
Несколько ближайших лекций будут по мотивам первого Я.Субботника по базам данных, который состоялся весной. Сначала на Я.Субботнике выступил разработчик Андрей Бородин. Он рассказал о WAL-G — простом и эффективном инструменте для резервного копирования PostgreSQL в облако, а также об алгоритмах и технологиях, которые позволяют WAL-G создавать бэкапы быстрее. Главная особенность WAL-G — дельта-бэкапы. Из лекции вы узнаете об их реализации и о том, как поддержка этой технологии развивается в PostgreSQL.
— Привет! Я разработчик в Яндексе из Екатеринбурга. К технологиям быстрого бэкапа. Бэкапом мы занимаемся довольно давно, были доклады Владимира Бородина и Евгения Дюкова о том, как мы исследуем и что разрабатываем, чтобы хранить данные безопасно, надежно, удобно и эффективно. Эта серия посвящена последним наработкам в указанной области.
Поговорим про бэкапы в PostgreSQL в принципе. Стандартная утилита для переноса данных — pg_dump — определяется как консольная утилита, создающая файл с логическим представлением ваших данных.
То, что это логическая копия, довольно удобно. Вы всегда можете перенести данные между различными версиями, можете нарезать свою базу кусочками, и это стандартный инструмент, который, например, поставляется в коробке с утилитой администрирования PgAdmin.
Про pg_dump надо в первую очередь знать то, что это инструмент разработчика.
Это не инструмент эксплуатации базы данных. pg_dump не предназначен для работы с высоконагруженной БД.

Предположим, у вас все серьезно и вы хотите применить технологию «Восстановление на точку времени», которая использует API PostgreSQL в части работы с онлайн-бэкапами. Вы вызываете функцию pg_start_backup и делаете файловую копию БД. Фактически pg_start_backup заставляет БД сделать CHECKPOINT; и включить запись full page writes в журнал опережающей записи. Та копия БД, которую вы делаете, когда вызываете API, не является консистентной копией данных. Вам также нужен журнал опережающей записи, чтобы иметь возможность восстановить вашу БД на время вызова pg_stop_backup, то есть на время окончания снятия бэкапа.
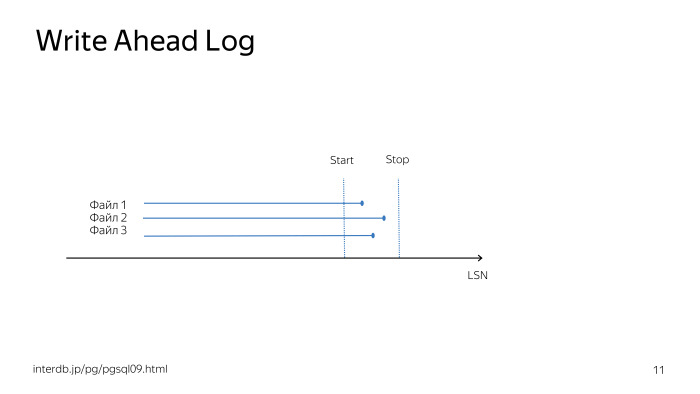
После времени окончания снятия бэкапа и при наличии журнала опережающей записи вы можете восстановиться на требуемую точку времени жизни вашей БД.
В коробке поставляется утилита pg_basebackup, которая реализует всю эту технологию в каноничном виде и позволяет вам сделать бэкап с минимально необходимой функциональностью.
Если у вас все еще серьезнее, чем раньше, то вы используете какой-то софт для управления бэкапами, и обычно это Barman.
У него есть несколько плюсов. Самый главный плюс — это очень распространенная утилита, у нее огромное комьюнити, огромное количество вопросов на Stack Overflow.

Вам достаточно поднять один бэкапный сервер, и бэкапить туда все свои PostgreSQL. Это очень удобно — до тех пор пока вам хватает одного сервера резервных копий.
Как только у вас появляется много серверов резервного копирования, вам надо отслеживать, не переполнился ли какой-то из них. В случае выхода из строя какого-то бэкапного сервера вам нужно понять, какие из ваших БД сейчас в опасности. Вам нужно понять в принципе, куда копировать новый кластер БД при его создании.
Есть значительно более простая утилита для снятия резервной копии, которая называется WAL-E.

WAL-E выполняет четыре главных команды. Команда WAL-PUSH отправляет один WAL-файл в облако, а WAL-FETCH забирает один WAL-файл при необходимости восстановления выполнения restore_command.
Также есть BACKUP-PUSH (реализует снятие API резервной копии) и BACKUP-FETCH (забирает все данные из облака). Данные хранятся в облаке, поэтому мониторить ничего не нужно, это уже проблема облачного сервиса, как обеспечить доступность ваших данных, когда они вам нужны. Наверное, это главное достоинство WAL-E.

