
gRPC — опенсорсный фреймворк для удаленного вызова процедур. В Яндекс.Маркете gRPC используется как более удобная альтернатива REST. Сергей Федосеенков, который руководит службой разработки инструментов для партнеров Маркета, поделился опытом использования gRPC в качестве протокола для построения интеграций между сервисами на Java и C++. Из доклада вы узнаете, как избежать частых проблем, если вы начинаете использовать gRPC после REST, как возвращать ошибки, реализовать трассировку, отлаживать запросы и тестировать вызовы клиентов. В конце есть неофициальная запись доклада.
— Сначала хотелось бы познакомить вас с некоторыми фактами про Яндекс.Маркет, они будут полезны в рамках доклада. Первый факт: мы пишем сервисы на разных языках. Это накладывает требования по наличию клиентов для сервисов.
И если у нас есть сервис на Java, было бы неплохо, чтобы клиент для него был, например, еще и плюсовый или питонячий.

Все сервисы у нас независимые, нет никаких плановых больших релизов всего-всего Маркета. Микросервисы релизятся независимо, и тут нам важна обратная совместимость, и чтобы протокол ее поддерживал.
Третий факт: у нас есть как синхронная, так и асинхронная интеграция. В докладе я в основном буду говорить про синхронную.
Что мы использовали? Сейчас, конечно, основу наших интеграций составляют REST- или похожие на REST сервисы, которые обмениваются XML/JSON поверх протокола HTTP 1.1. Также есть XML-RPC — его мы в основном используем, когда интегрируемся с Python-кодом, то есть в Python есть встроенный XML-RPC-сервер. Его там достаточно удобно разворачивать, и мы его поддерживаем.
Когда-то у нас была CORBA. К нашему счастью, мы от нее отказались. Сейчас в основном REST и XML/JSON поверх HTTP.

У синхронных интеграций есть проблемы с существующим протоколами. Мы с такими проблемами сталкиваемся и пытаемся их полечить при помощи gRPC. Какие это проблемы? Как я уже говорил, хочется иметь клиентов на разных языках. Желательно, чтобы их еще не надо было писать самим. И, вообще, было бы круто, если бы клиент мог быть и синхронным, и асинхронным — в зависимости от целей пользователя сервиса.
Также хотелось бы, чтобы протокол, который мы используем, достаточно хорошо поддерживал обратную совместимость: это очень важно с параллельными независимыми релизами. Все наши релизы обратно совместимые, мы не ломаем обратную связь. Если сломал — это баг, и его просто надо как можно быстрее починить.
Необходим и какой-то стройный подход к обработке ошибок: все, кто делал REST-сервисы, знают — нельзя просто использовать HTTP-статус. Они обычно не позволяют детально описать проблему, приходится вводить какие-то свои статусы, свою детализацию. В REST-сервисах каждый вводит свою реализацию этих ошибок, приходится каждый раз по-разному с этим работать. Это не всегда удобно.
Хотелось бы также иметь управление таймаутами со стороны клиента. Опять же, те, кто работает с HTTP, понимают — если на стороне клиента мы выставили таймаут и он закончился, то клиент перестанет ожидать выполнения запроса, но сервер об этом ничего не узнает и продолжит его выполнять. Более того, посередине бывают различные прокси, которые ставят глобальные таймауты. И клиент может про них просто ничего не знать и конфигурировать их не всегда тривиально.
И наконец, проблема документации. Не всегда понятно, где для REST-ресурсов или для каких-то методов взять документацию, какие параметры они принимают, какое тело можно передать и как эту документацию коммуницировать с потребителями сервиса. Понятно, что есть Swagger, но с ним тоже не все тривиально.
Я хотел бы рассказать про теоретическую часть gRPC — что это такое, какие есть задумки. А дальше уже перейдем к практике.

Вообще, gRPC — это абстрактная спецификация. Она описывает абстрактную RPC (remote procedure call), то есть удаленный вызов процедуры, которая обладает определенными свойствами. Сейчас мы их перечислим. Первое свойство — поддержка как одиночных вызовов, так и стриминга. То есть все сервисы, которые реализовывают эту спеку, поддерживают оба варианта. Следующий пункт — наличие метаданных, то есть чтобы вместе с полезной нагрузкой вы могли бы передать какие-то метаданные — условно, заголовки. И — поддержка отмены запроса и таймаутов из коробки.
Также она предполагает, что описание сообщений и самих сервисов осуществляется через некий Interface Definition Language или IDL. Также спецификация описывает wire-протокол поверх HTTP/2, то есть gRPC предполагает работу только поверх HTTP/2.

Есть типичная реализация gRPC, которая используется в большинстве случаев. У нас она также используется, и сейчас мы ее посмотрим. В качестве IDL используется proto-формат. gRPC плагин для proto-компилятора позволяет из proto-описания получать исходники, сгенерированных сервисов. И существуют runtime-библиотеки на разных языках — Java, С++, Python. В общем, практически все популярные языки поддерживаются, runtime-библиотеки для них существуют. И в качестве сообщений, которыми обмениваются сервисы, используется proto-сообщение, стилизованные сообщения по схеме protobuf.

Хочется немного погрузиться в какие-то определенные фичи. Вот они. Строгая типизация, то есть сообщение proto message, это строго типизированные сообщения. Те, кто с protobuf когда-то работал, знает, что там можно описывать поля в своем сообщении типами. Типы существуют как примитивные, так и строковые, массивы байт. Они могут быть скалярные, могут быть векторные. И, на самом деле, сообщения могут, в качестве поля, содержать другие сообщения, что достаточно удобно, в общем, можно представить любую модель.

Про обратную совместимость. Хочется заметить, что proto IDL это формат, в который заложена обратная совместимость из коробки, то есть он задумывался с заделом на обратную совместимость, и Google выпустил версию proto3, которая по сравнению с proto2 еще больше улучшает обратную совместимость. Там, плюс, есть всякие спецификации, как и что можно менять так, чтобы обратную совместимость сохранять в каких-то нетривиальных кейсах.
Есть возможность значений по умолчанию, можно добавлять новые поля и у потребителя ничего не требуется, собственно, изменять. Все поля в proto3 опциональные и их можно, допустим, удалять, и обращение к удаленному полю не вызывает ошибок на клиенте.

Еще одна фича gRPC — клиент и сервер генерируются при помощи proto-компилятора и gRPC-плагина на основе proto-описания. Есть возможность в моменте, когда пишется код, выбрать какой клиент будет использоваться. То есть выбрать асинхронный или синхронный клиент, в зависимости от того, какого рода код вы пишите. Например, для реактивного кода асинхронный клиент очень подходит. И эта возможность есть для любого языка. То есть один раз вы пишите proto-описание, после этого вы можете генерировать клиент для любого языка, и не нужно их как-то отдельно разрабатывать. Распространять интерфейс для своего сервиса можете просто в виде proto-описания. Любой потребитель может сгенерировать себе клиент сам.

Про отмену запроса и дедлайны хотел бы отметить, что запрос можно отменить на сервере и на клиенте. Если мы понимаем, что все, запрос нам дальше выполнять не нужно, то мы его можем отменить. Есть возможность выставить таймаут на запрос. В gRPC в большинстве runtime-библиотек в качестве понятия таймаута используется дедлайн. Но по факту это то же самое. То есть это время, когда запрос должен завершиться.
И что самое интересное, это то, что сервер может узнать, как об отмене запроса, так и об истечении таймаута и перестать выполнять запрос на своей стороне. Это очень круто, такого, мне кажется, нигде особо больше нет.
Про документацию хотел заметить, что поскольку в IDL для gRPC используется proto-формат, это обычный код. Там можно писать комментарии, в том числе очень развернутые. И нужно понимать, что вашим пользователям для того, чтобы сделать интеграцию с вашим сервисом, нужно иметь этот proto-формат у себя, и он попадет к ним вместе с комментариями, они не будут лежать где-то в другом месте. Это очень удобно. И можно расширять это описание, то есть это такая удобная фича, что документация идет рядом с кодом, примерно так же, как она может лежать рядом с методами в виде javadoc или любых других комментариев.
Давайте двигаться дальше, посмотрим немного на практику. И самый базовый пример использования gRPC, это так называемый unary call, или одиночный вызов. Это классическая схема — мы отправляем запрос на сервер и получаем один ответ от сервера. Похоже на то, как это работает в HTTP.
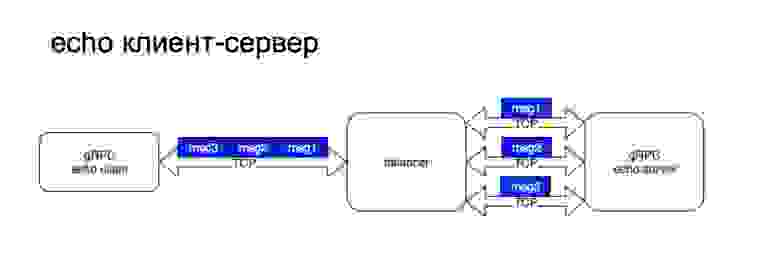
Рассмотрим пример echo сервиса, который мы делаем. Сервер будет написан на плюсах, клиент — на Java. Здесь использовалась классическая схема с балансировкой. То есть клиент обращается к балансеру, а дальше балансер уже выбирает конкретный бэкенд для обработки запроса.
Хотел обратить внимание — поскольку gRPC работает по HTTP/2, то используется одно TCP-соединение. И дальше уже различные стримы проходят по нему. Здесь можно заметить, что соединение между клиентом и балансером устанавливается один раз и остается персистентным, а дальше балансер уже на каждый вызов балансирует нагрузку на разные бэкенды. Если посмотреть, то это происходит вот так и вот так, если сообщения распространяются.

