
Иногда люди обращаются к Яндексу, чтобы найти фильм, название которого вылетело из головы. Описывают сюжет, запомнившиеся сцены, яркие детали: например, [как называется фильм там где мужик выбирает красная или синяя таблетка]. Мы решили изучить описания забытых фильмов и выяснить, что сильнее всего запоминается людям в кино.
Сегодня мы не только поделимся ссылкой на наше исследование, но и вкратце расскажем о том, как развивался семантический поиск Яндекса. Вы узнаете, какие технологии помогают поиску находить ответ даже тогда, когда точно сформулировать запрос просто не получается.
А ещё мы добавили слайдеры-загадки с примерами реальных запросов людей — почувствуйте себя поисковой системой и попробуйте угадать ответ.
Все поисковые системы начинались с поиска слов. Яндекс уже на старте умел учитывать морфологию русского языка, но это был всё тот же поиск слов из запроса на страницах в сети. Мы хранили списки всех известных страниц для каждого слова. Если запрос содержал фразу, то достаточно было пересечь списки слов — вот вам ответ. Отлично работало в те времена, когда сайтов было мало, а вопрос ранжирования ещё не стоял так остро.
Рунет развивался, сайтов становилось всё больше. К фактору пересечения слов добавились ещё два. С одной стороны, нам помогли сами пользователи. Мы стали учитывать, какие сайты и по каким запросам они выбирают. Нет точного соответствия слов, но сайт решает проблему человека? Это полезный сигнал. С другой стороны, на помощь пришли ссылки между сайтами, которые помогли оценить значимость страниц.
Три фактора — это очень мало. Особенно когда их пытаются накрутить зачастую очень талантливые поисковые оптимизаторы. Но переварить больше вручную было сложно. И здесь началась эпоха машинного обучения. В 2009 году мы внедряем Матрикснет на основе градиентного бустинга (позднее эта технология легла в основу более совершенной опенсорсной библиотеки CatBoost).
С тех пор факторов становилось всё больше, потому что нам уже не приходилось искать взаимосвязи между ними вручную. За нас это делала машина.
Для рассказа обо всех последующих изменениях в Поиске будет мало не то что поста, но и книги, поэтому попробуем сфокусироваться на наиболее показательных.
Ранжирование — это уже давно не только сравнение слов запроса и страницы. Два примера.
Ещё в 2014-м мы внедрили технологию аннотации документа характерными запросами. Допустим, что в прошлом был запрос [сериал из бразилии про мясного короля], для которого хороший ответ уже известен. Затем другой пользователь вводит запрос [бразильский сериал в котором были мясной король и молочный король], для которого машина ещё не знает ответ. Но у этих запросов много общих слов. Это сигнал, что найденная по первому запросу страница может быть релевантна и по второму.
Другой пример. Возьмём запросы [бразильский сериал в котором были мясной король и молочный король] и [сериал роковое наследство]. Из общего у них только одно слово — «сериал», а этого мало для явного сопоставления запросов. На этот случай мы начали учитывать историю поиска. Если у двух непохожих запросов пользуются спросом одни и те же сайты в выдаче, то можно предположить, что запросы взаимозаменяемы. Это полезно, потому что теперь мы будем использовать для поиска тексты обоих запросов, чтобы найти больше полезных страниц. Но это работает только для повторяющихся запросов, когда уже есть хоть какая-то статистика. Что делать с новыми запросами?
Недостаток статистических данных можно компенсировать анализом контента. А в анализе однородных данных (текст, голос, изображения) лучше всего себя показывают нейронные сети. В 2016-м мы впервые рассказали сообществу Хабра о технологии «Палех», которая стала отправной точкой для более масштабного применения нейросетей в Поиске.
Мы начали обучать нейросеть сравнивать смысловую (семантическую) близость текстов запроса и заголовка страницы. Два текста представляются в виде векторов в многомерном пространстве так, чтобы косинус угла между ними хорошо предсказывал вероятность выбора страницы человеком, а значит, и смысловую близость. Это позволяет оценить близость смыслов даже тех текстов, в которых нет пересечения слов.
Таким же способом мы стали сравнивать тексты запросов, чтобы выявлять между ними связи. Реальный пример из-под капота поисковой системы: для запроса [американский сериал про то как варят метамфетамин] именно нейронная сеть находит в качестве похожих по смыслу фразы [во все тяжкие] и [breaking bad].