Там довольно много функциональности. Есть листинг бэкапов, есть retention policy, то есть мы хотим хранить бэкапы за последние семь дней, например, или последние пять бэкапов, что-нибудь такое. И WAL-E умеет делать резервные копии в огромное множество облачных сервисов: S3, Azure, Google, может локальную файловую систему назвать облаком.

У него есть несколько свойств. Во-первых, он написан на Python и активно использует конвейер Unix, отчасти из-за этого у него есть зависимости и он не очень производительный. Это нормально, потому что WAL-E фокусирован на простоте использования, простоте настройки, чтобы нельзя было сделать ошибку, когда вы делаете план резервного копирования. И это очень хорошая идея.
В WAL-E написано очень много фич, и куда его развивать дальше, авторам было не очень понятно. Пришла идея, что нужна новая тулза.

Главная ее фича в том, что она переписана на Go, у нее почти нет внешних зависимостей, если вы не используете внешнее шифрование, и она значительно более производительная.
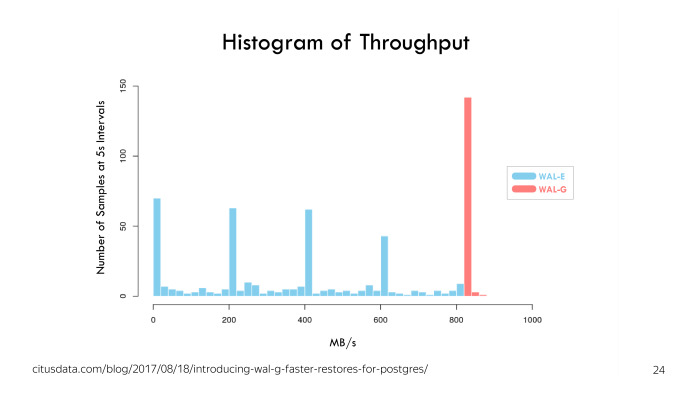
WAL-G изначально был создан двумя авторами из Citus Data, и главное достоинство изображено на этой гистограмме — скорость отправки «валов». Мы видим, что WAL-E бывает быстрой, бывает всяко, бывает большой столбик около нуля.

У WAL-G достаточно стабильная пропускная способность. На тестах в Citus Data он показал, что стабильно отправляет порядка 800 Мб/с «валов».
Кроме того в WAL-G я, например, писал фичу, которая реализует бэкап с реплики. Вам не нужно нагружать ваш мастер БД читающей нагрузкой, вы можете снять резервную копию с реплики.

Но есть одна маленькая проблема. В момент начала снятия резервной копии, вы должны назвать как-то резервную копию. В название попадает таймлайн, который будет изменен в случае необходимости промоута реплики. Если в цепочке реплик перед той репликой, с которой вы делаете резервную копию, произойдет failover, вы запромоутите какую-то из реплик, таймлайн будет изменен. WAL-G понимает, что эта ситуация неконсистентная, потому что имея название на старом таймлайне, название вам обещает, что вы можете продолжить развитие истории БД в любом существовавшем направлении. А это не так. В одном из направлений вы уже поехали, вы не можете задним вагоном перескочить на другой таймлайн. Поэтому WAL-G понимает эту ситуацию и не загружает фишишный JSON файл в облако. Вы создаете физически копию. Но требуется вмешательство администратора, чтобы этой копией можно было воспользоваться.

У нас в WAL-G реализованы дельта-копии, этой разработкой тоже я занимался. Это позволяет снимать меньше данных в очередном base-бэкапе, вы не делаете копию тех страниц данных, которые не менялись с предыдущего бэкапа.