Вот пример кода нашего proto-файла. Можно обратить внимание, что сначала мы описываем сообщение, то есть у нас есть EchoRequest и EchoResponse. В нем всего одно строковое поле, которое хранит в себе сообщение.
Вторым шагом мы описываем нашу процедуру. Процедура на вход принимает EchoRequest, в качестве результата возвращает EchoResponse, все достаточно тривиально. Так выглядит описание gRPC сервиса и сообщений, которые будут гоняться.

Посмотрим, как это собирается в случае плюсов, например. Собирается в три этапа. На первом этапе наша задача — сгенерировать исходники сообщений. Вот этой командой мы это делаем. Вызываем proto компилятор, на вход передаем proto-файл, указываем, куда нужно положить выходные файлы.
Вторая команда. Мы точно так же генерируем сервисы. Единственная разница с предыдущей командой — мы передаем плагин, и на основании описания, которое есть в proto-формате, оно генерирует сервисы.
Третий шаг — мы все это собираем в один бинарь, чтобы можно было запустить наш сервер.
Линкеру тут передается дополнительный флаг, он называется grpc++_reflection. Хочу отметить — у gRPC-сервера есть такая фича, серверная рефлексия. Она позволяет исследовать, какие вообще сервисы, RPC-вызовы и сообщения есть у сервиса. По дефолту она выключена, и к сервису можно обратиться, только имея на руках proto-формат. Но, например, для отладки, очень удобно, не имея под рукой proto-формата, просто включить сервер с фичей рефлексии и получать информацию сразу.
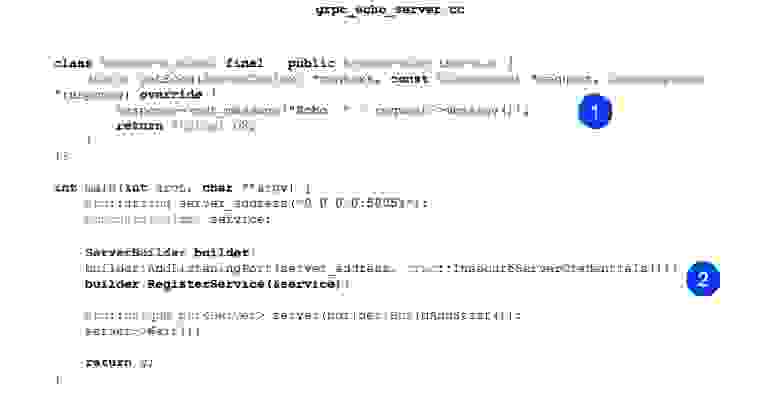
Теперь посмотрим на реализацию. Реализация тоже минималистичная. То есть основная наша задача — реализовать сгенерированный echo-сервис. В нем есть один метод getEcho. Он просто генерирует сообщения и отправляет его обратно. Статус OK — статус успеха.
Дальше мы создаем ServerBuilder, регистрируем в нем наш сервис, который чуть выше сконструировали.
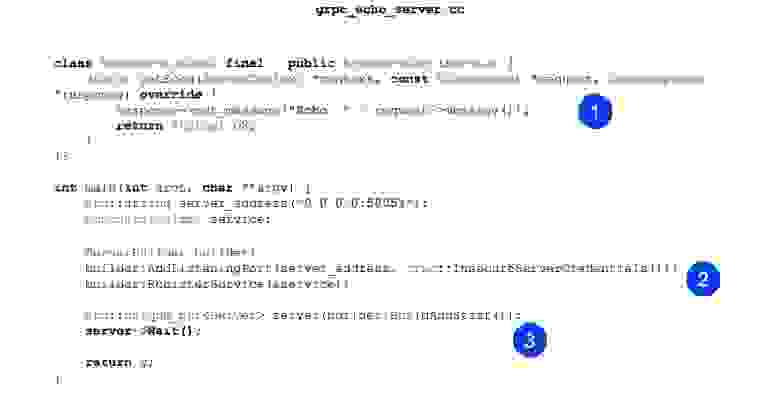
Теперь мы просто стартуем и ждем входящих запросов.

Посмотрим теперь клиент на Java. Собираем gradle. Наша задача — первым делом подключить плагин protobuf.
Есть базовый набор зависимостей, которые нам нужно притащить для нашего сервиса, они необходимы на этапе компиляции.
Также хочу обратить внимание, что есть runtime-библиотека. Для Java она использует netty в качестве сервера и клиента, он поддерживает HTTP/2, это достаточно удобно и высокопроизводительно.
Дальше мы настраиваем proto-компилятор. Сам компилятор локально для Java ставить необязательно, он может быть взят из артефактов.
То же самое с плагинами. Локально для Java его иметь не обязательно. Можно притащить артефактом. И важно просто настроить его так, чтобы для всех тасок он также вызвался, чтобы были сгенерированы заглушки (stub).
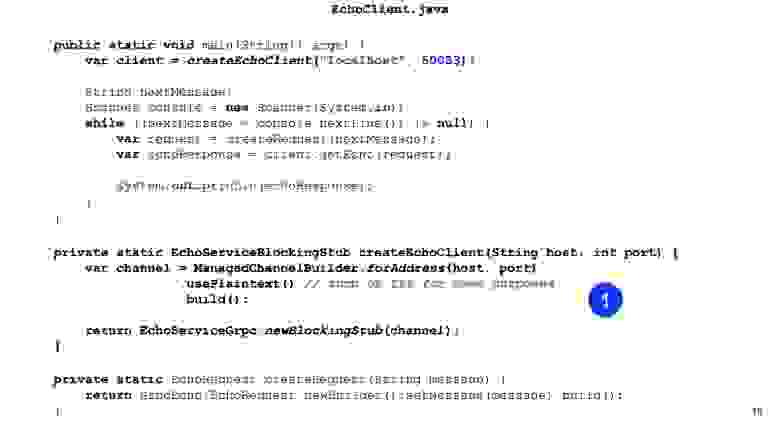
Двигаемся дальше в Java-код. Здесь первым мы создаем stub нашего сервиса. То есть наша задача для Java предоставить Channel. В runtime-библиотеке есть ChannelBuilder, которым мы можем построить этот канал. Здесь мы вручную включили формат plain text для упрощения, но HTTP2 и gRPC по умолчанию все шифрует и использует TLS.
У нас есть stub нашего клиента, здесь сгенерирован синхронный клиент. Точно так же можно сгенерировать асинхронный клиент, есть и другие варианты.
Дальше мы создаем наш протобуффный Request, то есть конструируем протобуффное сообщение.

Все, отправляем его, на нашем клиенте вызываем getEcho и печатаем результат. Все просто. Как видите, нужно достаточно мало кода, и интеграция построена.
Посмотрим теперь на более продвинутую вещь, это стриминг. Я сейчас расскажу, как он работает, а позже еще расскажу, как его можно применять.
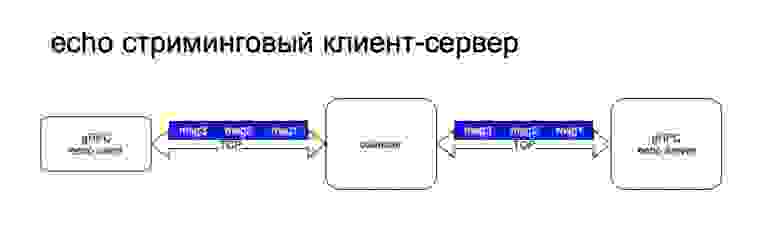
Стриминговый клиент-сервер выглядит архитектурно примерно точно также. То есть у нас есть персистентное соединение между клиентом и балансером. Дальше начинаются отличия. Суть стриминга в том, что клиент привязывается к какому-то конечному бэкенду, и соединение насквозь сохраняется. То есть дальше происходит вот так. И вот так. Здесь я хотел бы отдельно отметить, что для стриминга не типично использование балансера, то есть нужно понимать, что стриминговые запросы могут быть достаточно долго живущие. То есть их можно открыть и долго обмениваться сообщениями. И эти сообщения будут проходить через balancer, но, по факту, всегда идти на один и тот же бэкенд. И не очень понятно, зачем он вообще нужен.
Распространенная практика — когда сервис, например, чисто стриминговый, или, в основном стриминговый, то используется service discovery. В gRPC есть точка расширения, где можно встроить service discovery.

