math.sqrt((radius * radius) - (a*a)); double rx = -dy * (h/d); double ry = dx * (h/d); Point p = new Point(p2.x + rx, p2.y + ry); if(p.distance() <= EARTH_R) { result.add(p); } p = new Point(p2.x - rx, p2.y - ry); if(p.distance() <= EARTH_R) { result.add(p); } return result; } public boolean hasPoint(Point p) { double d = center.distance(p); return Math.abs(d - radius) <= PRECISION; } } } - habrunit — 83.9379 балла, буквально вырвал призовое место из рук Staker.
Смотреть исходник//@habrunit //package olimp; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; import java.io.UnsupportedEncodingException; import java.security.NoSuchAlgorithmException; import static java.lang.Math.*; public class Olimp { private static int cash[]={0xc0001200,0x10818201,0x51feba02,0x1483a003,0xb6ffc304,0x8d953105,0x1b2e7e06,0x780a707,0x59041a08,0x283b1c09,0x5818430a,0xc13b950b,0x3921ed0c,0x599b60d,0x99c8400e,0x2612640f,0xb7b0ca10,0x8c17d11,0xd35fda12,0x96863f13,0xca7ea414,0x90875415,0xc860e416,0x6239c317,0x9f39d418,0xccc48419,0x3f43d11a,0x9e366d1b,0x37fc9a1c,0x103bd91d,0xe96c501e,0x80ccf81f,0x602aca20,0xed28b721,0xcedf2d22,0xd2da9e23,0x93574024,0xebba4125,0x77fcc26,0xf8eb1a27,0xc6e09728,0x58dfe129,0xc776642a,0x6688342b,0x102a252c,0xedec802d,0xdf737f2e,0x4b5b402f,0x9c29fb30,0x93300a31,0xc30d2b32,0xabe73633,0x61f4fa34,0xf4334c35,0xd27b8a36,0xf7b63e37,0x602d9038,0x2e8aff39,0x4e62003a,0xc489143b,0x4e5ed53c,0x57a46f3d,0xf6630b3e,0xb392f53f,0xba827340,0x5b9b7e41,0x3e9d1f42,0x29b2c743,0x47f8644,0xe4d74745,0xf1263046,0x3d44e47,0xb1905148,0xd079d849,0x66f16d4a,0x281ff94b,0x4cbc284c,0xe364e94d,0x5fda1a4e,0x4628d24f,0x47d17d50,0x53ca2751,0x6738c52,0x2a1c9653,0xcdab0454,0x7429e855,0x91c38556,0xb3c8ab57,0xa98cb258,0x26151d59,0x5525b75a,0xd955c75b,0x51c3475c,0x8350855d,0x1c30b65e,0x70339d5f,0x78a88460,0x4cc2a361,0x12464c62,0x5a34b63,0x3fee8864,0xa8633565,0x3e23d766,0xf8cd5767,0x52432068,0x9cae0969,0x63aa1d6a,0x8742826b,0x75e67b6c,0x2ef696d,0x25006d6e,0x89daa76f,0xbbb71870,0x2faca571,0x71374172,0x9b818673,0xa0de6274,0x29326075,0xb2401776,0x8edcb677,0x7a265378,0x87dd7779,0xb726ce7a,0x99f0397b,0x81a8967c,0x97d0437d,0xc9147e,0x27a1a17f,0xabd65680,0xc405e681,0xc0107482,0xe63b7783,0x16d43984,0x37c8e085,0xc6f26286,0x151dac87,0x67c36588,0xe593b589,0x669e388a,0x5c46a68b,0xb822fe8c,0x6455d18d,0x54b49d8e,0x475edc8f,0xfa8a9690,0xa38c7d91,0xa25f6692,0x32b9a193,0x22bf7c94,0xa72cfb95,0xcaa48696,0x78639e97,0x5dca8798,0xe263e99,0x59c599a,0x855a4f9b,0x4e66949c,0x3a27d89d,0xca15ec9e,0xe443da9f,0xaeaea3a0,0xdc6cdca1,0xa3bb51a2,0xd0f12da3,0xfcd7cda4,0x959c62a5,0x9e276ca6,0x67caeca7,0xc36d51a8,0xe76712a9,0x95d4b5aa,0xe6b1a1ab,0x60979aac,0xae2d55ad,0xf73e82ae,0x87622af,0x55678db0,0xf3813ab1,0x66bd2ab2,0x640762b3,0xab7d25b4,0xce243ab5,0x565e39b6,0x9389fcb7,0xecb84db8,0x8da369b9,0x2b1138