

Представьте, что вы хотите провести вечер за просмотром фильма, но не знаете, какой выбрать. Пользователи Яндекса часто оказываются в такой же ситуации, поэтому наша команда разрабатывает рекомендации, которые можно встретить в Поиске и Эфире. Казалось бы, что тут сложного: берём оценки пользователей, с их помощью обучаем машину находить фильмы, которым с высокой вероятностью поставят 5 баллов, получаем готовый список фильмов. Но этот подход не работает. Почему? Вот об этом я сегодня и расскажу вам.
Немного истории. В далёком 2006 году Netflix запустила конкурс по машинному обучению Netflix Prize. Если вы вдруг забыли, тогда компания ещё не занималась стримингом в интернете, а сдавала в прокат фильмы на DVD. Но уже тогда ей было важно предугадывать оценку пользователя, чтобы что-то рекомендовать ему. Итак, суть конкурса: предсказать оценки зрителей на 10% лучше (по метрике RMSE), чем Cinematch, рекомендательная система Netflix. Это было одно из первых массовых соревнований такого рода. Интерес подогревал огромный датасет (больше 100 миллионов оценок), а также приз в 1 млн долларов.
Конкурс закончился в 2009 году. Команды BellKor’s Pragmatic Chaos и The Ensemble пришли к финишу с одинаковым результатом (RMSE = 0,8567), но The Ensemble заняла второе место, потому что отправила решение на 20 минут позже конкурентов. Результаты и работы можно найти тут. Но самое интересное в другом. Если верить неоднократным рассказам на профильных конференциях, алгоритмы-победители так и не оказались в продакшене в запущенном вскоре сервисе видеостриминга. Я не могу говорить о причинах чужих решений, но расскажу, почему мы поступили аналогичным образом.
Персональный рейтинг
Уже достаточно давно пользователи Яндекса могут оценивать просмотренные фильмы. Причём не только на КиноПоиске, но и в результатах поиска. Со временем у нас накопились сотни миллионов оценок десятков миллионов людей. В какой-то момент мы решили воспользоваться этими данными, чтобы помочь пользователям понять, насколько тот или иной фильм им понравится. По сути, мы решали ту же задачу, что и на конкурсе Netflix Prize, то есть предсказывали, какую оценку пользователь поставит фильму. На тот момент уже существовали рейтинги КиноПоиска и IMDB, которые строились на основе оценок людей. Мы же строили персональный рейтинг, поэтому решили использовать отдельную шкалу в процентах, чтобы избежать визуального сходства и путаницы.

Кстати, необходимость соотнести балльную шкалу и процентную — это отдельная неочевидная головная боль, поэтому коротко расскажу и о ней. Казалось бы, для 10-балльной шкалы возьмите по 10% на каждый балл — и дело в шляпе. Но нет. Причина в психологии и привычках. Например, с точки зрения пользователей, оценка 8/10 — это сильно лучше, чем 80%. Как такое соотнести? С помощью краудсорсинга! Так мы и поступили: запустили задание в Толоке, в котором толокеры описывали ожидания от фильмов с определённым баллом или процентом персонального рейтинга. На основе такой разметки мы подобрали функцию, которая переводит предсказание оценки из балльной в процентную так, чтобы при этом сохранялись ожидания пользователей.