Что нам требуется для того, чтобы стриминговые сервисы реализовать? У нас есть тот же самый proto-формат. Мы добавляем еще одну RPC, и здесь можно обратить внимание, что у нас добавилось два ключевых слова перед запросом и перед ответом. Таким образом, мы объявляем стримы EchoRequest и EchoResponse.
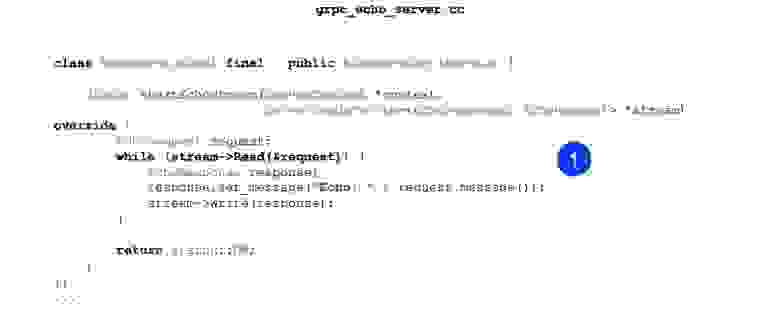
Дальше начинается более интересное. Компиляция у нас никак не меняется для того, чтобы стриминговые сервисы делать. Наша дальнейшая задача — переопределить наш новый метод в нашем Echo-сервисе, который будет работать со стримами. В случае с сервером это все несколько проще. То есть мы постоянно можем читать из стрима и можем что-то отвечать. Можем отвечать асинхронно. То есть они независимые, стрим на запись и стрим на чтение, и тут все просто для простого сценария.
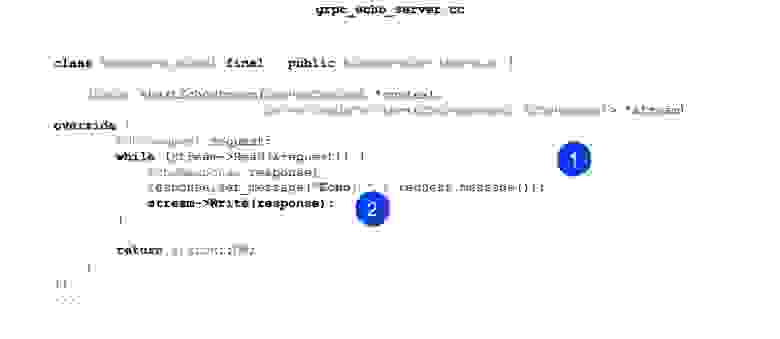
Вот здесь сейчас чтение, здесь запись.

В Java-клиентах все немного посложнее. Там нельзя использовать какой-нибудь синхронный API, то есть он просто со стримами не работает. И там используется асинхронный API. То есть наша задача — реализовать шаблон Observer. Там есть интерфейс StreamObserver. Он содержит три метода: onNext, onCompleted и onError. Здесь я для упрощения реализовал только onNext. Он дергается, только когда к нам с сервера приходит ответ.

Здесь я просто для обмена сообщениями между потоками складываю в очередь.

В чем отличие? Вместо blockingStub мы просто делаем newStub. Это асинхронная реализация, которая как раз с Observer может работать. На самом деле на Observer можно делать и unary-вызовы, просто не так удобно. Мы, по крайней мере, используем это не так активно.
Дальше конструируем наш Observer.
И делаем наш RPC-вызов. На вход мы передаем ResponseObserver, и на выходе он нам выдает RequestObserver. Дальше мы на RequestObserver можем делать вызовы, таким образом передавая сообщения на сервер. И наш ResponseObserver будет дергаться и обрабатывать сообщения.
Здесь пример. Мы как раз делаем вызов. Вызываем onNext, передаем туда Request.
Дальше из очереди мы ждем, когда нам ответит сервер, и распечатываем.

Хочу обратить внимание, что наша задача здесь, как людей, которые отвечают за реализацию стриминга, корректно обработать закрытие вот этого RequestObserver. То есть мы должны в случае ошибки вызвать метод onError на нем, и в случае успешного завершения, когда мы считаем, что стрим можно закрывать, мы должны вызвать метод onCompleted.

Двигаемся дальше. Какие у стриминга области применения? Это более продвинутая штука, не факт, что она прямо всем пригодится, но иногда используется. То есть, первое, это скачивание и загрузка каких-то больших объемов данных. Сервер или клиент может какими-то порциями выдавать данные. Эти порции могут уже как-то на клиенте или на сервере группироваться. То есть можно здесь уже оптимизации дополнительные делать.
Также схема стриминга хорошо подходит для серверных пушей. Нужно понимать, что я рассмотрел самый экстремальный вариант, когда у нас двунаправленный стриминг. А может быть стриминг в одном направлении. Например, с клиента на сервер или с сервера на клиент. Вот в случае с сервера на клиент мы можем подключиться к какому-нибудь серверу, и он нам будет пуши отправлять, и для этого нам не нужно будет регулярно опрашивать.
Следующее преимущество стриминга, это привязка к одной машине. Как я уже говорил, будет установлено одно сквозное соединение на все сообщения внутри стрима, и это соединение будет привязано к одной машине, и оно точно гарантированно никуда не переключится. Поэтому можно, во-первых, что-то упростить, какую-то синхронизацию межсерверную, и плюс, можно и транзакционные вещи делать.
И двунаправленный стриминг, как раз пример я показывал, это возможность строить какие-то свои протоколы. Достаточно интересная штука. У нас есть внутренние очереди в Яндексе, которые как раз используют двунаправленный стриминг. И если вдруг у кого-то есть такие задачи, то достаточно хорошая возможность использовать его.
Хочу также обратить внимание, я говорил раньше про метаданные. И со стримингом метаданные отправляются только вначале стрима и в конце стрима. То есть перед каждым сообщением и после каждого сообщения они не отправляются. Поэтому, если у вас есть какие-то задачи про метаданные, которые должны летать с каждым сообщением, то это уже нужно самим прорабатывать. Но это как раз и протоколы. Здесь gRPC можно использовать как транспорт.
Давайте посмотрим, как типичные задачи решаются в gRPC.

Про обработку ошибок я говорил, что есть проблема. Хотелось бы как-то это унифицировать. И в gRPC есть подход к унификации. Он, конечно, не навязывается, но в целом, наверное, хорошо его использовать. В первую очередь, код ответа в runtime-библиотеках стандартный. Вот статус, его можно использовать. Там есть набор констант этих статусов, например статус OK, которые достаточно хорошо работают и в runtime-библиотеках поддержаны.
Например, для Java в случае ошибочного статуса выкидывается исключение. Для плюсов статус является просто результатом выполнения вызова функции и можно проверить и дальше уже действовать в зависимости от него. Внутри google.rpc.Status есть 3 поля: код ответа, сообщение и детали. Есть стандартный набор кодов ответа, которые можно использовать. В поле сообщения можно просто записать нелокализованное сообщение, чтобы разобраться с проблемой. Детали — это вектор, в котором можно передавать кастомные объекты, в том числе бинарные.
И есть целый набор готовых error details, которые можно использовать, они уже проработаны. Есть подводные камни: например, чтобы внутренние устройства, скажем, stack traces, не светить в этих внутренних деталях. Там есть рекомендации, что и как использовать.
Здесь резонный вопрос — тут есть код, в HTTP тоже есть код, а чем они вообще отличаются? На самом деле они не сильно отличаются. Точно так же есть BadRequest и так далее. Но нужно понимать, что есть четкая рекомендация здесь, как код мапить на конкретные error details, которые нужно передавать.
Есть прямо таблица. Если вы возвращаете, условно, BadRequest или что-то еще (там целый набор кодов), то используйте с ним такой-то error detail. И можно эту таблицу просто распечатать себе, повесить, и каждый раз не изобретать велосипед, а брать что-то стандартное. И всем будет понятно, кто и что использует.

К типичным задачам относится и трассировка запросов. Опишу проблему. В микросервисной архитектуре, когда делается вызов фронта, например, то часто вызываются десятки сервисов. И если где-то что-то пошло не так, или где-то что-то затормозило, там не так быстро понять, что происходит. И для решения этих вопросов есть трассировка. Опенсорсное решение, например, Zipkin. И понятное дело, в HTTP он поддерживается через заголовки, здесь — через metadata. Это хорошее место для трассировки и хранения трассировочных атрибутов.
Атрибуты в метадате могут быть как строковые, так и бинарные. В случае с трассировкой проще использовать строковую, потому что если мы вдруг получаем в каком-то клиенте, который используем для отладки, то легче читать строку, чем потом дополнительно десервизовать бинарник.
И поддержка интерсепторов в runtime-библиотеках, то есть возможность вот эту метадату через интерсепторы прозрачно для бизнес-логики встраивать, это очень удобно. Для Java это ClientInterceptor и ServerInterceptor. Для плюсов, там более длинное название, не буду читать. Единственное, что для плюсов, хочу заметить, что они пока в экспериментальных фичах лежат, но я не думаю, что их когда-то выпилят. Возможно, там как-то API чуть-чуть поменяется. И дело в том, что интерсепторы, кроме трассировки, конечно, применяются для какой-то аутентификации. То есть, есть встроенная аутентификация в gRPC, но она далеко не всем подходит, хочется какую-то свою. И без интерсепторов ее никак не сделать, поэтому маловероятно, что это как-то выпилится, и, скорее всего, будет развиваться.