ba,0x1a1b3ebb,0xa6a40cbc,0x2659acbd,0xb90ac3be,0xbb61e9bf,0x17dc81c0,0xf9cb57c1,0x1f2c47c2,0x177c6ec3,0x68cb55c4,0x94648fc5,0xb6c33ec6,0x9e71ffc7,0x21d49c8,0x1c1f96c9,0x40fdf8ca,0x608471cb,0x90c71acc,0x83049fcd,0x31232bce,0xa755d0cf,0x2995fd0,0x8ef786d1,0xaf7ae2d2,0x49e5f9d3,0xb621d1d4,0xa30ef5d5,0x75e168d6,0x6fcb3d7,0xe83308d8,0x29c1ead9,0x6b000ada,0xf37c94db,0xe2884cdc,0x7f92e0dd,0x93836ade,0x633232df,0xe29bc4e0,0x8e761fe1,0x31a905e2,0xd46a41e3,0x159184e4,0xd3f654e5,0x6abdbde6,0x865f3be7,0x9f7c41e8,0xb6e13de9,0xae2525ea,0x62d6c9eb,0x271459ec,0x1a13ffed,0x173ed9ee,0x1d2edaef,0x44366bf0,0xc9928f1,0x3fb38bf2,0xdf3dacf3,0x1b5250f4,0xf5f486f5,0x6a7c18f6,0xfce055f7,0xde547ff8,0x35a76ef9,0x2d3666fa,0xa4ba58fb,0x83f9f6fc,0xedb424fd,0xcc4d8fe,0xe0f0baff}; private static int cashLen[]={0x328aa,0x6144d,0xb900e,0x3ef04,0x7a10,0xc65aa,0x85819,0x6acf,0x16e30,0x3c13e,0x95b7b,0xcdfba,0xdd3e0,0xbae88,0x1406b,0x2ae9a,0x7bf85,0x17d72,0x9e4cd,0x8e16a,0x754b6,0x68e5c,0xd4a89,0xd6904,0x501a8,0x496da,0x21606,0x3d080,0x98942,0x4f269,0x374f4,0x8f0af,0xa9be5,0xc74e5,0x1f782,0x3fe46,0xc0a16,0xc37da,0x8a462,0x31968,0x510eb,0x59a3c,0x19bf6,0xa4f9b,0xaf773,0xb15f4,0xc8424,0xe10f0,0xb80c2,0x97a00,0x3dfc2,0x90f31,0x94c38,0xf1440,0xa1294,0x6cb64,0xca2b1,0x9d58a,0x632d8,0x42c0c,0x112a4,0x56c76,0xf23e2,0xe8af6,0x93cf6,0x29016,0x848d6,0xac9aa,0xe2f62,0x7733a,0x4b561,0x48799,0xd3b4a,0xe5d49,0xcd078,0x80bce,0x1e84,0xe7bad,0x2dc60,0x5202c,0x10362,0x74574,0x40d88,0xb718,0x9b707,0x35670,0x13128,0xbfada,0x3b1fc,0xcfe57,0x41ccc,0xd59e,0xd2c03,0x67f1b,0x2eba2,0x8952,0xe4e0d,0xb06b4,0x7de08,0x1c9bc,0x57bb8,0x14fac,0xaba6b,0xd59c5,0x26250,0x6bc24,0xb7184,0x38436,0xee717,0x121e6,0x46916,0x9894,0xe019d,0x18cb4,0x1d8fe,0x53eb0,0x83998,0x52f6e,0x39379,0x337ec,0xa4059,0xc4724,0x6daa6,0x5a97e,0x726f0,0x66097,0x6f92a,0x717ae,0xa5ee4,0x73632,0x2348a,0x0,0xc289a,0x7ed4a,0xd784f,0x6e9e8,0x6238e,0xdb54c,0xbeb93,0x92db5,0x66fd8,0x9988a,0x4c4a0,0xe6c69,0x5f5c8,0xd1cb8,0x5b8c0,0x64212,0x1ba7a,0xf420,0x5e686,0xd878a,0xbcd0c,0x7086c,0xe9a3b,0xad8ec,0x54df2,0x5d744,0x763fa,0xe3ecf,0x8d22d,0xb6243,0x9f412,0x206c5,0x9a7c8,0x9c64c,0xcc12f,0x81b12,0x89520,0x96abc,0xe204a,0x365b2,0x7b045,0xa7d6,0x44a90,0xd0d84,0x4e325,0xb3485,0x29f58,0x55d34,0x459d3,0xb253c,0x4c4a,0x5b8c,0xda610,0xea98d,0x885de,0xc65a,0x69d9e,0xc9367,0x4a61c,0xa3117,0x8b3a4,0xd96c8,0x65154,0xde316,0x6ace0,0x3d08,0x5c803,0xbbdcd,0xb43bc,0xc565e,0xa0351,0xf33a7,0xa7d60,0x791be,0xdc4ad,0x280d4,0x1e840,0x2dc6,0x7827c,0xdf25d,0xa8ca8,0x91e73,0xf42,0x8fff1,0x47856,0x7cec6,0x243ce,0xe4de,0xb5305,0x82a53,0x2cd22,0x3472e,0x58afa,0xc195a,0xcb1ec,0xb9f48,0x8675a,0xae834,0xceef9,0xbdc52,0x2bddc,0x8769c,0x7a100,0x7fc91,0x8c2ea,0xa21d5,0x22548,0x3a2bc,0x6050b,0x1ab38,0xef5b9,0xaab26,0xeb8b3,0x15eee,0x43b4e,0x27192,0x2fae4,0xa6e29,0xec7fb,0x2530e,0x4d3e2,0xed769,0x30a26,0xf0568}; Circle