Пример заданий в Толоке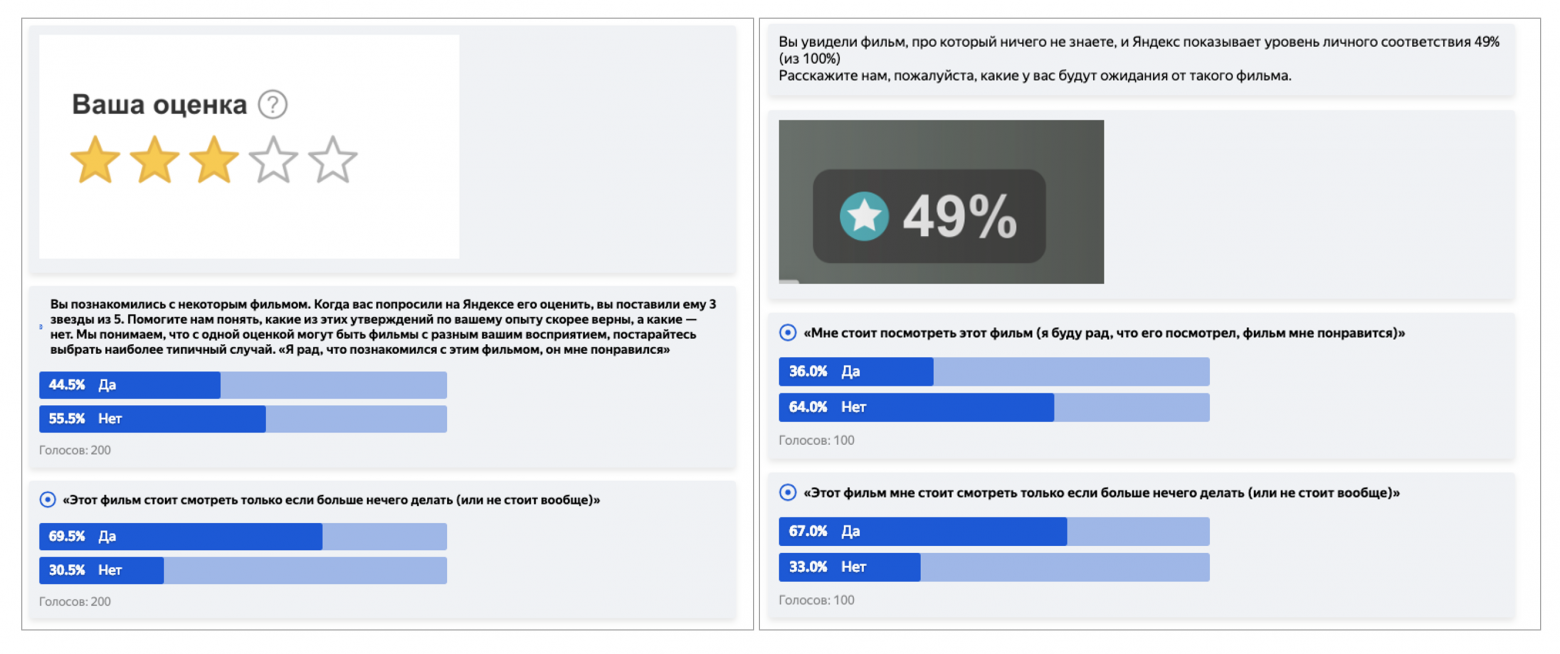
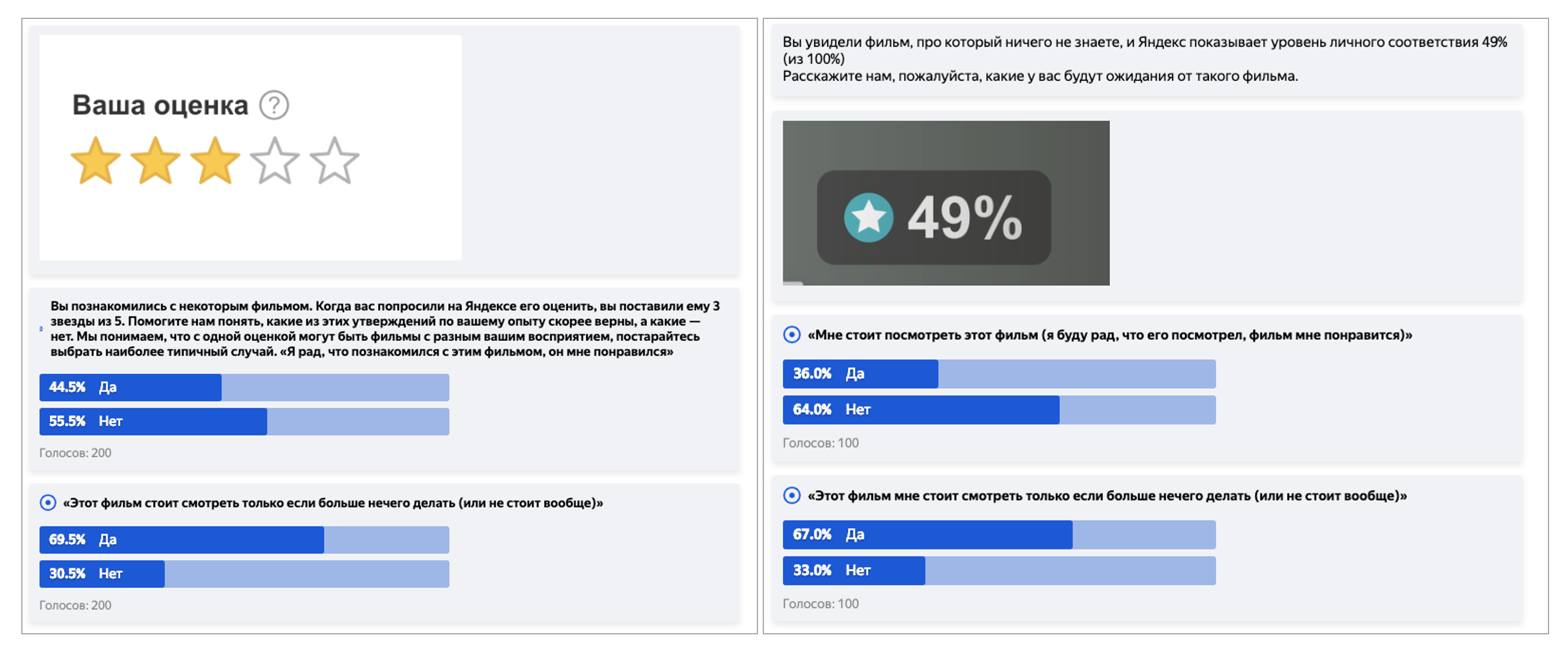
Предсказывать ожидания от фильма полезно, но хорошо бы ещё и рекомендации строить. То есть сразу показывать человеку список хороших фильмов. В этот момент многие из вас могли подумать: «А давайте просто отсортируем по персональному рейтингу те фильмы, которые пользователь ещё не смотрел». Мы тоже так подумали сначала. Но затем пришлось решать две проблемы.
Проблема инструмента
Когда пользователь ищет определённый фильм (или хочет взять конкретный DVD напрокат), то сервис должен предсказать оценку именно этого фильма. Ровно эта задача и решалась на конкурсе Netflix Prize, где использовалась метрика RMSE. Но в рекомендациях решается другая задача: нужно не угадать оценку, а найти фильм, который и будет в итоге просмотрен. И метрика RMSE плохо справляется с этой задачей. Например, штраф за предсказание оценки 2 вместо 1 точно такой же, как за 5 вместо 4. Но наша система вообще никогда не должна рекомендовать фильмы, которым пользователь поставит 2! Для решения этой задачи гораздо лучше подходят метрики на основе списка, например Precision@K, Recall@K, MRR или NDCG. Не могу не рассказать о них чуть подробнее (но если метрики вам неинтересны, то просто пропустите следующий абзац).
Начнём с метрики MRR (mean reciprocal rank). Будем смотреть, на какой позиции в ранжировании окажется фильм, с которым пользователь взаимодействовал (например, посмотрел или высоко оценил) в тестовом периоде. Метрика MRR — это усреднённая по пользователям обратная позиция такого фильма. То есть