Также про юнит-тестирование хотел отдельно рассказать. Есть достаточно хорошая поддержка юнит-тестирования. Я для Java примеры писал. Есть возможность сделать заглушки канала и сервера, и на основе них уже генерировать сервис, то есть с юнит-тестированием все неплохо. Не надо что-то еще изобретать, там уже есть готовое решение.

Типичный вопрос. Вроде как gRPC — бинарный протокол. HTTP/2 и вообще. Можно его как-то отладить и разобраться, что там происходит? Такой же типичный ответ: да, можно. Уже есть некоторые инструменты. В первую очередь, вместе с поставкой gRPC идет инструмент grpc_cli, аналог curl. Он очень простой, но позволяет все делать с вызовами. Позволяет, по-моему, даже стриминг. И что самое удобное, если вы поставили gRPC себе на локальную машину, у вас он уже есть из коробки.
Есть более гламурные вещи, например evans. Я попробовал его, это такой интерактивный CLI: он выдает подсказки, когда вы заполняете протобуффное сообщение, сразу пишет, какие поля. В общем, он более интерактивный. Для каких-то скриптов, наверное, не подойдет, но использовать можно, неплохо, я попробовал.
Если кто-то хочет UI — например, привык к Postman, — есть BloomRPC. Он очень похож на Postman визуально. Но Postman, конечно, круче, он намного дольше развивался. Тем не менее, BloomRPC неплох, базовые функциональности выполняет.
Это какие-то базовые инструменты, которые я попробовал. В практике, конечно, я в основном использую grpc_cli. Два остальных инструмента я попробовал уже при подготовке к докладу. Но в целом, их намного больше. Призываю тех, кто хочет попробовать, тоже посмотреть. Дальше у меня будет ссылка на страницу, где можно посмотреть список всех известных клиентов. Может быть, кто-то что-то получше найдет. Если найдете лучше — напишите.

Конечно, индустрия не стоит на месте, и есть альтернативы gRPC. Хотелось бы про эти альтернативы поговорить подробнее. Какие-то из них мы пробовали, какие-то я нашел, когда готовился. Есть Swagger. Наверное, в случае с HTTP/1 это наиболее зрелая штука. Есть возможность в формате OpenAPI описать свой протокол, на основе него точно так же сгенерировать клиента. Клиента тоже можно генерировать для разных языков. Кажется, что если инфраструктура пока не готова к HTTP/2, то Swagger — самое хорошее решение.
WSDL — это классика, мне кажется. Ее тоже используют. Она очень похожа своими идеями на Swagger, но просто не такая хайповая, не такая модная. Но в целом используется. Я пользовался когда-то.
Для тех, у кого, например, нет требования строить сервисы между разными языками, есть JAX-RS, который для Java хорошо работает. Его тоже можно использовать.
Хотел бы отдельно отметить Twirp. Что это такое? Это штука только для Go, насколько я понял из документации. Я ее никогда не использовал. Знаю, что те, кто на Go пишут, перешли с gRPC на Twirp. В чем идея? Я говорил, что gRPC — достаточно абстрактная штука, которая не специфицирует, например, какую IDL использовать. Точно так же и proto-формат не специфицирует, что поверх него могут быть сгенерированы только gRPC-сервисы. Можно написать свой плагин к protoc, который будет генерировать сервисы на любом языке, на любых технологиях и как угодно обмениваться.
И Twirp как раз использует эту идею. Они берут proto-формат и на основе него генерируют сервисы, которые работают по HTTP/1.1 и обмениваются как бинарниками, так и JSON. Эта идея не нова, просто Twirp ее зарелизил в опенсорс для Go. И у нас тоже была такая мысль, и есть реализация плагина, который для Java генерирует таких клиентов на основе Jetty. Это вроде нормально работает, но там есть ограничения.

Какие выводы хотелось бы сделать? gRPC — достаточно хорошая альтернатива REST для новых сервисов. Если ваша инфраструктура позволяет, вы можете договориться с админами, что у вас, например, будет HTTP/2 balancer. Или есть service discovery, который вы можете использовать. gRPC хорош, он достаточно взрослый. Мы даже апгрейд пережили.
По поводу инструментов для отладки gRPC — инфраструктура молодая, но готовая. Есть как CLI, так и UI. Понятно, что с ростом комьюнити оно будет только улучшаться.
И есть хороший пример, как можно попробовать начать использовать gRPC. Это inter-process-коммуникации. Например, sidecar pattern. Это подход, при котором мы часть нашей логики выносим в отдельное приложение. Оно запускается на той же машине, но в отдельном процессе. Например, это различные мониторинг-агенты. Если мы хотим какие-нибудь метрики отправлять во внешнюю систему, то чтобы нам из нашего приложения эти метрики напрямую в эту систему не писать, мы пишем их в мониторинг-агент. Он уже по своим алгоритмам асинхронно может их группировать и отправлять во внешнюю систему. С логами точно такой же подход, если они, например, не на файловую систему, а тоже пуляются в какие-нибудь очереди.
Очевидно, что возникает задача коммуникаций с этим агентом. И gRPC здесь очень хороший инструмент. В первую очередь, персистентное соединение. Можно использовать как стриминг, так и unary-вызовы. Если у вас в компании есть такого рода задачи, можно на них этот протокол попробовать.
Вот полезные ресурсы:
— Cайт самого gRPC — там много туториалов, вводные. полезный сайт, с которого можно начать, почитать, там есть примеры на разных языках.
— Awesome gRPC — репа в GitHub с коллекцию ссылок на разные ресурсы. Там как раз описание всех клиентов, подходов для разных языков, куча внешних докладов, слайдов. Крутая штука. Если хотите использовать — очень рекомендую, мне понравилось.
Можно в интернете найти множество других ресурсов, на несколько слайдов. Но эти мне больше всего понравились. Немного модифицированный код из презентации лежит по ссылке. Спасибо!
— Сначала хотелось бы познакомить вас с некоторыми фактами про Яндекс.Маркет, они будут полезны в рамках доклада. Первый факт: мы пишем сервисы на разных языках. Это накладывает требования по наличию клиентов для сервисов.
И если у нас есть сервис на Java, было бы неплохо, чтобы клиент для него был, например, еще и плюсовый или питонячий.

Все сервисы у нас независимые, нет никаких плановых больших релизов всего-всего Маркета. Микросервисы релизятся независимо, и тут нам важна обратная совместимость, и чтобы протокол ее поддерживал.
Третий факт: у нас есть как синхронная, так и асинхронная интеграция. В докладе я в основном буду говорить про синхронную.
Что мы использовали? Сейчас, конечно, основу наших интеграций составляют REST- или похожие на REST сервисы, которые обмениваются XML/JSON поверх протокола HTTP 1.1. Также есть XML-RPC — его мы в основном используем, когда интегрируемся с Python-кодом, то есть в Python есть встроенный XML-RPC-сервер. Его там достаточно удобно разворачивать, и мы его поддерживаем.
Когда-то у нас была CORBA. К нашему счастью, мы от нее отказались. Сейчас в основном REST и XML/JSON поверх HTTP.

У синхронных интеграций есть проблемы с существующим протоколами. Мы с такими проблемами сталкиваемся и пытаемся их полечить при помощи gRPC. Какие это проблемы? Как я уже говорил, хочется иметь клиентов на разных языках. Желательно, чтобы их еще не надо было писать самим. И, вообще, было бы круто, если бы клиент мог быть и синхронным, и асинхронным — в зависимости от целей пользователя сервиса.
Также хотелось бы, чтобы протокол, который мы используем, достаточно хорошо поддерживал обратную совместимость: это очень важно с параллельными независимыми релизами. Все наши релизы обратно совместимые, мы не ломаем обратную связь. Если сломал — это баг, и его просто надо как можно быстрее починить.
Необходим и какой-то стройный подход к обработке ошибок: все, кто делал REST-сервисы, знают — нельзя просто использовать HTTP-статус. Они обычно не позволяют детально описать проблему, приходится вводить какие-то свои статусы, свою детализацию. В REST-сервисах каждый вводит свою реализацию этих ошибок, приходится каждый раз по-разному с этим работать. Это не всегда удобно.
Хотелось бы также иметь управление таймаутами со стороны клиента. Опять же, те, кто работает с HTTP, понимают — если на стороне клиента мы выставили таймаут и он закончился, то клиент перестанет ожидать выполнения запроса, но сервер об этом ничего не узнает и продолжит его выполнять. Более того, посередине бывают различные прокси, которые ставят глобальные таймауты. И клиент может про них просто ничего не знать и конфигурировать их не всегда тривиально.
И наконец, проблема документации. Не всегда понятно, где для REST-ресурсов или для каких-то методов взять документацию, какие параметры они принимают, какое тело можно передать и как эту документацию коммуницировать с потребителями сервиса. Понятно, что есть Swagger, но с ним тоже не все тривиально.
gRPC. Теория
Я хотел бы рассказать про теоретическую часть gRPC — что это такое, какие есть задумки. А дальше уже перейдем к практике.

