Комментарии 405
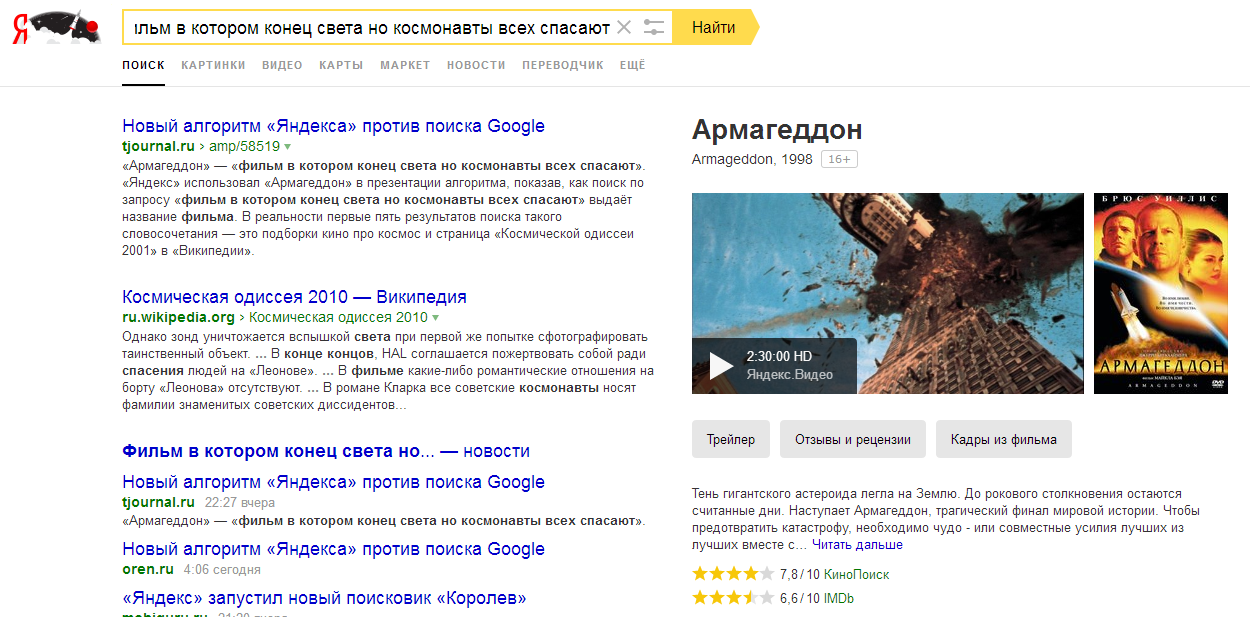
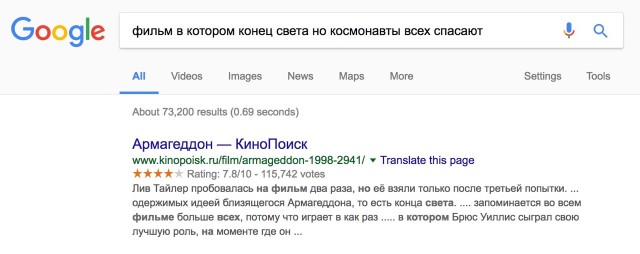
… именно «Палех» лежит в основе «Королева».
Потому что было проще добавить правило (=костыль), чем пропечатать эти точки в газетах. Но сейчас такой проблемы уже нет.
Так пора рефакторить :)
Соверш(е|ё)нный, передохн(е|ё)м, узна(е|ё)м, приближ(е|ё)нных, вс(е|ё), н(е|ё)бо, бер(е|ё)т, в(е|ё)сел, гн(е|ё)т, л(е|ё)том, м(е|ё)л, н(е|ё)м, ос(е|ё)л, отс(е|ё)к, по(е|ё)м, сл(е|ё)з, съ(е|ё)м, пад(е|ё)жТеперь найдём предложения с этими словами и попытаемся быстро из контекста понять о чём речь. Неудобно разбираться в плохо оформленном исходнике!
Она плохо выглядит, зато хорошо звучит. ©Она прекрасна!
А жители некоторых стран не ленятся печатать диакритические знаки (ê, è, ë, ï, ã). И мы ведь пишем "й", чем "ё" хуже?
Спасибо вам огромное за то что вы делаете!)
Я понимаю что над системой поиска ещё работать и работать (в том плане что процесс разработки и усовершенствования, по сути, бесконечный), но лет 15 назад даже то что уже есть сейчас казалось просто фантастикой.
При этом этот один текст выдается не на сайте, где был опубликован впервые, а на сайтах, которые сделали копи-паст, подчас удалив или изменив ФИО автора.
(полные ссылки отправил личным сообщением)
Только что проверил (в очередной раз).
В запросе два ключевых слова по теме статьи, написанной в 1998г.
Первопубликация, оригинал — w.....article4.htm дата создания — ранее 23.04.1999г
Доказательства: От 14.02.2001г web.archive.org/.....article4.htm
От 23.04.1999г web.archive.org/....article4.htm
Т.е. по идее именно эта страница должна быть на первой позиции.
Но вместо нее на первой же позиции выдачи — копия — w.b..........01
Восьмая позиция еще один копипаст w.m..........54.htm
Вторая страница
седьмая ссылка — копипаст //lo..............ko.html
восьмая — копипаст //mi..................ko
девятая — копипаст //www.m................54.htm (причем повтор с первой страницы выдачи. Т.е. на второй странице выдачи та же ссылка, что и на первой странице)
десятая — копипаст //www.b............01 (аналогично — повтор ссылки с первой страницы)
Четвертая страница
четвертая ссылка — копипаст//e..................5
пятая страница — копипаст //d............1
девятая — копипаст //k..........80.html
десятая — копипаст //m.........9.html
Пятая страница
первая позиция — копипаст //s.................2.html
вторая — копипаст //l.............9.html
шестая — копипаст //y...........5.htm
седьмая — копипаст //d...........93
восьмая — копипаст //www.m...........73
Шестая страница
вторая позиция — копипаст //www.p..........C.pdf
третья — копипаст //b........z.html
пятая — копипаст //www.s...........76.0
шестая — копипаст //k...................73.html
седьмая — копипаст //www.k...............161
Седьмая страница
четвертая позиция — копипаст //e............................oz
И так далее…
А где же оригинал, первоисточник, первопубликация, не менявшая адрес с 1998г?
А его нет.
Просто нет.
Во всяком случае на 30 страницах выдачи. Т.е. среди 300 ссылок выдачи копипасты статьи более 30-ти раз, а оригинала нет.
Я, конечно, пишу хорошие статьи. Плохие не воруют.
Но если это поиск, то…
Если это качество, если это «мы стараемся не ранжировать высоко сайты с вторичным контентом» (Яндекс), если это «найдется все», то…
А ведь как просто — выдать один раз первоисточник. А далее что-то еще, другое.
Вот тогда будет конкуренция качественных текстов, а не конкуренция оптимизаторов.
Тогда вебмастер на самом деле будет думать как сделать «сайт для людей», а не о том, как перехитрить робота.
Сложно Вам? Сложно мне?
Согласен.
Сложно Яндексу?
Нет.
Этот механизм у Яндекса был и расставлял все корректно в 2009 — 2011 году, например.
Т.е. тут даже придумывать ничего не нужно. У Яндекса есть эта технология.
Но ему лень.
Не лень только врать про понижение сайтов со вторичным контентом, ибо понижает он источники, первопубликации, исходники.
В принципе, таким образом, Яндекс обманывает своих пользователей, подсовывая им в выдаче вместо оригинала — копию.
Это как вместо яблока дать муляж. Выглядит может быть и красивее, но не вкусно.
Более половины, а м.б. 80% первоисточников тогда будут корректно определены.
В некоторых случаях, действительно, это сделать сложнее (наверно). Я не знаю как. Но в Яндексе вроде бы много светлых голов? Или нет?
Пример на «Очень часто поиск в Яндексе выдает один и тот же документ размещенный на разных сайтах» выслан.
А Вашей реакции нет.
Кроме того, что Яндекс не нашел первоисточник и ввел пользователей в заблуждение, выдав 30 копий, вместо одной первопубликации… Т.е. просто замусорив выдачу.
Яндекс и с поиском ответов не справился.
Только на моем сайте он не нашел по данной теме:
Еще четыре популярные статьи по этой теме
m...............cle56.htm
m...............pia.htm
m..............ikl371.htm
m.................tikl314.htm
четыре текста для специалистов
m................ikl307.htm
m.....................ioz15.htm
m.......................z14.htm
m.................oz16.htm
Расшифровку двух интервью
m.............tv13.htm
m...........tv7.htm
Расшифровки лекции и семинара
m.................le427.htm
m...................gia.htm
Подборку ответов на вопросы по этой теме
m...................tez.htm
m......................a.htm
Т.е. 14 релевантных запросу документа Яндекс на моем сайте не нашел и в выдачу не поставил.
Зато поставил 30 копий моей статьи m...........cle4.htm, забыв показать в выдаче ее как источник (первопубликацию) и вообще исключив источник из выдачи.
Так же в выдаче нет вот этого уважаемого журнала, где так же размещена статья по теме. lv........0932/
Или книги по той же теме books............lse
О каком качестве выдачи можно говорить в этом случае?
Множество документов не найдено.
Источники не найдены.
Выдача замусорена копиями (и не только моего текста).
И «Найдется все» и «Зеркало Рунета» — это вранье. Введение потребителя в заблуждение. Яндексу было бы полезно изучить закон о «Защите прав потребителя».
И это не единственный закон, который Яндекс нарушает, показывая копии вместо источника и скрывая информацию (все эти страницы Яндексом проиндексированы, но в выдаче их нет, хотя они точно соответствуют тексту запроса).
С тем, что Яндекс вводит в заблуждение пользователей, скрывая информацию мы разобрались.
С тем, что Яндекс — кривое «зеркало Рунета», показывающее копии вместо оригиналов тоже.
Что с этим делать пользователю — понятно. Ну его, такой сервис. Есть другие поисковые системы.
Что делать автору понятно тоже — прекратить писать, потратить время на что-то более полезное. Или вот сюда писать, например… Или Платону… Но Платону — это все равно, что в шредер — в пустоту.
Теперь о том, как Яндекс обманывает вебмастеров.
Есть два сайта. Со сравнимым ТИЦ (сотни, были тысячи), сравнимым (тысячи) количеством страниц с контентом, сравнимым (тысячи в сутки) количеством посетителей.
Оба сайта сделаны для людей, оба на 2012 год имели десятки тысяч посетителей в сутки.
Сайт А — метатеги прописаны верно. Сайт В — криво.
С тегом Н1 то же самое.
На А есть мобильная версия, В не адаптирован.
Ракламы на В больше.
Тег noindex на А расставлен корректно, на В — отсутствует.
Сайт А содержит 99% текстов «первопубликаций», т.е. впервые текст опубликован в Интернете именно на А.
У сайта В с этим похуже. Примерно 30% первопубликаций.
Страницы сайта А загружаются в 10 раз быстрее сайта В.
На сайте А битых ссылок нет (ни внешних, ни внутренних). У сайта В — есть.
У сайта А хорошая карта сайта, у В — плохая.
Сайт А обновляется чаще сайта В.
Сайт А на 5 лет старше сайта В.
По мелочи так же — у сайта А меньше грехов, чем у В.
У А есть он-лайн сервис. У В — нет.
Итого… Сайт А гораздо лучше соответствует всем рекомендациям Яндекса для вебмастеров, чем В.
Сайт В по множеству параметров не соответсвует.
Итого десятки параметров различны. (Здесь намек на танец Платона «алгоритм выдачи учитывает сотню параметров».)
Оба сайта «чисты», не под «фильтрами», по утверждению «Платона» и данным «Вебмастера».
Однако динамика падения посещаемости у обоих сайтов одинаковая. Выпадение страниц из Яндекс выдачи — одинаковое. Математический нонсенс, доказывающий, глюк алгоритма ранжирования и выдачи.
Т.е. Яндекс не учитывает в алгоритме выдачи свои же рекомендации. Т.е. заставляет вебмастеров тратить время впустую. Обманывает их. Заставляет гадать и дергаться, вместо того, чтобы «делать сайты для людей».
А потом пляшет вокруг с бубном «Матрикснета», рассказывая, что у него миллионы данных, а у вебмастера лишь тысячи в лучшем случае.
Но как сказал здесь один комментатор: "… математическое доказательство.
Есть утверждение, «...». Чтобы доказать, что утверждение неверно, достаточно 1 контрпримера!"
Контрпримеров только я уже прислал Вам, Тимур, несколько. Могу еще. Сколько нужно? 10, 100, 1000. У меня 5300 страниц на сайте А. Значит, несколько тысяч я Вам точно могу прислать.
Но как уже сказано выше для того, чтобы понять, что алгоритм работает криво достаточно одного примера. У Вас, Тимур, уже больше одного примера.
Так что в реальности эти пляски имеют цель скрыть ошибки и обман, рассказывая про фильтры для вторичных сайтов и прочее. В действительности же Яндекс, вероятно, внедряет какие-то иные фильтры, которые не имеют отношения к качеству «сайта для людей», а имеют отношения либо к деньгам, либо к благонадежности, либо к личным пристрастиям кого-то из Яндекса.
Иного объяснения нежеланию исправлять многолетнюю ошибку я не вижу.
Хотелось бы услышать от работников Яндекса объяснение — почему не исправлена ошибка, почему копипаст выше оригинала, почему Яндекс обманывает вебмастеров и читателей? В чем его выгода?
Я, правда, пойму, если это разумная стратегия.
Пока же это напоминает стратегию временщиков — «украл, выпил...» — дальше сами знаете, полагаю.
И если я делаю сайты «для людей», то Яндекс делает что-то иное и для чего-то другого.
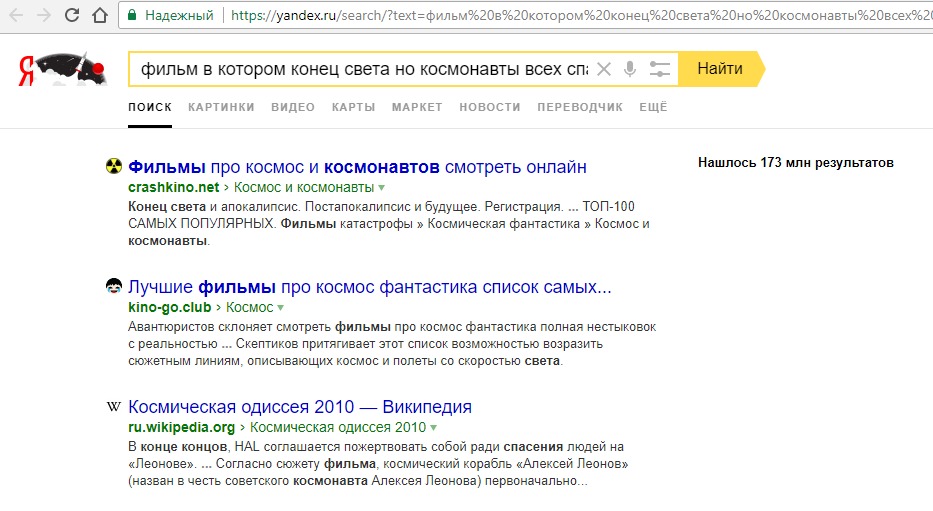
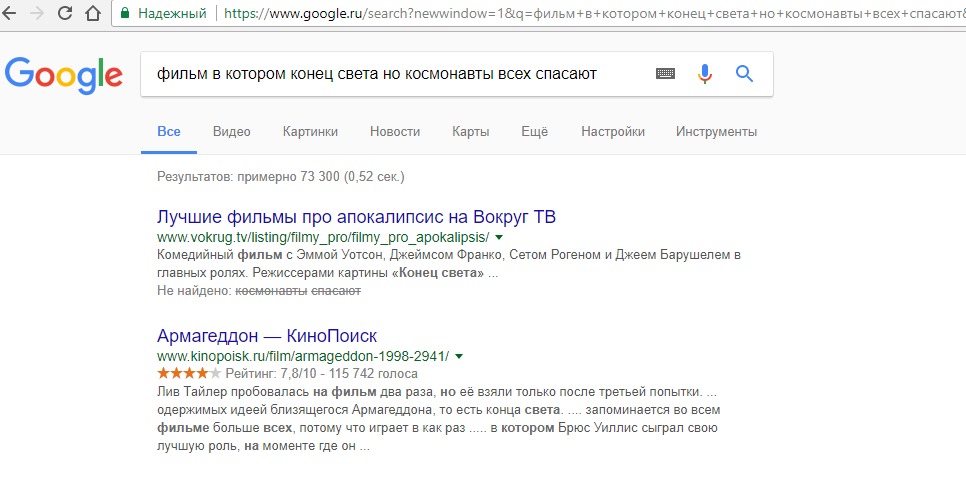