 . Такая метрика, в отличие от RMSE, оценивает список целиком, но, к сожалению, смотрит только на первый угаданный элемент. Впрочем, легко модифицировать метрику, чтобы избавиться от этого недостатка. Мы можем посчитать сумму обратных позиций всех фильмов, с которыми взаимодействовал пользователь. Такая метрика называется Average Reciprocal Hit Rank. Такая метрика учитывает все угаданные фильмы в выдаче. Заметим, что позиция k в выдаче получает вес 1/k за угаданный фильм и вес 0 за другой фильм. Часто вместо 1/k используют 1/log(k): это лучше соответствует вероятности, что пользователь доскроллит выдачу до k позиции. Получится метрика DCG (discounted cumulative gain)
. Такая метрика, в отличие от RMSE, оценивает список целиком, но, к сожалению, смотрит только на первый угаданный элемент. Впрочем, легко модифицировать метрику, чтобы избавиться от этого недостатка. Мы можем посчитать сумму обратных позиций всех фильмов, с которыми взаимодействовал пользователь. Такая метрика называется Average Reciprocal Hit Rank. Такая метрика учитывает все угаданные фильмы в выдаче. Заметим, что позиция k в выдаче получает вес 1/k за угаданный фильм и вес 0 за другой фильм. Часто вместо 1/k используют 1/log(k): это лучше соответствует вероятности, что пользователь доскроллит выдачу до k позиции. Получится метрика DCG (discounted cumulative gain)  . Но вклад разных пользователей в метрику разный: для кого-то мы угадали все фильмы, для кого-то не угадали ничего. Поэтому, как правило, эту метрику нормируют. Поделим DCG каждого пользователя на DCG наилучшего ранжирования для этого пользователя. Полученная метрика называется NDCG (normalized discounted cumulative gain). Она широко используется для оценки качества ранжирования.