Запросы и заголовки — это уже хорошо, но мы не оставляли надежду применить нейросети и на полном тексте страниц. Кроме того, когда мы получаем пользовательский запрос, то среди миллионов страниц индекса начинаем поэтапно выбирать лучшие страницы, но в «Палехе» мы использовали нейросетевые модели только на самых поздних этапах ранжирования (L3) — приблизительно к 150 лучшим документам. Это может привести к потере хороших ответов.
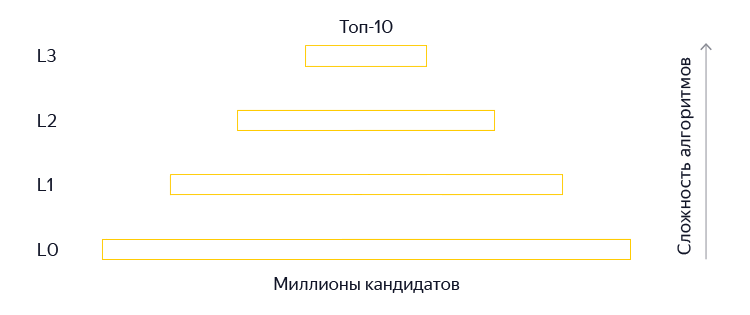
Причина предсказуема — ограниченность ресурсов и высокие требования к скорости ответа. Жёсткие ограничения вычислений связаны с простым фактом: нельзя заставлять пользователя ждать. Но затем мы кое-что придумали.
В 2017-м мы представили поисковое обновление «Королёв», которое включало в себя не только расширенное применение нейросетей, но и серьёзную работу над архитектурой для экономии ресурсов. Более подробно, со схемами слоёв и прочими деталями мы уже рассказывали в другом посте на Хабре, но сейчас напомним главное.
Вместо того чтобы брать заголовок документа и во время исполнения запроса вычислять его семантический вектор, можно предвычислить этот вектор и сохранить его в поисковой базе. Другими словами, мы можем проделать существенную часть работы заранее. Разумеется, при этом нам потребовалось больше места для хранения векторов, но так мы сэкономили процессорное время. Но и это ещё не всё.
Мы построили дополнительный индекс. В его основе лежит гипотеза: если к запросу из нескольких слов взять достаточно большой список из самых релевантных документов по каждому слову или словосочетанию, то среди них найдутся документы, релевантные одновременно всем словам. На практике это значит вот что. Для всех слов и популярных пар слов формируется дополнительный индекс со списком страниц и их предварительной релевантностью запросу. То есть мы переносим часть работы из этапа L0 на этап индексирования и опять же экономим.
В итоге изменение архитектуры и перераспределение нагрузок позволило нам применить нейросети не только на стадии L3, но и для L2 и L1. Более того, возможность сформировать вектор заранее и с менее жёсткими требованиями к производительности позволила нам использовать не только заголовок страницы, но и её текст.
Дальше — больше. Со временем мы стали применять нейросети на самом раннем этапе ранжирования. Мы учим нейросети выявлять неявные закономерности в порядке слов и их взаимном расположении. И даже выявлять смысловую схожесть текстов на разных языках. Каждое из этих направлений тянет на отдельную статью, и мы постараемся вернуться с ними в ближайшем будущем.
Сегодня мы ещё раз напомнили о том, как поисковые системы учатся находить ответ в условиях размытости запроса и недостатка информации. Поиск фильмов по их описанию — это не только частный случай таких запросов, но и отличная тема для исследования. Из него вы узнаете: что сильнее всего запоминается людям в кино, с чем ассоциируются разные жанры и кинематографы разных стран, какие сюжетные ходы производят особенное впечатление.
Сегодня мы не только поделимся ссылкой на наше исследование, но и вкратце расскажем о том, как развивался семантический поиск Яндекса. Вы узнаете, какие технологии помогают поиску находить ответ даже тогда, когда точно сформулировать запрос просто не получается.
А ещё мы добавили слайдеры-загадки с примерами реальных запросов людей — почувствуйте себя поисковой системой и попробуйте угадать ответ.
Все поисковые системы начинались с поиска слов. Яндекс уже на старте умел учитывать морфологию русского языка, но это был всё тот же поиск слов из запроса на страницах в сети. Мы хранили списки всех известных страниц для каждого слова. Если запрос содержал фразу, то достаточно было пересечь списки слов — вот вам ответ. Отлично работало в те времена, когда сайтов было мало, а вопрос ранжирования ещё не стоял так остро.
