
Это конспект лекции Татьяны Денисовой tdenisova — бэкенд-разработчика в Яндекс.Учебнике. Вы узнаете, какие бывают базы данных, какие их особенности важно помнить, как в работе с данными учитывать характеристики системы и планы масштабирования, в какую из тем нужно углубиться для решения конкретной задачи. А также как при возникновении багов определить, является ли работа с БД источником проблемы (и если да, то в какую сторону копать).
— О чем именно мы будем говорить? Не о примитивных селектах и джойнах — о них, я думаю, большинство из вас уже знает.
Мы будем говорить о реальном применении баз, о том, с какими сложностями вы можете столкнуться и что вам как бэкенд-разработчику нужно знать. Информации будет много, вот содержание. Не нужно прямо досконально знать детали каждого из этих пунктов, но нужно знать, что этот пункт существует.

И нужно знать, как какие проблемы решаются, чтобы, когда у вас будет задача построить структуру, сохранить данные, вы знали, какую модель данных выбрать и как их сохранить. Или предположим, у вас проблема, вы видите, что база данных не работает, работает медленно, или возникли проблемы с данными, несогласованность. Тогда вы должны понимать, куда копать. То есть нужно знать, какие понятия существуют и с какой стороны подойти к проблемам.

Сначала мы с вами поговорим о данных. Что это такое вообще? Вокруг нас много фактов, много сведений, но пока они никак не собраны, они для нас бесполезны. Мы их собираем, структурируем и сохраняем. И именно это сохраненное структурирование называется данными, а то, что их хранит, — базой данных. Но пока эти данные просто где-то лежат собранные, они для нас тоже в принципе бесполезны. Поэтому существует прослойка над базами данных — СУБД. Это то, что позволяет нам доставать данные, сохранять их и анализировать. Таким образом, данные, которые мы получаем, мы превращаем в информацию, которую уже можем вывести пользователю. Пользователь получает знания и применяет их.
Мы обсудим, как структурировать сведения и факты, хранить их, в каком виде данных, в какой модели. И как их достать так, чтобы много пользователей одновременно могли обращаться к данным и получить корректный результат, чтобы наши итоговые знания, которые мы будем применять, были правдивыми и верными.
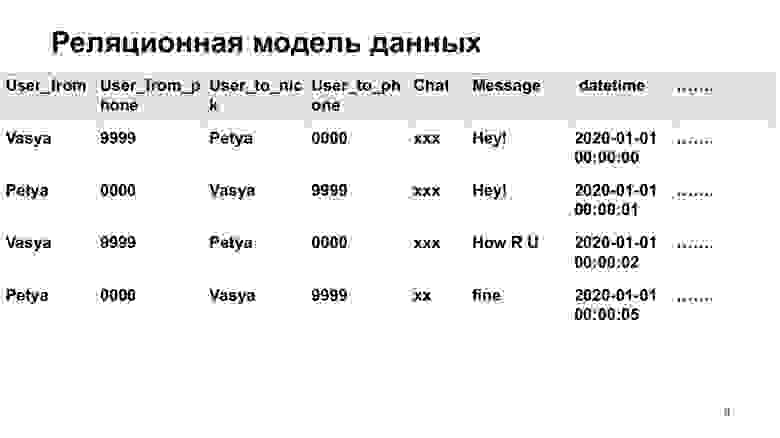
Для начала мы с вами поговорим о реляционных базах данных. Думаю, реляционная модель многим из вас знакома. Это модель типа таблиц и отношений между таблицами. Представим, что у нас есть мессенджер, в который мы записываем данные и сообщения между пользователями. Мы можем их записать все в одну такую большую объемную таблицу, широкую, где у нас будет много повторяющихся данных — от кого, кто, кому, в какой чат. А можем всеэто записать в различные таблицы, то есть нормализовать наши данные, привести в третью нормальную форму.
На слайдах есть примечания и ссылочки. Мы не будем сейчас углубляться в каждое понятие. Я постараюсь технические понятия, которые могут быть вам незнакомы, не говорить. Но все, что я говорю, вы найдете в примечаниях к слайдам. В том числе по нормализации тоже будет ссылочка, вы сможете почитать, если это понятие вам не знакомо.
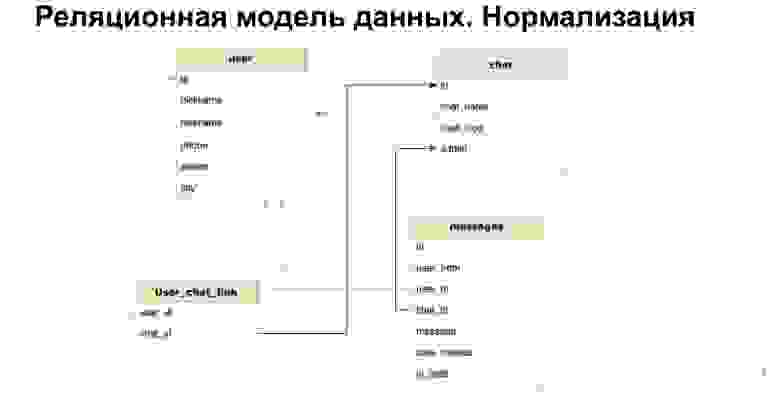
В общих словах, нормализация — это разбиение данных на таблицы с целью, чтобы эти данные стали более структурированы. Например, здесь есть теперь таблица юзера, чата мессенджера и сообщений. Такая структура обеспечивает, что сюда будут записаны сообщения именно тех пользователей, которых мы знаем, и из известных нам чатов. То есть мы обеспечиваем целостность данных. Мы обеспечиваем факт того, что мы всегда можем собрать общую картинку целиком. Но при этом мы храним, например, в таблице сообщений только айдишники, только идентификаторы. Таким образом мы сокращаем общий размер базы данных, делаем ее меньше. Соответственно, делаем проще запись в эту БД. Нам не нужно постоянно записывать во много таблиц. Мы просто записываем в одну таблицу с айдишником.

Если говорить про нормализацию, она вообще очень упрощает видение системы, потому что очень графична, и нам сразу становится понятно, какие взаимоотношения между какими таблицами у нас есть.
Мы уменьшаем количество ошибок при записи данных, потому что если мы записываем сообщение в месседжере и такого пользователя у нас еще нет, то нам придется его завести. Но итоговая картина, общие данные у нас останутся целостными.
Про уменьшение размера базы данных я уже сказала. Нам в таблице сообщений не придется каждый раз писать все данные о пользователе. Чтобы посмотреть профиль, мы можем просто зайти в таблицу User.
О несогласованной зависимости также предупредила. Это как раз ссылки на айдишники других таблиц, идентификаторы являются уникальными значениями в рамках одной таблицы. По-другому они называются primary key, и когда у нас есть ссылка на эти primary key, то сама ссылка в другой таблице называется foreign key.
Такая структура также защищает наши данные от случайного удаления. Мы не можем удалить юзера, потому что, например, у него есть сообщение. Это такая небольшая, но подстраховка.
Казалось бы, мы сделали отличную структуру, все понятно, все зависимо, все цельно. С чем еще нужно работать?
Представим, что мы реально запустили это в эксплуатацию, у нас стало много пользователей и, соответственно, много сообщений. Они постоянно друг с другом общаются. Что происходит в нашей таблице сообщений? Она постоянно растет. И чтобы искать в не данные, нам нужно постоянно перебирать абсолютно все сообщения, проверять, от этого пользователя они или нет, в этом чате или нет, и только тогда их выводить.
Естественно, чем больше пользователей, чем больше сообщений, тем дольше будут проходить запросы полного перебора. Нам нужно решение, которое позволит быстро искать сообщения в таблице.
Для такого случая, для ускорения поиска, используют индексы. Самая простая ассоциация с индексами — это содержание в книге. Если вам нужно в книге найти информацию, вы можете просто пролистать книгу, а можете зайти в оглавление. Индексы — это своего рода оглавление.
Есть еще хороший пример с телефонной книжкой. Вы можете нажать на букву на своем телефоне, и вас сразу перекинет ссылочно на фамилии, начинающиеся с этой буквы. Индексы баз данных работают по очень похожему принципу. Давайте посмотрим нашу таблицу с сообщениями и то, как мы эти данные будем доставать.
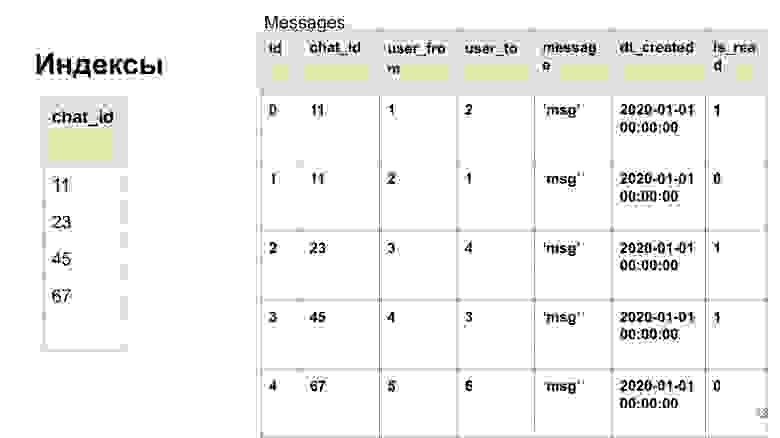
Прошу обратить внимание, как именно мы будем работать с данными. Не с тем, какие у нас есть строки в таблице, а вообще. Индексы строятся по принципу того, какие запросы вы делаете.
Представим, что мы делаем в основном запросы по чату, то есть узнаём, какие сообщения есть в этом чате. Построим индекс именно по столбцу чатов. Индексы в базе данных — это отдельная структура. Таблица от нее не зависима. То есть индекс вы можете в любой момент удалить и перестроить заново, и таблица от этого не пострадает.
Здесь видно, что мы выделили, поставили индекс на столбец, и у нас выделилась отдельная структурка, которая уже немножко сократила количество записей, потому что в 11 чате уже есть несколько сообщений. СУБД обеспечивает быстрый поиск по вот этой маленькой таблице чата. Как это делается? Естественно, поиск происходит не простым перебором. Есть много алгоритмов быстрого поиска, мы с вами рассмотрим один из самых популярных алгоритмов, которые используются по умолчанию в большинстве баз данных. Это сбалансированное дерево.
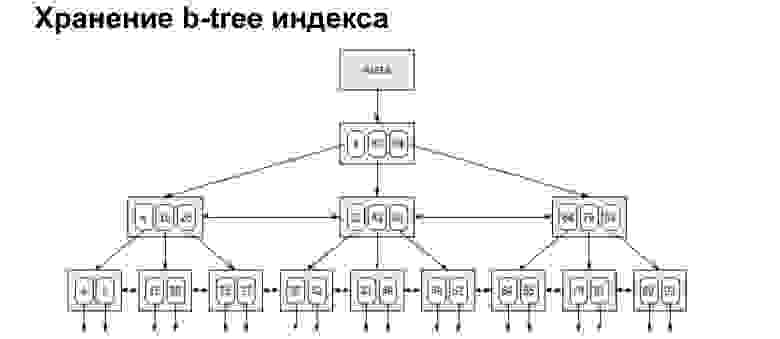
Как оно работает? У нас есть номер чата, это целое значение, и дерево выстраивается по такому принципу: то, что слева от узла значений меньше, справа от узла значений больше. Что нам дает такая структура? Если посмотреть на итоговые листы этого дерева, то все значения внизу упорядочены. Это огромный плюс в приросте производительности. Сейчас покажу, почему.

Например, мы ищем значение. Одно значение искать очень просто. Мы проходим вниз по дереву или влево, вправо — в зависимости от того, больше это значение или меньше.
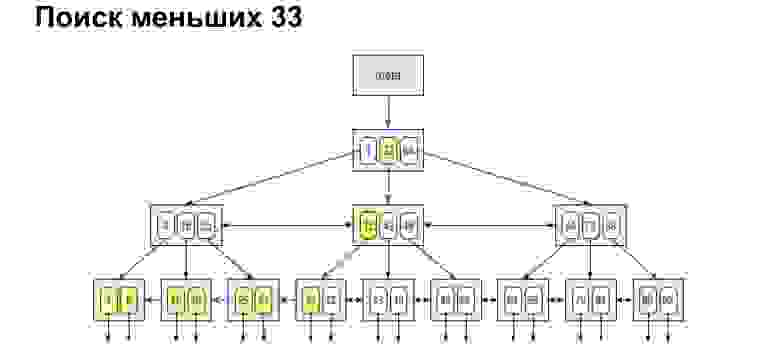
А если мы хотим найти, например, диапазон, то смотрите, как просто и быстро это получается. Мы доходим до значения и дальше по ссылкам в листьях уже по упорядоченным значениям просто идем до конца.

Если нам нужен диапазон, определенный от и до, — делаем абсолютно то же самое. Находим начальное значение и уже по ссылкам листьев идем до максимального значения. Мы по дереву прошли только один раз. Это очень удобно, очень быстро.
Точно так же у нас будут искаться максимальные и минимальные значения. Пройти совсем влево, совсем вправо. Так же у нас будет происходит получение упорядоченного списка. То есть если нам нужно просто получить все чаты упорядоченно, мы доходим до первого и уже по листьям идем до самого правого значения, получаем упорядоченный список. Именно по такому принципу база данных очень быстро ищет в таблице индексов те строчки, которые нам нужны для выборки, и возвращает их.
Что тут важно знать? Казалось бы, классная структура — мы сейчас на каждый столбец построим по такому дереву и будем искать. Как вы думаете, почему это не сработает? Почему у нас не будет прироста скорости, если мы на каждый столбец построим по дереву? (...)
У нас действительно ускорятся селекты. Каждый раз, когда нам нужно пройти по какому-то значению, мы заходим в индекс, находим там ссылку на сами значения. Индексы, как правило, содержат именно ссылки на строки, а не сами строки. И для селектов это работает идеально. Но как только мы захотим задать данные таблицы, проапдейтить либо удалить данные, то все эти деревья придется перестраивать.
На самом деле удаление не перестроит, а просто фрагментирует это дерево, и у нас получатся много пустых значений. Будет огромное дерево с пустыми значениями. Но именно при update и при create эти деревья каждый раз будут перестраиваться. В итоге мы получим огромный overhead над всех этой структурой. И вместо того, чтобы быстренько достать данные и ускорить базу данных, мы будем замедлять наши запросы.

Что еще важно знать? Когда вы будете работать с базой, посмотрите, почитайте, какие индексы в ней существуют, потому что в каждой базе свои реализации, свои разные индексы. Есть индексы для ускорения, есть индексы для обеспечения целостности. Один из самых простых — как раз primary key. Это тоже индекс уникальности. И относительно вашей базы смотрите, как он устроен, как с ним работать, потому что это такие знания, которые вам помогут писать наиболее оптимальные запросы.
Мы обсудили, что нужно иметь в виду накладные расходы на поддержание индексов при вставке данных. Забыла сказать, что когда вы выстраиваете индекс, он должен обладать высокой селективностью. Что это значит?
Посмотрим на это дерево. Мы понимаем, что если стоит индекс на true false, то получается просто два огромных куска дерева слева и справа. И мы проходимся в лучшем случае по 50% таблицы, что на самом деле не очень эффективно. Лучше всего делать индекс именно на те столбцы, у которых наиболее разные значения. Таким образом мы ускорим наши выборки.
Про фрагментацию я сказала, при удалении данных ее нужно иметь в виду. Если у нас часто проходит удаление по данным, содержащимся в индексе, то его, возможно, придется дефрагментировать, и за этим тоже нужно следить. Также важно понимать, что вы строите индекс исходя не из того, какие у вас столбцы, а из того, как вы эти данные используете. И запросы, которые включают индексы, нужно писать очень аккуратно. Что значит аккуратно? Когда вы пишете запрос, отправляете его в базу данных, он отправляется не напрямую в базу, а в некую программную прослойку, которая называется планировщиком запросов.
Планировщик имеет у себя определенную таблицу соответствия того, какая операция сколько стоит и насколько она дорогая. В примере с PostgreSQL есть специальные технические таблицы, которые собирают информацию о ваших данных, о ваших таблицах. Планировщик смотрит, какой у вас запрос, какие данные хранятся в таблице pg_stat. Это как раз таблица, которая хранит общую информацию о том, сколько у вас данных и какие столбцы в вашей таблице, какие индексы на ней. Исходя из этого он смотрит планы выполнения вашего запроса, считает, сколько времени по какому плану уйдет на запрос, и выбирает самый оптимальный.

Если вы хотите посмотреть прогнозируемое время выполнения вашего запроса, можете использовать операцию Explain. Если хотите фактическое выполнение, можете использовать Explain analyze. Какая разница? Как я и говорила, планировщик изначально рассчитывает время выполнения, исходя из примерного времени на каждую операцию. Поэтому реальное время может отличаться в зависимости от машины и от особенностей ваших данных. Так что если вам нужно именно фактическое выполнение, то, конечно, лучше использовать Explain analyze.
На этом слайде вы можете посмотреть пример. Он показывает, что иногда запросы с учетом вашего столбца, на котором есть индексы, могут использовать не индекс scan, а просто full scan по всей таблице. Это происходит, если у нас невысокая селективность индекса и если планировщик считает, что запрос полным scan по таблице будет выгоднее.
Представим, что у нас есть наш мессенджер и мы хотим в списке чатов, например, показывать имя чата либо количество непрочитанных сообщений. Если мы каждый раз, открывая чатик, будем пересчитывать все данные по всем чатам, это будет очень невыгодно.
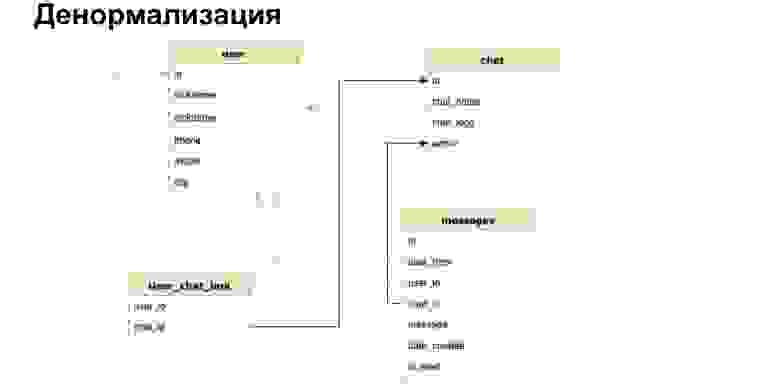
Есть такое понятие — денормализация. Это копирование наиболее горячих используемых данных либо предрасчет нужных данных и сохранение их в таблицу.
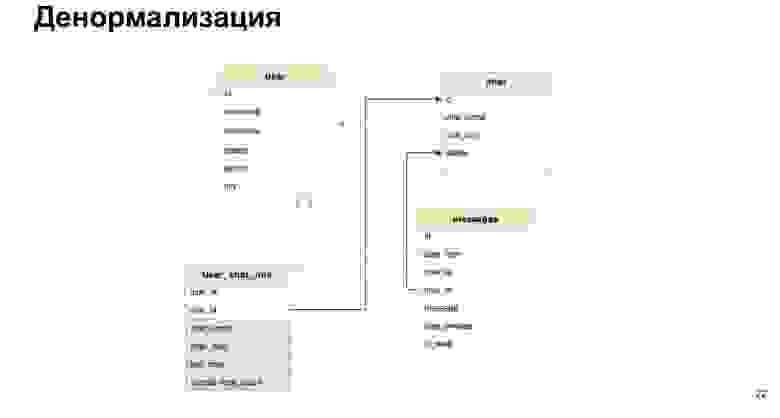
Так может выглядеть соотношение юзера с чатом. То есть помимо ID юзера и ID чата мы кратко туда сохраним имя чата, лог чата и количество непрочитанных сообщений. Таким образом нам каждый раз не нужно будет нагружать все наши таблицы, делать селект и все это пересчитывать.

В чем плюс денормализации? Мы ускоряем процесс выборки данных. То есть наши селекты проходят максимально быстро, мы максимально быстро отдаем пользователям ответ.
Сложность в том, что каждый раз, когда мы добавляем новые данные, нам все эти столбцы нужно пересчитывать и очень велика вероятность ошибки. То есть если наши селекты становятся гораздо проще и нам не нужно все время джойнить, то наши update и create становятся очень громоздкими, потому что нам нужно повесить туда триггеры, пересчитать и ничего не забыть.
Поэтому денормализацию нужно использовать, только когда она вам действительно нужна. И как мы сейчас шли по вот этой всей логике, сначала нужно данные нормализовать, посмотреть, как вы их будете использовать, настроить индексы. Если у вас есть запросы, которые, как вы считаете, плохо работают, то перед денормализацией посмотрите Explain. Узнайте, как они реально выполняются, как планировщик их выполняет. И только потом, когда вы уже придете к тому, что денормализация все-таки нужна, тогда вы можете ее сделать. Но такая практика есть, и в реальных проектах денормализация данных достаточно часто используется.
Пойдем дальше. Даже если вы хорошо структурировали данные, выбрали модель данных, собрали, все денормализовали, придумали индексы, — все равно очень многое в IT-мире может пойти не так.
Может отказать ПО, может выключиться электроэнергия, может отказать аппаратное обеспечение или сеть. Есть и второй класс проблем: нашими базами данных одновременно пользуется очень много пользователей. Они могут одновременно обновлять одни и те же данные. Все эти проблемы мы должны уметь решать.
Давайте посмотрим на конкретных примерах, о чем идет речь.
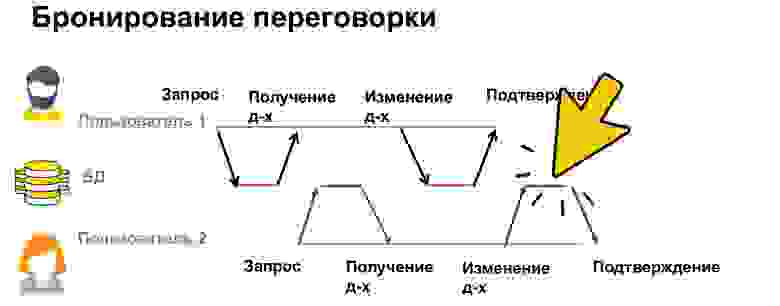
Представим, что есть два пользователя, которые хотят забронировать переговорку. Пользователь 1 видит, что переговорка в это время свободна, и начинает ее бронировать. У него открывается окошко, и он думает, кого же из коллег я позову. Пока он думает, пользователь 2 тоже видит, что переговорка свободна, и открывает себе окошко редактирования.
В итоге, когда пользователь 1 сохранил эти данные, он ушел и думает, что все отлично, переговорка забронирована. Но в это время пользователь 2 перезаписывает его данные, и получается так, что переговорка закрепилась за пользователем 2. Это называется конфликтом данных. И мы должны уметь показывать эти конфликты людям и как-то их разрешать. Именно в этом месте у нас будет перезапись.

