
В Python имеется так много встроенных исключений, что программисты редко нуждаются в создании и использовании пользовательских исключений. Или это не так?
В Python имеется так много встроенных исключений, что программисты редко нуждаются в создании и использовании пользовательских исключений. Или это не так?

Подошёл к концу 25-летний период, когда в компании Netflix придерживались подхода, в соответствии с которым все инженеры-программисты находились на одном карьерном уровне. Что можно сказать о новой системе карьерных уровней Netflix? Как их воспринимают сотрудники компании?
В апреле сего года я, в The Scoop #9, рассказал о том, как Netflix собирается ввести у себя систему карьерных уровней для инженеров-программистов:
Netflix рассматривает вопрос о введении следующей системы карьерных уровней:
— Engineer 1 (Инженер-программист 1)
— Engineer 2 (Инженер-программист 2)
— Senior (Старший инженер-программист)
— Staff (Ведущий инженер-программист)
— Principal (Главный инженер-программист)
Детали этой системы всё ещё прорабатываются, предложение распространено среди инженерного персонала. Это предложение, что понятно, привело к появлению множества вопросов. Особенно — относительно того, получат ли существующие инженеры должности ведущих или главных инженеров-программистов. Исходя из первоначального предложения, складывалось такое впечатление, что все останутся старшими инженерами-программистами, а переход на следующие уровни возможен при продвижении по службе.
Почему компания вводит систему карьерных уровней, если она весьма неплохо обходилась без них последние 25 лет? За это время количество программистов в ней дошло до 2000 человек, все они были старшими инженерами-программистами. Предполагаю, что всё дело в проблемах, которые имелись в существующей системе.
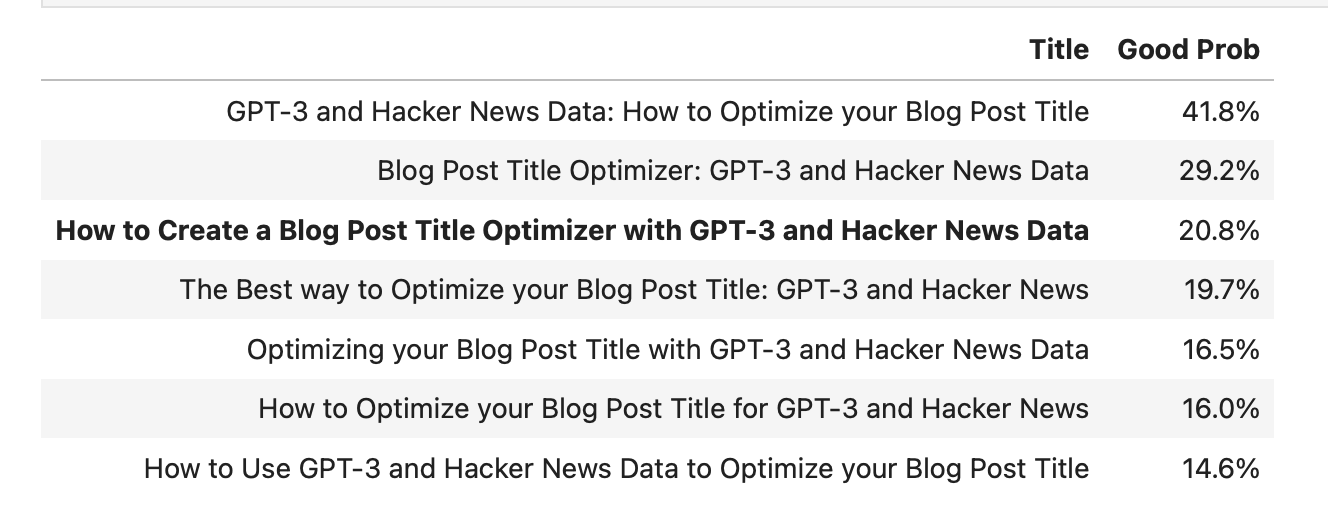
Система, основанная на GPT-3, сообщает о том, что заголовок для этой статьи (How to Create a Blog Post Title Optimizer with GPT-3 and Hacker News Data) очень плох.
Я, с объективной точки зрения, очень плохо умею придумывать заголовки для своих статей. И это — проблема, так как в наши дни всем известно, что хороший заголовок может оказаться единственным фактором, влияющим на то, «завирусится» ли статья, или останется никем не замеченной. Особенно это справедливо для таких сфер, как наука о данных и машинное обучение. Пишу я обычно именно об этом.
Почему бы мне не воспользоваться приёмами из вышеупомянутых областей знаний для создания оптимизированных заголовков для блог-постов?