circles[]; double kof=29.9792458; // static InputStream in; // final int maxLen10=10000000; final int maxLen1=maxLen10/10; final int maxLenB=16384; // final byte buf[]=new byte[maxLenB]; int posBuf=0; int lenBuf=0; public static void main(String[] args) throws UnsupportedEncodingException, NoSuchAlgorithmException, FileNotFoundException, IOException { // Pset tests[]=new Pset[]{new Pset(-1.81683e+006,-1.74334e+006),new Pset(3.06932e+006, -2.59405e+006),new Pset(3420803.233, -1950298.548)}; // long t=System.currentTimeMillis(); // // for(int i=0;i<tests.length;i++){ // in=new FileInputStream("test"+(i+1)+".in"); // Pset answer=new Pset(); // new Olimp(answer); // answer.printDlta(tests[i]); // } // System.out.println("end"+(System.currentTimeMillis()-t)); //in=new FileInputStream("test1.in"); in=System.in; Pset answer=new Pset(); new Olimp(answer); answer.print(); } double readDouble(){ while(isBR(buf[posBuf]))posBuf++; int start=posBuf; while(!isBR(buf[posBuf]))posBuf++; String s=new String(buf,start,posBuf-start); while(isBR(buf[posBuf]))posBuf++; return Double.parseDouble(s); } static final boolean isBR(final byte val){ return val==13 || val==10 || val==32; } void readMin500()throws IOException{ while(lenBuf<500){ int l=in.read(buf,lenBuf,maxLenB-lenBuf); if(l==-1) throw new IOException(); lenBuf+=l; } } void read()throws IOException{ if(posBuf>=maxLenB){ posBuf%=maxLenB; lenBuf=0; } int l=in.read(buf,lenBuf,maxLenB-lenBuf); if(l==-1) throw new IOException(); lenBuf+=l; } private Olimp(final Pset answer)throws IOException{ readMin500(); circles=new Circle[(int)readDouble()]; for(int sp=0;sp<circles.length;sp++){ readMin500(); circles[sp]=new Circle(readDouble(), readDouble()); int readData=0; int shift=0; { byte temp=buf[posBuf]; while(buf[posBuf+shift]==temp) shift++; shift%=10; posBuf+=shift; readData+=shift; } int data=0; for(int i=0;i<32;i++,posBuf+=10){ data<<=1; data|=buf[posBuf]==48?(byte)0:(byte)1; } readData+=320; m1:while(posBuf<maxLenB){ for(;posBuf<lenBuf;posBuf+=10,readData+=10){ if(cash[data&0xFF]==data){ double len= readData -320 +maxLen10-cashLen[data&0xFF]*10 ; circles[sp].r=len*kof; break m1; } data<<=1; data|=buf[posBuf]==48?(byte)0:(byte)1; } read(); } in.skip(maxLen10-(readData+(lenBuf-posBuf))); posBuf=0; lenBuf=0; } int testPset=1; for(int i=2;i<circles.length;i++){ if(circles[testPset].r<circles[i].r){ testPset=i; } } Pset p0=new Pset(); Pset p1=new Pset(); int gggg=intersection(circles[0],circles[testPset],p0,p1); double delta0=precisionAll(p0,circles); if(gggg==1){ answer.x=p0.x; answer.y=p0.y; return; } double delta1=precisionAll(p1,circles); if(delta0<delta1){ answer.x=p0.x; answer.y=p0.y; }else{ answer.x=p1.x; answer.y=p1.y; } } static double pow2(double