
Бэкенд КиноПоиска HD — это платформа для передачи контента с помощью технологии Over the Top (OTT) на разные устройства, регионы и площадки. На нашей конференции о видеотехнологиях PlayButton я рассказал, как мы составляем персональные рекомендации, с какими трудностями справились, а какие еще собираемся преодолеть.
— Начну с того, откуда пошли онлайн-кинотеатры.

По ходу развития интернета появились OTT-медиасервисы, которые стали использоваться для передачи медиаконтента по интернету, в отличие от традиционных медиасервисов, где применялся кабель, спутник и другие каналы связи.
Такие медиасервисы основываются на OVP — online video platform, куда входит система управления контентом, веб-плеер и CDN. Отдельный класс таких систем — OTT-TV, онлайн-кинотеатр, который, помимо OVP, реализовывает системы контроля и управления доступом к контенту, систему защиты прав цифрового контента, управление подписками, покупками, разнообразные продуктовые и технические метрики. И предъявляет к этим системам повышенные требования по аптайму и задержкам.
Я расскажу о бэкенде, который отвечает за систему управления контентом, за пользовательскую функциональность онлайн-кинотеатра и за часть системы управления и контроля доступа к контенту.

Посмотрим, из чего состоят онлайн-кинотеатры. В параллелепипеде КиноПоиск HD реализованы всякие прикольные штуки и режимы просмотра. Пользователи тысячами RPS выбирают доступный контент на витринах, оформляют подписки и покупки. Сохраняют прогресс просмотра, пользовательские настройки. Тысячами RPS генерируют различные метрики. Это довольно большой и интересный набор компонентов, в подробности которых мы сегодня углубляться не будем. Но стоит упомянуть, что в целом это хорошо и понятно масштабируемые сервисы — за счет того, что они шардируются по пользователям.
Сегодня мы сконцентрируемся на облаке под параллелепипедом. Это платформа, отвечающая за хранение фильмов, сериалов, различных ограничений от правообладателей. Поддерживается усилиями нескольких отделов. Частью этой платформы является трансформатор доступности, который отвечает на вопросы, что я могу посмотреть прямо сейчас в этом месте. Без трансформатора доступности на КиноПоиске HD буквально не появится никакой контент.
Задача трансформатора — перевод гибкой и многоуровневой модели доступности в эффективную модель, которая хорошо масштабируется на как можно большее количество потребителей контента.
Почему она гибкая и масштабируемая? В первую очередь потому, что туда входят различные сущности, описывающие контент, монетизацию, реляционную доступность, доступность на площадках. Все это состоит в революционных отношениях, имеет сложную иерархию. И эта гибкость нужна для того, чтобы обеспечить требования десятков правообладателей и различные гибкие возможности по ценовой политике.
Под площадками мы понимаем, например, онлайн-кинотеатр в вебе, онлайн-кинотеатр на устройствах и другие партнерские ОТТ-сервисы, также проигрывающие наш контент.
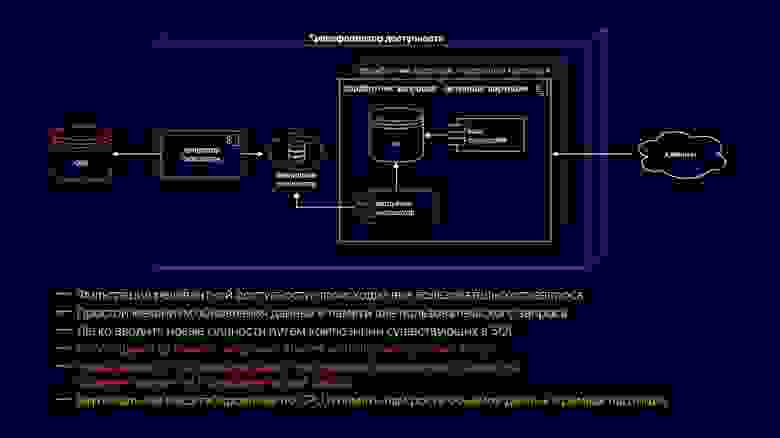
Понятно, что для эффективного подсчета доступности такой многоуровневой модели нужно строить сложные джойны, и подобные запросы не масштабируются на какую-либо нагрузку, они достаточно сложны в интерпретации, чтобы на них строить какую-то функциональность быстро и понятно. Чтобы решить эти проблемы, возник трансформатор доступности, денормализующий модель, представленную на слайде, как составной ключ, куда входят айдишники контента, страны, площадки, подписки и некоторый незримый неключевой остаток, который составляет большую часть объема памяти. Как раз о трудностях масштабирования трансформатора доступности мы сегодня и поговорим.

Погрузимся глубже в этот компонент и посмотрим, из чего он состоит. Здесь мы видим состояние системы непосредственно перед началом проблемы. Все это время трансформатор доступности двигался по пути молниеносного развития онлайн-кинотеатра. Важно было быстро запускать новую функциональность, в первую очередь — обеспечить доступность десятков тысяч фильмов и сериалов.
Если идти слева направо, то там CMS, реляционная база данных, в которой в третьей нормальной форме и в EAV хранятся наши основные сущности. Далее загрузчик снэпшотов. Далее генератор снэпшотов, который регулярно получает релевантные данные, фильтрует их, складывает в хранилище снэпшотов. Фактически это SQL-дамп. Дальше внутри инстанса обработчика запросов загрузчик снэпшотов регулярно получает новые данные и импортирует их в H2. H2 — это in-memory-база данных, написанная на Java, которая реализовывает основные возможности СУБД, то есть там есть интерпретатор запросов, оптимизатор запросов, индексы.
Фактически это как раз тот компонент, который обеспечивает гибкость создания новой функциональности онлайн-кинотеатра за счет того, что можно просто писать запросы на SQL и джойнить денормализованные сущности быстро и просто.
H2 обновляется по модели copy-on-write. Загрузчик снэпшотов поднимает новый инстанс базы данных и наполняет его. А потом, после наполнения, утилизирует старый, с помощью garbage collector.