Вообще, gRPC — это абстрактная спецификация. Она описывает абстрактную RPC (remote procedure call), то есть удаленный вызов процедуры, которая обладает определенными свойствами. Сейчас мы их перечислим. Первое свойство — поддержка как одиночных вызовов, так и стриминга. То есть все сервисы, которые реализовывают эту спеку, поддерживают оба варианта. Следующий пункт — наличие метаданных, то есть чтобы вместе с полезной нагрузкой вы могли бы передать какие-то метаданные — условно, заголовки. И — поддержка отмены запроса и таймаутов из коробки.
Также она предполагает, что описание сообщений и самих сервисов осуществляется через некий Interface Definition Language или IDL. Также спецификация описывает wire-протокол поверх HTTP/2, то есть gRPC предполагает работу только поверх HTTP/2.

Есть типичная реализация gRPC, которая используется в большинстве случаев. У нас она также используется, и сейчас мы ее посмотрим. В качестве IDL используется proto-формат. gRPC плагин для proto-компилятора позволяет из proto-описания получать исходники, сгенерированных сервисов. И существуют runtime-библиотеки на разных языках — Java, С++, Python. В общем, практически все популярные языки поддерживаются, runtime-библиотеки для них существуют. И в качестве сообщений, которыми обмениваются сервисы, используется proto-сообщение, стилизованные сообщения по схеме protobuf.

Хочется немного погрузиться в какие-то определенные фичи. Вот они. Строгая типизация, то есть сообщение proto message, это строго типизированные сообщения. Те, кто с protobuf когда-то работал, знает, что там можно описывать поля в своем сообщении типами. Типы существуют как примитивные, так и строковые, массивы байт. Они могут быть скалярные, могут быть векторные. И, на самом деле, сообщения могут, в качестве поля, содержать другие сообщения, что достаточно удобно, в общем, можно представить любую модель.

Про обратную совместимость. Хочется заметить, что proto IDL это формат, в который заложена обратная совместимость из коробки, то есть он задумывался с заделом на обратную совместимость, и Google выпустил версию proto3, которая по сравнению с proto2 еще больше улучшает обратную совместимость. Там, плюс, есть всякие спецификации, как и что можно менять так, чтобы обратную совместимость сохранять в каких-то нетривиальных кейсах.
Есть возможность значений по умолчанию, можно добавлять новые поля и у потребителя ничего не требуется, собственно, изменять. Все поля в proto3 опциональные и их можно, допустим, удалять, и обращение к удаленному полю не вызывает ошибок на клиенте.

Еще одна фича gRPC — клиент и сервер генерируются при помощи proto-компилятора и gRPC-плагина на основе proto-описания. Есть возможность в моменте, когда пишется код, выбрать какой клиент будет использоваться. То есть выбрать асинхронный или синхронный клиент, в зависимости от того, какого рода код вы пишите. Например, для реактивного кода асинхронный клиент очень подходит. И эта возможность есть для любого языка. То есть один раз вы пишите proto-описание, после этого вы можете генерировать клиент для любого языка, и не нужно их как-то отдельно разрабатывать. Распространять интерфейс для своего сервиса можете просто в виде proto-описания. Любой потребитель может сгенерировать себе клиент сам.

Про отмену запроса и дедлайны хотел бы отметить, что запрос можно отменить на сервере и на клиенте. Если мы понимаем, что все, запрос нам дальше выполнять не нужно, то мы его можем отменить. Есть возможность выставить таймаут на запрос. В gRPC в большинстве runtime-библиотек в качестве понятия таймаута используется дедлайн. Но по факту это то же самое. То есть это время, когда запрос должен завершиться.
И что самое интересное, это то, что сервер может узнать, как об отмене запроса, так и об истечении таймаута и перестать выполнять запрос на своей стороне. Это очень круто, такого, мне кажется, нигде особо больше нет.
Про документацию хотел заметить, что поскольку в IDL для gRPC используется proto-формат, это обычный код. Там можно писать комментарии, в том числе очень развернутые. И нужно понимать, что вашим пользователям для того, чтобы сделать интеграцию с вашим сервисом, нужно иметь этот proto-формат у себя, и он попадет к ним вместе с комментариями, они не будут лежать где-то в другом месте. Это очень удобно. И можно расширять это описание, то есть это такая удобная фича, что документация идет рядом с кодом, примерно так же, как она может лежать рядом с методами в виде javadoc или любых других комментариев.
gRPC unary call. Практика
Давайте двигаться дальше, посмотрим немного на практику. И самый базовый пример использования gRPC, это так называемый unary call, или одиночный вызов. Это классическая схема — мы отправляем запрос на сервер и получаем один ответ от сервера. Похоже на то, как это работает в HTTP.

Рассмотрим пример echo сервиса, который мы делаем. Сервер будет написан на плюсах, клиент — на Java. Здесь использовалась классическая схема с балансировкой. То есть клиент обращается к балансеру, а дальше балансер уже выбирает конкретный бэкенд для обработки запроса.
Хотел обратить внимание — поскольку gRPC работает по HTTP/2, то используется одно TCP-соединение. И дальше уже различные стримы проходят по нему. Здесь можно заметить, что соединение между клиентом и балансером устанавливается один раз и остается персистентным, а дальше балансер уже на каждый вызов балансирует нагрузку на разные бэкенды. Если посмотреть, то это происходит вот так и вот так, если сообщения распространяются.

Вот пример кода нашего proto-файла. Можно обратить внимание, что сначала мы описываем сообщение, то есть у нас есть EchoRequest и EchoResponse. В нем всего одно строковое поле, которое хранит в себе сообщение.
Вторым шагом мы описываем нашу процедуру. Процедура на вход принимает EchoRequest, в качестве результата возвращает EchoResponse, все достаточно тривиально. Так выглядит описание gRPC сервиса и сообщений, которые будут гоняться.