Как это сделать? Мы можем просто заблокировать переговорку на какое-то время, пока пользователь 1 думает. Если он сохранил данные, то пользователю 2 мы не разрешим это делать. Если он данные отпустил и не стал сохранять, то пользователь 2 сможет забронировать переговорку. Подобную картину вы могли видеть, когда покупаете билеты в кино. Вам дается 15 минут на то, чтобы оплатить билеты, иначе они вновь предоставляются другим людям, которые тоже могут их взять и оплатить.
Вот другой пример, который нам покажет, насколько важно следить, чтобы наши операции выполнялись полностью. Допустим, я хочу с банковского счета 1 перекинуть деньги на счет 2. В этом моменте у меня есть три операции. Я проверяю, что у меня достаточно средств, вычитаю со своего первого счета средства и кидаю на второй счет. Понятное дело, что если в любой из этих моментов у меня произойдет сбой, то что-то пойдет не так.
Например, если вот на этом этапе произойдет другая транзакция, которая считывает данные, то средств на моем счете будет уже недостаточно, я не смогу выполнить другие операции. Если на втором моменте произойдет проблема, то мы, например, сняли с одного счета деньги, а на второй не закинули. Получается, что в итоге на моем банковском счету, на всех моих счетах станет на какую-то сумму меньше. Эти деньги уже никак не вернуть.
Для решения таких проблем существует понятие транзакции — атомарного, целостного выполнения всех трех операций одновременно.
Как это делает база данных? Она записывает все эти изменения в определенный журнал и применяет их, только когда у нас транзакция коммитится. Таким образом мы гарантируем, что все вот эти операции будут выполнены как единое целое либо не будут выполнены вовсе.
Если в любой момент этого времени у нас произойдет сбой, то с первого счета не будут вычтены деньги и, соответственно, мы их не потеряем.
У транзакций есть четыре свойства, четыре требования к ним. Это Atomicity, Consistency, Isolation и Durability — атомарность, согласованность, изоляция и сохраняемость данных. Что это за свойства?
Поговорим побольше про изоляцию. Изолированность транзакций — очень дорогое свойство, на него тратится очень много ресурсов, из-за этого у нас в базах существует несколько уровней изоляции. Давайте посмотрим, какие проблемы могут быть, и исходя из этого уже обсудим, как их решать.
Существует четыре основных класса проблем — потерянное обновление, «грязное» чтение, неповторяющееся чтение и фантомное чтение. Рассмотрим подробнее.
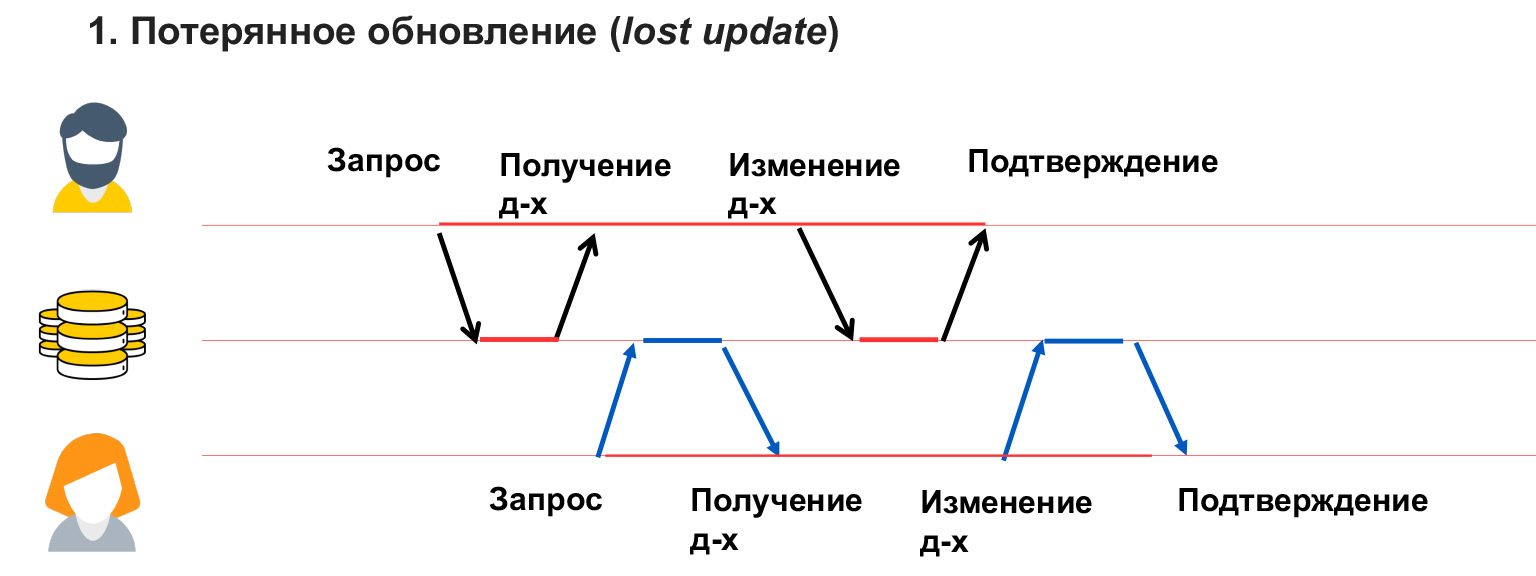
Потерянное обновление — это как в примере с переговорками, когда у пользователя 1 перезаписались данные и он об этом не знает. То есть мы не блокировали данные, которые этот пользователь изменяет, и, соответственно, получили их перезапись.

Проблема «грязного» чтения возникает, когда пользователь видит временные изменения другого пользователя, которые потом могут быть откатаны или просто сделаны временно.
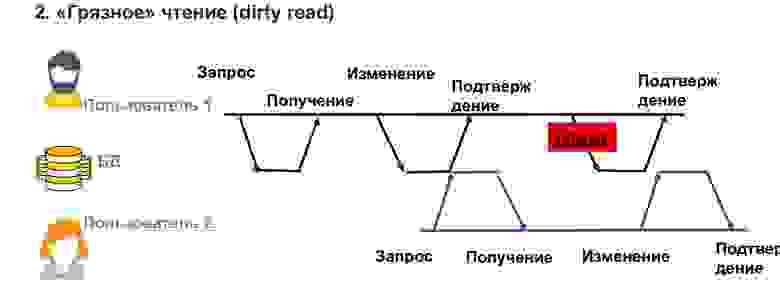
В данном случае пользователь 1 что-то записал в базу данных. Пользователь 2 в это время что-то оттуда считал и строит аналитику по этим данным. А пользователь 1 столкнулся с ошибкой, несоответствием и эти данные откатывает. Таким образом, аналитика, которую записал пользователь 2, будет ненастоящая, неверная, потому что уже нет тех данных, исходя из которых он ее рассчитывал. Такую проблему тоже нужно уметь решать.
Неповторяемое чтение — это когда у нас у пользователя 1 долгая транзакция. Он выбирает данные из базы, а в это время пользователь 2 изменяет часть тех же самых данных.
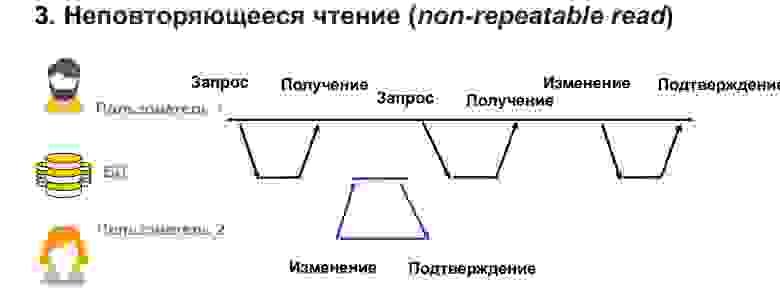
В данном случае получается, что пользователь 1 не заблокировал изменения тех данных, которые у него есть. И несмотря на то, что он сам получил слепок данных, при повторном запросе на тот же самый селект он может получить другие значения в этих строках. Таким образом, у него будет конфликт, несоответствие данных, которые он записывает.
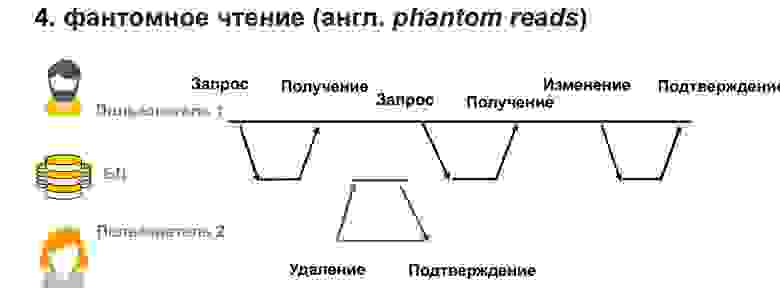
Похожая проблема может быть, если пользователь 2 добавил или удалил данные. То есть пользователь 1 сделал запрос, а потом при повторном запросе этих же самых данных у него появились или пропали строки. В этом случае в рамках транзакции очень сложно понять, что с ними делать, как их вообще обрабатывать.

Чтобы решать эти проблемы, есть четыре уровня изоляции. Первый, самый низкий уровень — Read uncommitted. Это то, что в PostgreSQL описывается как No lock. Когда мы читаем или пишем данные, мы не блокируем другим пользователям ни чтение, ни запись этих данных. Получается, что мы не блокируем никакие изменения. Все четыре перечисленные проблемы по-прежнему могут произойти. Но от чего защищает этот уровень изоляции? Он гарантирует, что все транзакции, которые пришли в базу данных, будут выполнены. Если два пользователя одновременно начали выполнять запросы с одними и теми же данными, то обе эти транзакции будут выполнены последовательно.
Для чего это может быть полезно? Этот уровень изоляции очень редко используется в практике, но он может быть полезен, например, когда есть большой аналитический запрос и вы хотите во втором запросе почитать и посмотреть, на каком этапе находится ваша аналитика, какие данные уже записаны а какие нет. И тогда второй запрос — который для дебага, отладки, проверки — вы запускаете как раз в таком уровне изоляции. И он видит все изменения вашего первого аналитического запроса, которые в итоге могут быть откатаны. Или не откатаны, но в текущий момент вы можете посмотреть состояние системы.

Read committed, чтение фиксированных данных. Этот уровень изоляции используется по умолчанию в большинстве реляционных баз, в том числе и в PostgreSQL, и в Oracle. Он гарантирует, что вы никогда не прочитаете «грязные» данные. То есть другая транзакция никогда не видит промежуточных этапов первой транзакции. Преимущество в том, что это очень хорошо подходит для маленьких коротких запросов. Мы гарантируем, что у нас никогда не будет ситуации, когда мы видим какие-то части данных, недописанные данные. Например, увеличиваем зарплату целому отделу и не видим, когда только часть людей получили прибавку, а вторая часть сидит с неиндексированной зарплатой. Потому что если у нас будет такая ситуация, логично, что наша аналитика сразу «поедет».
От чего не защищает этот уровень изоляции? Он не защищает от того, что данные, которые вы проселектили, могут быть изменены. В случае небольших запросов этого уровня изоляции вполне достаточно, но для больших, долгих запросов, сложной аналитики, естественно, можно использовать более сложные уровни, которые блокируют ваши таблицы.
Уровень изоляции Repeatable read защищает от первых трех проблем, которые мы с вами обсуждали. Это и потерянное обновление, когда перезаписали нашу переговорку; «грязное» чтение — чтение незафиксированных данных; и это неповторяющееся чтение — чтение данных, обновленных другими транзакциями.

Как оно обеспечивается? С помощью блокировки таблицы, то есть блокировки нашего селекта. Когда мы берем селект в нашу транзакцию, то получается как будто слепок данных. И мы в этот момент не видим изменений других пользователей, все время работаем именно с этим слепком данных. Минус в том, что мы блокируем данные и, соответственно, у нас меньше параллельных запросов, которые могут работать с данными. Это очень важный аспект. И вообще, почему этих уровней изоляции так много?
Чем выше уровень, тем больше блоков и меньше пользователей, которые параллельно могут работать с базой. Каждая транзакция видит определенный слепок данных, который не может меняться. Но могут появиться новые данные. Так что этот уровень изоляции нас не спасает от появления новых данных, которые подходят под селект.
Есть еще один уровень изоляции — сериализация. Часто ее называют упорядочиваемостью. Это полная блокировка данных в таблице. Она спасает от фантомного чтения, то есть от чтения как раз тех данных, которые у нас добавились или удалились, потому что мы блокируем таблицу, не разрешаем в нее писать. И выполняем наши запросы целостно.

Это очень полезно для сложных, больших аналитических запросов, в которых очень важна точность и целостность данных. Не получится так, что мы в какой-то момент считали данные пользователя, а потом в другой таблице появились новые статистики и получился рассинхрон.
Это самый высокий уровень изоляции. Здесь самое большое количество блокировок и самая маленькая возможность параллелизации запросов.
Что нужно знать о транзакциях? Что они нам упрощают жизнь, потому что реализованы на уровне СУБД и нам нужно только правильно делать наши запросы, правильно их формировать, так, чтобы данные в итоге были согласованы. И чтобы блокировать именно те данные, с которыми наши пользователи работают. Нужно иметь в виду, что плохо блокировать всё и везде. В зависимости от того, какая у вас система и кто сколько читает/пишет, у вас будет разный уровень изолированности. Если вам нужна максимально быстрая система, которая допускает какие-то ошибки, вы можете выбрать минимальный уровень изоляции. Если у вас банковская система, которая должна гарантировать, что данные согласованы, все выполнено и ничего не потерялось — тогда, конечно, нужно выбирать максимальный уровень изоляции.
Мы уже достаточно классно продвинулись в понимании того, как выстраивать структуру базы данных и что может произойти. Пойдем дальше.
Насколько безопасно хранить одну базу данных. Конечно, не безопасно. Если с ней что-то случается, мы теряем все данные. Если есть бекап, мы можем его накатить, но тогда возникнет время простоя системы. Если у нас ломается сеть или узел становится недоступен, система тоже будет какое-то время находиться в простое, в downtime.
Как это можно разрешить? Есть такое понятие — репликация. Это дублирование базы данных на другие узлы и серверы.

Это именно дублирование полностью, копия базы данных. Как мы можем этот механизм использовать?
Во-первых, если с БД что-то случилось, мы можем перенаправить запросы на другую копию базы данных, что в принципе логично. Это основное применение. Как еще мы можем это использовать?
Представим, что пользователь находится далеко от сервера. Мы можем распределить серверы так, чтобы покрывать максимальное количество пользователей и максимально быстро отдавать им запросы. На каждом из этих серверов будет одинаковая с другими копия, но запросы будут возвращаться пользователям быстрее.

Еще одно очень популярное использование — распределение нагрузки. Так как у нас одинаковые копии данных, мы можем читать не из головы, не из одной базы данных, а из разных. Таким образом мы разгружаем наш сервер.

Также у нас есть понятие OLTP-запросов и OLAP-запросов. Что это такое? OLTP — короткие транзакционные запросы. OLAP — долгая аналитика. Это когда мы берем огромный джойн, огромный селект, всё мёржим и нам очень важно, чтобы в этот момент все данные были залочены, чтобы не было никаких изменений и БД была целостна.
Для таких ситуаций можно делать аналитику на отдельной копии базы данных. Так мы не будем аффектить наших пользователей, они смогут тоже делать записи в базу, просто потом эти записи придут и на нашу копию.
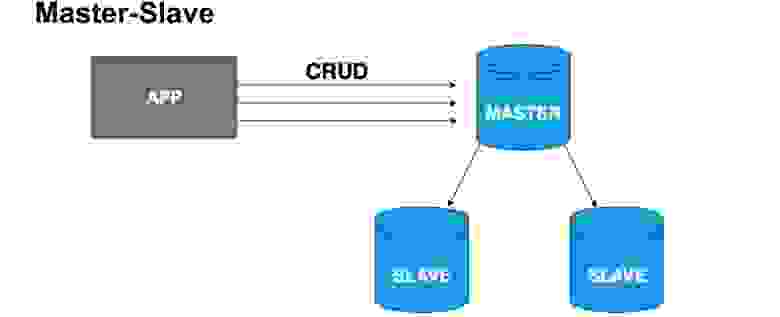
Чтобы грамотно распределить копии баз данных, вводится понятие ведущего узла и ведомого узла, Master и Slave. Slave очень часто называют репликой либо follower. Master — узел, в который наш пользователь, наше приложение пишет. Master применяет все изменения, ведет журнал изменений, и этот журнал отправляет на Slave. Slave не принимает изменения от пользователей, а применяет лишь изменения журнала от Master. Прошу заметить, что Master не отправляет каждый раз копию, а отправляет именно изменения. Slave накатывает эти изменения и получает такую же копию данных, как и в Master.
Очень важный параметр реплицируемой системы — синхронно или асинхронно выполняются запросы. Что такое синхронный запрос? Это когда Master отправляет запрос на синхронную реплику, на синхронный Slave, и ждет, когда Slave скажет: «Да, я принял», — и вернет Master подтверждение. Только тогда Master вернет пользователю ответ. Если же реплика асинхронная, то Master отправляет запрос на реплику, но сразу говорит пользователю, что «Всё, я записал». Давайте посмотрим, как это работает.
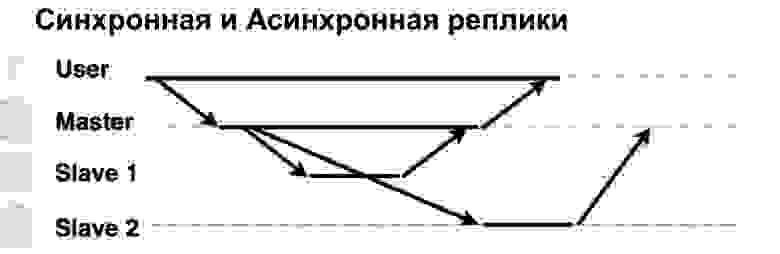
Есть юзер, который записал данные в Master. Master отправил их на две реплики, подождал ответа от синхронной реплики и сразу дал ответ пользователю. Асинхронная реплика записала и сказала Master: «Да, все окей, данные записаны».
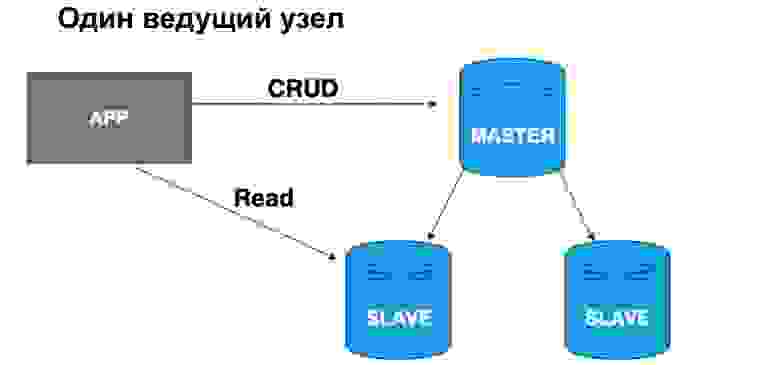
С точки зрения такой иерархии, Master и Slave, у нас может быть одна голова или несколько. Если у нас один ведущих узел, в него очень удобно писать, а читать можно из синхронной реплики. Почему именно из синхронной? Потому что синхронная реплика с максимальной точностью гарантирует, что в ней актуальные данные.
Когда к данным применяется запрос, операция из журнала, это тоже требует времени. Поэтому, если вам важна стопроцентная точность данных, которые вы хотите получить, вы должны ходить за чтением, за селектом в Master. Если вам не критично, что данные могут прийти с небольшим опозданием, вы можете читать из синхронного Slave. Если вам абсолютно не критична актуальность данных, вы можете читать в том числе из асинхронной реплики, тем самым разгружая Master и синхронную реплику от запросов.
В репликации также может быть несколько ведущих узлов. Разные приложения могут писать в разные головы, и эти Master потом между собой разрешают конфликты.
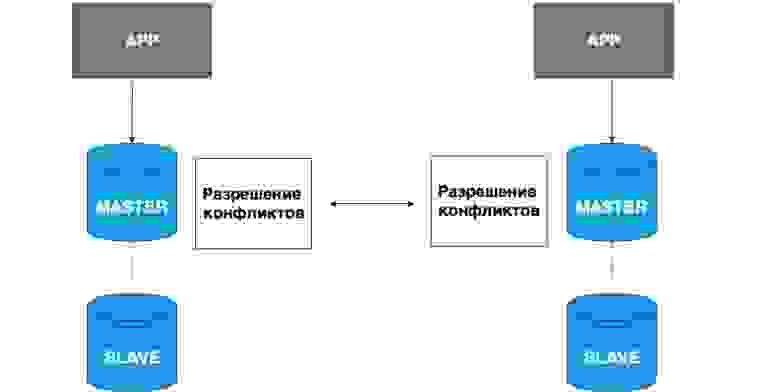
Очень простой пример применения таких данных — всякие офлайн-приложения. Например, на вашем телефоне есть календарь. Вы отключились от сети и записали в календарь событие. В данном случае ваше локальное хранилище, ваш телефон, — это Master. Он сохранил в себе данные, и при появлении сети Master вашей локальной копии и копия, которая на сервере, разрешат конфликты, объединят эти данные.
Это очень простой пример такой репликации. Она часто применяется для совместного редактирования онлайн-документов, либо когда очень велика вероятность потери сети.
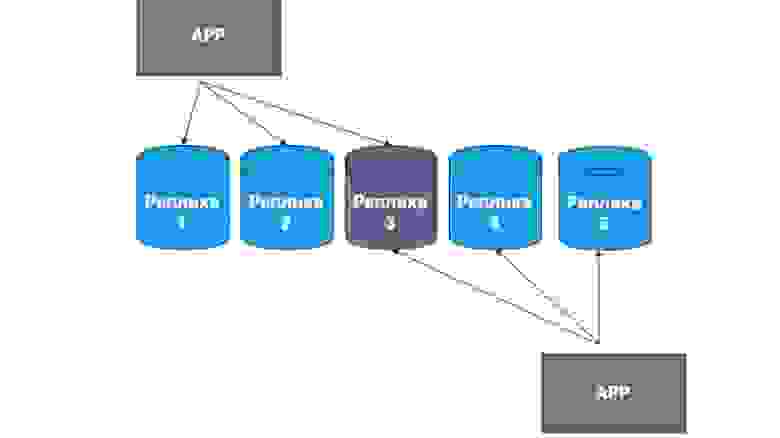
Также существуют репликации без ведущих узлов. Что это такое? Это репликация, при которой сам клиент отсылает данные на бóльшую часть реплик и читает их тоже из бóльшей части реплик. Здесь видно, что серединная реплика у нас является пересечением наших Read и update.
То есть мы гарантируем, что каждый раз, читая данные, мы попадем хотя бы в одну из реплик, в которой данные самые актуальные. А между собой у реплик выстраивается механизм обмена информаций с основным логом изменений и конфликтов между репликами. В данном случае очень часто реализовывают именно толстый клиент. Если он получил данные от реплики, в которой лежат более поздние изменения, чем в другой, то он просто отправляет данные на другую реплику либо разрешает конфликт.