Одновременно с H2 поднимается кэш сущности, куда входят композитные сущности и индекс над ними. Композитные сущности — это, по сути, продолжение денормализации того, что лежит в H2, чтобы обеспечить более требовательные запросы от клиентов по задержкам. Кэш-сущности точно так же обновляются по модели copy-on-write, одновременно с поднятием и новых инстансов H2.
Основные плюсы системы: можно легко и гибко добавлять новую функциональность за счет джойнов. Относительно простая схема обновления данных по copy-on-write. Из минусов — конечно, то, что требуется x2 памяти, чтобы эти сущности хранить и обновлять. Это косвенно влияет на пользовательский запрос, поскольку он утилизируется с помощью garbage collector.
Также во время построения кэша сущности необходим ресурс CPU для индексации. И это точно так же косвенно влияет на пользовательский запрос, но уже за счет конкуренции за ресурсы CPU. Оба этих пункта в совокупности приводят к тому, что при росте объема данных наших основных сущностей требуется вертикальное масштабирование обработчика запросов, как по CPU, так и по памяти.
Но система рассчитывалась на десятки тысяч фильмов и сериалов, доступных онлайн. Поэтому долгое время эти минусы были приемлемыми, позволяли эксплуатировать основной плюс по гибкости и легкости введения новый функций онлайн-кинотеатра.
Понятно, что все это работало до определенного момента. Представим, что этот желтый автобус — наш трансформатор доступности.

В нем едут фильмы и сериалы, размноженные по денормализации, то есть их десятки тысяч. И на одной из остановок нужно поднять на борт сотни тысяч музыкальных клипов и трейлеров и тоже их как-то разместить. Поднявшись на борт, они тоже размножатся за счет денормализации. Тем, кто находится внутри, нужно ужаться, а тем, кто снаружи, надо запрыгнуть, протиснуться. Можете себе представить, как это происходит. Технически в этот момент у нас объем памяти на инстансе вырос до десятков гигабайт. Построение кэша и утилизация старых инстансов с помощью garbage collector занимала несколько виртуальных ядер. И поскольку радикально вырос объем данных, вся эта процедура в совокупности привела к тому, что для публикации нового контента требуются десятки минут.
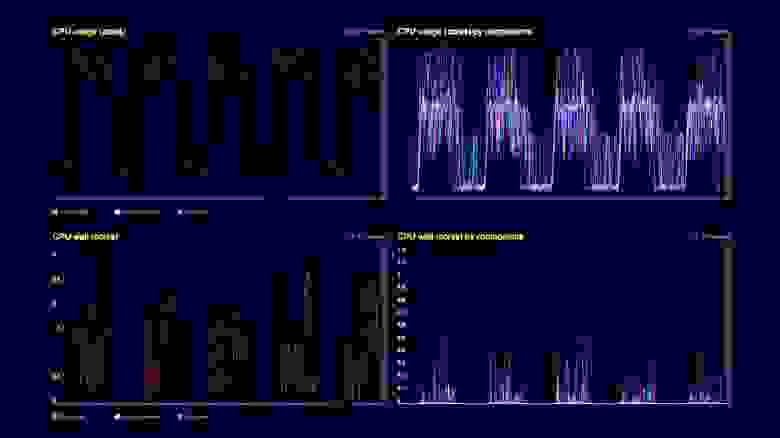
Технически мы видим здесь утилизацию CPU на кластере обработчика запросов. Во впадинах — обработка клиентских запросов порядка нескольких тысяч RPS, а на холмах — те же самые несколько тысяч RPS, плюс та же самая загрузка снэпшотов и их утилизация с помощью garbage collector. Нижние два графика — CPU wait на контейнере. Мы видим, что они тоже начинают себя проявлять в момент загрузки снэпшотов и их утилизации.
Чтобы разместить эти музыкальные клипы и трейлеры и продолжать масштабирование, мы ввели активные и пассивные инстансы обработчика запросов. Фактически это перенос copy-on-write на уровень выше. Теперь у нас в контейнере одновременно активный и пассивный инстанс. Пассивный готовит новый H2 и кэш сущностей, а активный просто обрабатывает запросы пользователей. Тем самым мы снизили влияние garbage collection, его пауз на обработку пользовательских запросов. Но при этом, поскольку они все еще живут в одном контейнере, загрузка снэпшотов и построение кэша все еще конкурирует за ресурсы CPU, и влияние на пользовательские запросы все еще есть.
Мы дополнительно ввели партиционирование по площадкам. Это обеспечивало нам сокращение памяти на тех площадках, где не нужны все эти новые типы контента. Например, онлайн-кинотеатру это позволило не загружать музыкальные клипы и трейлеры, и снизить влияние. Но при этом для площадок, которым нужно обеспечивать весь контент доступностью, конечно, ничего не поменялось.
Поэтому плюсы и минусы схемы остались примерно такими же, как раньше. Но за счет партиционирования вертикальное масштабирование по CPU и памяти переехало на площадки, и это позволило некоторым площадкам продолжить масштабироваться. По сравнению с прошлой схемой публикации контента это никак не поменялось. Он в целом занимал те же десятки минут, поэтому мы продолжали искать пути оптимизации.

Что мы к э тому моменту поняли? Что запросы онлайн-кинотеатра используют малую часть возможностей СУБД. Интерпретатор и оптимизатор запросов со временем выродился в кэш сущностей. Мы поняли, что определение доступности в целом универсально. Запросы отличаются тем, что нужно понять доступность единицы контента или списка и к этой доступности приклеить дополнительные атрибуты. В целом это можно делать без полноценной СУБД.
И второе: часть составного ключа — это низкокардинальные параметры. Стран — десятки, в пределе пара сотен, площадок — десятки, а подписок единицы. Скорее всего, денормализация в полном объеме не требуется. Оба этих вывода привели к тому, что мы стали двигаться в сторону более компактного и менее денормализованного представления в памяти, но которое при этом все еще быстро отвечает на запросы пользователей.