Посмотрим, как это собирается в случае плюсов, например. Собирается в три этапа. На первом этапе наша задача — сгенерировать исходники сообщений. Вот этой командой мы это делаем. Вызываем proto компилятор, на вход передаем proto-файл, указываем, куда нужно положить выходные файлы.
Вторая команда. Мы точно так же генерируем сервисы. Единственная разница с предыдущей командой — мы передаем плагин, и на основании описания, которое есть в proto-формате, оно генерирует сервисы.
Третий шаг — мы все это собираем в один бинарь, чтобы можно было запустить наш сервер.
Линкеру тут передается дополнительный флаг, он называется grpc++_reflection. Хочу отметить — у gRPC-сервера есть такая фича, серверная рефлексия. Она позволяет исследовать, какие вообще сервисы, RPC-вызовы и сообщения есть у сервиса. По дефолту она выключена, и к сервису можно обратиться, только имея на руках proto-формат. Но, например, для отладки, очень удобно, не имея под рукой proto-формата, просто включить сервер с фичей рефлексии и получать информацию сразу.
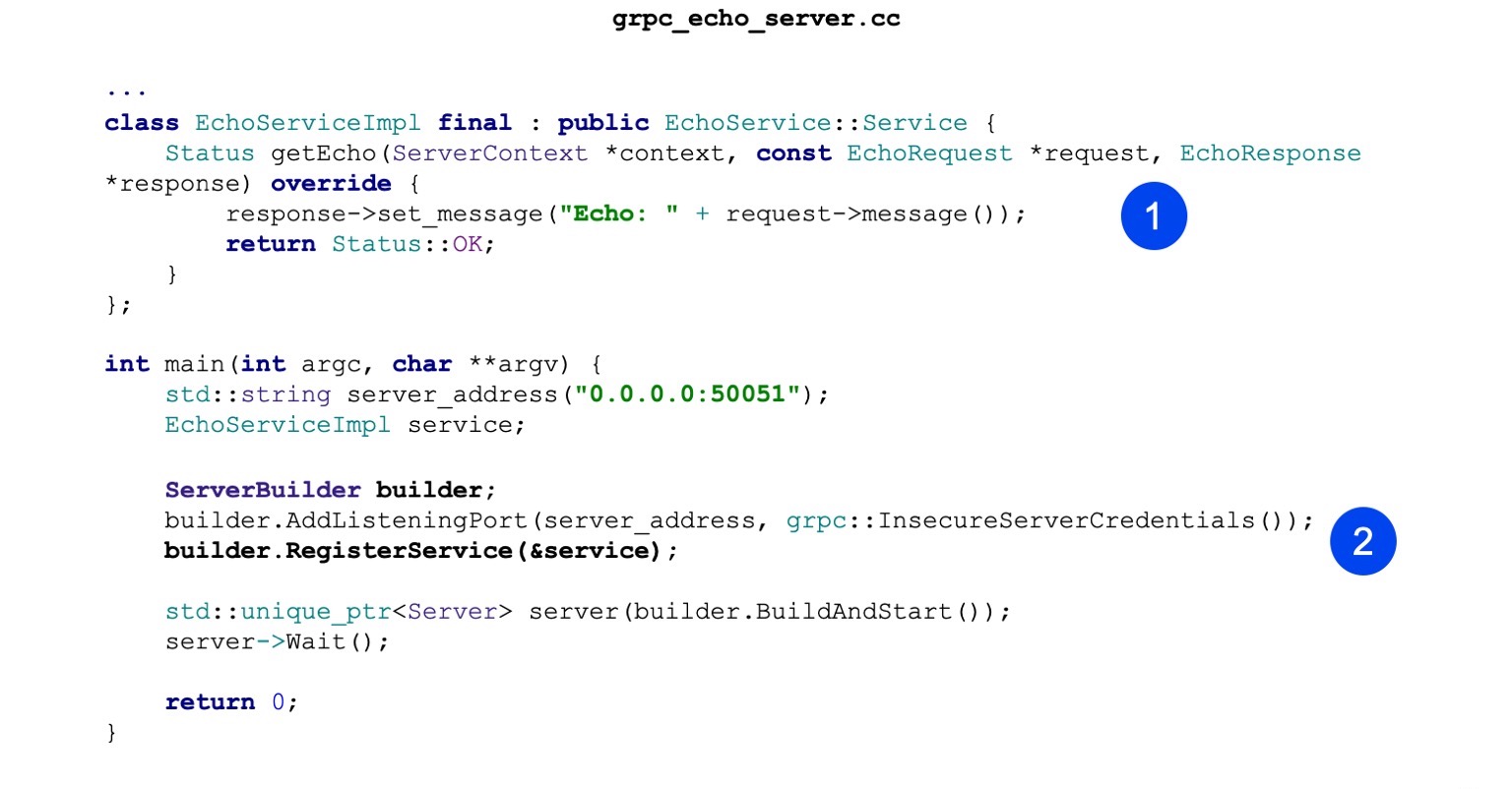
Теперь посмотрим на реализацию. Реализация тоже минималистичная. То есть основная наша задача — реализовать сгенерированный echo-сервис. В нем есть один метод getEcho. Он просто генерирует сообщения и отправляет его обратно. Статус OK — статус успеха.
Дальше мы создаем ServerBuilder, регистрируем в нем наш сервис, который чуть выше сконструировали.

Теперь мы просто стартуем и ждем входящих запросов.

Посмотрим теперь клиент на Java. Собираем gradle. Наша задача — первым делом подключить плагин protobuf.
Есть базовый набор зависимостей, которые нам нужно притащить для нашего сервиса, они необходимы на этапе компиляции.
Также хочу обратить внимание, что есть runtime-библиотека. Для Java она использует netty в качестве сервера и клиента, он поддерживает HTTP/2, это достаточно удобно и высокопроизводительно.
Дальше мы настраиваем proto-компилятор. Сам компилятор локально для Java ставить необязательно, он может быть взят из артефактов.
То же самое с плагинами. Локально для Java его иметь не обязательно. Можно притащить артефактом. И важно просто настроить его так, чтобы для всех тасок он также вызвался, чтобы были сгенерированы заглушки (stub).
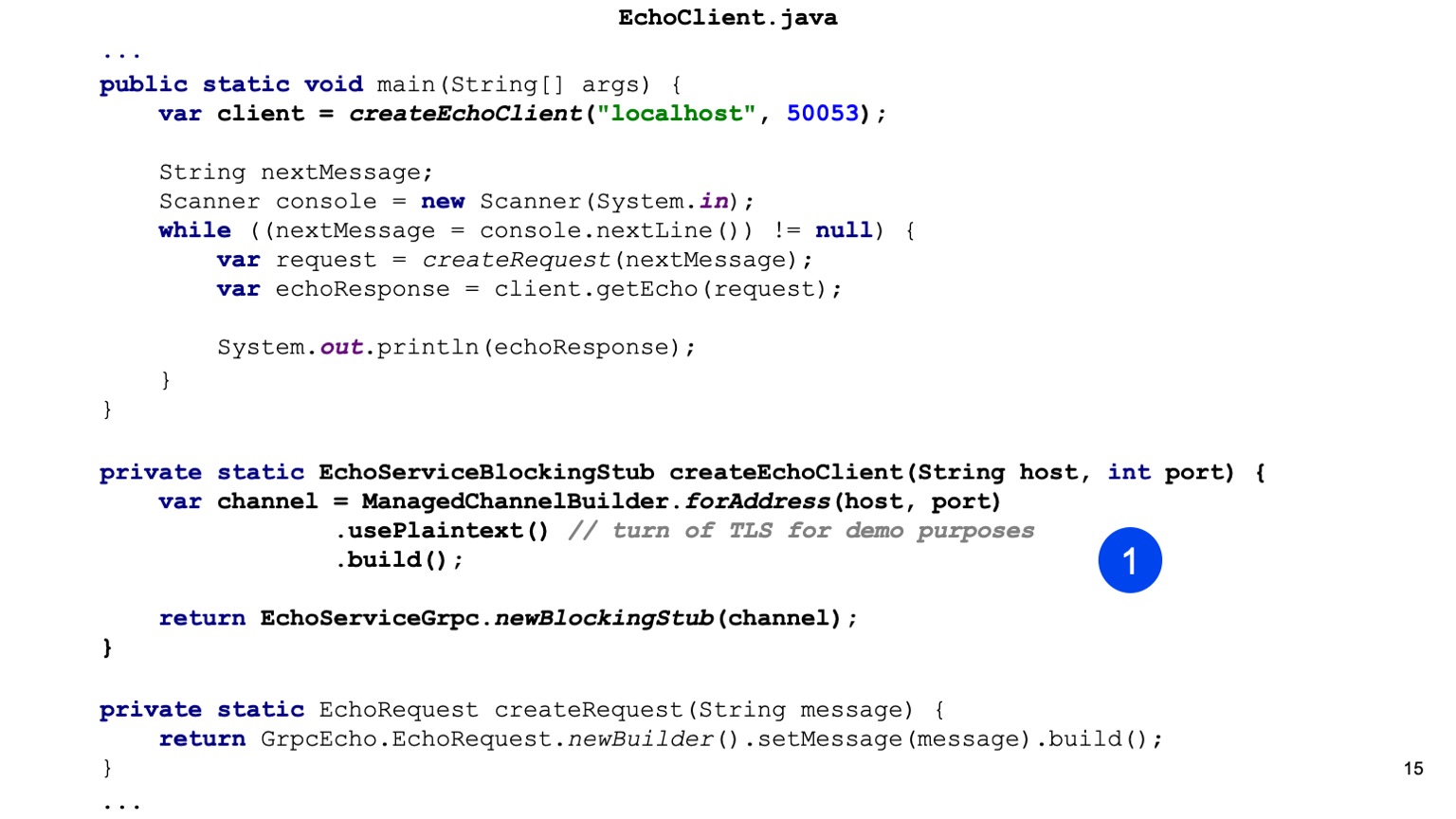
Двигаемся дальше в Java-код. Здесь первым мы создаем stub нашего сервиса. То есть наша задача для Java предоставить Channel. В runtime-библиотеке есть ChannelBuilder, которым мы можем построить этот канал. Здесь мы вручную включили формат plain text для упрощения, но HTTP2 и gRPC по умолчанию все шифрует и использует TLS.
У нас есть stub нашего клиента, здесь сгенерирован синхронный клиент. Точно так же можно сгенерировать асинхронный клиент, есть и другие варианты.
Дальше мы создаем наш протобуффный Request, то есть конструируем протобуффное сообщение.
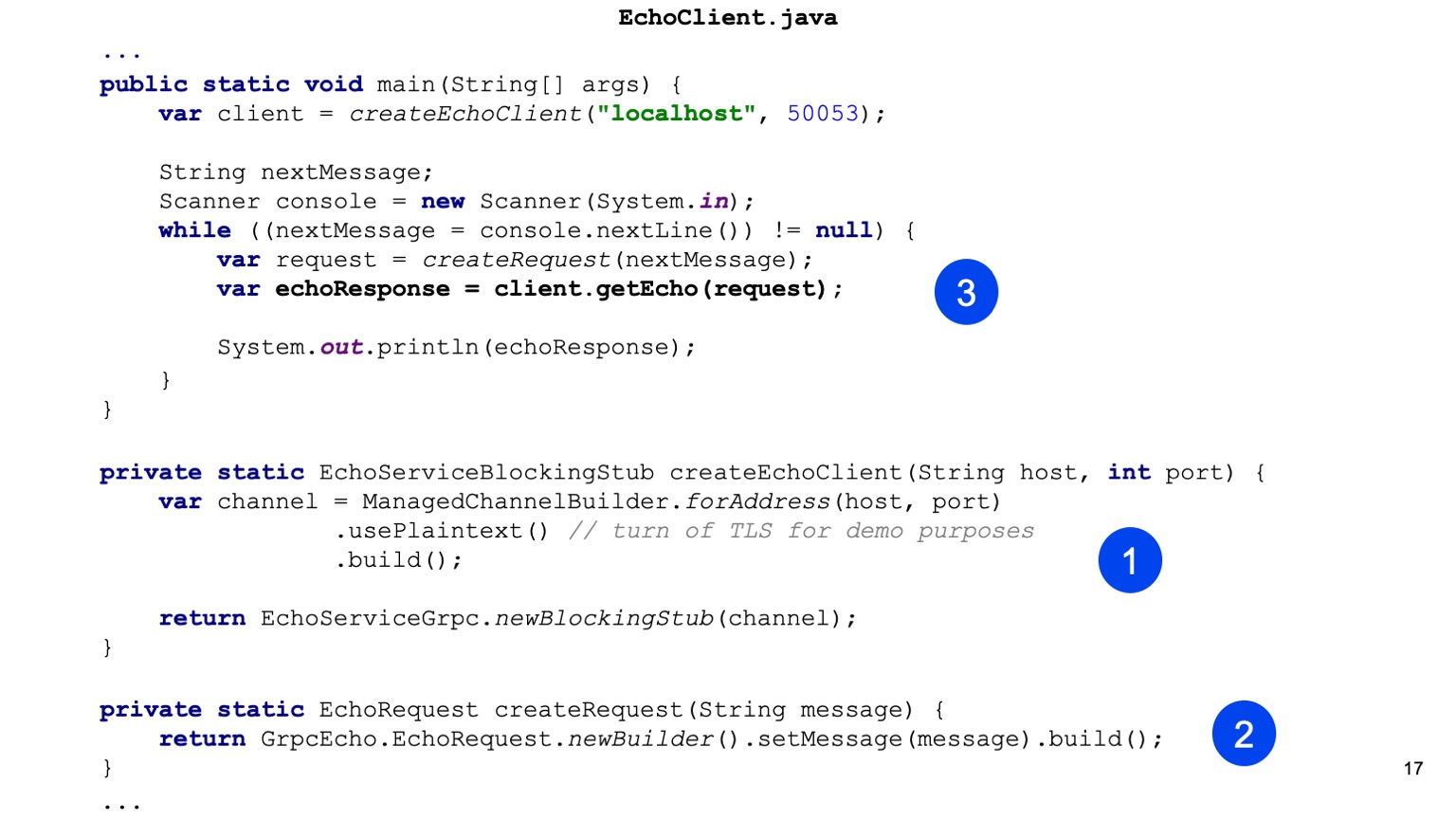
Все, отправляем его, на нашем клиенте вызываем getEcho и печатаем результат. Все просто. Как видите, нужно достаточно мало кода, и интеграция построена.
gRPC streaming. Практика
Посмотрим теперь на более продвинутую вещь, это стриминг. Я сейчас расскажу, как он работает, а позже еще расскажу, как его можно применять.