Что важно знать про репликацию? Основной смысл репликации — отказоустойчивость системы, высокая доступность вашего сервера. Что бы ни случилось с базой, система будет доступна, ваши пользователи смогут писать данные, и когда восстановится соединение с Master или с другой репликой, то все данные тоже будут восстановлены.
Репликация очень помогает разгрузке серверов и перераспределению запросов чтения с Master на реплики. Мы можем масштабировать это чтение, создавать больше реплик на чтение и делать нашу систему еще быстрее. Еще можно сделать реплику на сложные долгие аналитические запросы, которые требуют большого количества блокировок и могут повлиять на доступность системы.
На примере офлайн-приложений мы с вами посмотрели, как можно такие данные хранить и разруливать конфликты. В случае синхронной реплики может быть Replication lag, то есть отставание по времени. В случае асинхронной реплики он есть практически всегда. То есть когда вы читаете данные из асинхронной реплики, вы должны понимать, что они могут быть не актуальны.
По иерархии забыла сказать, что когда есть один Master, который ждет ответа от синхронной реплики, логично предположить, что если у нас все реплики синхронны, и какая-то вдруг стала недоступна, то наша система не сможет сохранить запрос. Тогда Master запишет нас в первый синхронный Slave, получит ответ, попросит второй Slave, ответа не получит, и в итоге придется откатывать всю транзакцию.
Поэтому в таких системах, как правило, делают одну реплику синхронной, а остальные асинхронными. Синхронная реплика гарантирует, что ваши данные сохранились еще где-то. То есть помимо Master, с которым может что-то произойти, мы гарантируем, что есть хотя бы еще один узел, который содержит полную копию абсолютно того же журнала транзакций, тех же самых данных.
Асинхронная реплика, с другой стороны, не гарантирует сохранность данных. Если у нас есть только асинхронные реплики и Master отключился, то они могут отставать, туда могли еще не прийти данные. В таких случаях, как правило, выстраивают такую иерархию, что либо у нас Master, одна синхронная реплика и остальные асинхронные, либо у нас Master и все реплики асинхронные, если нам не важна сохраняемость данных.
Есть одно «но»: все реплики должны иметь одинаковую конфигурацию. Если говорить на примере PostgreSQL, они должны иметь одинаковую версию самого PostgreSQL, потому что разные версии базы могут иметь и разный формат журнала операций. И если реплика поднимается из другой версии, она просто может не прочитать операции, которые записала другая база.
Что такое реплика? Это полная копия всех данных. Представим, что данных так много, что сервер не справляется. Какое первое решение?
Первое решение — купить более дорогую машину с большим количеством памяти, с большим CPU, с большим диском. Это решение будет по большей части правильным, пока вы не столкнетесь с проблемой дороговизны железа. Однажды покупать новую машину станет слишком дорого, либо будет уже просто некуда расти. Есть огромное количество данных, которые просто физически невозможно разместить на одной машине.
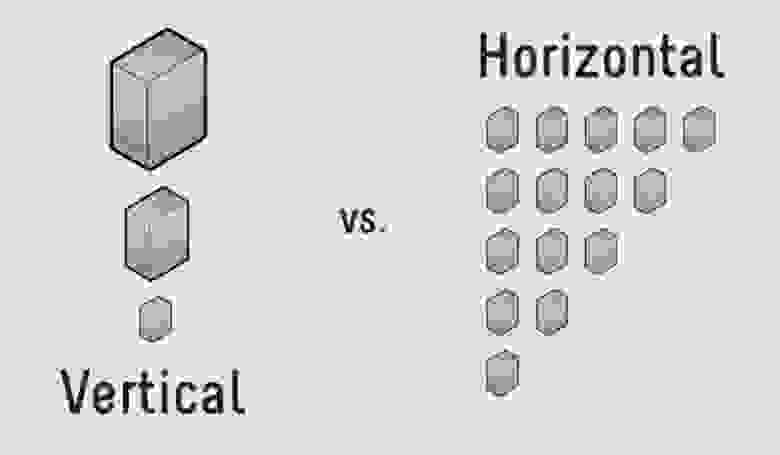
В таких случаях можно использовать горизонтальное масштабирование. То, что мы видели ранее, увеличение производительности одной машины, является вертикальным масштабированием. Увеличение количества машин — это горизонтальное масштабирование.

Чтобы разбить данные по машинам, используют шардинг или, по-другому, секционирование. То есть разбиение данных на секции и блоки по ключу, по айдишнику, по дате. Мы еще поговорим об этом дальше, это один из ключевых параметров, но смысл именно в том, чтобы по определенному признаку разделить данные и отправить их на разные машины. Таким образом, наши машины могут стать менее производительными, но система по-прежнему сможет функционировать и получать данные уже с разных машин.

Чтобы в целом понять, где какие данные лежат, нужна определенная таблица соответствий шарда, нашей копии и данных.
Бывают случаи, когда не используется специальное хранилище данных и клиент просто ходит по очереди на каждый шард и проверяет, есть ли там данные, которые соответствуют его запросу.
Бывает специальная программная прослойка, которая хранит в себе определенные знания о том, в каком шарде какой диапазон данных лежит. И, соответственно, идет уже именно туда, на тот самый узел, где лежат необходимые данные.

Бывает толстый клиент. Это когда мы не зашиваем сам клиент в отдельную прослойку, а зашиваем в него самого данные о том, как у нас шардированы данные.
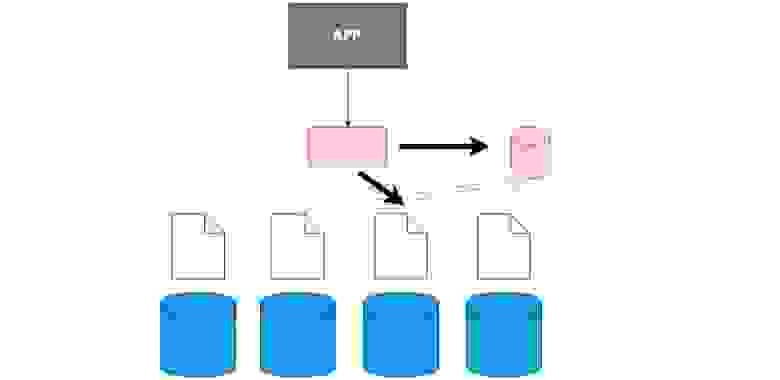
Вот этот случай. Он, кстати, самый частоиспользуемый. Хорош тем, что наше приложение, наш клиент, даже тот код, который вы пишете, — он не знает о том, что таблица шардирована, хотя мы указываем это в config, в самой базе. Мы просто говорим ей — селект, и уже в самой БД идет разбиение на шарды и понимание, откуда селектить. Здесь же вы в самом коде определяете то, откуда читать данные.
Есть специальные сервисы, которые помогают структурировать и вообще апдейтить информаци. Сложно ее держать согласованной и актуальной. Мы что-то заселектили, записали новые данные. Или что-то изменилось, и нам нужно очень правильно маршрутизировать наши запросы. Есть специальные сервисы координации запросов. Один из них — Zookeper. Вы можете посмотреть, как они вообще работают. Очень интересная структура. Они сохранили очень много нервов и времени разработчикам.
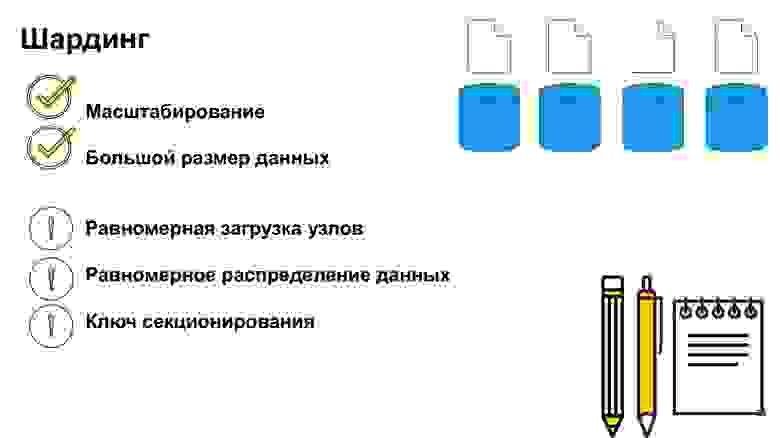
Что важно, какие аспекты нужно иметь в виду, когда вы секционируете? Важно понимать, по какому ключу мы будем делать разбиение на шарды. Пересобирать все эти данные достаточно дорого, поэтому очень важно не ошибаться с тем, как данные будут потенциально в будущем использоваться. Если мы хорошо и правильно сделали шардинг, то при наиболее частоиспользуемых запросах мы будем всегда знать, на какую реплику ходить.
Например, если мы по айдишникам пользователя храним все их данные на определенных репликах, тогда мы понимаем, что можем прийти на одну это реплику и все джойны сделать именно на ней. Но хранить именно по айдишнику — не самая крутая идея. Сейчас я расскажу, почему.
Если мы неправильно определили ключ в секционировании, если у нас очень сложный запрос, то нам и правда придется сходить на разные шарды, объединить все данные и только потом отдать их приложению. К счастью, большая часть СУБД делает это за нас. Но какие накладные расходы возникнут под плохо написанными запросами? Или под шардингом, который разбит по неправильному узлу?
Про айдишники. Если система работает только с новыми пользователями и у нас по айдишникам увеличение, то все запросы будут идти в последний узел.
Что получится? Три других работающих машины будут стоять без дела. А эта машина будет просто гореть — так называемый hot spot. Это узкое место вашей потенциальной системы, то место, которое может даже отказать по коннектам.
Поэтому, когда мы определяем ключ шардирования, очень важно понимать, насколько сбалансированы будут эти узлы. Очень часто используются хэши, это такое более-менее нейтральное, сбалансированное расположение данных. Но если у вас хэш-функция на ключе, то вы не сможете выбирать, например, по диапазонам. Логично, потому что по диапазонам нельзя раскинуться в разные шарды.
По дате — то же самое. Если мы, например, аналитику раскидываем и сделаем шарды по дате, то, понятное дело, какой-нибудь один шард десятилетней давности вообще не будет использоваться. Нам это не выгодно. А пересобирать данные и перешардировать всегда очень дорого.
Отвечу на вопрос, который был до этого. Что лучше сделать — определить индексы или сделать шарды? Конечно, индексы.
Смотрите, шарды — это отдельные машины с целой поднятой инфраструктурой. И этот средний компонент содержит нечто похожее на индексы. Есть быстрый поиск по параметрам — где, куда ходить. Вот такое соотношение. Но если есть шардинг, итоговая картина будет вот такая:
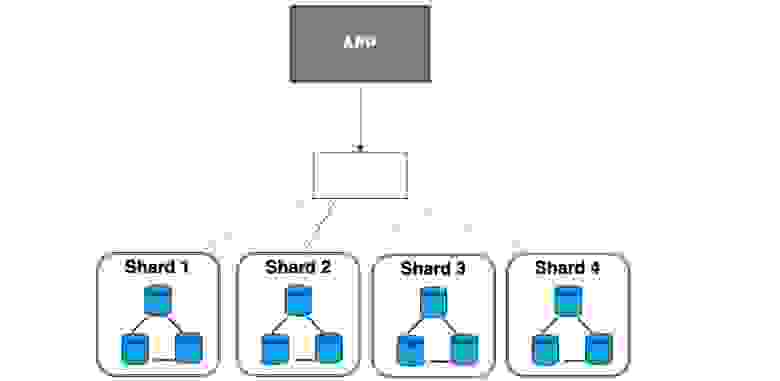
Есть приложения, какая-то голова, которая знает, куда ходить. И есть шарды, на каждом из которых настроена реплика. Это реально очень большой overhead, если данных немного. То есть к шардингу нужно прибегать, только когда вы действительно достигли лимита вертикального масштабирования, когда покупать более дорогую машину не релевантно количеству ваших данных или доходам. Тогда можно купить несколько разных, более дешевых машин и выстроить на них вот такую архитектуру.
Для чего нужны реплики, я думаю, понятно: потому что шарды разбиваются, это куски баз данных, но они как бы уникальные. Они находятся только в этих местах. Мы их разбиваем еще и на копии, которые делают наши узлы отказоустойчивыми и подстраховывают на случай проблем.
Самое главное: шардинг используется именно там, где вам не просто хочется разбить данные на классификацию, а именно там, где данных действительно много.
Теперь давайте подойдем больше к моделям данных и посмотрим, как данные можно хранить.
Реляционные БД, которые мы смотрели до этого, имеют огромное количество преимуществ, потому что они, в первую очередь, очень распространены и всем понятны. Они наглядно показывают отношение между объектами и обеспечивают целостность.
Но есть минус: они требуют четкой структуры. Есть таблица, в которую мы должны запихнуть все данные. Если посмотреть с точки зрения вообще всех сведений и фактов, которые мы собираем, они очень разные. То есть у нас может быть работа с продуктовыми данными, с данными пользователей, сообщений и так далее. Эти данные реально требуют четкой структуры, целостности. Для них идеально подходит реляционная база.
Но предположим, у нас есть, например, лог операций или описание объектов, где каждый объект имеет разные характеристики. Мы, конечно, можем это записать в джейсончик в реляционной БД и радоваться, что у нас он разрастается бесконечно.
А можем посмотреть на другие схемы, на другие системы хранения. NoSQL — очень кричащая аббревиатура, даже прямо провоцирующая — «нет SQL». Как она появилась?
Когда люди столкнулись с тем, что реляционные базы данных не везде успешны, они собрали конференцию, который нужен был хештег, — вот и придумали #NoSQL. Он прижился. Позже начали говорить не «нет SQL», а «не только SQL». Это просто все, что не реляционное: огромное семейство разных баз данных, которые не являются такими жестко структурированными, схематичными и табличными, как реляционные БД.
Семейство нереляционных моделей данных разделяют на четыре вида: ключ-значение, документоориентированные, столбцовые и графовые базы данных. Рассмотрим каждый из этих пунктов, узнаем, какие данные в каких из них лучше хранить и для чего они используются.
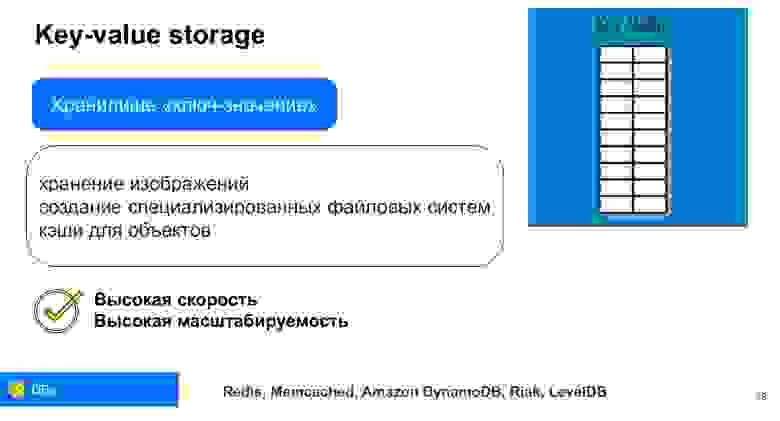
Ключ-значение. Это самое простое. Вот словарь, вот соотношение. Эта база данных, в которой данные хранятся по ключам, причем неважно, что лежит под конкретным ключом. У нас и сам ключ, и данные могут быть и простыми, и гораздо более сложными структурами. Такая база хороша тем, что она, подобно индексу, очень быстро ищет данные. Именно поэтому key-value очень часто используется для кэша. Преимущество в том, что наше value может быть разное в разных ключах.
Мы можем использовать ключ, например, для хранения сессий пользователя. Пользователь кликнул, мы записали это в value. Это такой schemaless, модель данных без определенной схемы, структуры значений. Благодаря тому, что это очень простая структура, она имеет высокую скорость и легко масштабируется. У нас уже есть ключи, и мы можем очень легко их шардировать, сделать их хэши. Это одна из самых высокомасштабируемых баз данных.
Примеры — Redis, Memcached, Amazon DynamoDB, Riak, LevelDB. Вы можете посмотреть особенности реализации именно key-value хранилищ.

Документоориентированные базы данных очень похожи на key-value в какой-то из областей их применения. Но у них единицей является документ. Это такая сложная структура, по которой мы можем селектить определенные данные, делать балковые операции: Bulk insert, Bulk update.
Каждый документ может хранить в себе, как правило, XML, JSON или BSON — бинарно-сохраняемый JSON. Но сейчас это уже практически всегда JSON или BSON. Это тоже как бы пара ключ-значение, можно это себе представить как таблицу, в которой каждая строка имеет определенные характеристики, и мы по этим ключам можем из нее что-либо доставать.
Преимущество документоориентированных БД: они обладают очень высокой доступностью и гибкостью данных. В любой документ, в любой JSON вы можете записать абсолютно любой набор данных. И они очень часто применяются — например, когда нужно сделать какой-нибудь каталог и когда каждый продукт в каталоге может иметь разные характеристики.
Или, например, профили пользователей. Кто-то указал свой любимый фильм, кто-то — любимую еду. Чтобы не засовывать все в одно поле, которое будет хранить непонятно что, мы можем все записать в JSON документоориентированной базы.
Еще одна модель, в которой удобно хранить данные, — столбцовые БД. Их еще называют колоночными, column database.

Это очень интересная структура, которая используется, как мне кажется, практически во всех больших и сложных проектах. Такая база данных подразумевает, что мы храним данные на диске не строчками, а столбцами. Используется для очень быстрого поиска по огромному объему данных. Как правило — для аналитики, когда нужно проселектить значения только из определенных столбцов.
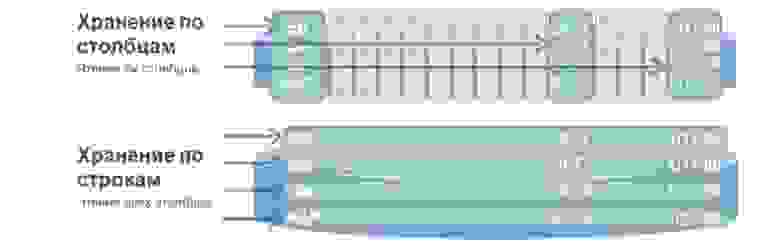
Представим, что у нас есть огромная таблица. И если бы мы хранили данные строчками, то было бы то, что внизу: огромное количество строчек. Для селекта даже по трем параметрам этой таблицы нам нужно пройти по всей таблице. А когда мы храним значения по столбцам, то при селекте по трем значениям нужно пройтись только по трем вот таким, грубо говоря, строчкам, потому что столбцы у нас записываются вот так. Проходя по этим трем строчкам, мы сразу получаем порядковый номер нужного нам значения и достаем его уже из других столбцов.
В чем преимущество таких баз данных? За счет того, что они ищут по маленькому объему данных, у них очень высокая скорость обработки запросов и большая гибкость данных, потому что мы можем добавлять любое количество столбцов, не меняя структуру. Здесь не как в реляционных БД, нам не нужно засовывать наши данные в определенные рамки.
Самые популярные столбцовые — это, наверное, Cassandra, HBase и ClickHouse. Испытайте их. Очень интересно инвертировать в голове отношение строк и столбцов. И это действительно эффективный и быстрый доступ к большому количеству данных.