На слайде мы видим переход от трансформатора доступности v1 к v2. Здесь схематически изображена новая схема доступности, где составной ключ фактически сводится к тому, что это просто ключ по айдишнику контента. А доступность физически или логически сводится к определению доступности по спискам стран, площадок и подписок.
Тем самым мы уменьшаем объем незримого неключевого остатка, который составляет большую часть памяти, и уменьшаем объем памяти одновременно с ним.
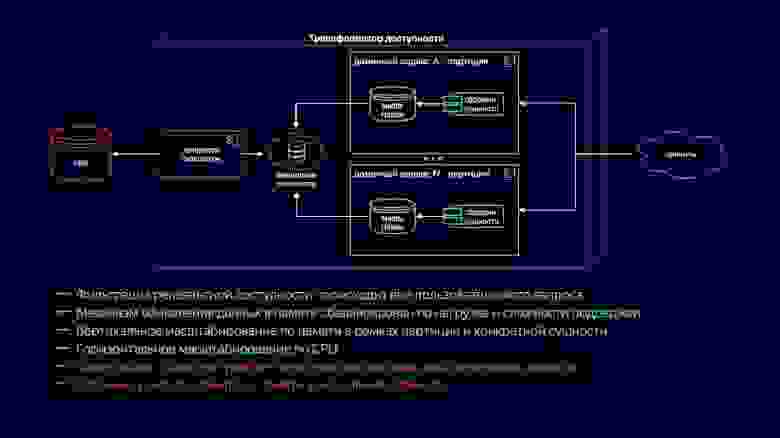
Здесь мы видим процесс перехода к новой схеме трансформатора доступности. Netflix Hollow играет роль поставщика и индексатора базовых сущностей, над которым доменные сервисы на лету собирают сборку композитных сущностей разного масштаба. Это работает, потому что базовые сущности все еще денормализованы и количество джойнов при сборке минимальное. С другой стороны, определение доступности сводится к простым и дешевым циклам и трудностей вызывать не должно.
При этом Netflix Hollow хранит и достаточно бережно относится к нагрузке на CPU и garbage collection, как во время обновления данных, так и во время доступа к ним. Это позволяет снизить холмы, которые мы видели на графиках утилизации CPU и свести их к приемлемому минимуму. Дополнительно, поскольку он реализовывает гибридную схему доставки в виде снэпшотов и диффов к ним, это позволяет увеличить скорость публикации нового контента до единиц минут.
Понятно, что сохранилась большая часть плюсов предыдущей схемы. Механизм обновления данных в памяти стал проще и дешевле по утилизации ресурсов. Вертикальное масштабирование по партициям, по площадкам также дополнилось масштабированием по конкретной сущности, оно теперь дешевле. И поскольку мы снизили накладные расходы на обновление снэпшотов, появилось действительно горизонтальное масштабирование по CPU.
Из минусов в этой схеме — то, что композиция сущностей требует межсервисных вызовов или отдельных сервисов. И все еще присутствует дубликация данных на уровне базовых сущностей, поскольку они теперь хранятся в каждом доменном сервисе, где используются. Но Netflix Hollow хранит данные компактнее, чем H2, а H2 хранит их гораздо компактнее, чем HashMap с объектами. Так что этот минус точно тоже считается приемлемым и позволяет смотреть в будущее с оптимизмом.

Этот слайд способен зарядить оптимизмом даже воду из-под крана. Потому что масштабирование на новые страны теперь не является мультиплицирующим фактором по памяти — как и масштабирование на новые площадки. За счет партиционирования оно переводится в горизонтальное масштабирование.
Ну а масштабирование новых пользователей и расширение функциональности онлайн-кинотеатра сводится к росту нагрузки. Чтобы его обеспечить, мы готовы поднять столько легких CPU-bound-сервисов, сколько нужно. С другой стороны, мы накопили достаточное количество знаний в области определения доступности, чтобы с уверенностью ждать новых вызовов. Надеюсь, что мне удалось поделиться с вами частью этих знаний. Спасибо за внимание.
— Начну с того, откуда пошли онлайн-кинотеатры.

По ходу развития интернета появились OTT-медиасервисы, которые стали использоваться для передачи медиаконтента по интернету, в отличие от традиционных медиасервисов, где применялся кабель, спутник и другие каналы связи.
Такие медиасервисы основываются на OVP — online video platform, куда входит система управления контентом, веб-плеер и CDN. Отдельный класс таких систем — OTT-TV, онлайн-кинотеатр, который, помимо OVP, реализовывает системы контроля и управления доступом к контенту, систему защиты прав цифрового контента, управление подписками, покупками, разнообразные продуктовые и технические метрики. И предъявляет к этим системам повышенные требования по аптайму и задержкам.
Я расскажу о бэкенде, который отвечает за систему управления контентом, за пользовательскую функциональность онлайн-кинотеатра и за часть системы управления и контроля доступа к контенту.