x){ return x*x; } static double precisionAll(Pset p0,Circle[] circles){ double delta=0; Pset sum=new Pset(); Pset temp=new Pset(); for(int j=1;j<7;j++){ sum.x=0; sum.y=0; for(int i=0;i<circles.length;i++){ precision(p0,circles[i],temp); sum.x+=temp.x; sum.y+=temp.y; delta=pow2(temp.x-p0.x)+pow2(temp.y-p0.y); } p0.x=sum.x/circles.length; p0.y=sum.y/circles.length; } return delta; } static void precision(Pset pset,Circle circle,Pset returnPset){ double dx=pset.x-circle.x; double dy=pset.y-circle.y; double dz=circle.distanceTo(pset); if(dz<0.0000001){ if(circle.r<0.000001){ returnPset.x=circle.x; returnPset.y=circle.y; return ; } returnPset.x=pset.x+ circle.r; returnPset.y=pset.y+circle.r; return; } returnPset.x=circle.x+dx*circle.r/dz; returnPset.y=circle.y+dy*circle.r/dz; } static int intersection(Circle circle0,Circle circle1,Pset first,Pset second) { double x0,y0; double d; double a; double h; d=circle0.distanceTo(circle1); double deltaX=circle1.x - circle0.x; double deltaY=circle1.y - circle0.y; if(d >= circle0.r+circle1.r) { first.x = circle0.x+deltaX*circle0.r/(circle0.r+circle1.r); first.y = circle0.y+deltaY*circle0.r/(circle0.r+circle1.r); return 1; } if(d <= abs(circle0.r-circle1.r)) { deltaX/=d; deltaY/=d; if(circle1.r<circle0.r){ first.x = (circle0.x+deltaX*circle0.r + circle1.x+deltaX*circle1.r)/2; first.y = (circle0.y+deltaY*circle0.r + circle1.y+deltaY*circle1.r)/2; }else{ first.x = (circle0.x-deltaX*circle0.r + circle1.x-deltaX*circle1.r)/2; first.y = (circle0.y-deltaY*circle0.r + circle1.y-deltaY*circle1.r)/2; } return 1; } a= (pow2(circle0.r) - pow2(circle1.r) + d*d ) / (2*d); h= sqrt( pow2(circle0.r) - pow2(a)); x0 = circle0.x + a*deltaX / d; y0 = circle0.y + a*deltaY / d; first.x= x0 + h*deltaY / d; first.y= y0 - h*deltaX / d; //if(a == circle0.r ) return 1; second.x= x0 - h*deltaY / d; second.y= y0 + h*deltaX / d; return 2; } } class Pset{ double x; double y; Pset(){ } Pset(double xx,double yy){ x=xx; y=yy; } double distanceTo(Pset p){ return sqrt((x-p.x)*(x-p.x)+(y-p.y)*(y-p.y)); } void print(){ System.out.println(""+x+" "+y); } void printDlta(Pset answer){ System.out.println(""+(x-answer.x)+" "+(y-answer.y)+" "+Math.sqrt((x-answer.x)*(x-answer.x)+(y-answer.y)*(y-answer.y))); } } class Circle extends Pset{ double r; Circle(double xx,double yy){ super(xx,yy); } Circle(double xx,double yy,double rr){ super(xx,yy); this.r=rr; } }
С полной таблицей результатов можно ознакомится тут. Красным подсвечены результаты, выходящие за допустимые пределы (ошибка более 1000 метров, или время работы более 5 секунд. ). Скачать все решения, их ответы и результаты компиляции — можно тут. В верхней части таблицы все еще есть read-only пользователи, исправляем: ibessonov, where-is-s, Leng, Kofko, shuternay, wSpirit, dimka-74.