При настройке WAL-G вы указываете количество шагов на которые максимально отстоит от base-бэкапа дельта-бэкап, и указываете политику дельта-копии. Либо вы делаете копию с последней существующей дельты, либо делаете дельту от изначального полного бэкапа. Это нужно на тот случай, когда у вас в базе данных всегда меняется одна и та же составляющая БД, одни и те же данные постоянно изменяются.
Зачем в принципе нужны дельта-копии БД? По идее, у вас есть WAL, вы и так можете накатиться на любую точку.
На нагруженном сервере проигрывание WAL пяти физических секунд прошлого может занять четыре физические секунды настоящего. Если вас просят накатить WAL за четыре дня, это значит, что возможно, человек, который просит это сделать, должен еще три дня подождать. Не всегда приемлемая ситуация.
Вам нужны base-бэкапы на каждый день, но тем не менее, вы не можете себе хранить там 7 или 14 полных копий вашей БД, даже учитывая, что WAL-G заархивирует их, все равно это будут достаточно большие объемы. И в этом случае помогают дельта-копии.
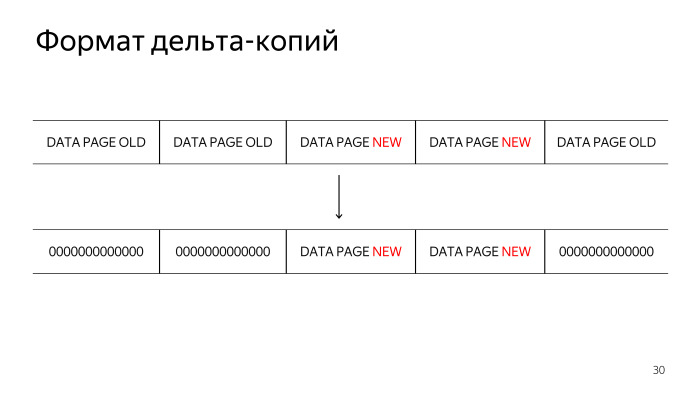
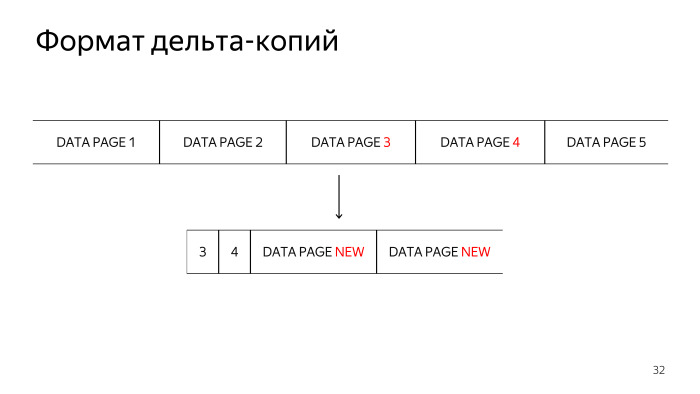
При разработке дельта-копий обсуждалось несколько возможных форматов data файлов. В первую очередь предлагался формат, когда мы не изменяющуюся страницу просто зануляем. Но мы пришли к тому, что это не очень эффективный способ, нули потом эффективно сжимаются, но мы от этого способа хранения потом отказались, потому что его сложно отлаживать в случае внештатных ситуаций.

Следующая технология, которая рассматривалась, это хранение сначала номера блока и затем изменившегося блока. Но тут мы столкнулись с особенностью хранения в TAR-файлах, что нам нужно сначала указать размер TAR-файлов, в которых мы храним нашу дельта-копию, а потом начать его записывать. Хотелось сделать реализацию технологии с минимумом потребляемой оперативной памяти, поэтому нам пришлось использовать третий формат, в котором мы сначала полностью читаем каждый data-файл, ищем изменившиеся страницы данных, сначала складируем в TAR-файл номера изменившихся блоков, и только потом сами изменившиеся блоки.

Вот эта фича еще не реализована. Я присматриваюсь к ней или ищу человека, который хочет сделать pull request в WAL-G. При восстановлении из дельта-копии, БД переживает каждую из реинкарнаций БД на каждый шаг дельта-бэкапа. Иногда в середине жизни какие-то файлы удаляются. При этом нам можно было бы не переживать их состояние, если они все равно будут удалены, а потом пересозданы из дельта-копии. Кажется, что это не слишком сложная фича, так что если вам интересно пописать что-нибудь на Go, присмотритесь к этой фиче.

График про использование сети, CPU и диска. У WAL-E, как мы видим, тут бэкап еще не закончился, начался в час ночи по Москве, и не закончился на последний отчет, который мы видим. График WAL-G закончился, быстрее работает и значительно равномернее в плане потребления ресурсов.
Самое интересное — график потребления ресурсов при дельта-копии. Мы видим, что все ресурсы стали практически нулевыми. Нагрузка на ЦП — это практически стандартная нагрузка на БД, ночью какие-то запросики выполняются. Мы видим большой зубец чтения. Им я тоже занимаюсь, тоже хотел бы pull request или сам это сделаю летом. Суть в том, что нам приходится все равно считать наши данные, чтобы найти, что в них изменилось. Этого чтения можно было бы избежать.

В WAL-G есть удаление, когда мы указываем количество бэкапов либо дату, от которой нам нужно хранить все WAL-ы и все base-бэкапы. И WAL-G уже занимается решением вопроса, какие WAL-ы и base-бэкапы нужны. Пока у нас нет фичи, которая удалила бы все. В WAL-E она есть, тоже повод для pull request. Интересная команда DELETE EVERYTHING у нас пока не реализована.