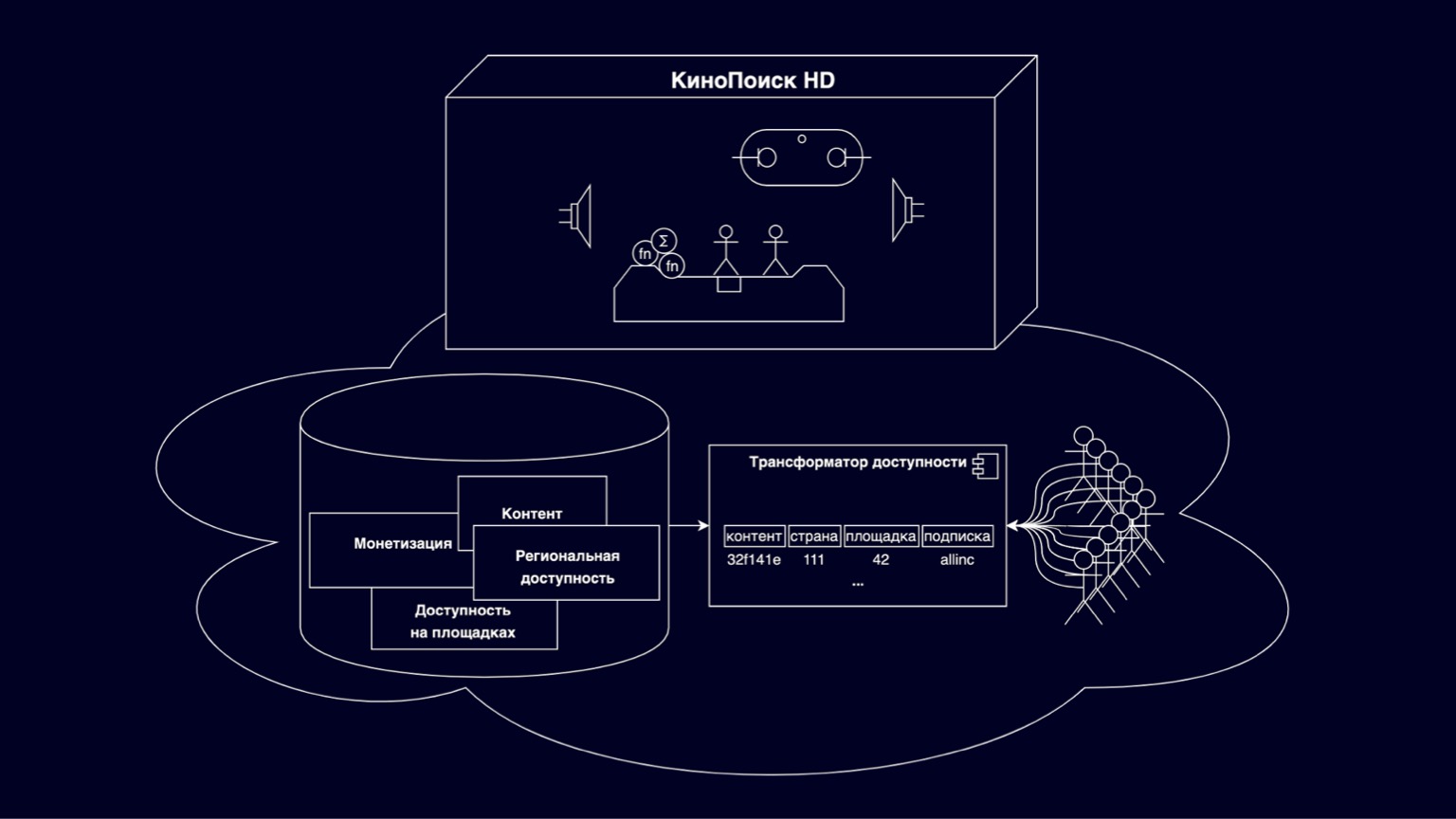
Посмотрим, из чего состоят онлайн-кинотеатры. В параллелепипеде КиноПоиск HD реализованы всякие прикольные штуки и режимы просмотра. Пользователи тысячами RPS выбирают доступный контент на витринах, оформляют подписки и покупки. Сохраняют прогресс просмотра, пользовательские настройки. Тысячами RPS генерируют различные метрики. Это довольно большой и интересный набор компонентов, в подробности которых мы сегодня углубляться не будем. Но стоит упомянуть, что в целом это хорошо и понятно масштабируемые сервисы — за счет того, что они шардируются по пользователям.
Сегодня мы сконцентрируемся на облаке под параллелепипедом. Это платформа, отвечающая за хранение фильмов, сериалов, различных ограничений от правообладателей. Поддерживается усилиями нескольких отделов. Частью этой платформы является трансформатор доступности, который отвечает на вопросы, что я могу посмотреть прямо сейчас в этом месте. Без трансформатора доступности на КиноПоиске HD буквально не появится никакой контент.
Задача трансформатора — перевод гибкой и многоуровневой модели доступности в эффективную модель, которая хорошо масштабируется на как можно большее количество потребителей контента.
Почему она гибкая и масштабируемая? В первую очередь потому, что туда входят различные сущности, описывающие контент, монетизацию, реляционную доступность, доступность на площадках. Все это состоит в революционных отношениях, имеет сложную иерархию. И эта гибкость нужна для того, чтобы обеспечить требования десятков правообладателей и различные гибкие возможности по ценовой политике.
Под площадками мы понимаем, например, онлайн-кинотеатр в вебе, онлайн-кинотеатр на устройствах и другие партнерские ОТТ-сервисы, также проигрывающие наш контент.
Понятно, что для эффективного подсчета доступности такой многоуровневой модели нужно строить сложные джойны, и подобные запросы не масштабируются на какую-либо нагрузку, они достаточно сложны в интерпретации, чтобы на них строить какую-то функциональность быстро и понятно. Чтобы решить эти проблемы, возник трансформатор доступности, денормализующий модель, представленную на слайде, как составной ключ, куда входят айдишники контента, страны, площадки, подписки и некоторый незримый неключевой остаток, который составляет большую часть объема памяти. Как раз о трудностях масштабирования трансформатора доступности мы сегодня и поговорим.