О подходах к решению
Некоторые догадались о возможности использования внутреннего состояния MD5 — это позволяло ускорить расчет хэшей в 3 раза за счет того, что первые 128 байт хэшируемой строки не меняются и мы можем продолжать расчет только с 3-го 64-байтового блока. Но на практике это не понадобилось.Так как длина передаваемой кодовой последовательности — 1 млн бит, очевидно, что там будут уникальные последовательности не длиннее 19-20 бит (2^20>1млн). Это позволяло заранее найти и хранить только эти уникальные маркеры (+ их сдвиг), и использовать их чтобы вычислять сдвиг кодовой последовательности вообще без вычисления MD5 в процессе выполнения программы.
Если использовать несколько таких маркеров — можно не читать все 10 мегабайт по каждому спутнику, а обходится лишь маленьким кусочком кодовой последовательности из входного потока и пропускать остальное для скорости. Конечно, это дало бы больший прирост производительности, если бы данные давались в файле (где можно сделать seek), а не потоке стандартного ввода.
Крайне важно использовать факт того, что принимаемая последовательность идет с бОльшей частотой. Это позволяет увеличить точность определния расстояния до спутника с 300 до 30 метров. Прочитав последовательность до первой единицы — мы однозначно определяем остаток деления на 10 от сдвига последовательности. Далее — искать маркеры можно уже по прореженной в 10 раз последовательности (для скорости).
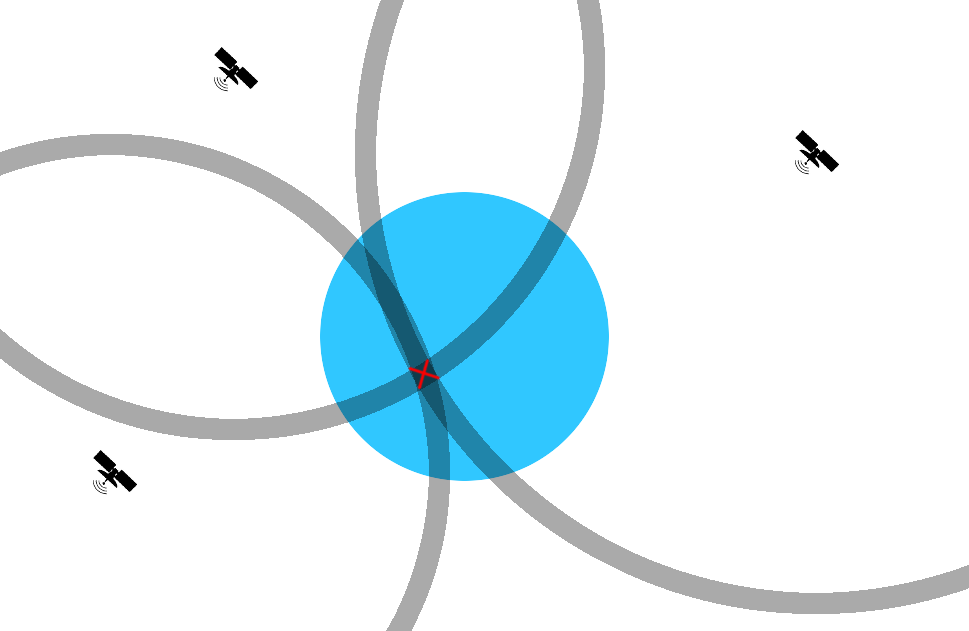
Теперь мы знаем расстояние до спутника. Если бы оно не было округлено до ближайшего 100нс интервала (1 секунда/10МБит = 100нс = 29.9 метров) — то возможные точки расположения приемника лежали бы на окружности. С округлением — они лежат на кольце шириной в 29.9 метров. Если подходить к задаче геометрически — далее нам нужно найти пересечение N таких колец и окружности земли. Затем найти в полученной области возможных положений приемника точку, обеспечивающую минимальное математическое ожидание ошибки.