у меня все ОК
Скриншот с лендинга

Результат выдачи

Но самое забавное в другом:
Ну а поисковая выдача Яндекса, с каждым днем становится все хуже и хуже. Уж не знаю, учитывается ли там статистика мои запросов индивидуально или нет (хотя несколько лет назад твердили, что учитывается) — но если я ищу что-то конкретное по определенной теме, то в выдаче 95% результатов на первой странице будут одними и теми же, хотя я прекрасно знаю что ищу и уже конкретно пишу ключевую фразу в кавычках (и с "+", и без...). Но Яндексу видимо пофигу. А что до тех оставшихся 5% — так там может вылезти такое, что вообще не имеет никакого отношения к поиску.
Отдельно заслуживает внимания навязчивая простыня рекламы по любому обновлению любого сервиса Яндекса. Но это уже не относится к теме поста, а в общем и целом.
Вы хотите сказать, что сортируете по популярности вместо количества совпавших слов?
Почему у вас фактор "популярность" перекрывает фактор "число совпавших слов"?
Не зная внутрянку тех механизмов в Яндексе, могу предположить что фактор "популярность" гораздо менее прожорливый (по накладным расходам, как например LA, так и по времени исполнения запроса) чем фактор "число совпавших слов".
Если конечно запрос не повторялся и оно (пара слова/число) не "кэшируется"...
Почему у вас Матрикснет генерирует такие формулы, где фактор "популярность" перекрывает фактор "число совпавших слов"?

PS Если поисковику так легко «отравить» низкочастотный запрос, то понятно откуда берутся [перламутровые] и [почему путин краб]…
То есть Ваш поисковик не готов к резкому всплеску популярности запроса? Например появляется очередной "Pokemon GO" и начинается огромный поток запросов по нему. Какая будет реакция? Естестенна ли данная ситуация?
Чтоб не быть голословным: поиск по имени "Альфи" в Яндексе выдаст кучу ссылок на фильм «Красавчик Алфи, или Чего хотят мужчины». Даже если закавычить это слово. Гугл же дает ссылку на актера Альфи Аллена. Я понимаю, что большинство русскоязычных пользователей Интернета орфографически безграмотны и наверное при запросе «Альфи» на самом деле они искали тот фильм. Но при добавлении кавычек хотелось бы, чтобы Яндекс искал именно заданное слово.
Еще хуже, когда ищешь слово на белорусском языке. Учитывая близость к русскому, начинается настоящая борьба с орфографическим анализатором поисковика.
Посмотрите в справку по поиску хотя б, там же написано всё. Точная форма — это восклицательный, кавычки это порядок слов.
Пару месяцев назад, кстати, был масштабный сбой, минус-слова не работали. Может, BarakAdama поделится инфой, что там тогда случилось? И почему так плохо всё с кавычками?
Яндекс — «Найдётся всё!»
Гугл — «А ничего и не терялось»…
:)
Качество поиска Яндекса ужасное. С каждым годом все хуже и хуже.
О каком «Королеве» можно говорить, если Яндекс банально не может отличить авторский текст от ворованного, первопубликацию от копии, текст специалиста от текста ничего не понимающего в теме компилятора?
Результат — повсеместное поощрение копипаста и воровских сайтов (они в выдаче на первых позициях), фактическая пессимизация оригинального контента (его просто нет в выдаче… совсем). (Что противоречит опубликованным Яндексом принципам. Т.е. Яндекс — врет.)
Результат — нерелевантная выдача, низкое качество поиска. (Это не очевидно только на первый взгляд, но если наплевать на качество и заигрывать с ворами в одном, то и все остальное сыпется.)
Результат — потеря доли поискового трафика по 5% в год.
И до сих пор никто не уволен. Ничего не исправлено. К любым обращениям Яндекс глух.
Смешно.
Еще несколько лет такого «качества» и Яндекс просто исчезнет.
Несколько лет назад я заметил значительное снижение заходов на мой сайт из Яндекса. С Гууглом при этом все было в порядке.
Начал разбираться.
Выяснилось, что вместо моих оригинальных текстов, моих первопубликаций, моих авторских текстов, в выдаче Яндекса сайты, которые своровали мои тексты, страницы копипастеров.
Рекорд был, когда я обнаружил, что мой текст, который я опубликовал на своем сайте впервые в 1998 году, Яндекс выдает на 70-ти сайтах-ворах.
Т.е. в выдаче я насчитал 70 копий моей статьи на чужих сайтах… А своего сайта в выдаче так и не нашел. Совсем.
Начал переписку с Яндексом.
Ответ — «работайте над сайтом», «пишите оригинальные тексты».
Мой ответ — «у меня размещено 5000 оригинальных хороших текстов, только в выдаче они показаны не на моем сайте, а на сайте вора-копипастера».
Ответ Яндекса — «мы не следим за авторскими правами».
И так 4 года.
Но Яндекс врет.
И вот почему.
1. Яндекс утверждает, что он «лишь зеркало Интернета»… ну так не кривое же зеркало. Значит, оригинал, первичная публикация должна быть в выдаче выше копипаста. И раньше, до 2012 года так и было.
2. Яндекс пишет на своей странице «Некачественные сайты»: «Мы стараемся не индексировать или не ранжировать высоко: Сайты, копирующие или переписывающие информацию с других ресурсов и не создающие оригинального контента.»
Яндекс пишет там же: «Сайты, которые содержат неоригинальный, вторичный… контент… Исключение из поиска страниц сайта, понижение в результатах поиска, аннулирование тИЦ»
И еще там же: «Создавайте сайты с оригинальным контентом или сервисом.» (Что я и делал с 1998г. и по сей день делаю).
Однако…
Что же по факту?
По факту десятки ресурсов, разместивших копии моих текстов в выдаче есть. Моего сайта нет.
Яндекс врет или не умеет работать?
Полтора года назад поставил эксперимент. Решил «вылизать» сайт в соответствии со всеми рекомендациями Яндекса.
1. Прописал правильно все метатеги.
2. Правильно проставил H1.
3. Удалил 80% рекламы.
4. Все ссылки, все, что не относится к сути страницы, тексту статьи, включая навигацию, закрыл в noindex.
5. Улучшил юзабилити — фон, границы, внутреннюю перелинковку, шрифт, расположение статьи на странице, добавил картинки, прикрепил интерактивный чат для пользователей для моментальных консультаций.
6. Оптимизировал код страниц, удалил все скрипты, которые было можно, ускорил загрузку страниц в 3-5 раз. (В 10 раз быстрее, чем у копипастеров, которые в выдаче вместо моей первопубликации оригинального текста).
7. Оптимизировал для мобильных устройств (Яндекс и Гуугл сейчас считают сайт оптимизированным. Замечаний в «Вебмастере» нет).
8. Добавил (за несколько лет, разумеется) около 1000 новых текстов, прописав все сначала в «Оригинальных текстах» Яндекса.
9. Исправил 99% входящих «битых» ссылок. (Замечу — никогда никакие СЕО-ссылки не покупал. Все ссылки на мой сайт «естественные».)
10. Убрал 100% внутренних битых ссылок и т.п. ошибок (404 и др.)
11. Исправил орфографию, форматирование и т.п. огрехи там, где были.
12. Сделал карту сайта.
13. Перенес сайт на самый быстрый сервер провайдера.
14. Убрал во фреймы часть рекламы и навигации, чтобы грузилось быстрее, чтобы робот работал со страницей быстрее и точнее индексировал (только сам контент, саму статью).
15. И еще много чего по мелочи. Осталось сделать еще на части сайта перелинковку.
Каков же результат?
Для сайта с 5000 оригинальными статьями, размещенными с 1998 по 2016 год, никогда не менявших URL, с общей посещаемостью в несколько тысяч человек в день от всех этих изменений, затронувших 99% страниц…
Результат… ноль!
А точнее — минус. За этот год в Яндекс-выдаче сайт упал еще вдвое. При этом в Гуугле не изменился.
Гуугл как выдавал мои оригиналы выше копипастов, так и выдает. Яндекс — наоборот. Как пособничал ворам-копипастерам, так и продолжает.
Предположил, что Яндекс просто «потерял» данные о первоисточниках. Может сгорела у него база или что еще…
Написал в поддержку алгоритм, как можно восстановить базу первопубликаций до 2005 примерно года с гарантией (позже чуть сложнее, но тоже можно).
В ответ — молчание.
Просто молчание. Это Яндексу не интересно. Не нужно. Он самый умный.
Отправил еще несколько предложений.
«В ответ тишина...», разумеется.
Несколько лет назад, общаясь с поддержкой, обратил их внимание, что выдача стала не релевантной. Для меня во всяком случае.
Мне пришлось уйти на Гуугл-поиск, потому что Гуугл 1-3-й ссылкой всегда выдавал мне то, что надо, а у Яндекса часто приходилось искать на 2-3-й странице выдачи… и не всегда с положительным результатом.
Написал Яндексу. С примерами. Объяснил, что так ищут многие…
300 писем за 4 года…
Но кто я такой? Ну автор какой-то, веб-мастер. А Яндекс — это же Яндекс — он умнее всех…
Еще в 2012 году я предположил, что доля Яндекса в поисковом сегменте будет падать. И она упала.
Яндекс обвиняет в этом кого угодно, кроме себя.
Но именно в 2012 году Яндекс решил, что первопубликация — это не главное. И начал менять алгоритмы выдачи.
Однако… именно из-за того, что Яндексу стало наплевать на пользователей, а с ним и на вебмастеров и авторов, создающих контент, он уже который год теряет посетителей. Примерно по 5% поискового трафика Рунета в год. А значит теряет доходы от продажи рекламы.
Если Яндексу наплевать на людей, то людям тоже становится не интересно пользоваться Яндексом.
Может, конечно, менеджеры и рапортуют, что продали в этом году на n-миллионов больше… Но в реальности — потеря доли = упущенная прибыль.
Итого. Яндекс обманывает вебмастеров и авторов, декларируя одно, а на деле делая совершенно противоположное.
Яндекс анонсирует свои АГС и пр., но копипастеры прекрасно это обходят и смеются над Яндексом.
Яндекс размахивает дубиной и крушит оригинальные сайты, расчищая дорогу ворам-копипастерам.
И… в результате, по «закону бумеранга» — Яндекс получает снижение доли на рынке, снижение возможных доходов, упускает свою прибыль… и продолжает исправно платить зарплату людям, которые великолепно раздувают щеки, но ничего не делают для улучшения работы поисковика.
Ладно. Яндекс не первый монстр, которого переживут авторские сайты. Такими темпами как сейчас, лет через 5 Яндекс превратится в маленькую конторку или вообще исчезнет с рынка. Подождем.
Придет иной поисковик, который уважает тех, кто создает контент и заберет оставшиеся проценты рынка из рук Яндекса, который вовсе и не пытается эти проценты удержать.
А копипаст — это минут 10, полагаю, если с кофе и перекуром.
Но, конечно, сайт с копипастом гораздо ценнее для Яндекса, чем сайт с оригинальной первопубликацией.
Пишите в личные сообщения, чтобы это не выглядело рекламой и не противоречило правилам habrahabr.
Психология автора и то, что публично озвучивает Яндекс — интересные сайты для людей.
Автор это понимает так — написать интересный текст.
Но его интересный текст Яндекс показывает на сайте-копипастере.
Зачем тогда писать?
Тогда нужно изучать СЕО и соревноваться с оптимизаторами?
Или все-таки писать тексты?
Или размещать статьи с вечными ссылками, ибо за это платят?
Или все-таки делать интересный сайт с хорошими текстами?
Одна из частей моего эксперимента последнего года — написал около сотни хороших текстов (некоторые опубликованы и оплачены офф-лайн журналами).
Тексты по 5000-10000 знаков.
Работы (чистого времени) около 300 часов.
Результат — нулевой.
Или отрицательный, если учесть, что выдача в Яндексе за этот год уменьшилась еще вдвое.
Т.е. смысла создавать хороший контент нет никакого.
Т.е. это нормально для яндекса выдавать в топе сайты на которых он зарабатывает на рекламе или которые у него покупают контекст — они же провели IPO. На совете директоров обычно разбирают показатели прибыльности компании за год, а не сколько ворованных статей в выдаче — у нас нет закона по которому бы поисковик за это наказывался бы.
Вопрос в том, когда, наконец, акционеры поймут, что Яндекс их так банально собирается… подвести.
Теоретически, в идеале, если делать по умному.
И я об этом в техподдержку (и не только) писал много раз на протяжении последних 5-ти (!) лет.
А вот практически оказывается прав Infanty, ибо именно так как он пишет и происходит в реальности. А жаль.
Но это, конечно, в компетенции Яндекса и акционеров.
А пользователи просто выбирают иной магазин (сервис, поисковик).
Но мне было бы приятнее, если бы Яндекс искал так же хорошо, как и Гуугл.
Если качество будет хромать в поиске, то и в остальных сервисах корпорации оно начнет хромать тоже.
Это что в биологии, что в экономике — закон :)
Я как раз «за». Двумя руками.
Проблема в том, что этот Ваш постулат никак не реализуется Яндексом.
(Простите, что Вам приходится «отдуваться» здесь за 2999 (если не ошибаюсь) остальных сотрудников компании :) )
Может я несколько эмоционален…
Возможно меня извинит 5 лет безуспешной переписки с Яндексом.
Ваш ответ «важно, чтобы пользователи искали в Яндексе,… И здесь без качества выдачи уже никак» вселяет некоторую осторожную надежду.
Сейчас очень модно говорить «где пруф?» и требовать ссылку, собственно, на первоисточник.
А с Яндексом его найти невозможно.
И такой человек банально уходит из Яндекс-поиска.
Исходя из лозунга Яндекса «делайте сайты для людей»…
Автор приносит свой текст, свои идеи, сайт-источник, первопубликатор — находит автора, договаривается, публикует.
После этого это текст индексируется и показывается пользователю поисковой системой.
Это все «для людей».
Без автора — нет текста. Без первопубликации нет он-лайн доступа, без поиска нет быстрого обнаружения текста.
А что привносит «для людей» копипастер? Занимает место в выдаче?, Размещает много блоков Яндекс-Директа? Меняет фон или шрифт? Стирает подпись? Не указывает источник? Разбивает текст рекламой? Изменяет слова, искажая текст? Правильно прописывает ключевые слова и прочие технические примочки, которые пользователь не видит?
Что из этого «для людей»?
Чем тексты на сайте копипастере для людей лучше, чем на сайте-источнике?
К тому моменту как помрёт поиск уже будут и уже есть Яндеск.Такси и Яндекс.Маркет
Нонсенс.
Яндекс.Такси и Яндекс.Маркет без собственного поиска — ничто.
Гугль, оставшийся в гордом одиночестве — тут же опустит эти сайты в своем поиске.
Напишите, пожалуйста, в личку ссылку на сайт.
Несколько лет назад я заметил значительное снижение заходов на мой сайт из Яндекса. С Гууглом при этом все было в порядке.
У меня ровно обратная ситуация.
Сайт интернет-магазина, существует уже лет 10, накрутками через копирайтеров не пользуется, статей на сайте нет, только товары, SEO-ссылки не покупает.
Весной 2017 мы приняли решение что больше воооообще нам не нужен Гугль. Там даже на 3-ю страницу хрен пробьешься. Хотя мы и выполняли все рекомендации Гугля, работали над сайтом постоянно.
Основной трафик идет с Яндекса. Стабильно первая страница. Как правило 2-5 место в поисковой выдаче.
А где-то года 2 назад с Гугля шло больше.
А еще лет 5 назад с Гугля и Яндекса шло одинаково.
При том что суммарная посещаемость стабильная. Наблюдается незначительный рост с годами.
Во-вторых, мы в этом не уникальны и даже не мы это придумали. И ниже примеры.