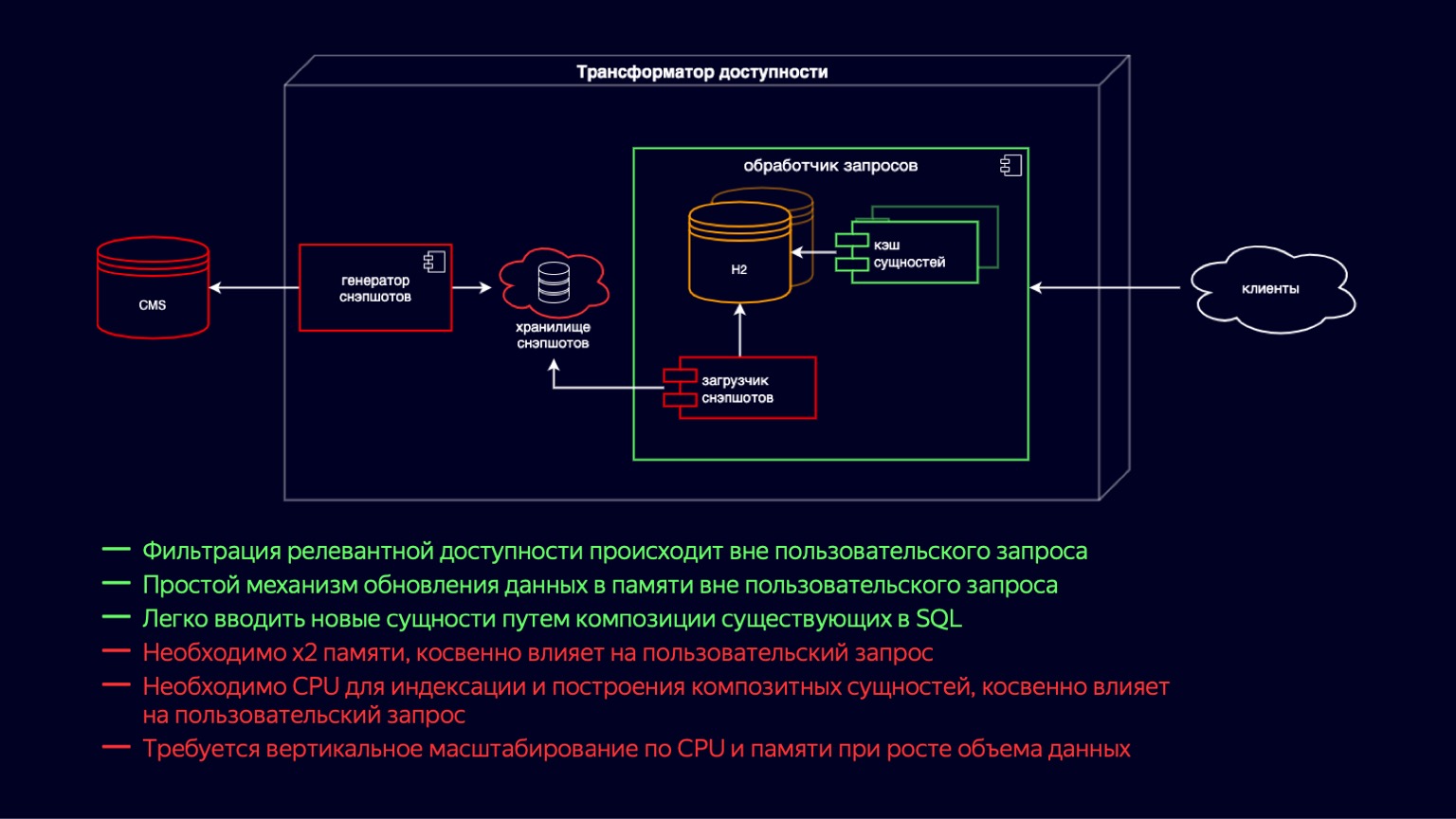
Погрузимся глубже в этот компонент и посмотрим, из чего он состоит. Здесь мы видим состояние системы непосредственно перед началом проблемы. Все это время трансформатор доступности двигался по пути молниеносного развития онлайн-кинотеатра. Важно было быстро запускать новую функциональность, в первую очередь — обеспечить доступность десятков тысяч фильмов и сериалов.
Если идти слева направо, то там CMS, реляционная база данных, в которой в третьей нормальной форме и в EAV хранятся наши основные сущности. Далее загрузчик снэпшотов. Далее генератор снэпшотов, который регулярно получает релевантные данные, фильтрует их, складывает в хранилище снэпшотов. Фактически это SQL-дамп. Дальше внутри инстанса обработчика запросов загрузчик снэпшотов регулярно получает новые данные и импортирует их в H2. H2 — это in-memory-база данных, написанная на Java, которая реализовывает основные возможности СУБД, то есть там есть интерпретатор запросов, оптимизатор запросов, индексы.
Фактически это как раз тот компонент, который обеспечивает гибкость создания новой функциональности онлайн-кинотеатра за счет того, что можно просто писать запросы на SQL и джойнить денормализованные сущности быстро и просто.
H2 обновляется по модели copy-on-write. Загрузчик снэпшотов поднимает новый инстанс базы данных и наполняет его. А потом, после наполнения, утилизирует старый, с помощью garbage collector.
Одновременно с H2 поднимается кэш сущности, куда входят композитные сущности и индекс над ними. Композитные сущности — это, по сути, продолжение денормализации того, что лежит в H2, чтобы обеспечить более требовательные запросы от клиентов по задержкам. Кэш-сущности точно так же обновляются по модели copy-on-write, одновременно с поднятием и новых инстансов H2.
Основные плюсы системы: можно легко и гибко добавлять новую функциональность за счет джойнов. Относительно простая схема обновления данных по copy-on-write. Из минусов — конечно, то, что требуется x2 памяти, чтобы эти сущности хранить и обновлять. Это косвенно влияет на пользовательский запрос, поскольку он утилизируется с помощью garbage collector.
Также во время построения кэша сущности необходим ресурс CPU для индексации. И это точно так же косвенно влияет на пользовательский запрос, но уже за счет конкуренции за ресурсы CPU. Оба этих пункта в совокупности приводят к тому, что при росте объема данных наших основных сущностей требуется вертикальное масштабирование обработчика запросов, как по CPU, так и по памяти.
Но система рассчитывалась на десятки тысяч фильмов и сериалов, доступных онлайн. Поэтому долгое время эти минусы были приемлемыми, позволяли эксплуатировать основной плюс по гибкости и легкости введения новый функций онлайн-кинотеатра.
Понятно, что все это работало до определенного момента. Представим, что этот желтый автобус — наш трансформатор доступности.