Есть еще семейство графовых баз данных. Они также содержат узлы и ребра. Ребра используются, чтобы показать отношния, как и в реляционных базах. Но графовые базы могут расти бесконечно в разные стороны. Поэтому она более гибкая. У нее очень высокая скорость поиска, потому что не нужно селектить и джойнить по всем таблицам. У нашего узла сразу есть ребра, которые показывают отношение ко всем разным объектам.
Для чего используются эти базы данных? Чаще всего — именно чтобы показать отношения. Например, в соцсетях можно ответить на вопрос, кто на кого подписан. У нас сразу есть линки на всех фолловеров нужного человека. Еще очень часто эти базы используются для определения схем мошенничества, потому что это тоже связано с демонстрацией связей операций друг с другом. Например, можно отследить, когда эта же банковская карта была использована в другом городе или когда с этого же айпишника заходили в аккаунт какого-нибудь другого пользователя.
Именно эти сложные отношения, которые помогают разрулить нестандартные ситуации, часто используются для анализа такого взаимодействия и взаимоотношения.
Нереляционные базы данных не заменяют реляционные. Они просто другие. Другой формат данных и другая логика их работы, не хуже и не лучше. Это просто другой подход к другим данным. И да, нереляционные базы используются очень часто. Их не нужно бояться, их нужно, наоборот, пробовать.
Если вы делаете кэш, то, естественно, берете какой-нибудь Redis, простое и быстрое key-value. Если у вас есть огромное количество логов для анализа, вы можете скинуть его в ClickHouse или в какую-нибудь колоночную базу, по которой потом будет очень удобно искать. Либо записать в документоориентированную базу, потому что там может быть разное значение документов. Это тоже может оказаться удобно для селекта.
Выбирайте модель данных в зависимости от того, какие данные вы будете использовать. Либо реляционная, либо нереляционная. Охарактеризуйте данные. Так вы сможете подобрать самое подходящее хранилище, которое в будущем сможете масштабировать.

Вы сегодня узнали очень много о самых разных проблемах и способах хранения данных. Еще раз повторю то, что я говорила в самом начале: не нужно знать прямо все досконально, не нужно копаться в чем-то одном. Если интересно — конечно, можно. Но важно знать о том, что это вообще существует, какие есть подходы и как вообще можно мыслить. Если нужна отказоустойчивость, есть смысл сделать реплику. Предположим, я записала данные, но не увидела. Тогда, наверное, моя реплика дала лаг. Не нужно изобретать велосипеды — есть уже много готовых решений для разных задач. Расширяйте кругозор, а если появится баг или какая-нибудь другая проблема, вы по характеристикам бага поймете, где именно произошел сбой, сможете найти решение через поисковик. Спасибо за внимание.
— О чем именно мы будем говорить? Не о примитивных селектах и джойнах — о них, я думаю, большинство из вас уже знает.
Мы будем говорить о реальном применении баз, о том, с какими сложностями вы можете столкнуться и что вам как бэкенд-разработчику нужно знать. Информации будет много, вот содержание. Не нужно прямо досконально знать детали каждого из этих пунктов, но нужно знать, что этот пункт существует.

И нужно знать, как какие проблемы решаются, чтобы, когда у вас будет задача построить структуру, сохранить данные, вы знали, какую модель данных выбрать и как их сохранить. Или предположим, у вас проблема, вы видите, что база данных не работает, работает медленно, или возникли проблемы с данными, несогласованность. Тогда вы должны понимать, куда копать. То есть нужно знать, какие понятия существуют и с какой стороны подойти к проблемам.

Сначала мы с вами поговорим о данных. Что это такое вообще? Вокруг нас много фактов, много сведений, но пока они никак не собраны, они для нас бесполезны. Мы их собираем, структурируем и сохраняем. И именно это сохраненное структурирование называется данными, а то, что их хранит, — базой данных. Но пока эти данные просто где-то лежат собранные, они для нас тоже в принципе бесполезны. Поэтому существует прослойка над базами данных — СУБД. Это то, что позволяет нам доставать данные, сохранять их и анализировать. Таким образом, данные, которые мы получаем, мы превращаем в информацию, которую уже можем вывести пользователю. Пользователь получает знания и применяет их.

Мы обсудим, как структурировать сведения и факты, хранить их, в каком виде данных, в какой модели. И как их достать так, чтобы много пользователей одновременно могли обращаться к данным и получить корректный результат, чтобы наши итоговые знания, которые мы будем применять, были правдивыми и верными.

Для начала мы с вами поговорим о реляционных базах данных. Думаю, реляционная модель многим из вас знакома. Это модель типа таблиц и отношений между таблицами. Представим, что у нас есть мессенджер, в который мы записываем данные и сообщения между пользователями. Мы можем их записать все в одну такую большую объемную таблицу, широкую, где у нас будет много повторяющихся данных — от кого, кто, кому, в какой чат. А можем всеэто записать в различные таблицы, то есть нормализовать наши данные, привести в третью нормальную форму.
На слайдах есть примечания и ссылочки. Мы не будем сейчас углубляться в каждое понятие. Я постараюсь технические понятия, которые могут быть вам незнакомы, не говорить. Но все, что я говорю, вы найдете в примечаниях к слайдам. В том числе по нормализации тоже будет ссылочка, вы сможете почитать, если это понятие вам не знакомо.

В общих словах, нормализация — это разбиение данных на таблицы с целью, чтобы эти данные стали более структурированы. Например, здесь есть теперь таблица юзера, чата мессенджера и сообщений. Такая структура обеспечивает, что сюда будут записаны сообщения именно тех пользователей, которых мы знаем, и из известных нам чатов. То есть мы обеспечиваем целостность данных. Мы обеспечиваем факт того, что мы всегда можем собрать общую картинку целиком. Но при этом мы храним, например, в таблице сообщений только айдишники, только идентификаторы. Таким образом мы сокращаем общий размер базы данных, делаем ее меньше. Соответственно, делаем проще запись в эту БД. Нам не нужно постоянно записывать во много таблиц. Мы просто записываем в одну таблицу с айдишником.

Если говорить про нормализацию, она вообще очень упрощает видение системы, потому что очень графична, и нам сразу становится понятно, какие взаимоотношения между какими таблицами у нас есть.
Мы уменьшаем количество ошибок при записи данных, потому что если мы записываем сообщение в месседжере и такого пользователя у нас еще нет, то нам придется его завести. Но итоговая картина, общие данные у нас останутся целостными.
Про уменьшение размера базы данных я уже сказала. Нам в таблице сообщений не придется каждый раз писать все данные о пользователе. Чтобы посмотреть профиль, мы можем просто зайти в таблицу User.
О несогласованной зависимости также предупредила. Это как раз ссылки на айдишники других таблиц, идентификаторы являются уникальными значениями в рамках одной таблицы. По-другому они называются primary key, и когда у нас есть ссылка на эти primary key, то сама ссылка в другой таблице называется foreign key.
Такая структура также защищает наши данные от случайного удаления. Мы не можем удалить юзера, потому что, например, у него есть сообщение. Это такая небольшая, но подстраховка.
Казалось бы, мы сделали отличную структуру, все понятно, все зависимо, все цельно. С чем еще нужно работать?

Представим, что мы реально запустили это в эксплуатацию, у нас стало много пользователей и, соответственно, много сообщений. Они постоянно друг с другом общаются. Что происходит в нашей таблице сообщений? Она постоянно растет. И чтобы искать в не данные, нам нужно постоянно перебирать абсолютно все сообщения, проверять, от этого пользователя они или нет, в этом чате или нет, и только тогда их выводить.
Естественно, чем больше пользователей, чем больше сообщений, тем дольше будут проходить запросы полного перебора. Нам нужно решение, которое позволит быстро искать сообщения в таблице.
Для такого случая, для ускорения поиска, используют индексы. Самая простая ассоциация с индексами — это содержание в книге. Если вам нужно в книге найти информацию, вы можете просто пролистать книгу, а можете зайти в оглавление. Индексы — это своего рода оглавление.
Есть еще хороший пример с телефонной книжкой. Вы можете нажать на букву на своем телефоне, и вас сразу перекинет ссылочно на фамилии, начинающиеся с этой буквы. Индексы баз данных работают по очень похожему принципу. Давайте посмотрим нашу таблицу с сообщениями и то, как мы эти данные будем доставать.

Прошу обратить внимание, как именно мы будем работать с данными. Не с тем, какие у нас есть строки в таблице, а вообще. Индексы строятся по принципу того, какие запросы вы делаете.
Представим, что мы делаем в основном запросы по чату, то есть узнаём, какие сообщения есть в этом чате. Построим индекс именно по столбцу чатов. Индексы в базе данных — это отдельная структура. Таблица от нее не зависима. То есть индекс вы можете в любой момент удалить и перестроить заново, и таблица от этого не пострадает.
Здесь видно, что мы выделили, поставили индекс на столбец, и у нас выделилась отдельная структурка, которая уже немножко сократила количество записей, потому что в 11 чате уже есть несколько сообщений. СУБД обеспечивает быстрый поиск по вот этой маленькой таблице чата. Как это делается? Естественно, поиск происходит не простым перебором. Есть много алгоритмов быстрого поиска, мы с вами рассмотрим один из самых популярных алгоритмов, которые используются по умолчанию в большинстве баз данных. Это сбалансированное дерево.

Как оно работает? У нас есть номер чата, это целое значение, и дерево выстраивается по такому принципу: то, что слева от узла значений меньше, справа от узла значений больше. Что нам дает такая структура? Если посмотреть на итоговые листы этого дерева, то все значения внизу упорядочены. Это огромный плюс в приросте производительности. Сейчас покажу, почему.
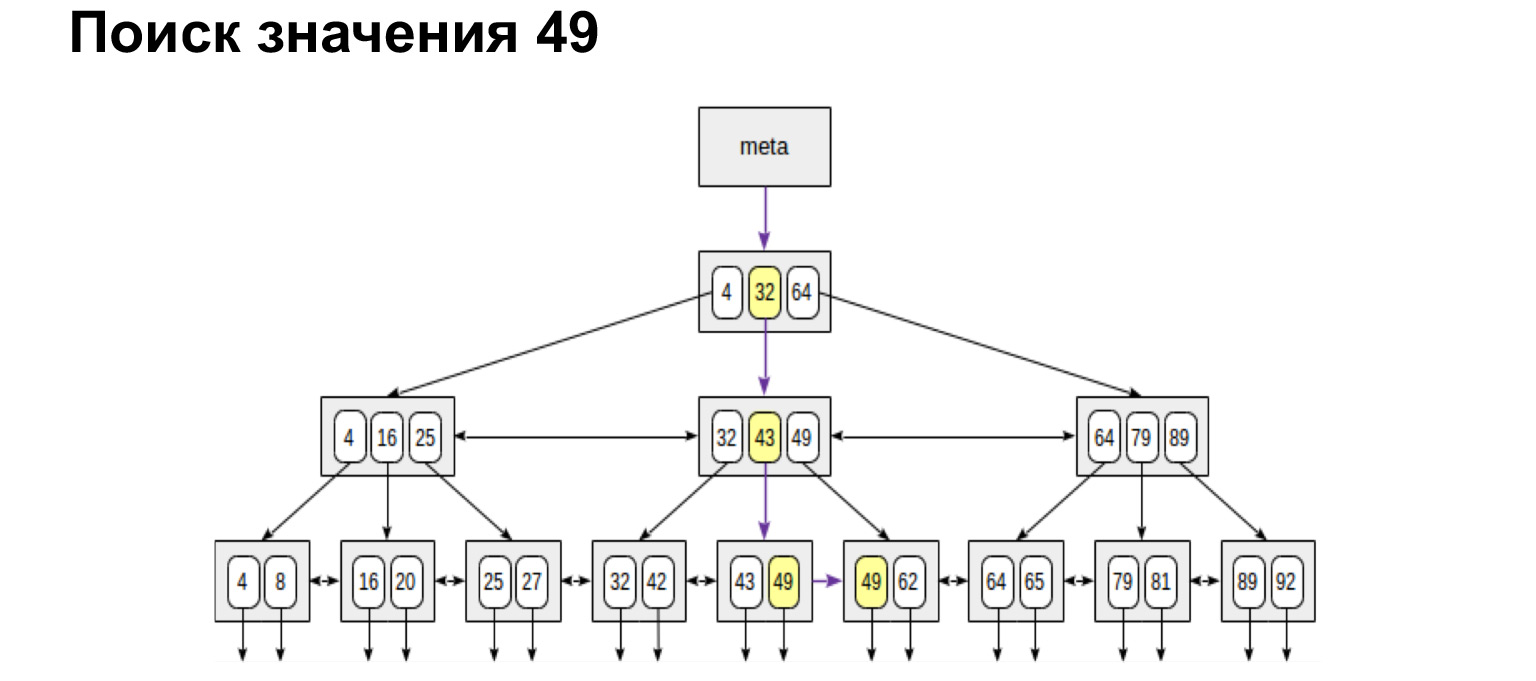
Например, мы ищем значение. Одно значение искать очень просто. Мы проходим вниз по дереву или влево, вправо — в зависимости от того, больше это значение или меньше.
А если мы хотим найти, например, диапазон, то смотрите, как просто и быстро это получается. Мы доходим до значения и дальше по ссылкам в листьях уже по упорядоченным значениям просто идем до конца.
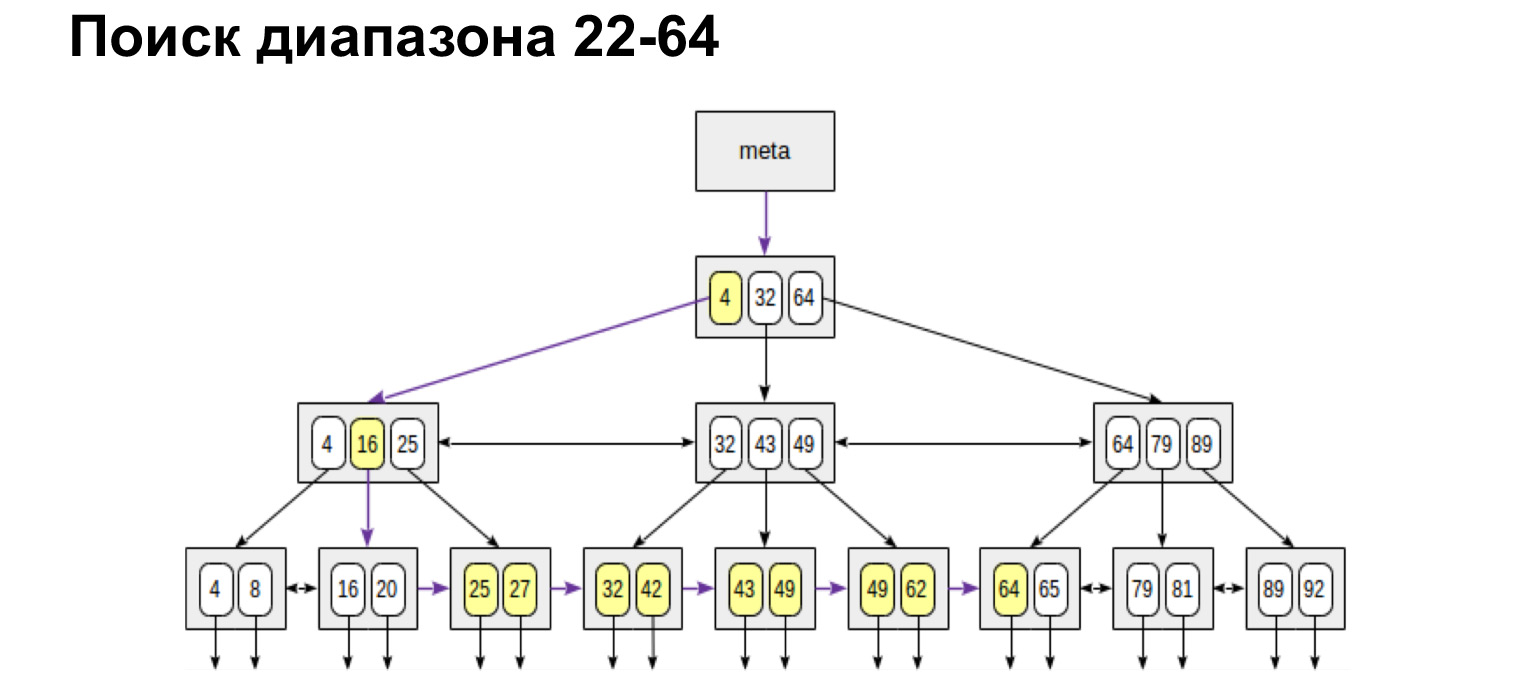
Если нам нужен диапазон, определенный от и до, — делаем абсолютно то же самое. Находим начальное значение и уже по ссылкам листьев идем до максимального значения. Мы по дереву прошли только один раз. Это очень удобно, очень быстро.
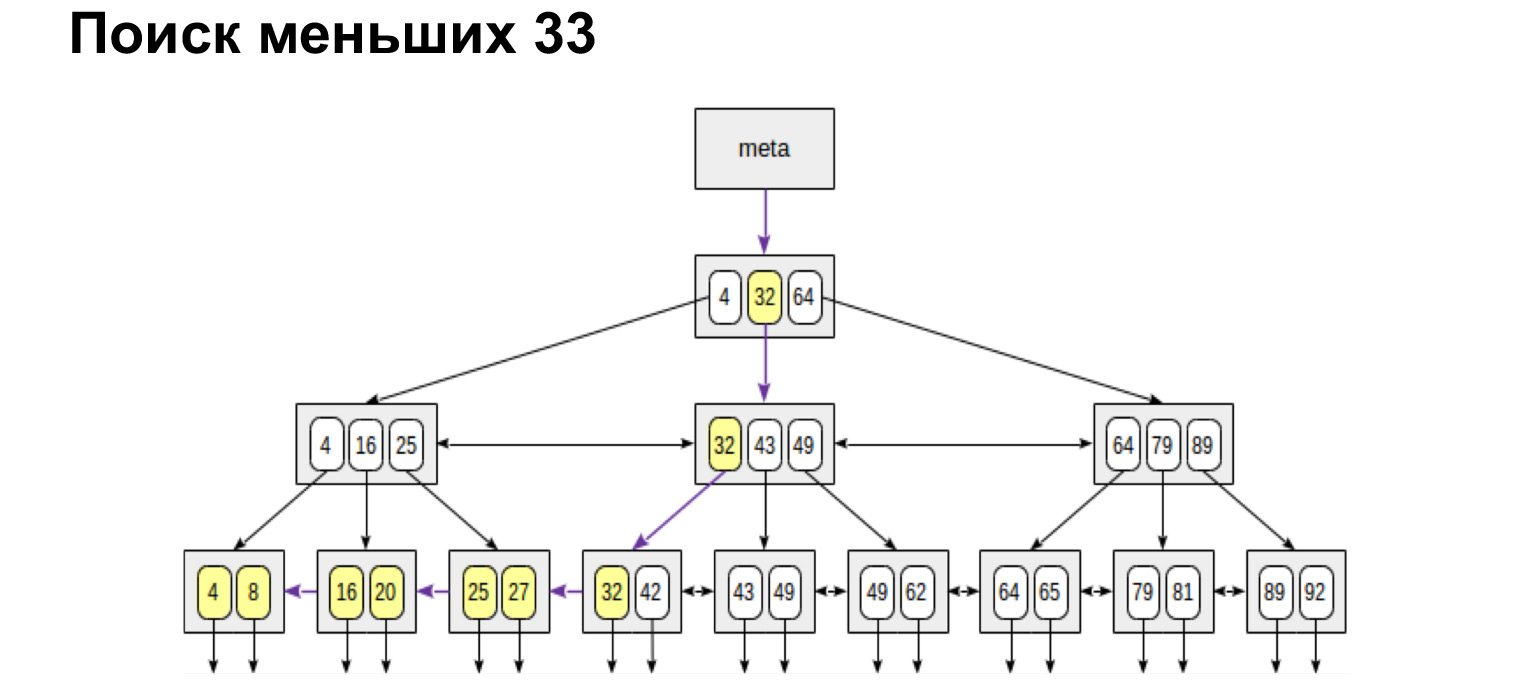
Точно так же у нас будут искаться максимальные и минимальные значения. Пройти совсем влево, совсем вправо. Так же у нас будет происходит получение упорядоченного списка. То есть если нам нужно просто получить все чаты упорядоченно, мы доходим до первого и уже по листьям идем до самого правого значения, получаем упорядоченный список. Именно по такому принципу база данных очень быстро ищет в таблице индексов те строчки, которые нам нужны для выборки, и возвращает их.
Что тут важно знать? Казалось бы, классная структура — мы сейчас на каждый столбец построим по такому дереву и будем искать. Как вы думаете, почему это не сработает? Почему у нас не будет прироста скорости, если мы на каждый столбец построим по дереву? (...)
У нас действительно ускорятся селекты. Каждый раз, когда нам нужно пройти по какому-то значению, мы заходим в индекс, находим там ссылку на сами значения. Индексы, как правило, содержат именно ссылки на строки, а не сами строки. И для селектов это работает идеально. Но как только мы захотим задать данные таблицы, проапдейтить либо удалить данные, то все эти деревья придется перестраивать.
На самом деле удаление не перестроит, а просто фрагментирует это дерево, и у нас получатся много пустых значений. Будет огромное дерево с пустыми значениями. Но именно при update и при create эти деревья каждый раз будут перестраиваться. В итоге мы получим огромный overhead над всех этой структурой. И вместо того, чтобы быстренько достать данные и ускорить базу данных, мы будем замедлять наши запросы.
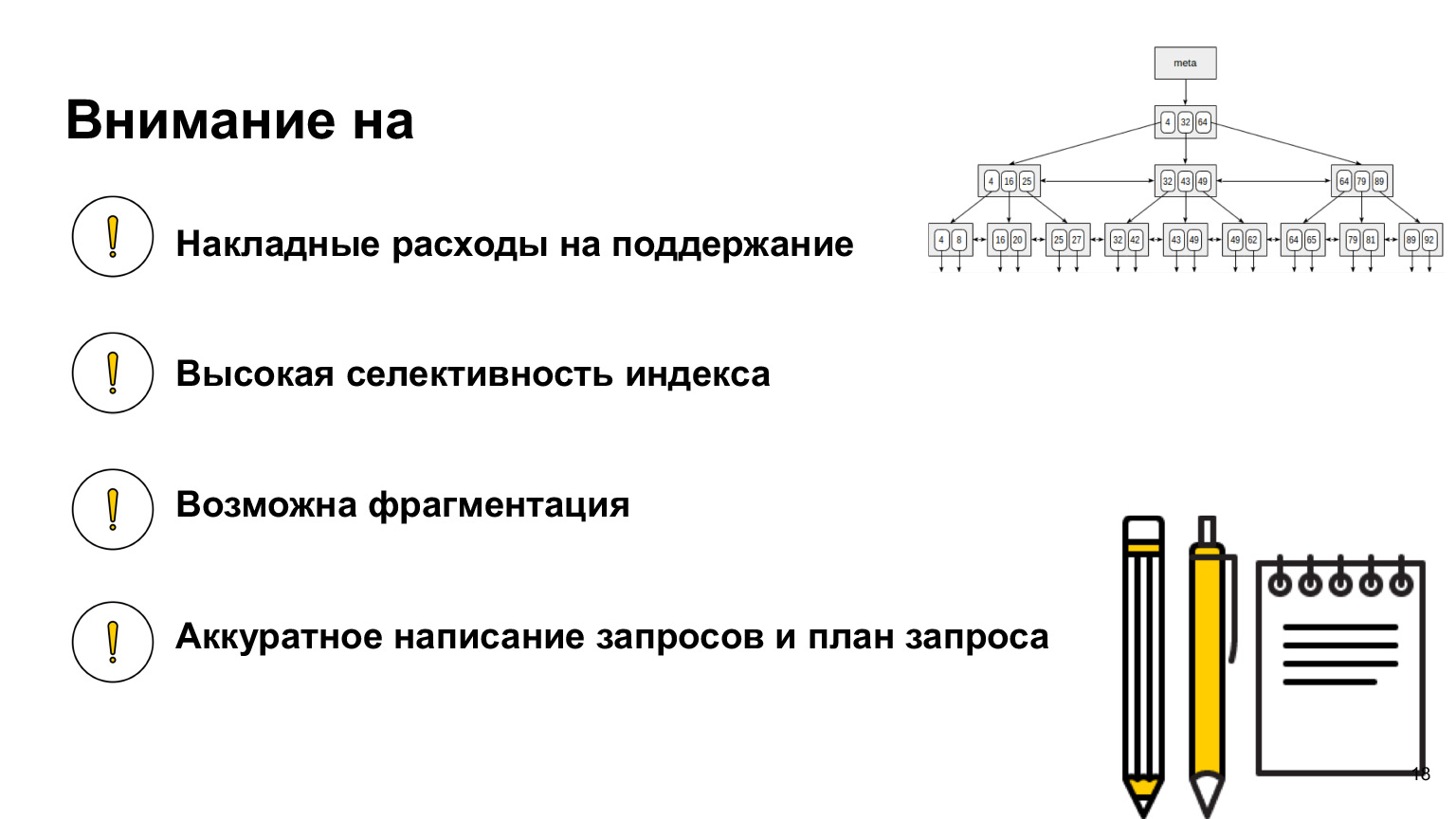
Что еще важно знать? Когда вы будете работать с базой, посмотрите, почитайте, какие индексы в ней существуют, потому что в каждой базе свои реализации, свои разные индексы. Есть индексы для ускорения, есть индексы для обеспечения целостности. Один из самых простых — как раз primary key. Это тоже индекс уникальности. И относительно вашей базы смотрите, как он устроен, как с ним работать, потому что это такие знания, которые вам помогут писать наиболее оптимальные запросы.
Мы обсудили, что нужно иметь в виду накладные расходы на поддержание индексов при вставке данных. Забыла сказать, что когда вы выстраиваете индекс, он должен обладать высокой селективностью. Что это значит?
Посмотрим на это дерево. Мы понимаем, что если стоит индекс на true false, то получается просто два огромных куска дерева слева и справа. И мы проходимся в лучшем случае по 50% таблицы, что на самом деле не очень эффективно. Лучше всего делать индекс именно на те столбцы, у которых наиболее разные значения. Таким образом мы ускорим наши выборки.
Про фрагментацию я сказала, при удалении данных ее нужно иметь в виду. Если у нас часто проходит удаление по данным, содержащимся в индексе, то его, возможно, придется дефрагментировать, и за этим тоже нужно следить. Также важно понимать, что вы строите индекс исходя не из того, какие у вас столбцы, а из того, как вы эти данные используете. И запросы, которые включают индексы, нужно писать очень аккуратно. Что значит аккуратно? Когда вы пишете запрос, отправляете его в базу данных, он отправляется не напрямую в базу, а в некую программную прослойку, которая называется планировщиком запросов.
Планировщик имеет у себя определенную таблицу соответствия того, какая операция сколько стоит и насколько она дорогая. В примере с PostgreSQL есть специальные технические таблицы, которые собирают информацию о ваших данных, о ваших таблицах. Планировщик смотрит, какой у вас запрос, какие данные хранятся в таблице pg_stat. Это как раз таблица, которая хранит общую информацию о том, сколько у вас данных и какие столбцы в вашей таблице, какие индексы на ней. Исходя из этого он смотрит планы выполнения вашего запроса, считает, сколько времени по какому плану уйдет на запрос, и выбирает самый оптимальный.