что каждое третье приложение в сети поставить дефолтом поиск от Яндекса.
У Гугля возможностей договориться с хозяевами приложений побольше будет.
Признайтесь, вы просто не любите все разработки российского происхождения.
;)
А обвинять меня в ненависти к российским разработкам, по меньшей мере глупо
Т.е. дело не в формате? Только в количестве?
Яндекс.Бара не существует уже 5-6 лет.Поэтому и пишу «был»
В русскоязычном сегменте. Что логично.Не логично, гугл в русскоязычном сегменте тоже присутствует.
Т.е. дело не в формате? Только в количестве?Формат мне тоже не нравится. Такой метод распространения — почти мошенничество (да на гугл это тоже распространяется)
Как поступить?
А вот лет 10 назад Яндекс искал в Рунете лучше всех. Это факт.
Сейчас факт, что ищет плохо. Очень плохо.
Т.е. нет смысла пытаться найти что-то через Яндекс, ибо Гуугл сделает это корректнее.
Я примерно год (2013) тестировал обе системы по своим личным нуждам. А я ищу каждый день по много раз и по многим темам.
И Гуугл всегда давал более релевантный ответ. Т.е. 1-3 ссылка. Редко 1-10.
В Яндексе же редко на 1-3 странице(!) я находил адекватный моему запросу ответ.
Кстати, не помню, чтобы Гуугл когда-либо пытался предложить мне установить себя. Насколько помню, мне везде нужно было принудительно переключаться на него.
Что касается «большинства»… ну, большинство считало родимые пятна признаком ведьмачества, большинство радовалось сожжению очередной ведьмы, большинство считало, что Земля плоская и что Солнце вращается вокруг нее. А большинство пигмеев не имеет компьютеров вовсе. А большинство опытных пользователей не используют Яндекс-поиск. Есть и много других примеров про «большинство»…
Например, говорят, что сотрудники Яндекса тоже предпочитают использовать Гуугл-поиск.
Все это пляски с бубном, как и «поведение пользователя».
Если сайт пользователю не показывать, то и поведения не будет. А если сайта в выдаче нет, то и показа нет и поведения нет.
А если на сайте нет Метрики, то Яндекс не знает о поведении.
И так до бесконечности.
Зачем было ломать то, что построил Сегалович, непонятно.
Про «большинство» — это не личный опыт. Это исторические факты.
Про «поведение пользователя» — правила математики.
Про то, что раньше Яндекс корректно ставил Источник выше копипаста — это факт. Так было в 2010 и 2011 году.
Падение доли Яндекса в поисковом сегменте Рунета — тоже факт. (Может, конечно, эти данные не верны, но они публиковались чуть ли не в РБК или Вестях. И Яндекс их не опровергал).
Что Яндекс плохо ищет? Так уже в этой ветке примеров нерелевантного поиска столь много, что пора прислушаться к пользователям, а не молиться на Матрикснет.
Так где ошибка? :)
«10 назад Яндекс искал в Рунете лучше всех. Это факт.»
:)
И тогда искал хуже?
Или «не факт» — это когда критика, а «факт», когда хвалят?
Но для устранения ошибки эта отговорка не работает.
И отговорками релевантность не повышается.
В отличии от внимательного анализа и критичного отношения к своим возможным ошибкам.
Яндекс никто не обвиняет в ошибках.
А вот категорическое нежелание Яндекса замечать ошибки и реагировать на критику исправлением ошибки ему уважения не прибавляет.
И происходит потеря клиентов.
Вы отвечаете на то, что я не говорил. Ошибки нужно анализировать и исправлять. Но общую картинку по ним не увидеть. Какой бы пример подобрать. Например, планета Земля. Если где-то горит лес и все вокруг окутано дымом, это не значит, что вся планета в огне :)
Яндекс считает нормальным, то что в выдаче копипаст, а не источник?
То, что копипаст в выдаче выше первопубликации?
То, что эта ситуация не исправлена за 5 лет активной переписки с «Платоном»?
То, что в выдаче вместо разнообразной информации по теме несколько десятков копипастов, а статей, адекватных запросу просто нет? (Примеры выше и в личном сообщении.)
То, что в лекции Яндекса «Как писать хорошие тексты» одной из первых фраз идет «как написать хороший копиррайт»? (Т.е. как намусорить, ибо копиррайт это еще больший мусор, чем копипаст, поскольку просто содержит ошибки.)
Когда вместо копипастов в выдаче будут первопубликации?
Как сделать хороший поиск — виднее Яндексу.
Почему он не делает хороший поиск — мне непонятно.
Я предлагал Платону, а теперь уже и Вам несколько вариантов, как очевидно можно исправить ошибку, о которой здесь говорил не только я. Ошибку, которая противоречит правилам Яндекса и нарушает законы.
И Вы и Платон на это отмалчиваетесь.
Я предложил простой и понятный механизм для того, чтобы оригинал был в выдаче выше копипаста. Но молчание… Этот механизм Вам не нужен…
Я предложил Вам использовать мой сайт для тренировки Вашего алгоритма, чтобы не гадать, что откуда, насколько важно, интересно, полезно, для спецов, для неспецов, авторский, компиляторский, авторская ссылка, СЕО ссылка и т.д., а точно знать и настроить алгоритм тонко и качественно. Имея «инсайд», «правильный ответ» от меня.
И в ответ опять молчание.
Вывод. Хороший поиск Яндексу не нужен. А нужно что-то другое…
В Яндексе же редко на 1-3 странице(!) я находил адекватный моему запросу ответ.
Гугль раньше внедрил персональный поиск?
Но! Я хочу, чтобы Яндекс искал так же. Мне, как пользователю, выгодно, чтобы было две сильных системы. Это же элементарно.
Гугл очень агрессивно предлагал установить себя, а именно хром. Одно время на каждом сайте гугла при каждом посещении появлялась плашка с предложением срочно установить хром. Они успокоились, только когда получили почти монополистическое положение на рынку браузеров.
Как поступить?Попросите чтобы галочки по умолчанию не были нажаты.
И если мы уйдем, то место займут те, которые галочек не требуют
А легкие наркотики случаем вы не продаёте? а то ведь придут те которые будут тяжелыми торговать…
А отток пользователей есть. Но по каким-то причинам он Яндекс не беспокоит.
(Т.е. люди уходят с Яндекс-поиска в другие системы. Это факт. Просто до последнего времени Яндекс получал приток новых клиентов, благодаря своему броузеру и прочему. Благодаря маркетингу. Но не качеству.)
Мне хотелось бы, чтобы Яндекс выдавал качество сравнимое с Гууглом. Но увы. Качество Яндекс-поиска настолько плохое, что мне пришлось прекратить им пользоваться.
В моей — часто и Гугль лажает.
Потому я их сочетаю в поиске.
Ведь что бы принять решение — уйти или остаться достаточно десяток раз не найти нужный ответ быстро у поисковика А и тот же десяток раз найти у поисковика В… И вот уже везде по умолчанию переустановлен поисковик В.
А темы и области, поверьте, ну очень разные.
Ведь что бы принять решение — уйти или остаться достаточно десяток раз не найти нужный ответ быстро у поисковика А и тот же десяток раз найти у поисковика В… И вот уже везде по умолчанию переустановлен поисковик В.
Когда в интернете есть 50 альтернативных поисков — да.
Когда их по сути по пальцам одной руки можно пересчитать — ваш вариант ухода не годится.
Про исчезновение тоже интересно, учитывая, что в том месяце Яндекс был топ1 поиск в России.
Вы из Яндекса? Могу здесь написать Вам номер тикета(ов). Это не ссылки. Это можно.
Что касается исчезновения, то 6 лет назад доля Яндекса в русскоязычном поиске была более 80%. Сейчас чуть более 50%. Это называется катастрофической потерей рынка.
Причина — нерелевантная выдача.
(Могу по памяти немного ошибиться в цифрах, но тенденция именно такая. Примерно по 5% потери каждый год.)
Вот кстати, да! Обратил внимание уже давно. По телефону помогая кому-нибудь, что-то сделать на компьютере:
— Пиши в поиске "текст запроса".
— Открывай первую ссылку.
— Тыкай теперь туда-то.
— Эээ… ммм, у меня нет этого!
— Как так нет? А! Возле строки с запросом там такое жёлтенькое?
— Ага!
— Ну пиши тогда в поиске goo...
Яндекс — не система учёта авторских прав. Если текст одинаковый, то с точки зрения пользователя нет большой разницы, с какого сайта его смотреть. Это только для автора текста важно.
Если Вы немножко поразмыслите, то поймете, что первоисточник важен очень многим, начиная от журналистов, заканчивая обычным пользователем, который даже не постит ничего, а только «для себя» читает. Например, если я нашел статью на авторском сайте, то я могу автору задать вопрос. А если на сайте копипастера, то не только не могу, а могу напороться на неграмотный ответ.
Плюс Вы просто не в курсе публичных правил Яндекса.
Яндекс пишет на своей странице «Некачественные сайты»: «Мы стараемся не индексировать или не ранжировать высоко: Сайты, копирующие или переписывающие информацию с других ресурсов и не создающие оригинального контента.»
Яндекс пишет там же: «Сайты, которые содержат неоригинальный, вторичный… контент… Исключение из поиска страниц сайта, понижение в результатах поиска, аннулирование тИЦ»
И еще там же: «Создавайте сайты с оригинальным контентом или сервисом.»
Т.е. это совершенно обычные люди. Ваши, например, соседи. А может быть и родственники.
И Яндекс, выдавая копипаст, вместо моей первопубликации, этим людям приносит вред, ибо они ко мне обратиться не могут. А если ищут не через Яндекс, то находят мой текст не у воров-копипастеров, а на моем сайте и спокойно что-то могут спросить, если им нужно.
По поводу…
«Если текст одинаковый, то с точки зрения пользователя нет большой разницы, с какого сайта его смотреть.»
Есть два сайта. А и В. С одинаковым текстом. На А больше рекламы, дольше загрузка (в разы), текст статьи перекрывается попапом и разбит в середине рекламным блоком.
На В — быстрая загрузка, начало текста чуть выше экрана монитора.
Какой сайт лучше «с точки зрения пользователя»? Где лучше прочитать «одинаковый текст»?
С точки зрения Яндекса — сайт А.
Это как раз вор-копипастер сделал сайт А через 7 лет, после того, как я опубликовал текст, используемый в сравнении на своем сайте (который быстрее и чище, который В).
Про комментарии согласен. Если текст подразумевает вопросы, то найти автора очень полезно. Однако это не вопрос "воровства" текста (термин крайне неудачный, не думали выбрать более точный?), это вопрос права авторства. Присвоение авторства может повлечь наказание по УК РФ. Тем не менее, Яндекс не судебный орган. Если плохо работает — теряет долю рынка, вполне закономерно.
Он вроде направлен на то, чтобы избегать подобных ситуаций (правда, без гарантий).
Последние несколько сотен текстов специально до загрузки прописывал в «Оригинальных текстах».
Однако, значительная часть сайта была создана не только до появления «Оригинальных текстов», но и до появления Яндекса.
Текст привязывается к странице с самой ранней датой публикации. С наибольшей долей вероятности — это первоисточник.
Конечно, есть некоторое запаздывание в работе самого web. archive. org, но для текстов до 2003 года не существенное. А повальное воровство и копипаст как раз начались позже. А может сейчас web. archive. org и пошустрее работает.
Впрочем, используя свои базы (Яндекса), вебархив, «оригинальные тексты», — все, где любой текст так или иначе привязывается к дате, довольно просто при выборе какой вариант идентичного текста показывать — выбирать текст с самой ранней датой публикации.
А потом показывать иной текст (совсем иной), тоже выбрав по наиболее старой дате публикации.
И пусть эти два разных текста конкурируют качеством, юзабилити, поведением пользователя и пр.
А копии просто отбрасывать, не показывать в выдаче. Это же мусор. Вроде как никто не превращает свою квартиру в мусорное ведро — выносят мусор? Так зачем превращать поисковую выдачу в помойку?
В итоге освободится место для множества оригинальных текстов. А не так, как сейчас — на 10 позиций выдачи — 2-4 повтора одного и того же текста в разном дизайне.
Пример 1. Автор продолжает публикации по теме или корректирует старые (актуализирует). Тексты вроде бы те же самые, что и у копипастеров, но читатель получит больше пользы именно от авторского сайта.
Пример 2, более конкретный. На прежней работе публиковал тексты в корпоративном блоге. Особо удачные копировал себе кто попало, впрочем, мне не жалко. В копии текст тот же, что и в оригинале, но убирались внутренние ссылки, раскрывающие тему, а возможности обратной связи с автором не было. То есть, меньше пользы для читателя.
Пример 3. Наш авторский книжный магазин. В данный момент Яндекс не показывает нужные страницы по запросу «Все книги такого-то автора». Где-то в десятке висит «Литрес», где те же книги стоят 400 руб. вместо 150 и появляются на 3 месяца позже. Контент у «Литреса» — тот же, что на авторском сайте: заголовки, анонсы, обложки, отзывы.
Ссылка на сайт авторского магазина у Яндекса присутствует в топ-10, но почему-то на страницу с анонсом романа, который ещё не вышел, а не на «все книги...»
При этом Google показывает в топ-5 то, что нужно. И даёт ссылку на самую выгодную покупку: все книги напрямую от автора пакетом со скидкой.
С точки зрения пользователя, ищущего «все книги», очень большая разница: купить на авторском сайте все книги пакетом или ПО ТОЙ ЖЕ ЦЕНЕ взять одну книгу на «Литресе», накормив всех посредников… Контент тот же самый, но на авторском сайте пользы от него больше.
Вы совершенно правы.
И, например, в 2011 году Яндекс четко выдавал сначала первопубликацию, а потом сайты с копиями. Что вполне себе «зеркало Рунета», ибо сначала текст публикуется, а потом копируется.
Особое спасибо за пример с магазином.
Я думал, что товары Яндекс ищет еще нормально, а оказывается и их стал искать криво.
Полностью согласен. Если цена разная — разница для посетителя существенная. Если текст бесплатный — разница уже не так очевидна.
Яндекс — не система учёта авторских прав. Если текст одинаковый, то с точки зрения пользователя нет большой разницы, с какого сайта его смотреть. Это только для автора текста важно.
Не совсем так.
Напрямую — да, Яндексу все равно. Главное чтобы ищущий нашел хоть какую то копию, не обязательно оригинал. Тут это обидки только авторов.
Косвенно же — политика Яндекса и Гугля определяет то чем будет фактически наполнен интернет.
Появилась целая индустрия вторичных сайтов.
И вторичная индустрия накруток.
А это в свою очередь порождает второй круг проблем с которым уже приходится боротся Яндексу.
Там уже по 5 рекламных позиций над поиском. Т.е. на первом экране у пользователя результатов выдачи нет вообще.
Только бабло.
Авторам, тем кто создает контент — это вовсе не интересно.
А как видно из комментария vladds (выше), магазинам такой подход Яндекса не интересен тоже.
Т.о. дело не в авторском праве. Дело в неуважении к пользователю со стороны Яндекса.
И к автору, и к читателю.