В нем едут фильмы и сериалы, размноженные по денормализации, то есть их десятки тысяч. И на одной из остановок нужно поднять на борт сотни тысяч музыкальных клипов и трейлеров и тоже их как-то разместить. Поднявшись на борт, они тоже размножатся за счет денормализации. Тем, кто находится внутри, нужно ужаться, а тем, кто снаружи, надо запрыгнуть, протиснуться. Можете себе представить, как это происходит. Технически в этот момент у нас объем памяти на инстансе вырос до десятков гигабайт. Построение кэша и утилизация старых инстансов с помощью garbage collector занимала несколько виртуальных ядер. И поскольку радикально вырос объем данных, вся эта процедура в совокупности привела к тому, что для публикации нового контента требуются десятки минут.
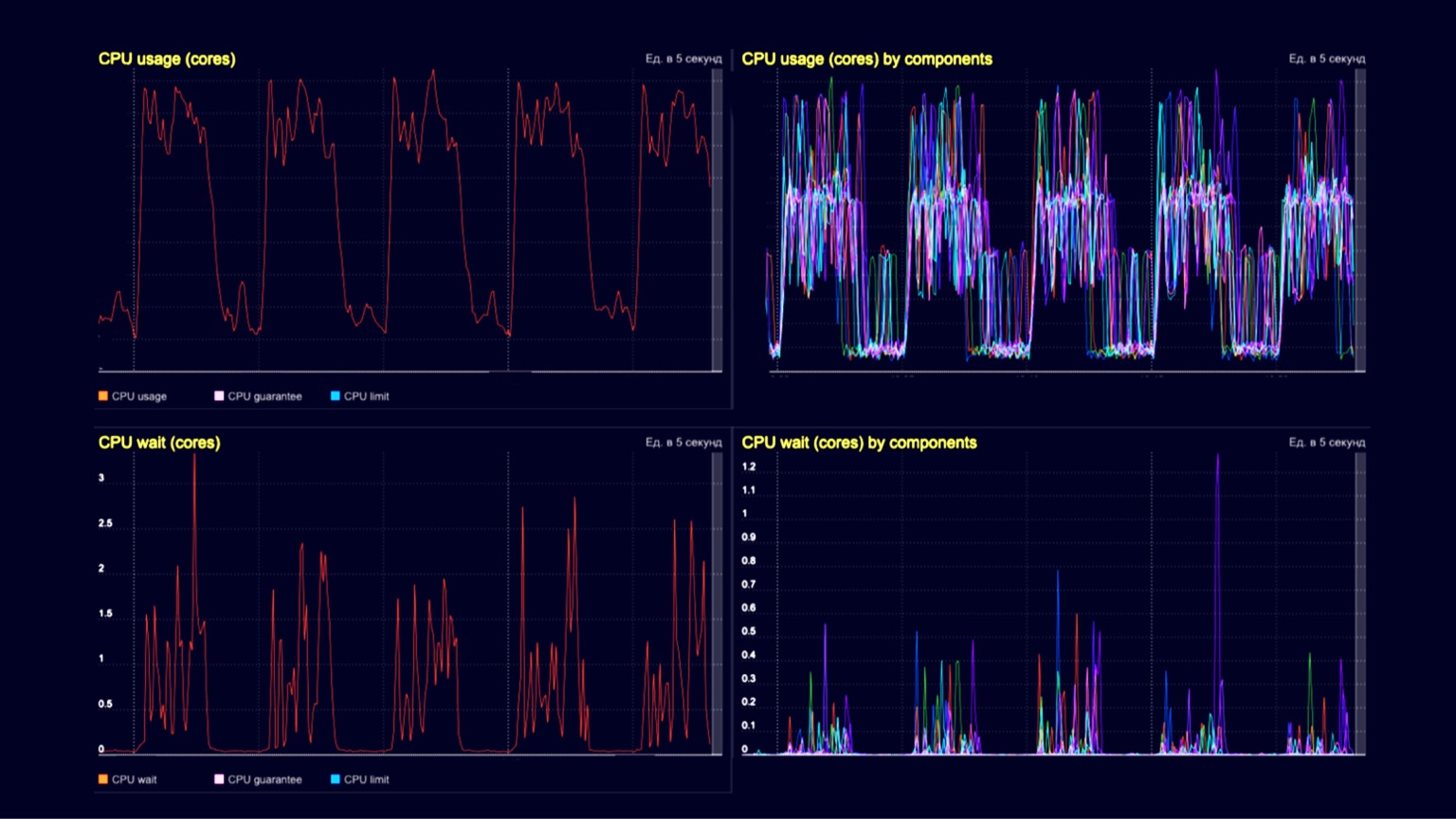
Технически мы видим здесь утилизацию CPU на кластере обработчика запросов. Во впадинах — обработка клиентских запросов порядка нескольких тысяч RPS, а на холмах — те же самые несколько тысяч RPS, плюс та же самая загрузка снэпшотов и их утилизация с помощью garbage collector. Нижние два графика — CPU wait на контейнере. Мы видим, что они тоже начинают себя проявлять в момент загрузки снэпшотов и их утилизации.