Есть листинг бэкапов.
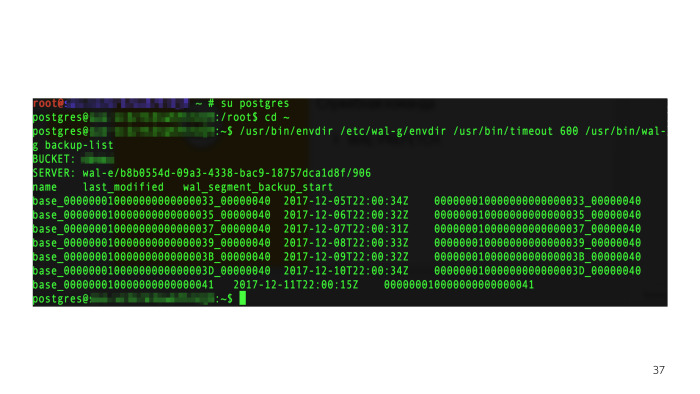
Мы устанавливаем переменное окружение, необходимое в WAL-G для функционирования, и вызываем консольную утилиту WAL-G. Отображаются бэкапы, которые нам нужно просмотреть.

В WAL-G реализовано довольно много технологий по распараллеливанию бэкапов и вообще различных операций. Например, такая технология используется для отправки «валов» в архив. Как только PostgreSQL вызывает archive_command для отправки одного файла, WAL-G смотрит, есть ли еще файлы рядом готовые.
Вообще, это не очень документированная особенность, она очень стабильна в последних версиях PostgreSQL, многие технологии ее используют. Мы смотрим, есть ли в archive status готовые WAL-файлы, и их тоже отправляем вместе с тем, кторый просила отправить в архив база. А когда PostgreSQL попросит их отправить, мы уже их отправили, у нас все готово. Это значительно ускоряет отправку WAL-а на нагруженных базах и позволяет делать ее не однопоточной. В норме PostgreSQL готовит один файл, потом ждет, когда он отправится, готовит следующий. Нам удается этой последовательной работы избежать.

При WAL-FETCH, когда кластер восстанавливается, мы также пытаемся скачать следующие N файлов, которые понадобятся, и стараемся сбалансировать паузы между стартами префетчей новых WAL-файлов так, чтобы максимально утилизировать все ресурсы, которые у нас есть: либо упереться в сеть, либо упереться в диск в редких случаях.

Это все настраивается переменными окружения.

Также есть параллелизм снятия копии. Пока эта фича не присутствует в различных релизах — А. Б. выпущено в релизе 0.1.10 в июне 2018-го, — поскольку параллелизм чтения с диска позволяет вам гарантированно упереться либо в сеть, либо в диск. Это не очень хорошо при нагруженной БД. У WAL-E была фича, позволяющая делать троттлинг. Пока что у нас этого нет. Нужно ограничить скорость снятия бэкапа, чтобы база могла нормально жить своей жизнью и обслуживать нагрузку.
Самая главная наша фича — не совсем про технологии.
Два года назад Женя Дюков реализовал технологию дельта-бэкапов для Barman, ее до сих пор не помержили, сообщество до сих пор ее обсуждает.
Почти год назад Женя починил баг WAL-E, и полгода мы его отправляли (ссылка на GitHub — прим. ред.). Довольно часто в опенсорсных решениях встречается проблема с тем, что они не очень хорошо мэйнтейнятся.

С WAL-G все довольно просто: мы его используем и я его мэйнтейню. Если нам или вам что-то нужно, вы просто сообщайте, что у вас есть проблема. Мы постараемся ее решить.
Стандартный запрос от сообщества простой — «давайте больше всего».
Больше криптографии, больше платформ. Может, не только PostgreSQL, а MySQL еще бэкапить или что-то еще? Мне видятся немного другие вещи.