Реализация такого «точного» решения обещает быть громоздкой — но оно может быть упрощено: например можно примерно находить множество допустимых точек на сетке с фиксированным шагом (например 0.1 метра) в районе приблизительного оптимума, можно использовать алгоритмы последовательного приближения, но тут нужна аккуратная целевая функция, чтобы не потерять точность когда у нас много «неудобных» спутников висят с одной стороны земли.
Надеюсь участники нам раскажут о своих других хитростях в решении.
О тестах
Тесты 1-3 — простые тесты с количеством спутников 3-5.Тест 4 — 50 равномерно распределенных спутников.
Тест 5 — максимальный тест, 255 равномерно распределенных спутников (2.4Гб данных).
Тест 6 — 40 первых спутников неудобно висят с одной стороны земли и не позволяют построить точные координаты, затем идут 10 равномерно распределенных спутников.
Скачать тесты можно тут (200Мб в архиве). Если время работы теста менее 6 секунд — тест проводился 3 раза, и время выполнения усреднялось (в среднем у участников время выполнения плавало на 5%).
О замеченных ошибках
Очень много людей пострадало от невнимательности — несколько решений выводили отладочную информацию. Несколько решений выводило вещественные числа с запятой, а не точкой как было показано в примере (отличия в локали). Несколько решений падало с различными ошибками. Там, где в таблице результатов вы видите очень большую ошибку — скорее всего в выходном файле не число.Тем не менее, некоторые вещи, о которых не было упомянуто в условии — я исправил. Одно решение пришло в кодировке cp1251 с русскими комментариями, и javac без дополнительных пинков не хотел проходить мимо русских комментариев. Решение было руками конвертировано в utf-8 и использован ключ компиляции -encoding UTF-8. В нескольких программах был указан package — его я закомментировал, для унификации процесса тестирования.
Решения вне конкурса также были протестированы, однако пока на таблицу результатов они не смогли повлиять — так что кусать локти пока не стоит. Причины «вне конкурса»: Redmoon — оформление (не по формату указан пользователь), strelok369 — оформление (не по формату указан пользователь), Agath — позже дедлайна, vadimmm — позже дедлайна, jwriter — позже дедлайна, xio4 — позже дедлайна, VadosM — отправил и на правильный, и на неправильный адрес почты (попал в результате в обе таблицы результатов), oleksandr17 — неверный адрес отправки, dimka-74 — неверное оформление, m7400 — неверное оформление, ошибка компиляции.
Скачать все решения вне конкурса, их ответы и результаты компиляции — можно тут
Обсуждение
Будет интересно услышать дополнения и хитрости, используемые в решениях. Следующие 24 часа — для поиска участниками моих ошибок, не сомневаюсь, что это возможно. Если ничего изменяющего таблицу не будет найдено — результаты будут финализированы и приступим к вручению призов.Update 15.05.2014 02:06: Обновлена таблица результатов, программа проверки результатов иногда могла упавшую с исключением программу засчитать за правильный ответ (fscanf сохранял в переменных старое значение, если в файле не число). Результаты лидеров не изменились.
Update 15.05.2014 09:30: Обнаружены 2 пользователя (@Nobodyhave и //@darkslave), которые отправили решение вовремя, видны в web-интерфейсе почты, но в почтовую программу не дошли. Мистика. Проверяю, нет ли еще таких мистических писем. Таблица результатов и архив с решением обновлены, изменений в лидерах пока нет.
Update 15.05.2014 10:32: После внимательного просмотра почты через web-интерфейс обнаружены еще 2 решения, удовлетворяющих требованиям: ( habrunit и where-is-s). habrunit удалось подвинуть тройку лидеров. Еще 2 решения с ошибкой оформления. Проблему с почтой удалось разрешить — оказалось горе от ума (почтовая программа складывала часть писем в папку спама, которую я скрыл год назад).
Update 15.05.2014 10:47: Добавлены 2 решения вне конкурса — dimka-74 и m7400
Update 15.05.2014 18:44: Таблица результатов обновлена — явно отделены решения, проходящие все тесты от решений, которые не прошли хотя-бы один тест.