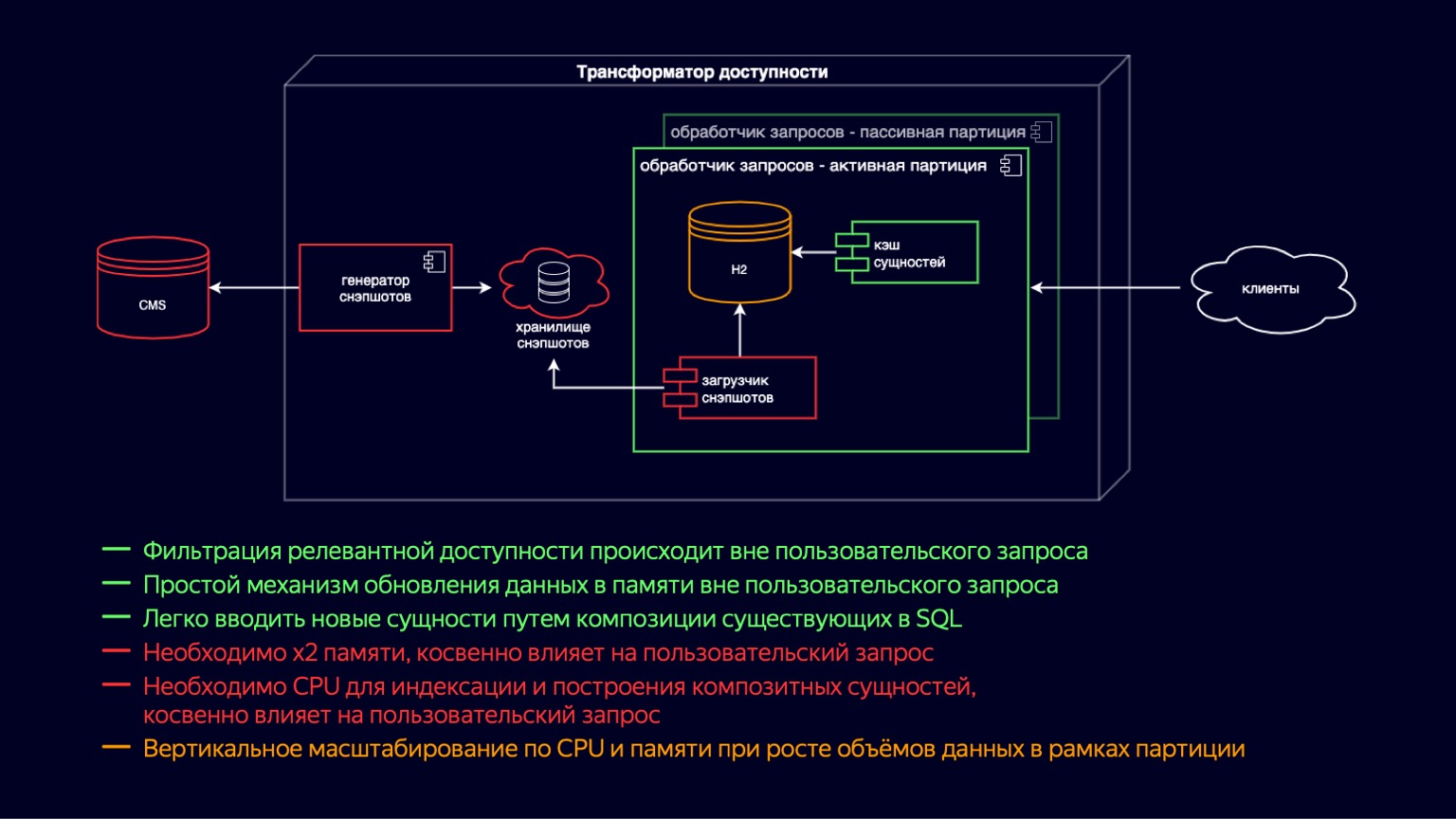
Чтобы разместить эти музыкальные клипы и трейлеры и продолжать масштабирование, мы ввели активные и пассивные инстансы обработчика запросов. Фактически это перенос copy-on-write на уровень выше. Теперь у нас в контейнере одновременно активный и пассивный инстанс. Пассивный готовит новый H2 и кэш сущностей, а активный просто обрабатывает запросы пользователей. Тем самым мы снизили влияние garbage collection, его пауз на обработку пользовательских запросов. Но при этом, поскольку они все еще живут в одном контейнере, загрузка снэпшотов и построение кэша все еще конкурирует за ресурсы CPU, и влияние на пользовательские запросы все еще есть.
Мы дополнительно ввели партиционирование по площадкам. Это обеспечивало нам сокращение памяти на тех площадках, где не нужны все эти новые типы контента. Например, онлайн-кинотеатру это позволило не загружать музыкальные клипы и трейлеры, и снизить влияние. Но при этом для площадок, которым нужно обеспечивать весь контент доступностью, конечно, ничего не поменялось.
Поэтому плюсы и минусы схемы остались примерно такими же, как раньше. Но за счет партиционирования вертикальное масштабирование по CPU и памяти переехало на площадки, и это позволило некоторым площадкам продолжить масштабироваться. По сравнению с прошлой схемой публикации контента это никак не поменялось. Он в целом занимал те же десятки минут, поэтому мы продолжали искать пути оптимизации.

Что мы к э тому моменту поняли? Что запросы онлайн-кинотеатра используют малую часть возможностей СУБД. Интерпретатор и оптимизатор запросов со временем выродился в кэш сущностей. Мы поняли, что определение доступности в целом универсально. Запросы отличаются тем, что нужно понять доступность единицы контента или списка и к этой доступности приклеить дополнительные атрибуты. В целом это можно делать без полноценной СУБД.
И второе: часть составного ключа — это низкокардинальные параметры. Стран — десятки, в пределе пара сотен, площадок — десятки, а подписок единицы. Скорее всего, денормализация в полном объеме не требуется. Оба этих вывода привели к тому, что мы стали двигаться в сторону более компактного и менее денормализованного представления в памяти, но которое при этом все еще быстро отвечает на запросы пользователей.

На слайде мы видим переход от трансформатора доступности v1 к v2. Здесь схематически изображена новая схема доступности, где составной ключ фактически сводится к тому, что это просто ключ по айдишнику контента. А доступность физически или логически сводится к определению доступности по спискам стран, площадок и подписок.
Тем самым мы уменьшаем объем незримого неключевого остатка, который составляет большую часть памяти, и уменьшаем объем памяти одновременно с ним.