Если вы хотите посмотреть прогнозируемое время выполнения вашего запроса, можете использовать операцию Explain. Если хотите фактическое выполнение, можете использовать Explain analyze. Какая разница? Как я и говорила, планировщик изначально рассчитывает время выполнения, исходя из примерного времени на каждую операцию. Поэтому реальное время может отличаться в зависимости от машины и от особенностей ваших данных. Так что если вам нужно именно фактическое выполнение, то, конечно, лучше использовать Explain analyze.
На этом слайде вы можете посмотреть пример. Он показывает, что иногда запросы с учетом вашего столбца, на котором есть индексы, могут использовать не индекс scan, а просто full scan по всей таблице. Это происходит, если у нас невысокая селективность индекса и если планировщик считает, что запрос полным scan по таблице будет выгоднее.
Представим, что у нас есть наш мессенджер и мы хотим в списке чатов, например, показывать имя чата либо количество непрочитанных сообщений. Если мы каждый раз, открывая чатик, будем пересчитывать все данные по всем чатам, это будет очень невыгодно.
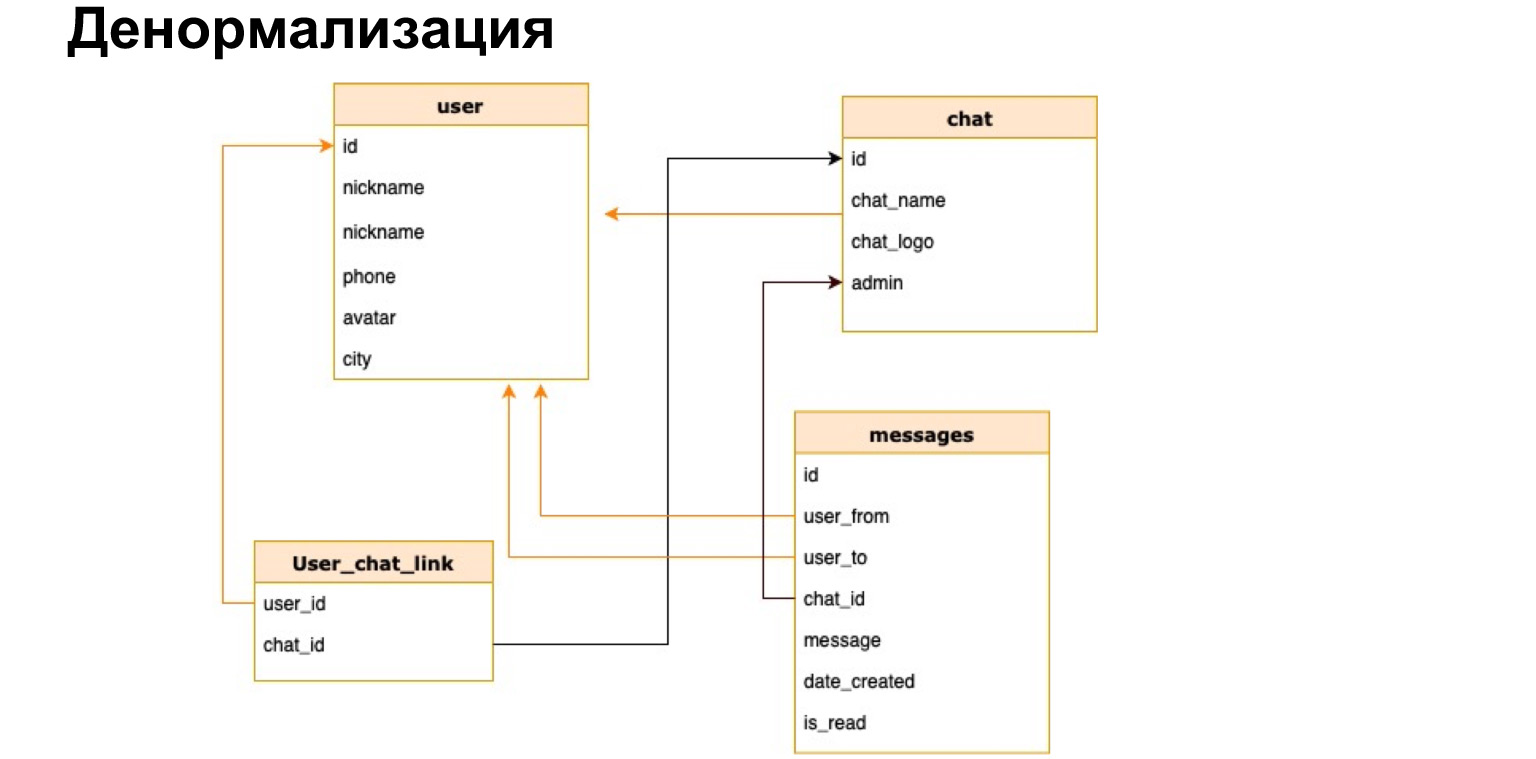
Есть такое понятие — денормализация. Это копирование наиболее горячих используемых данных либо предрасчет нужных данных и сохранение их в таблицу.
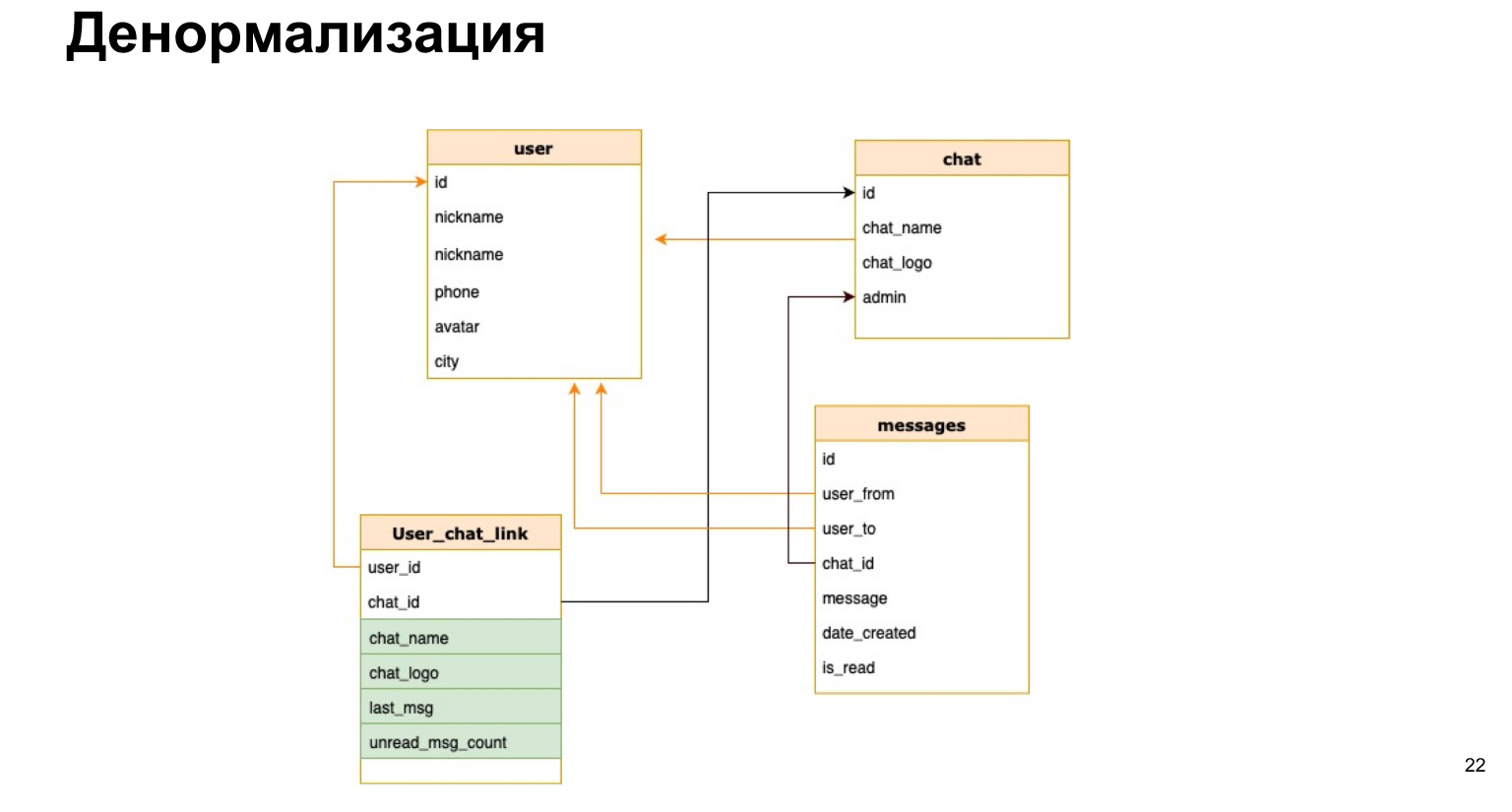
Так может выглядеть соотношение юзера с чатом. То есть помимо ID юзера и ID чата мы кратко туда сохраним имя чата, лог чата и количество непрочитанных сообщений. Таким образом нам каждый раз не нужно будет нагружать все наши таблицы, делать селект и все это пересчитывать.

В чем плюс денормализации? Мы ускоряем процесс выборки данных. То есть наши селекты проходят максимально быстро, мы максимально быстро отдаем пользователям ответ.
Сложность в том, что каждый раз, когда мы добавляем новые данные, нам все эти столбцы нужно пересчитывать и очень велика вероятность ошибки. То есть если наши селекты становятся гораздо проще и нам не нужно все время джойнить, то наши update и create становятся очень громоздкими, потому что нам нужно повесить туда триггеры, пересчитать и ничего не забыть.
Поэтому денормализацию нужно использовать, только когда она вам действительно нужна. И как мы сейчас шли по вот этой всей логике, сначала нужно данные нормализовать, посмотреть, как вы их будете использовать, настроить индексы. Если у вас есть запросы, которые, как вы считаете, плохо работают, то перед денормализацией посмотрите Explain. Узнайте, как они реально выполняются, как планировщик их выполняет. И только потом, когда вы уже придете к тому, что денормализация все-таки нужна, тогда вы можете ее сделать. Но такая практика есть, и в реальных проектах денормализация данных достаточно часто используется.
Пойдем дальше. Даже если вы хорошо структурировали данные, выбрали модель данных, собрали, все денормализовали, придумали индексы, — все равно очень многое в IT-мире может пойти не так.
Может отказать ПО, может выключиться электроэнергия, может отказать аппаратное обеспечение или сеть. Есть и второй класс проблем: нашими базами данных одновременно пользуется очень много пользователей. Они могут одновременно обновлять одни и те же данные. Все эти проблемы мы должны уметь решать.
Давайте посмотрим на конкретных примерах, о чем идет речь.

Представим, что есть два пользователя, которые хотят забронировать переговорку. Пользователь 1 видит, что переговорка в это время свободна, и начинает ее бронировать. У него открывается окошко, и он думает, кого же из коллег я позову. Пока он думает, пользователь 2 тоже видит, что переговорка свободна, и открывает себе окошко редактирования.
В итоге, когда пользователь 1 сохранил эти данные, он ушел и думает, что все отлично, переговорка забронирована. Но в это время пользователь 2 перезаписывает его данные, и получается так, что переговорка закрепилась за пользователем 2. Это называется конфликтом данных. И мы должны уметь показывать эти конфликты людям и как-то их разрешать. Именно в этом месте у нас будет перезапись.