Стриминговый клиент-сервер выглядит архитектурно примерно точно также. То есть у нас есть персистентное соединение между клиентом и балансером. Дальше начинаются отличия. Суть стриминга в том, что клиент привязывается к какому-то конечному бэкенду, и соединение насквозь сохраняется. То есть дальше происходит вот так. И вот так. Здесь я хотел бы отдельно отметить, что для стриминга не типично использование балансера, то есть нужно понимать, что стриминговые запросы могут быть достаточно долго живущие. То есть их можно открыть и долго обмениваться сообщениями. И эти сообщения будут проходить через balancer, но, по факту, всегда идти на один и тот же бэкенд. И не очень понятно, зачем он вообще нужен.
Распространенная практика — когда сервис, например, чисто стриминговый, или, в основном стриминговый, то используется service discovery. В gRPC есть точка расширения, где можно встроить service discovery.

Что нам требуется для того, чтобы стриминговые сервисы реализовать? У нас есть тот же самый proto-формат. Мы добавляем еще одну RPC, и здесь можно обратить внимание, что у нас добавилось два ключевых слова перед запросом и перед ответом. Таким образом, мы объявляем стримы EchoRequest и EchoResponse.

Дальше начинается более интересное. Компиляция у нас никак не меняется для того, чтобы стриминговые сервисы делать. Наша дальнейшая задача — переопределить наш новый метод в нашем Echo-сервисе, который будет работать со стримами. В случае с сервером это все несколько проще. То есть мы постоянно можем читать из стрима и можем что-то отвечать. Можем отвечать асинхронно. То есть они независимые, стрим на запись и стрим на чтение, и тут все просто для простого сценария.

Вот здесь сейчас чтение, здесь запись.

В Java-клиентах все немного посложнее. Там нельзя использовать какой-нибудь синхронный API, то есть он просто со стримами не работает. И там используется асинхронный API. То есть наша задача — реализовать шаблон Observer. Там есть интерфейс StreamObserver. Он содержит три метода: onNext, onCompleted и onError. Здесь я для упрощения реализовал только onNext. Он дергается, только когда к нам с сервера приходит ответ.

Здесь я просто для обмена сообщениями между потоками складываю в очередь.

В чем отличие? Вместо blockingStub мы просто делаем newStub. Это асинхронная реализация, которая как раз с Observer может работать. На самом деле на Observer можно делать и unary-вызовы, просто не так удобно. Мы, по крайней мере, используем это не так активно.
Дальше конструируем наш Observer.
И делаем наш RPC-вызов. На вход мы передаем ResponseObserver, и на выходе он нам выдает RequestObserver. Дальше мы на RequestObserver можем делать вызовы, таким образом передавая сообщения на сервер. И наш ResponseObserver будет дергаться и обрабатывать сообщения.
Здесь пример. Мы как раз делаем вызов. Вызываем onNext, передаем туда Request.
Дальше из очереди мы ждем, когда нам ответит сервер, и распечатываем.

Хочу обратить внимание, что наша задача здесь, как людей, которые отвечают за реализацию стриминга, корректно обработать закрытие вот этого RequestObserver. То есть мы должны в случае ошибки вызвать метод onError на нем, и в случае успешного завершения, когда мы считаем, что стрим можно закрывать, мы должны вызвать метод onCompleted.

Двигаемся дальше. Какие у стриминга области применения? Это более продвинутая штука, не факт, что она прямо всем пригодится, но иногда используется. То есть, первое, это скачивание и загрузка каких-то больших объемов данных. Сервер или клиент может какими-то порциями выдавать данные. Эти порции могут уже как-то на клиенте или на сервере группироваться. То есть можно здесь уже оптимизации дополнительные делать.
Также схема стриминга хорошо подходит для серверных пушей. Нужно понимать, что я рассмотрел самый экстремальный вариант, когда у нас двунаправленный стриминг. А может быть стриминг в одном направлении. Например, с клиента на сервер или с сервера на клиент. Вот в случае с сервера на клиент мы можем подключиться к какому-нибудь серверу, и он нам будет пуши отправлять, и для этого нам не нужно будет регулярно опрашивать.
Следующее преимущество стриминга, это привязка к одной машине. Как я уже говорил, будет установлено одно сквозное соединение на все сообщения внутри стрима, и это соединение будет привязано к одной машине, и оно точно гарантированно никуда не переключится. Поэтому можно, во-первых, что-то упростить, какую-то синхронизацию межсерверную, и плюс, можно и транзакционные вещи делать.
И двунаправленный стриминг, как раз пример я показывал, это возможность строить какие-то свои протоколы. Достаточно интересная штука. У нас есть внутренние очереди в Яндексе, которые как раз используют двунаправленный стриминг. И если вдруг у кого-то есть такие задачи, то достаточно хорошая возможность использовать его.
Хочу также обратить внимание, я говорил раньше про метаданные. И со стримингом метаданные отправляются только вначале стрима и в конце стрима. То есть перед каждым сообщением и после каждого сообщения они не отправляются. Поэтому, если у вас есть какие-то задачи про метаданные, которые должны летать с каждым сообщением, то это уже нужно самим прорабатывать. Но это как раз и протоколы. Здесь gRPC можно использовать как транспорт.
Типичные задачи
Давайте посмотрим, как типичные задачи решаются в gRPC.