. Но вклад разных пользователей в метрику разный: для кого-то мы угадали все фильмы, для кого-то не угадали ничего. Поэтому, как правило, эту метрику нормируют. Поделим DCG каждого пользователя на DCG наилучшего ранжирования для этого пользователя. Полученная метрика называется NDCG (normalized discounted cumulative gain). Она широко используется для оценки качества ранжирования.Итак, каждой задаче — своя метрика. А вот следующая проблема уже не такая очевидная.
Проблема выбора
Её достаточно трудно описать, но я попробую. Оказывается, люди ставят высокие оценки не тем фильмам, которые обычно смотрят. Высшие оценки получают редкие киношедевры, классика, артхаус, но это не мешает людям вечером после работы с удовольствием посмотреть неплохую комедию, новый боевичок или эффектную космооперу. Добавьте к этому, что пользователи оценили в Яндексе далеко не все фильмы, которые когда-то и где-то уже посмотрели. И если ориентироваться только на высшие оценки, то мы рискуем получить ленту рекомендованных фильмов, которая будет выглядеть логично, пользователи могут даже признать её качество, но смотреть в итоге ничего не станут.
Например, вот так могла бы выглядеть моя лента фильмов, если бы мы отранжировали её по персональному рейтингу и ничего не знали о моих просмотрах в прошлом. Отличные фильмы. Но пересматривать сегодня я их не хочу.

Получается, что в условиях разрозненности оценок и дефицита фильмов с высоким рейтингом стоит смотреть не только на рейтинг. Хорошо, тогда обучим машину предсказывать просмотр рекомендованного фильма, а не оценку. Казалось бы, логично, ведь пользователь этого и хочет. Что же может пойти не так? Проблема в том, что лента заполнится фильмами, каждый из которых вполне подойдёт для лёгкого времяпровождения вечером, но их персональный рейтинг будет невысок. Пользователи, конечно же, обратят внимание на то, что в ленте нет «шедевров», а значит, доверие к рекомендациям будет подорвано, они не станут смотреть то, что в иных условиях посмотрели бы.
В итоге мы пришли к пониманию, что необходим баланс между двумя крайностями. Нужно обучать машину так, чтобы учитывался и потенциал для просмотра, и восприятие рекомендации человеком.
Как работают наши рекомендации
Наша система — часть Поиска, так что нам нужно строить рекомендации очень быстро: время ответа сервиса должно быть меньше 100 миллисекунд. Поэтому мы стараемся как можно больше тяжёлых операций выполнять в офлайне, на этапе подготовки данных. Все фильмы и пользователи в рекомендательной системе представлены профилями (важно не путать с аккаунтом), которые включают в себя ключи объекта, счётчики и эмбеддинги (проще говоря, векторы в некотором пространстве). Профили фильмов каждый день готовятся на YT (читается как «Ыть») и загружаются в оперативную память машин, которые отвечают на запросы. А вот с пользователями всё немного сложнее.
Каждый день мы также строим основной профиль пользователя на YT и отправляем в хранилище Яндекса, из которого можно получать профиль за пару десятков миллисекунд. Но данные быстро устаревают, если человек активно смотрит и оценивает видео. Нехорошо, если рекомендации начнут отставать. Поэтому мы читаем поток событий пользователя и формируем динамическую часть профиля. Когда человек вводит запрос, мы объединяем профиль из хранилища с динамическим профилем и получаем единый профиль, который всего на несколько секунд может отставать от реальности.
Это происходит в офлайне (то есть заранее), а теперь переходим непосредственно к рантайму. Здесь рекомендательная система состоит из двух шагов. Ранжировать всю базу фильмов слишком долго, поэтому на первом шаге мы просто отбираем несколько сотен кандидатов, то есть находим фильмы, которые могут быть интересны зрителю. Сюда попадают как популярные картины, так и близкие к пользователю по некоторым эмбеддингам. Существует несколько алгоритмов для быстрого нахождения ближайших соседей, мы используем HNSW (Hierarchical Navigable Small World). С его помощью мы находим ближайшие к пользователю фильмы всего за несколько миллисекунд.
На втором шаге мы извлекаем фичи (иногда их ещё называют факторами) по фильмам, пользователю и паре пользователь/фильм и ранжируем кандидатов с помощью CatBoost. Напомню: мы уже поняли, что нужно ориентироваться не только на просмотры, но и на другие характеристики качества рекомендаций, поэтому для ранжирования мы пришли к комбинации нескольких моделей CatBoost, обученных на различные таргеты.