Как это сделать? Мы можем просто заблокировать переговорку на какое-то время, пока пользователь 1 думает. Если он сохранил данные, то пользователю 2 мы не разрешим это делать. Если он данные отпустил и не стал сохранять, то пользователь 2 сможет забронировать переговорку. Подобную картину вы могли видеть, когда покупаете билеты в кино. Вам дается 15 минут на то, чтобы оплатить билеты, иначе они вновь предоставляются другим людям, которые тоже могут их взять и оплатить.
Вот другой пример, который нам покажет, насколько важно следить, чтобы наши операции выполнялись полностью. Допустим, я хочу с банковского счета 1 перекинуть деньги на счет 2. В этом моменте у меня есть три операции. Я проверяю, что у меня достаточно средств, вычитаю со своего первого счета средства и кидаю на второй счет. Понятное дело, что если в любой из этих моментов у меня произойдет сбой, то что-то пойдет не так.
Например, если вот на этом этапе произойдет другая транзакция, которая считывает данные, то средств на моем счете будет уже недостаточно, я не смогу выполнить другие операции. Если на втором моменте произойдет проблема, то мы, например, сняли с одного счета деньги, а на второй не закинули. Получается, что в итоге на моем банковском счету, на всех моих счетах станет на какую-то сумму меньше. Эти деньги уже никак не вернуть.
Для решения таких проблем существует понятие транзакции — атомарного, целостного выполнения всех трех операций одновременно.
Как это делает база данных? Она записывает все эти изменения в определенный журнал и применяет их, только когда у нас транзакция коммитится. Таким образом мы гарантируем, что все вот эти операции будут выполнены как единое целое либо не будут выполнены вовсе.
Если в любой момент этого времени у нас произойдет сбой, то с первого счета не будут вычтены деньги и, соответственно, мы их не потеряем.
У транзакций есть четыре свойства, четыре требования к ним. Это Atomicity, Consistency, Isolation и Durability — атомарность, согласованность, изоляция и сохраняемость данных. Что это за свойства?
- Atomicity или атомарность — гарантия того, что операция, которую вы выполняете, будет выполнена полностью, что она не будет выполнена частично. Таким образом мы гарантируем, что общая согласованность данных в нашей базе будет и до операции, и после.
- Consistency или согласованность — больше бизнес-правило, скорее не со стороны СУБД или самой базы данных. Согласованность не нужно путать с целостностью (Integrity). Если кто-то из вас работал с базами данных и передавал данные с айдишника, который не существует, то вы могли получать Integrity Error, ошибку целостности: система не понимала, что с ним делать. Именно наличие взаимосвязи отношений и уникальности ключей называется целостностью. А согласованность — то, что мы пишем в самой транзакции.
Например, в этом примере, когда мы пишем транзакцию, нужно с одного счета снимать столько же денег, сколько мы кидаем на второй счет. То есть в итоге у нас данные по общему балансу в начале и в конце должны быть одинаковыми. Это и есть согласованность.
- Isolation или изоляция — это как раз то, что мы с вами смотрели на примере переговорки. Ваша система должна вести себя предсказуемо и контролируемо относительно параллельного выполнения операций. Она должна гарантировать, что параллельно работающие пользователи не будут мешать друг другу и что не будет неожиданных изменений.
- Durability или сохраняемость — свойство транзакции, которое говорит о том, что если ответ пришел пользователю, то эти данные уже точно будут сохранены, что они не пропадут.
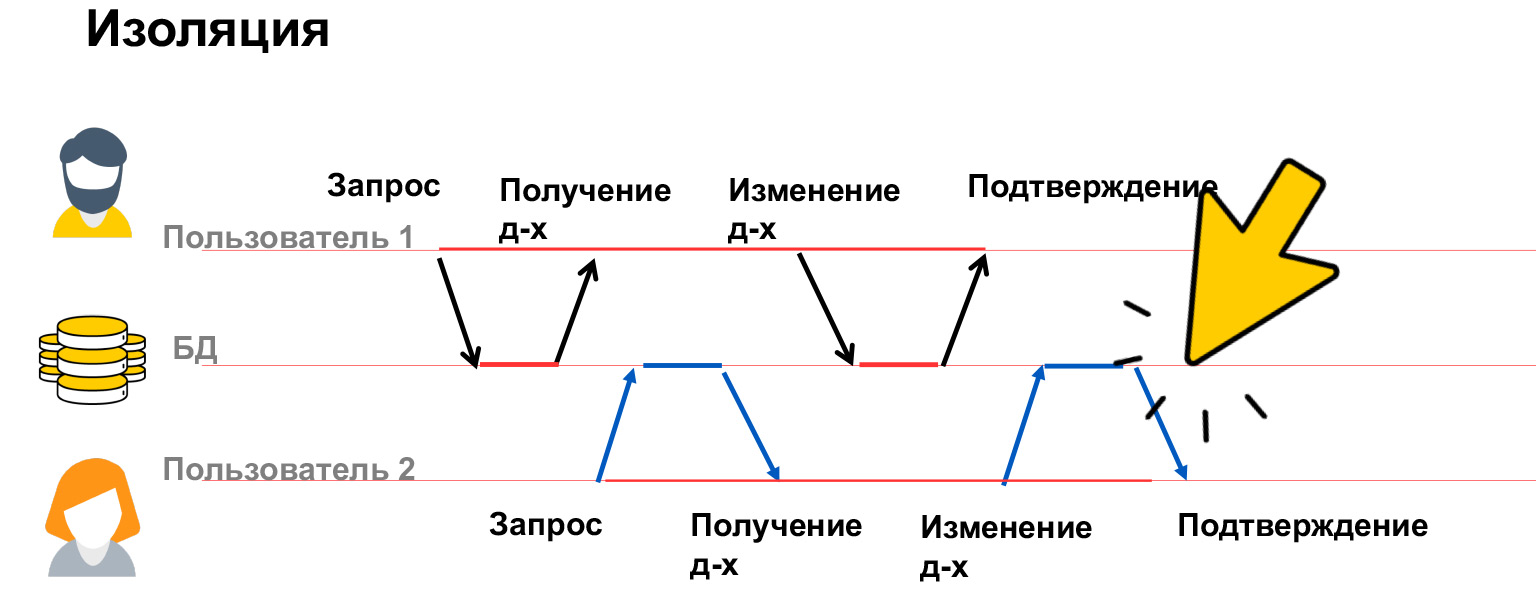
Поговорим побольше про изоляцию. Изолированность транзакций — очень дорогое свойство, на него тратится очень много ресурсов, из-за этого у нас в базах существует несколько уровней изоляции. Давайте посмотрим, какие проблемы могут быть, и исходя из этого уже обсудим, как их решать.
Существует четыре основных класса проблем — потерянное обновление, «грязное» чтение, неповторяющееся чтение и фантомное чтение. Рассмотрим подробнее.
Потерянное обновление — это как в примере с переговорками, когда у пользователя 1 перезаписались данные и он об этом не знает. То есть мы не блокировали данные, которые этот пользователь изменяет, и, соответственно, получили их перезапись.
Проблема «грязного» чтения возникает, когда пользователь видит временные изменения другого пользователя, которые потом могут быть откатаны или просто сделаны временно.

В данном случае пользователь 1 что-то записал в базу данных. Пользователь 2 в это время что-то оттуда считал и строит аналитику по этим данным. А пользователь 1 столкнулся с ошибкой, несоответствием и эти данные откатывает. Таким образом, аналитика, которую записал пользователь 2, будет ненастоящая, неверная, потому что уже нет тех данных, исходя из которых он ее рассчитывал. Такую проблему тоже нужно уметь решать.
Неповторяемое чтение — это когда у нас у пользователя 1 долгая транзакция. Он выбирает данные из базы, а в это время пользователь 2 изменяет часть тех же самых данных.
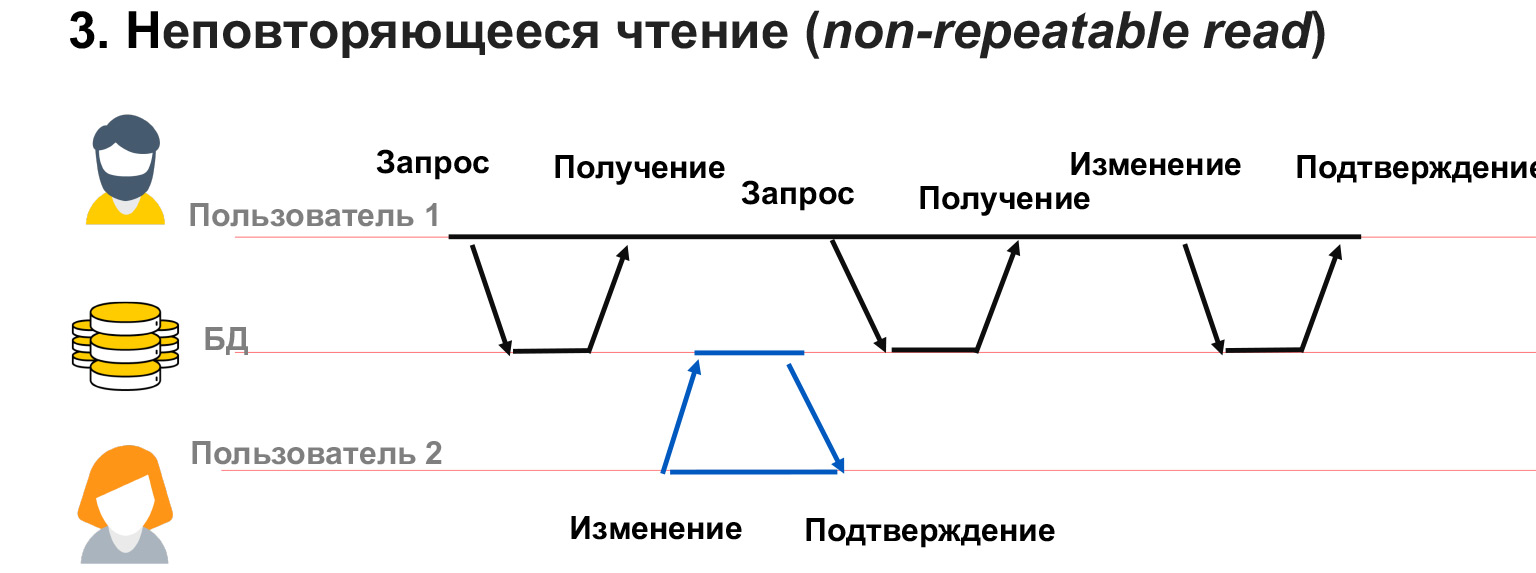
В данном случае получается, что пользователь 1 не заблокировал изменения тех данных, которые у него есть. И несмотря на то, что он сам получил слепок данных, при повторном запросе на тот же самый селект он может получить другие значения в этих строках. Таким образом, у него будет конфликт, несоответствие данных, которые он записывает.

Похожая проблема может быть, если пользователь 2 добавил или удалил данные. То есть пользователь 1 сделал запрос, а потом при повторном запросе этих же самых данных у него появились или пропали строки. В этом случае в рамках транзакции очень сложно понять, что с ними делать, как их вообще обрабатывать.

Чтобы решать эти проблемы, есть четыре уровня изоляции. Первый, самый низкий уровень — Read uncommitted. Это то, что в PostgreSQL описывается как No lock. Когда мы читаем или пишем данные, мы не блокируем другим пользователям ни чтение, ни запись этих данных. Получается, что мы не блокируем никакие изменения. Все четыре перечисленные проблемы по-прежнему могут произойти. Но от чего защищает этот уровень изоляции? Он гарантирует, что все транзакции, которые пришли в базу данных, будут выполнены. Если два пользователя одновременно начали выполнять запросы с одними и теми же данными, то обе эти транзакции будут выполнены последовательно.
Для чего это может быть полезно? Этот уровень изоляции очень редко используется в практике, но он может быть полезен, например, когда есть большой аналитический запрос и вы хотите во втором запросе почитать и посмотреть, на каком этапе находится ваша аналитика, какие данные уже записаны а какие нет. И тогда второй запрос — который для дебага, отладки, проверки — вы запускаете как раз в таком уровне изоляции. И он видит все изменения вашего первого аналитического запроса, которые в итоге могут быть откатаны. Или не откатаны, но в текущий момент вы можете посмотреть состояние системы.

Read committed, чтение фиксированных данных. Этот уровень изоляции используется по умолчанию в большинстве реляционных баз, в том числе и в PostgreSQL, и в Oracle. Он гарантирует, что вы никогда не прочитаете «грязные» данные. То есть другая транзакция никогда не видит промежуточных этапов первой транзакции. Преимущество в том, что это очень хорошо подходит для маленьких коротких запросов. Мы гарантируем, что у нас никогда не будет ситуации, когда мы видим какие-то части данных, недописанные данные. Например, увеличиваем зарплату целому отделу и не видим, когда только часть людей получили прибавку, а вторая часть сидит с неиндексированной зарплатой. Потому что если у нас будет такая ситуация, логично, что наша аналитика сразу «поедет».
От чего не защищает этот уровень изоляции? Он не защищает от того, что данные, которые вы проселектили, могут быть изменены. В случае небольших запросов этого уровня изоляции вполне достаточно, но для больших, долгих запросов, сложной аналитики, естественно, можно использовать более сложные уровни, которые блокируют ваши таблицы.
Уровень изоляции Repeatable read защищает от первых трех проблем, которые мы с вами обсуждали. Это и потерянное обновление, когда перезаписали нашу переговорку; «грязное» чтение — чтение незафиксированных данных; и это неповторяющееся чтение — чтение данных, обновленных другими транзакциями.

Как оно обеспечивается? С помощью блокировки таблицы, то есть блокировки нашего селекта. Когда мы берем селект в нашу транзакцию, то получается как будто слепок данных. И мы в этот момент не видим изменений других пользователей, все время работаем именно с этим слепком данных. Минус в том, что мы блокируем данные и, соответственно, у нас меньше параллельных запросов, которые могут работать с данными. Это очень важный аспект. И вообще, почему этих уровней изоляции так много?
Чем выше уровень, тем больше блоков и меньше пользователей, которые параллельно могут работать с базой. Каждая транзакция видит определенный слепок данных, который не может меняться. Но могут появиться новые данные. Так что этот уровень изоляции нас не спасает от появления новых данных, которые подходят под селект.
Есть еще один уровень изоляции — сериализация. Часто ее называют упорядочиваемостью. Это полная блокировка данных в таблице. Она спасает от фантомного чтения, то есть от чтения как раз тех данных, которые у нас добавились или удалились, потому что мы блокируем таблицу, не разрешаем в нее писать. И выполняем наши запросы целостно.

Это очень полезно для сложных, больших аналитических запросов, в которых очень важна точность и целостность данных. Не получится так, что мы в какой-то момент считали данные пользователя, а потом в другой таблице появились новые статистики и получился рассинхрон.
Это самый высокий уровень изоляции. Здесь самое большое количество блокировок и самая маленькая возможность параллелизации запросов.
Что нужно знать о транзакциях? Что они нам упрощают жизнь, потому что реализованы на уровне СУБД и нам нужно только правильно делать наши запросы, правильно их формировать, так, чтобы данные в итоге были согласованы. И чтобы блокировать именно те данные, с которыми наши пользователи работают. Нужно иметь в виду, что плохо блокировать всё и везде. В зависимости от того, какая у вас система и кто сколько читает/пишет, у вас будет разный уровень изолированности. Если вам нужна максимально быстрая система, которая допускает какие-то ошибки, вы можете выбрать минимальный уровень изоляции. Если у вас банковская система, которая должна гарантировать, что данные согласованы, все выполнено и ничего не потерялось — тогда, конечно, нужно выбирать максимальный уровень изоляции.
Мы уже достаточно классно продвинулись в понимании того, как выстраивать структуру базы данных и что может произойти. Пойдем дальше.
Насколько безопасно хранить одну базу данных. Конечно, не безопасно. Если с ней что-то случается, мы теряем все данные. Если есть бекап, мы можем его накатить, но тогда возникнет время простоя системы. Если у нас ломается сеть или узел становится недоступен, система тоже будет какое-то время находиться в простое, в downtime.
Как это можно разрешить? Есть такое понятие — репликация. Это дублирование базы данных на другие узлы и серверы.

Это именно дублирование полностью, копия базы данных. Как мы можем этот механизм использовать?
Во-первых, если с БД что-то случилось, мы можем перенаправить запросы на другую копию базы данных, что в принципе логично. Это основное применение. Как еще мы можем это использовать?
Представим, что пользователь находится далеко от сервера. Мы можем распределить серверы так, чтобы покрывать максимальное количество пользователей и максимально быстро отдавать им запросы. На каждом из этих серверов будет одинаковая с другими копия, но запросы будут возвращаться пользователям быстрее.

Еще одно очень популярное использование — распределение нагрузки. Так как у нас одинаковые копии данных, мы можем читать не из головы, не из одной базы данных, а из разных. Таким образом мы разгружаем наш сервер.