Про обработку ошибок я говорил, что есть проблема. Хотелось бы как-то это унифицировать. И в gRPC есть подход к унификации. Он, конечно, не навязывается, но в целом, наверное, хорошо его использовать. В первую очередь, код ответа в runtime-библиотеках стандартный. Вот статус, его можно использовать. Там есть набор констант этих статусов, например статус OK, которые достаточно хорошо работают и в runtime-библиотеках поддержаны.
Например, для Java в случае ошибочного статуса выкидывается исключение. Для плюсов статус является просто результатом выполнения вызова функции и можно проверить и дальше уже действовать в зависимости от него. Внутри google.rpc.Status есть 3 поля: код ответа, сообщение и детали. Есть стандартный набор кодов ответа, которые можно использовать. В поле сообщения можно просто записать нелокализованное сообщение, чтобы разобраться с проблемой. Детали — это вектор, в котором можно передавать кастомные объекты, в том числе бинарные.
И есть целый набор готовых error details, которые можно использовать, они уже проработаны. Есть подводные камни: например, чтобы внутренние устройства, скажем, stack traces, не светить в этих внутренних деталях. Там есть рекомендации, что и как использовать.
Здесь резонный вопрос — тут есть код, в HTTP тоже есть код, а чем они вообще отличаются? На самом деле они не сильно отличаются. Точно так же есть BadRequest и так далее. Но нужно понимать, что есть четкая рекомендация здесь, как код мапить на конкретные error details, которые нужно передавать.
Есть прямо таблица. Если вы возвращаете, условно, BadRequest или что-то еще (там целый набор кодов), то используйте с ним такой-то error detail. И можно эту таблицу просто распечатать себе, повесить, и каждый раз не изобретать велосипед, а брать что-то стандартное. И всем будет понятно, кто и что использует.

К типичным задачам относится и трассировка запросов. Опишу проблему. В микросервисной архитектуре, когда делается вызов фронта, например, то часто вызываются десятки сервисов. И если где-то что-то пошло не так, или где-то что-то затормозило, там не так быстро понять, что происходит. И для решения этих вопросов есть трассировка. Опенсорсное решение, например, Zipkin. И понятное дело, в HTTP он поддерживается через заголовки, здесь — через metadata. Это хорошее место для трассировки и хранения трассировочных атрибутов.
Атрибуты в метадате могут быть как строковые, так и бинарные. В случае с трассировкой проще использовать строковую, потому что если мы вдруг получаем в каком-то клиенте, который используем для отладки, то легче читать строку, чем потом дополнительно десервизовать бинарник.
И поддержка интерсепторов в runtime-библиотеках, то есть возможность вот эту метадату через интерсепторы прозрачно для бизнес-логики встраивать, это очень удобно. Для Java это ClientInterceptor и ServerInterceptor. Для плюсов, там более длинное название, не буду читать. Единственное, что для плюсов, хочу заметить, что они пока в экспериментальных фичах лежат, но я не думаю, что их когда-то выпилят. Возможно, там как-то API чуть-чуть поменяется. И дело в том, что интерсепторы, кроме трассировки, конечно, применяются для какой-то аутентификации. То есть, есть встроенная аутентификация в gRPC, но она далеко не всем подходит, хочется какую-то свою. И без интерсепторов ее никак не сделать, поэтому маловероятно, что это как-то выпилится, и, скорее всего, будет развиваться.

Также про юнит-тестирование хотел отдельно рассказать. Есть достаточно хорошая поддержка юнит-тестирования. Я для Java примеры писал. Есть возможность сделать заглушки канала и сервера, и на основе них уже генерировать сервис, то есть с юнит-тестированием все неплохо. Не надо что-то еще изобретать, там уже есть готовое решение.

Типичный вопрос. Вроде как gRPC — бинарный протокол. HTTP/2 и вообще. Можно его как-то отладить и разобраться, что там происходит? Такой же типичный ответ: да, можно. Уже есть некоторые инструменты. В первую очередь, вместе с поставкой gRPC идет инструмент grpc_cli, аналог curl. Он очень простой, но позволяет все делать с вызовами. Позволяет, по-моему, даже стриминг. И что самое удобное, если вы поставили gRPC себе на локальную машину, у вас он уже есть из коробки.
Есть более гламурные вещи, например evans. Я попробовал его, это такой интерактивный CLI: он выдает подсказки, когда вы заполняете протобуффное сообщение, сразу пишет, какие поля. В общем, он более интерактивный. Для каких-то скриптов, наверное, не подойдет, но использовать можно, неплохо, я попробовал.
Если кто-то хочет UI — например, привык к Postman, — есть BloomRPC. Он очень похож на Postman визуально. Но Postman, конечно, круче, он намного дольше развивался. Тем не менее, BloomRPC неплох, базовые функциональности выполняет.
Это какие-то базовые инструменты, которые я попробовал. В практике, конечно, я в основном использую grpc_cli. Два остальных инструмента я попробовал уже при подготовке к докладу. Но в целом, их намного больше. Призываю тех, кто хочет попробовать, тоже посмотреть. Дальше у меня будет ссылка на страницу, где можно посмотреть список всех известных клиентов. Может быть, кто-то что-то получше найдет. Если найдете лучше — напишите.

Конечно, индустрия не стоит на месте, и есть альтернативы gRPC. Хотелось бы про эти альтернативы поговорить подробнее. Какие-то из них мы пробовали, какие-то я нашел, когда готовился. Есть Swagger. Наверное, в случае с HTTP/1 это наиболее зрелая штука. Есть возможность в формате OpenAPI описать свой протокол, на основе него точно так же сгенерировать клиента. Клиента тоже можно генерировать для разных языков. Кажется, что если инфраструктура пока не готова к HTTP/2, то Swagger — самое хорошее решение.
WSDL — это классика, мне кажется. Ее тоже используют. Она очень похожа своими идеями на Swagger, но просто не такая хайповая, не такая модная. Но в целом используется. Я пользовался когда-то.
Для тех, у кого, например, нет требования строить сервисы между разными языками, есть JAX-RS, который для Java хорошо работает. Его тоже можно использовать.
Хотел бы отдельно отметить Twirp. Что это такое? Это штука только для Go, насколько я понял из документации. Я ее никогда не использовал. Знаю, что те, кто на Go пишут, перешли с gRPC на Twirp. В чем идея? Я говорил, что gRPC — достаточно абстрактная штука, которая не специфицирует, например, какую IDL использовать. Точно так же и proto-формат не специфицирует, что поверх него могут быть сгенерированы только gRPC-сервисы. Можно написать свой плагин к protoc, который будет генерировать сервисы на любом языке, на любых технологиях и как угодно обмениваться.
И Twirp как раз использует эту идею. Они берут proto-формат и на основе него генерируют сервисы, которые работают по HTTP/1.1 и обмениваются как бинарниками, так и JSON. Эта идея не нова, просто Twirp ее зарелизил в опенсорс для Go. И у нас тоже была такая мысль, и есть реализация плагина, который для Java генерирует таких клиентов на основе Jetty. Это вроде нормально работает, но там есть ограничения.

Какие выводы хотелось бы сделать? gRPC — достаточно хорошая альтернатива REST для новых сервисов. Если ваша инфраструктура позволяет, вы можете договориться с админами, что у вас, например, будет HTTP/2 balancer. Или есть service discovery, который вы можете использовать. gRPC хорош, он достаточно взрослый. Мы даже апгрейд пережили.
По поводу инструментов для отладки gRPC — инфраструктура молодая, но готовая. Есть как CLI, так и UI. Понятно, что с ростом комьюнити оно будет только улучшаться.
И есть хороший пример, как можно попробовать начать использовать gRPC. Это inter-process-коммуникации. Например, sidecar pattern. Это подход, при котором мы часть нашей логики выносим в отдельное приложение. Оно запускается на той же машине, но в отдельном процессе. Например, это различные мониторинг-агенты. Если мы хотим какие-нибудь метрики отправлять во внешнюю систему, то чтобы нам из нашего приложения эти метрики напрямую в эту систему не писать, мы пишем их в мониторинг-агент. Он уже по своим алгоритмам асинхронно может их группировать и отправлять во внешнюю систему. С логами точно такой же подход, если они, например, не на файловую систему, а тоже пуляются в какие-нибудь очереди.
Очевидно, что возникает задача коммуникаций с этим агентом. И gRPC здесь очень хороший инструмент. В первую очередь, персистентное соединение. Можно использовать как стриминг, так и unary-вызовы. Если у вас в компании есть такого рода задачи, можно на них этот протокол попробовать.
Вот полезные ресурсы:
— Cайт самого gRPC — там много туториалов, вводные. полезный сайт, с которого можно начать, почитать, там есть примеры на разных языках.
— Awesome gRPC — репа в GitHub с коллекцию ссылок на разные ресурсы. Там как раз описание всех клиентов, подходов для разных языков, куча внешних докладов, слайдов. Крутая штука. Если хотите использовать — очень рекомендую, мне понравилось.
Можно в интернете найти множество других ресурсов, на несколько слайдов. Но эти мне больше всего понравились. Немного модифицированный код из презентации лежит по ссылке. Спасибо!
Неофициальная запись доклада