Результат — люди уходят в другие системы поиска, более релевантные, уважительнее относящиеся к пользователю.
Это как с магазинами. Если в одном нахамили — поменять магазин.
первопубликацию от копии
Тут вы прям в точку учитывая, что технологию описанную в статье разрабатывал майкрософт, а не яндекс, который даже ссылку на них поместить не удосужился
habrahabr.ru/company/yandex/blog/336094/#comment_10379076
И SPA можно сделать в 40Кб и MPA можно обвешать скриптами/картинками/видосами/фреймами на мегабайты. Тут всё же дело в кривизне рук разработчика, а не в SPA. Что примечательно, самые тяжёлые страницы как правило — вполне себе статические лендинги, в которые лепят fullhd видео на несколько десятков мегабайт в качестве фона.
С декабря сайт клиента падал с ТОП-10 до 45-го места сегодня. В Гугле же всё супер по 300 запросам ТОП-3. Так вот с ИИ "Короле/ёв" я надеюсь на АДЕКВАТ переиндексации ))))))))))
К слову, Яндекс не делает ничего такого, чего бы не делали другие поисковые системы.
Пример: Яндекс постоянно требует «Сделайте Яндекс основным поисковиком и ищите быстрее». При этом он даже не пытается запомнить мой ответ на этот запрос (я залогинен под учетной записью Яндекс) и каждый раз при открытии страницы навязчиво требует «Сделайте Яндекс основным поисковиком и ищите быстрее». Не наблюдаю такого поведения у того же google, например.
Но ответ должен запоминаться на какое-то время, конечно же. Если опишите мне шаги для воспроизведения, то было бы здорово.
Появилась «Дзен» лента. Сразу в яндекс баре, потом и на главной яндекса. Пользы в ней никакой, одни спамные заголовки статей сомнительного содержания, которые я не читаю. В баре нашел как отключить, а на главной яндекса похоже нельзя.
Еще был сильно раздражающий момент, когда яндекс почта без спроса! сменила интерфейс на новый с едкой для глаз зеленой темой. Вернуться на старый было нельзя, других менее броских тем еще не придумали. Контекстная реклама стала очень броской и огромной (в раза 2 больше и ярче чем темы писем). Знаю, что её можно отключить, но я не против рекламы, а против мешающей рекламы. Периодически перехожу по ней.
Когда вышли новые темы для почты, стало удобнее. Но в другой почтовик чуть не ушел…
Не могу того же написать про гугл, он не раздражает, качество поиска полностью устраивает. Почтой яндекса пока пользуюсь…
Вот такое окно увидел сегодня yadi.sk/i/ua1_Shy_3MH9hB, вчера его не было. И это еще не самое дерзкое, бывают четверть экрана ноутбука занимают в выдаче, насколько помню, в красном цвете.
yadi.sk/i/DFYlG3FJ3MHAJy
yadi.sk/i/Fz-kB9sY3MHAP6
Не наблюдаю такого поведения у того же google, например.
Может, просто потому что Гугль у вас уже сделан страницей по умолчанию?
Меня вот постоянно раздражает эта надпись Гугла:
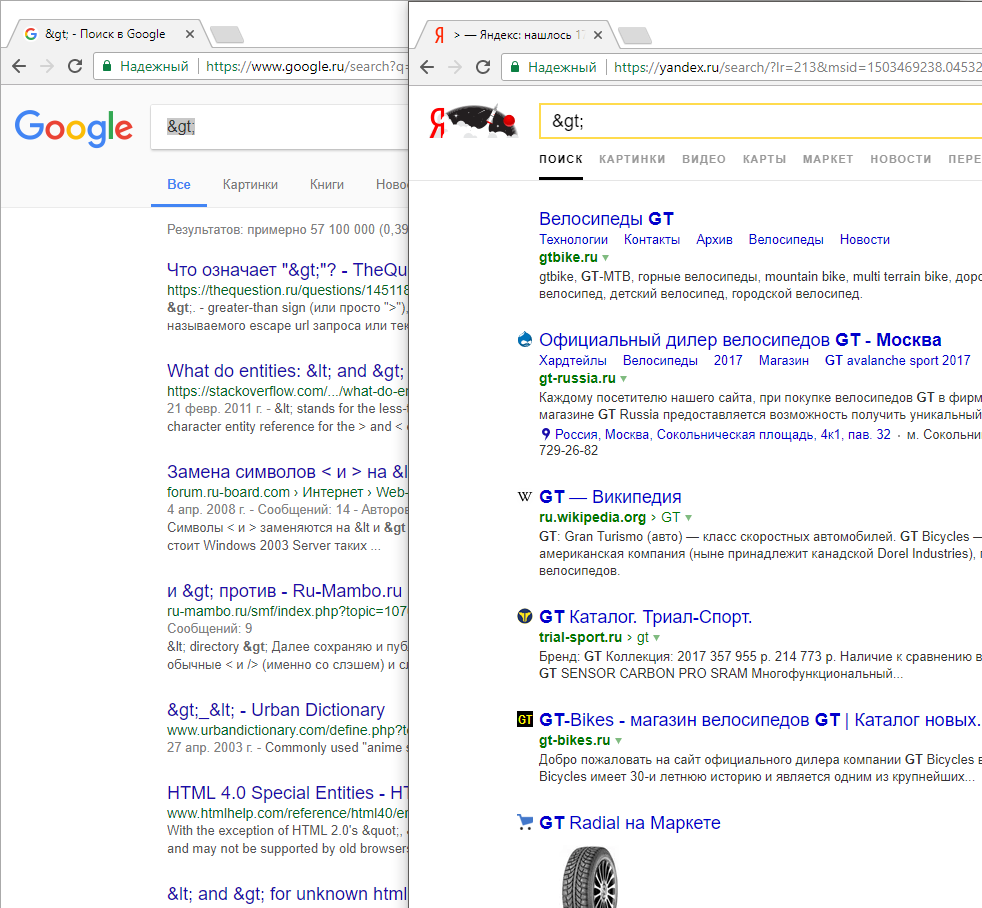
Важно, чтобы страница с источником, первопубликацией была на первом месте. Над любыми, самыми оптимизированными и распрекрасными копипастами.
Чтоб было понятно «откуда ноги растут».
Это занимает одну строчку и сильно улучшает релевантность поиска.
Ибо если выбирать, где видеть текст, то конечно в первоисточнике, а не в ксерокопии. :)
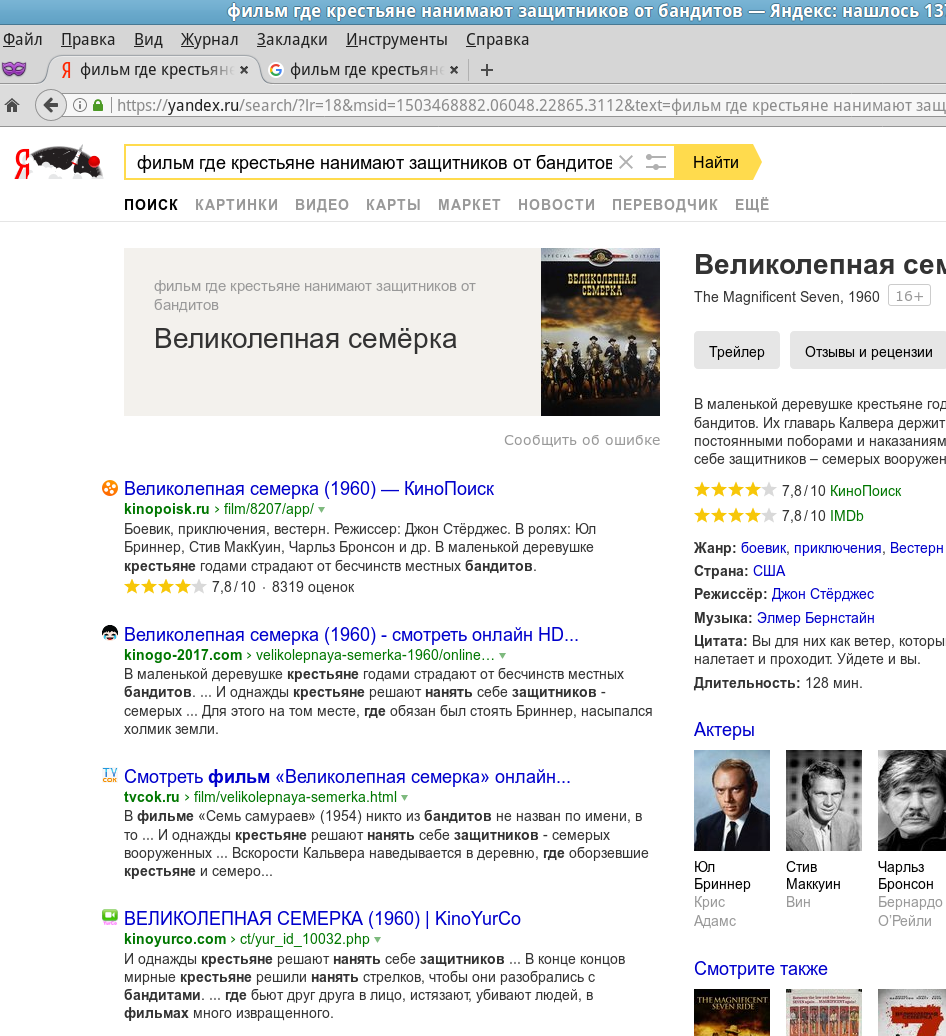
Этим, кстати, пример про «Великолепную семерку» очень показателен.
Т.е. Гуугл нашел дополнительный материал, не пытаясь угадать, «что ты имела ввиду».
А Яндекс, пытаясь угадать, выдал много копий, но меньше информации.
Есть утверждение, «Яндекс научил ИИ понимать смысл документов». Чтобы доказать, что утверждение неверно, достаточно 1 контрпримера!
А вот чтобы доказать, что утверждение верно, нужно доказать что контрпримеров нет. При этом не играет роли, сколько есть миллионов примеров, подтверждающих утверждение.
Есть утверждение, «Яндекс научил ИИ понимать смысл документов». Чтобы доказать, что утверждение неверно, достаточно 1 контрпримера!
Вы просто неявно подразумеваете "всех документов", хотя по смыслу скорее подходит некоторых или что-то подобное.
Из написанного и обсуждений в комментариях я понял, что яндекс не понимает смысла, он строит предположения. Причем, если речь о документах, в которых нет вхождений ключевых слов запроса, предположения строятся на основании поведения пользователей. Алгоритмы учатся не «понимать смысл» документов а более точно предполагать, что большинство пользователей хотели получить, набирая запрос.
Мои примеры для Вас недостаточно «плохи»?
Остался плохой осадок, когда он хочется установиться в компьютер любым способом. Напоминает спам.При обновлении Аваста если не снять галочку шестым шрифтом внизу, установится гугл. И будет основным и поисковиком, и браузером. А Яндекс в последнее время исправился :)
Никогда не пользовался Яндексом. Рамблер — да, ДакДакГо — было дело, даже Бингом.
Это ж насколько нужно ненавидеть Яндекс, чтобы так мучать себя — пользуясь хреново работающими недопоисками.
Писал в поддержку Яндекса, сказали мол посмотрят, и если будет необходимость — поправят.
Справедливости ради стоит отметить, что, когда C# только-только появился, то на запрос "C#" яндекс выдавал ссылки на тематические сайты, а гугл… ничего не выдавал, он воспринимал символ "#" как спецсимвол запроса, в итоге не понимал, что значит запрос "C#", и не выдавал вообще ни одного результата.
Из-за этого я долгое время не пользовался гуглом. Потом, конечно, ситуация кардинально поменялась.
Его это совсем не беспокоит.
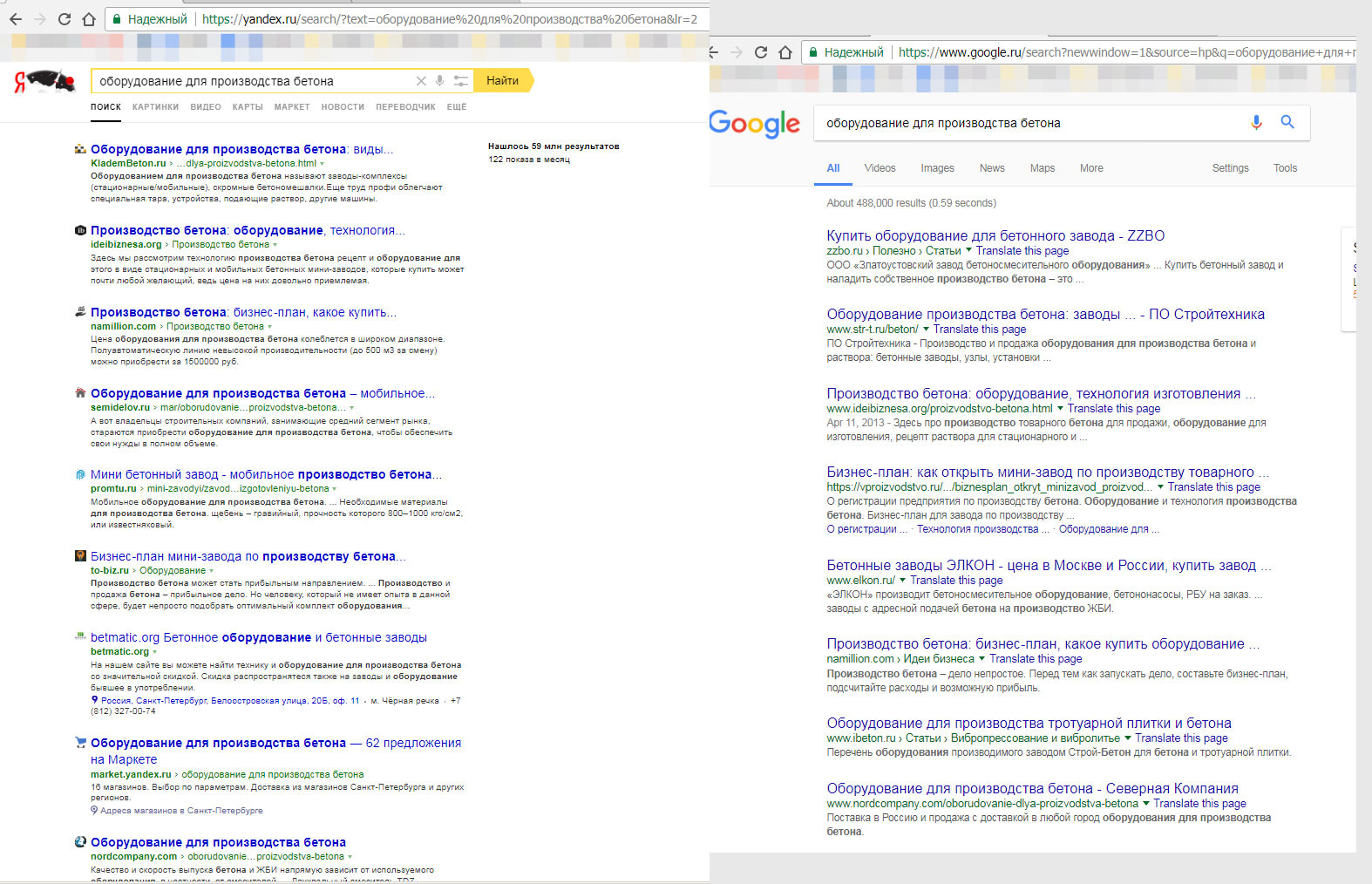
Например, вы производитель оборудования для производства бетона в Питере, вам надо его продавать по все России.
Ищут через поиск.
Когда вбивают в яндексе (55% рынка), то люди видят:
— странные сайты ни о чем
— конечно же яндекс маркет с мышками и т.п.
И вы вынуждены подавать рекламу с ценой около 300 рублей за клик на всю России. То есть у вас вымогают деньги под прикрытием несовершенства алгоритма.
В тоже время в Гугле все норм.
Такой маркетинг вполне может иметь место — книжечки, фильмы, инфу для школьников — ищем более менее норм. Все производство и торговлю рушим поиск, пусть дают рекламу.
Тогда и рынок поиска можно удержать и денег побольше снять с тех, кто может платить.
Картинка https://hsto.org/web/afa/e85/bb7/afae85bb7ac4471fb563e235286f1253.jpg
В 12-13 году окончательно перешел на гуугл-поиск из-за большей релевантности.
А ведь еще в 9-10-м году Гуугл искал в рунете значительно хуже Яндекса.
Итак, есть два запроса:
1. [оборудование для производства бетона] — я привел в пример, картинка выдачи выше
2. [купить бетон] — вы привели в пример
В чем разница между этими запросами?
В том, что:
— запрос 2. [купить бетон] — регионален, то есть если я из питера, то хочу купить бетон в питере, чтобы мне его доставили сегодня-завтра. Выдача нужна из питера от производителей бетона.
— а вот запрос 1. [оборудование для производства бетона] — вне регионов. Если я хочу найти оборудование для производства бетона и ищу это в Питере, то мне подойдут не только питерские производители, но и из Москвы, Новосибирска и т.п.
Это большая и дорогая тематика, которая в яндексе, в органическом поиске, не работает в принципе. На выдаче не сайты — производители оборудования или дилеры, а всякие помойки и, конечно, яндекс маркет где нет бетонных заводов.
Получается, что если я что-то произвожу — оборудование, дома, заводы или оказываю промышленные услуги — то я могу попасть в выдачу только платно, через рекламу. При этом в Google все нормально, сайт производитель, по профильному запросу — на первых местах и пользователи находят то, что нужно сразу, не шарясь по рекламным сайтам.
Поэтому падение % ваших клиентов в этой тематике скорее всего ооооочень большое.
Я, как вебмастер, веду около 20 промышленных сайтов, и, с моей точки зрения, у вас это либо намеренная политика вымогания денег, либо вопиющая некомпетентность.
Назовем, условно, эти алгоритмы «финансовым фильтром». Возможно есть и фильтр «благонадежности»…
И тут начинаются мантры и пляски с бубном про юзабилити, поведение пользователей и прочее. Под общей эгидой «мы Вас умнее»…
5% в год — потеря доли поискового трафика.
Т.е. 5% упущенной выгоды в год.
Это «не так значительно»?
Возможно, но 20 раз по пять и будет 100.
А падение началось с 80.
И на сегодняшний день, если тенденция сохранится, то через 5 лет Яндексом будет пользоваться не более четверти рунета.
Я могу ошибаться в долях процентов (м.б. в проценте) или в статистике за последний год.
Каждый год доля Яндекса в поисковом сегменте уменьшается примерно на 5%.
Яндекс пока это не замечал, так как был рост количества пользователей.
Т.е. в % терял (или упускал выгоду), а «в человеках» прирост был.
Однако у Гуугла, к примеру, этот прирост «в человеках» был больше.
Результат — Гуугл прирастал большим количеством пользователей Рунета в то время как Яндекс их, в реальности терял. Т.е. до поры до времени Яндекс позволял себе не замечать, что его пользователи переходят в другие поисковые сервисы, ибо был банальный приток новых пользователей, перекрывавший отток.
В этом году, судя по публичным выступлениям Яндекса, наконец эта тенденция стала для него явной.
Чем быстрее это заметят акционеры, тем скорее и моя и Ваша идея «хороший поиск = хорошие доходы» реализуется.
Если не заметят, то как и написал Infanty, Яндекс-поиск перестанет существовать, как и Yahoo.
Если не ошибаюсь, то эта информация была даже в пресс-релизах Яндекса.
Гугл в рунете прирастает только мобильным трафиком за счет андроида. Но так как поисковый трафик все больше уходит в мобильные, Яндекс теряет поиск в рунете. Это верно.
Так общий объем поискового трафика растет, и растет за счет мобильных, а не десктопа. Долю в общем поиске вы теряете.
Все платежеспособные знакомые в Гуугле. И все в него перешли в промежутке с 2012 по 2014 год. И остались.
Это, конечно не миллионы «в людях». Но в % — зашкаливает.
Думаете, что я хотел уйти? Я очень консервативен — не люблю смену интерфейса. А в Гуугл все немножко иначе. Поначалу непривычно было.
В конце концов давайте мы с Вами договоримся — ничего не падает, все растет. Пусть у нас будет такая «легенда».
Мы же не об этом, а о качестве поиска.
Вы сами сказали, что качество — это клиенты. Новые или удержанные.
Я предложил небольшое улучшение и механизм. (Смотрите личные сообщения).
Посмотрите на комментарии здесь и их оценки. Проблема копипаста важна многим. Очень многим. Решить ее можно довольно просто и быстро. И это улучшит качество поиска и стимулирует авторов на конкуренцию текстами. Т.е. выиграют все — авторы, читатели, Яндекс.
(Кроме воров-копипастеров, конечно).
Яндексу мешает мусор в выдаче? Это уберет мусор.
Яндекс хочет дать больше вариантов ответа на вопрос? Без мусора ответов будет больше.
Яндекс хочет, чтобы было меньше СЕО-шных г-сайтов? Наверно. Иначе не делал бы АГСы.
Убрать копипасты, оставить первопубликации — и будет меньше г-сайтов.
Я думаю, что цели авторов, Яндекса и добросовестных веб-мастеров совпадают.
Или я не прав?
Лукавите )) А поиск с мобильных vs декстоп смотрели как растет? Так вот с мобильных 90% — гугл ибо андроид. Никто особо не парится ставить Яндекс на смартфон. Выигрыш не очевиден пол названным причинам. Вот Яндекс такси есть смысл ))
Может быть BarakAdama имел ввиду это:
Возможно, но 20 раз по пять и будет 100
[КО] Ибо 20 лет по -5% будет "только" лишь -62%. [/КО]
А серьезно если, то я сам Яндексом редко пользуюсь, как раз по вышеозвученной многими причине "не релевантная выдача", а то и вовсе неадекват.
Про айтишный же (а так-же инженерный, научный и т.д.) поиск я вовсе лучше промолчу… Как блин сегодня можно не индексировать специальные символы (ну или худо-бедно хоть какой-нибудь whitelist для парсеров и алгоритмов рассечения, стоп-листов и т.д. должен же быть).
П.С. Про "Королёв" — попробовал тоже, хмм (немного разочарован)… А оно точно AI как обещано ("по смыслу запроса, а не по ключевым словам")? Или оно ещё учится?
И прикрутили бы они возраст что-ли (если человек залогинен), чтобы ЦА значит с поправкой на возраст… (хотя бы парочке нейронов его скормите, а?).
Ещё в 2009 году после Яндекс.Старт-а было предложение как это можно было попробовать сделать (алгоритм понимания смысла текста и запроса), но в тот момент Матрикснет удовлетворял нуждам компании и «домашний» проект не заинтересовал Яндекс. Хотя очень приятно побеседовали с ребятами из отдела поиска. Прочитал заголовок — думал Вы реализовали дополнительный интересный алгоритм (похожий на тот, что мы презентовали в 2009 году) в дополнение к нейронным сетям. Ан нет…
Яндекс использует для этого вектор в 300 значений, как я понял.
Получаем 300-мерное «плоское» пространство смыслов.
Мне кажется, оно может перекрыть существенную часть вариаций точного запроса и немного аллегорий.
Но, конечно, «смысл», формирующийся в нашем мозге — на порядки сложней, он включает много ассоциативных связей и цепочек и покрыть его полностью — необходим уже полноценный AI, который потребует на сегодня всей вычислительной мощности планеты (плюс\минус пару порядков)
Вектор — это все таки не смысл, к пишет автор, а похожесть контекстов как в word2vec с примесью tf-idf в «мягком» варианте. До смысла тут еще очень далеко, но в задаче поиска по релевантности вполне походит. А что Вы такого предложили им, можете написать? Интересно даже стало, что Вы подразумеваете под «смыслом».
А вообще хороший пример привели того как все эти нейросети не способны понять противоречие, состоящее в том, что детский шампунь — не питье. Они все рано лепят из него синонимы вектор фикс длинны. Все что они могут. Но Компрено (первое что приходит на кии как альтернатива) тут тоже не поможет, так как они не смогут описать все возможные метафоры и смыслы. 20 лет уже пишут )) Взял пример для тестов.
Так вот, по запросу «лечение храпа» без приставки «сыктывкар» или «в сыктывкаре» этот сайт невозможно найти, он аж на 3 странице выдачи. Это же нелогично? Поисковик предлагает мне кучу статей и сайты разных клиник в других городах, но клинику в моем городе не показывает. Хотя клиника есть в яндекс.справочнике (и мой город определяется как Сыктывкар). И вот на этом примере такая же проблема у многих местных грузоперевозчиков, магазинов автозапчастей и т.п. — они не могут выбиться вперед среди жирных федеральных сайтов, даже если эти сайты в выдаче не полезны и вообще не в тему. Вот определение запроса по смыслу это очень круто, но если бы еще поиск отдавал предпочтение тому решению проблемы, которое ближе всего для меня, жителя Сыктывкара, тогда поиск был бы полезнее, я думаю.
Так что Вы пестуйте и дальше свою паранойю, а я перейду к google.com.