Также у нас есть понятие OLTP-запросов и OLAP-запросов. Что это такое? OLTP — короткие транзакционные запросы. OLAP — долгая аналитика. Это когда мы берем огромный джойн, огромный селект, всё мёржим и нам очень важно, чтобы в этот момент все данные были залочены, чтобы не было никаких изменений и БД была целостна.
Для таких ситуаций можно делать аналитику на отдельной копии базы данных. Так мы не будем аффектить наших пользователей, они смогут тоже делать записи в базу, просто потом эти записи придут и на нашу копию.
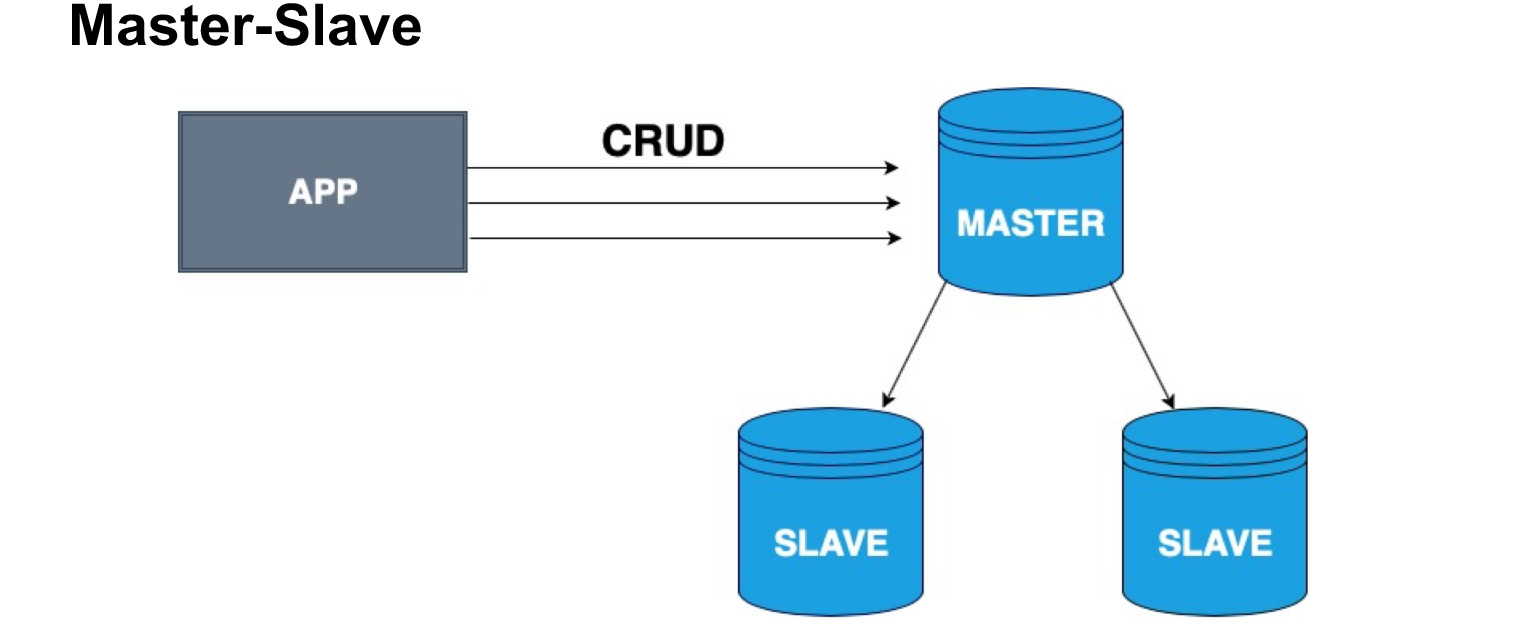
Чтобы грамотно распределить копии баз данных, вводится понятие ведущего узла и ведомого узла, Master и Slave. Slave очень часто называют репликой либо follower. Master — узел, в который наш пользователь, наше приложение пишет. Master применяет все изменения, ведет журнал изменений, и этот журнал отправляет на Slave. Slave не принимает изменения от пользователей, а применяет лишь изменения журнала от Master. Прошу заметить, что Master не отправляет каждый раз копию, а отправляет именно изменения. Slave накатывает эти изменения и получает такую же копию данных, как и в Master.
Очень важный параметр реплицируемой системы — синхронно или асинхронно выполняются запросы. Что такое синхронный запрос? Это когда Master отправляет запрос на синхронную реплику, на синхронный Slave, и ждет, когда Slave скажет: «Да, я принял», — и вернет Master подтверждение. Только тогда Master вернет пользователю ответ. Если же реплика асинхронная, то Master отправляет запрос на реплику, но сразу говорит пользователю, что «Всё, я записал». Давайте посмотрим, как это работает.
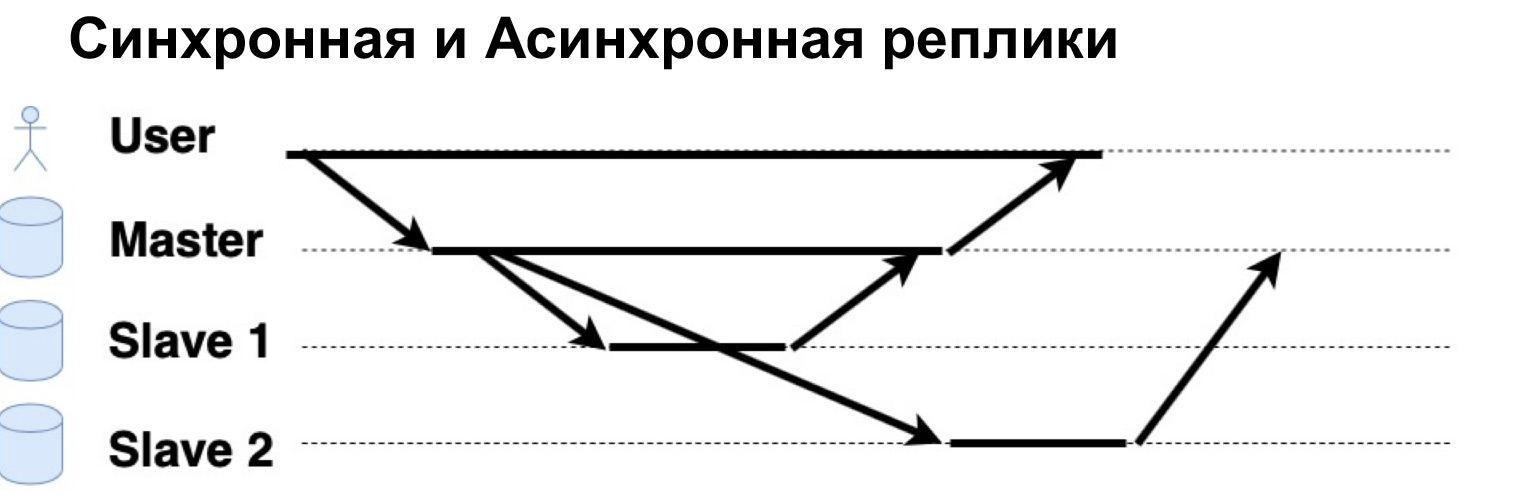
Есть юзер, который записал данные в Master. Master отправил их на две реплики, подождал ответа от синхронной реплики и сразу дал ответ пользователю. Асинхронная реплика записала и сказала Master: «Да, все окей, данные записаны».
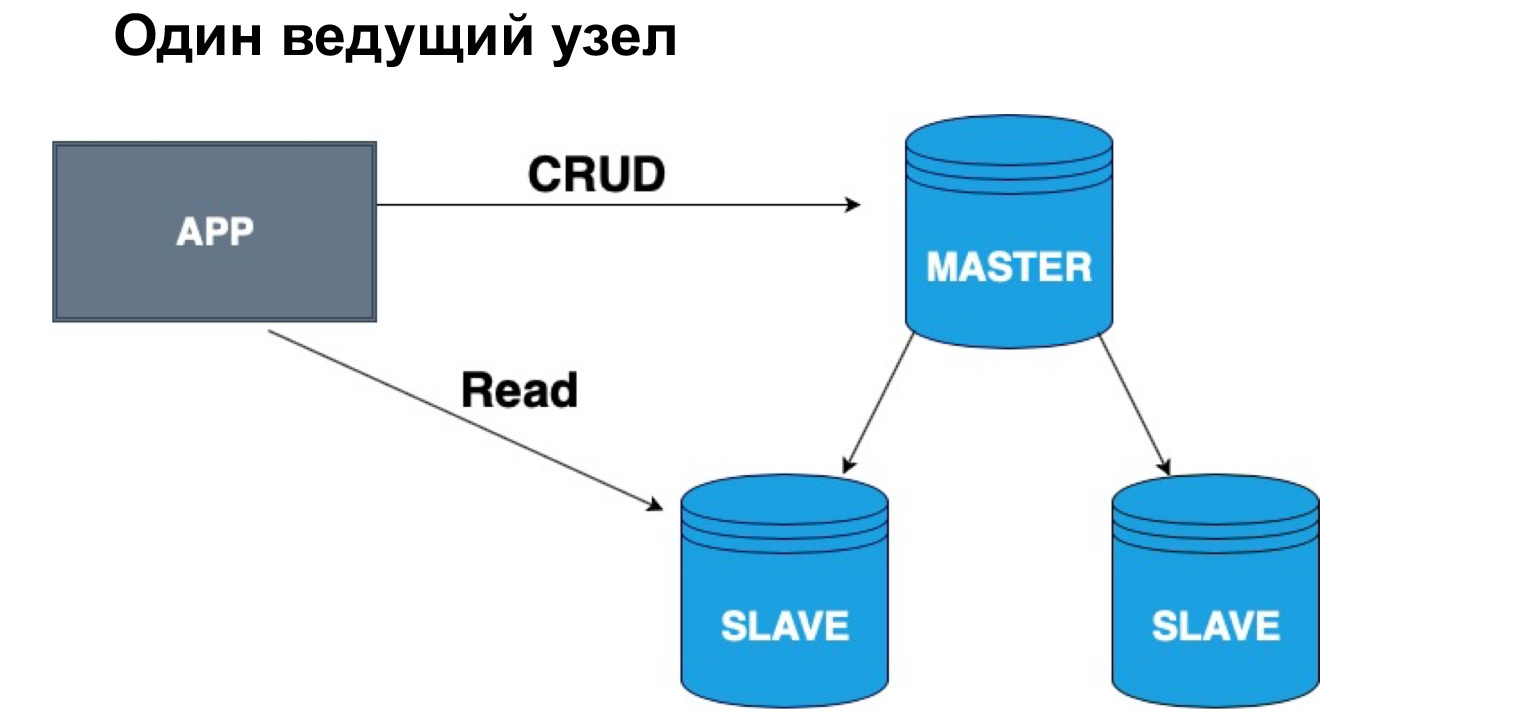
С точки зрения такой иерархии, Master и Slave, у нас может быть одна голова или несколько. Если у нас один ведущих узел, в него очень удобно писать, а читать можно из синхронной реплики. Почему именно из синхронной? Потому что синхронная реплика с максимальной точностью гарантирует, что в ней актуальные данные.
Когда к данным применяется запрос, операция из журнала, это тоже требует времени. Поэтому, если вам важна стопроцентная точность данных, которые вы хотите получить, вы должны ходить за чтением, за селектом в Master. Если вам не критично, что данные могут прийти с небольшим опозданием, вы можете читать из синхронного Slave. Если вам абсолютно не критична актуальность данных, вы можете читать в том числе из асинхронной реплики, тем самым разгружая Master и синхронную реплику от запросов.
В репликации также может быть несколько ведущих узлов. Разные приложения могут писать в разные головы, и эти Master потом между собой разрешают конфликты.
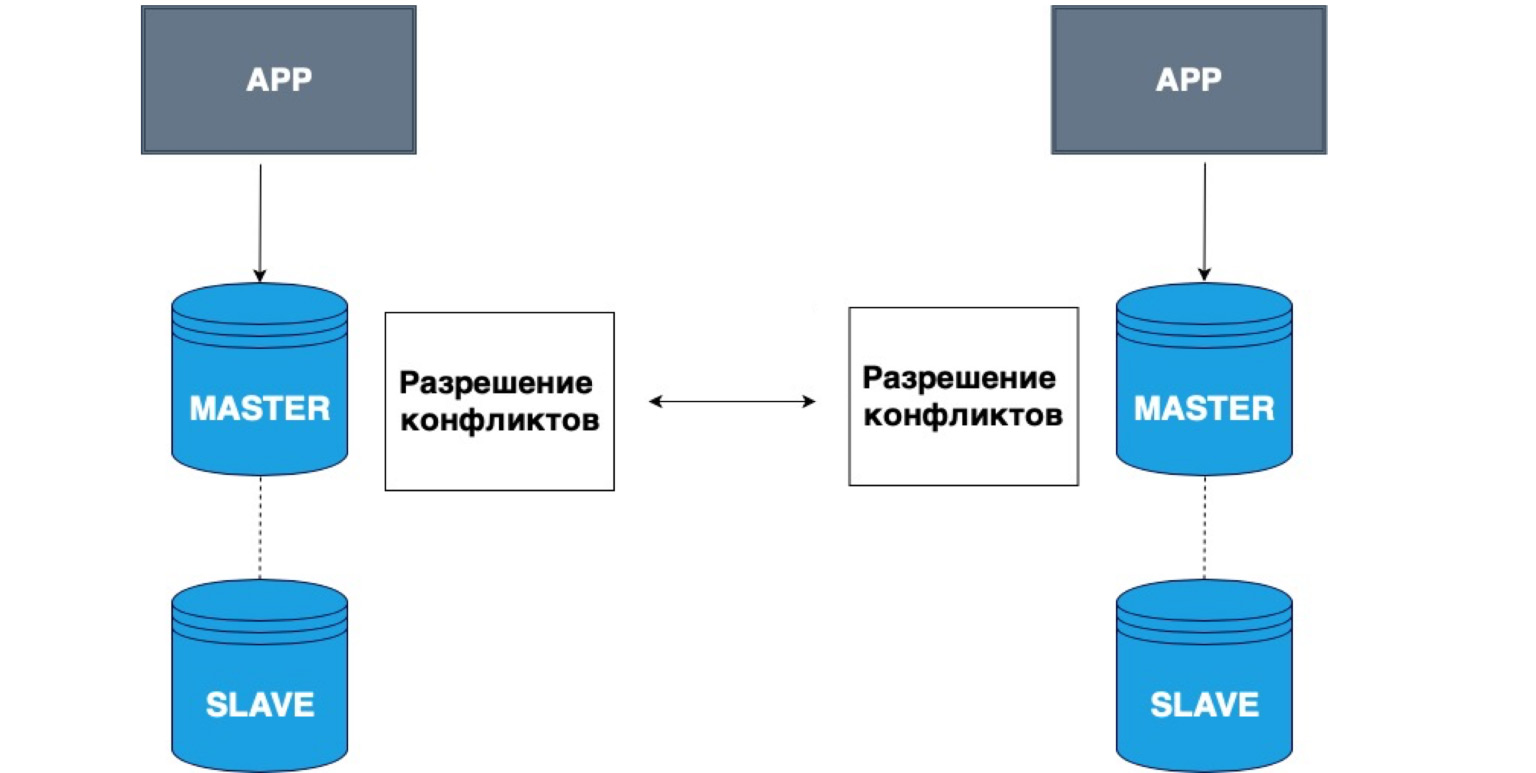
Очень простой пример применения таких данных — всякие офлайн-приложения. Например, на вашем телефоне есть календарь. Вы отключились от сети и записали в календарь событие. В данном случае ваше локальное хранилище, ваш телефон, — это Master. Он сохранил в себе данные, и при появлении сети Master вашей локальной копии и копия, которая на сервере, разрешат конфликты, объединят эти данные.
Это очень простой пример такой репликации. Она часто применяется для совместного редактирования онлайн-документов, либо когда очень велика вероятность потери сети.
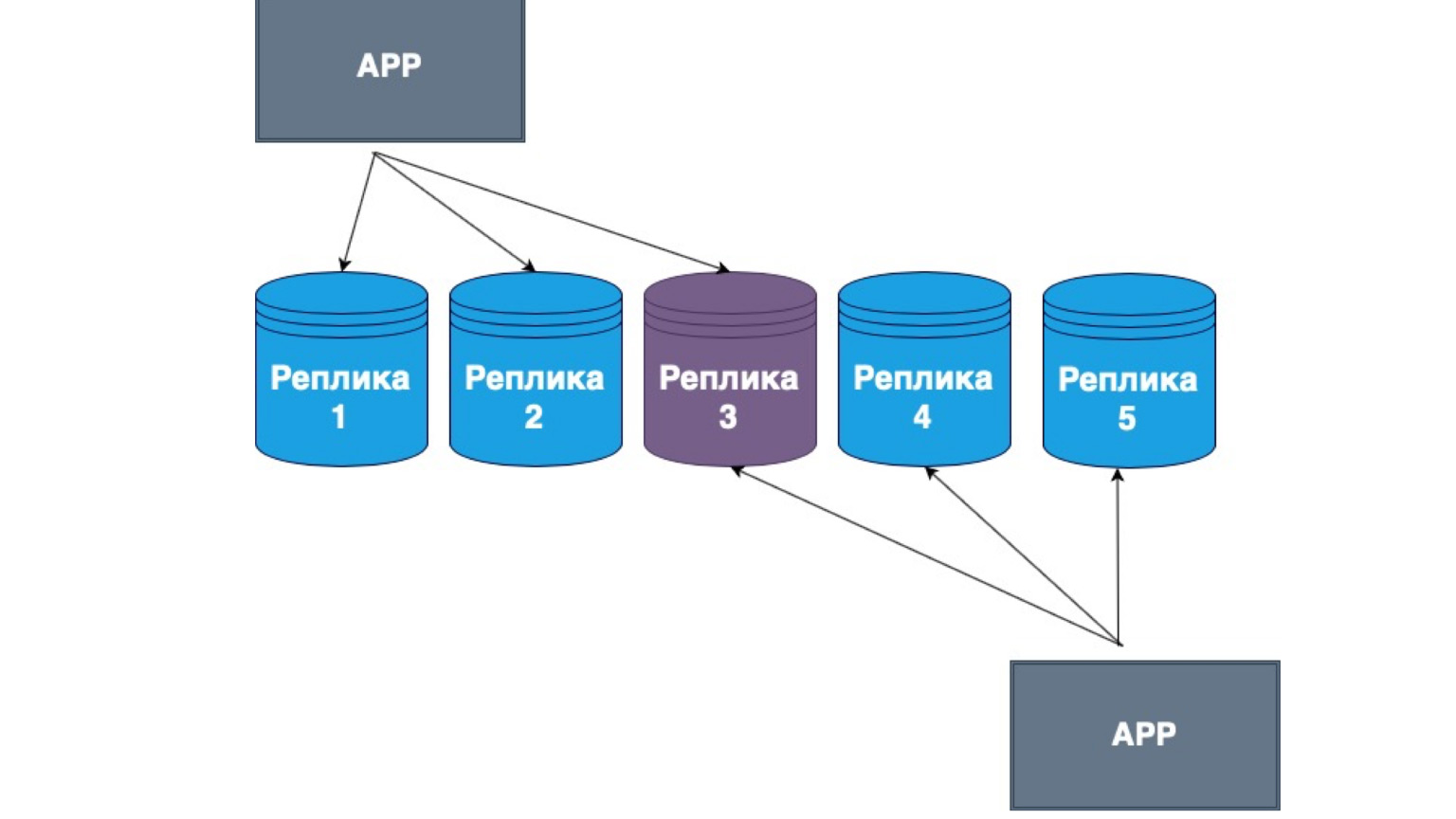
Также существуют репликации без ведущих узлов. Что это такое? Это репликация, при которой сам клиент отсылает данные на бóльшую часть реплик и читает их тоже из бóльшей части реплик. Здесь видно, что серединная реплика у нас является пересечением наших Read и update.
То есть мы гарантируем, что каждый раз, читая данные, мы попадем хотя бы в одну из реплик, в которой данные самые актуальные. А между собой у реплик выстраивается механизм обмена информаций с основным логом изменений и конфликтов между репликами. В данном случае очень часто реализовывают именно толстый клиент. Если он получил данные от реплики, в которой лежат более поздние изменения, чем в другой, то он просто отправляет данные на другую реплику либо разрешает конфликт.

Что важно знать про репликацию? Основной смысл репликации — отказоустойчивость системы, высокая доступность вашего сервера. Что бы ни случилось с базой, система будет доступна, ваши пользователи смогут писать данные, и когда восстановится соединение с Master или с другой репликой, то все данные тоже будут восстановлены.
Репликация очень помогает разгрузке серверов и перераспределению запросов чтения с Master на реплики. Мы можем масштабировать это чтение, создавать больше реплик на чтение и делать нашу систему еще быстрее. Еще можно сделать реплику на сложные долгие аналитические запросы, которые требуют большого количества блокировок и могут повлиять на доступность системы.
На примере офлайн-приложений мы с вами посмотрели, как можно такие данные хранить и разруливать конфликты. В случае синхронной реплики может быть Replication lag, то есть отставание по времени. В случае асинхронной реплики он есть практически всегда. То есть когда вы читаете данные из асинхронной реплики, вы должны понимать, что они могут быть не актуальны.
По иерархии забыла сказать, что когда есть один Master, который ждет ответа от синхронной реплики, логично предположить, что если у нас все реплики синхронны, и какая-то вдруг стала недоступна, то наша система не сможет сохранить запрос. Тогда Master запишет нас в первый синхронный Slave, получит ответ, попросит второй Slave, ответа не получит, и в итоге придется откатывать всю транзакцию.
Поэтому в таких системах, как правило, делают одну реплику синхронной, а остальные асинхронными. Синхронная реплика гарантирует, что ваши данные сохранились еще где-то. То есть помимо Master, с которым может что-то произойти, мы гарантируем, что есть хотя бы еще один узел, который содержит полную копию абсолютно того же журнала транзакций, тех же самых данных.
Асинхронная реплика, с другой стороны, не гарантирует сохранность данных. Если у нас есть только асинхронные реплики и Master отключился, то они могут отставать, туда могли еще не прийти данные. В таких случаях, как правило, выстраивают такую иерархию, что либо у нас Master, одна синхронная реплика и остальные асинхронные, либо у нас Master и все реплики асинхронные, если нам не важна сохраняемость данных.
Есть одно «но»: все реплики должны иметь одинаковую конфигурацию. Если говорить на примере PostgreSQL, они должны иметь одинаковую версию самого PostgreSQL, потому что разные версии базы могут иметь и разный формат журнала операций. И если реплика поднимается из другой версии, она просто может не прочитать операции, которые записала другая база.
Что такое реплика? Это полная копия всех данных. Представим, что данных так много, что сервер не справляется. Какое первое решение?
Первое решение — купить более дорогую машину с большим количеством памяти, с большим CPU, с большим диском. Это решение будет по большей части правильным, пока вы не столкнетесь с проблемой дороговизны железа. Однажды покупать новую машину станет слишком дорого, либо будет уже просто некуда расти. Есть огромное количество данных, которые просто физически невозможно разместить на одной машине.
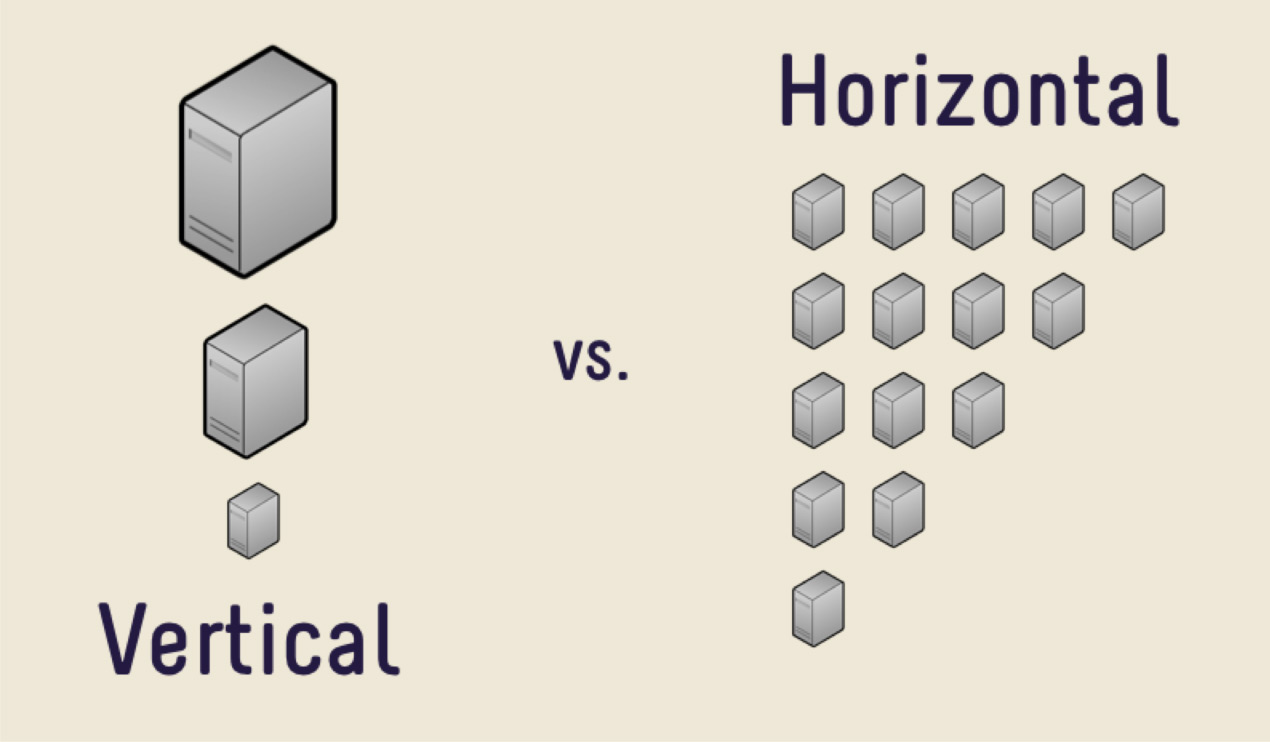
В таких случаях можно использовать горизонтальное масштабирование. То, что мы видели ранее, увеличение производительности одной машины, является вертикальным масштабированием. Увеличение количества машин — это горизонтальное масштабирование.
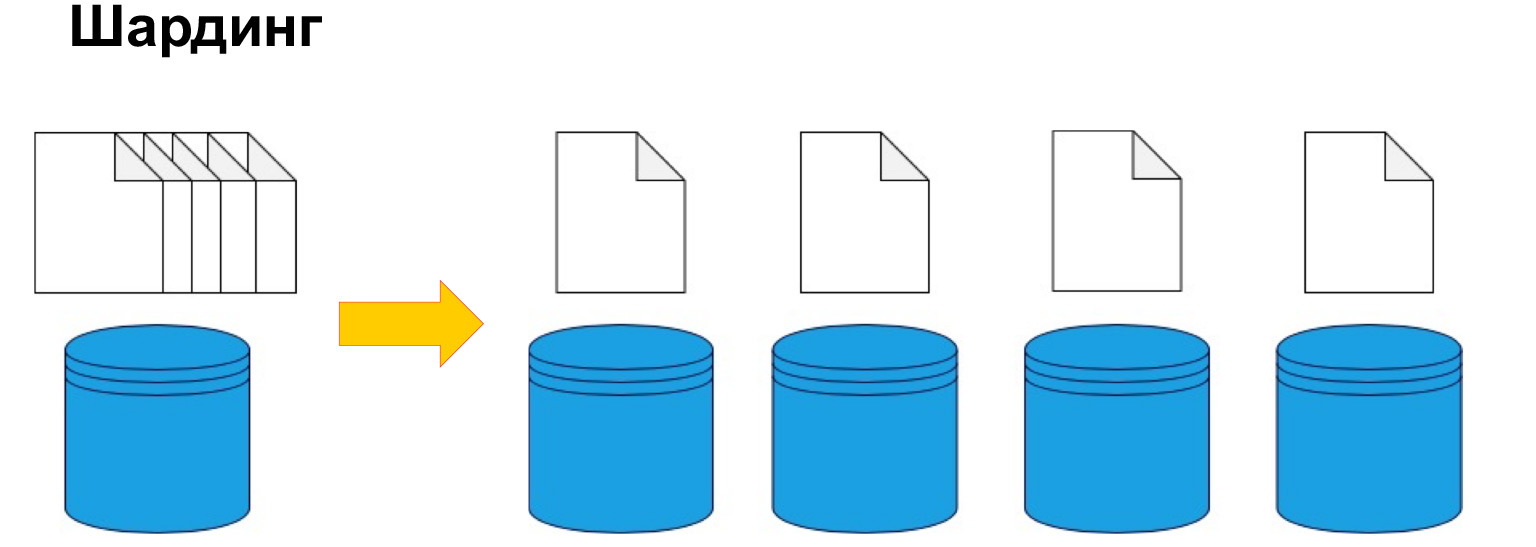
Чтобы разбить данные по машинам, используют шардинг или, по-другому, секционирование. То есть разбиение данных на секции и блоки по ключу, по айдишнику, по дате. Мы еще поговорим об этом дальше, это один из ключевых параметров, но смысл именно в том, чтобы по определенному признаку разделить данные и отправить их на разные машины. Таким образом, наши машины могут стать менее производительными, но система по-прежнему сможет функционировать и получать данные уже с разных машин.
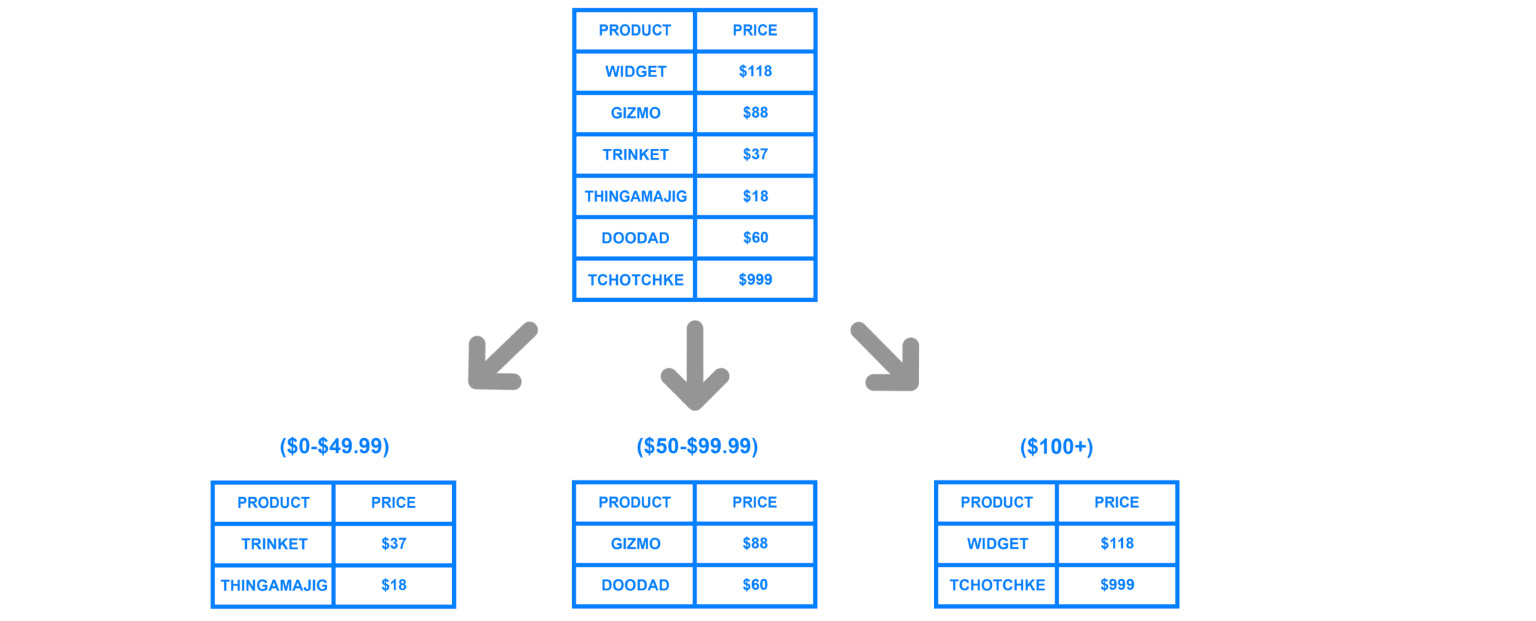
Чтобы в целом понять, где какие данные лежат, нужна определенная таблица соответствий шарда, нашей копии и данных.
Бывают случаи, когда не используется специальное хранилище данных и клиент просто ходит по очереди на каждый шард и проверяет, есть ли там данные, которые соответствуют его запросу.
Бывает специальная программная прослойка, которая хранит в себе определенные знания о том, в каком шарде какой диапазон данных лежит. И, соответственно, идет уже именно туда, на тот самый узел, где лежат необходимые данные.