Класс set (множество) — это одна из ключевых структур данных в Python. Она представляет собой неупорядоченную коллекцию уникальных элементов. Класс set, в некоторой степени, соответствует математическому множеству. Многие широко используемые математические операции, применимые к множествам, существуют и в Python. Часто вычисления, производимые над множествами, оказываются гораздо быстрее, чем альтернативные операции со списками. В результате, для того чтобы писать эффективный код, Python-программисту просто необходимо уметь пользоваться множествами. В этой статье я расскажу об особенностях работы с классом set в Python.

В Кремниевой долине есть очень особенный ресторан фаст-фуда, который всегда открыт. Там имеется один столик, за ним может разместиться лишь один посетитель, которому дадут совершенно фантастический гамбургер. Когда туда приходишь — ждёшь до тех пор, пока не настанет твоя очередь. Потом хозяин ресторана подведёт тебя к столику, и, это же Америка, тебе зададут, кажется, бесконечное количество вопросов о том, как приготовить и как подать твой гамбургер.
Сегодня, правда, мы не собираемся говорить о кулинарных изысках. Мы говорим о системе очередей, которую используют рестораны. Если вам повезло и вы прибыли в ресторан тогда, когда столик пуст, и когда никого в очереди нет, вы можете прямо сразу за него сеть. В противном случае хозяин даст вам специальный пейджер (из бескрайней кучи таких пейджеров!) и вы можете бродить вокруг ресторана до тех пор, пока этот пейджер не подаст сигнал. Дело хозяина ресторана — обеспечить, чтобы посетители попадали бы за столик в порядке их прибытия. Когда настанет ваша очередь, хозяин отправит сигнал на ваш пейджер, а вы вернётесь в ресторан, где сможете усесться за столик.
Если вы передумали — можете вернуть пейджер хозяину, а он, ни слова не сказав, спокойно его заберёт. Если ваш пейджер уже сработал, то хозяин, если на вас очередь не оканчивается, вызовет следующего посетителя. Посетители этого ресторана всегда вежливы, они, получив пейджер, не уходят украдкой, никого не предупредив. А хозяин всегда честен и не усадит за столик кого-то, кто стоит в очереди за вами, даже если вам, чтобы вернуться в ресторан после срабатывания пейджера, нужно некоторое время.

Базы данных (БД) существуют с первых дней программирования, а появились они ещё раньше. Это — неотъемлемые части любых приложений. Хорошо спроектированная БД — это один из важнейших компонентов, влияющих на производительность программных проектов. Из-за этого множество архитекторов программных решений исследовали массу подходов к управлению данными, пытаясь выяснить то, какие из этих подходов работоспособны в определённых сценариях, а какие — нет. Выбор подходящей архитектуры БД обычно сводится к выбору между SQL и NoSQL, между реляционными и нереляционными базами данных. А иногда в одном проекте используют и то, и другое.
В этой статье мы сделаем краткий обзор баз данных, поговорим об их истории, постараемся разобраться с тем, что собой представляют базы данных SQL и NoSQL, выясним ключевые различия между ними.

Python стал самым популярным языком во многих быстроразвивающихся областях, таких, как глубокое обучение и различные направления анализа и обработки данных. Но при этом за удобство работы с Python-кодом, за высокий уровень его читабельности, приходится платить производительностью. Конечно, все мы время от времени жалуемся на скорость работы программ, и Python, безусловно, не стоит винить во всех грехах. Несмотря на это, справедливым будет заявление о том, что природа Python, интерпретируемого языка, не способствует высокой производительности кода, особенно когда речь идёт о «тяжёлых» вычислениях (один из признаков таких вычислений — наличие в программе нескольких вложенных циклов).
Если вы когда-либо попадали в одну из следующих ситуация — тогда эта статья, определённо, написана для вас.