И ведь точно — отвечает :(
Но в среднем по больнице получается, что вы как часть народа получаете то, что ищет народ. И в среднем это наиболее верный ответ, а все ошибки яндекса, указанные тут, связаны со
специфичными запросами. Хуже то, что кликают чаще по тому что выдает сам Яндекс в топ10. А там все забито грандами. И как не старается Яндекс подмешивать, против лома нет приема, тем более если ты сам этот лом сделал.
Вообще непонятно, зачем в выдаче нужны копипасты. Достаточно много оригинальных текстов почти по любой теме. А копипаст только замусоривает выдачу.
Ну и желание что-то писать пропадает полностью. Я пишу, а кто-то ворует и зарабатывает на этом с помощью того же Директа.
Написать хорошую статью — это большой труд и много знаний.
А плохие статьи не копипастят.
На вашем сайте я узнаю только Ваше мнение по вопросу, а на сайте агрегатора и другие, там больше текстов по теме разных. И в этом они лучше. Другое дело, что авторство должно быть указано, лучше с ссылкой на Ваш сайт. Если этого нет — вэлком в суд со всеми доказательствами. Денег получите с них.
Отсюда и ответ на многочисленные обвинения в нарушении авторских прав от asdoc. Грубо, если твою статью скопипастили на более популярном сайте, радуйся и пиши им, а не Яндекс, чтобы указали автора.
Когда Вы научитесь писать тексты, то посмотрим, как изменится Ваше отношение к копипасту.
Если меня опубликовал тракторный журнал, я только радуюсь. Вы же хотите, чтобы весть Ваш сайт выше этого журнала. Так не бывает — вы не один автор у него, тем журнал и интереснее читателям. Надеюсь это понятно и не обидно Вам.
И он первым опубликует это в сети. Это нормально. И он должен быть первым в выдаче, так как у него первопубликация. И он может сообщить читателю мои координаты, если читателю нужно. И я разрешил эту публикацию.
В этом случае как раз моя публикация будет вторичной. Хотя и не вполне. Авторская версия почти всегда имеет отличия от журнальной.
И разговор идет не про сайт. Яндекс не рейтинг. Разговор идет о позиции оригинального текста в выдаче. Это привязано к странице, тексту и дате публикации.
Что касается «где интереснее», то у меня более 5000 разных текстов. Все интересные. Это вполне конкурентноспособно, относительно сайта журнала.
И не стоит равнять компипаст г-сайты и сайты журналов. Журналы копипастом не занимаются. Это прерогатива воров-копипастеров.
Это снижает качество, поскольку иногда нужно и связаться с автором, и уточнить, и просто знать, кто автор, откуда данные, тогда можно думать — доверять им или нет.
Кроме этого я приводил пример, как в выдаче 10% ссылок были на мой текст на других сайтах. На один и тот же текст.
А зачем пользователю 30 копий? Ему достаточно одного текста. От первоисточника.
На место этих 30-ти можно было поставить иные тексты по теме (я привел примеры какие тексты есть по теме на моем сайте. А ведь есть и другие сайты...) Но копипаст замусорил выдачу и для других текстов места не осталось.
Результат — пользователь получил выдачу гораздо хуже, чем мог бы, если бы Яндекс очистил ее от копипаста.
Что касается «кто-то разрешает», то я таковых за 20 лет не видел ни одного.
Копипастить и получить разрешение на публикацию — две большие разницы!
Копипаст — воровство. Перепечатка с разрешения — нормальная практика.
Однако в любом случае в поисковой выдаче копия должна быть ниже оригинала.
Иначе нет никакого смысла писать хорошие тексты.
В результате интернет полон бездумными дешевыми копирайтерскими текстами.
Отличить копипаст от оригинала для Яндекса дело очень простое.