Рунет развивался, сайтов становилось всё больше. К фактору пересечения слов добавились ещё два. С одной стороны, нам помогли сами пользователи. Мы стали учитывать, какие сайты и по каким запросам они выбирают. Нет точного соответствия слов, но сайт решает проблему человека? Это полезный сигнал. С другой стороны, на помощь пришли ссылки между сайтами, которые помогли оценить значимость страниц.
Три фактора — это очень мало. Особенно когда их пытаются накрутить зачастую очень талантливые поисковые оптимизаторы. Но переварить больше вручную было сложно. И здесь началась эпоха машинного обучения. В 2009 году мы внедряем Матрикснет на основе градиентного бустинга (позднее эта технология легла в основу более совершенной опенсорсной библиотеки CatBoost).
С тех пор факторов становилось всё больше, потому что нам уже не приходилось искать взаимосвязи между ними вручную. За нас это делала машина.
Для рассказа обо всех последующих изменениях в Поиске будет мало не то что поста, но и книги, поэтому попробуем сфокусироваться на наиболее показательных.
Ранжирование — это уже давно не только сравнение слов запроса и страницы. Два примера.
Ещё в 2014-м мы внедрили технологию аннотации документа характерными запросами. Допустим, что в прошлом был запрос [сериал из бразилии про мясного короля], для которого хороший ответ уже известен. Затем другой пользователь вводит запрос [бразильский сериал в котором были мясной король и молочный король], для которого машина ещё не знает ответ. Но у этих запросов много общих слов. Это сигнал, что найденная по первому запросу страница может быть релевантна и по второму.