В первую очередь, сейчас при отправке «вала» мы могли бы понимать, какие блоки БД изменились, сканировать эти WAL-файлы и сохранять информацию о том, что изменялось.
И когда придет cron с очередным дельта-бэкапом, мы могли бы не сканировать всю БД, тот зубец дискового чтения спилить и просто знать, какие страницы нам нужно утащить в облако.
Мы пытались использовать технологию page-track. Она на уровне ядра БД реализует отслеживание изменений страниц. Бэкап снимается очень быстро. Главная проблема с PTRACK — он очень инвазивен. Он содержит очень много изменений в ядре PostgreSQL в очень чувствительных местах, поэтому вряд ли он будет скоро принят.
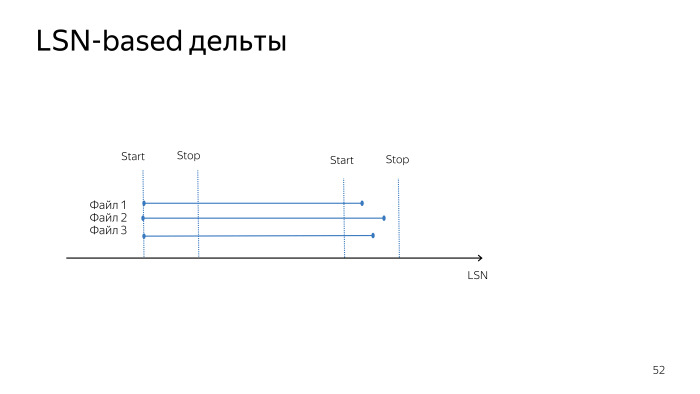
Кроме того, его дельты немного отличаются от тех дельт, которые сейчас у нас есть. При снятии LSN-based-дельты мы снимаем все изменения в дельта-файле, которые произошли от предыдущего старта до текущего времени.

В случае с PTRACK мы получаем изменения в дельта-файле, начиная с предыдущего получения дельты. У нас нет точного времени дельты до старта бэкапа, до начала снятия изменений. Это не главная проблема PTRACK, в целом он хорошо работает, но пока его сложно принять.

PTRACK не позволяет сделать снятие дельты в режиме LATEST_FULL, потому что он хранит карту изменившихся блоков с предыдущего снятия этой карты. У Oracle интересно сделана технология, там 8 карт предыдущих, которые они сохраняют на всякий случай. Может, мы могли бы сделать что-то подобное, но пока работаем не в этом направлении.
В сентябре прошлого года я пытался предложить сообществу технологию, основанную на том, что мы в ядро добавляем только нужные нам хуки, а отслеживание изменившихся страниц реализуем в extension, чтобы патч по отслеживанию страниц был не слишком инвазивным. После обсуждения этой технологии мы пришли к тому, что нам нужно несколько прототипов, и мы добавим хуки, когда будут прототипы. Может быть, посмотрим, как они будут работать. Сейчас я работаю над прототипами этих расширений, которые могли бы использовать хуки в ядре для отслеживания изменений в БД.
В сообществе есть выражение, что каждый постгресист должен иметь свой бэкап-тул. Это плохо. Каждый делает свою вещь, которая делает критически важный таск. Должна быть одна штука, у которой все будет в коробке, все будет идеально в идеальном мире.
Что хотелось бы увидеть в коробке в basebackup? Нам бы хотелось увидеть, наверное, архивацию в облако. И дельта-копии.

Еще хотелось бы сжатие, параллелизм, шифрование, троттлинг, листинг бэкапов, верификацию, валидацию бэкапов… Много всего. Мы понимаем, что если все это сейчас предлагать сообществу, получится несколько десятков патчей, которые довольно сложно обсудить и провести через commitfest. Поэтому сейчас мы все еще используем отдельную тулзу, но есть желание уделять сообществу время и технологии, чтобы PostgreSQL становился лучше.
— Привет! Я разработчик в Яндексе из Екатеринбурга. К технологиям быстрого бэкапа. Бэкапом мы занимаемся довольно давно, были доклады Владимира Бородина и Евгения Дюкова о том, как мы исследуем и что разрабатываем, чтобы хранить данные безопасно, надежно, удобно и эффективно. Эта серия посвящена последним наработкам в указанной области.
Поговорим про бэкапы в PostgreSQL в принципе. Стандартная утилита для переноса данных — pg_dump — определяется как консольная утилита, создающая файл с логическим представлением ваших данных.
То, что это логическая копия, довольно удобно. Вы всегда можете перенести данные между различными версиями, можете нарезать свою базу кусочками, и это стандартный инструмент, который, например, поставляется в коробке с утилитой администрирования PgAdmin.

Про pg_dump надо в первую очередь знать то, что это инструмент разработчика.
Это не инструмент эксплуатации базы данных. pg_dump не предназначен для работы с высоконагруженной БД.

Предположим, у вас все серьезно и вы хотите применить технологию «Восстановление на точку времени», которая использует API PostgreSQL в части работы с онлайн-бэкапами. Вы вызываете функцию pg_start_backup и делаете файловую копию БД. Фактически pg_start_backup заставляет БД сделать CHECKPOINT; и включить запись full page writes в журнал опережающей записи. Та копия БД, которую вы делаете, когда вызываете API, не является консистентной копией данных. Вам также нужен журнал опережающей записи, чтобы иметь возможность восстановить вашу БД на время вызова pg_stop_backup, то есть на время окончания снятия бэкапа.