Бывает толстый клиент. Это когда мы не зашиваем сам клиент в отдельную прослойку, а зашиваем в него самого данные о том, как у нас шардированы данные.
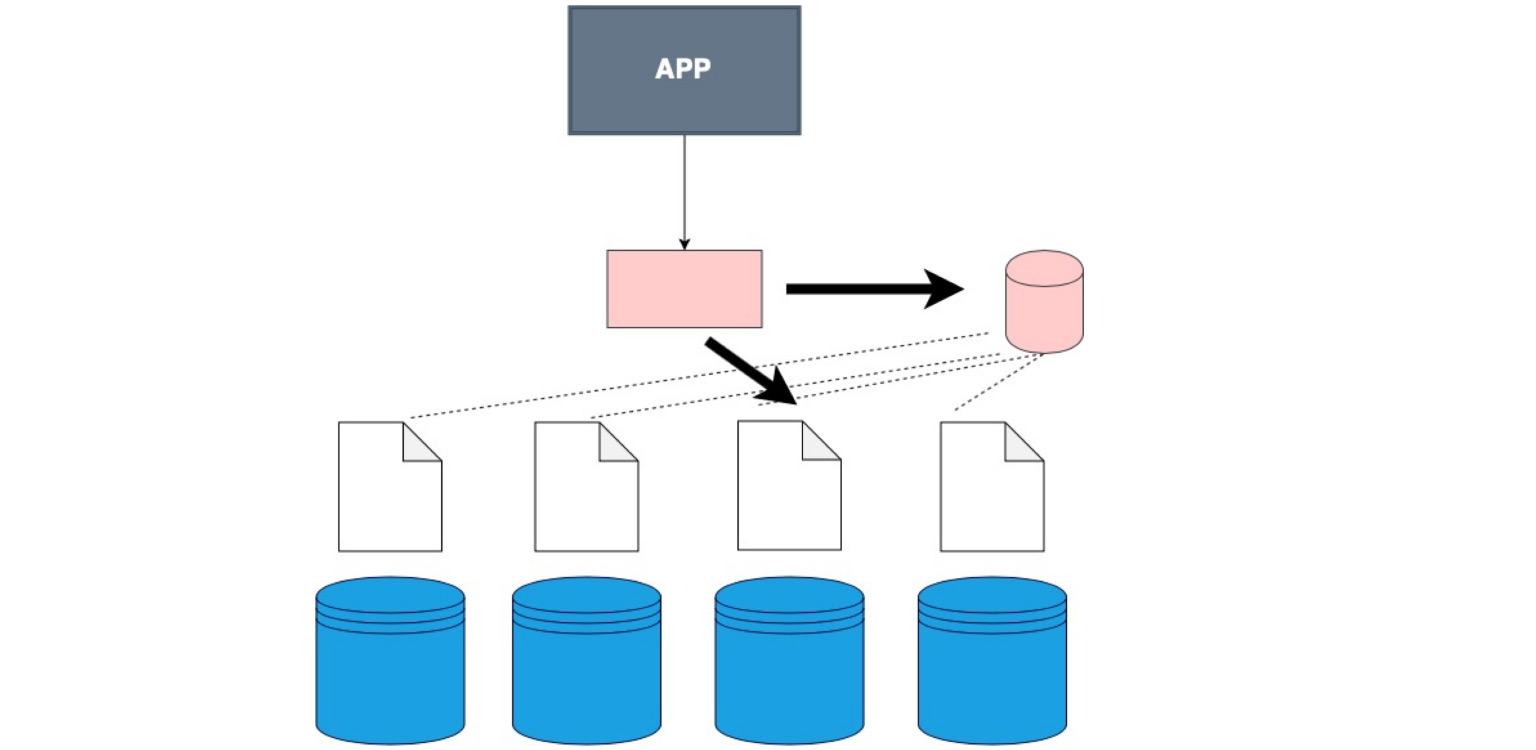
Вот этот случай. Он, кстати, самый частоиспользуемый. Хорош тем, что наше приложение, наш клиент, даже тот код, который вы пишете, — он не знает о том, что таблица шардирована, хотя мы указываем это в config, в самой базе. Мы просто говорим ей — селект, и уже в самой БД идет разбиение на шарды и понимание, откуда селектить. Здесь же вы в самом коде определяете то, откуда читать данные.
Есть специальные сервисы, которые помогают структурировать и вообще апдейтить информаци. Сложно ее держать согласованной и актуальной. Мы что-то заселектили, записали новые данные. Или что-то изменилось, и нам нужно очень правильно маршрутизировать наши запросы. Есть специальные сервисы координации запросов. Один из них — Zookeper. Вы можете посмотреть, как они вообще работают. Очень интересная структура. Они сохранили очень много нервов и времени разработчикам.
Что важно, какие аспекты нужно иметь в виду, когда вы секционируете? Важно понимать, по какому ключу мы будем делать разбиение на шарды. Пересобирать все эти данные достаточно дорого, поэтому очень важно не ошибаться с тем, как данные будут потенциально в будущем использоваться. Если мы хорошо и правильно сделали шардинг, то при наиболее частоиспользуемых запросах мы будем всегда знать, на какую реплику ходить.
Например, если мы по айдишникам пользователя храним все их данные на определенных репликах, тогда мы понимаем, что можем прийти на одну это реплику и все джойны сделать именно на ней. Но хранить именно по айдишнику — не самая крутая идея. Сейчас я расскажу, почему.
Если мы неправильно определили ключ в секционировании, если у нас очень сложный запрос, то нам и правда придется сходить на разные шарды, объединить все данные и только потом отдать их приложению. К счастью, большая часть СУБД делает это за нас. Но какие накладные расходы возникнут под плохо написанными запросами? Или под шардингом, который разбит по неправильному узлу?
Про айдишники. Если система работает только с новыми пользователями и у нас по айдишникам увеличение, то все запросы будут идти в последний узел.
Что получится? Три других работающих машины будут стоять без дела. А эта машина будет просто гореть — так называемый hot spot. Это узкое место вашей потенциальной системы, то место, которое может даже отказать по коннектам.
Поэтому, когда мы определяем ключ шардирования, очень важно понимать, насколько сбалансированы будут эти узлы. Очень часто используются хэши, это такое более-менее нейтральное, сбалансированное расположение данных. Но если у вас хэш-функция на ключе, то вы не сможете выбирать, например, по диапазонам. Логично, потому что по диапазонам нельзя раскинуться в разные шарды.
По дате — то же самое. Если мы, например, аналитику раскидываем и сделаем шарды по дате, то, понятное дело, какой-нибудь один шард десятилетней давности вообще не будет использоваться. Нам это не выгодно. А пересобирать данные и перешардировать всегда очень дорого.
Отвечу на вопрос, который был до этого. Что лучше сделать — определить индексы или сделать шарды? Конечно, индексы.
Смотрите, шарды — это отдельные машины с целой поднятой инфраструктурой. И этот средний компонент содержит нечто похожее на индексы. Есть быстрый поиск по параметрам — где, куда ходить. Вот такое соотношение. Но если есть шардинг, итоговая картина будет вот такая:

Есть приложения, какая-то голова, которая знает, куда ходить. И есть шарды, на каждом из которых настроена реплика. Это реально очень большой overhead, если данных немного. То есть к шардингу нужно прибегать, только когда вы действительно достигли лимита вертикального масштабирования, когда покупать более дорогую машину не релевантно количеству ваших данных или доходам. Тогда можно купить несколько разных, более дешевых машин и выстроить на них вот такую архитектуру.
Для чего нужны реплики, я думаю, понятно: потому что шарды разбиваются, это куски баз данных, но они как бы уникальные. Они находятся только в этих местах. Мы их разбиваем еще и на копии, которые делают наши узлы отказоустойчивыми и подстраховывают на случай проблем.

Самое главное: шардинг используется именно там, где вам не просто хочется разбить данные на классификацию, а именно там, где данных действительно много.
Теперь давайте подойдем больше к моделям данных и посмотрим, как данные можно хранить.
Реляционные БД, которые мы смотрели до этого, имеют огромное количество преимуществ, потому что они, в первую очередь, очень распространены и всем понятны. Они наглядно показывают отношение между объектами и обеспечивают целостность.
Но есть минус: они требуют четкой структуры. Есть таблица, в которую мы должны запихнуть все данные. Если посмотреть с точки зрения вообще всех сведений и фактов, которые мы собираем, они очень разные. То есть у нас может быть работа с продуктовыми данными, с данными пользователей, сообщений и так далее. Эти данные реально требуют четкой структуры, целостности. Для них идеально подходит реляционная база.
Но предположим, у нас есть, например, лог операций или описание объектов, где каждый объект имеет разные характеристики. Мы, конечно, можем это записать в джейсончик в реляционной БД и радоваться, что у нас он разрастается бесконечно.
А можем посмотреть на другие схемы, на другие системы хранения. NoSQL — очень кричащая аббревиатура, даже прямо провоцирующая — «нет SQL». Как она появилась?
Когда люди столкнулись с тем, что реляционные базы данных не везде успешны, они собрали конференцию, который нужен был хештег, — вот и придумали #NoSQL. Он прижился. Позже начали говорить не «нет SQL», а «не только SQL». Это просто все, что не реляционное: огромное семейство разных баз данных, которые не являются такими жестко структурированными, схематичными и табличными, как реляционные БД.
Семейство нереляционных моделей данных разделяют на четыре вида: ключ-значение, документоориентированные, столбцовые и графовые базы данных. Рассмотрим каждый из этих пунктов, узнаем, какие данные в каких из них лучше хранить и для чего они используются.

Ключ-значение. Это самое простое. Вот словарь, вот соотношение. Эта база данных, в которой данные хранятся по ключам, причем неважно, что лежит под конкретным ключом. У нас и сам ключ, и данные могут быть и простыми, и гораздо более сложными структурами. Такая база хороша тем, что она, подобно индексу, очень быстро ищет данные. Именно поэтому key-value очень часто используется для кэша. Преимущество в том, что наше value может быть разное в разных ключах.
Мы можем использовать ключ, например, для хранения сессий пользователя. Пользователь кликнул, мы записали это в value. Это такой schemaless, модель данных без определенной схемы, структуры значений. Благодаря тому, что это очень простая структура, она имеет высокую скорость и легко масштабируется. У нас уже есть ключи, и мы можем очень легко их шардировать, сделать их хэши. Это одна из самых высокомасштабируемых баз данных.
Примеры — Redis, Memcached, Amazon DynamoDB, Riak, LevelDB. Вы можете посмотреть особенности реализации именно key-value хранилищ.

Документоориентированные базы данных очень похожи на key-value в какой-то из областей их применения. Но у них единицей является документ. Это такая сложная структура, по которой мы можем селектить определенные данные, делать балковые операции: Bulk insert, Bulk update.
Каждый документ может хранить в себе, как правило, XML, JSON или BSON — бинарно-сохраняемый JSON. Но сейчас это уже практически всегда JSON или BSON. Это тоже как бы пара ключ-значение, можно это себе представить как таблицу, в которой каждая строка имеет определенные характеристики, и мы по этим ключам можем из нее что-либо доставать.
Преимущество документоориентированных БД: они обладают очень высокой доступностью и гибкостью данных. В любой документ, в любой JSON вы можете записать абсолютно любой набор данных. И они очень часто применяются — например, когда нужно сделать какой-нибудь каталог и когда каждый продукт в каталоге может иметь разные характеристики.
Или, например, профили пользователей. Кто-то указал свой любимый фильм, кто-то — любимую еду. Чтобы не засовывать все в одно поле, которое будет хранить непонятно что, мы можем все записать в JSON документоориентированной базы.
Еще одна модель, в которой удобно хранить данные, — столбцовые БД. Их еще называют колоночными, column database.

Это очень интересная структура, которая используется, как мне кажется, практически во всех больших и сложных проектах. Такая база данных подразумевает, что мы храним данные на диске не строчками, а столбцами. Используется для очень быстрого поиска по огромному объему данных. Как правило — для аналитики, когда нужно проселектить значения только из определенных столбцов.
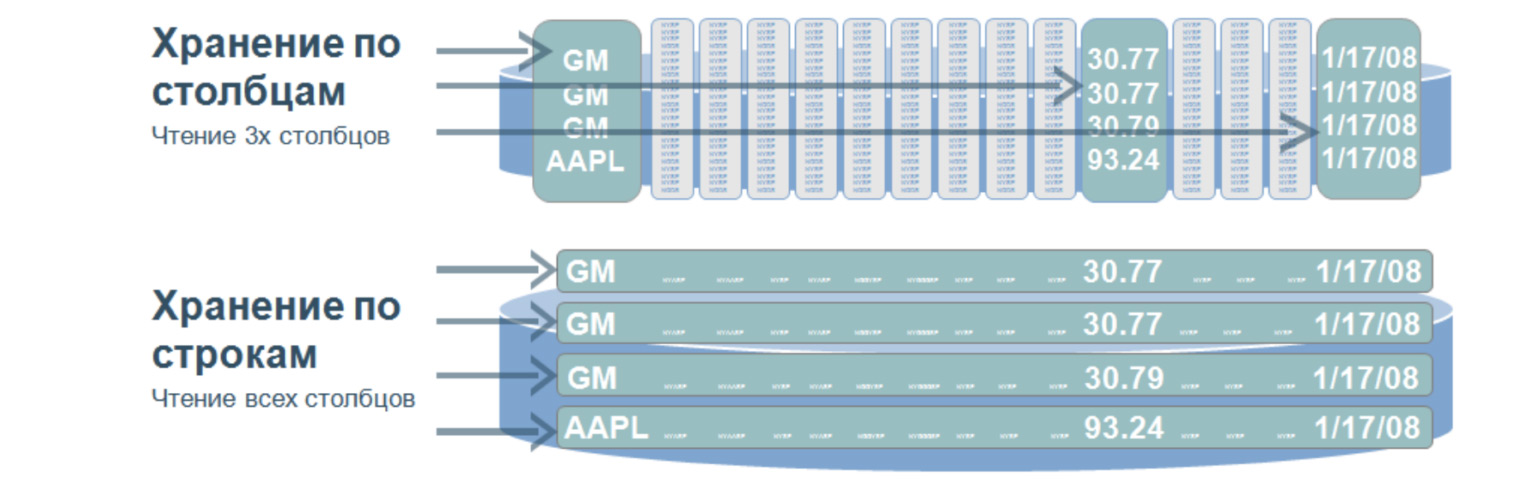
Представим, что у нас есть огромная таблица. И если бы мы хранили данные строчками, то было бы то, что внизу: огромное количество строчек. Для селекта даже по трем параметрам этой таблицы нам нужно пройти по всей таблице. А когда мы храним значения по столбцам, то при селекте по трем значениям нужно пройтись только по трем вот таким, грубо говоря, строчкам, потому что столбцы у нас записываются вот так. Проходя по этим трем строчкам, мы сразу получаем порядковый номер нужного нам значения и достаем его уже из других столбцов.
В чем преимущество таких баз данных? За счет того, что они ищут по маленькому объему данных, у них очень высокая скорость обработки запросов и большая гибкость данных, потому что мы можем добавлять любое количество столбцов, не меняя структуру. Здесь не как в реляционных БД, нам не нужно засовывать наши данные в определенные рамки.
Самые популярные столбцовые — это, наверное, Cassandra, HBase и ClickHouse. Испытайте их. Очень интересно инвертировать в голове отношение строк и столбцов. И это действительно эффективный и быстрый доступ к большому количеству данных.

Есть еще семейство графовых баз данных. Они также содержат узлы и ребра. Ребра используются, чтобы показать отношния, как и в реляционных базах. Но графовые базы могут расти бесконечно в разные стороны. Поэтому она более гибкая. У нее очень высокая скорость поиска, потому что не нужно селектить и джойнить по всем таблицам. У нашего узла сразу есть ребра, которые показывают отношение ко всем разным объектам.
Для чего используются эти базы данных? Чаще всего — именно чтобы показать отношения. Например, в соцсетях можно ответить на вопрос, кто на кого подписан. У нас сразу есть линки на всех фолловеров нужного человека. Еще очень часто эти базы используются для определения схем мошенничества, потому что это тоже связано с демонстрацией связей операций друг с другом. Например, можно отследить, когда эта же банковская карта была использована в другом городе или когда с этого же айпишника заходили в аккаунт какого-нибудь другого пользователя.
Именно эти сложные отношения, которые помогают разрулить нестандартные ситуации, часто используются для анализа такого взаимодействия и взаимоотношения.
Нереляционные базы данных не заменяют реляционные. Они просто другие. Другой формат данных и другая логика их работы, не хуже и не лучше. Это просто другой подход к другим данным. И да, нереляционные базы используются очень часто. Их не нужно бояться, их нужно, наоборот, пробовать.
Если вы делаете кэш, то, естественно, берете какой-нибудь Redis, простое и быстрое key-value. Если у вас есть огромное количество логов для анализа, вы можете скинуть его в ClickHouse или в какую-нибудь колоночную базу, по которой потом будет очень удобно искать. Либо записать в документоориентированную базу, потому что там может быть разное значение документов. Это тоже может оказаться удобно для селекта.
Выбирайте модель данных в зависимости от того, какие данные вы будете использовать. Либо реляционная, либо нереляционная. Охарактеризуйте данные. Так вы сможете подобрать самое подходящее хранилище, которое в будущем сможете масштабировать.

Вы сегодня узнали очень много о самых разных проблемах и способах хранения данных. Еще раз повторю то, что я говорила в самом начале: не нужно знать прямо все досконально, не нужно копаться в чем-то одном. Если интересно — конечно, можно. Но важно знать о том, что это вообще существует, какие есть подходы и как вообще можно мыслить. Если нужна отказоустойчивость, есть смысл сделать реплику. Предположим, я записала данные, но не увидела. Тогда, наверное, моя реплика дала лаг. Не нужно изобретать велосипеды — есть уже много готовых решений для разных задач. Расширяйте кругозор, а если появится баг или какая-нибудь другая проблема, вы по характеристикам бага поймете, где именно произошел сбой, сможете найти решение через поисковик. Спасибо за внимание.