Другой пример. Возьмём запросы [бразильский сериал в котором были мясной король и молочный король] и [сериал роковое наследство]. Из общего у них только одно слово — «сериал», а этого мало для явного сопоставления запросов. На этот случай мы начали учитывать историю поиска. Если у двух непохожих запросов пользуются спросом одни и те же сайты в выдаче, то можно предположить, что запросы взаимозаменяемы. Это полезно, потому что теперь мы будем использовать для поиска тексты обоих запросов, чтобы найти больше полезных страниц. Но это работает только для повторяющихся запросов, когда уже есть хоть какая-то статистика. Что делать с новыми запросами?
Недостаток статистических данных можно компенсировать анализом контента. А в анализе однородных данных (текст, голос, изображения) лучше всего себя показывают нейронные сети. В 2016-м мы впервые рассказали сообществу Хабра о технологии «Палех», которая стала отправной точкой для более масштабного применения нейросетей в Поиске.
Мы начали обучать нейросеть сравнивать смысловую (семантическую) близость текстов запроса и заголовка страницы. Два текста представляются в виде векторов в многомерном пространстве так, чтобы косинус угла между ними хорошо предсказывал вероятность выбора страницы человеком, а значит, и смысловую близость. Это позволяет оценить близость смыслов даже тех текстов, в которых нет пересечения слов.
Пример архитектуры слоёв для любопытных
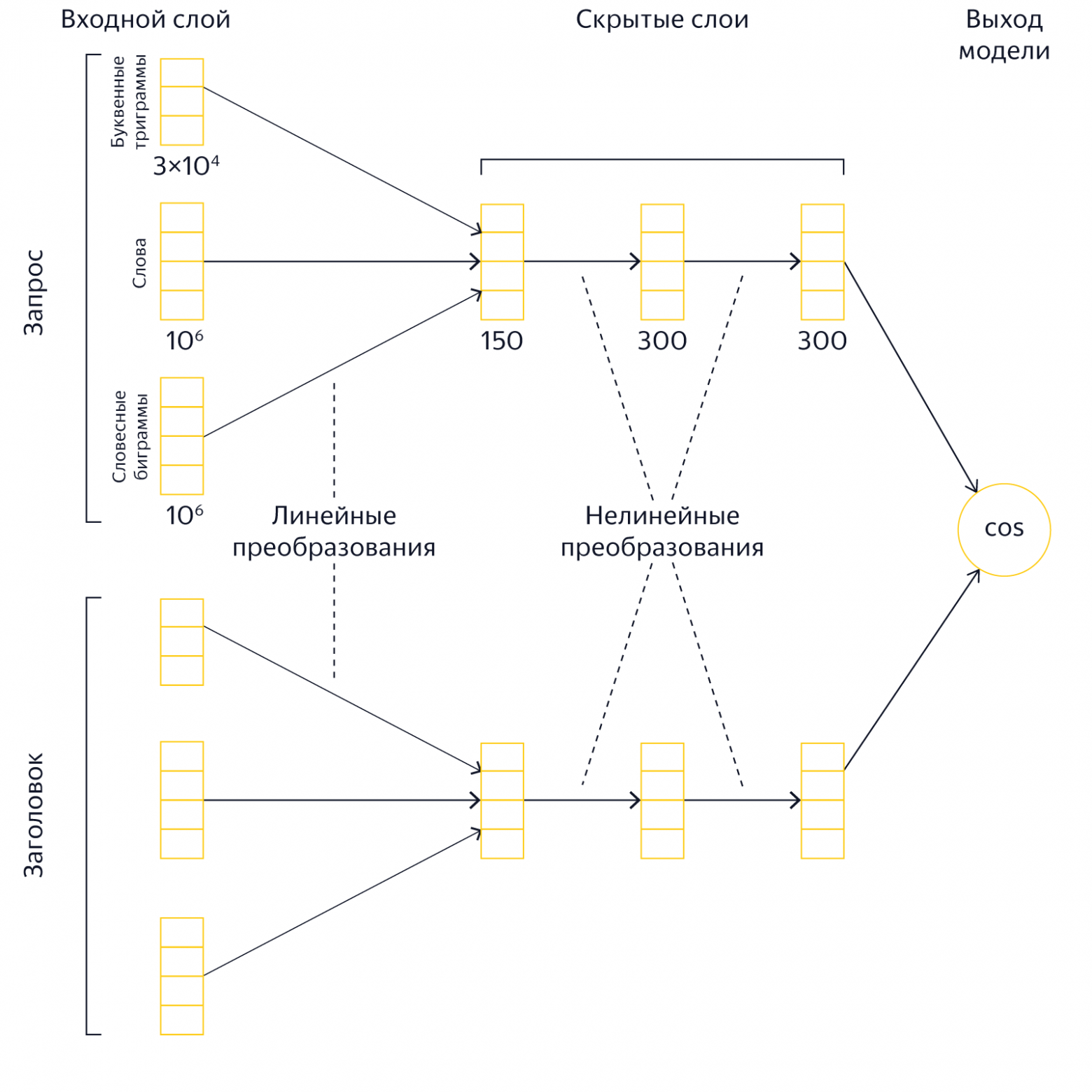
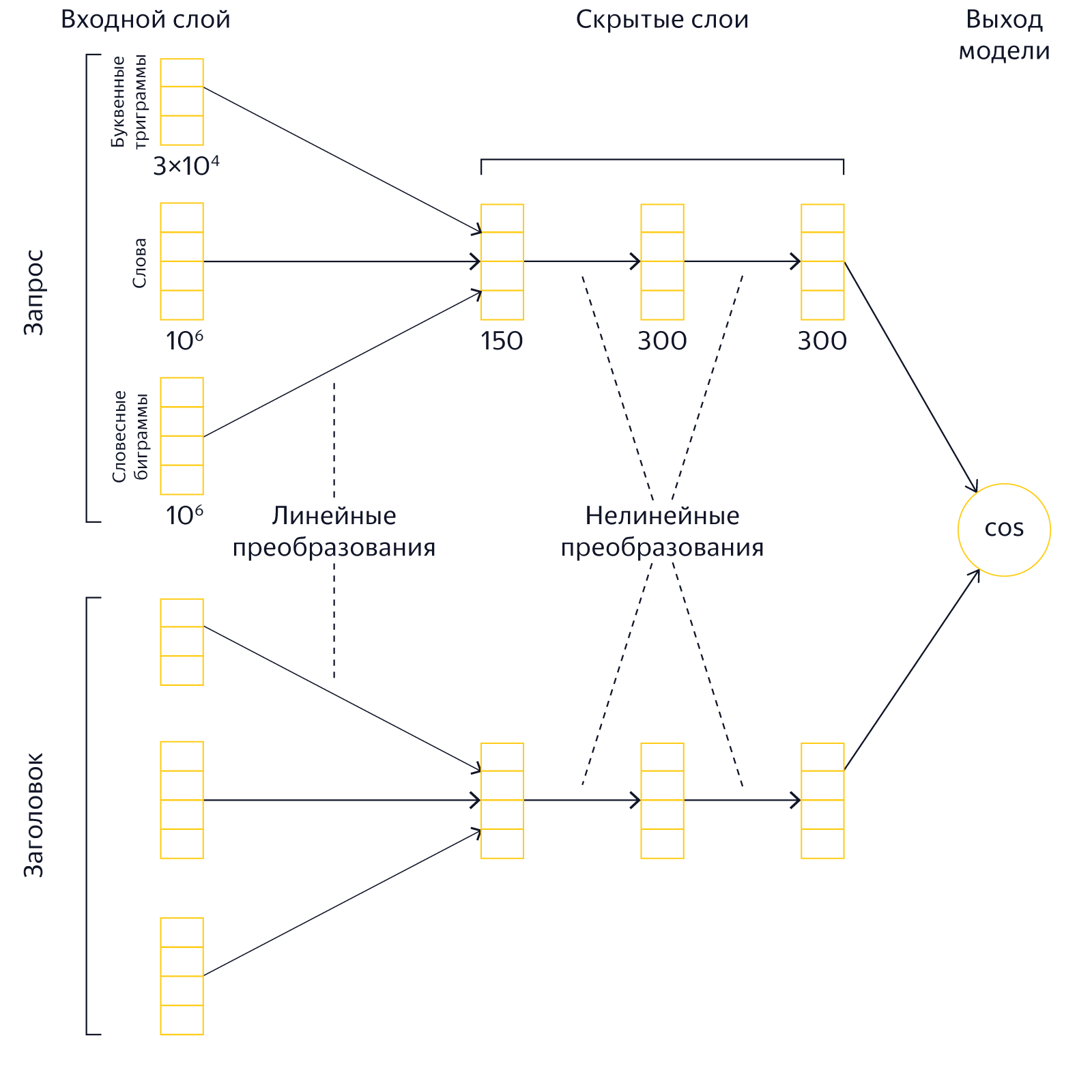