Ссылка со слайда
После времени окончания снятия бэкапа и при наличии журнала опережающей записи вы можете восстановиться на требуемую точку времени жизни вашей БД.
В коробке поставляется утилита pg_basebackup, которая реализует всю эту технологию в каноничном виде и позволяет вам сделать бэкап с минимально необходимой функциональностью.
Если у вас все еще серьезнее, чем раньше, то вы используете какой-то софт для управления бэкапами, и обычно это Barman.
У него есть несколько плюсов. Самый главный плюс — это очень распространенная утилита, у нее огромное комьюнити, огромное количество вопросов на Stack Overflow.

Вам достаточно поднять один бэкапный сервер, и бэкапить туда все свои PostgreSQL. Это очень удобно — до тех пор пока вам хватает одного сервера резервных копий.
Как только у вас появляется много серверов резервного копирования, вам надо отслеживать, не переполнился ли какой-то из них. В случае выхода из строя какого-то бэкапного сервера вам нужно понять, какие из ваших БД сейчас в опасности. Вам нужно понять в принципе, куда копировать новый кластер БД при его создании.
Есть значительно более простая утилита для снятия резервной копии, которая называется WAL-E.

WAL-E выполняет четыре главных команды. Команда WAL-PUSH отправляет один WAL-файл в облако, а WAL-FETCH забирает один WAL-файл при необходимости восстановления выполнения restore_command.
Также есть BACKUP-PUSH (реализует снятие API резервной копии) и BACKUP-FETCH (забирает все данные из облака). Данные хранятся в облаке, поэтому мониторить ничего не нужно, это уже проблема облачного сервиса, как обеспечить доступность ваших данных, когда они вам нужны. Наверное, это главное достоинство WAL-E.

Там довольно много функциональности. Есть листинг бэкапов, есть retention policy, то есть мы хотим хранить бэкапы за последние семь дней, например, или последние пять бэкапов, что-нибудь такое. И WAL-E умеет делать резервные копии в огромное множество облачных сервисов: S3, Azure, Google, может локальную файловую систему назвать облаком.

У него есть несколько свойств. Во-первых, он написан на Python и активно использует конвейер Unix, отчасти из-за этого у него есть зависимости и он не очень производительный. Это нормально, потому что WAL-E фокусирован на простоте использования, простоте настройки, чтобы нельзя было сделать ошибку, когда вы делаете план резервного копирования. И это очень хорошая идея.
В WAL-E написано очень много фич, и куда его развивать дальше, авторам было не очень понятно. Пришла идея, что нужна новая тулза.

Ссылка со слайда
Главная ее фича в том, что она переписана на Go, у нее почти нет внешних зависимостей, если вы не используете внешнее шифрование, и она значительно более производительная.

Ссылка со слайда
WAL-G изначально был создан двумя авторами из Citus Data, и главное достоинство изображено на этой гистограмме — скорость отправки «валов». Мы видим, что WAL-E бывает быстрой, бывает всяко, бывает большой столбик около нуля.

Ссылка со слайда
У WAL-G достаточно стабильная пропускная способность. На тестах в Citus Data он показал, что стабильно отправляет порядка 800 Мб/с «валов».
Кроме того в WAL-G я, например, писал фичу, которая реализует бэкап с реплики. Вам не нужно нагружать ваш мастер БД читающей нагрузкой, вы можете снять резервную копию с реплики.

Ссылка со слайда
Но есть одна маленькая проблема. В момент начала снятия резервной копии, вы должны назвать как-то резервную копию. В название попадает таймлайн, который будет изменен в случае необходимости промоута реплики. Если в цепочке реплик перед той репликой, с которой вы делаете резервную копию, произойдет failover, вы запромоутите какую-то из реплик, таймлайн будет изменен. WAL-G понимает, что эта ситуация неконсистентная, потому что имея название на старом таймлайне, название вам обещает, что вы можете продолжить развитие истории БД в любом существовавшем направлении. А это не так. В одном из направлений вы уже поехали, вы не можете задним вагоном перескочить на другой таймлайн. Поэтому WAL-G понимает эту ситуацию и не загружает фишишный JSON файл в облако. Вы создаете физически копию. Но требуется вмешательство администратора, чтобы этой копией можно было воспользоваться.

У нас в WAL-G реализованы дельта-копии, этой разработкой тоже я занимался. Это позволяет снимать меньше данных в очередном base-бэкапе, вы не делаете копию тех страниц данных, которые не менялись с предыдущего бэкапа.