В Python списковые включения (и генераторы списков) — замечательные механизмы, способные серьёзно упрощать программный код. Правда, чаще всего их используют в форме, предусматривающей наличие единственного цикла for и, возможно, одного условия if. И это всё. Но если попытаться немного вникнуть в эту тему, то окажется, что у списковых включений Python имеется гораздо больше возможностей, чем можно подумать, возможностей, разобравшись с которыми, можно, по меньшей мере, кое-чему научиться.

Недавно я сделал опрометчивый твит, в котором намекнул на то, что у меня имеется глубоко продуманное мнение по одному важному вопросу. Я написал, что пакет pytest-subtests достоин того, чтобы им пользовалось бы больше программистов. Я даже дошёл до того, что, говоря о подтестах (subtests), сказал, что они были единственным, что мне по-настоящему нравилось в unittest до появления их поддержки в pytest. И, как на грех, Брайан Оккен предложил мне поучаствовать в подкасте Test and Code, чтобы подробнее обсудить подтесты. Я могу лишь догадываться о том, что он это сделал, дабы преподнести мне урок, показать мне, что я не должен, накачавшись продуктами Splenda и травяным чаем, выдавать скороспелые мнения о тестировании кода.Но, тем не менее, когда Брайан взглянет на меня со своей хитрой улыбкой и скажет: «Итак, ты готов поговорить о подтестах?», я планировал ответить: «Да, я готов — сделал обширные заметки и набрал справочных материалов». А когда мы вместе будем стоять на сцене, получая Дневную премию «Эмми» за лучший подкаст о тестировании, я шепну ему: «Я раскрыл твою хитрость, и хотя я тебя обыграл, ты реально показал мне — что такое скромность», а по его щеке скатится одинокая слеза.
Или, что скорее всего так и есть, ему просто хотелось пригласить кого-то, с кем можно поговорить об этом конкретном аспекте Python-тестирования, а я оказался одним из тех немногих, встретившихся ему, кто высказывал по этому поводу своё мнение. В любом случае, этот пост будет играть роль моих заметок по механизму подтестов из unittest, который появился в Python 3.4. Здесь же пойдёт речь о сильных и слабых сторонах подтестов, о сценариях их использования. Этот материал можно считать дополнением к подкасту Test and Code Episode 111.

Этот материал представляет собой глубокое исследование всего, что связано с Redis. В частности — речь пойдёт о различных способах организации хранилищ Redis, о постоянном хранении данных, о форках процессов.

Сталкивались ли вы с трудностями при отладке Python-кода? Если это так — то изучение того, как наладить логирование (журналирование, logging) в Python, способно помочь вам упростить задачи, решаемые при отладке.
Если вы — новичок, то вы, наверняка, привыкли пользоваться командой print(), выводя с её помощью определённые значения в ходе работы программы, проверяя, работает ли код так, как от него ожидается. Использование print() вполне может оправдать себя при отладке маленьких Python-программ. Но, когда вы перейдёте к более крупным и сложным проектам, вам понадобится постоянный журнал, содержащий больше информации о поведении вашего кода, помогающий вам планомерно отлаживать и отслеживать ошибки.
Из этого учебного руководства вы узнаете о том, как настроить логирование в Python, используя встроенный модуль logging. Вы изучите основы логирования, особенности вывода в журналы значений переменных и исключений, разберётесь с настройкой собственных логгеров, с форматировщиками вывода и со многим другим.
Вы, кроме того, узнаете о том, как Sentry Python SDK способен помочь вам в мониторинге приложений и в упрощении рабочих процессов, связанных с отладкой кода. Платформа Sentry обладает нативной интеграцией со встроенным Python-модулем logging, и, кроме того, предоставляет подробную информацию об ошибках приложения и о проблемах с производительностью, которые в нём возникают.