Таким же способом мы стали сравнивать тексты запросов, чтобы выявлять между ними связи. Реальный пример из-под капота поисковой системы: для запроса [американский сериал про то как варят метамфетамин] именно нейронная сеть находит в качестве похожих по смыслу фразы [во все тяжкие] и [breaking bad].
Запросы и заголовки — это уже хорошо, но мы не оставляли надежду применить нейросети и на полном тексте страниц. Кроме того, когда мы получаем пользовательский запрос, то среди миллионов страниц индекса начинаем поэтапно выбирать лучшие страницы, но в «Палехе» мы использовали нейросетевые модели только на самых поздних этапах ранжирования (L3) — приблизительно к 150 лучшим документам. Это может привести к потере хороших ответов.

Причина предсказуема — ограниченность ресурсов и высокие требования к скорости ответа. Жёсткие ограничения вычислений связаны с простым фактом: нельзя заставлять пользователя ждать. Но затем мы кое-что придумали.
В 2017-м мы представили поисковое обновление «Королёв», которое включало в себя не только расширенное применение нейросетей, но и серьёзную работу над архитектурой для экономии ресурсов. Более подробно, со схемами слоёв и прочими деталями мы уже рассказывали в другом посте на Хабре, но сейчас напомним главное.
Вместо того чтобы брать заголовок документа и во время исполнения запроса вычислять его семантический вектор, можно предвычислить этот вектор и сохранить его в поисковой базе. Другими словами, мы можем проделать существенную часть работы заранее. Разумеется, при этом нам потребовалось больше места для хранения векторов, но так мы сэкономили процессорное время. Но и это ещё не всё.