При настройке WAL-G вы указываете количество шагов на которые максимально отстоит от base-бэкапа дельта-бэкап, и указываете политику дельта-копии. Либо вы делаете копию с последней существующей дельты, либо делаете дельту от изначального полного бэкапа. Это нужно на тот случай, когда у вас в базе данных всегда меняется одна и та же составляющая БД, одни и те же данные постоянно изменяются.
Зачем в принципе нужны дельта-копии БД? По идее, у вас есть WAL, вы и так можете накатиться на любую точку.
На нагруженном сервере проигрывание WAL пяти физических секунд прошлого может занять четыре физические секунды настоящего. Если вас просят накатить WAL за четыре дня, это значит, что возможно, человек, который просит это сделать, должен еще три дня подождать. Не всегда приемлемая ситуация.
Вам нужны base-бэкапы на каждый день, но тем не менее, вы не можете себе хранить там 7 или 14 полных копий вашей БД, даже учитывая, что WAL-G заархивирует их, все равно это будут достаточно большие объемы. И в этом случае помогают дельта-копии.

При разработке дельта-копий обсуждалось несколько возможных форматов data файлов. В первую очередь предлагался формат, когда мы не изменяющуюся страницу просто зануляем. Но мы пришли к тому, что это не очень эффективный способ, нули потом эффективно сжимаются, но мы от этого способа хранения потом отказались, потому что его сложно отлаживать в случае внештатных ситуаций.

Следующая технология, которая рассматривалась, это хранение сначала номера блока и затем изменившегося блока. Но тут мы столкнулись с особенностью хранения в TAR-файлах, что нам нужно сначала указать размер TAR-файлов, в которых мы храним нашу дельта-копию, а потом начать его записывать. Хотелось сделать реализацию технологии с минимумом потребляемой оперативной памяти, поэтому нам пришлось использовать третий формат, в котором мы сначала полностью читаем каждый data-файл, ищем изменившиеся страницы данных, сначала складируем в TAR-файл номера изменившихся блоков, и только потом сами изменившиеся блоки.


Вот эта фича еще не реализована. Я присматриваюсь к ней или ищу человека, который хочет сделать pull request в WAL-G. При восстановлении из дельта-копии, БД переживает каждую из реинкарнаций БД на каждый шаг дельта-бэкапа. Иногда в середине жизни какие-то файлы удаляются. При этом нам можно было бы не переживать их состояние, если они все равно будут удалены, а потом пересозданы из дельта-копии. Кажется, что это не слишком сложная фича, так что если вам интересно пописать что-нибудь на Go, присмотритесь к этой фиче.

График про использование сети, CPU и диска. У WAL-E, как мы видим, тут бэкап еще не закончился, начался в час ночи по Москве, и не закончился на последний отчет, который мы видим. График WAL-G закончился, быстрее работает и значительно равномернее в плане потребления ресурсов.
Самое интересное — график потребления ресурсов при дельта-копии. Мы видим, что все ресурсы стали практически нулевыми. Нагрузка на ЦП — это практически стандартная нагрузка на БД, ночью какие-то запросики выполняются. Мы видим большой зубец чтения. Им я тоже занимаюсь, тоже хотел бы pull request или сам это сделаю летом. Суть в том, что нам приходится все равно считать наши данные, чтобы найти, что в них изменилось. Этого чтения можно было бы избежать.

В WAL-G есть удаление, когда мы указываем количество бэкапов либо дату, от которой нам нужно хранить все WAL-ы и все base-бэкапы. И WAL-G уже занимается решением вопроса, какие WAL-ы и base-бэкапы нужны. Пока у нас нет фичи, которая удалила бы все. В WAL-E она есть, тоже повод для pull request. Интересная команда DELETE EVERYTHING у нас пока не реализована.

Есть листинг бэкапов.

Мы устанавливаем переменное окружение, необходимое в WAL-G для функционирования, и вызываем консольную утилиту WAL-G. Отображаются бэкапы, которые нам нужно просмотреть.

В WAL-G реализовано довольно много технологий по распараллеливанию бэкапов и вообще различных операций. Например, такая технология используется для отправки «валов» в архив. Как только PostgreSQL вызывает archive_command для отправки одного файла, WAL-G смотрит, есть ли еще файлы рядом готовые.
Вообще, это не очень документированная особенность, она очень стабильна в последних версиях PostgreSQL, многие технологии ее используют. Мы смотрим, есть ли в archive status готовые WAL-файлы, и их тоже отправляем вместе с тем, кторый просила отправить в архив база. А когда PostgreSQL попросит их отправить, мы уже их отправили, у нас все готово. Это значительно ускоряет отправку WAL-а на нагруженных базах и позволяет делать ее не однопоточной. В норме PostgreSQL готовит один файл, потом ждет, когда он отправится, готовит следующий. Нам удается этой последовательной работы избежать.