Объясняю красивый пример. Так случилось, что последние несколько лет я занимаюсь строительством, это не моя специальность и частенько приходится отправляться в интернет за ответами, даже для решения простых задач.
При вводе поисковых запросов по любому вопросу, будь то «технология заливки фундамента» или «сварка алюминия», почти 100% выдачи занимают веб страницы составленные под копирку — оглавление 4-7 пунктов, копипаста картинок, одно-два видео с ютуба и рерайт соседних статей из выдачи. Там точно не будет ни слова про то как правильно что-то сделать, выжимок из ГОСТов и нормативов или личного опыта, что привело к тому, что последнее время, вместо поиска в яндексе приходится либо искать ответы на ютубе, где уровень контента значительно лучше, либо в книгах соответствующей тематики, что очень огорчает, т.к. требует значительных затрат времени.
Техподдержка говорит что всё в порядке, выдача релевантна запросу, но выдача хлам, планируете это исправить?
P.S. И еще бы галочку «никогда не сватать мне сервисы яндекса», а то я даже и не знаю, почему меня в сотый раз спрашивают, хочу ли я установить его в роли стартовой страницы, и не хочу ли я Я.Браузер" — будто бы после 99 ответов еще не понятно.
Возможно, такой персонализированный поисковый функционал стоит денег. Интересно, много ли было бы подписчиков платного поискового сервиса на основе Яндекса или Гугла, глубоко персонализированного, со множеством настроек? Я думаю, если бы они сделали цену $10 в год, они смогли бы набрать достаточно подписчиков и окупить затраты.
Тоже строю домик — вот тут www.allbeton.ru/wiki поиск по текстам строительных книг и тут же можно их скачать (почитать).
Меня удивляет почему нет подобного от гигантов индустрии, на том сайте это сделали энтузиасты, поиск по тексту распознанных книг djvu.
Вот бы у яндекса (или Google) был еще переключатель — ищу инженерную (программисткую, строительную, радиоэлектронную, ...) проф. инфу и они бы выдавали и искали по книгам и серьезным статьям только.
Это был бы прорыв мне кажется.
Ребята из Яндекса — дарю идею :)
применить нейросети на стадии поиска L0, чтобы семантические вектора помогали нам находить документы, близкие по смыслу к запросу, но вовсе не содержащие слов запроса
В гугле часто встречался с таким. Откапывает какие-то поросшие мхом архивы, где указанное слово не встречается вовсе (это вообще могут быть исходники на Си с минимумом комментариев) но неожиданно это оказывается именно тем, что я хотел. Причём в выдаче порой всего-то 10-20 документов, и можно проучиться, что подобный бред до меня никто не искал.
До этого гуглил по текстам ошибок из логов jitsi — софтина для видеоконференций. В основном в выдаче были только дампы чужих логов, причём очень немного, ибо изделие глючное и непопулярное. Но помимо дампов также нашлась ссылка на архивы почтовой рассылки (mailing lists), где искомого текста в явном виде не было, но проблему обсуждали.
В следующий раз буду записывать)
BarakAdama, и сама фича классная, и рассказ отличный! Вы большие молодцы, спасибо, что так интересно и понятно пишете о сложных штуках.