Ещё одна схема для любопытных
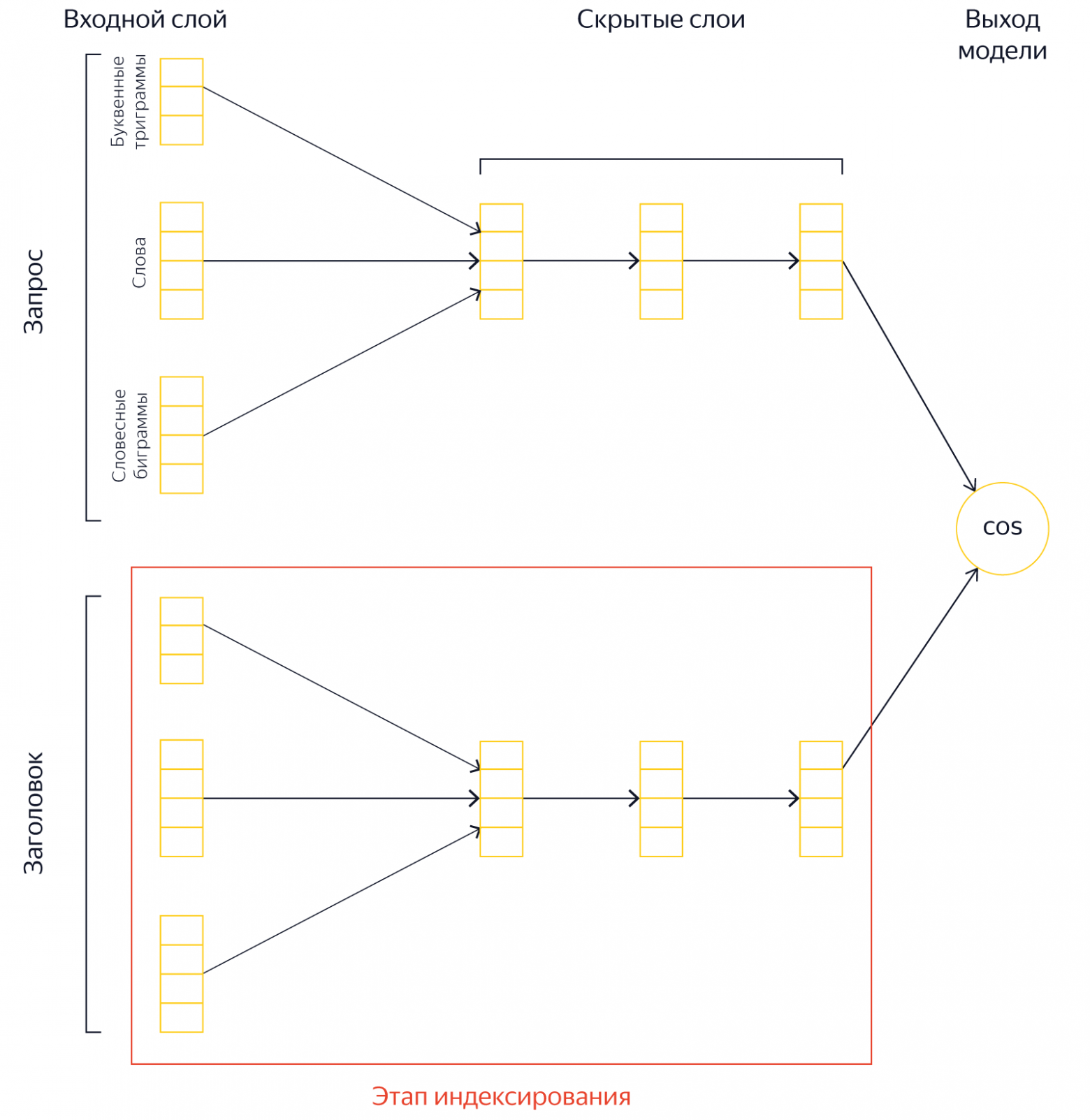

Мы построили дополнительный индекс. В его основе лежит гипотеза: если к запросу из нескольких слов взять достаточно большой список из самых релевантных документов по каждому слову или словосочетанию, то среди них найдутся документы, релевантные одновременно всем словам. На практике это значит вот что. Для всех слов и популярных пар слов формируется дополнительный индекс со списком страниц и их предварительной релевантностью запросу. То есть мы переносим часть работы из этапа L0 на этап индексирования и опять же экономим.
В итоге изменение архитектуры и перераспределение нагрузок позволило нам применить нейросети не только на стадии L3, но и для L2 и L1. Более того, возможность сформировать вектор заранее и с менее жёсткими требованиями к производительности позволила нам использовать не только заголовок страницы, но и её текст.
Дальше — больше. Со временем мы стали применять нейросети на самом раннем этапе ранжирования. Мы учим нейросети выявлять неявные закономерности в порядке слов и их взаимном расположении. И даже выявлять смысловую схожесть текстов на разных языках. Каждое из этих направлений тянет на отдельную статью, и мы постараемся вернуться с ними в ближайшем будущем.
Сегодня мы ещё раз напомнили о том, как поисковые системы учатся находить ответ в условиях размытости запроса и недостатка информации. Поиск фильмов по их описанию — это не только частный случай таких запросов, но и отличная тема для исследования. Из него вы узнаете: что сильнее всего запоминается людям в кино, с чем ассоциируются разные жанры и кинематографы разных стран, какие сюжетные ходы производят особенное впечатление.