Чтобы находить кандидатов, мы используем эмбеддинги из нескольких матричных разложений: от классического варианта ALS, который предсказывает оценку, до более сложных вариаций на базе SVD++. В качестве фич для ранжирования используются как простые счётчики событий пользователя и фильмы, CTR’ы по разным событиям, так и более сложные предобученные модели. Например, предсказание ALS тоже выступает в роли фичи. Одна из наиболее полезных моделей — нейросеть Recommender DSSM, о которой я, пожалуй, расскажу чуть подробнее.
Recommender DSSM
DSSM — это нейросеть из двух башен. Каждая башня строит свой эмбеддинг, затем между эмбеддингами считается косинусное расстояние, это число — выход сети. То есть сеть учится оценивать близость объектов в левой и правой башне. Подобные нейросети используются, например, в веб-поиске, чтобы находить релевантные запросу документы. Для задачи поиска в одну из башен подаётся запрос, в другую — документ. Для нашей сети роль запроса играет пользователь, а в качестве документов выступают фильмы.
Башня фильма строит эмбеддинг на основе данных о фильме: это заголовок, описание, жанр, страна, актёры и т. д. Эта часть сети достаточно сильно похожа на поисковую. Однако для зрителя мы хотим использовать его историю. Чтобы это сделать, мы агрегируем эмбеддинги фильмов из истории с затуханием по времени с момента события. Затем поверх суммарного эмбеддинга применяем несколько слоёв сети и в итоге получаем эмбеддинг размера 400.
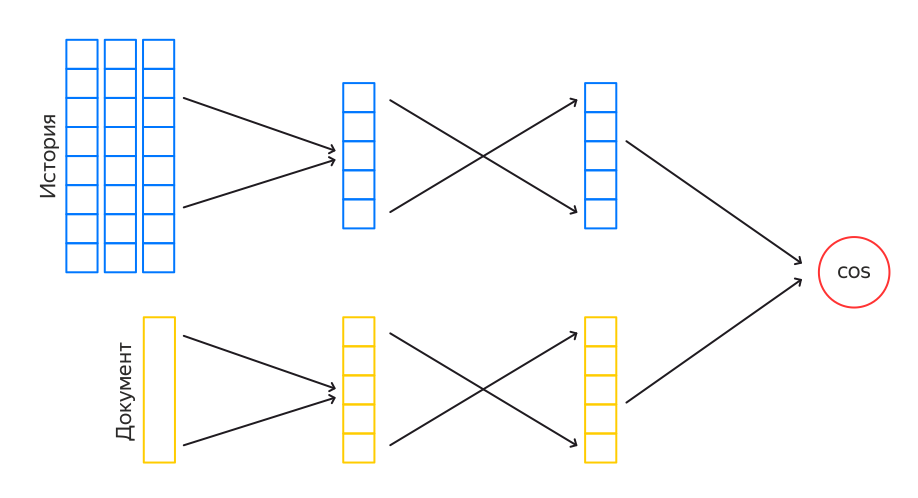
Если учитывать сразу всю историю пользователя в эмбеддинге, то это сильно замедлит обучение. Поэтому идём на хитрость и учим сеть в два этапа. Сначала учится более простой InnerDSSM. На вход он получает только последние 50 событий из истории пользователя без разделения на типы событий (просмотры, оценки...). Затем мы переобучаем полученный InnerDSSM на всей истории пользователя, но уже с разбиением на типы событий. Так получаем OuterDSSM, который и используется в рантайме.
Применение сети в рантайме в лоб требует довольно много вычислительных ресурсов. Поэтому мы сохраняем эмбеддинги из башни фильмов в базе, а эмбеддинги по истории пользователя обновляем near real-time. Таким образом, во время обработки запроса нужно применить только небольшую часть OuterDSSM и посчитать косинусы, это не занимает много времени.
Заключение
Сейчас наши рекомендации уже доступны в нашем поиске (например, по запросу [что посмотреть]), в сервисе Яндекс.Эфир, а ещё адаптированная версия этой технологии применяется в Яндекс.Станции. Но это не значит, что нам можно расслабиться. Мы постоянно обучаем новые модели, применяем всё больше данных, пробуем новые подходы к обучению и новые метрики качества. На мой взгляд, чем старше область, тем сложнее её развивать. Но в этом и заключается главный интерес для специалистов.