При WAL-FETCH, когда кластер восстанавливается, мы также пытаемся скачать следующие N файлов, которые понадобятся, и стараемся сбалансировать паузы между стартами префетчей новых WAL-файлов так, чтобы максимально утилизировать все ресурсы, которые у нас есть: либо упереться в сеть, либо упереться в диск в редких случаях.

Это все настраивается переменными окружения.

Также есть параллелизм снятия копии. Пока эта фича не присутствует в различных релизах — А. Б. выпущено в релизе 0.1.10 в июне 2018-го, — поскольку параллелизм чтения с диска позволяет вам гарантированно упереться либо в сеть, либо в диск. Это не очень хорошо при нагруженной БД. У WAL-E была фича, позволяющая делать троттлинг. Пока что у нас этого нет. Нужно ограничить скорость снятия бэкапа, чтобы база могла нормально жить своей жизнью и обслуживать нагрузку.
Самая главная наша фича — не совсем про технологии.
Два года назад Женя Дюков реализовал технологию дельта-бэкапов для Barman, ее до сих пор не помержили, сообщество до сих пор ее обсуждает.
Почти год назад Женя починил баг WAL-E, и полгода мы его отправляли (ссылка на GitHub — прим. ред.). Довольно часто в опенсорсных решениях встречается проблема с тем, что они не очень хорошо мэйнтейнятся.

С WAL-G все довольно просто: мы его используем и я его мэйнтейню. Если нам или вам что-то нужно, вы просто сообщайте, что у вас есть проблема. Мы постараемся ее решить.
Стандартный запрос от сообщества простой — «давайте больше всего».
Больше криптографии, больше платформ. Может, не только PostgreSQL, а MySQL еще бэкапить или что-то еще? Мне видятся немного другие вещи.

В первую очередь, сейчас при отправке «вала» мы могли бы понимать, какие блоки БД изменились, сканировать эти WAL-файлы и сохранять информацию о том, что изменялось.
И когда придет cron с очередным дельта-бэкапом, мы могли бы не сканировать всю БД, тот зубец дискового чтения спилить и просто знать, какие страницы нам нужно утащить в облако.
Мы пытались использовать технологию page-track. Она на уровне ядра БД реализует отслеживание изменений страниц. Бэкап снимается очень быстро. Главная проблема с PTRACK — он очень инвазивен. Он содержит очень много изменений в ядре PostgreSQL в очень чувствительных местах, поэтому вряд ли он будет скоро принят.

Кроме того, его дельты немного отличаются от тех дельт, которые сейчас у нас есть. При снятии LSN-based-дельты мы снимаем все изменения в дельта-файле, которые произошли от предыдущего старта до текущего времени.

В случае с PTRACK мы получаем изменения в дельта-файле, начиная с предыдущего получения дельты. У нас нет точного времени дельты до старта бэкапа, до начала снятия изменений. Это не главная проблема PTRACK, в целом он хорошо работает, но пока его сложно принять.

PTRACK не позволяет сделать снятие дельты в режиме LATEST_FULL, потому что он хранит карту изменившихся блоков с предыдущего снятия этой карты. У Oracle интересно сделана технология, там 8 карт предыдущих, которые они сохраняют на всякий случай. Может, мы могли бы сделать что-то подобное, но пока работаем не в этом направлении.

Ссылка со слайда
В сентябре прошлого года я пытался предложить сообществу технологию, основанную на том, что мы в ядро добавляем только нужные нам хуки, а отслеживание изменившихся страниц реализуем в extension, чтобы патч по отслеживанию страниц был не слишком инвазивным. После обсуждения этой технологии мы пришли к тому, что нам нужно несколько прототипов, и мы добавим хуки, когда будут прототипы. Может быть, посмотрим, как они будут работать. Сейчас я работаю над прототипами этих расширений, которые могли бы использовать хуки в ядре для отслеживания изменений в БД.
В сообществе есть выражение, что каждый постгресист должен иметь свой бэкап-тул. Это плохо. Каждый делает свою вещь, которая делает критически важный таск. Должна быть одна штука, у которой все будет в коробке, все будет идеально в идеальном мире.
Что хотелось бы увидеть в коробке в basebackup? Нам бы хотелось увидеть, наверное, архивацию в облако. И дельта-копии.

Еще хотелось бы сжатие, параллелизм, шифрование, троттлинг, листинг бэкапов, верификацию, валидацию бэкапов… Много всего. Мы понимаем, что если все это сейчас предлагать сообществу, получится несколько десятков патчей, которые довольно сложно обсудить и провести через commitfest. Поэтому сейчас мы все еще используем отдельную тулзу, но есть желание уделять сообществу время и технологии, чтобы PostgreSQL становился лучше.