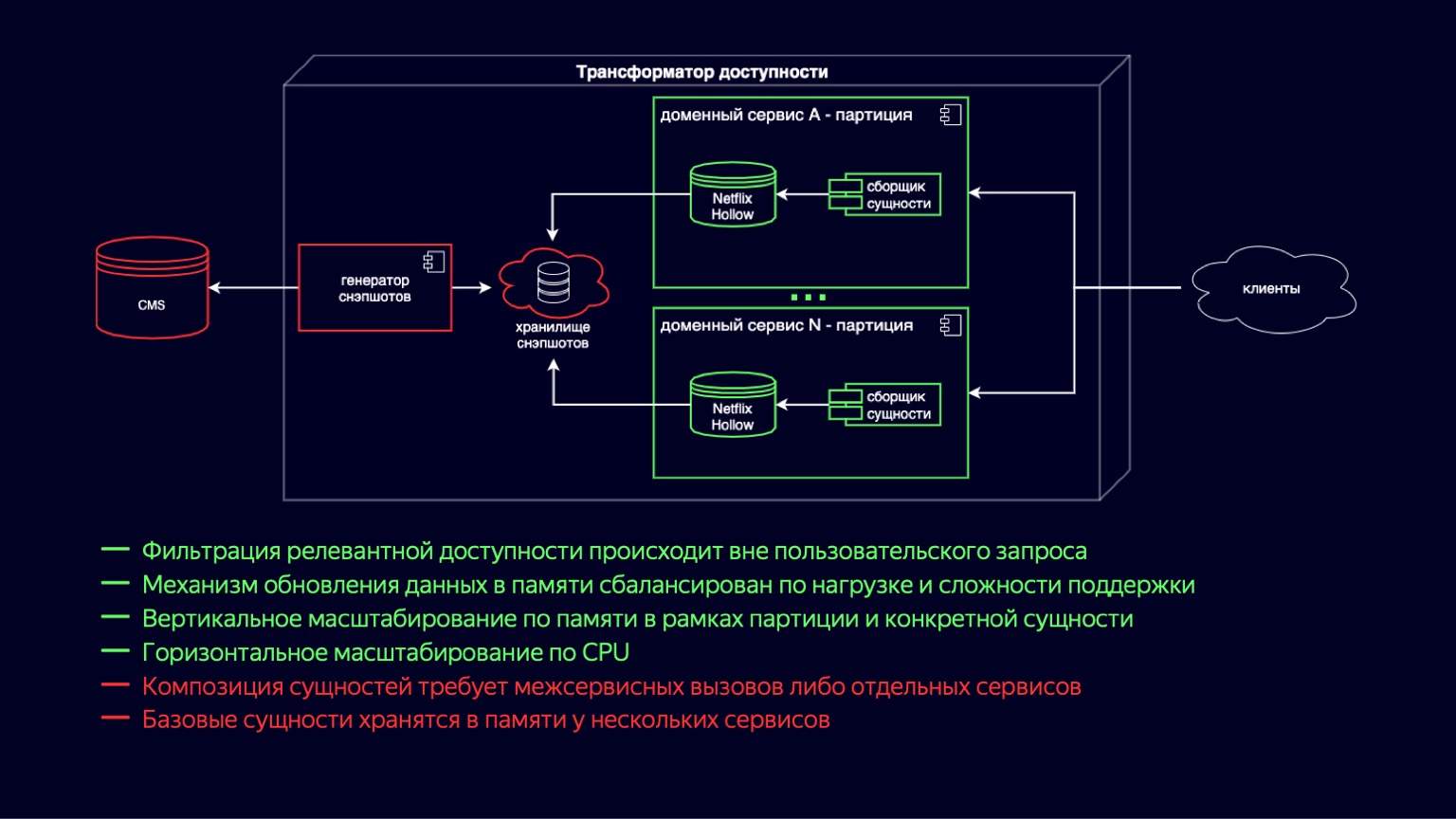
Здесь мы видим процесс перехода к новой схеме трансформатора доступности. Netflix Hollow играет роль поставщика и индексатора базовых сущностей, над которым доменные сервисы на лету собирают сборку композитных сущностей разного масштаба. Это работает, потому что базовые сущности все еще денормализованы и количество джойнов при сборке минимальное. С другой стороны, определение доступности сводится к простым и дешевым циклам и трудностей вызывать не должно.
При этом Netflix Hollow хранит и достаточно бережно относится к нагрузке на CPU и garbage collection, как во время обновления данных, так и во время доступа к ним. Это позволяет снизить холмы, которые мы видели на графиках утилизации CPU и свести их к приемлемому минимуму. Дополнительно, поскольку он реализовывает гибридную схему доставки в виде снэпшотов и диффов к ним, это позволяет увеличить скорость публикации нового контента до единиц минут.
Понятно, что сохранилась большая часть плюсов предыдущей схемы. Механизм обновления данных в памяти стал проще и дешевле по утилизации ресурсов. Вертикальное масштабирование по партициям, по площадкам также дополнилось масштабированием по конкретной сущности, оно теперь дешевле. И поскольку мы снизили накладные расходы на обновление снэпшотов, появилось действительно горизонтальное масштабирование по CPU.
Из минусов в этой схеме — то, что композиция сущностей требует межсервисных вызовов или отдельных сервисов. И все еще присутствует дубликация данных на уровне базовых сущностей, поскольку они теперь хранятся в каждом доменном сервисе, где используются. Но Netflix Hollow хранит данные компактнее, чем H2, а H2 хранит их гораздо компактнее, чем HashMap с объектами. Так что этот минус точно тоже считается приемлемым и позволяет смотреть в будущее с оптимизмом.

Этот слайд способен зарядить оптимизмом даже воду из-под крана. Потому что масштабирование на новые страны теперь не является мультиплицирующим фактором по памяти — как и масштабирование на новые площадки. За счет партиционирования оно переводится в горизонтальное масштабирование.
Ну а масштабирование новых пользователей и расширение функциональности онлайн-кинотеатра сводится к росту нагрузки. Чтобы его обеспечить, мы готовы поднять столько легких CPU-bound-сервисов, сколько нужно. С другой стороны, мы накопили достаточное количество знаний в области определения доступности, чтобы с уверенностью ждать новых вызовов. Надеюсь, что мне удалось поделиться с вами частью этих знаний. Спасибо за внимание.