Pandas — это мощная библиотека для анализа данных, API которой обладает широкими функциональными возможностями. Этот API позволяет решить любую задачу, связанную с обработкой данных, несколькими способами. Некоторые из подходов к решению задач лучше других. Часто бывает так, что пользователи pandas узнают о подходах, не отличающихся особой эффективностью, привыкают к ним и постоянно их применяют. Этот материал посвящён разбору четырёх анти-паттернов pandas и рассказу о приёмах работы, которые стоит использовать вместо них.
Автор черпал вдохновение из многих источников, ссылки на которые даны в статье. В частности — из замечательной книги Effective Pandas.

Вот вам задача: надо проверить, входит ли число 200 миллионов в диапазон от 0 до 1 миллиарда. Знаю, что на Python её решение выглядит до крайности примитивно — достаточно воспользоваться функцией any и списковым включением:

В Python, с каждым релизом, добавляют новые модули, появляются новые и улучшенные способы решения различных задач. Все мы привыкли пользоваться старыми добрыми Python-библиотеками, привыкли к определённым способам работы. Но пришло время обновиться, время воспользоваться новыми и улучшенными модулями и их возможностями.

Мне всегда нравилась визуальная эстетика дизеринга (dithering, псевдотонирование, псевдосмешение цветов), но я не знал о том, как он применяется. Поэтому я провёл кое-какие изыскания. Эта статья может содержать отголоски ностальгии, но в ней не будет никаких следов Лены.

Каждая минута, потраченная на организацию своей деятельности, экономит вам целый час.
Бенджамин Франклин
Python отличается от таких языков программирования, как C# или Java, заставляющих программиста давать классам имена, соответствующие именам файлов, в которых находится код этих классов.
Python — это самый гибкий язык программирования из тех, с которыми мне приходилось сталкиваться. А когда имеешь дело с чем-то «слишком гибким» — возрастает вероятность принятия неправильных решений.

Библиотека Pandas — это весьма эффективный инструмент для обработки данных, представляющих собой временные ряды. На самом деле, эта библиотека была создана Уэсом МакКинни для работы с финансовыми данными, которые состоят, главным образом, из временных рядов.
При работе с временными рядами много сил уходит на выполнение различных операций с датой и временем. Этот материал посвящён ответам на четыре распространённых вопроса из данной сферы.
Возможно, вы уже сталкивались с этими вопросами. Ответить на все из них, кроме последнего, можно сравнительно просто. А вот ответ на последний, довольно-таки хитрый вопрос, представляет собой последовательность из нескольких действий.
Начнём с создания учебного датафрейма (объекта DataFrame), с которым будем экспериментировать:

Любому Python-проекту может пойти на пользу надёжный и стабильный конвейер непрерывной интеграции (Continuous Integration, CI). В рамках таких конвейеров выполняется сборка приложений, запуск тестов, проверка кода линтерами, контроль качества программ, анализ уязвимости приложений. Правда, построение CI-конвейеров занимает много времени, требует выполнения действий, которые, сами по себе, никакой пользы не приносят. Этот материал написан для тех Python-программистов, которым нужен полнофункциональный, настраиваемый CI-конвейер, основанный на GitHub Actions. Этот конвейер оснащён всеми мыслимыми инструментами, подключён ко всем необходимым сервисам, а подготовить его к работе можно всего за несколько минут.

Форматированные строковые литералы, которые ещё называют f-строками (f-strings), появились довольно давно, в Python 3.6. Поэтому все знают о том, что это такое, и о том, как ими пользоваться. Правда, f-строки обладают кое-какими полезными возможностями, некоторыми особенностями, о которых кто-нибудь может и не знать. Разберёмся с некоторыми интересными возможностями f-строк, которые могут оказаться очень кстати в повседневной работе Python-программиста.

В предыдущем материале из этой серии мы рассказали о сетях Deep Q (Deep Q Network, DQN) и написали алгоритм их обучения на псевдокоде. Хотя такие сети, в принципе, работоспособны, практическая реализация алгоритмов обучения с подкреплением (Reinforcement Learning, RL), выполняемая без понимания их ограничений, может вести к нестабильности создаваемых систем и к плохим результатам обучения. В этом материале мы обсудим два важных ограничения, две проблемы, способных привести к нестабильности Q-обучения. Мы поговорим и о том, как, на практике, решать эти проблемы. Вспомните о том, что уравнение Беллмана связывает, с помощью рекурсии, Q-функции для текущего и следующего временных шагов.