В данном случае фамилия «Бозник» не внесена в базу орфографического анализатора. Я описывал эту проблему выше и давал примеры. Помогает знак "!" перед словом, но документы с иными формами этого слова поиск искать не будет.

{kind=link}
{kind=link}
Более того, если на странице три рекламных блока, а я только что искать дрова для ноутбука Asus, то в этих блоках почти наверняка будет — угадаем! — правильно, реклама Asus (нечто «суперполезное» для меня, правда?)! Так вот мало что реклама нерелевантна (если я ищу дрова к буку, то у меня не радость, а проблема с моим буком Asus, если задуматься), так еще и непонятно, что делать-то: мне, как, в каждом блоке нажать крестик и выразить мысль, что мне не интересно, или одного хватить должно?
Уже несколько писем за месяц-два ушло в ТП яндекса по поводу всяких всплывающих предложений, которые постоянно появляются вновь и вновь. А учитывая, что и на работе и дома на разных браузерах везде используется одна учетка, то это дико выбешивает (что и послужило причиной обращений в ТП). Собственно никаких изменений не происходит, только отписки «передано кому-то там»
Когда уже появится в настройках галочка «Отказаться от всех предложений», которая будет привязываться к почте и навсегда решит эту проблему?
P.S. из-за вашего [Яндекса] бездействия все это добро выпилилось с помощью блокеров, и о чудо, на главной странице исчезает полоса прокрутки, которая появляется из-за предложения установить Яндекс браузер на свои устройства (но зачем оно мне на ПК показывается?), бесполезный «Дзен», всякие надписи над футерами и предложения к поиску (я что первый раз зашел на страницу? у меня яндекс почта наверно уже 10 лет, зачем мне мне все это видеть при каждом рефреше страницы?)
P.S.S. а уж обновление погоды — это вообще тихий ужас (в ТП тоже написано письмо с пожеланиями) информация просто стала невоспринимаемой при беглом осмотре — теперь полностью отсутвует дизайн, который позволяет цепляться глазами за информацию (в основном это цвет в зависимости от температуры).
Я понимаю, что это просто бизнесс и перед начальством надо отчитываться о проделанной работе, новым фишкам, но бл@ть доколе? Вы же Яндекс (пока еще с большой буквы)
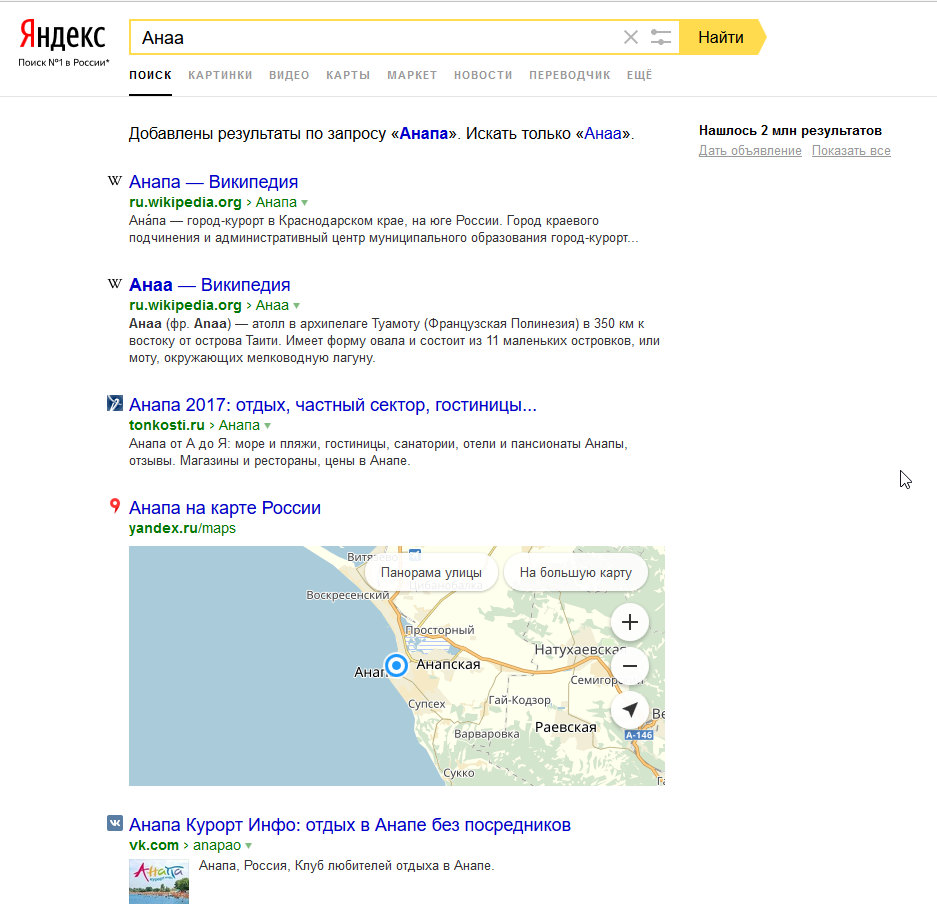
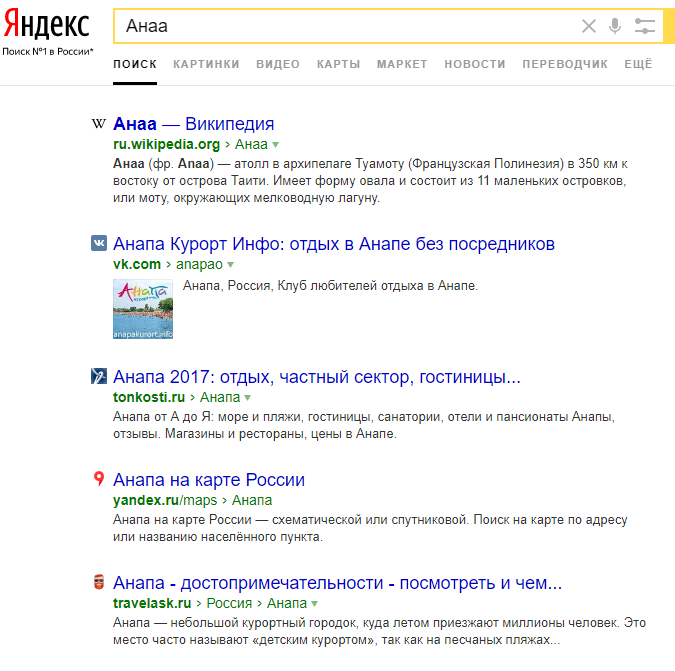
Ok, запрос низкочастотный, поищем только Анаа

Кроме добавления назойливой рекламы что поменялось?

Так как поведение операторов зачастую удивляет попробуем закавычить

О, класс! Реклама переместилась!
Ну ладно, почти у цели — появилась карта! Кликаем по ней и получаем…

Ладно, попробуем на предыдущей странице кликнуть на ссылку «Карты».

Лучше бы не пробовал…
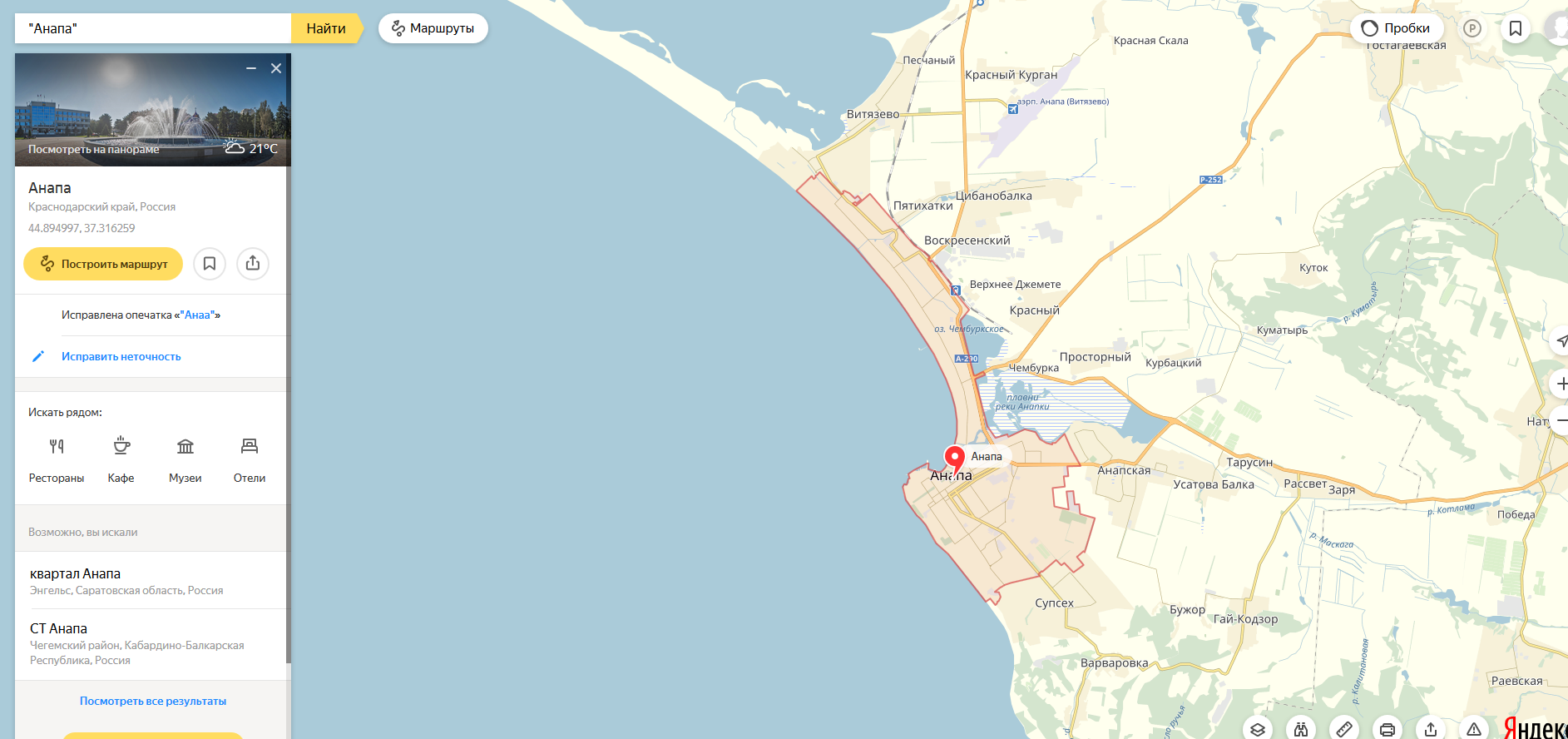
Хорошо, попробуем помочь Яндексу, уточним запрос — ищем "Анаа, Туамоту"
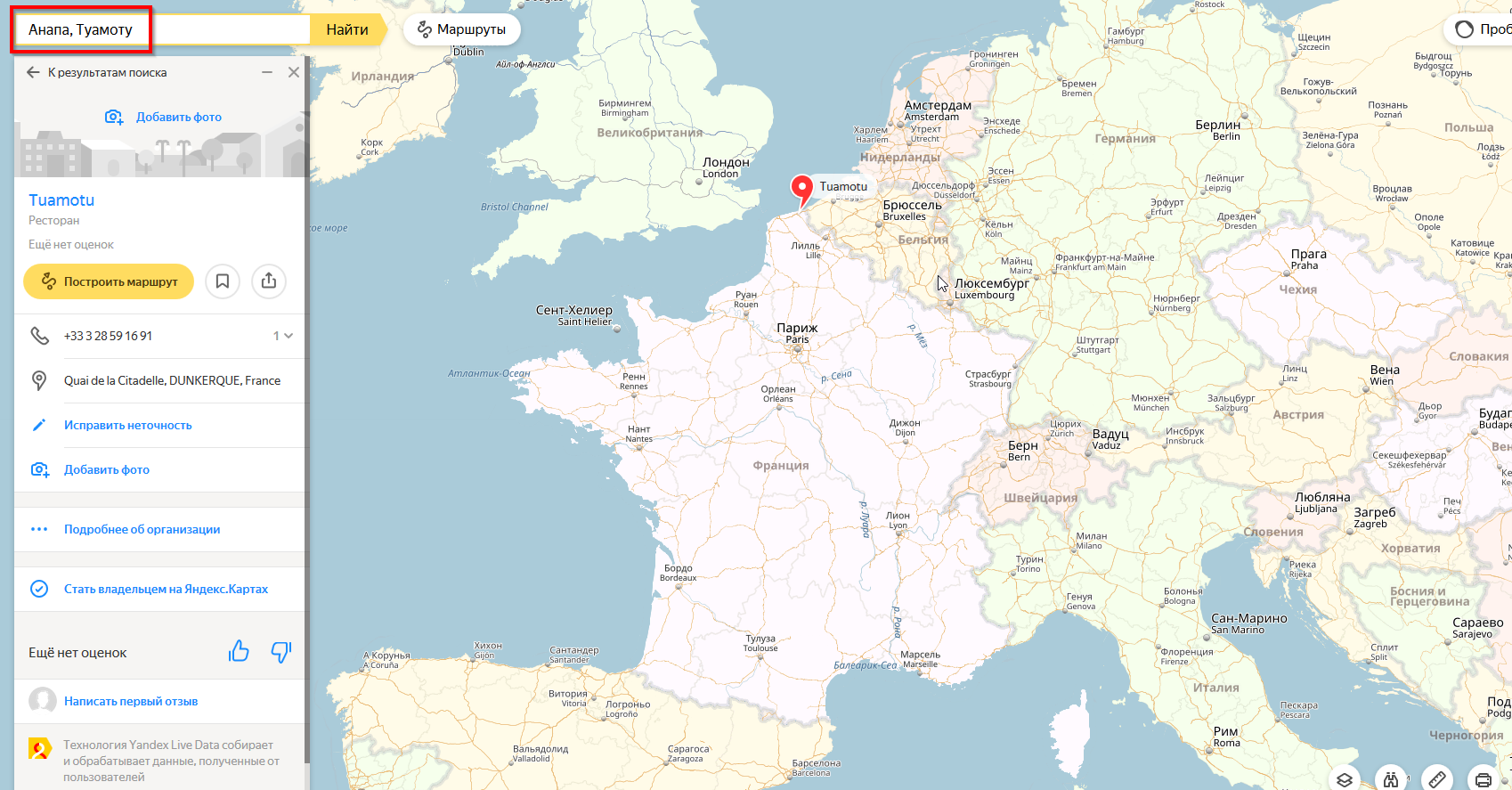
Получаем ни Анаа ни Анапау, а вообще ресторан во Франции
Уфффф… Возвращаемся на предыдущую страницу и кликаем по самой полезной кнопке на странице поиска
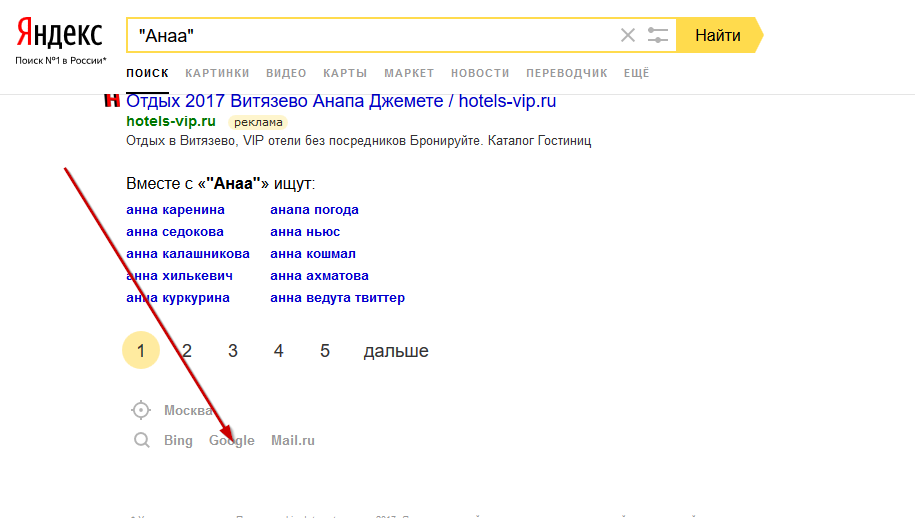
Теперь от цели нас отделяет всего 2 хода:


У меня после отказа от исправления опечатки нашел как раз Анаа.
Попробовал из другого браузера (под другим логином) и другого региона, результаты почти те же:
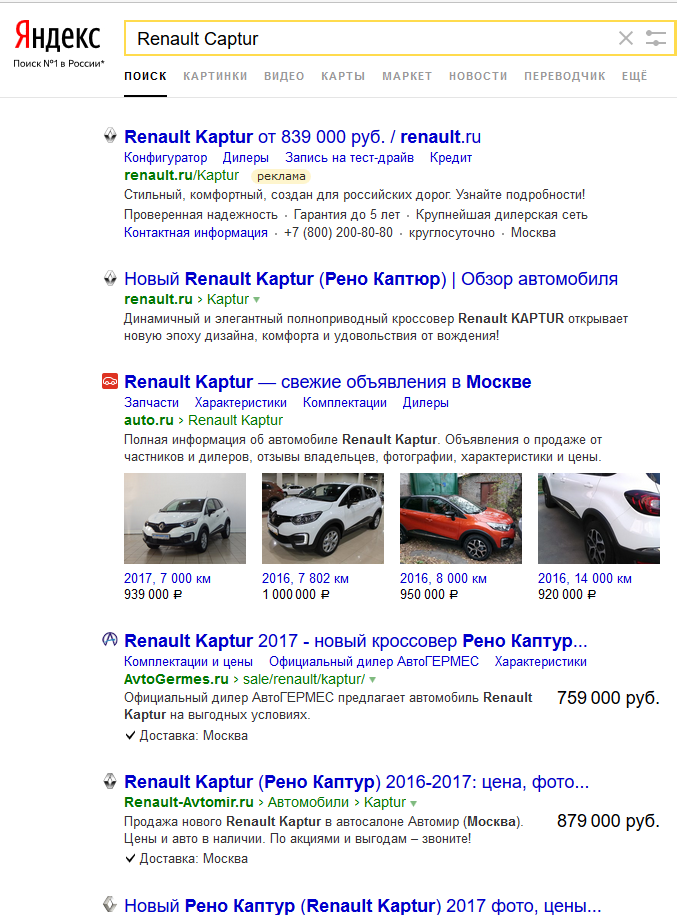
Captur != Kaptur — это вообще разные авто, а в итоге упоминание о Captur оказалось только на 13-й строке.
Здесь также «радуют» карты выдавая данные для Мурманска при поиске из Москвы:


Кеширование векторов — это интересный, но типовой приём (например, ещё часто запихивают вектора документов в какой-нибудь индексатор типа ElasticSearch, чтобы потом быстро дёргать ближайших соседей к вектору — у вас наверняка свой продукт для этого). Серьёзно, вы и вправду раньше считали вектора всех документов заново на каждый чих?
Хитрая многоуровневая фильтрация и индексы? Да, это нужно. Это касается скорее оптимизации, не так ли?
Нейронные сети это очень хорошо, конечно. Хочется пожелать успехов Яндексу (да и нам, улучшение поиска это же для нас) на этом поприще. Но уже не один год я ожидаю изменений в более прозаичной области. Если незалогиненным при включенном VPN (что системном, что оперовском) вбивать в адресную строку yandex.ru происходит редирект на yandex.ua. Вводишь yandex.kz попадаешь на yandex.kz, та же история с yandex.com.tr. И только yandex.ru недостижимая цель. Видимо, это непосильная задача даже для исскуственного интеллекта.) Но я не оставляю надежд, на подходе квантовые компьютеры — и, может, при их внедрении, я, набрав в адресной строке yandex.ru, попаду именно на этот домен.) Всем удачи!..
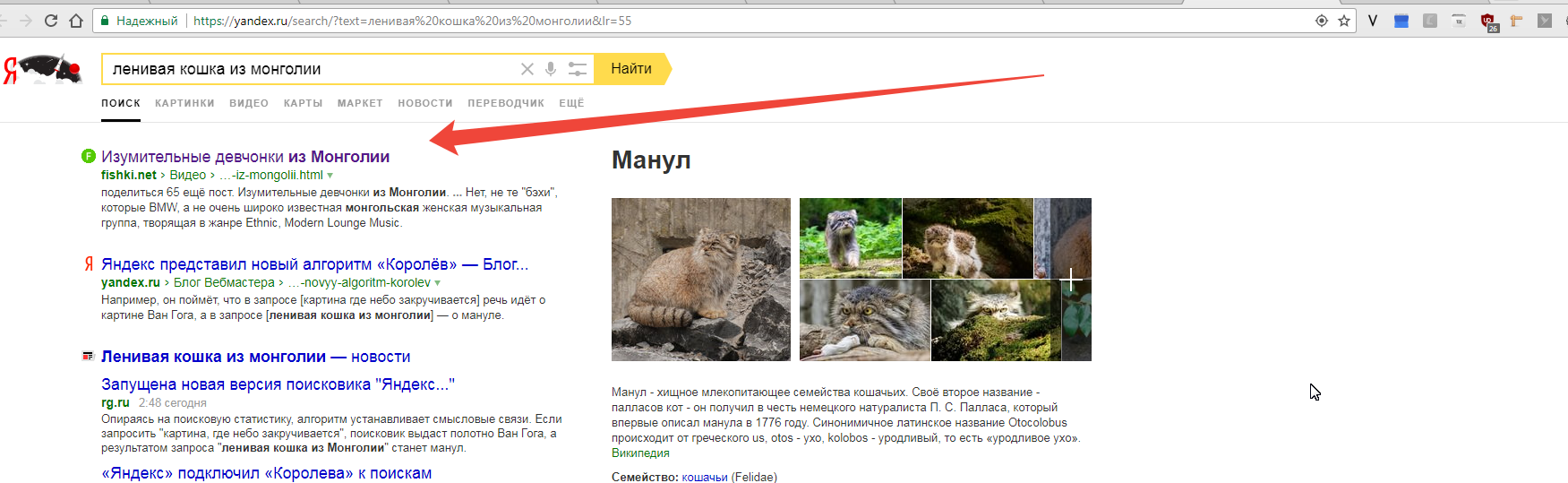
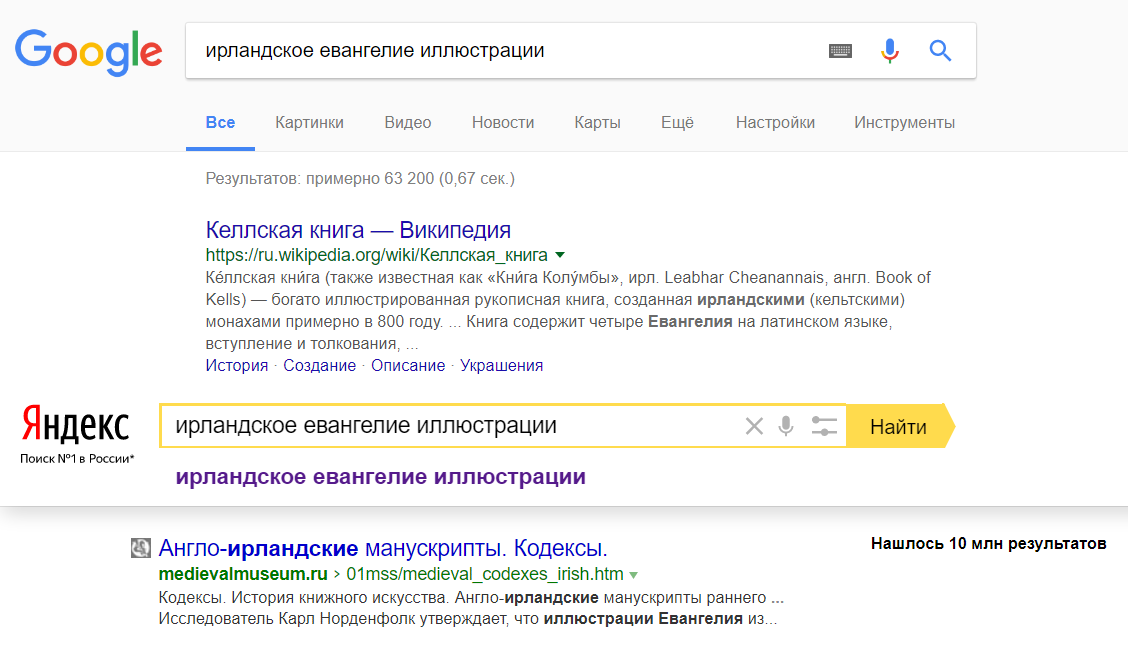
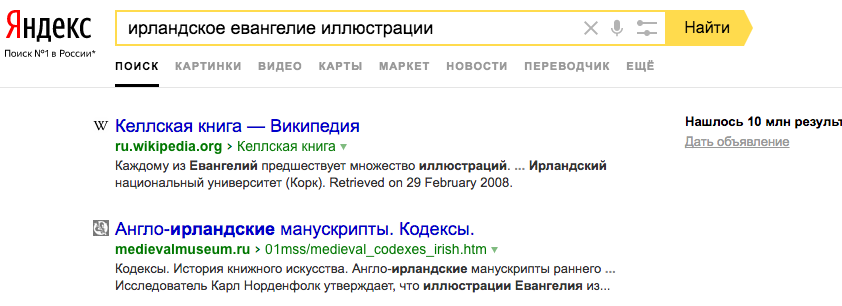
Если на уровне L0 все равно ищет по словам как написано в посте, то может ли Королев найти, как заявили, тексты по смыслу, даже без слов из запроса. Например, келлские книги без слов «ирландское евангелие». Противоречие однако.
Прочёл всё от корки до корки со всеми коментами. НИЧЕГО про смысл не нашёл. Может, плохо искал?
Таки научили Вы Яндекс понимать смысл?
Смотря, что Вы вкладываете в понятия "смысл" и "понимать". Так и под искусственным интеллекто многие почему-то представляют себе Скайнет.
У комментаторов могут быть, действительно, множество своих дефиниций, но, обсуждая Вашу статью, нам всем надо отталкиваться от Ваших базовых позиций и даже пресуппозиций.
Буду Вам признателен, если Вы бы объяснили своё видение в этом вопросе.
«Наш робот сейчас не поддерживает межхостовый атрибут rel=»canonical", поэтому ссылки на другой сайт www… ru/ будут им игнорироваться."
Т.е. примерно за 10 лет существования мобильных версий сайтов Яндекс не научился корректно обрабатывать атрибут rel=«canonical», указывающий где мобильная, а где классическая версии страницы.
Сколько для такого умения нужно написать строк кода? Две? Пару десятков?
И за 10 лет 3000 сотрудников Яндекса с этим не справились!
Тогда о каком Матрикснете, о каком искусственном интеллекте, о каком качестве можно говорить?
Ау, господа из Яндекса! Может сначала научиться решать простые задачи, а потом уже переходить к более сложным?
Понимать смысл говорите умеет? А Тест Тьюринга^W^W Winograd Schema Challenge (WSC) оно уже проходит? =)
PS. ну или вот тут даже луше, чем на вики: http://commonsensereasoning.org/winograd.html
Ребята из Яндекса искренне верят, что каждое слово имеет свой смысл. Но это совершенно не так, в противном случае все общались бы одно-сложно:
— Да; в; очень; было; не; лесу; сейчас; завтра;…
А где смысл то? Нетути!
Ведь копипаст ничего не привносит ни в текст, ни в картинку. Пользы читателю, пользователю от копипаста — ноль.
И при этом Яндекс уверяет, что копипаст ценнее для пользователя… Ведь у него есть шаманский танец под названием «поведение пользователя» и молитва «Матрикснет»…
Это примерно как уверять, что репродукция или глянцевый постер дороже, чем оригинальная картина.
Разрешите согласиться. Большинство заявлений поисковиков, в том числе Мюллера из Гугла, как-то не впечатляют на фоне только им понятной релевантности. Кто-кто, а уж агрегаторы, это сплошной спам-переспам по меркам Баденов и Брайнов, но вечно находящийся в ТОПе. Ни где в руководствах ни Гугла ни Яндекса не сказано, млин, а как же чётко и однозначно указать АВТОРСТВО текста или фото, негде, зато "искусственного" интеллекта хоть убавляй.
Кстати, у Гугла просто вышибает микроразметка по сути и принципу, и уж картинок и видео, да ещё link hreflang особенно. А ещё все это вместе просит вогнать в sitemap. Друзья, искусственный интеллект чего или кого декларируется? Я так, понимаю, и Яндекс и Гугл говорят не о их, а о НАШЕМ с вами ИСКУССТВЕННОМ интеллекте.
Или почему этот текст Тимура Гаскарова не имеет смысла.
Итоги многолетнего исследования.
Как устроен тайный фильтр Яндекса?
Очень просто. Если сайт отвечает всем техническим требованиям Яндекса, если на нем расположена хорошая и оригинальная информация, но сайт по каким-то причинам, назовем их «личными», не устраивает Яндекс, то происходит вот что.
Сайт исправно индексируется и в Вебмастере видно, что все страницы «В поиске».
Но на самом деле, из выдачи постепенно выпадают страницы сайта.
Страница за страницей.
Вместо них появляются страницы сайтов-воров, скопипастивших текст у первоисточника.
Т.е. пока текст никто не своровал, Яндекс выдает их на пессимизируемом «по личным соображениям» сайте. Но как только этот же текст появляется на сайте копипастера, то страница сайта первоисточника из поиска выпадает, а остается страница сайта-копипастера.
При этом сайт-первоисточник, по всем публично озвученным Яндексом требованиям, может многократно превосходить сайт-копипастер. Но в выдаче будет только копипастер.
Такая вот оригинальная «блокировочка».
Действует она примерно с 2012 года.
Что это дает Яндексу? Видимо так Яндекс проявляет свою «лояльность». (Хотя сайт, пропадающий из выдачи, может быть любой нейтральной тематики).
К чему это приведет? К тому, что строчка в резюме «работал в Яндекс» будет восприниматься как минус при последующем трудоустройстве.
Ну а Яндекс, разумеется, продолжит терять долю рынка.
Как писали С.Левитт и С.Дабнер «информация представляет собой валюту Интернета», а раз так, то исключая первопубликации из выдачи, Яндекс обворовывает авторов и способствует «продаже краденного».
Так что вопрос многомилионных исков к Яндексу это лишь вопрос времени.
Как Яндекс научил искусственный интеллект понимать смысл документов